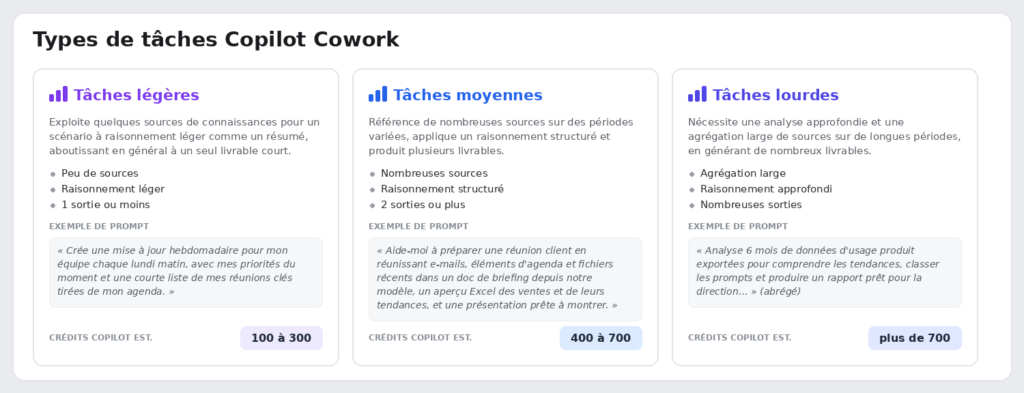
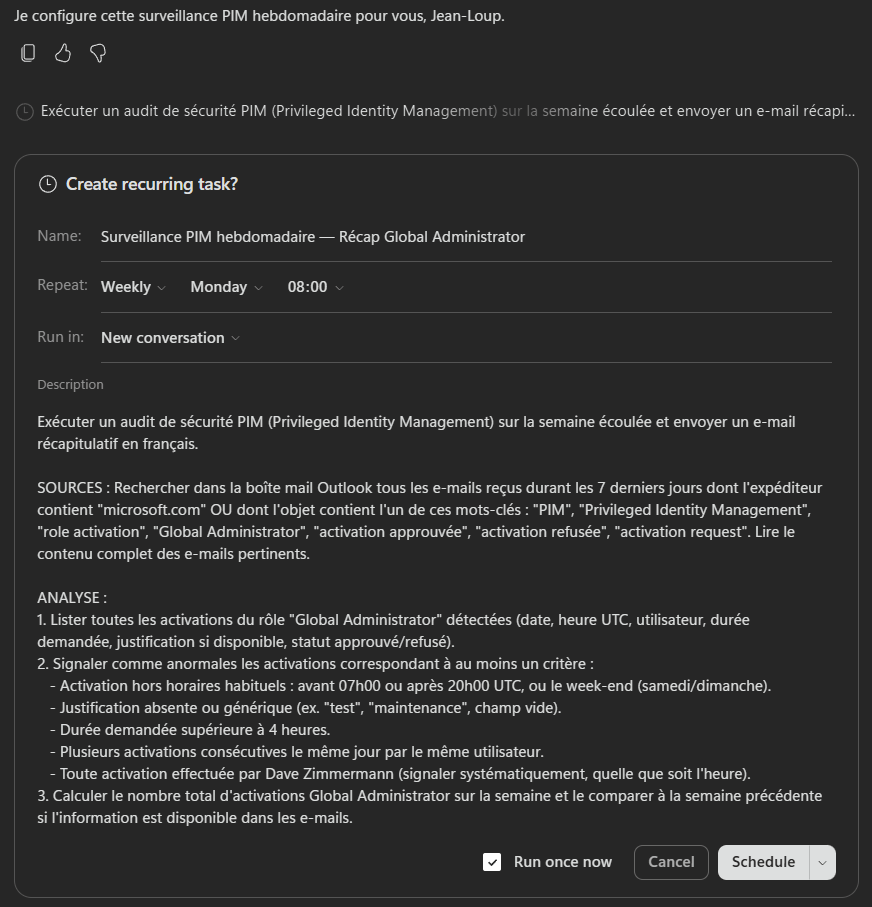
Depuis quelques mois, à l’heure où j’écris ces lignes fin juillet 2026, vous avez peut-être déjà reçu un ou plusieurs mails d’Azure au sujet de certaines de vos machines virtuelles : des annonces sur les Reserved Instances, sur des séries qui partent à la retraite, et vous vous demandez ce qui va réellement vous tomber dessus, et surtout quand ? Cet article est fait pour vous.

Car ces annonces ne forment pas un seul événement, mais trois vagues distinctes qui convergent sur la même période. On va les démêler une par une, poser le calendrier noir sur blanc, puis dérouler, capture après capture, ce que vous devez vérifier et faire dès maintenant dans le portail Azure. Objectif : que vous ressortiez de cette lecture avec un plan d’action clair, pas juste une vague inquiétude.
Pour vous guider plus facilement dans cet article, voici des liens rapides :
- Pour rappel : de quoi on parle ?
- Vague 1 : la fin des Reserved Instances (1er juillet 2026)
- Vague 2 : le gel de la croissance de capacité (31 juillet 2026)
- Vague 3 : le calendrier de retraite des séries v1 à v4
- Vers quoi migrer ? Les séries cibles v5, v6, v7
- Ce que vous devez faire, concrètement
- En résumé : les pièges à retenir
Pour rappel : de quoi on parle ?
Les annonces Azure mélangent plusieurs vocabulaires, et la plupart des malentendus viennent de leur confusion. Le cycle de vie d’une taille de VM passe par quatre états successifs :
- Génération courante : la série recommandée, avec capacité garantie.
- Previous-gen (génération précédente) : encore pleinement supportée, mais sans garantie de capacité supplémentaire. Deux nuances, next-gen available (pas encore de date de retraite) et capacity limited (plus aucune capacité déployée).
- Retraite annoncée : une date de fin est fixée, la VM tourne encore mais il faut migrer.
- Retirée : la taille n’est plus disponible, impossible d’en provisionner.
Deux autres termes, financiers cette fois, reviennent sans arrêt :
- Reserved Instance (RI) : un engagement d’un ou trois ans sur une série de VM précise, en échange d’une remise. C’est un dispositif de facturation, pas un état de la VM.
- Quota : le plafond de cœurs que votre abonnement peut déployer pour une série donnée, dans une région donnée.
Le fil rouge de tout l’article tient en deux phrases : previous-gen ne veut pas dire retirée, et fin des RI ne veut pas dire retraite de la VM. Gardez ces distinctions en tête, elles évitent la grande majorité des paniques inutiles.
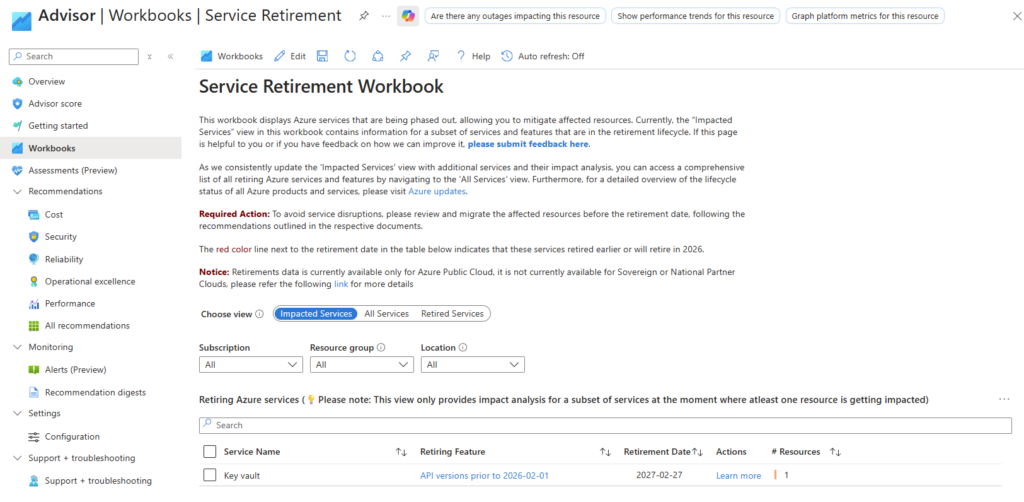
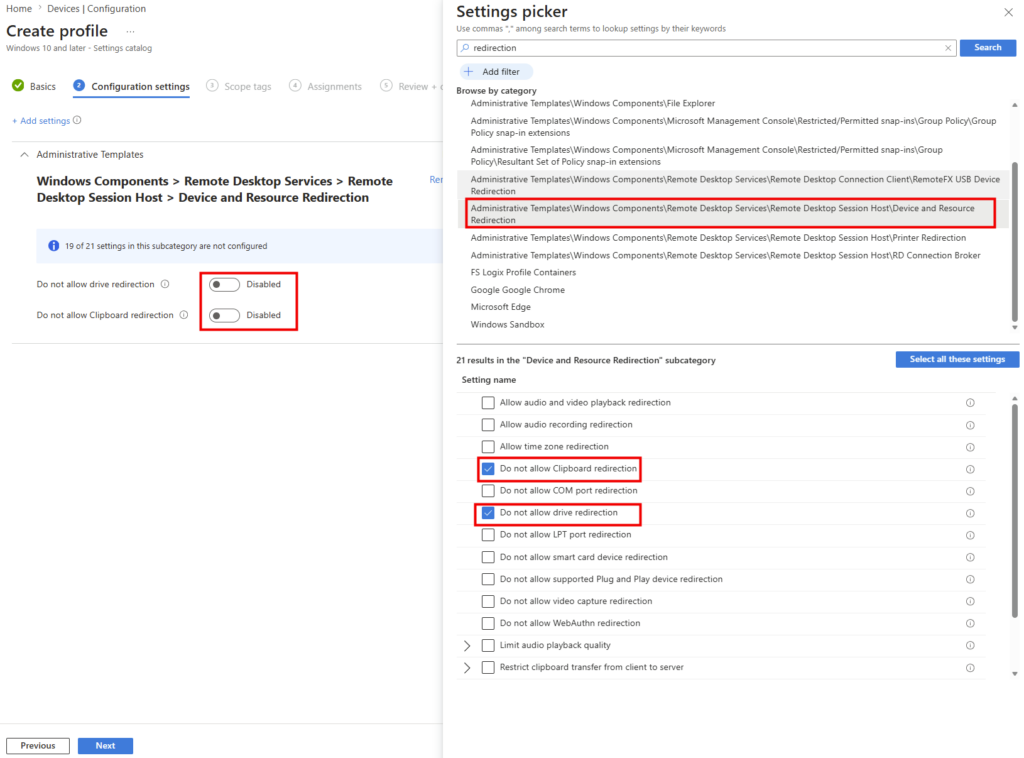
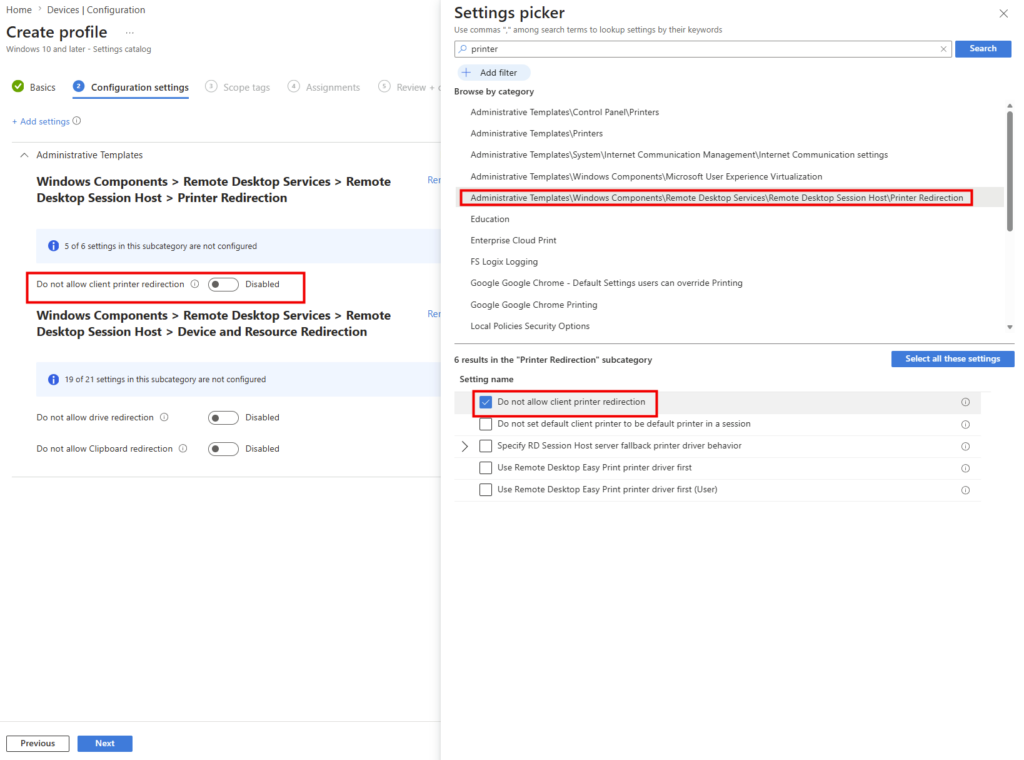
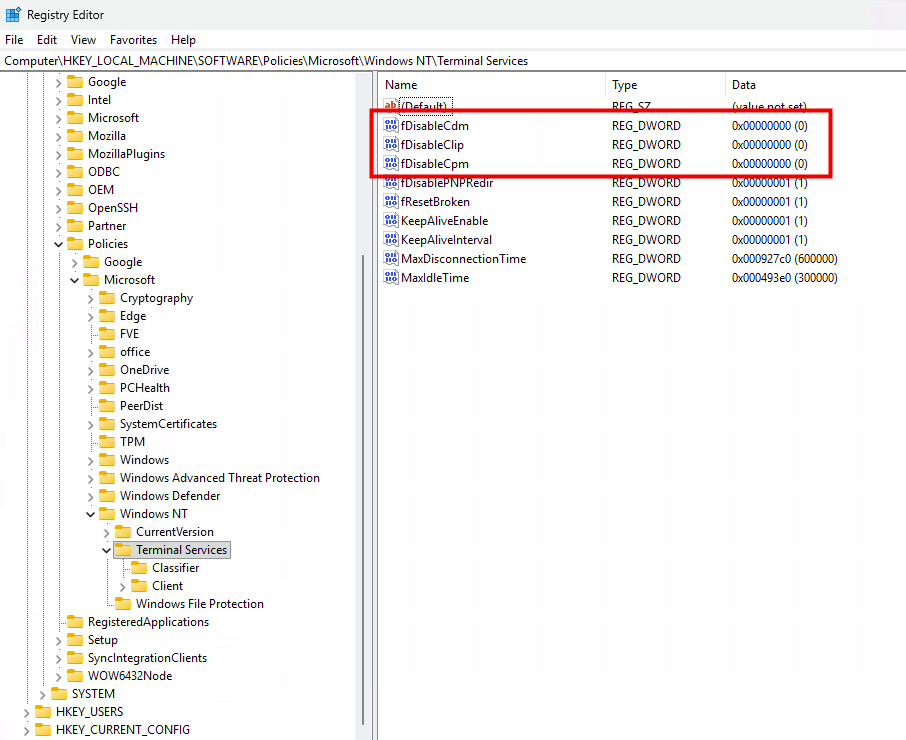
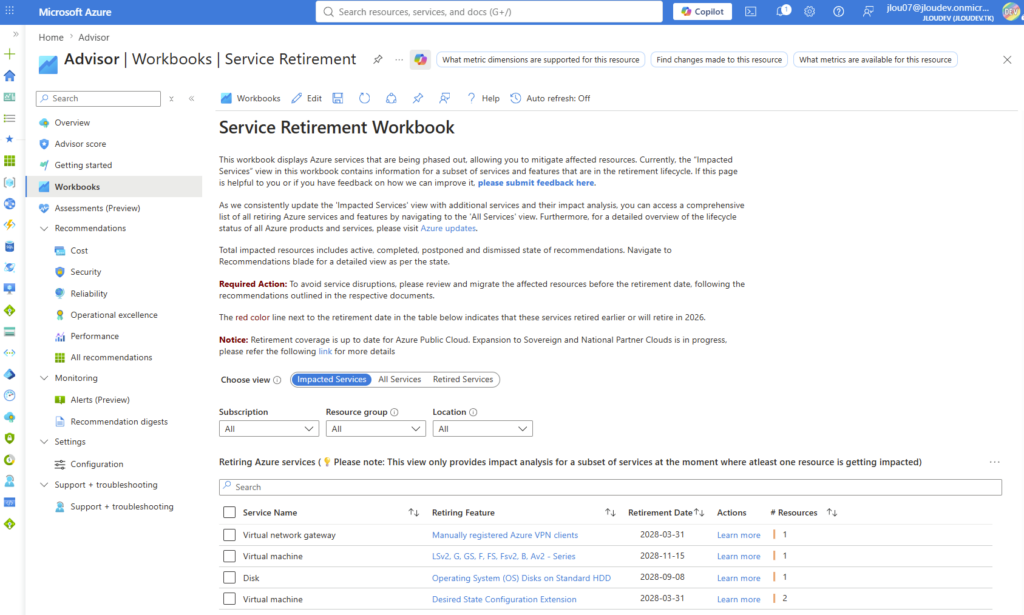
Voici d’ailleurs pour info un portail très utile des décommissionnements prévus par Microsoft, accessible directement depuis le portail Azure Advisor :
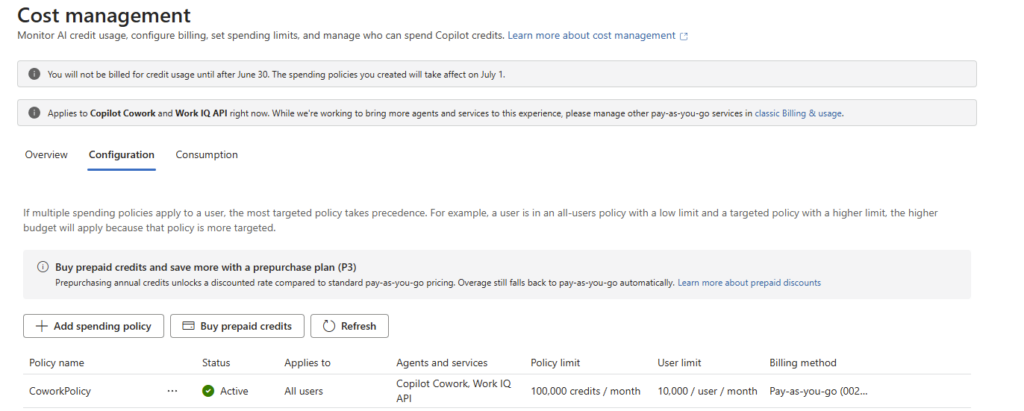
Vague 1 : la fin des Reserved Instances (1er juillet 2026)
Première vague dans l’ordre chronologique, et elle est déjà passée. Depuis le 1er juillet 2026, Azure ne vend plus et ne renouvelle plus certaines Reserved Instances. Mais l’histoire a commencé bien avant cette date, car les réservations 1 an et 3 ans ne s’arrêtent pas au même moment. Voici le tableau complet des échéances :
| Séries | RI 3 ans : plus d’achat ni de renouvellement depuis | RI 1 an : plus d’achat ni de renouvellement depuis |
|---|---|---|
| D, Ds, Dv2, Dsv2, Ls | 1er mai 2025 | 1er juillet 2026 |
| Av2, Amv2, Bv1, F, Fs, Fsv2, G, Gs, Lsv2 | 15 novembre 2025 | 1er juillet 2026 |
| Dv3, Dsv3, Ev3, Esv3 | 1er juillet 2026 | 1er juillet 2026 |
Ce qu’il faut lire dans ce tableau : pour la plupart de ces séries, les réservations 3 ans ne sont déjà plus renouvelables depuis 2025 (mai pour la famille D et Ls, novembre pour les autres). Seules les réservations 1 an tenaient encore, et c’est cette dernière porte qui s’est refermée le 1er juillet 2026. Pour Dv3, Dsv3, Ev3 et Esv3, les deux durées s’arrêtent le même jour, le 1er juillet 2026.
Un point capital pour Dv3, Dsv3, Ev3 et Esv3 : ces séries ne sont pas retirées, elles restent « product active ». Ce sont seulement leurs réservations qui s’arrêtent. Ne confondez pas les deux.
Le piège classique : croire que le renouvellement automatique vous protège. Il ne joue plus pour ces séries. Vos réservations existantes restent valables jusqu’au bout de leur terme, un contrat 3 ans en cours court par exemple jusqu’à sa date de fin, mais à leur expiration, la charge bascule automatiquement en tarif pay-as-you-go, souvent bien plus cher, même si l’option de renouvellement automatique était cochée.
« July 1, 2026 does not terminate existing RIs. RIs remain valid until their individual expiration dates. »
Source : Transition guide for retired Azure Reserved VM Instances, Microsoft Learn
Trois leviers, selon votre situation :
- Passer à l’Azure savings plan for compute : un engagement basé sur la dépense horaire, flexible entre familles de VM et entre régions. C’est la recommandation numéro un de Microsoft.
- Migrer vos charges vers une série récente, qui redonne accès aux RI comme aux Savings Plans.
- Ne rien faire et assumer le pay-as-you-go, mais que ce soit un choix conscient, pas un oubli.
Note : la possibilité de renouveler une dernière fois les réservations 1 an existait jusqu’au 30 juin. Depuis le 1er juillet, cette porte est fermée pour les séries listées ci-dessus, et celle des réservations 3 ans l’était déjà depuis 2025 :
Vague 2 : le gel de la croissance de capacité (31 juillet 2026)
Deuxième vague, et de loin la plus imminente puisque la première est déjà derrière nous. À compter du 31 juillet 2026, Azure gèle la croissance de capacité des anciennes séries. Concrètement, les demandes suivantes ne seront plus approuvées :
- les nouveaux déploiements de VM sur ces séries,
- les opérations de scale-out qui réclament de la capacité supplémentaire,
- les demandes d’augmentation de quota,
- vos plans de croissance future sur ces séries.
Ce qui n’est pas touché, et c’est la bonne nouvelle : vos déploiements existants continuent de tourner dans la limite de la capacité déjà allouée. Aucune interruption, aucune VM coupée du jour au lendemain à cause de ce gel.
Les séries concernées se répartissent en deux groupes. D’abord celles qui partent à la retraite et sont soumises au gel :
- Compute optimisé : F, Fs, Fsv2
- Usage général : D, Ds, Dv2, Dsv2, Av2, Amv2, B, Bs
- Mémoire : G, Gs
- Stockage : Ls, Lsv2
Ensuite celles qui ne sont pas (encore) retirées mais déjà soumises au contrôle de croissance :
- Usage général : Dv3, Dsv3, Dv4, Dsv4, Ddv4, Ddsv4, Dav4, Dasv4
- Mémoire : Ev3, Esv3, Ev4, Esv4, Edv4, Edsv4, Eav4, Easv4
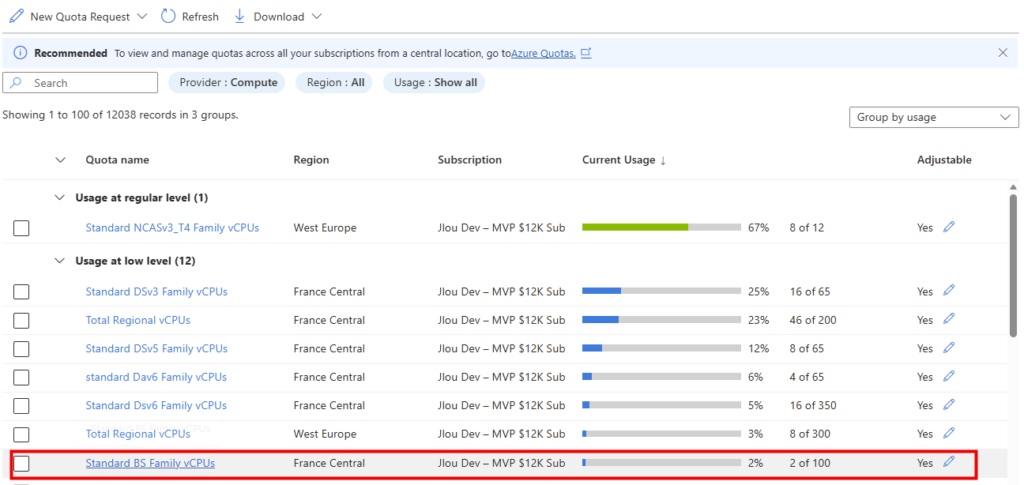
Je vous propose de regarder en exemple une machine virtuelle en série Bs avant la date du 31 juillet 2026. Le redimensionnement de celle-ci vers différentes tailles de la même famille est possible :
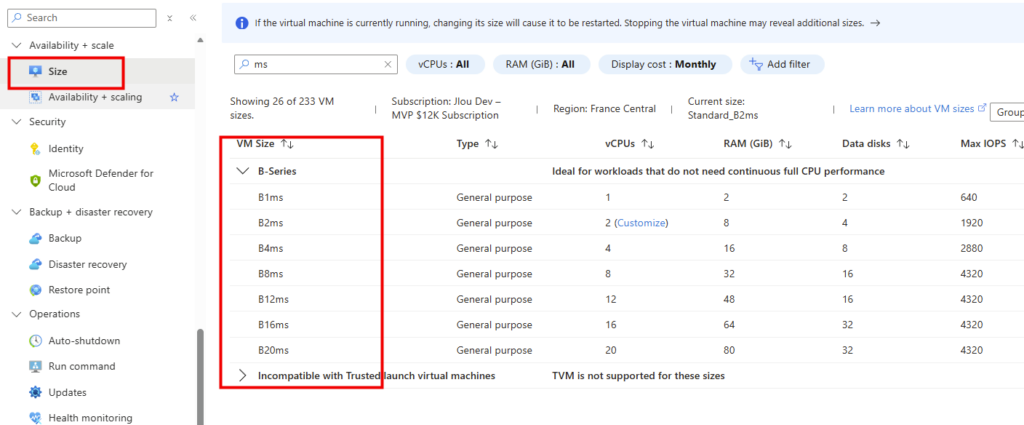
Et celui-ci fonctionne bien :
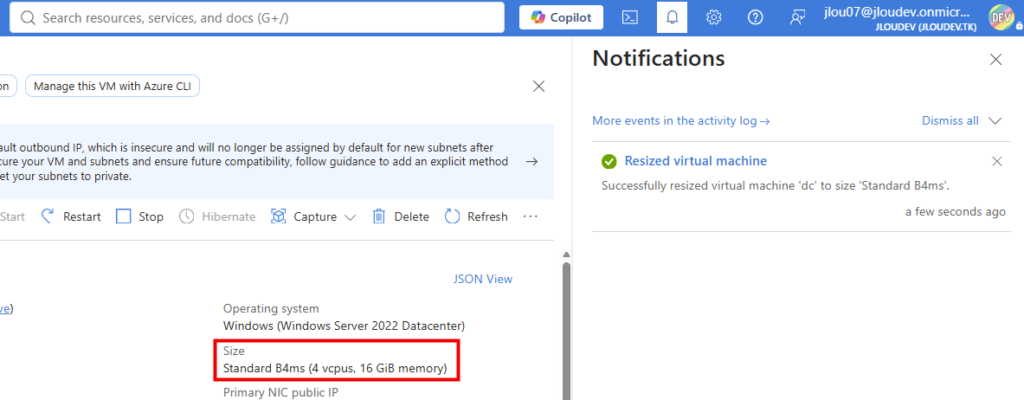
Par contre, j’avais déjà eu un refus de la part de Microsoft sur une demande d’augmentation de quota pour cette série :

Je vous referai dans quelques jours d’autres copies d’écran afin de comparer le changement à partir du 1er août.
Vague 3 : le calendrier de retraite des séries v1 à v4
Troisième vague, la plus étalée dans le temps. Voici le calendrier consolidé des retraites, de la plus ancienne (déjà effective) à la plus lointaine.
| Série | Catégorie | Statut | Date de retraite |
|---|---|---|---|
| NCv3, NCv3-NC24rs | GPU | Retirée | 30/09/2025 |
| NVv3, NVv4 | GPU | Annoncée | 30/09/2026 |
| M192idms_v2, M192ids_v2, M192ims_v2, M192is_v2 | Mémoire | Annoncée | 31/03/2027 |
| NP-series | FPGA | Annoncée | 31/05/2027 |
| D, Ds, Dv2, Dsv2 | Usage général | Annoncée | 01/05/2028 |
| Ls | Stockage | Annoncée | 01/05/2028 |
| Av2, Amv2 | Usage général | Annoncée | 15/11/2028 |
| B-series (V1) | Usage général | Annoncée | 15/11/2028 |
| F, Fs, Fsv2 | Compute optimisé | Annoncée | 15/11/2028 |
| G, Gs | Mémoire | Annoncée | 15/11/2028 |
| Lsv2 | Stockage | Annoncée | 15/11/2028 |
Deux lectures à retenir. D’une part, certaines séries GPU sont déjà retirées depuis septembre 2025 : si vous tournez encore dessus, vous êtes hors support et hors SLA. D’autre part, le gros des séries généralistes (D, Ds, Av2, F, G et compagnie) part en 2028, ce qui vous laisse du temps pour planifier, à condition de commencer maintenant. Le lot du 15 novembre 2028 (F, Fs, Fsv2, Lsv2, G, Gs, Av2, Amv2 et la série B) fait d’ailleurs l’objet d’une annonce dédiée, l’Azure Update 500682.
Vers quoi migrer ? Les séries cibles v5, v6, v7
Bonne nouvelle, Microsoft fournit une table de correspondance claire. Voici les cibles recommandées, série par série.
| Séries actuelles | Cibles recommandées | À noter |
|---|---|---|
| D, Ds, Dv2, Dsv2 | Dsv5/Ddsv5/Dasv5/Dadsv5, Dsv6/Ddsv6/Dasv6/Dadsv6, Dasv7/Dadsv7 | Contrôleur de disque SCSI en v5, NVMe en v6 et v7 |
| Av2, Amv2 | Bsv2/Basv2, Dsv5/Dasv5, Esv5/Easv5, Dsv6/Dasv6, Esv6/Easv6 | SCSI en v5, NVMe en v6 |
| Bv1 | Bsv2/Basv2, Dlsv5/Dalsv5, Dlsv6/Dalsv6 | Débit de stockage distant plus élevé |
| F, Fs, Fsv2 | Falsv6, Dlsv6/Daldsv6, Dlsv5/Dsv5/Ddsv5 | NVMe en v6 |
| G, Gs | Lsv3/Lasv3, Lsv4/Lasv4 | Stockage local NVMe, débit distant nettement supérieur |
| Ls, Lsv2 | Lsv3/Lasv3, Lsv4/Lasv4 | Lsv4 et Lasv4 sont la dernière génération L |
| Dv3, Dsv3 (RI arrêtées) | Dsv5/Ddsv5/Dasv5, Dsv6/Ddsv6/Dasv6 | Pas retirées, mais plus de RI |
| Ev3, Esv3 (RI arrêtées) | Esv5/Edsv5/Easv5, Esv6/Edsv6/Easv6 | Pas retirées, mais plus de RI |
Ce que vous devez faire, concrètement
Assez de théorie. Voici la marche à suivre, étape par étape, capture après capture. Comptez une petite heure pour un premier inventaire propre.
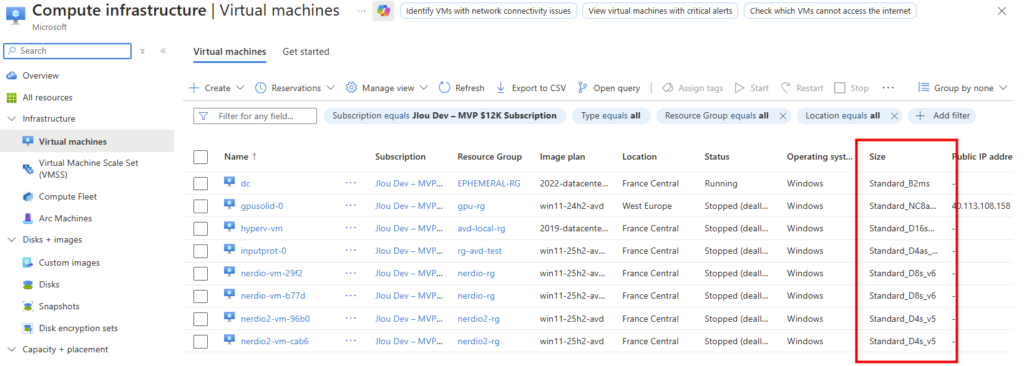
Étape 1 : inventorier vos VM par série
Direction le portail Azure. Dans la barre de recherche, tapez Virtual machines pour ouvrir la liste de vos VM. Ajoutez la colonne Size (bouton Manage view puis Edit columns) pour voir d’un coup d’œil la taille de chaque machine, puis repérez celles dont la série figure dans les tableaux ci-dessus :
Vous pouvez aussi utiliser le rapport Service Retirement Workbook disponible dans Azure Advisor :
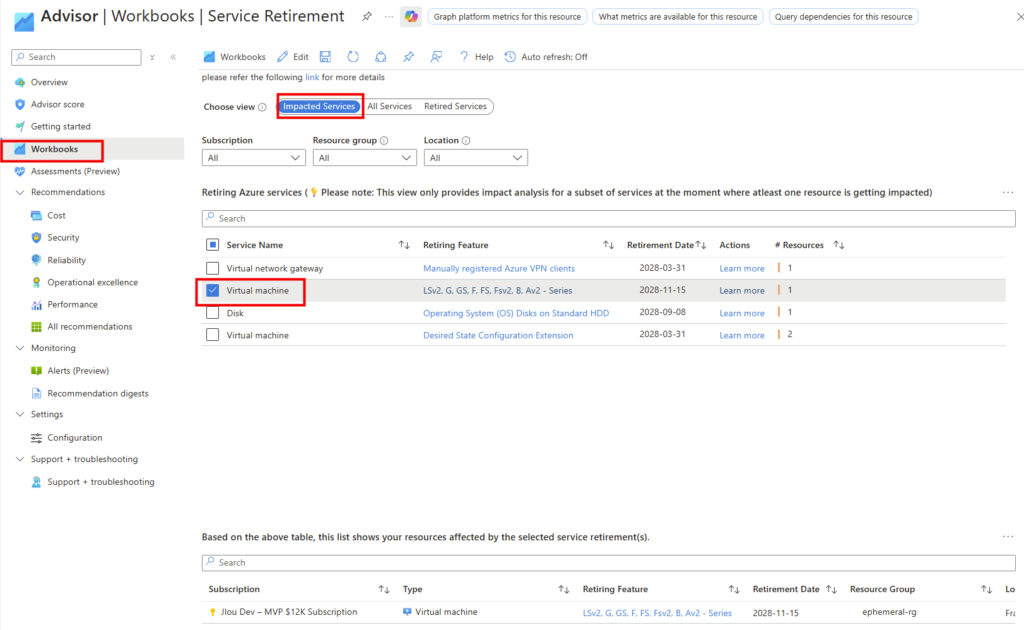
Étape 2 : auditer vos Reserved Instances
Toujours dans le portail, recherchez Reservations. Filtrez par Product type réglé sur Virtual machines, puis examinez deux colonnes, la VM family et la date d’expiration. Toute réservation dont la famille figure dans la liste de la vague 1 est concernée :
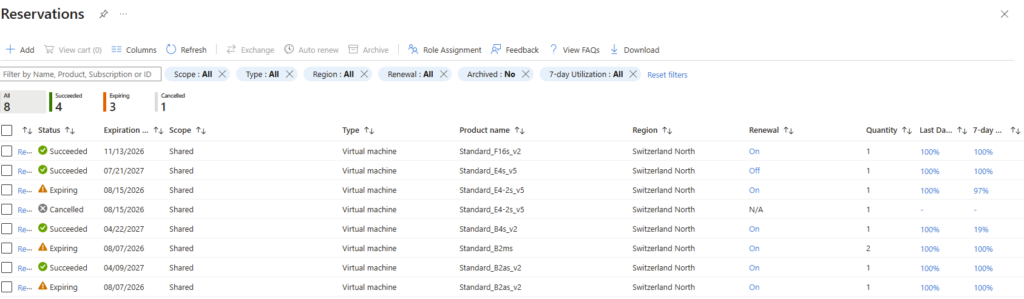
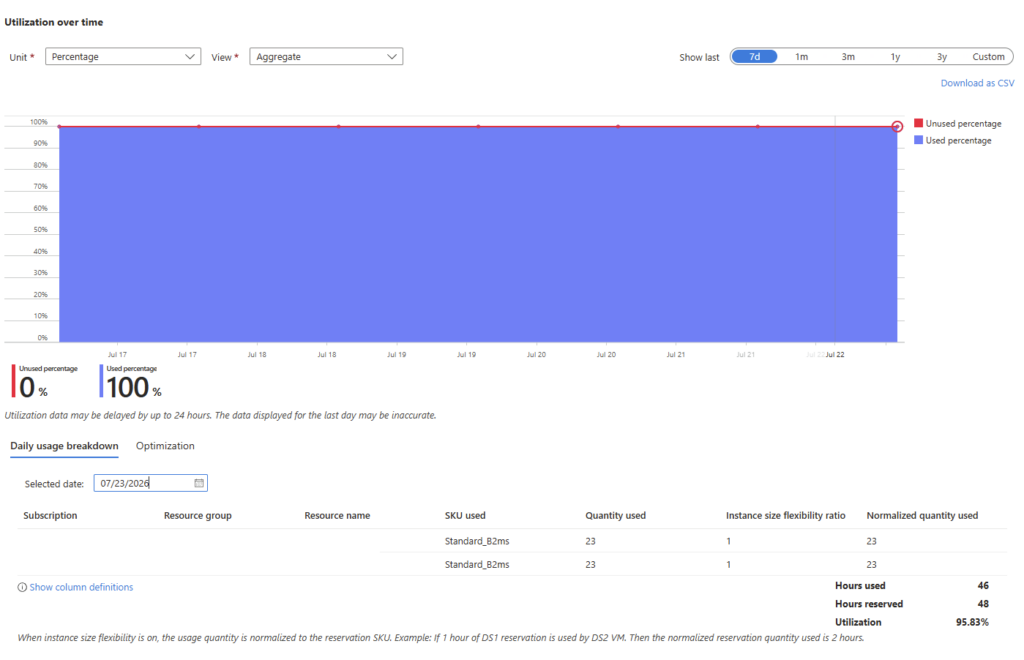
Pour aller plus loin, ouvrez le détail de la réservation concernée et vérifiez son taux d’utilisation ainsi que sa date de fin. Confirmez si la charge continuera au-delà de l’expiration : si oui, il faut agir avant :
Étape 3 : choisir votre stratégie de coûts
Pour chaque réservation ou VM concernée, tranchez entre trois options : basculer vers un Azure savings plan for compute, moderniser la VM, ou assumer le pay-as-you-go.
Le trade-in d’une réservation vers un Savings Plan se fait en libre-service depuis le portail :
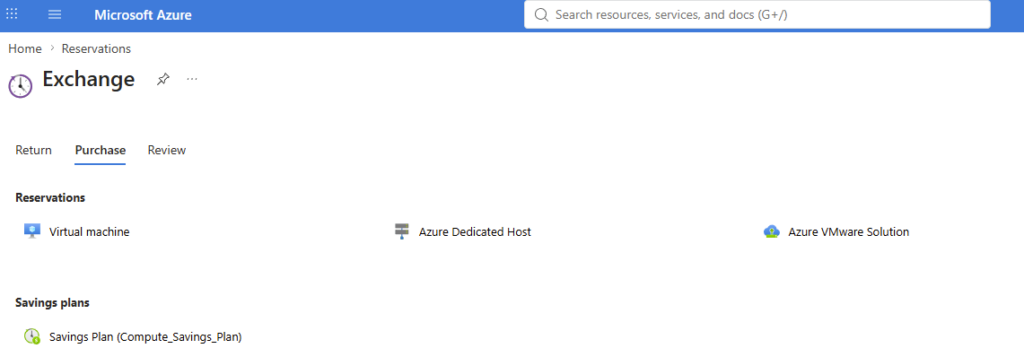
Passez un instant sur le calculateur de prix Azure pour chiffrer l’écart entre votre coût actuel et la cible :
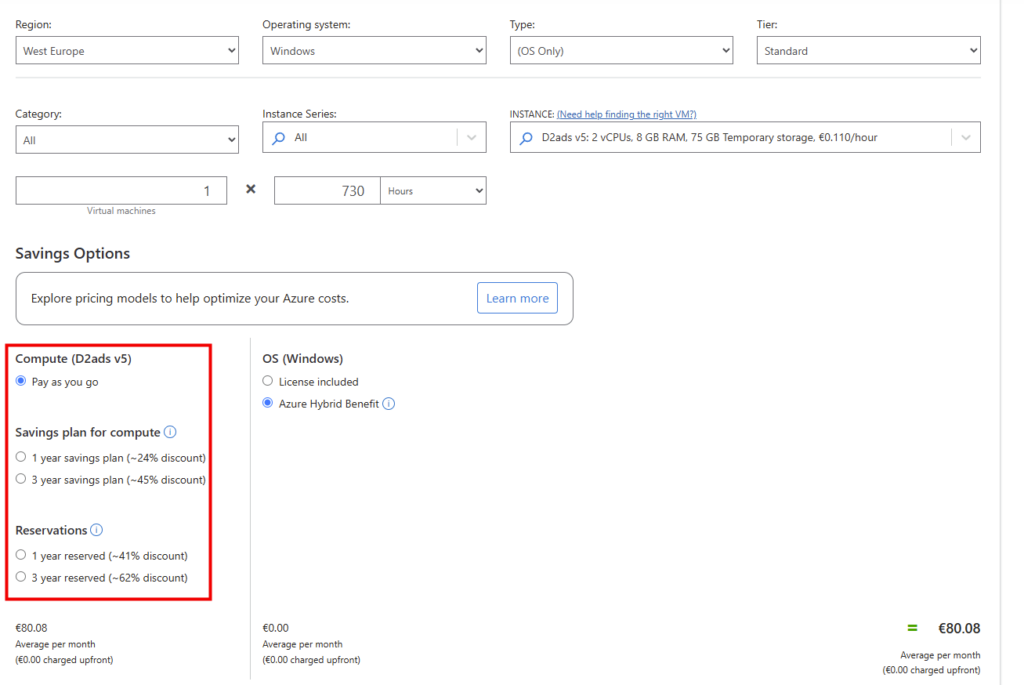
Étape 4 : vérifier le quota de la série cible
Avant de redimensionner, assurez-vous que votre abonnement dispose d’assez de quota pour la série visée. Ouvrez Subscriptions, sélectionnez votre abonnement, puis Usage + quotas :
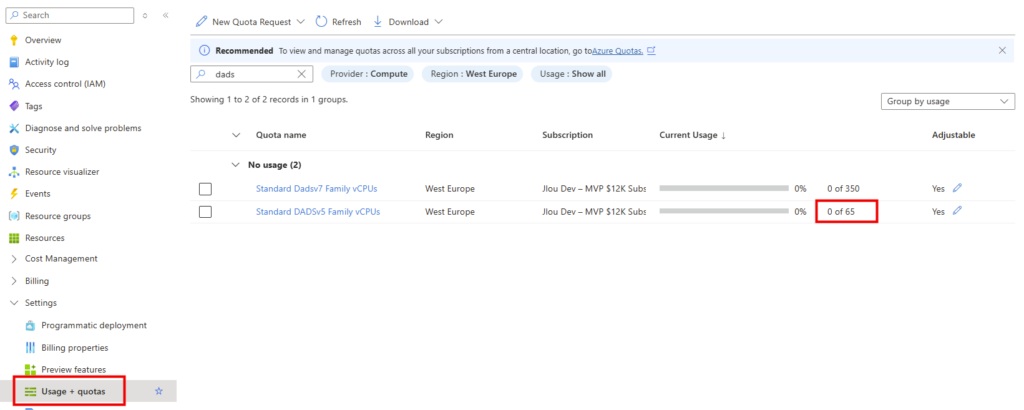
Si le plafond est trop bas, cliquez sur Request increase pour demander une augmentation sur la série cible :
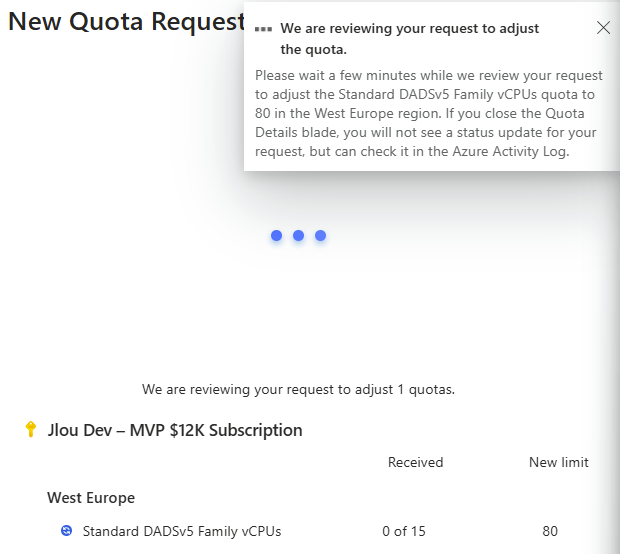
Étape 5 : redimensionner la VM
Dernière ligne droite. Le redimensionnement se fait en trois temps. Sur la VM, cliquez sur Stop pour la désallouer proprement avant :
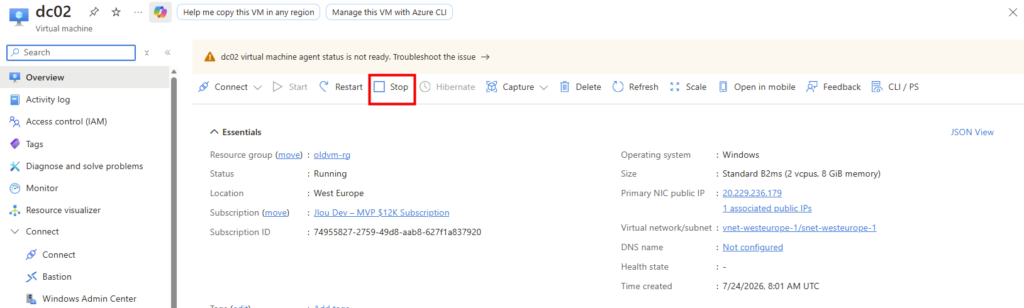
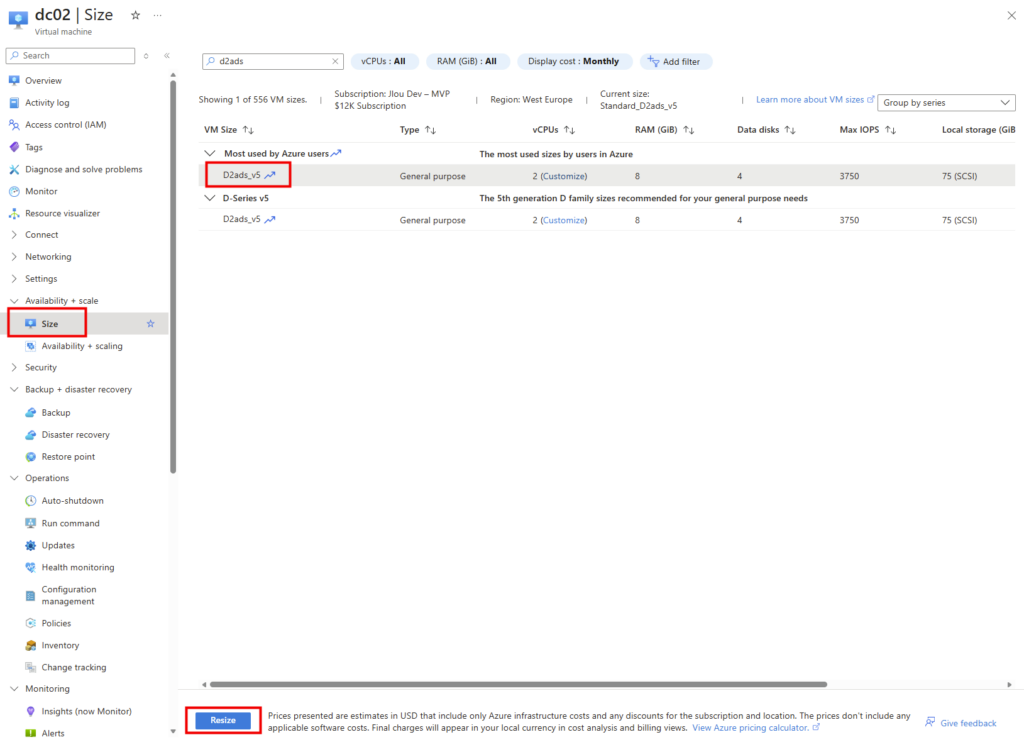
Une fois la machine virtuelle arrêtée et désallouée, ouvrez le volet Size, choisissez la taille cible, validez avec Resize :
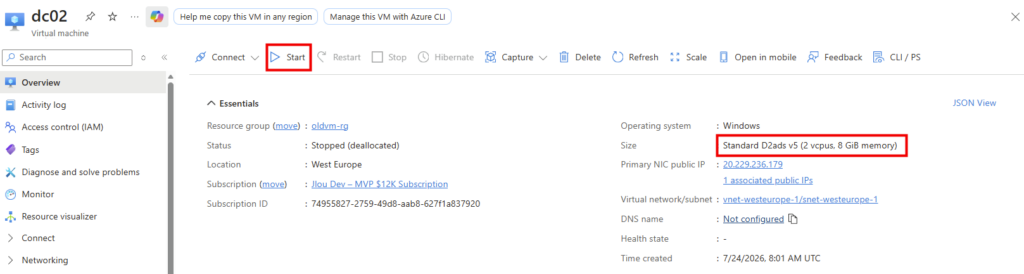
Une fois le redimensionnement réussi, cliquez sur Start pour redémarrer la machine :
Le piège classique : oublier que les données du disque temporaire et de la mémoire sont perdues à la désallocation. Les disques managés, eux, sont conservés. Prévenez donc les applications qui s’appuient sur le disque temporaire avant de lancer l’opération.
En résumé : les pièges à retenir
Voilà, en trois vagues, tout ce qui se joue sur vos anciennes VM Azure. Concrètement, qu’est-ce que vous devez garder en tête ?
- Deux dates pivots : le 1er juillet 2026 (fin des RI 1 an, déjà passé, les RI 3 ans ayant même cessé dès 2025) et le 31 juillet 2026 (gel de capacité, imminent).
- Previous-gen n’est pas retirée, mais capacity limited peut vous bloquer bien avant la date de retraite officielle.
- Fin des RI n’est pas retraite de la VM : Dv3, Dsv3, Ev3 et Esv3 restent actives, seules leurs réservations s’arrêtent.
- Le renouvellement automatique ne joue plus : à l’expiration, bascule silencieuse en pay-as-you-go.
- La v6 impose des prérequis (NVMe, Génération 2, MANA) et une capacité régionale non garantie : testez avant.
- À la désallocation, disque temporaire et mémoire perdus, disques managés conservés.
Le vrai message : aucune de ces vagues ne coupe vos VM du jour au lendemain, mais toutes récompensent ceux qui anticipent et punissent ceux qui attendent. Faites votre inventaire cette semaine, pendant que vous avez encore le temps de choisir plutôt que de subir.
Foncez auditer vos abonnements, et si cet article vous a fait gagner du temps, dites-le moi en commentaire.
Pour aller plus loin
- Retired VM Sizes Migration Guide, Microsoft Learn
- Migration guidance for newer-generation VM series (v6, v7), Microsoft Learn
- Retired Azure VM size series, Microsoft Learn
- Previous-gen and retired VM size series, Microsoft Learn
- Azure Reserved VM Instances for select VM series will no longer be available starting July 1, 2026, Tech Community
- Transition guide for retired Azure Reserved VM Instances, Microsoft Learn
- Retirement: The F, Fs, Fsv2, Lsv2, G, Gs, Av2, Amv2, and B series VMs are retiring in 2028 (Azure Update 500682)