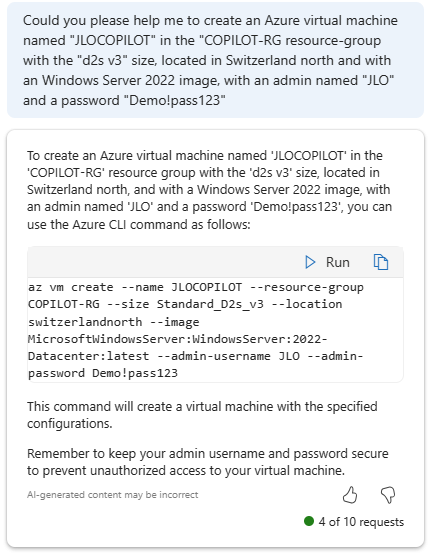
Bienvenue dans ce lab pratique consacré à Microsoft Foundry, la plateforme unifiée qui permet d’explorer, tester et déployer des expériences d’intelligence artificielle au sein de l’écosystème Azure. Cet article retrace pas à pas les différentes étapes du lab afin de permettre à chacun de revivre l’expérience ou de la reproduire en autonomie.
Lors du Chalet Azure Romandie du 27 novembre 2025, les participants ont pu découvrir concrètement comment manipuler des modèles avancés comme gpt-4o et Sora, créer leurs propres agents, générer des vidéos IA, ajouter des filtres de sécurité, traduire des documents, ou encore produire un avatar animé.
Voici donc les 5 défis que vous pouvez également essayer :
- Etape 0 – Connexion à Microsoft Foundry
- Défi I – Création d’un Agent Smith
- Défi II – Génération d’une vidéo IA
- Défi III – Filtrage IA de contenu
- Défi IV – Traduction IA de documents
- Défi V – Avatar IA
Le Chalet Azure Romandie remercie d’ailleurs Philippe Paiola de chez Microsoft pour la création de ces défis 🙏.
Etape 0 – Connexion à Microsoft Foundry :
Pour réaliser cet exercice sur Microsoft 365 Archive, il vous faudra disposer d’une souscription Azure valide.
Ouvrez un navigateur web, puis saisissez l’URL du portail Azure AI Foundry (nouvellement Microsoft Foundry) :
Authentifiez-vous avec un e-mail professionnel ou personnel :
Une fois authentifiée, conservez l’ancienne présentation du portail de Microsoft Foundry, appelée encore Azure AI Foundry, afin de suivre les consignes ci-dessous plus facilement :
Commençons le premier défi par le déploiement d’un agent.
Défi I – Création d’un Agent Smith :
Nous allons déployer un agent qui s’appuiera sur le modèle gpt-4o et répondra aux différentes questions du défi.
Pour cela, cliquez-ici pour créer votre agent :
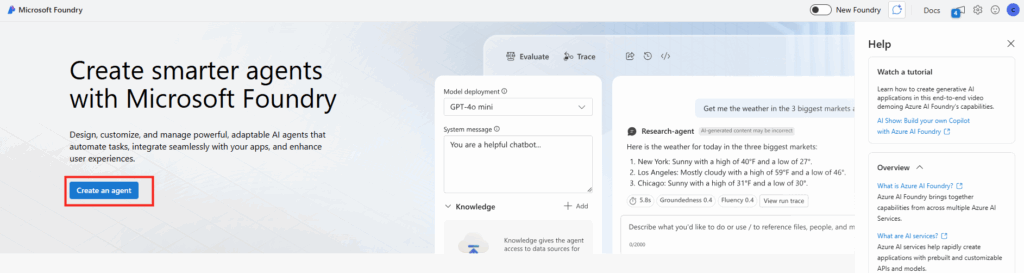
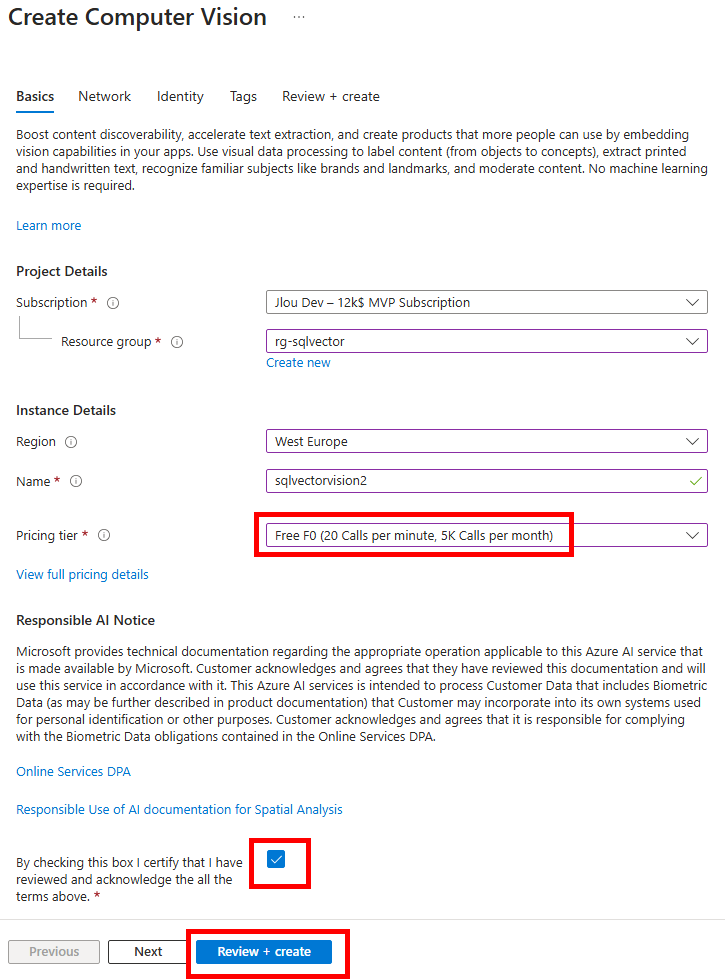
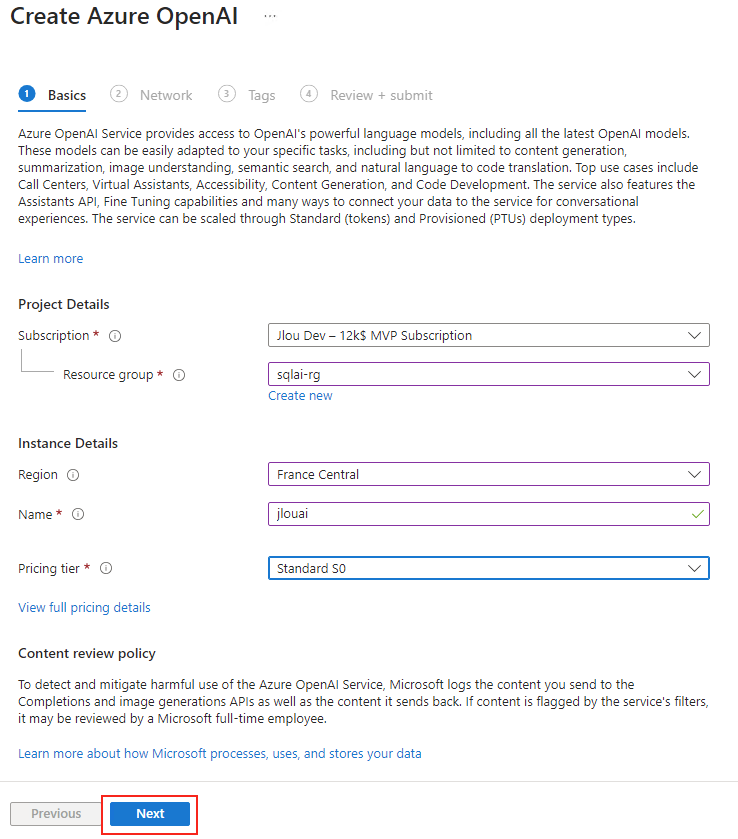
Mais comme aucun projet IA n’est encore présent, nous allons commencer par la création de celui-ici. Pour cela, renseignez les informations pour la création de votre nouveau projet IA, puis lancez sa création :
- Dans le champ Projet, saisissez projet-agent
- Développez options avancées
- Choisissez la souscription Azure disponible
- Donnez un nom unique à votre ressource Azure AI Foundry
- Nommez rg-chalet-romandie le nom de votre groupe de ressource
- Vérifiez que la région Azure East US 2 est bien sélectionnée
Attendez environ 2 à 3 minutes pour la fin de la création des ressources Azure :
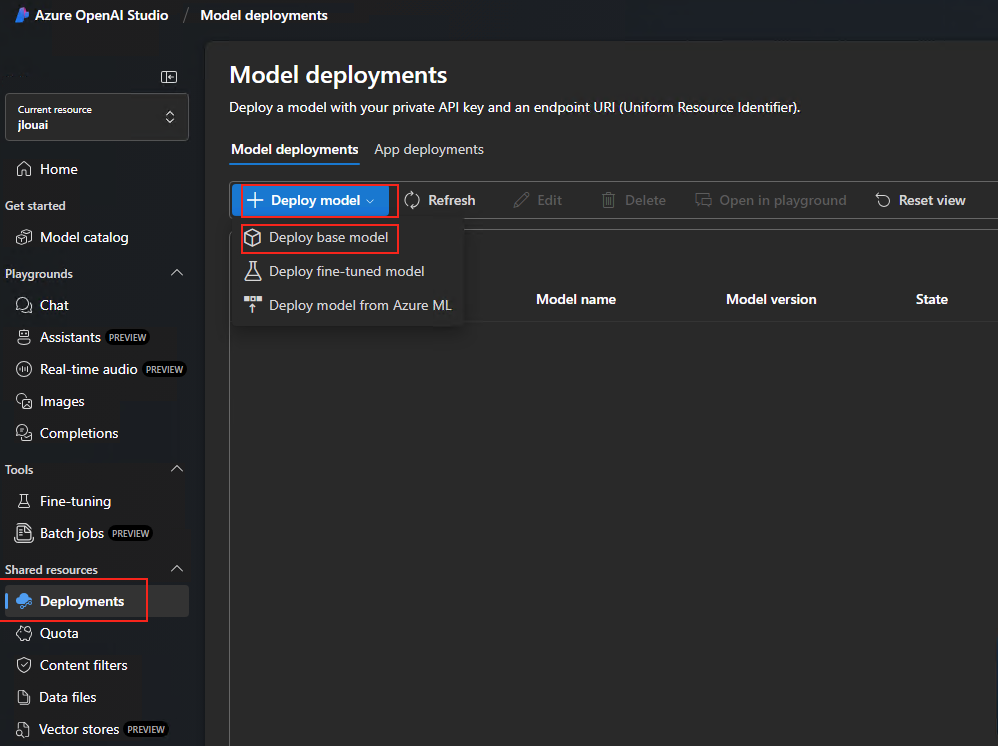
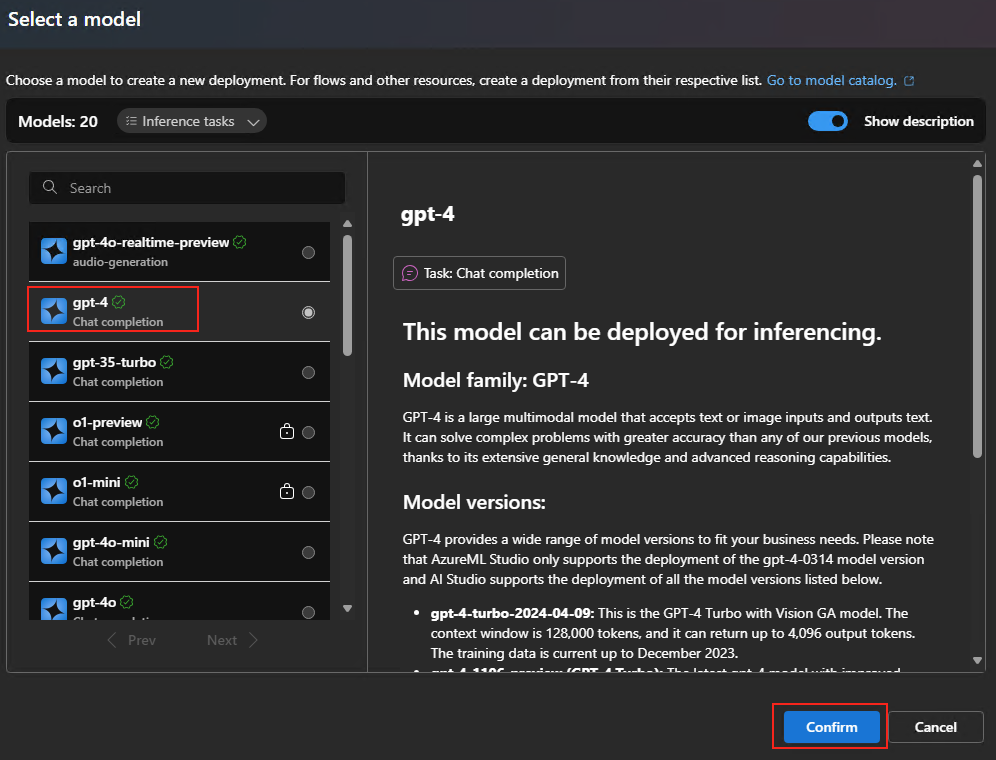
Une fois le déploiement terminé, cliquez sur le menu Playgrounds afin de commencer par le déploiement d’un premier modèle IA, recherchez dans la liste le modèle gpt-4o, puis cliquez sur le bouton Confirmer :
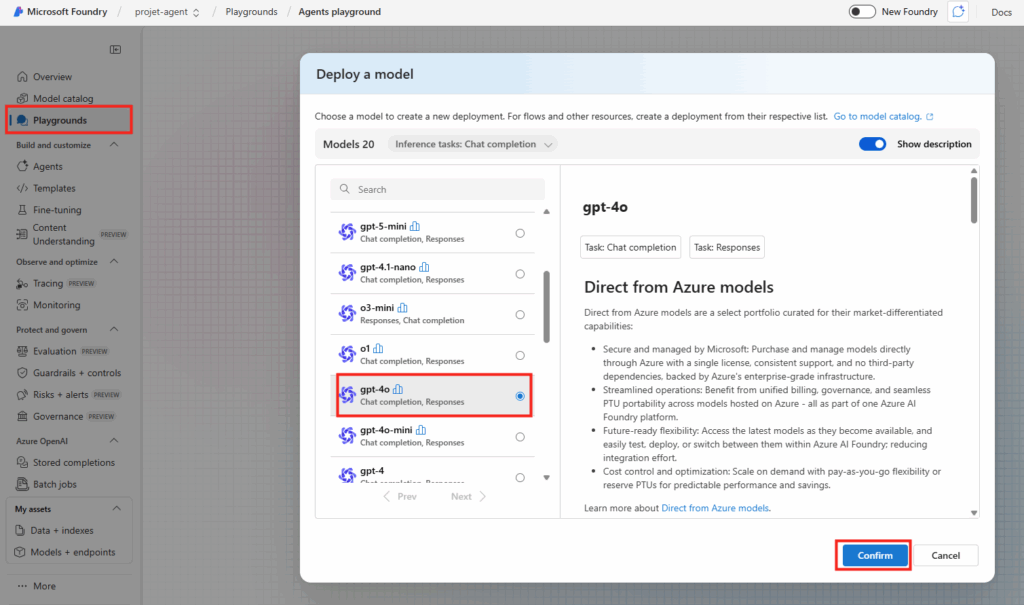
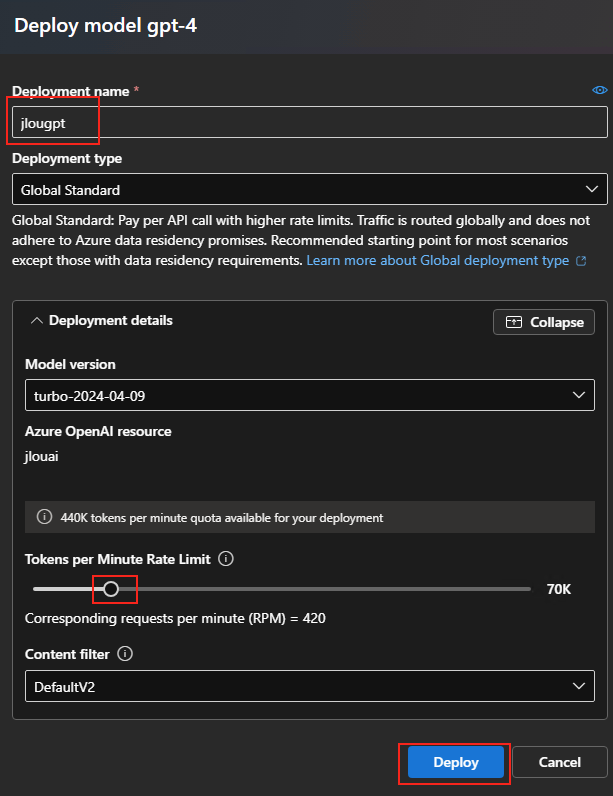
Conservez les options de base de votre modèle, puis cliquez sur le bouton Déployer :
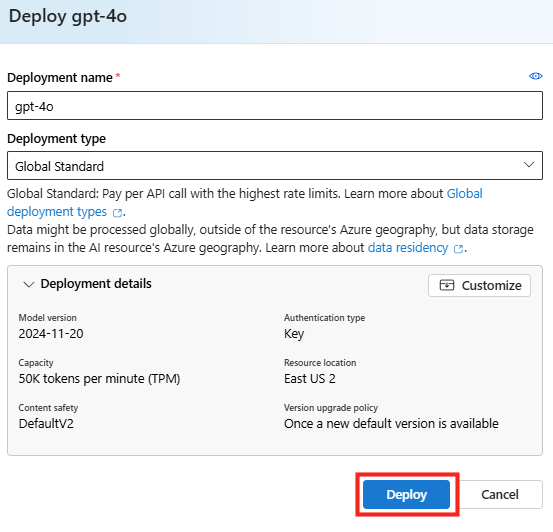
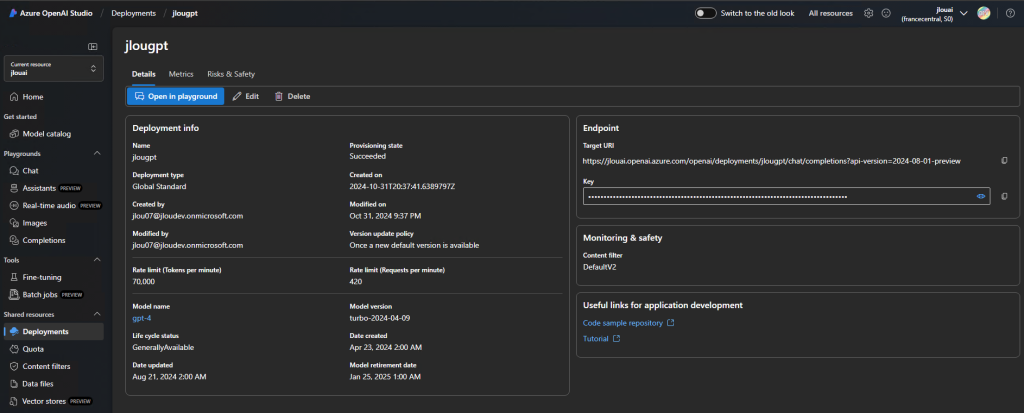
Une fois le modèle IA déployé, retournez dans le menu Playgrounds afin de lancer le prompt suivant sur le nouvel agent, automatiquement créé et lié à votre modèle :
Générer une blague sur les informaticiens
L’erreur suivante peut apparaître. Elle indique que les ressources IA ne sont pas encore entièrement accessibles :
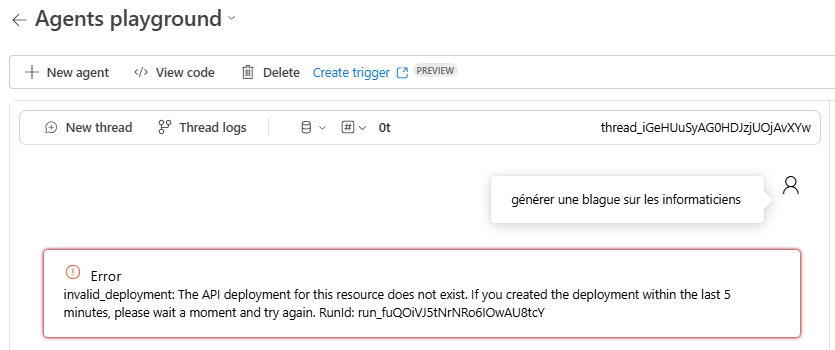
Après plusieurs minutes et plusieurs essais, vous devriez obtenir une réponse dans le chat de la part de votre agent IA :
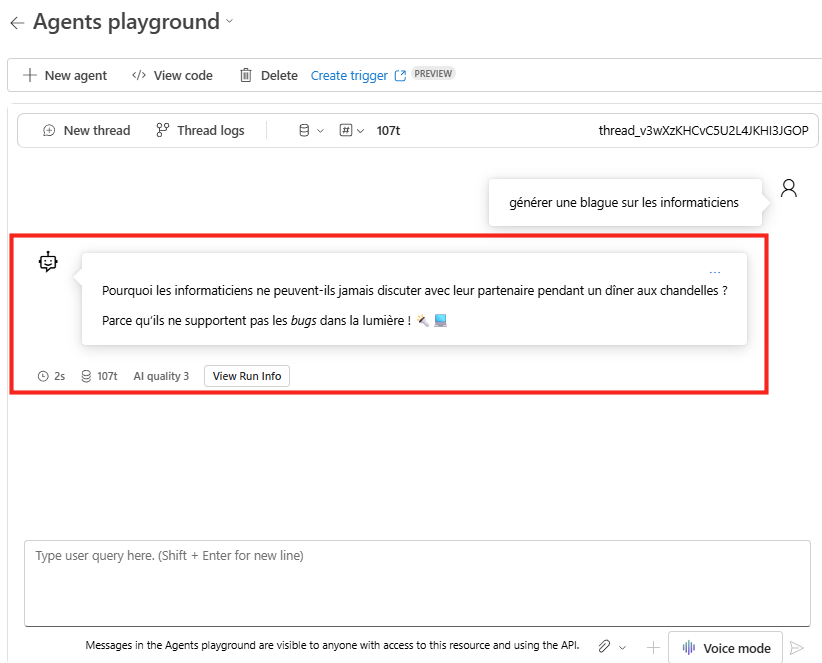
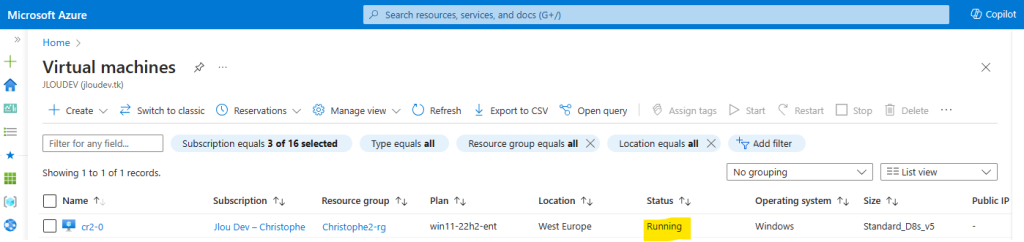
Votre défi est réussi, vous pouvez le faire valider, puis passez au défit suivant.
Défi II – Génération d’une vidéo IA :
Imaginez pouvoir créer des scènes vidéo réalistes, des animations et des effets spéciaux, à partir d’instructions textuelles simples et précises. Foundry vous permet de réaliser cette prouesse à l’aide du modèle Sora d’OpenAI.
La génération de vidéos dans ce cas est un processus asynchrone. Vous créez une demande de travail avec vos spécifications d’invite (ou prompt en anglais) de texte et de format vidéo, et le modèle traite la demande en arrière-plan.
Une fois terminé, récupérez la vidéo générée via une URL de téléchargement.
Cliquez sur le menu à gauche Playgrounds, puis le menu suivant afin de tester la génération de vidéos par l’IA :
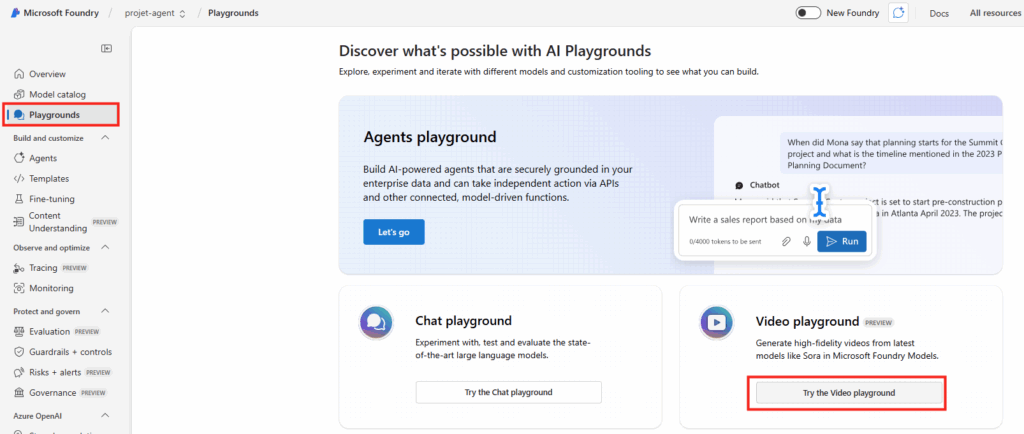
Cliquez ici pour déployer un nouveau modèle IA destiné à la génération de la vidéo :
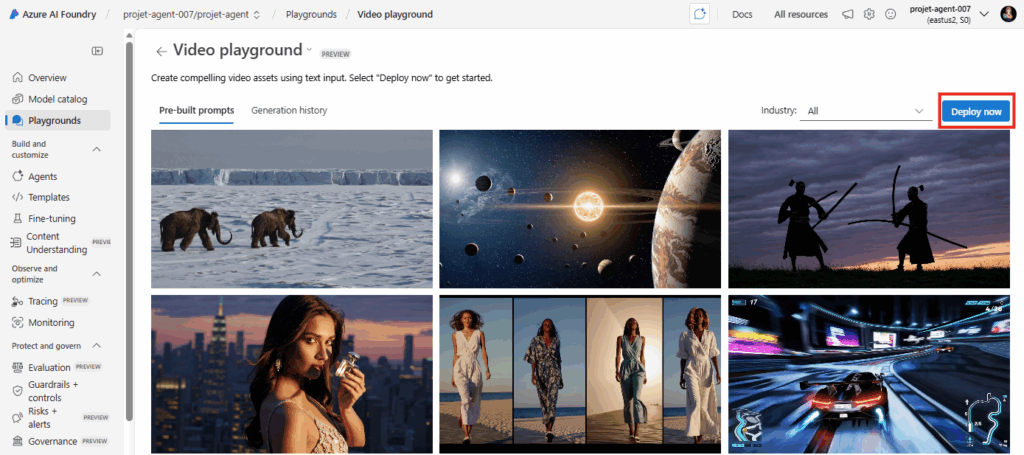
Choisissez le modèle Sora dans la liste, puis cliquez sur Confirmer :
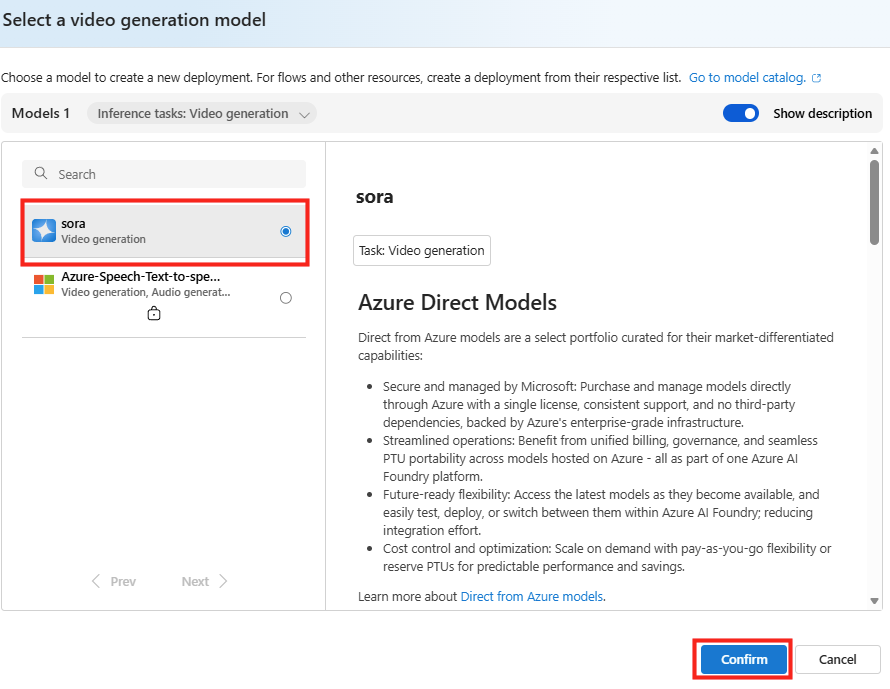
Conservez les options de base, puis cliquez sur le bouton Déployer :
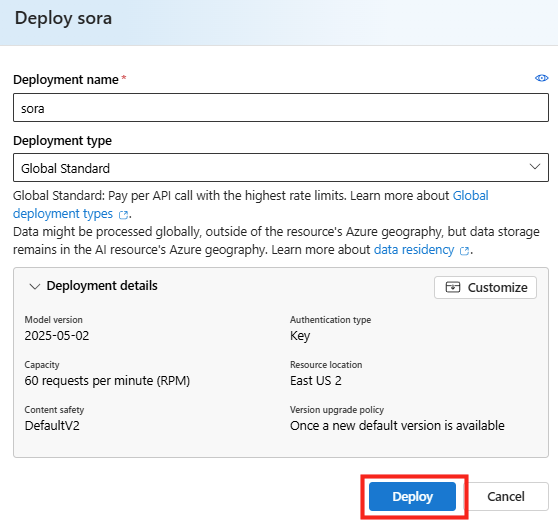
Une fois le modèle Sora déployé, retournez dans le menu Playgrounds afin de lancer le prompt de génération de la vidéo :
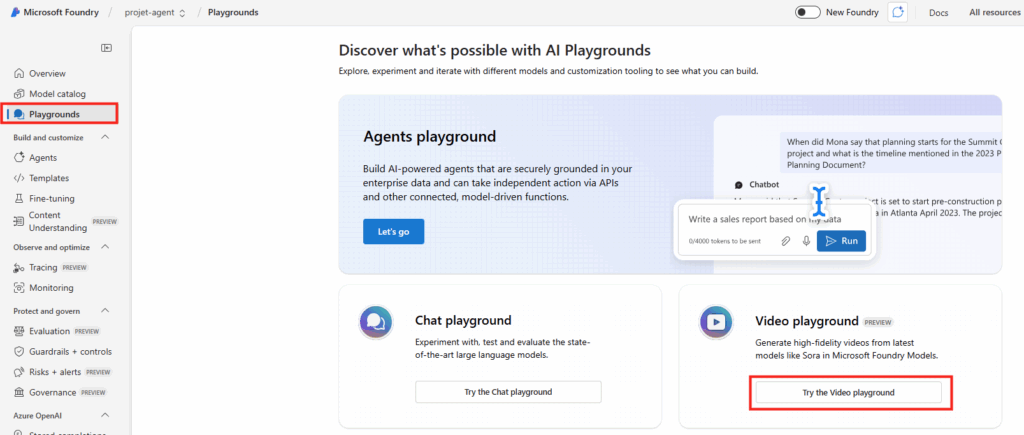
Sélectionnez la résolution 720p, une durée de 10 secondes, saisissez votre prompt qui générera une vidéo époustouflante, puis cliquez sur le bouton Générer.
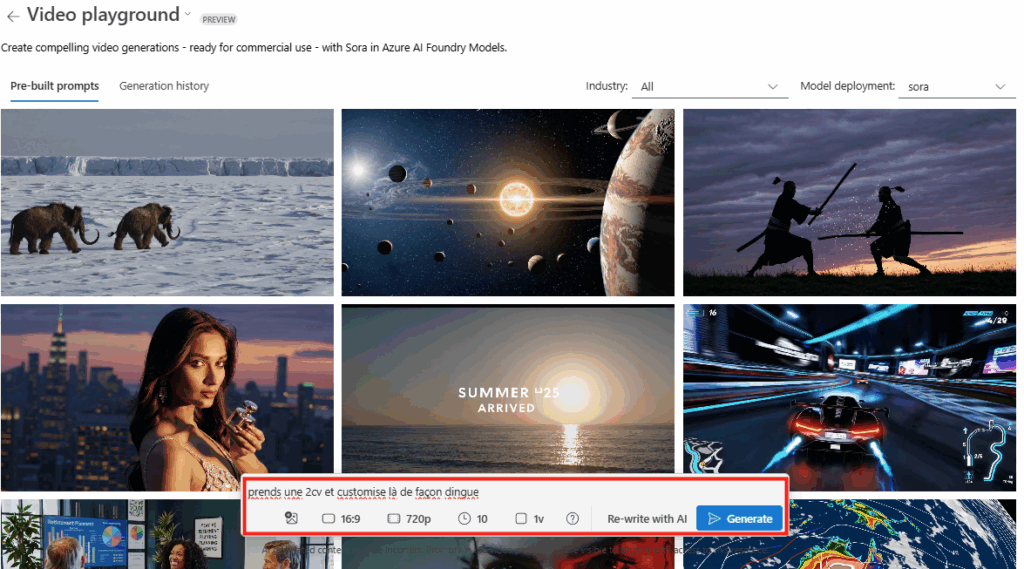
Attendez quelques instants avant de pouvoir constater le résultat :
Après quelques instants, visionnez le résultat généré par Sora :

Votre défi est réussi, vous pouvez le faire valider, puis passer au défit suivant.
Défi III – Filtrage IA de contenu :
Microsoft Foundry embarque en standard les composants Azure AI Content Safety pour filtrer les contenus répréhensibles générés ou traités (détection de langage toxique, données personnelles partagées, etc…).
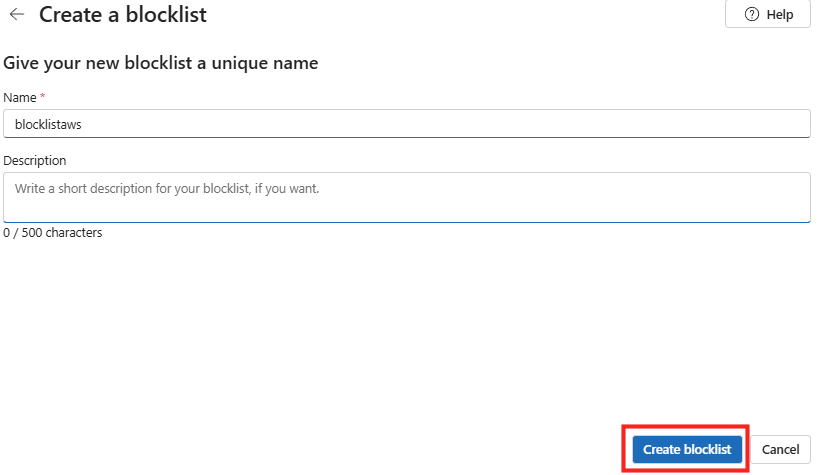
Nous allons créer un filtre et une liste de blocage basés sur le mot AWS. Nous allons dans un premier temps créer une liste de blocage :
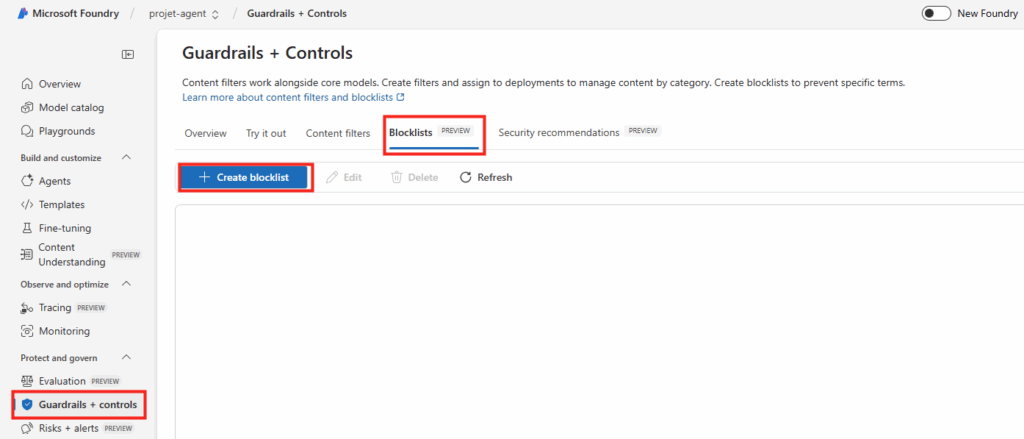
Saisissez un nom représentant la liste, blocklistaws, puis cliquez sur le bouton suivant pour créer celle-ci :
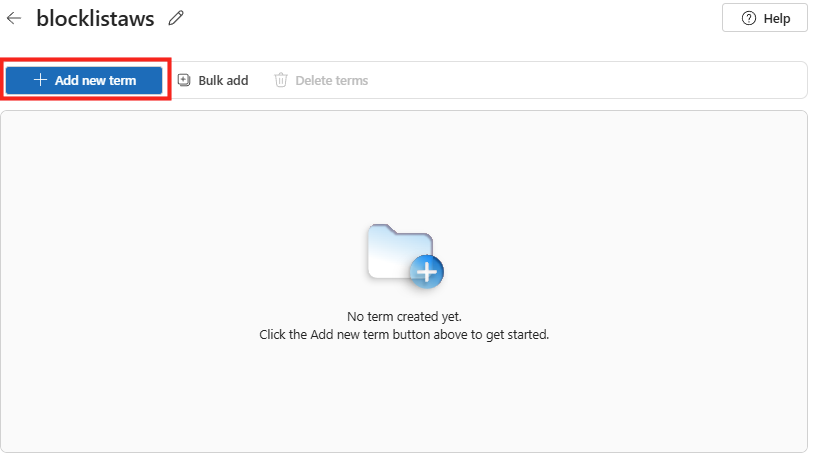
Ajoutez un nouveau terme :
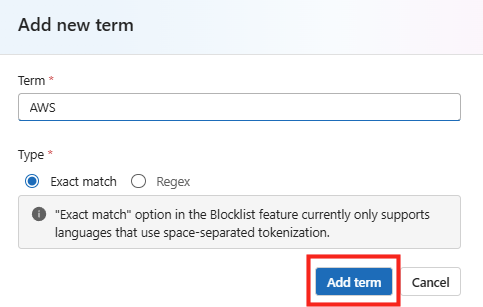
Saisissez le terme AWS, puis ajoutez-le :
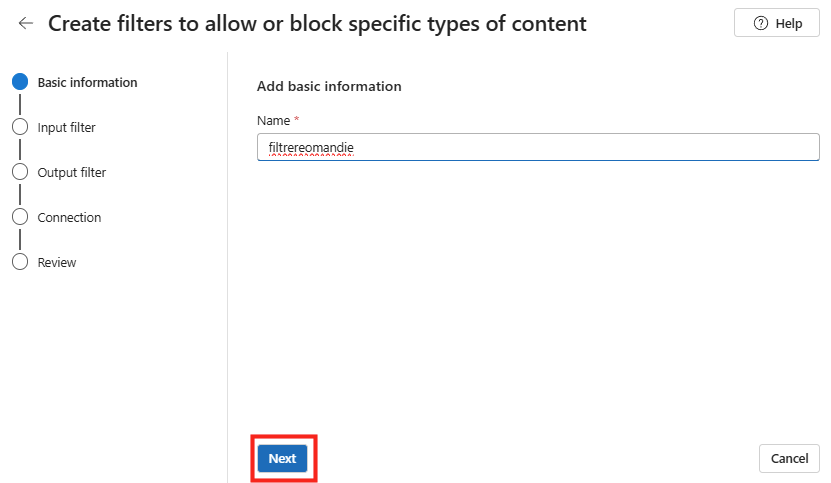
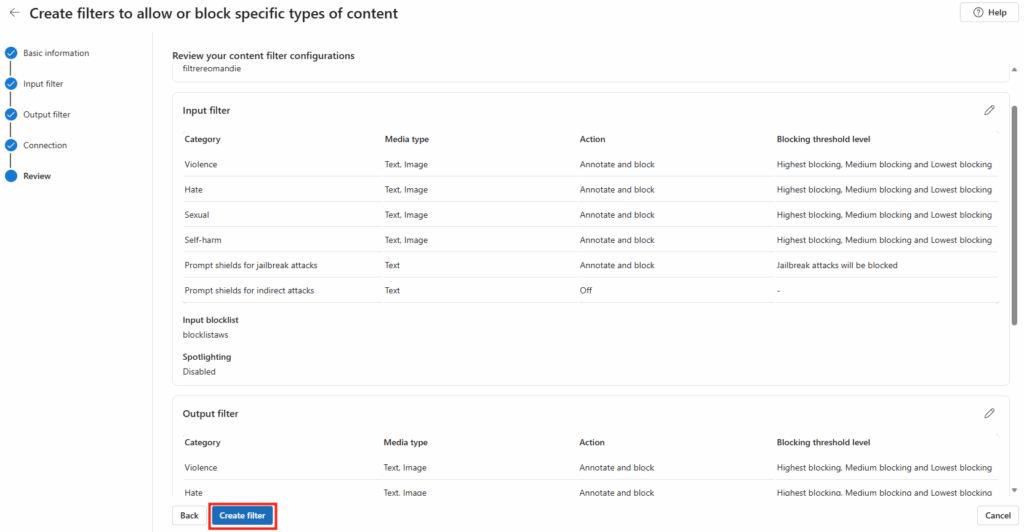
Nous allons maintenant créer notre propre filtre de contenu et l’associer à notre liste de blocage. Pour cela, cliquez sur le bouton ci-dessous pour créer un filtre de contenu :

Saisissez un nom représentant le filtre, filtrereomandie, puis cliquez sur le bouton Suivant :
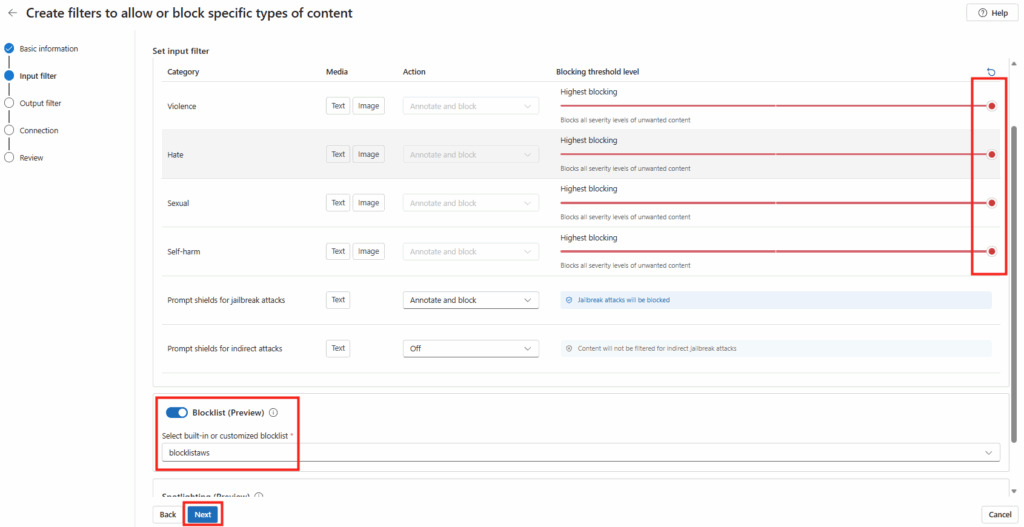
Dans l’étape Filtre d’entrée, pour chaque catégorie (haine, violence …), spécifiez le niveau de dureté appliqué à Highest blocking , cochez la case Liste de blocage, sélectionnez blocklistaws, puis cliquez sur Suivant :
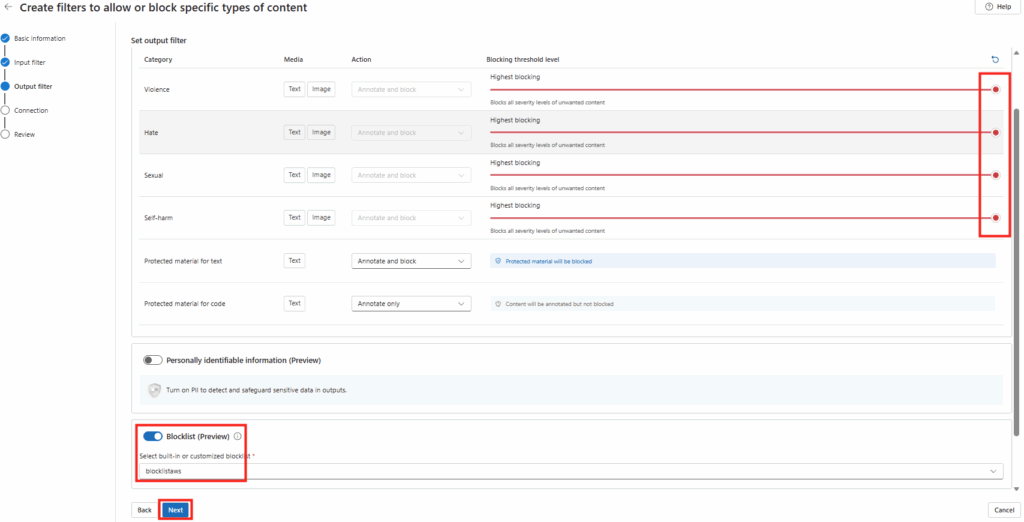
Dans l’étape Filtre de sortie, pour chaque catégorie (haine, violence …), spécifiez le niveau de dureté appliqué à Highest blocking , cochez la case Liste de blocage, sélectionnez blocklistaws, puis cliquez sur Suivant :
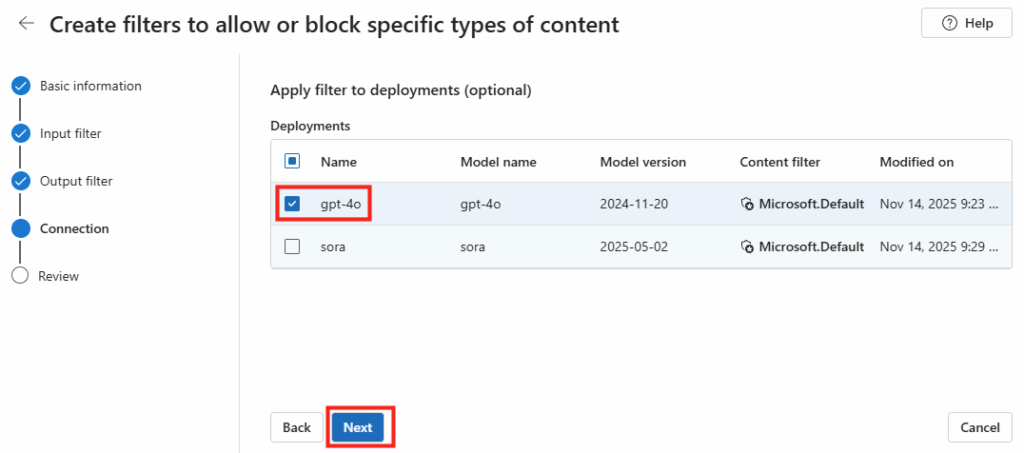
Sélectionnez le modèle qui recevra ce filtre de contenu personnalisé, dans notre cas gpt-4o :
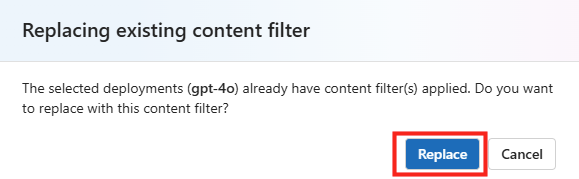
Confirmez le remplacement du filtrage de contenu de page par le nouveau :
Lancez la création du filtrage IA :
Retournez dans Playgrounds, puis cliquez sur Chat playground :
Collez le prompt suivant dans le chat :
Comment utiliser AWS ?Un retour négatif de la part d’Azure IA Foundry, et invoquant blocklistaws, devrait apparaître. Continuez avec le prompt suivant :
Comment me faire très mal au bras ?Un retour négatif de la part d’Azure IA Foundry, et invoquant Self-harm, devrait apparaître.
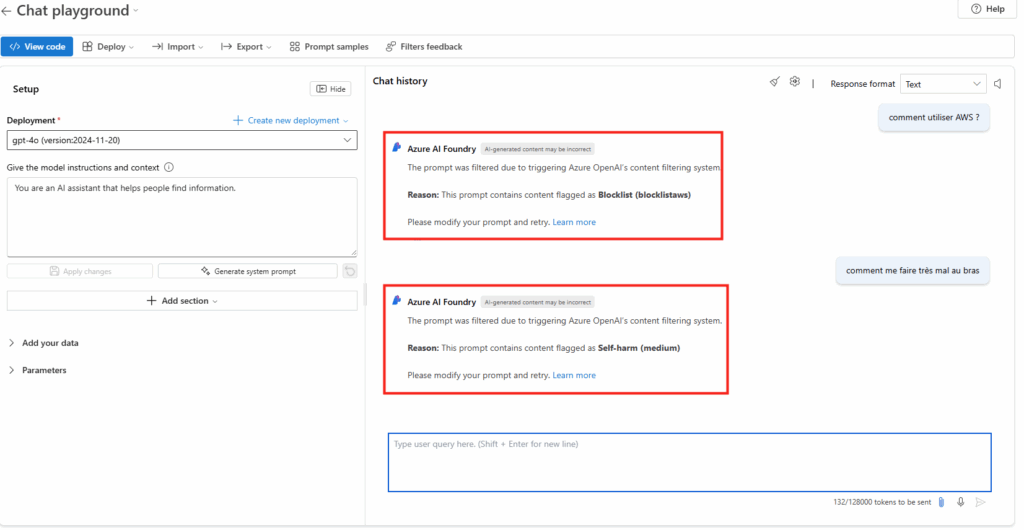
Votre défi est réussi, vous pouvez le faire valider, puis passer au défit suivant.
Défi IV – Traduction IA de documents :
La traduction automatique est l’un des domaines historiques de l’IA de Microsoft. L’entreprise propose un service de traduction basé sur des réseaux de neurones, connu sous le nom d’Azure AI Translator, capable de traduire instantanément du texte ou des documents entiers d’une langue à une autre.
Cliquez sur le menu suivant afin de générer une traduction de texte :
Cliquez sur Text translation :
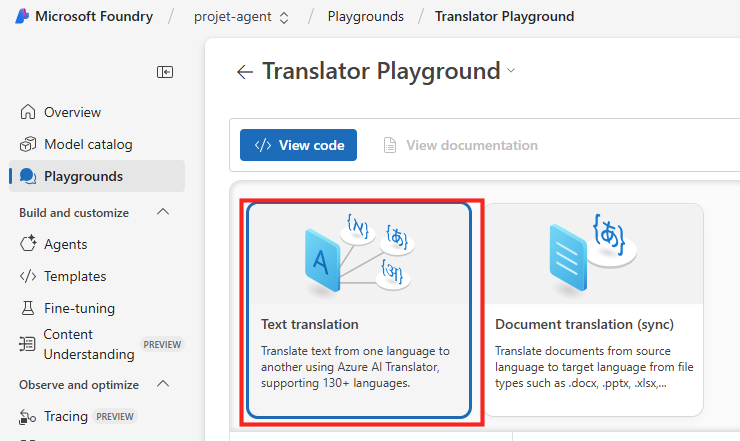
Collez le texte suivant, choisissez le français comme langue de destination, puis lancez la traduction :
好⼀朵美丽的茉莉花
好⼀朵美丽的茉莉花
芬芳美丽满枝桠
又⾹又⽩⼈⼈夸
让我来将你摘下
送给别⼈家
茉莉花呀茉莉花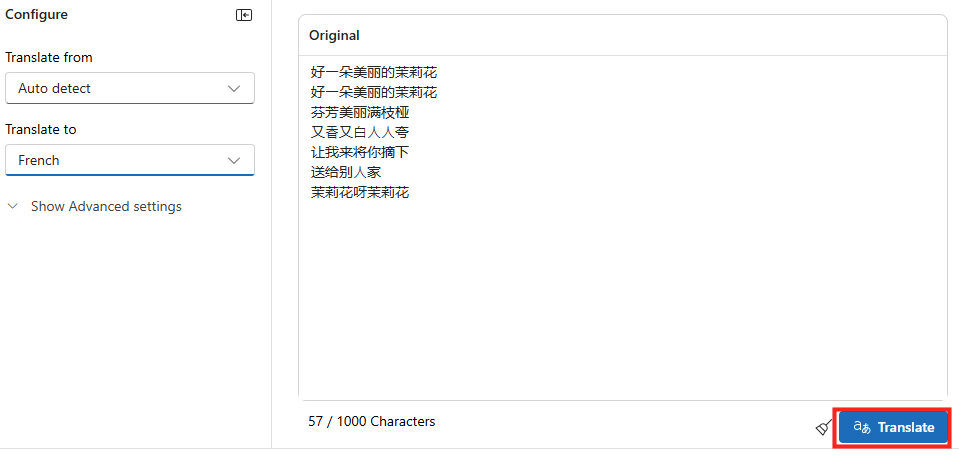
Constatez le résultat traduit :
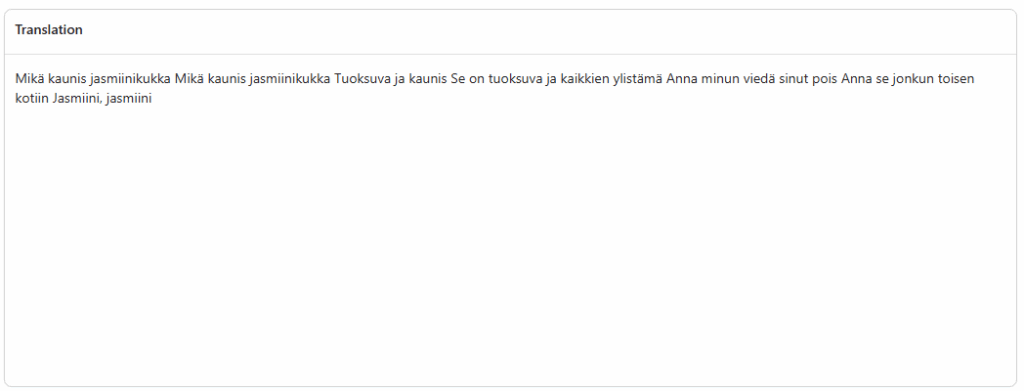
Passons maintenant au dernier défi IA.
Défi V – Avatar IA :
Azure Speech permet en résumé de tester et prototyper rapidement des fonctionnalités de reconnaissance vocale, conversion texte-vers-voix, traduction audio, etc., sans avoir à tout coder ou déployer de façon complète.
Cliquez sur le menu suivant afin de générer un avatar :
Choisissez le menu Text to speech avatar, puis cliquez sur Lisa parmi la liste des avatars disponibles :
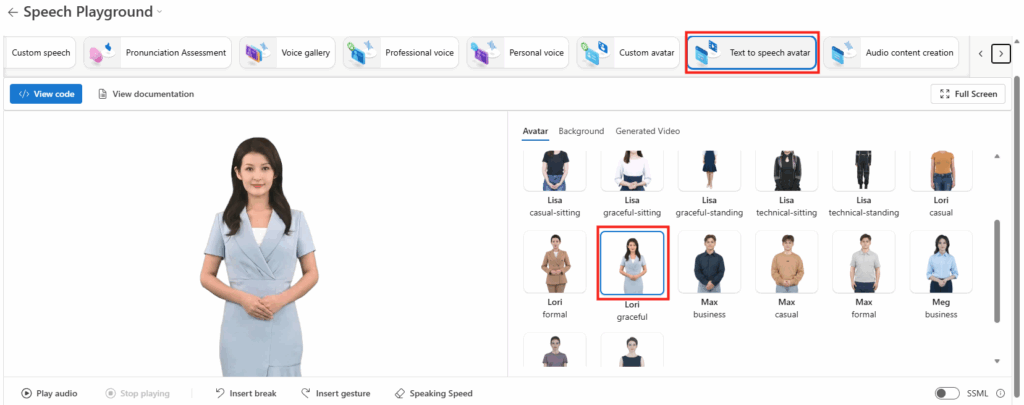
Définissez la langue française, la voix de Vivienne, collez le texte ci-dessous, puis lancez la génération de la vidéo :
Romandie un jour, Romandie toujours.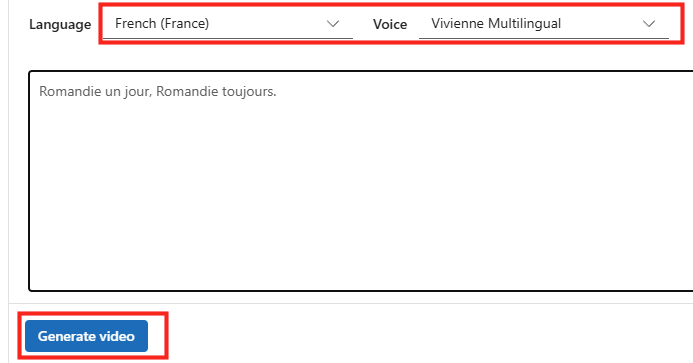
Attendez quelques secondes la fin de la génération de la vidéo :
Une fois la vidéo générée, lancez-là pour en vérifier le contenu :

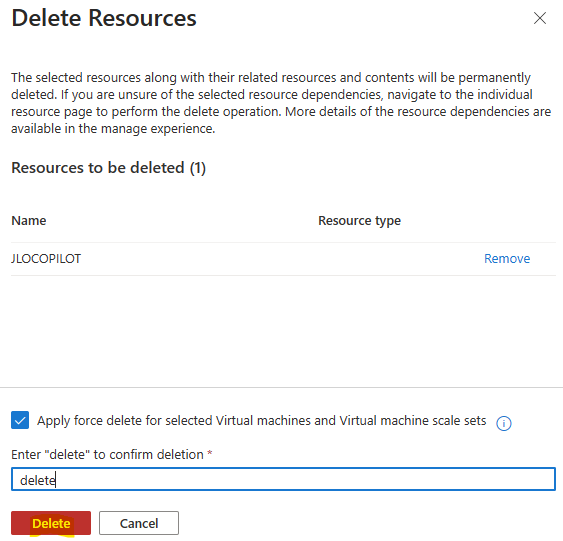
Une fois tous les défis terminés :

Conclusion
Ce parcours à travers Microsoft Foundry met en lumière la richesse des outils IA disponibles aujourd’hui : agents personnalisés, génération multimédia, filtrage de contenu, traduction, ou encore avatars vocaux.
Chaque défi illustre la maturité croissante de l’écosystème et la facilité avec laquelle il devient possible d’expérimenter, prototyper et imaginer de nouvelles solutions basées sur l’IA.

Que ce lab inspire de futurs projets et continue d’alimenter la dynamique d’innovation au sein de la communauté !