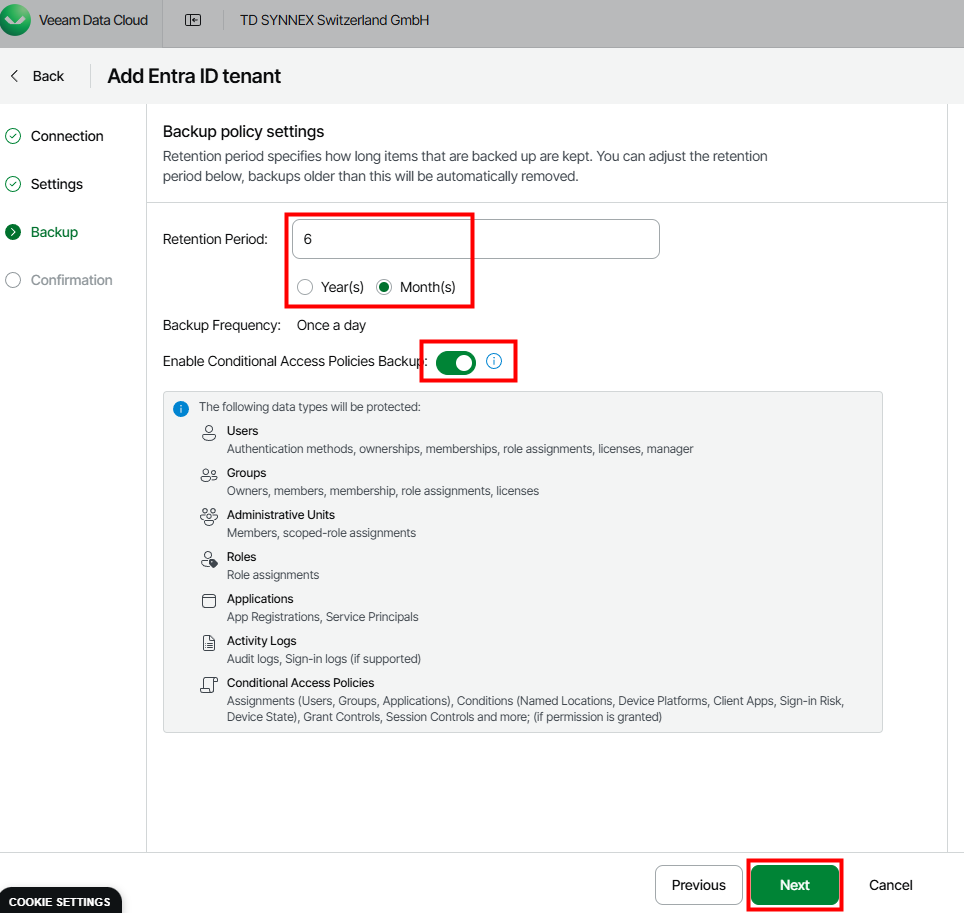
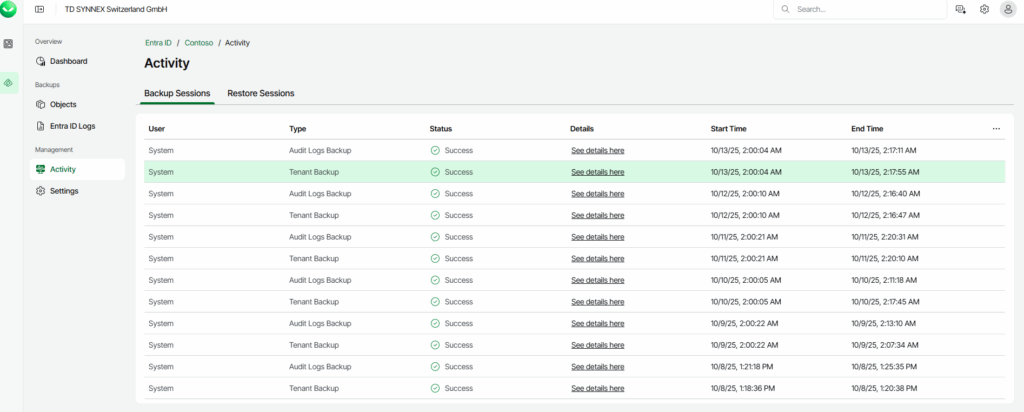
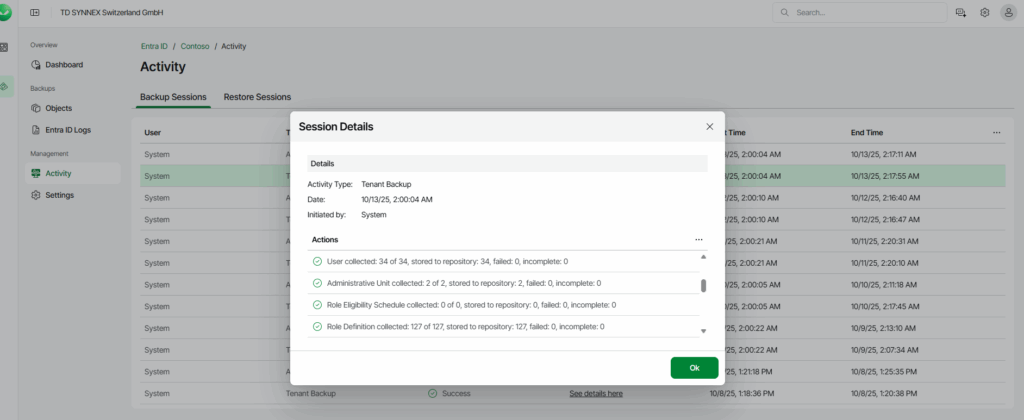
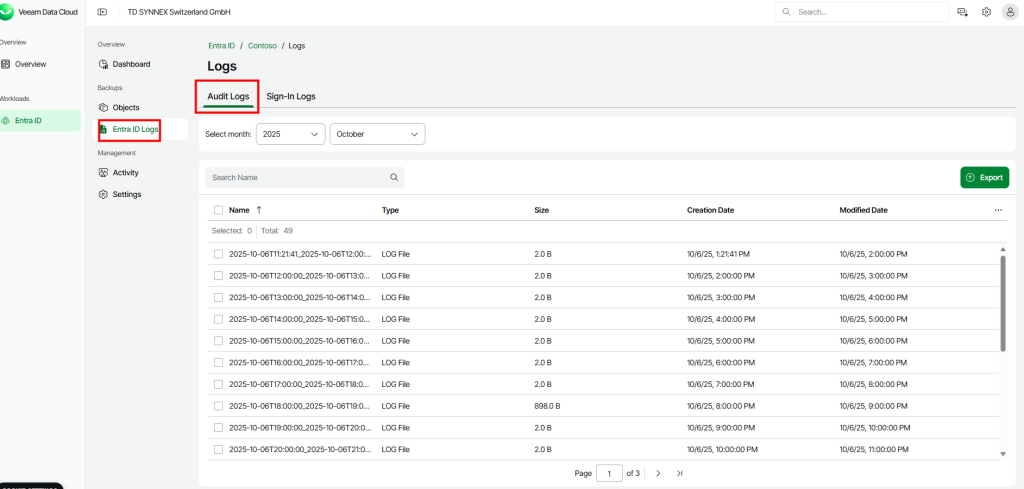
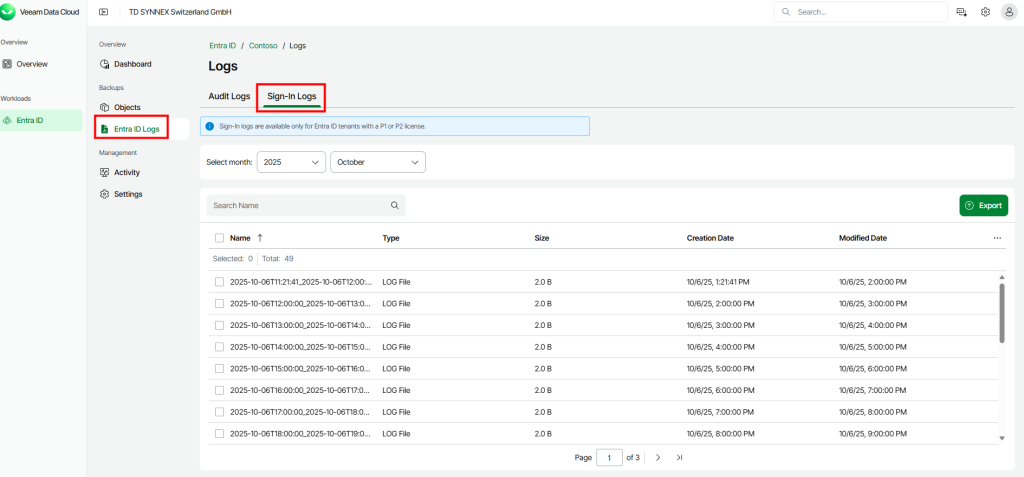
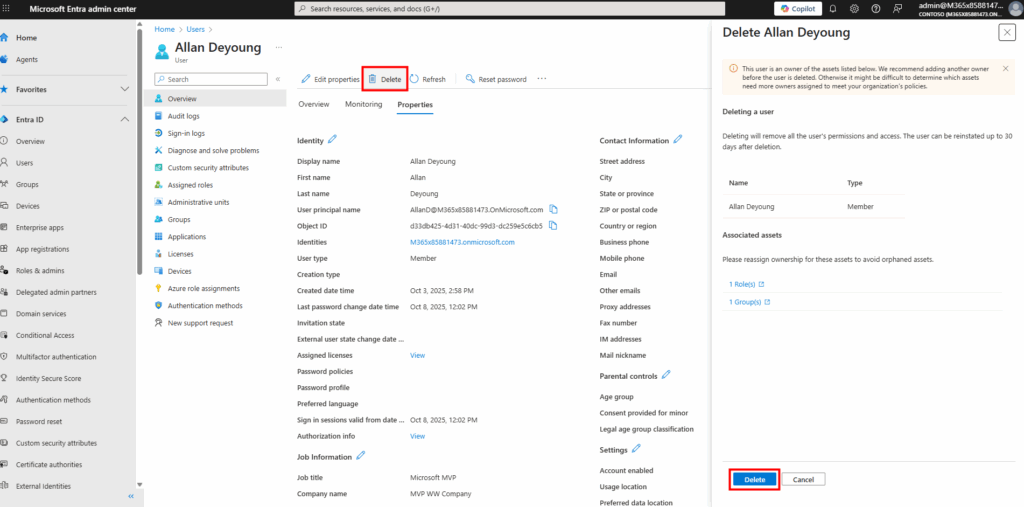
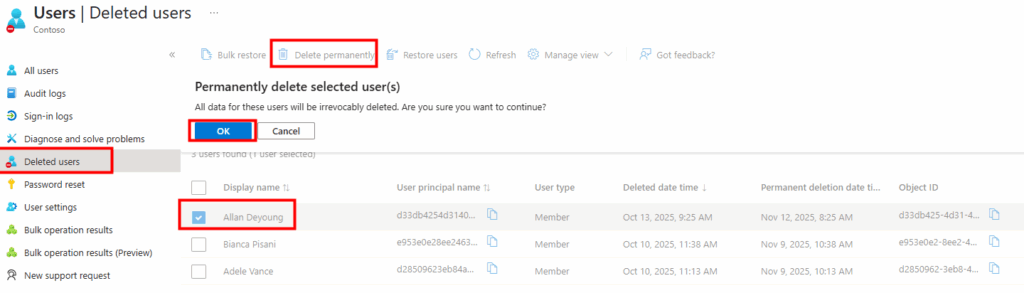
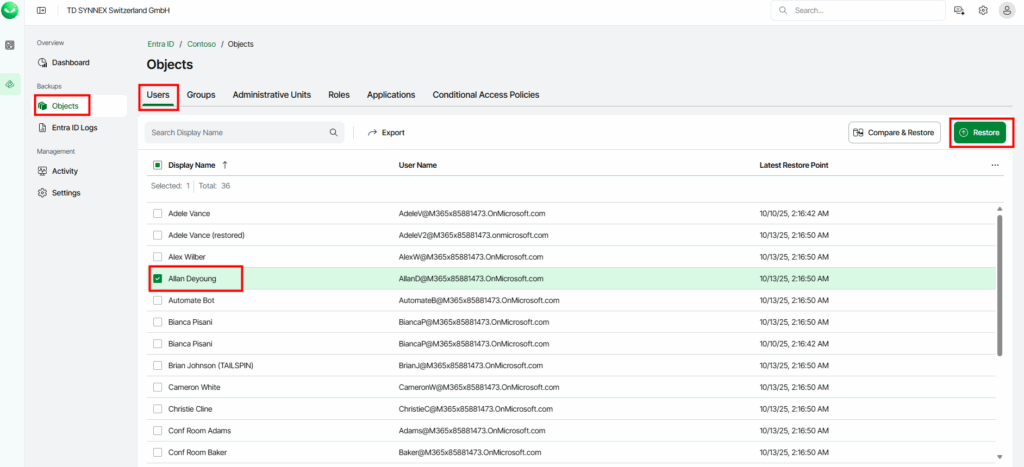
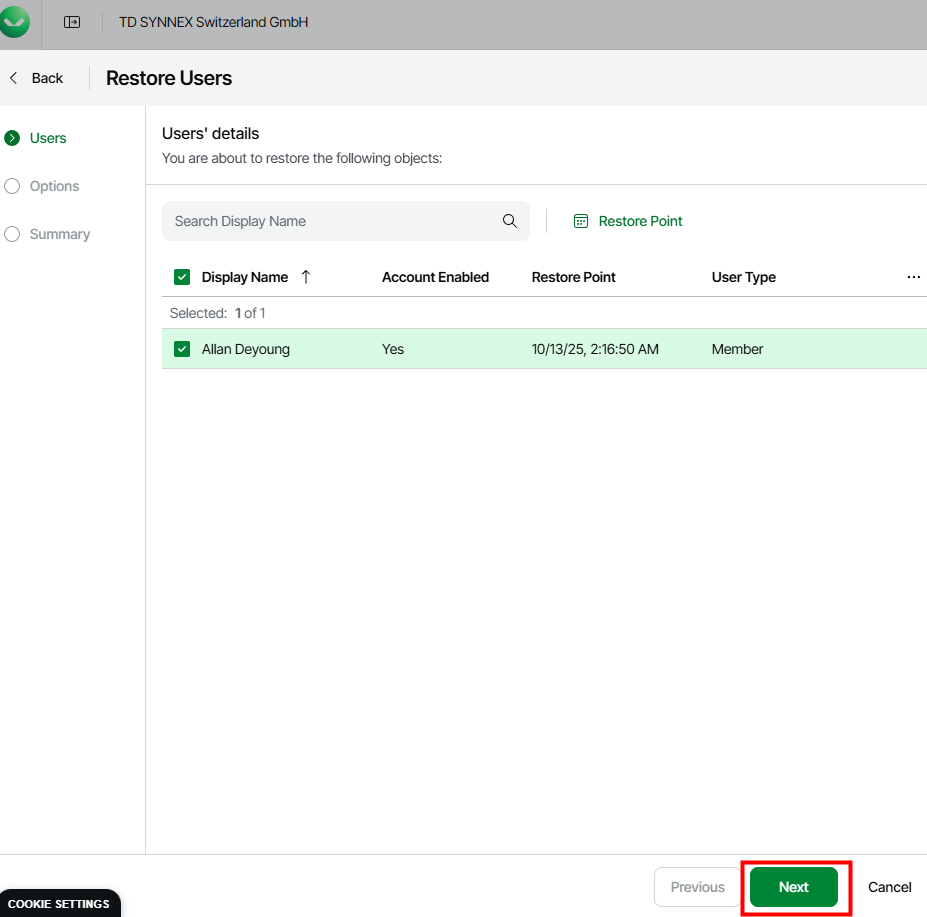
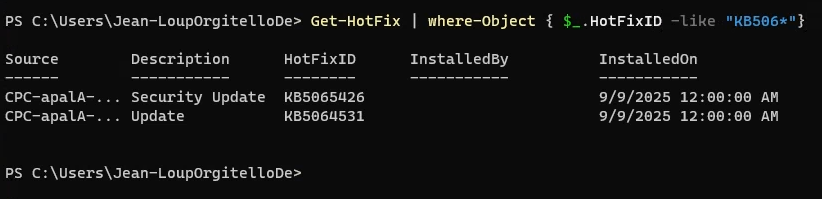
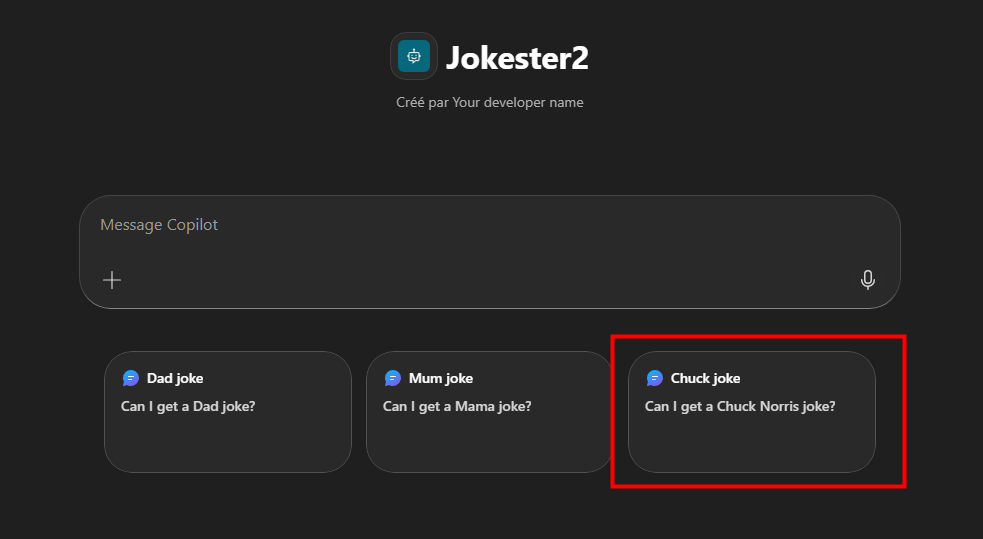
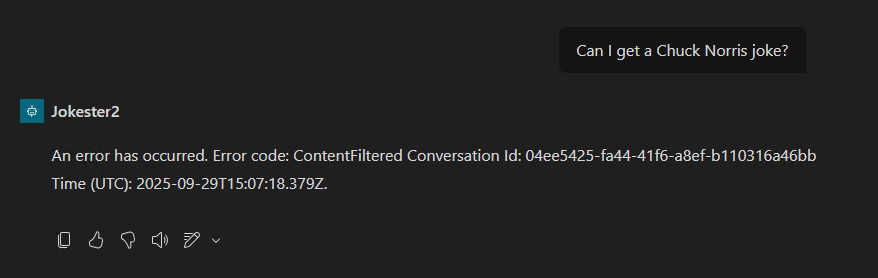
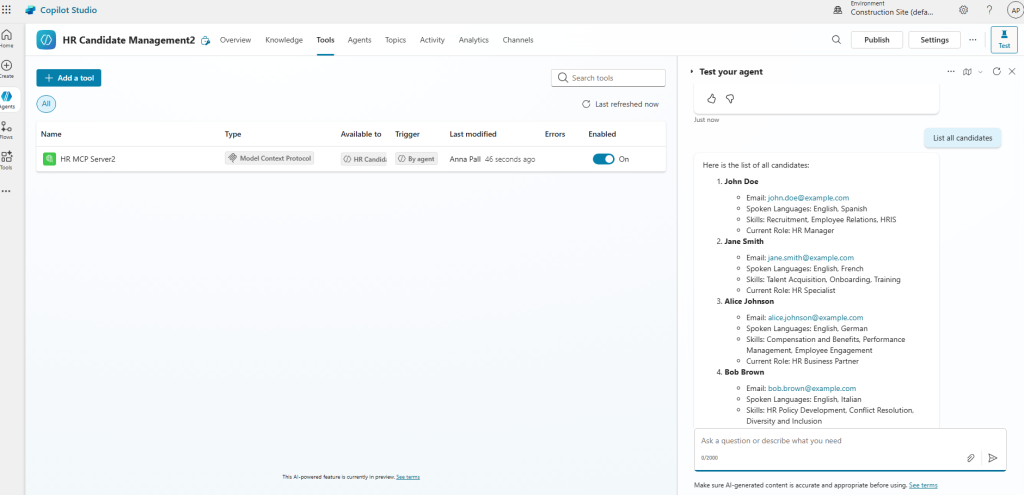
Pourquoi, en 2025, mettre à jour son AVD ronronnant encore et toujours sous Windows 10 22H2 ? Windows 10 ou 11, comme leurs prédécesseurs, reçoivent régulièrement plusieurs types de mises à jour (sécurité, correctifs de bugs, feature update, pilotes, …) . Bien que les Extended Security Updates soient gratuites pour les environnements AVD ou Windows 365 pendant encore une année, il ne faudrait pas trop traîner non plus. Mais … attention à BitLocker !

Voici d’ailleurs le lien vers la FAQ Microosft des Extended Security Updates (ESU) pour Windows 10.
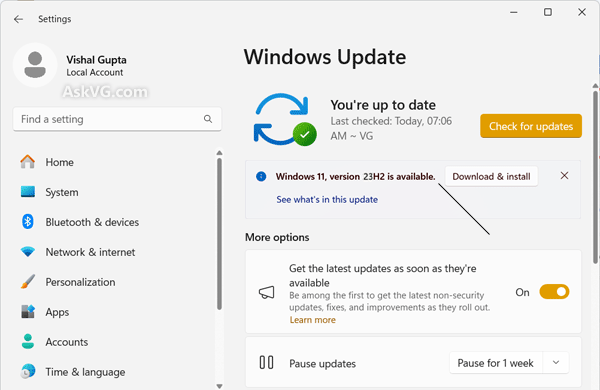
Sous Windows 11, la fréquence des Feature Updates a changé par rapport à Windows 10. Depuis 2022, Microsoft publie une seule Feature Update par an, généralement au second semestre (H2) :
- 21H2 → sortie en octobre 2021
- 22H2 → sortie en septembre 2022
- 23H2 → sortie en octobre 2023
- 24H2 → sortie en septembre/octobre 2024
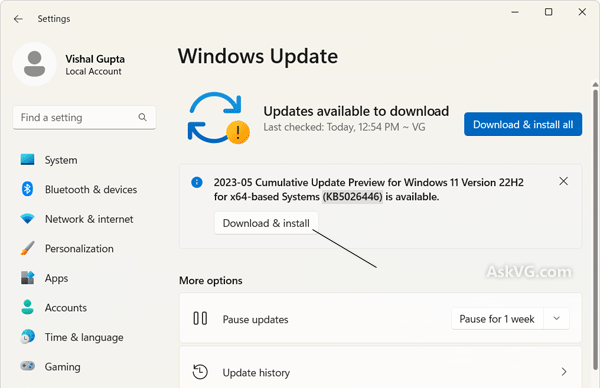
Mais, Microsoft ne maintient pas indéfiniment ses produits. La transition vers des versions plus récentes est donc inévitable :
| Système | Édition | Version | Date de fin de support / fin de maintenance |
|---|---|---|---|
| Windows 10 | Windows 10 Enterprise Windows 10 Enterprise multi-session Windows 10 Education, Windows 10 IoT Enterprise | 20H2 | 9 Mai 2023 |
| Windows 10 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 21H2 | 13 juin 2024 |
| Windows 10 | Enterprise Education Home Pro Enterprise 2015 LTSB IoT Enterprise LTSB 2015 | 22H2 | 14 octobre 2025 |
| Windows 10 | Enterprise and IoT Enterprise LTSB | ex. LTSC 2021 | 12 janvier 2027 |
| Windows 11 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 21H2 | 10 octobre 2023 |
| Windows 11 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 22H2 | 8 octobre 2024 |
| Windows 11 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 23H2 | 11 novembre 2025 |
| Windows 11 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 24H2 | 13 Octobre 2026 |
| Windows 11 | Windows 10 Home Windows 10 Pro Windows 10 Pro Edu Windows 10 Pro workstation | 25H2 | 12 Octobre 2027 |
Les versions Entreprise de Windows 11 ont toute une année de service en plus que leurs homologues respectives en version pro.
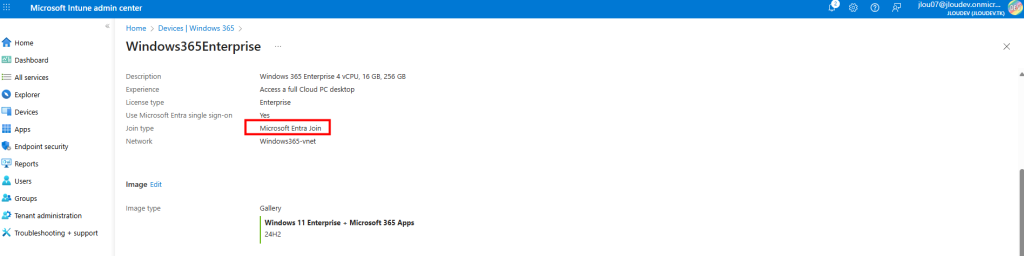
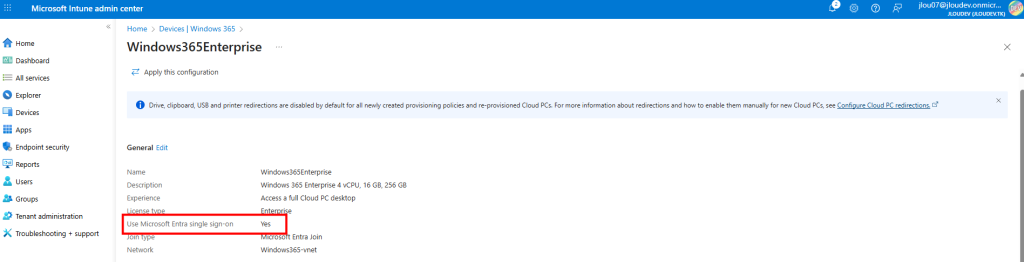
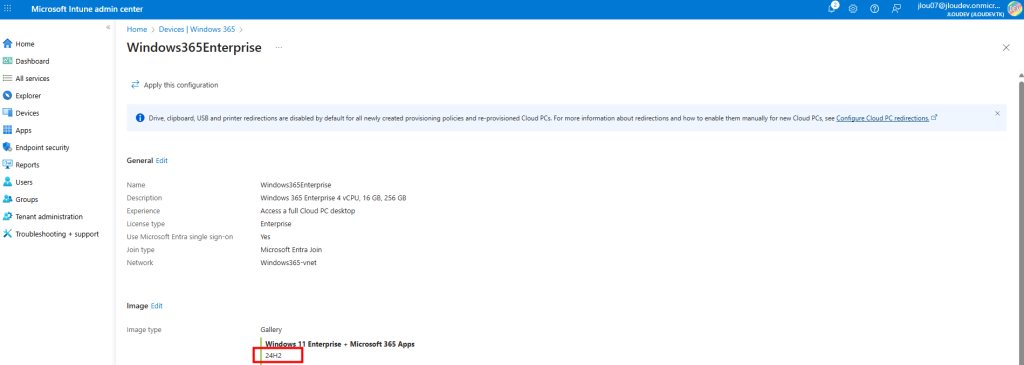
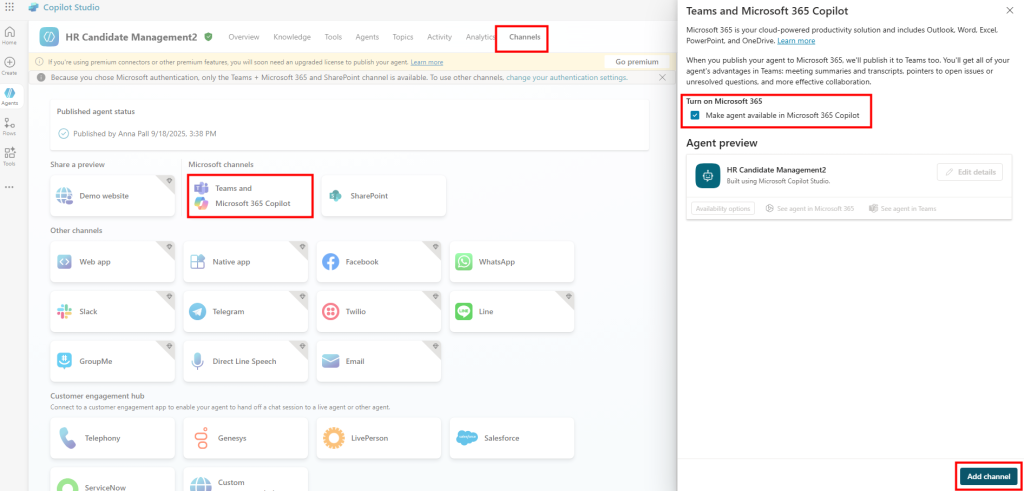
Comment les versions de Windows 10/11 sont disponibles sous Azure ?
Lors de la création d’une machine virtuelle sous Azure, Microsoft propose toujours plusieurs versions de Windows 10 ou 11, accessibles via le Marketplace Azure :
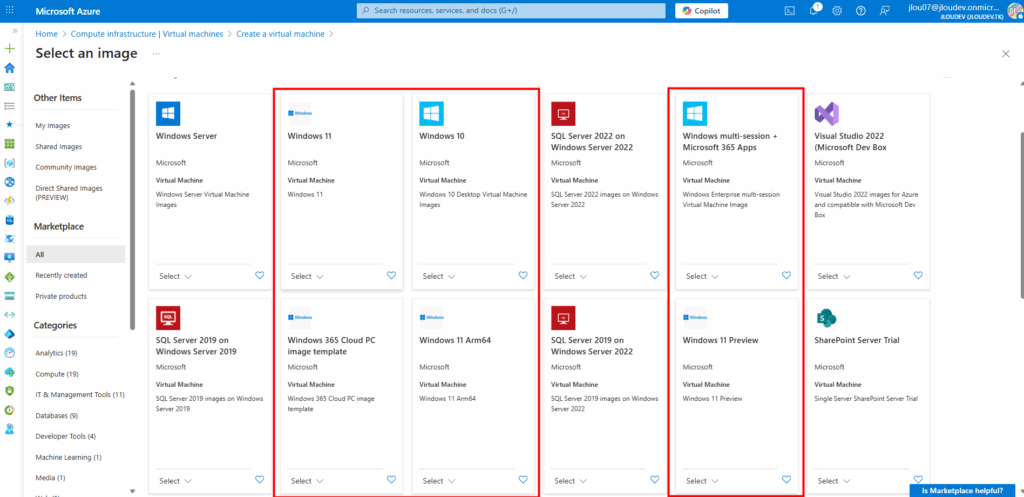
Un menu déroulant propose différentes versions et générations (Il est important de vérifier que la VM sélectionnée réponde aux conditions (hardware, Gen2, virt-TPM, Secure Boot…) car toutes les séries de VMs ne sont pas compatibles) :
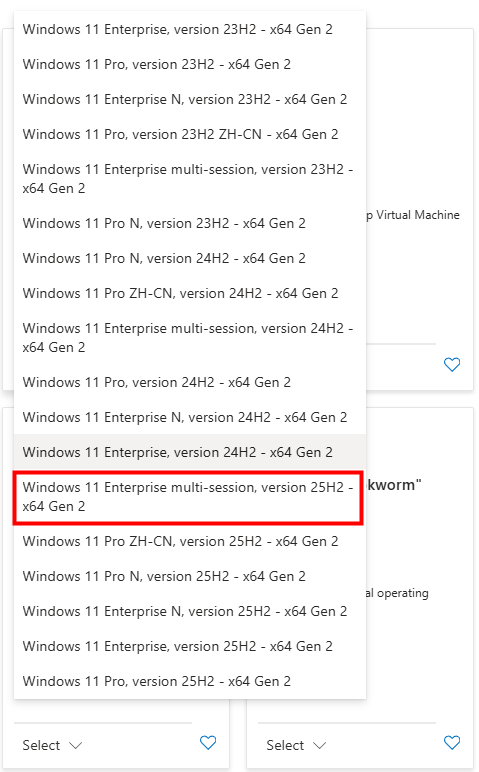
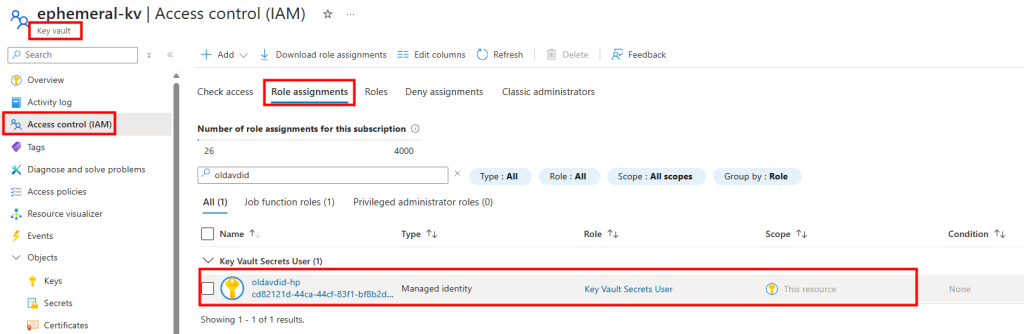
On peut noter qu’il y a donc distinction entre les éditions clients (Pro, Enterprise). De plus, certaines images sont destinées à des usages spécifiques comme Windows 11 Enterprise multi‑session.
Qu’est-ce qu’Azure Update Manager, et peut-il m’aider ?
Azure Update Manager (AUM) est un service de Microsoft disponible sur Microsoft Azure, conçu pour gérer et superviser les mises à jour logicielles (patches) des machines, tant sous Windows que sous Linux, dans des environnements Azure, sur-premises ou multicloud via Azure Arc.
Grâce à Azure Update Manager, vous allez pouvoir :
- Superviser la conformité des mises à jour pour les machines Windows et Linux, qu’elles soient dans Azure ou connectées via Azure Arc (on-premises ou multicloud).
- Planifier des fenêtres de maintenance pour appliquer les patches.
- Déployer un patch à la demande, ou d’un déploiement automatique selon une plage horaire définie.
- Mettre en œuvre des mises à jour critiques et les suivre via le monitoring.
- Gérer les droits via la granularité d’accès (RBAC) et d’autres fonctions de gouvernance Azure.
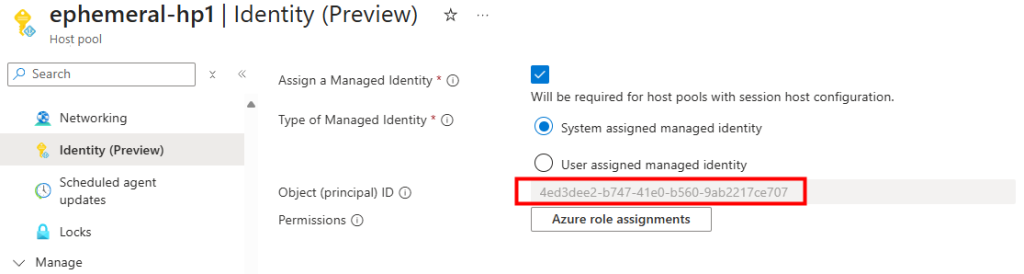
En ce qui concerne une machine virtuelle Azure avec un OS sous Windows 11, Microsoft est très clair sur ce point :
Automation Update Management ne fourni pas de prise en charge pour l’application de patchs à Windows 10 et 11. Il en va de même pour le Gestionnaire de mises à jour Azure. Nous vous recommandons d’utiliser Microsoft Intune comme solution pour maintenir les appareils Windows 10 et 11 à jour.
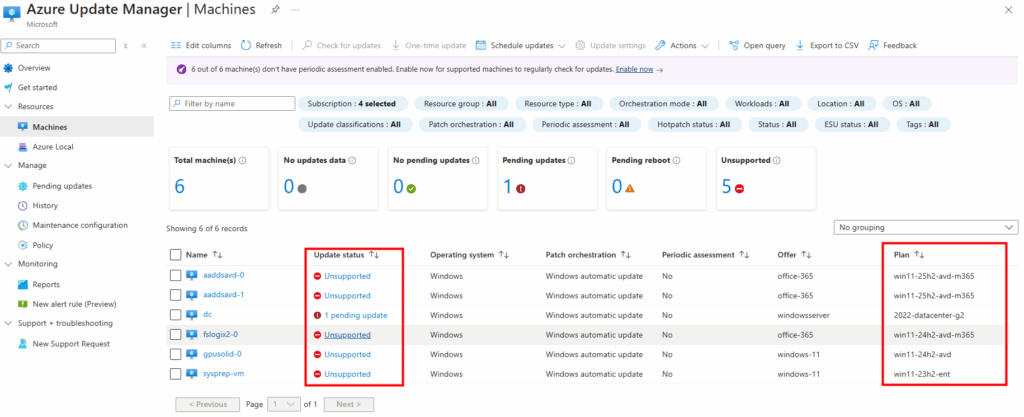
Peut-on faire une upgrade d’une VM Azure Windows 10 existante ?
Oui, mais avant d’aller plus loin, sachez que Microsoft recommande déjà de ne pas le faire 🤣
Le processus de cet article entraîne une déconnexion entre le plan de données et le plan de contrôle de la machine virtuelle.
Les fonctionnalités Azure telles que la mise à jour corrective automatique de l’invité, les mises à niveau automatiques de l’image du système d’exploitation, la mise à jour corrective à chaud et le Gestionnaire de mise à jour Azure ne seront pas disponibles.
Pour utiliser ces fonctionnalités, créez une machine virtuelle à l’aide de votre système d’exploitation préféré au lieu d’effectuer une mise à niveau sur place.
Microsoft ne recommande donc pas de faire une mise à niveau sur place pour une machine virtuelle Windows 10 ou 11 dans Azure pour des raisons techniques et structurelles.
Une mise à niveau sur place modifie profondément le système d’exploitation à l’intérieur de la VM sans qu’Azure en soit informé.
Résultat : La machine continue d’exister dans Azure avec les anciennes métadonnées d’image (Publisher, Offer, Plan, version, etc.), ce qui empêche Azure de reconnaître la nouvelle version de l’OS.
Et cela pose un ensemble de problèmes :
- de gestion du cycle de vie
- de sécurité et conformité (Azure Security Center/Azure Policy peuvent se tromper sur la version de l’OS)
- du support Microsoft, car ce dernier s’appuie sur l’image déclarée dans Azure
Mais Microsoft propose pourtant la mise à niveau pour Windows Server ?
Il existe bien une procédure d’upgrade sur place pour Windows Server pour une VM Azure :
Passer d’une version antérieure de Windows Server à une version plus récente tout en conservant les rôles, données et applications.
Que recommande alors Microsoft pour gérer une MAJ sur Windows 10 ?
Microsoft recommande donc de créer une nouvelle VM avec le système d’exploitation cible, car les mises à jour directes peuvent empêcher certaines fonctionnalités Azure de fonctionner correctement.
Donc, la meilleure pratique consiste à :
- Déployer une nouvelle VM avec l’image du nouvel OS supporté.
- Migrer les applications, données, configurations vers cette nouvelle VM.
- Valider le bon fonctionnement, puis retirer l’ancienne VM.
Plusieurs vidéos tutorielles existent sur Internet pour proposer des mises à jour depuis Windows 10 :
Et quid du passage de la 22H2 à la 24H2 ?
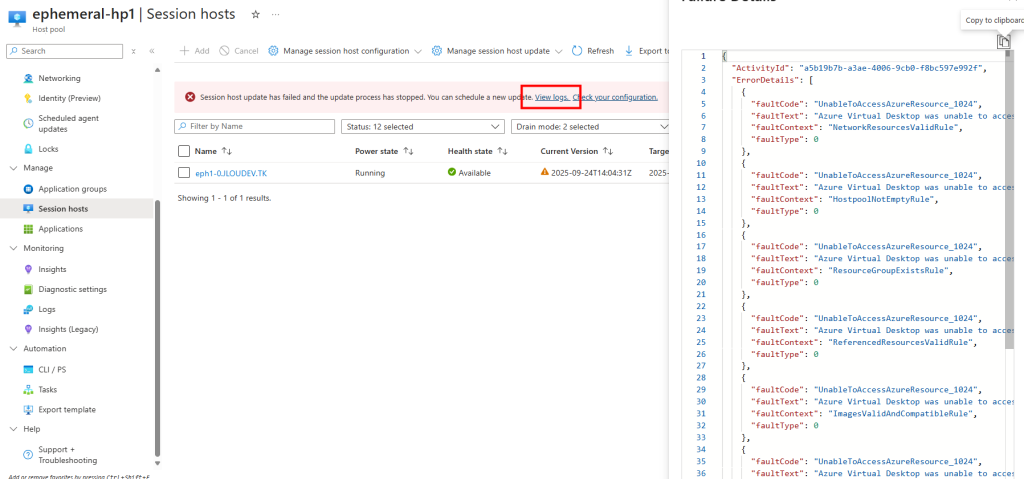
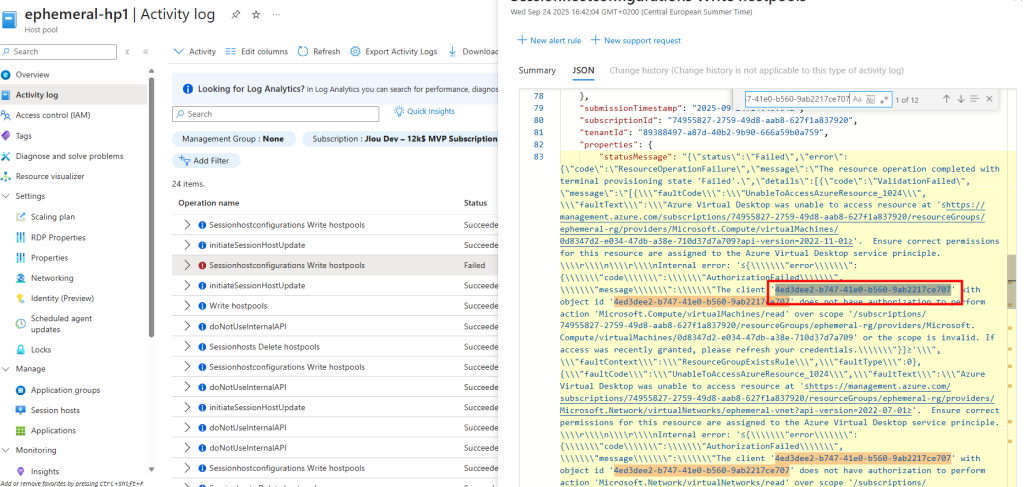
Si malgré tout vous devez conserver votre image de base et effectuer une mise à jour vers Windows 11 24H2, vous risquez de rencontrer un problème de démarrage après la capture de votre image après un sysprep.
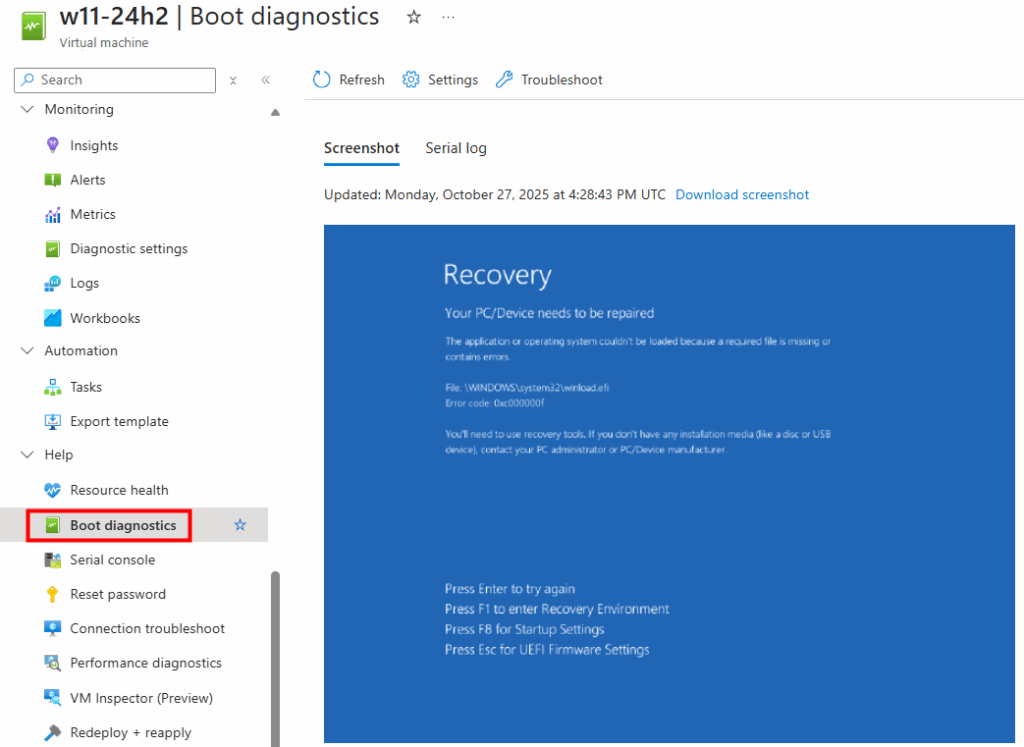
Lors du passage de Windows 10 22H2 ou Windows 11 22H2 vers la version 24H2, plusieurs administrateurs ont rencontré des écrans bleus ou des erreurs EFI (0xc000000f) juste après la capture d’image via Sysprep.
Le problème provient d’un bug dans le processus de Sysprep, qui modifie la configuration BCD lorsque BitLocker (ou le chiffrement automatique du périphérique) est actif.
Et le souci se manifeste à nouveau si on réactive BitLocker sans avoir corrigé la configuration BCD.
Résultat : l’image capturée devient partiellement chiffrée et inutilisable au déploiement.
Ce souci de démarrage est d’ailleurs confirmé dans les journaux de diagnostic Azure :
Pas de workaround possible ?
Pour éviter cela, il faut désactiver BitLocker avant le Sysprep. Une fois l’image déployée, BitLocker peut être réactivé proprement après correction de la configuration BCD. Ce comportement est spécifique aux builds 26100.x (Windows 11 24H2 et LTSC 2024) .
Voici d’abord une comparaison de l’état de BitLocker sur deux machines virtuelles Azure :
- A droite : Windows 10 Multi-session 22H2
- A gauche : Windows 11 Multi-session 24H2
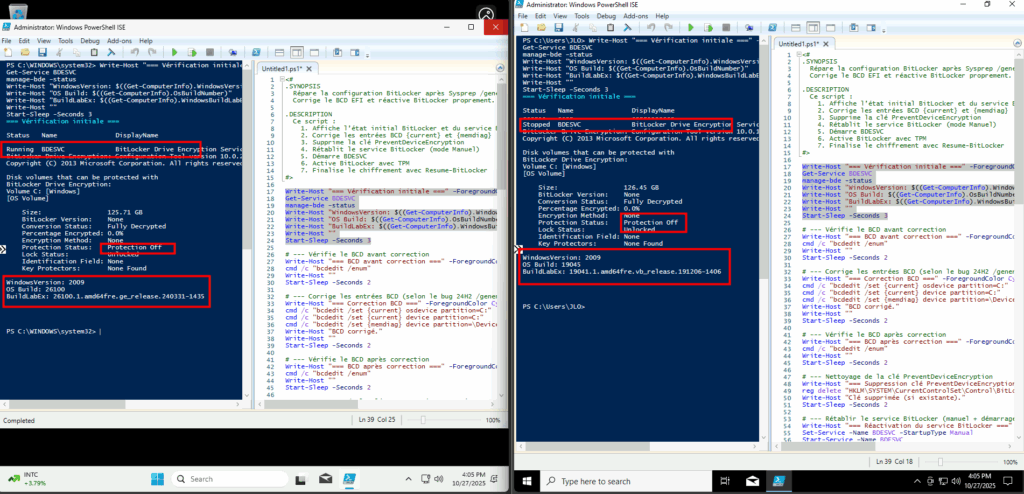
La désactivation de BitLocker doit donc être complète et certaine avant de lancer Sysprep, sous peine de le voir se réactiver.
Afin de voir ce qu’il est possible de faire pour résoudre le souci de BitLocker , je vous propose au travers de cet article un pas à pas sur le processus complet :
- Etape 0 – Rappel des prérequis
- Etape I – Création d’une VM W10 Multi-session 22H2 + MAJ 24H2
- Etape II – Capture de l’image Windows 11 24H2
- Etape III – Réactivation de BitLocker
- Etape IV – Azure Virtual Desktop
Etape 0 – Rappel des prérequis :
Pour réaliser ces tests de mise à jour de VM, il vous faudra disposer de :
- Un abonnement Azure valide
- Un tenant Microsoft
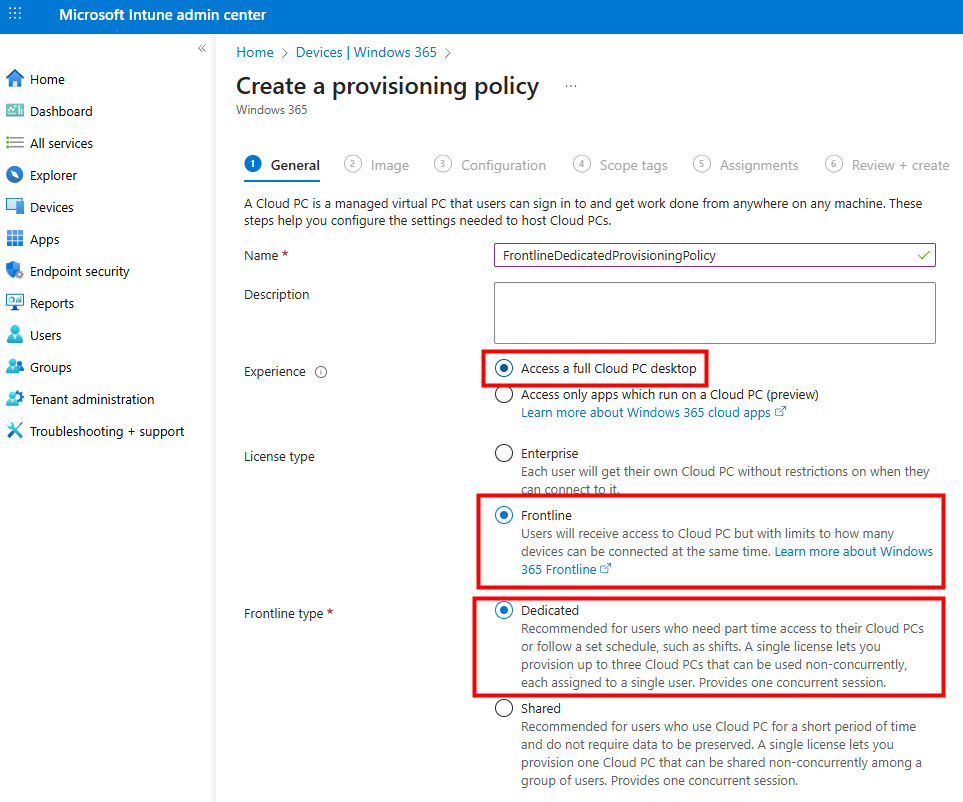
Afin d’être sûr des impacts de nos différentes actions, je vous propose de commencer par la création d’une machine virtuelle à partir d’une image Windows 10/11 multi-session en 22H2, que nous allons mettre à jour dans la foulée.
Etape I – Création d’une VM W10 Multi-session 22H2 + MAJ 24H2 :
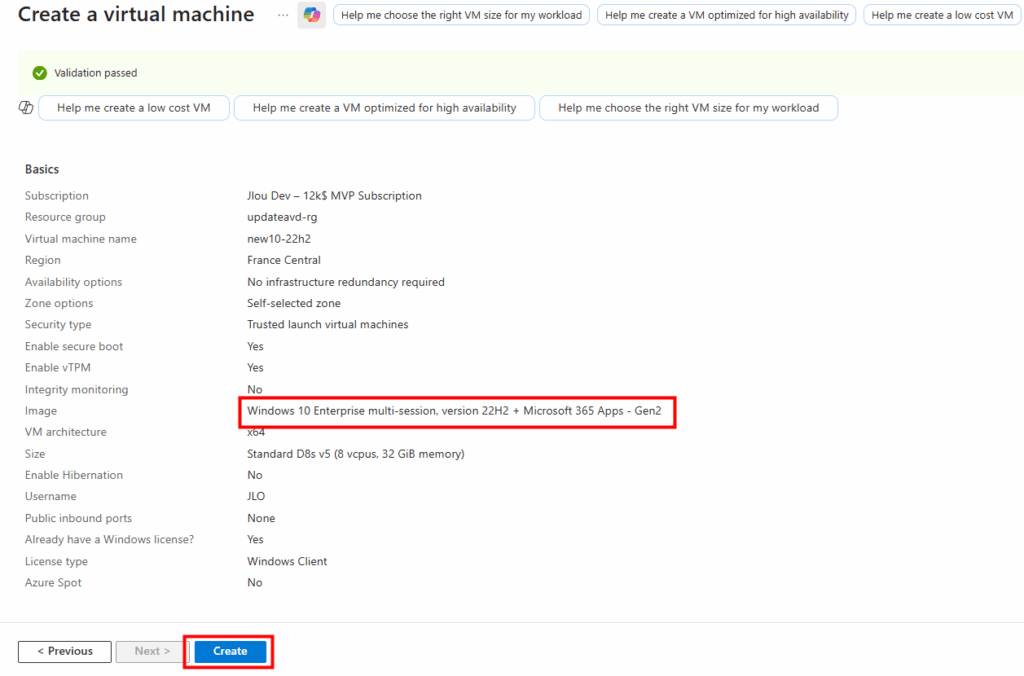
Pour cela, je commence par créer une machine virtuelle Azure en Windows 10 en 22H2 :
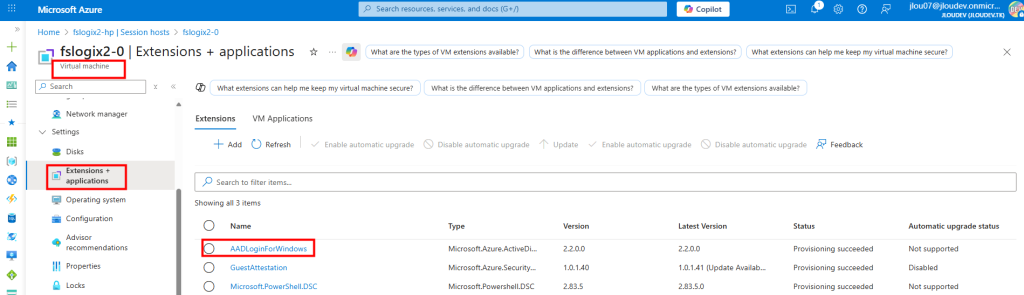
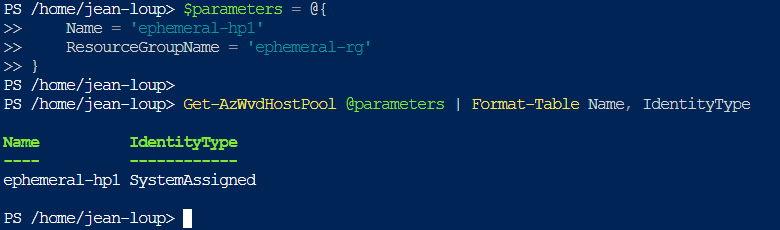
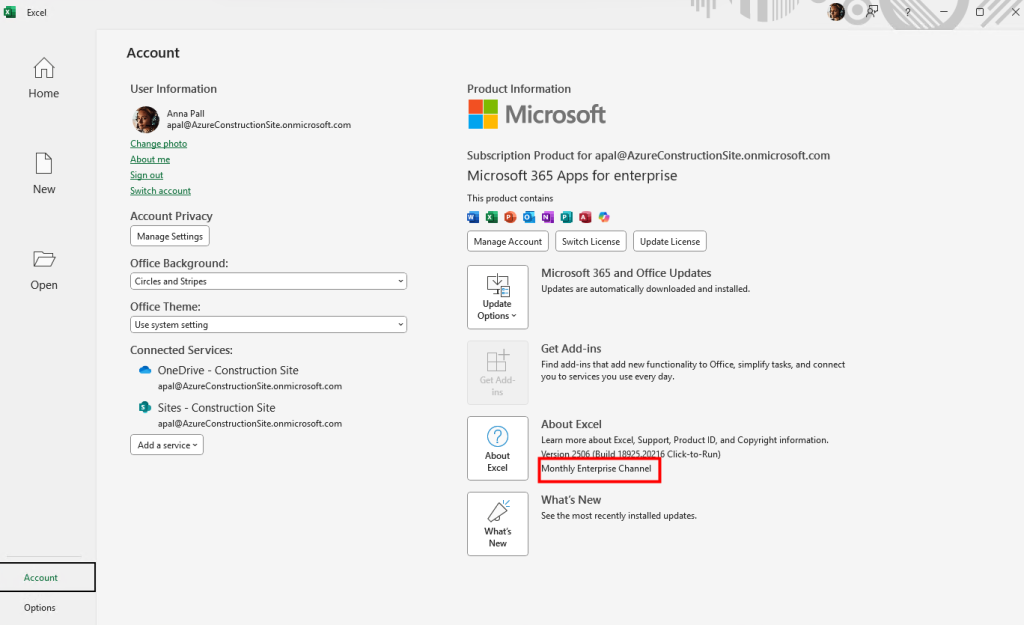
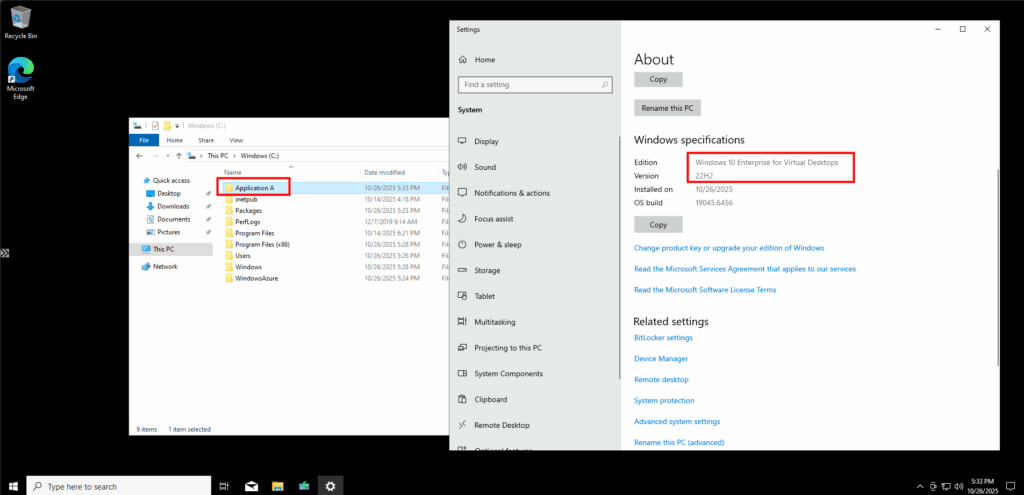
Une fois la machine virtuelle déployée, je vérifie la présence de mon application et de ma version actuelle de Windows :
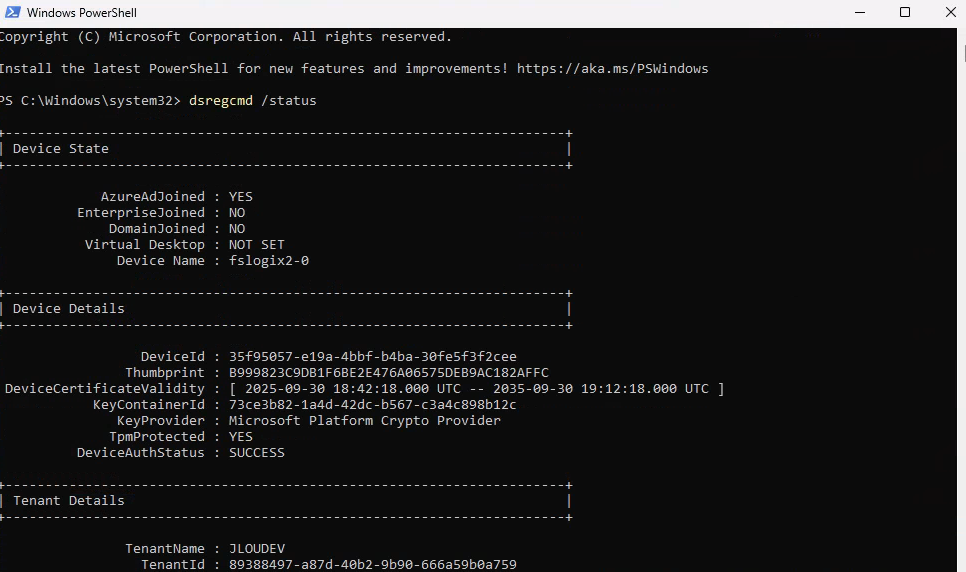
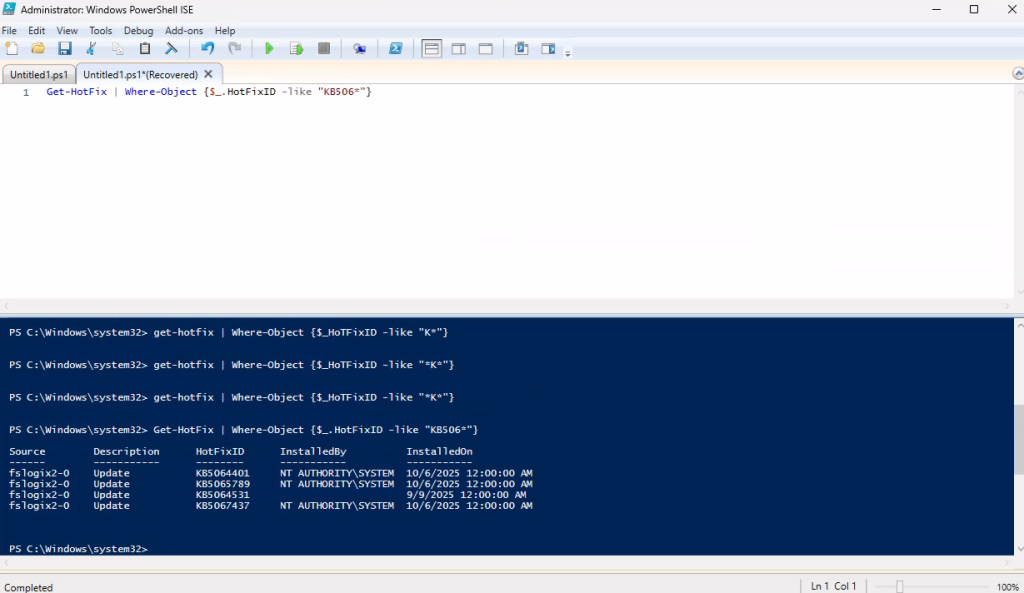
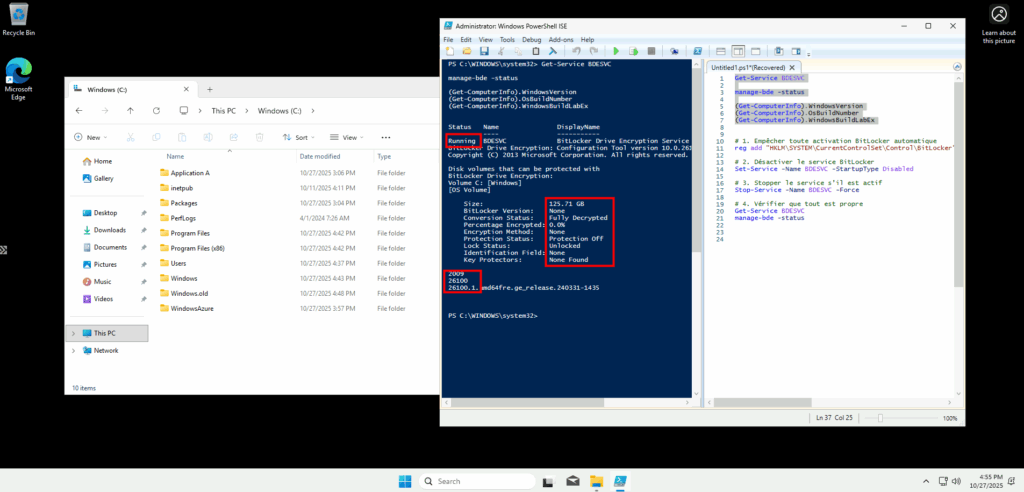
J’ouvre PowerShell ISE en mode administrateur afin de vérifier l’état actuel de BitLocker :
- Get-Service BDESVC : affiche l’état du service BitLocker Drive Encryption Service, qui gère le chiffrement BitLocker sur Windows.
- manage-bde -status : affiche le statut détaillé du chiffrement BitLocker sur tous les lecteurs du système.
- (Get-ComputerInfo).WindowsVersion : retourne la version majeure de Windows (ex. 10, 11, etc.).
- (Get-ComputerInfo).OsBuildNumber : affiche le numéro de build du système d’exploitation Windows.
- (Get-ComputerInfo).WindowsBuildLabEx : fournit la version complète du build Windows avec des informations additionnelles (branche, révision, date de compilation).
Get-Service BDESVC
manage-bde -status
(Get-ComputerInfo).WindowsVersion
(Get-ComputerInfo).OsBuildNumber
(Get-ComputerInfo).WindowsBuildLabEx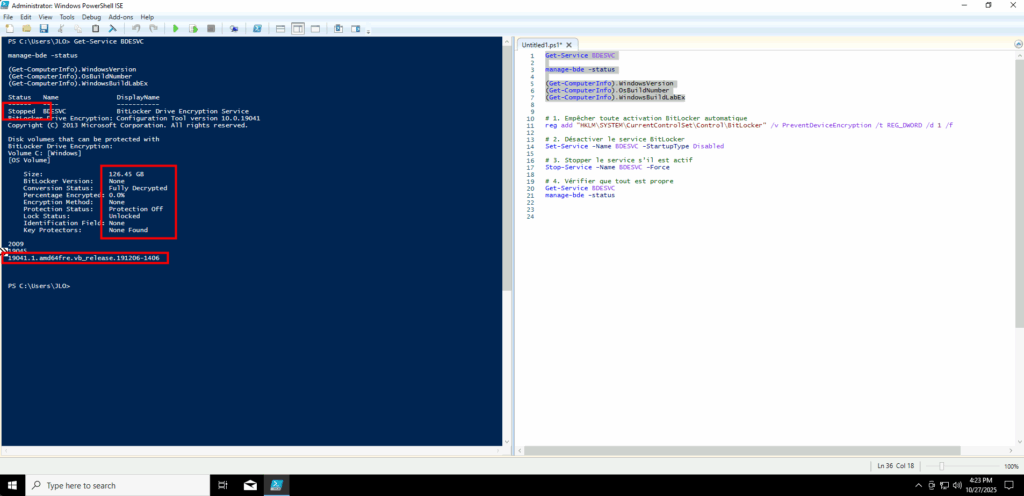
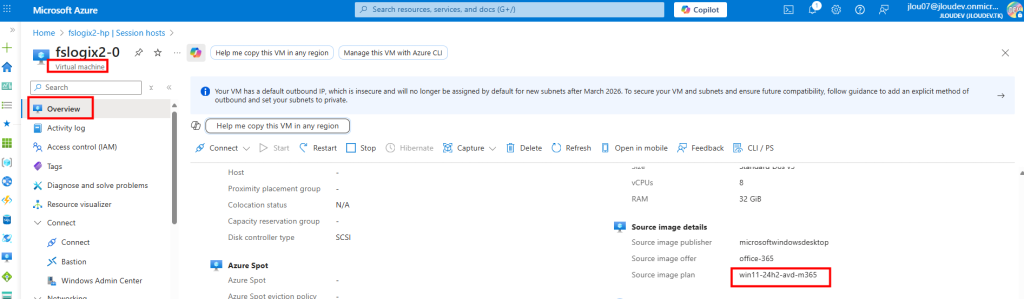
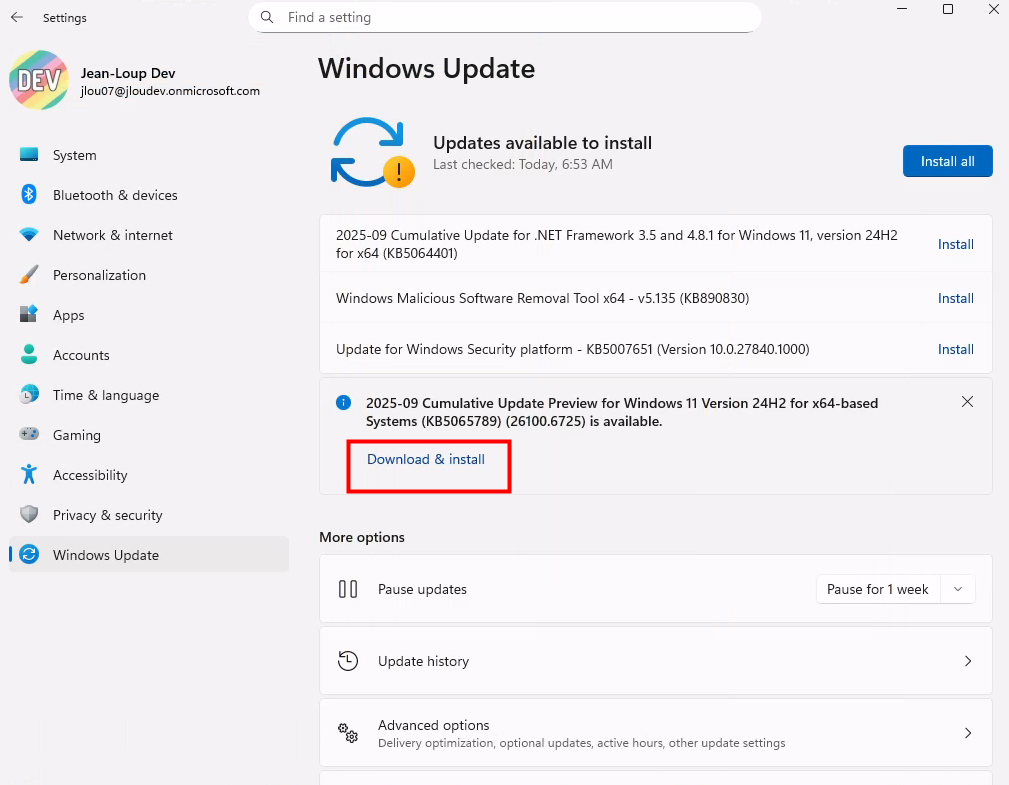
Je télécharge ensuite l’ISO Windows 11 24H2 depuis Visual Studio :
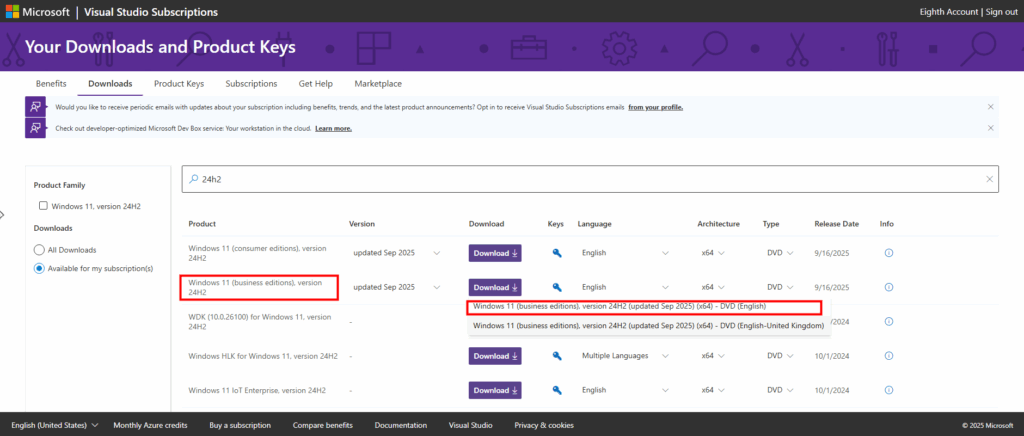
Je lance l’installation de Windows 11 en 24H2 :
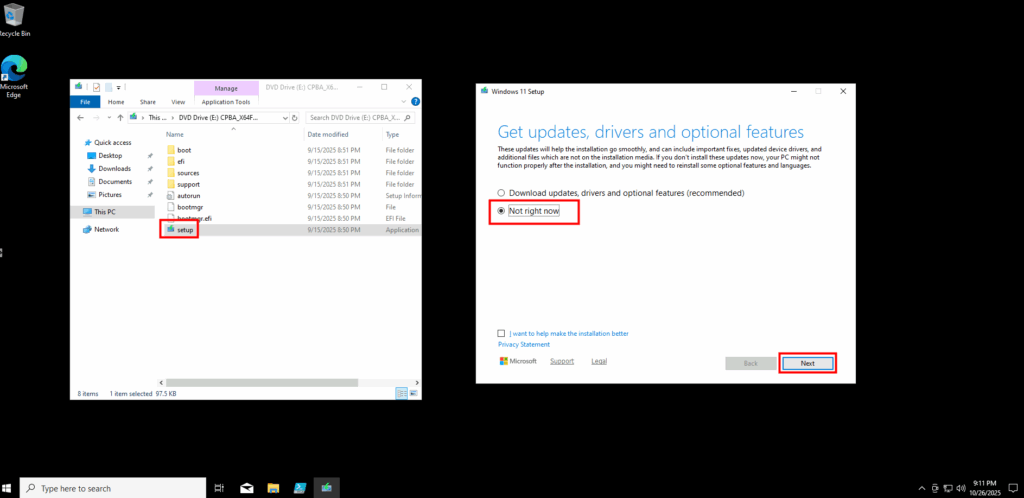
Je vérifie le maintien de la version Multi-session, puis je démarre l’installation :
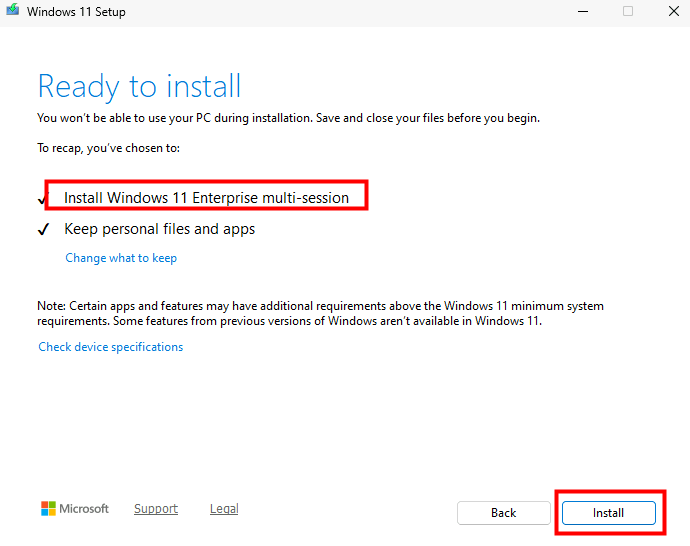
L’installation progresse lentement mais sûrement :
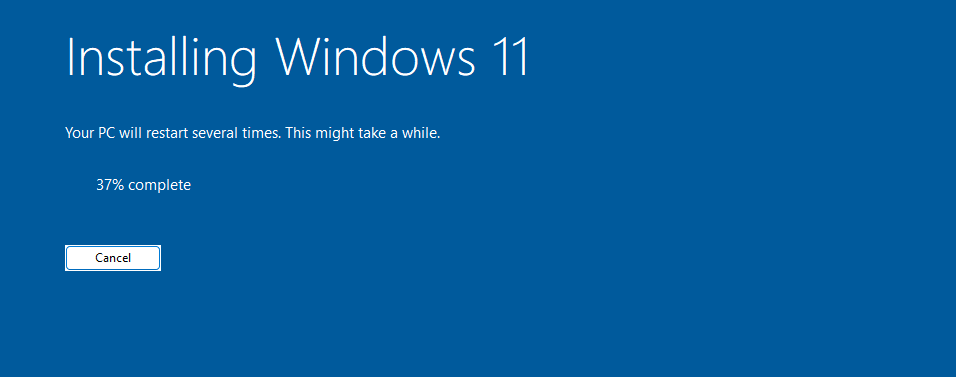
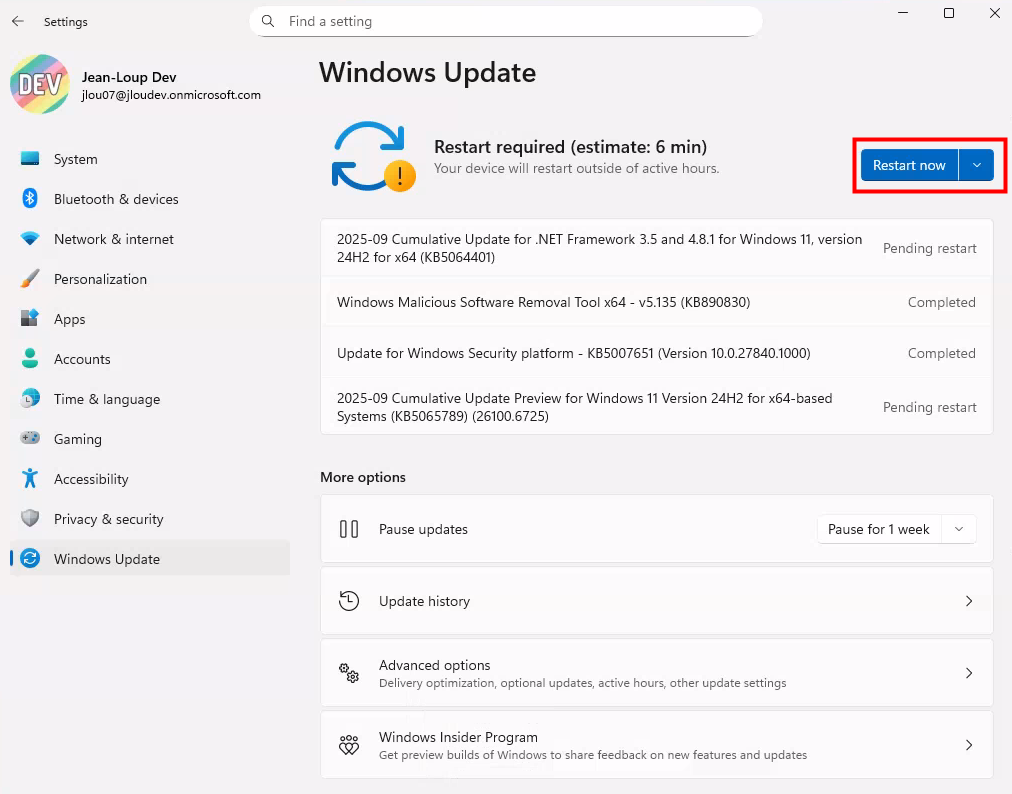
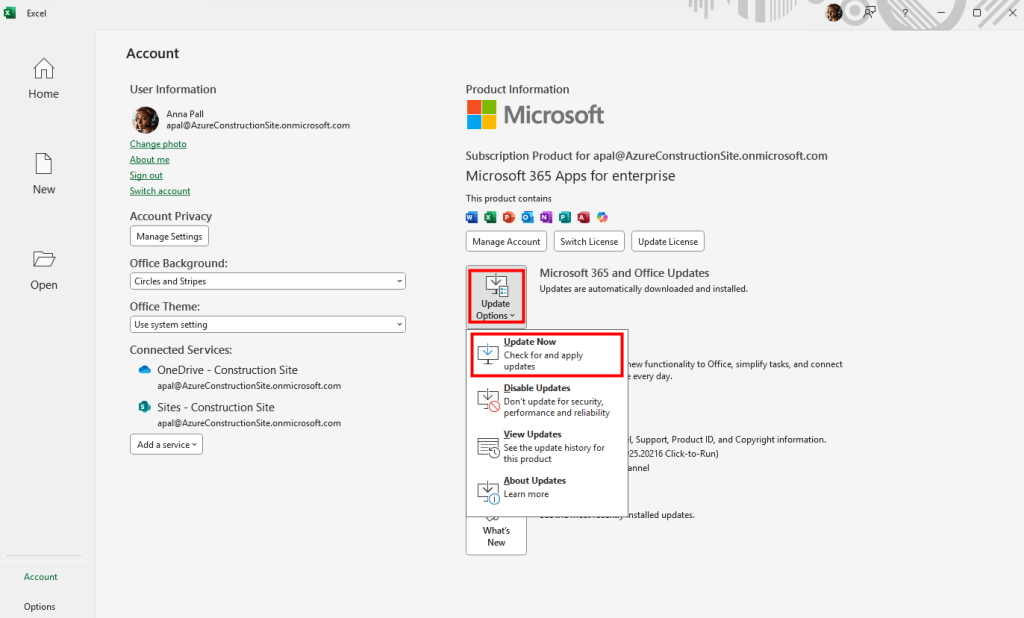
Afin de m’assurer que la mise à jour est terminée, je vérifie les journaux de diagnostic Azure pour confirmer le bon démarrage de la machine virtuelle :
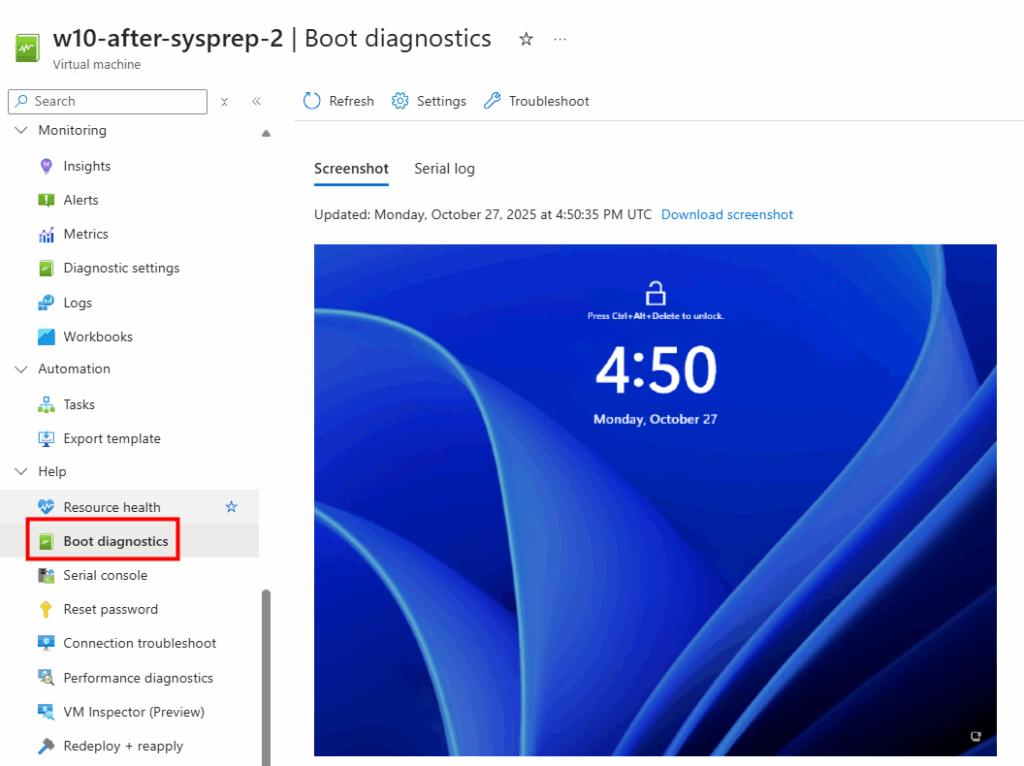
Je me connecte via Azure Bastion et je vérifie le statut de BitLocker :
Get-Service BDESVC
manage-bde -status
(Get-ComputerInfo).WindowsVersion
(Get-ComputerInfo).OsBuildNumber
(Get-ComputerInfo).WindowsBuildLabExLe service de BitLocker BDESVC est maintenant démarré en 24H2 :
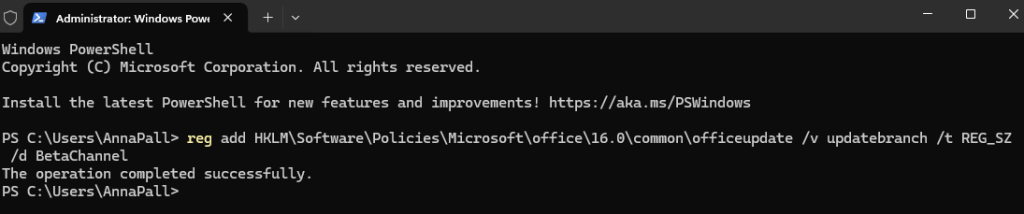
Je lance les commandes suivantes pour arrêter le service BitLocker BDESVC, mais aussi pour bloquer son changement de statut lors du sysprep :
# 1. Empêcher toute activation BitLocker automatique
reg add "HKLM\SYSTEM\CurrentControlSet\Control\BitLocker" /v PreventDeviceEncryption /t REG_DWORD /d 1 /f
# 2. Désactiver le service BitLocker
Set-Service -Name BDESVC -StartupType Disabled
# 3. Stopper le service s’il est actif
Stop-Service -Name BDESVC -Force
# 4. Vérifier que tout est propre
Get-Service BDESVC
manage-bde -status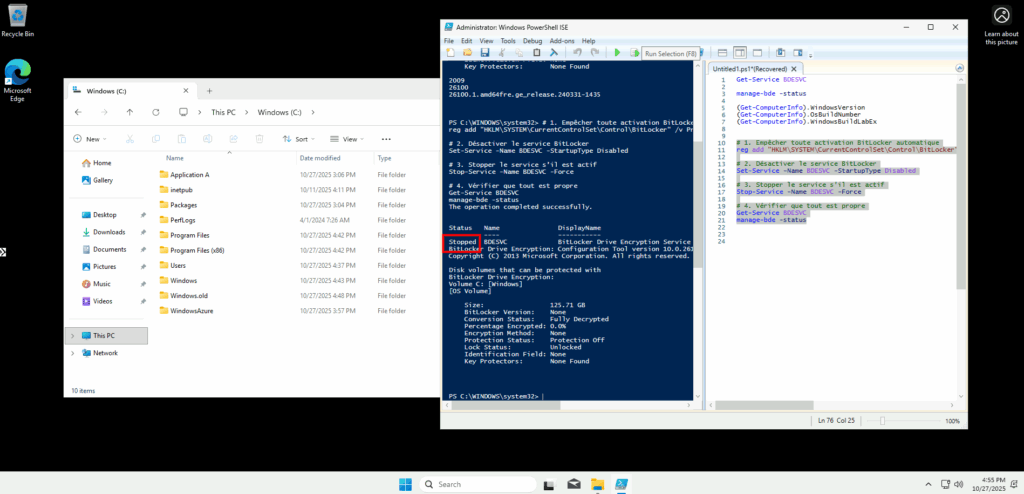
La machine virtuelle est maintenant prête pour la capture. Avant cela je pourrais effectuer un snapshot. Je décide de continuer avec la commande Sysprep.
Etape II – Capture de l’image Windows 11 24H2 :
Je lance la commande Sysprep pour capturer cette nouvelle image 24H2 :
C:\Windows\System32\Sysprep\sysprep.exe /quiet /generalize /oobe /mode:vm /shutdown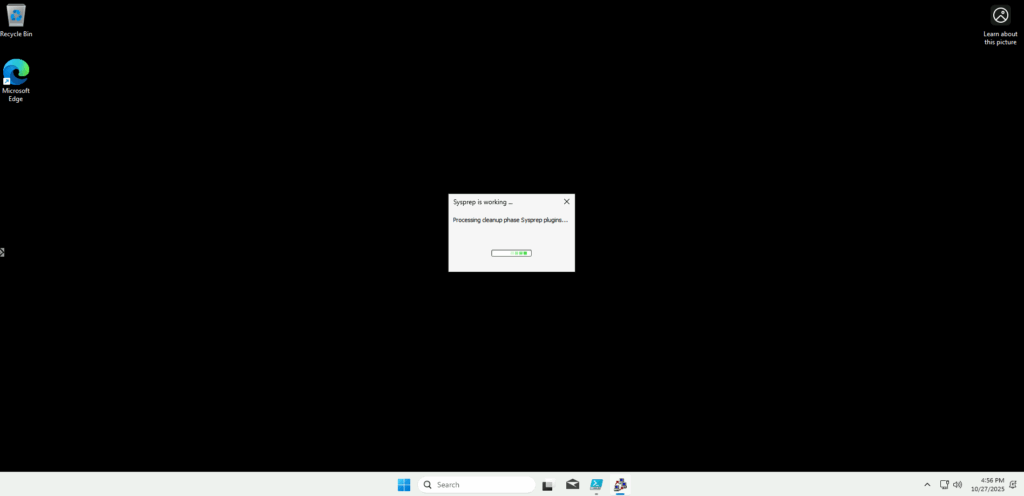
Une fois Sysprep terminé, j’arrête complètement la machine pour qu’elle soit désallouée, puis je lance l’action de capture de l’image depuis le portail Azure :
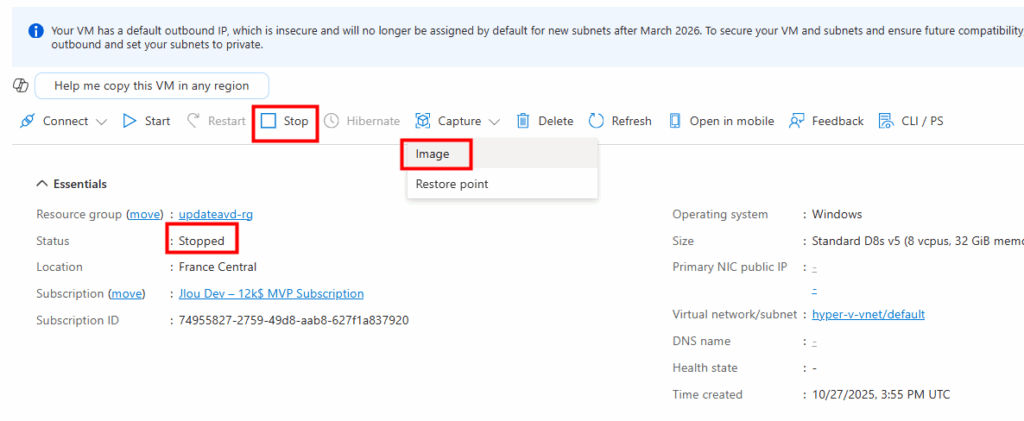
Je crée une nouvelle image au sein de ma Azure Compute Gallery :
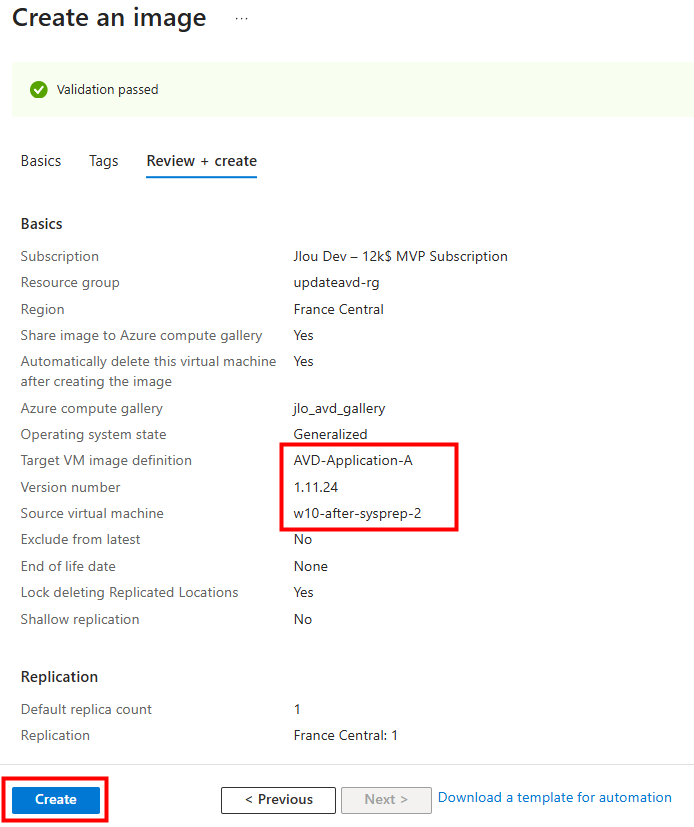
Avec cette nouvelle image en place, je déclenche la création d’une nouvelle machine virtuelle 24H2 à partir de celle-ci :
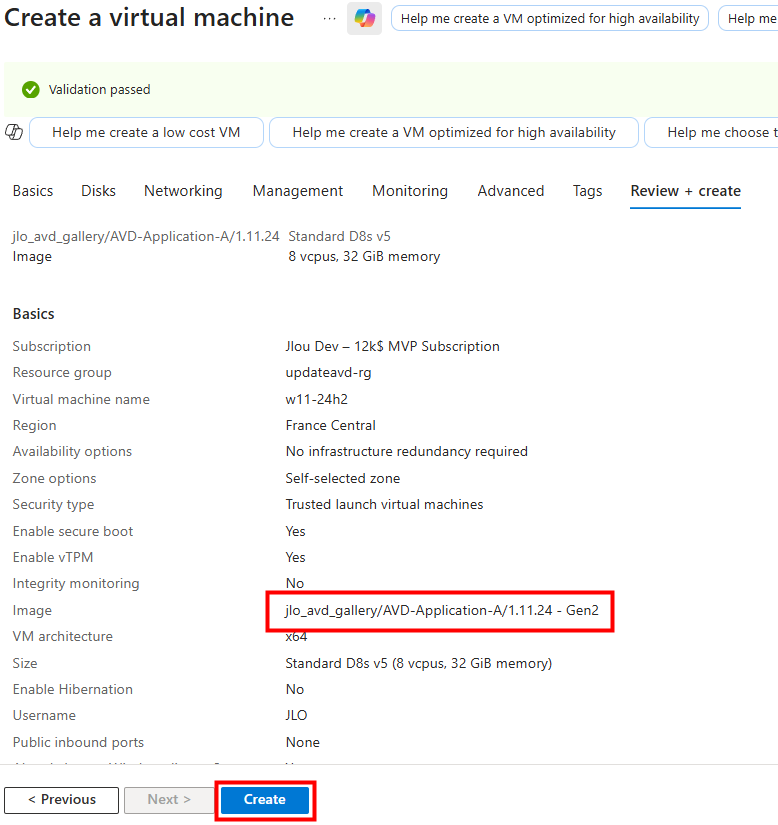
La nouvelle machine virtuelle est fonctionnelle, et cela est confirmé dans les journaux de diagnostic Azure :
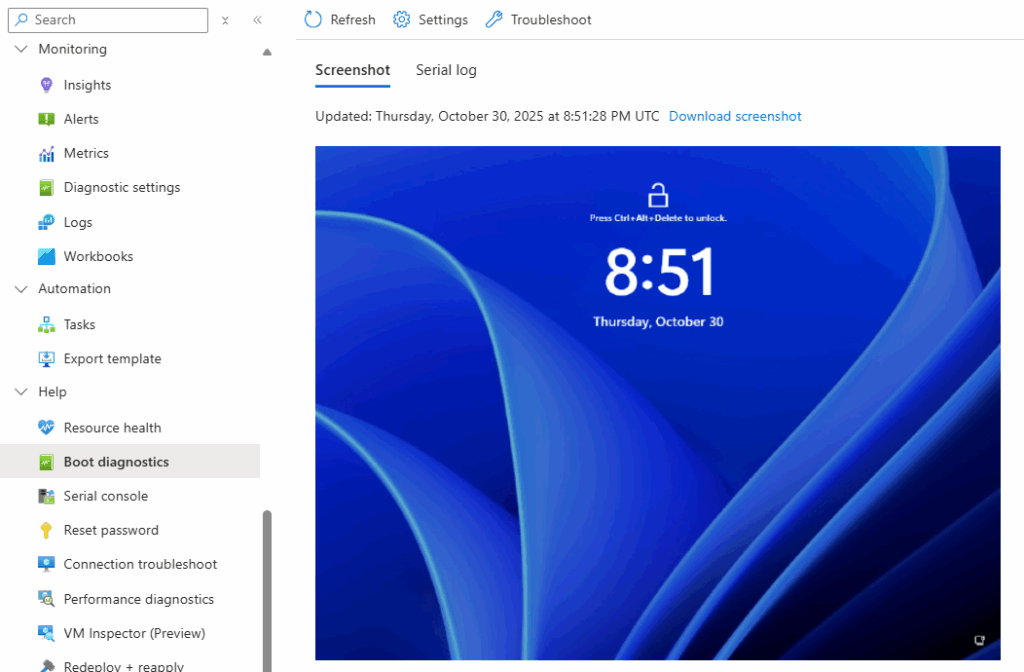
Etape III – Réactivation de BitLocker :
Une fois la VM créée, je m’y connecte via Azure Bastion, puis je lance la vérification initiale de l’état du service BitLocker et du chiffrement :
Write-Host "=== Vérification initiale ===" -ForegroundColor Cyan
Get-Service BDESVC
manage-bde -status
Write-Host "WindowsVersion: $((Get-ComputerInfo).WindowsVersion)"
Write-Host "OS Build: $((Get-ComputerInfo).OsBuildNumber)"
Write-Host "BuildLabEx: $((Get-ComputerInfo).WindowsBuildLabEx)"
Write-Host ""
Start-Sleep -Seconds 3Le statut du service BitLocker est toujours sur OFF comme attendu, et le disque OS se trouve toujours dans un état de déchiffrement :
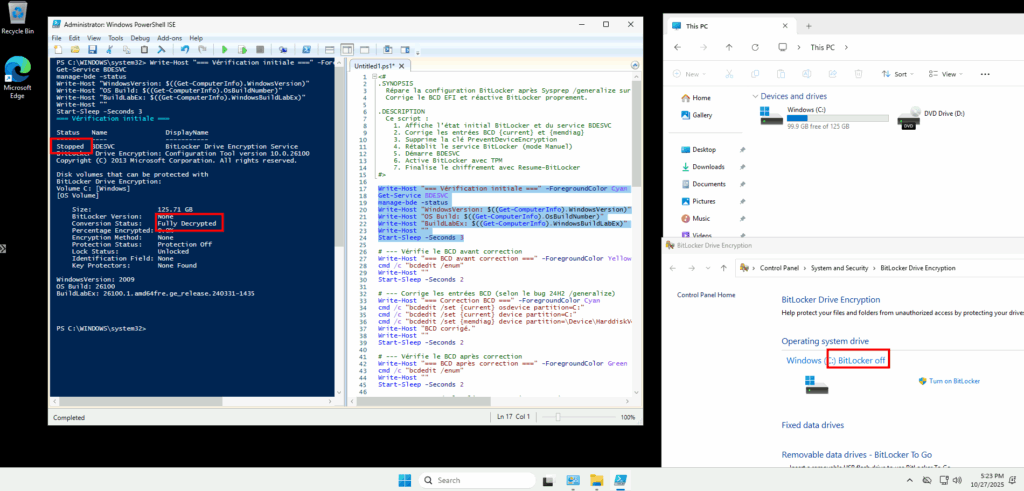
Avant de pouvoir chiffrer le disque OS, nous avons besoin de corriger la configuration de BCD.
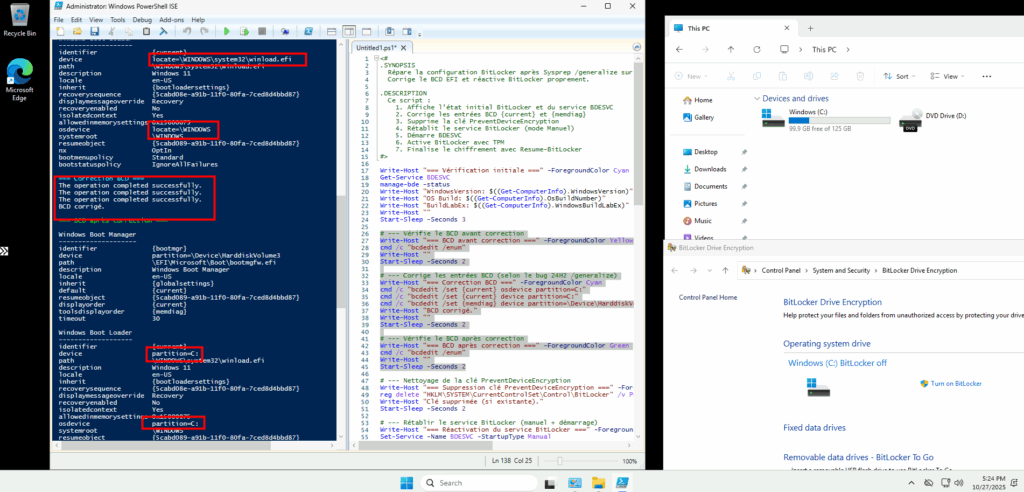
Je vérifie la configuration actuelle du BCD, corrige les entrées BCD liées à la partition système et au diagnostic mémoire :
# --- Vérifie le BCD avant correction
Write-Host "=== BCD avant correction ===" -ForegroundColor Yellow
cmd /c "bcdedit /enum"
Write-Host ""
Start-Sleep -Seconds 2
# --- Corrige les entrées BCD (selon le bug 24H2 /generalize)
Write-Host "=== Correction BCD ===" -ForegroundColor Cyan
cmd /c "bcdedit /set {current} osdevice partition=C:"
cmd /c "bcdedit /set {current} device partition=C:"
cmd /c "bcdedit /set {memdiag} device partition=\Device\HarddiskVolume3"
Write-Host "BCD corrigé."
Write-Host ""
Start-Sleep -Seconds 2
# --- Vérifie le BCD après correction
Write-Host "=== BCD après correction ===" -ForegroundColor Green
cmd /c "bcdedit /enum"
Write-Host ""
Start-Sleep -Seconds 2La correction est bien visible sur cette seconde partie de l’écran :
Je supprime la clé de registre PreventDeviceEncryption si elle est présente, je rétablis le service BitLocker en mode manuel, je le démarre, puis je contrôle à nouveau l’état du service BDESVC et de BitLocker :
# --- Nettoyage de la clé PreventDeviceEncryption
Write-Host "=== Suppression clé PreventDeviceEncryption ===" -ForegroundColor Cyan
reg delete "HKLM\SYSTEM\CurrentControlSet\Control\BitLocker" /v PreventDeviceEncryption /f | Out-Null
Write-Host "Clé supprimée (si existante)."
Start-Sleep -Seconds 2
# --- Rétablir le service BitLocker (manuel + démarrage)
Write-Host "=== Réactivation du service BitLocker ===" -ForegroundColor Cyan
Set-Service -Name BDESVC -StartupType Manual
Start-Service -Name BDESVC
Write-Host "Service BDESVC en cours d’exécution."
Write-Host ""
Start-Sleep -Seconds 2
# --- Vérifie l’état avant chiffrement
Write-Host "=== État avant chiffrement ===" -ForegroundColor Yellow
Get-Service BDESVC
manage-bde -status
Write-Host ""
Start-Sleep -Seconds 2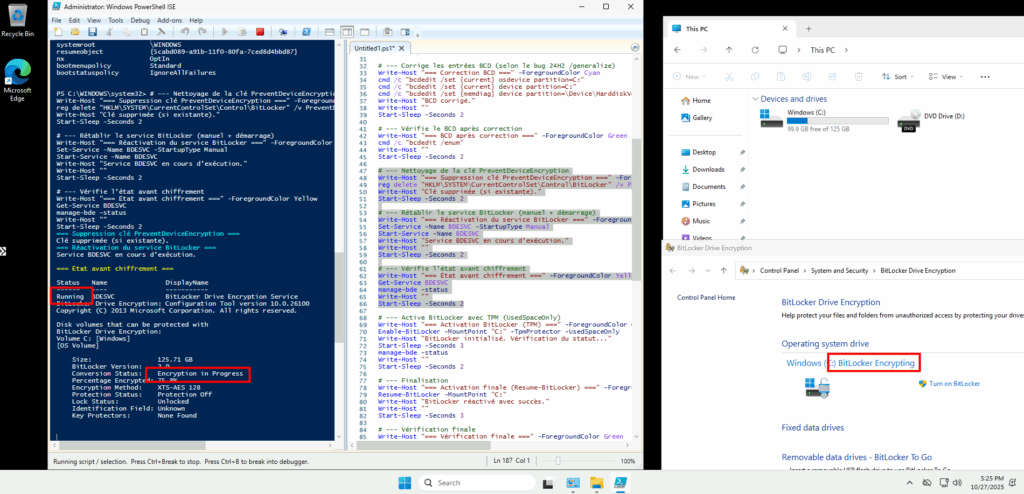
J’attends environ 15 minutes la fin du chiffrement du disque OS :
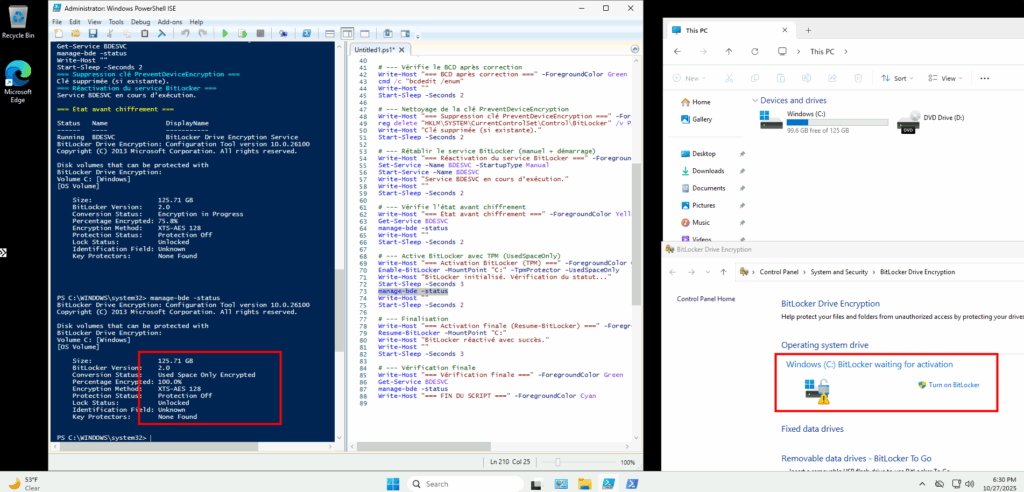
Ensuite, j’active la protection BitLooker :
# --- Active BitLocker avec TPM (UsedSpaceOnly)
Write-Host "=== Activation BitLocker (TPM) ===" -ForegroundColor Cyan
Enable-BitLocker -MountPoint "C:" -TpmProtector -UsedSpaceOnly
Write-Host "BitLocker initialisé. Vérification du statut..."
Start-Sleep -Seconds 3
manage-bde -status
Write-Host ""
Start-Sleep -Seconds 2Cette activation est visible par le petit cadenas présent dans les paramétrages BitLocker et dans l’explorateur de fichier, suivi éventuellement d’un avertissement pour me signaler que la protection est encore sur OFF :
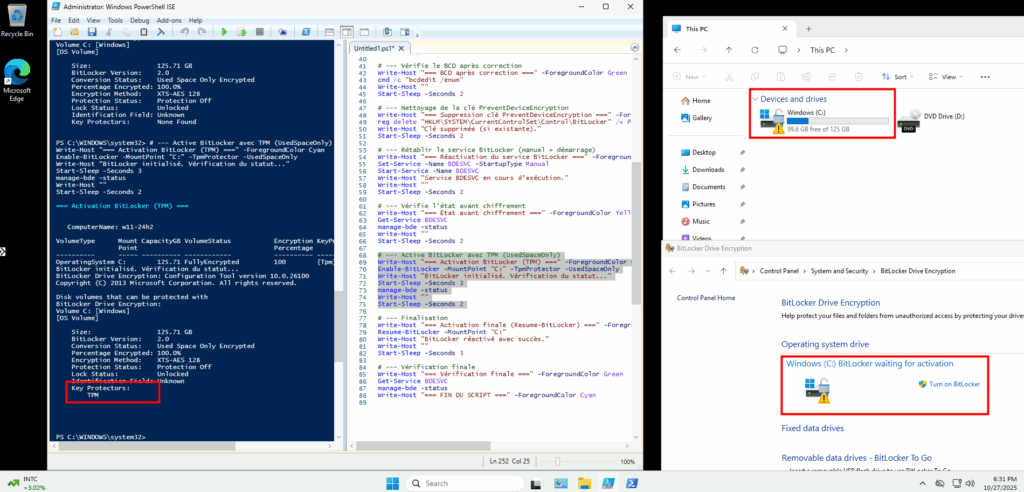
Une fois le chiffrement en place, je remets en route la protection (clé TPM active, verrouillage à l’amorçage autorisé)”.
# --- Finalisation
Write-Host "=== Activation finale (Resume-BitLocker) ===" -ForegroundColor Cyan
Resume-BitLocker -MountPoint "C:"
Write-Host "BitLocker réactivé avec succès."
Write-Host ""
Start-Sleep -Seconds 3
# --- Vérification finale
Write-Host "=== Vérification finale ===" -ForegroundColor Green
Get-Service BDESVC
manage-bde -status
Write-Host "=== FIN DU SCRIPT ===" -ForegroundColor CyanCette validation est visible par la disparition de l’avertissement pour me signaler que la protection est maintenant sur ON :
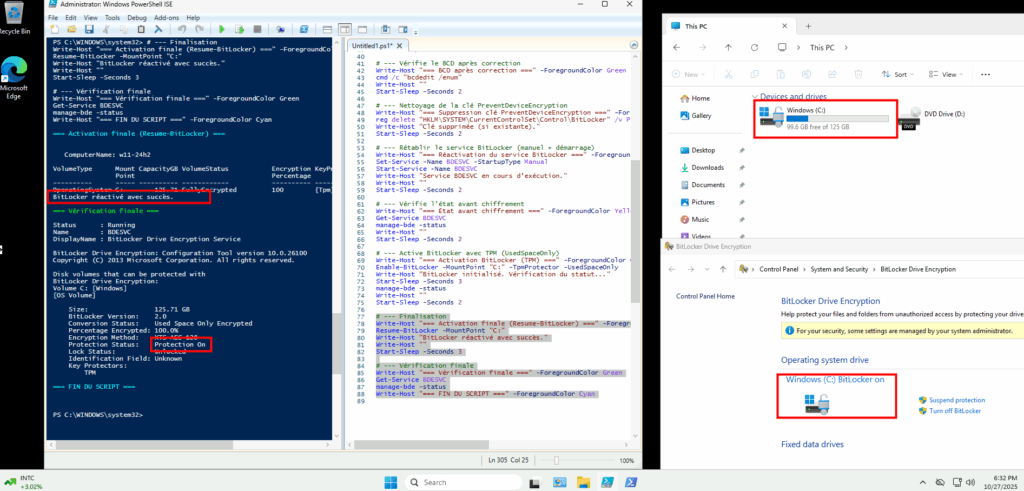
Etape IV – Azure Virtual Desktop :
Je redémarre la machine virtuelle pour vérifier le bon fonctionnement du boot de Windows :
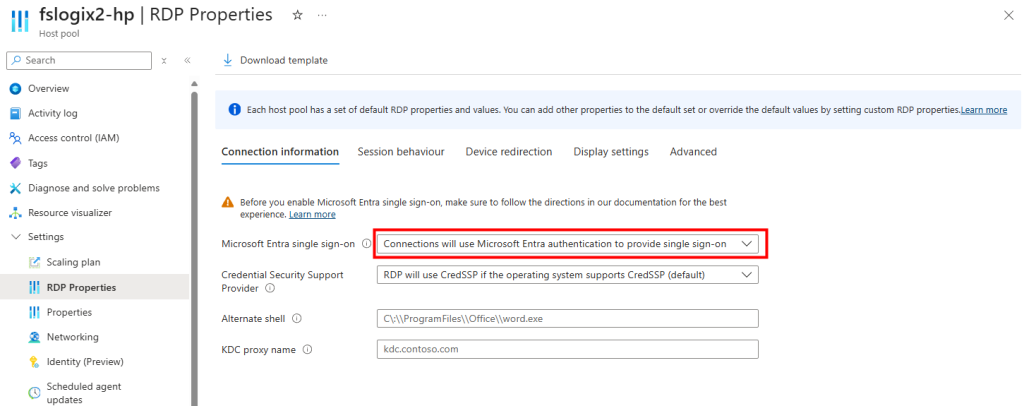
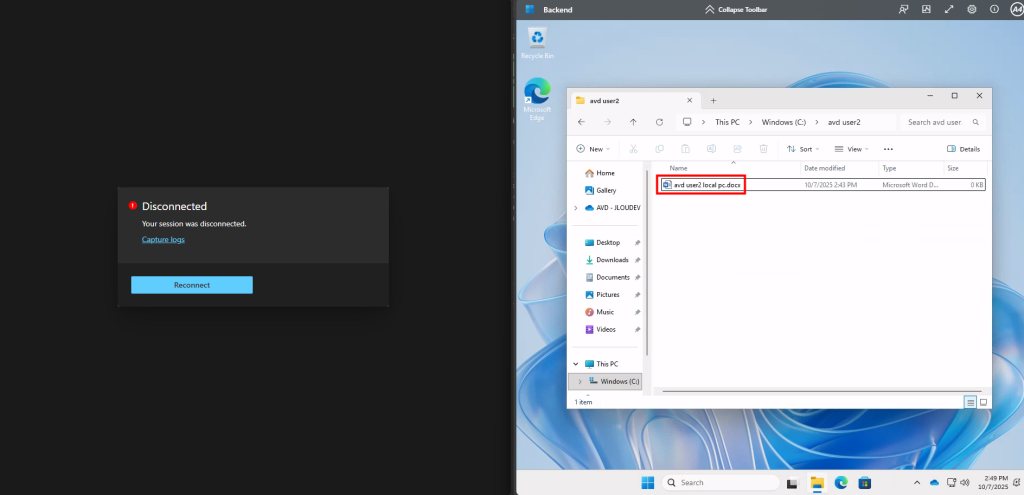
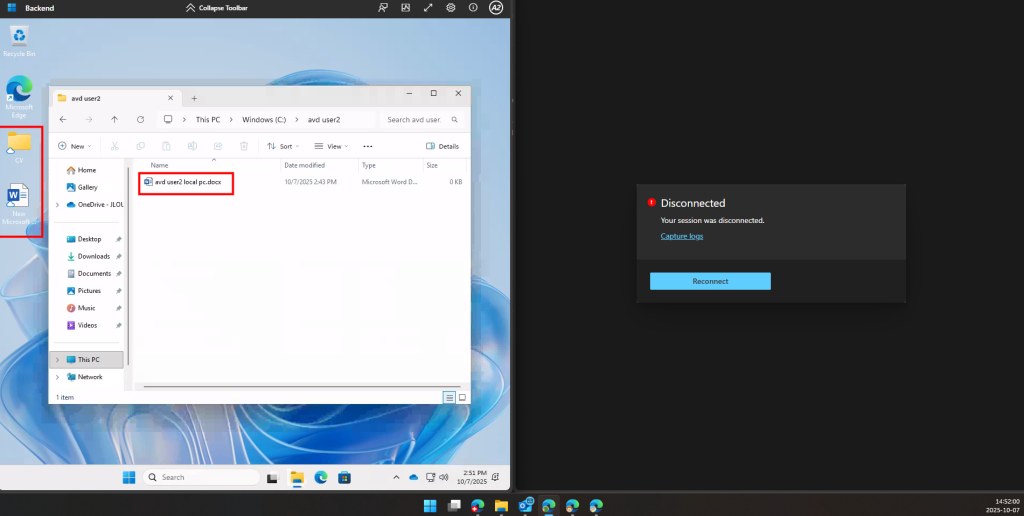
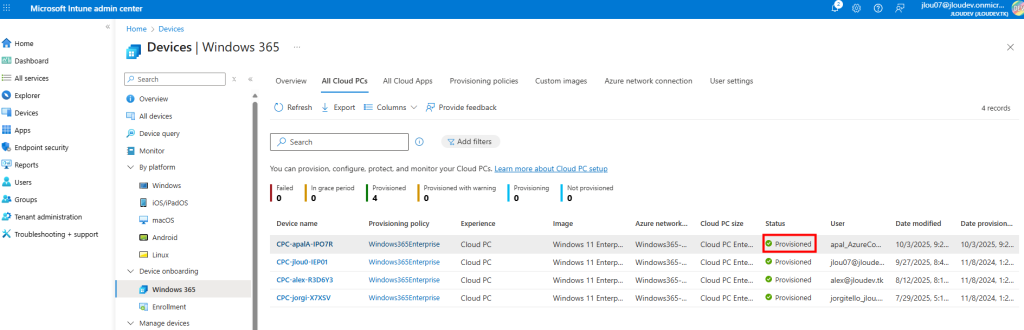
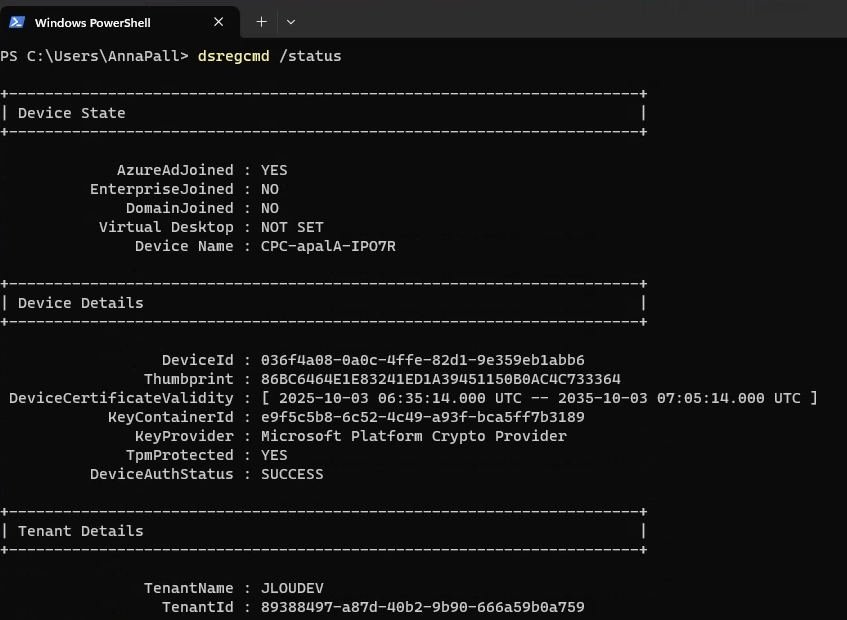
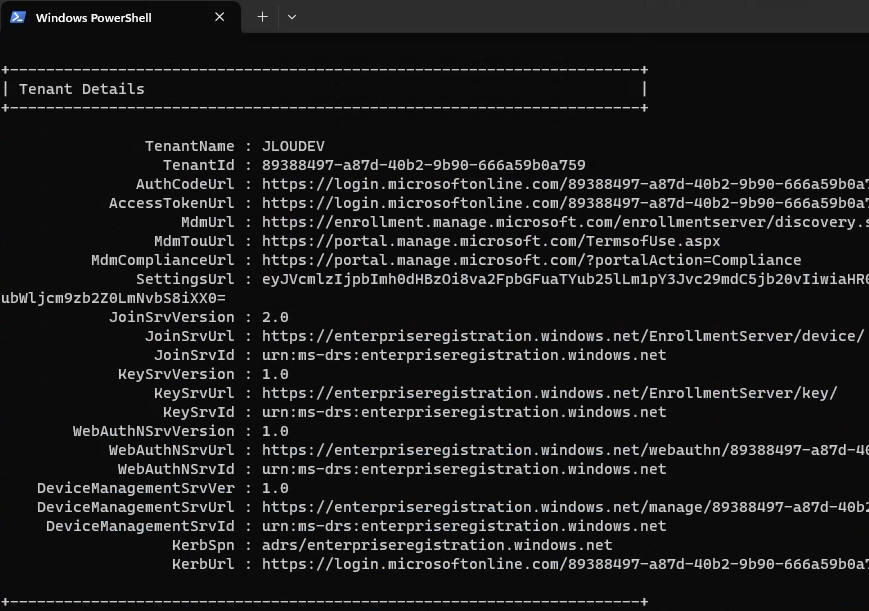
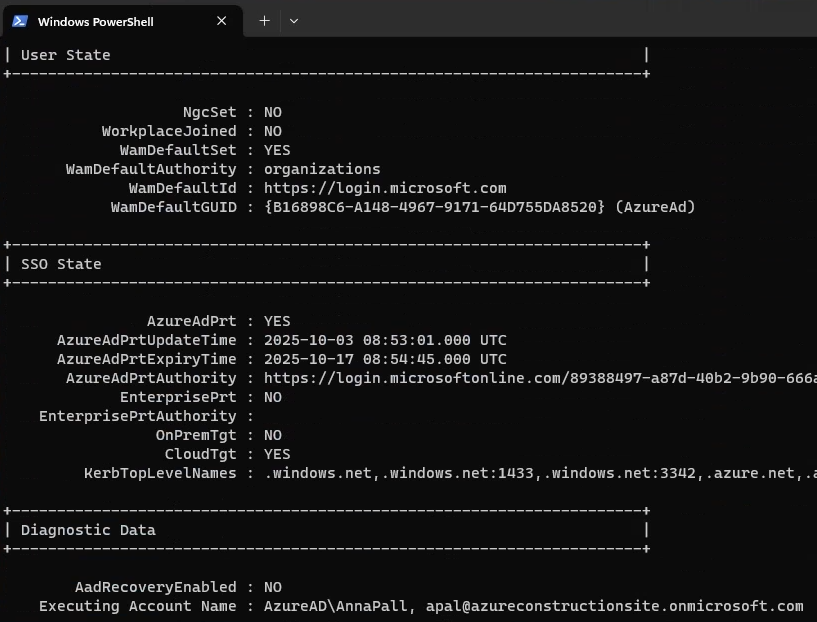
Une fois la VM redémarrée, je me reconnecte et confirme la présence de mon application, de la version 24H2 et de l’état actif de BitLocker sur cette machine virtuelle :
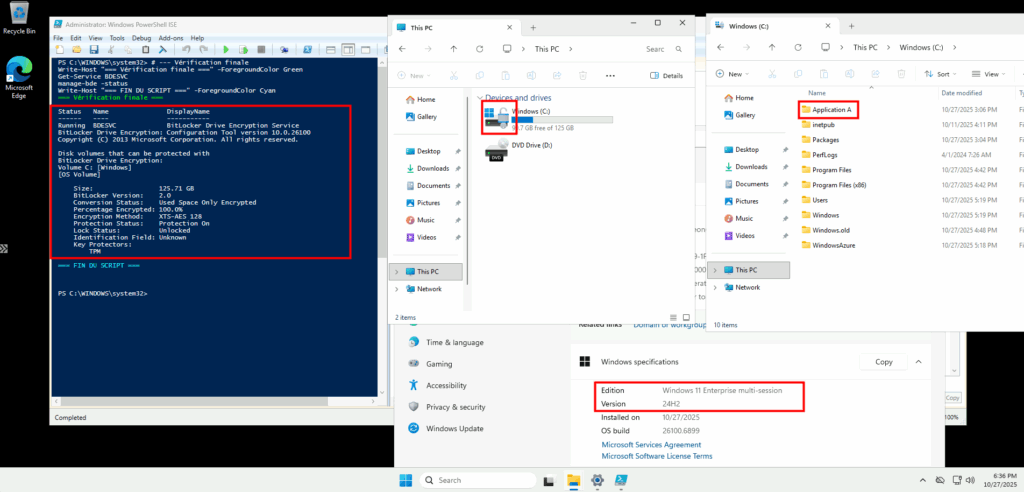
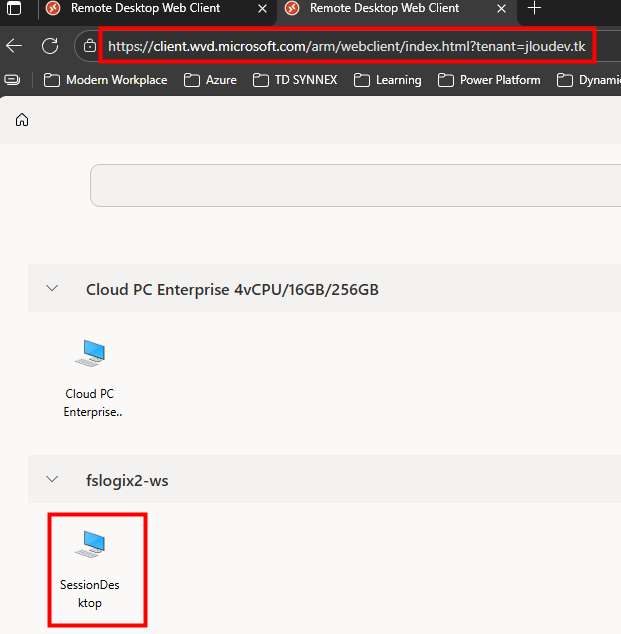
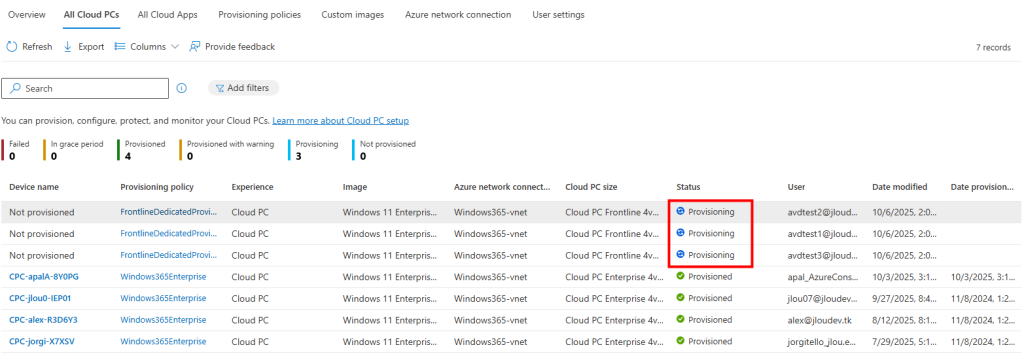
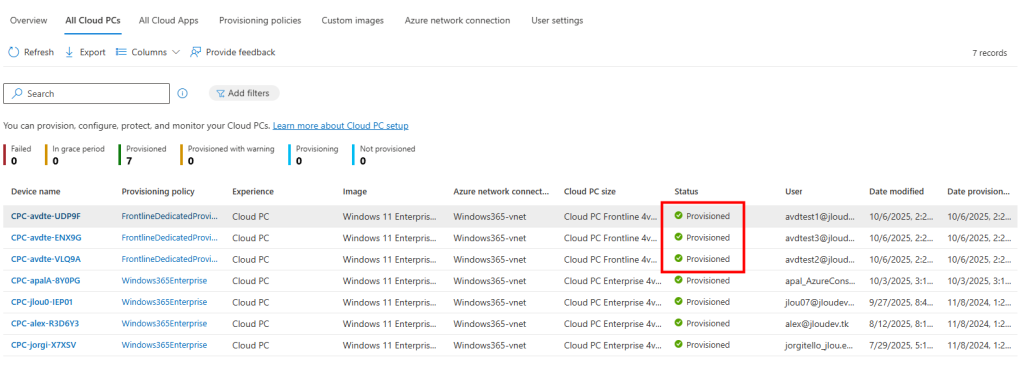
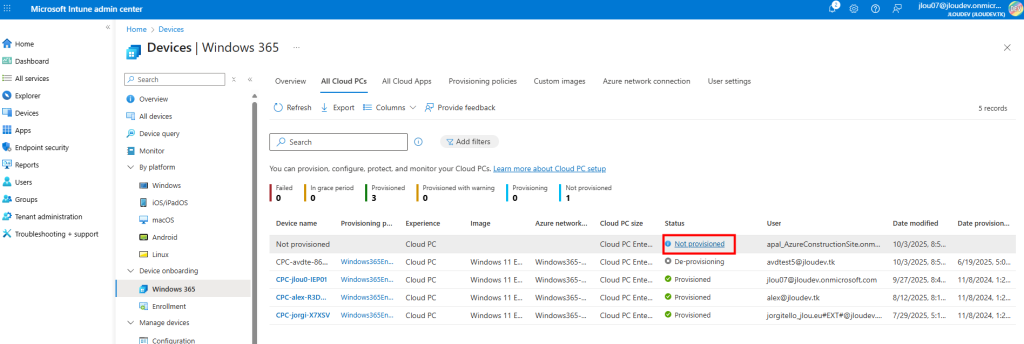
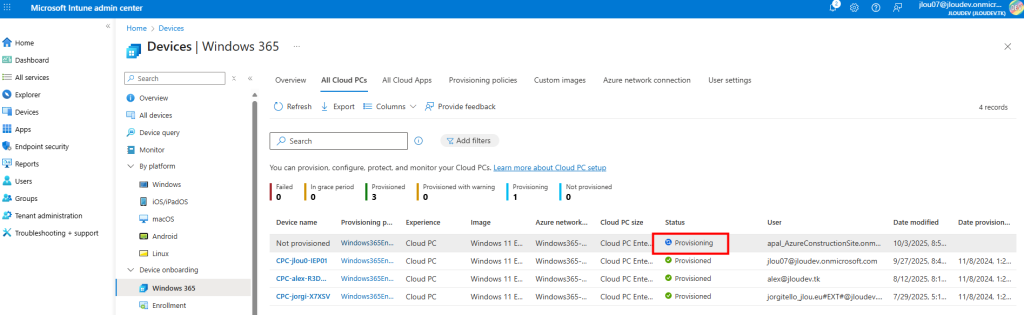
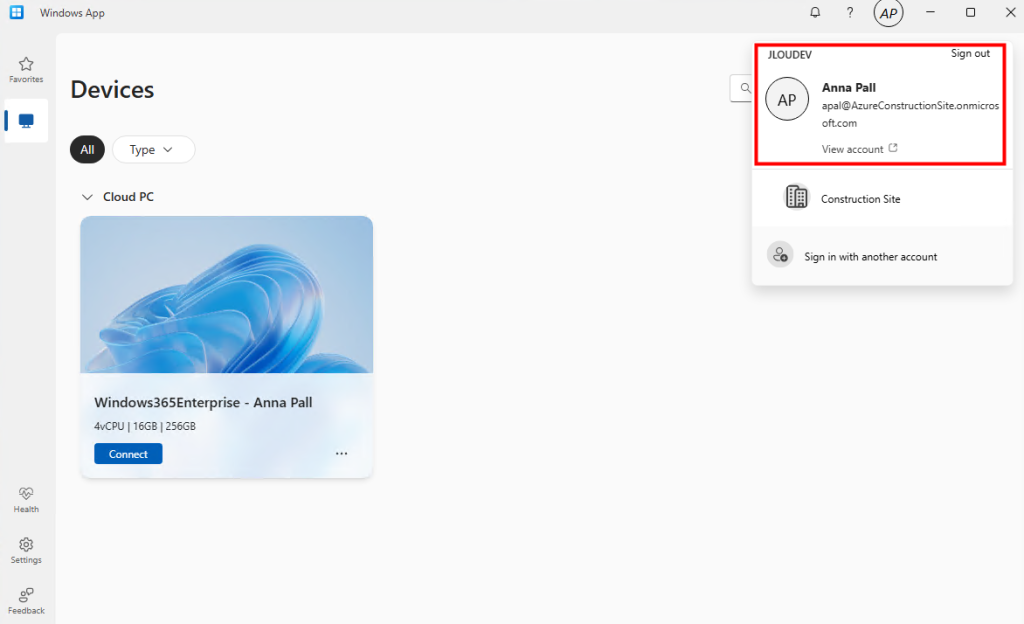
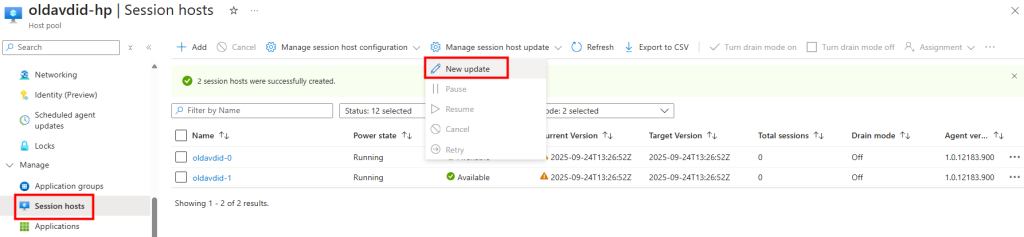
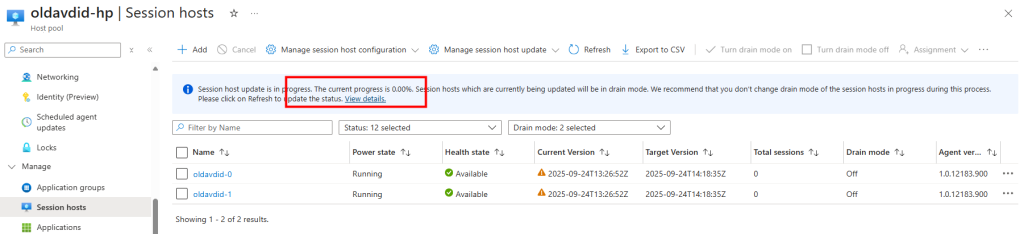
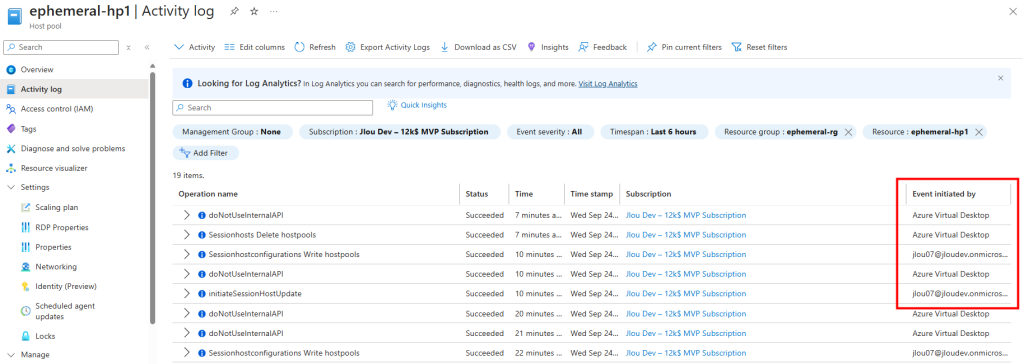
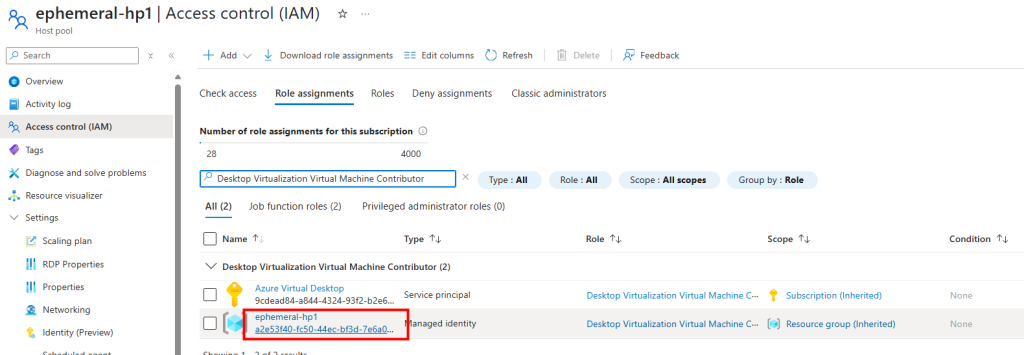
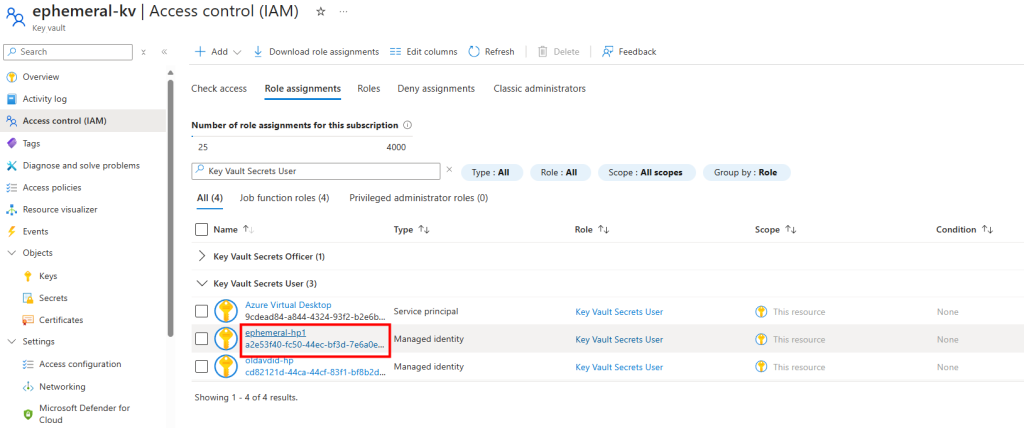
Je teste l’ajout de cette image dans un environnement Azure Virtual Desktop :
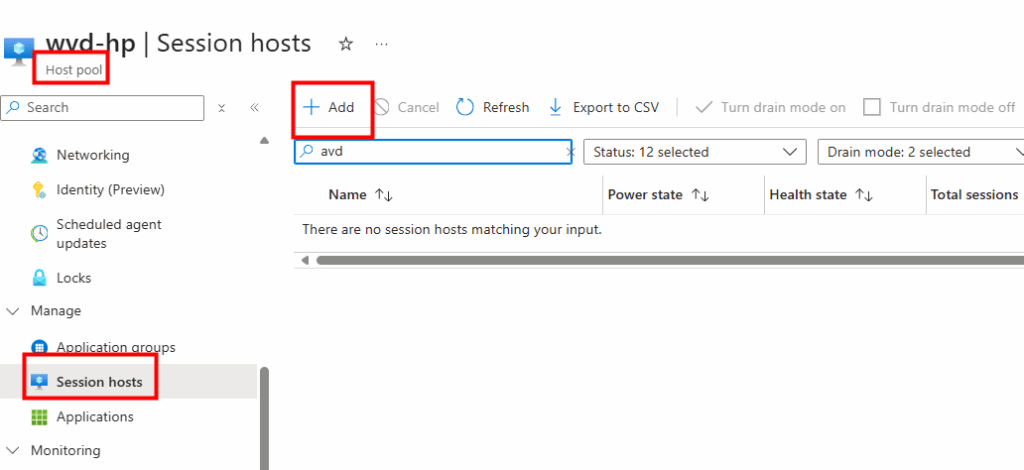
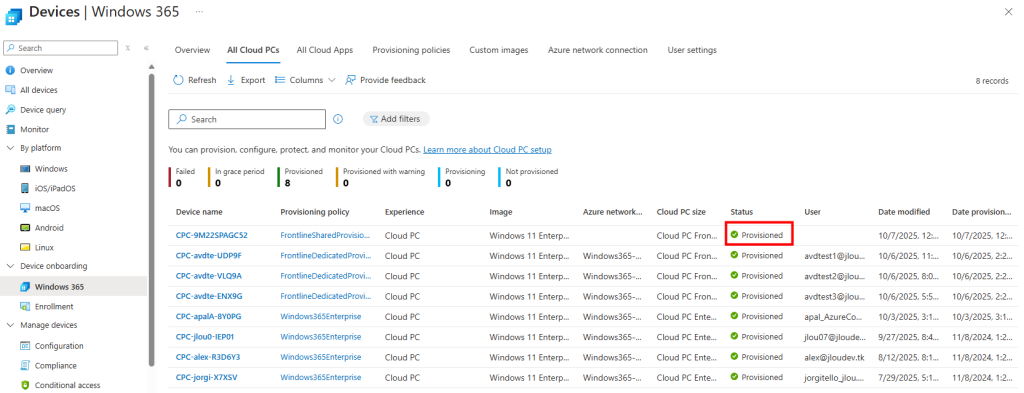
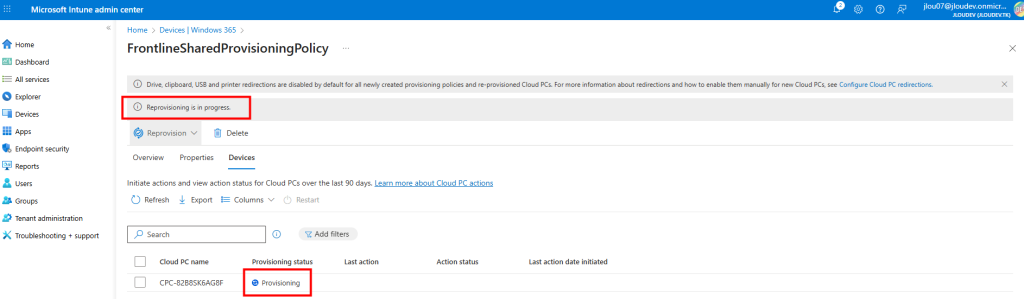
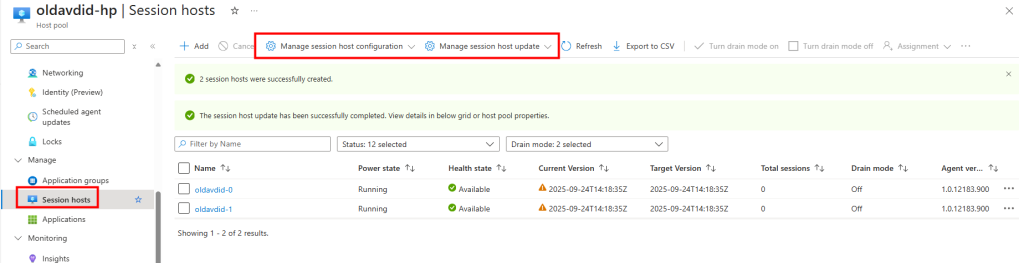
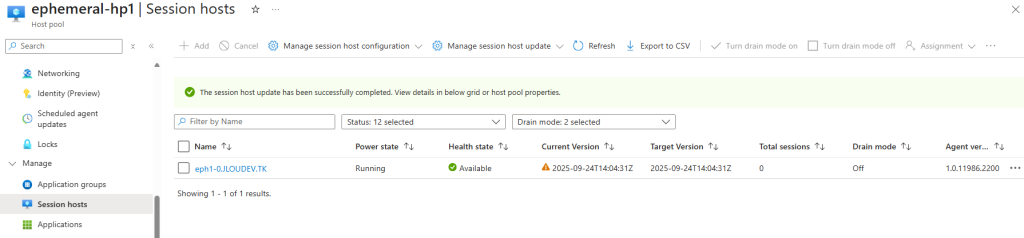
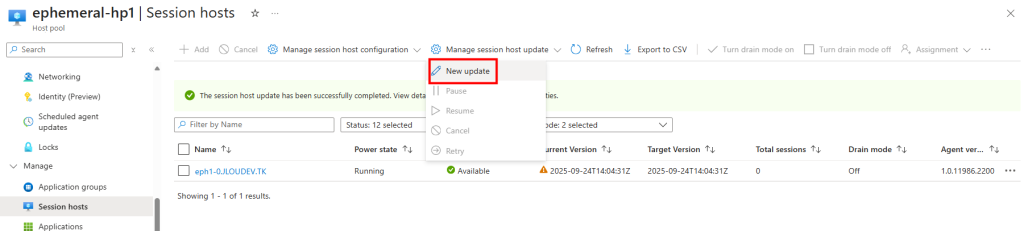
J’attends la fin de déploiement afin de constater la présence des VMs AVD comme étant disponibles :
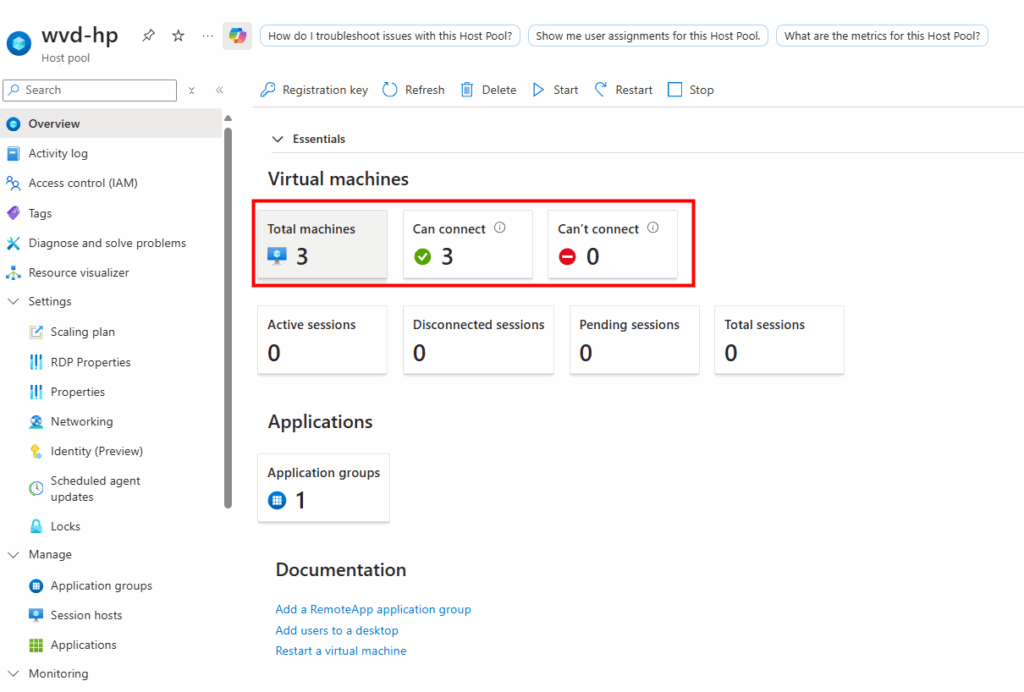
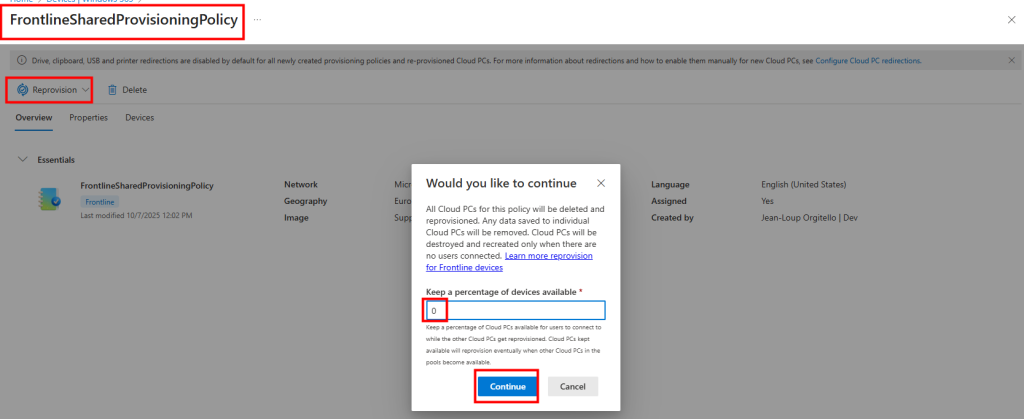
Je passe sur chacune des machines pour lancer le script suivant en local ou à distance :
<#
.SYNOPSIS
Répare la configuration BitLocker après Sysprep /generalize sur Windows 11 24H2.
Corrige le BCD EFI et réactive BitLocker proprement.
.DESCRIPTION
Ce script :
1. Affiche l’état initial BitLocker et du service BDESVC
2. Corrige les entrées BCD {current} et {memdiag}
3. Supprime la clé PreventDeviceEncryption
4. Rétablit le service BitLocker (mode Manuel)
5. Démarre BDESVC et attend qu’il soit prêt
6. Active BitLocker avec TPM (si nécessaire)
7. Attend la fin du chiffrement (max 2h)
8. Finalise avec Resume-BitLocker
#>
# --- FONCTIONS UTILITAIRES ---
function Wait-ForService {
param (
[string]$ServiceName,
[int]$TimeoutSec = 120
)
Write-Host "Attente du service $ServiceName..." -ForegroundColor Yellow
$sw = [Diagnostics.Stopwatch]::StartNew()
while ($sw.Elapsed.TotalSeconds -lt $TimeoutSec) {
$status = (Get-Service $ServiceName -ErrorAction SilentlyContinue).Status
if ($status -eq 'Running') {
Write-Host "Service $ServiceName opérationnel." -ForegroundColor Green
return
}
Start-Sleep -Seconds 3
}
Write-Host "⚠️ Le service $ServiceName n’a pas démarré après $TimeoutSec secondes." -ForegroundColor Red
}
function Wait-ForEncryption {
param (
[string]$MountPoint = "C:",
[int]$CheckIntervalSec = 15,
[int]$TimeoutSec = 7200 # 2 heures
)
Write-Host "Attente de la fin du chiffrement BitLocker sur $MountPoint (timeout $($TimeoutSec/60) min)..." -ForegroundColor Yellow
$sw = [Diagnostics.Stopwatch]::StartNew()
while ($sw.Elapsed.TotalSeconds -lt $TimeoutSec) {
$status = manage-bde -status $MountPoint | Select-String "Conversion Status"
$percent = manage-bde -status $MountPoint | Select-String "Percentage Encrypted"
$state = ($status -replace ".*:\s*", "").Trim()
$progress = ($percent -replace ".*:\s*", "").Trim()
Write-Host "État: $state | Progression: $progress"
if ($state -match "Fully Encrypted|Used Space Only Encrypted") {
Write-Host "✅ Chiffrement terminé sur $MountPoint" -ForegroundColor Green
return
}
Start-Sleep -Seconds $CheckIntervalSec
}
Write-Host "⚠️ Le chiffrement sur $MountPoint n’est pas terminé après $($TimeoutSec/60) minutes." -ForegroundColor Red
Write-Host "Le script continue, mais vérifie manuellement l’état avec 'manage-bde -status $MountPoint'." -ForegroundColor Yellow
}
# --- DÉBUT DU SCRIPT ---
Write-Host "=== Vérification initiale ===" -ForegroundColor Cyan
Get-Service BDESVC
manage-bde -status
Write-Host ""
Start-Sleep -Seconds 3
# --- Vérifie le BCD avant correction
Write-Host "=== BCD avant correction ===" -ForegroundColor Yellow
cmd /c "bcdedit /enum"
Write-Host ""
Start-Sleep -Seconds 2
# --- Corrige les entrées BCD
Write-Host "=== Correction BCD ===" -ForegroundColor Cyan
cmd /c "bcdedit /set {current} osdevice partition=C:"
cmd /c "bcdedit /set {current} device partition=C:"
cmd /c "bcdedit /set {memdiag} device partition=\Device\HarddiskVolume3"
Write-Host "BCD corrigé."
Start-Sleep -Seconds 2
# --- Vérifie le BCD après correction
Write-Host "=== BCD après correction ===" -ForegroundColor Green
cmd /c "bcdedit /enum"
Start-Sleep -Seconds 2
# --- Supprime PreventDeviceEncryption
Write-Host "=== Suppression clé PreventDeviceEncryption ===" -ForegroundColor Cyan
reg delete "HKLM\SYSTEM\CurrentControlSet\Control\BitLocker" /v PreventDeviceEncryption /f | Out-Null
Write-Host "Clé supprimée (si existante)."
Start-Sleep -Seconds 2
# --- Réactive BDESVC
Write-Host "=== Réactivation du service BitLocker ===" -ForegroundColor Cyan
Set-Service -Name BDESVC -StartupType Manual
Start-Service -Name BDESVC
Wait-ForService -ServiceName "BDESVC"
Write-Host ""
# --- Vérifie l’état avant chiffrement
Write-Host "=== État avant chiffrement ===" -ForegroundColor Yellow
Get-Service BDESVC
manage-bde -status
Start-Sleep -Seconds 2
# --- Active BitLocker avec TPM si nécessaire
Write-Host "=== Activation BitLocker (TPM) ===" -ForegroundColor Cyan
$bitlockerStatus = (manage-bde -status C: | Select-String "Conversion Status").ToString()
if ($bitlockerStatus -match "Encryption in Progress|Fully Encrypted|Used Space Only Encrypted") {
Write-Host "ℹ️ BitLocker est déjà actif ou en cours de chiffrement sur C:. Aucune réactivation nécessaire." -ForegroundColor Yellow
} else {
try {
Enable-BitLocker -MountPoint "C:" -TpmProtector -UsedSpaceOnly -ErrorAction Stop
Write-Host "BitLocker initialisé." -ForegroundColor Green
} catch {
Write-Host "⚠️ Impossible d’ajouter un protecteur TPM (probablement déjà présent) : $($_.Exception.Message)" -ForegroundColor Red
}
}
Write-Host "Vérification du statut..."
Wait-ForEncryption -MountPoint "C:" -TimeoutSec 7200
Write-Host ""
# --- Finalisation
Write-Host "=== Activation finale (Resume-BitLocker) ===" -ForegroundColor Cyan
Resume-BitLocker -MountPoint "C:"
Wait-ForEncryption -MountPoint "C:" -TimeoutSec 7200
Write-Host "BitLocker réactivé avec succès." -ForegroundColor Green
Write-Host ""
# --- Vérification finale
Write-Host "=== Vérification finale ===" -ForegroundColor Green
Get-Service BDESVC
manage-bde -status
Write-Host "=== FIN DU SCRIPT ===" -ForegroundColor Cyan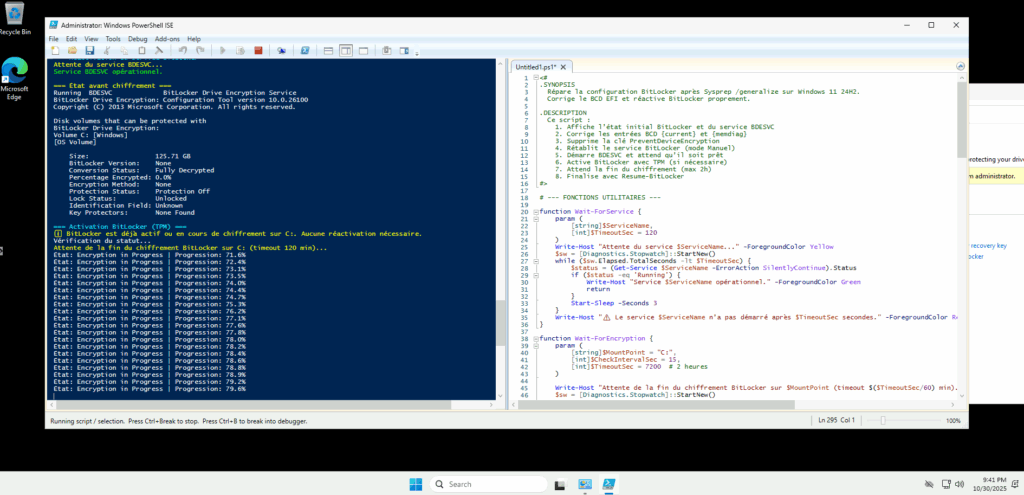
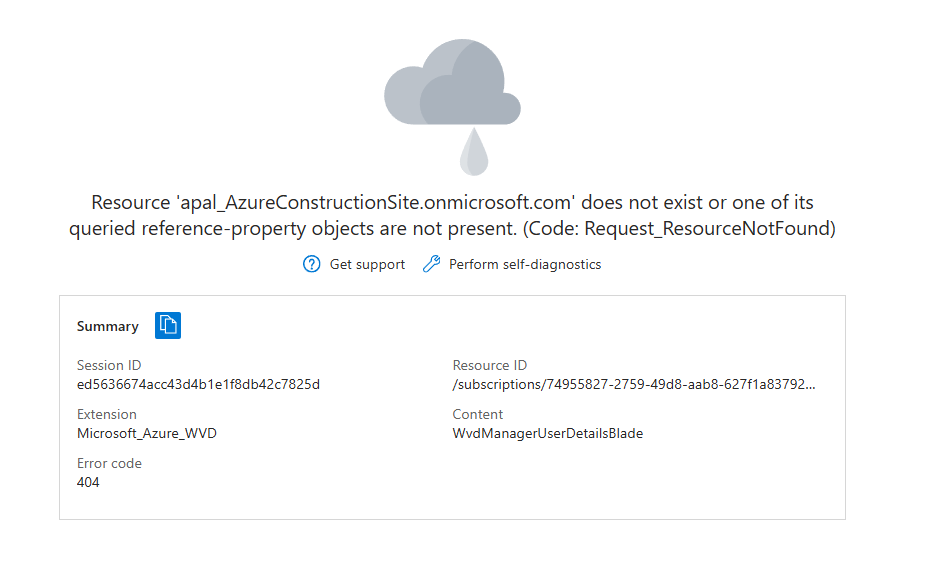
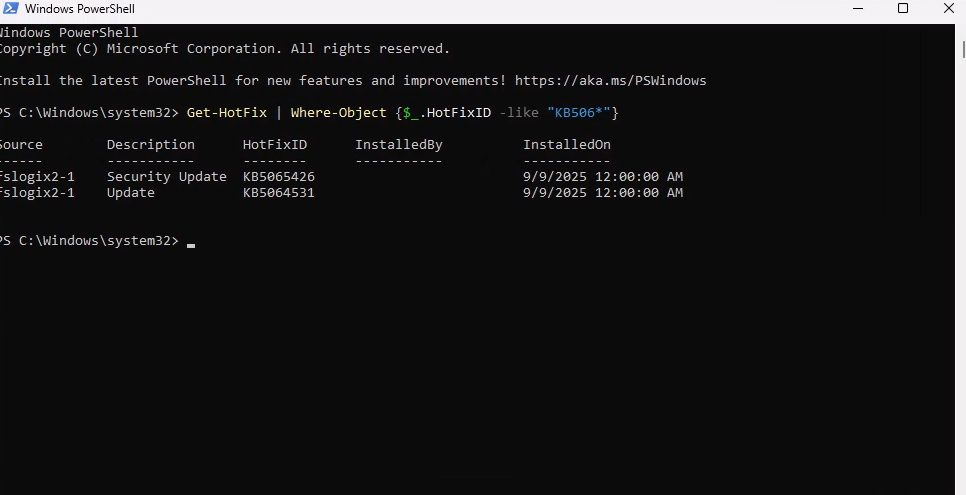
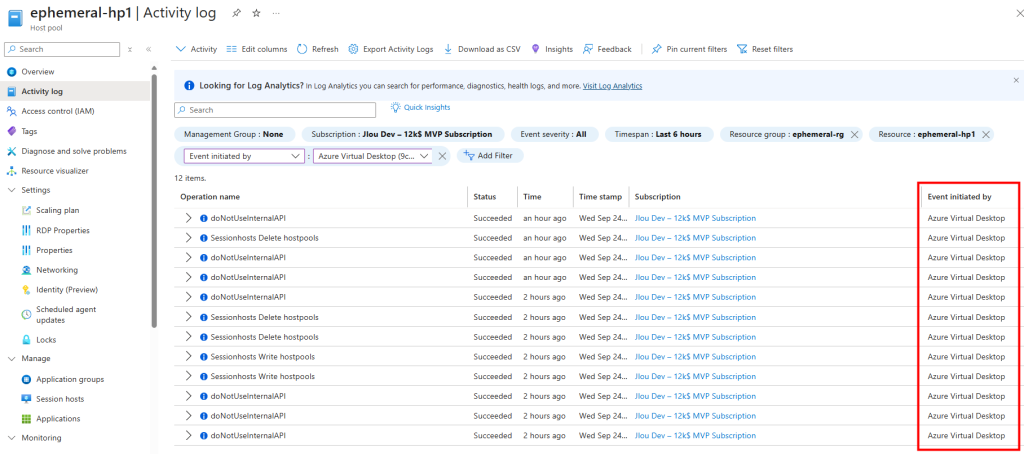
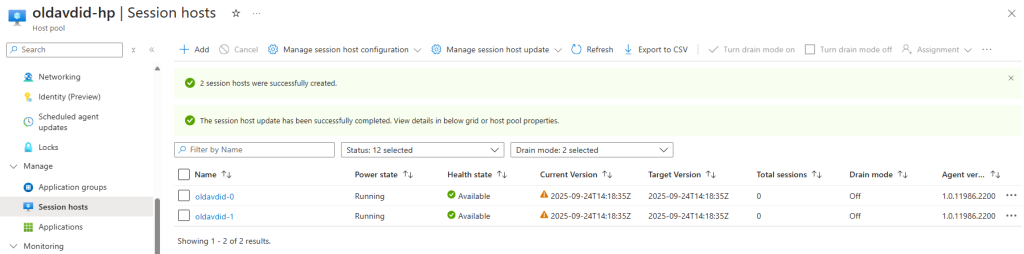
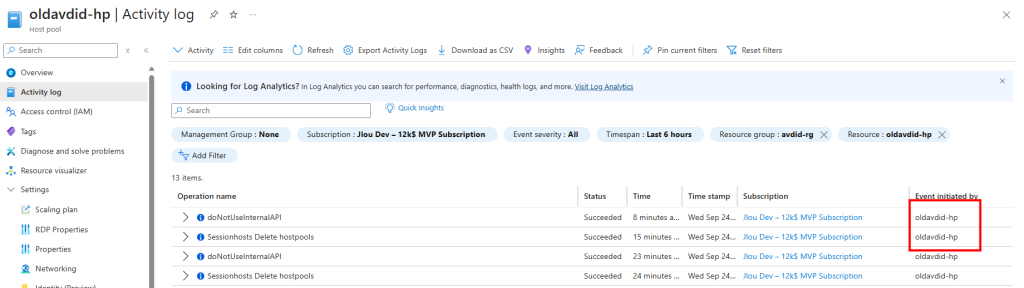
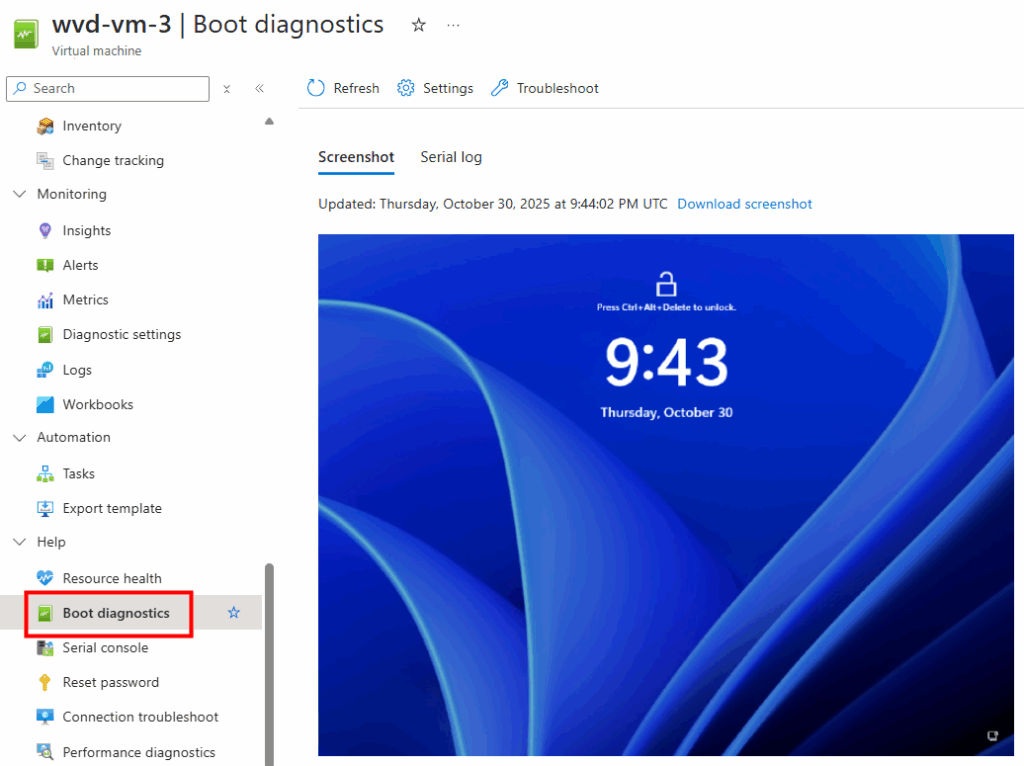
Je redémarre la machine AVD pour vérifier son statut dans les journaux de diagnostic Azure :
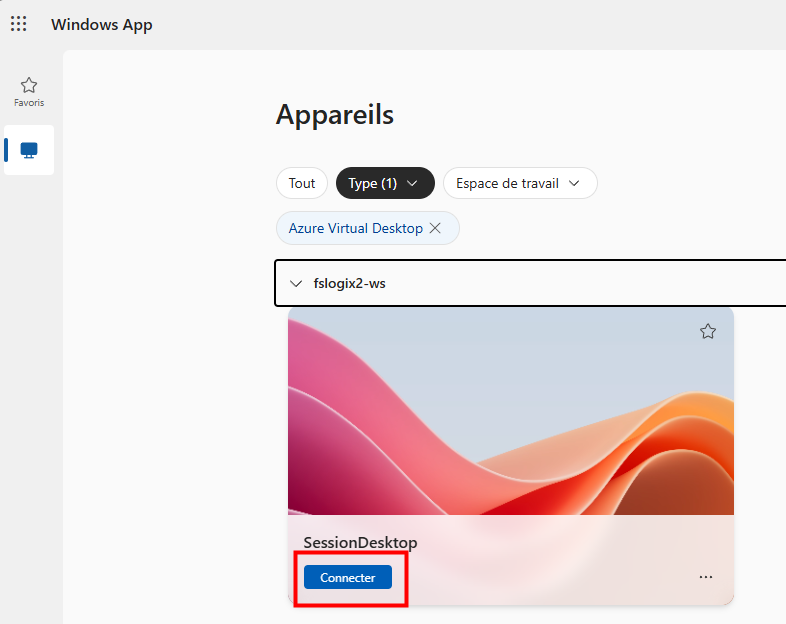
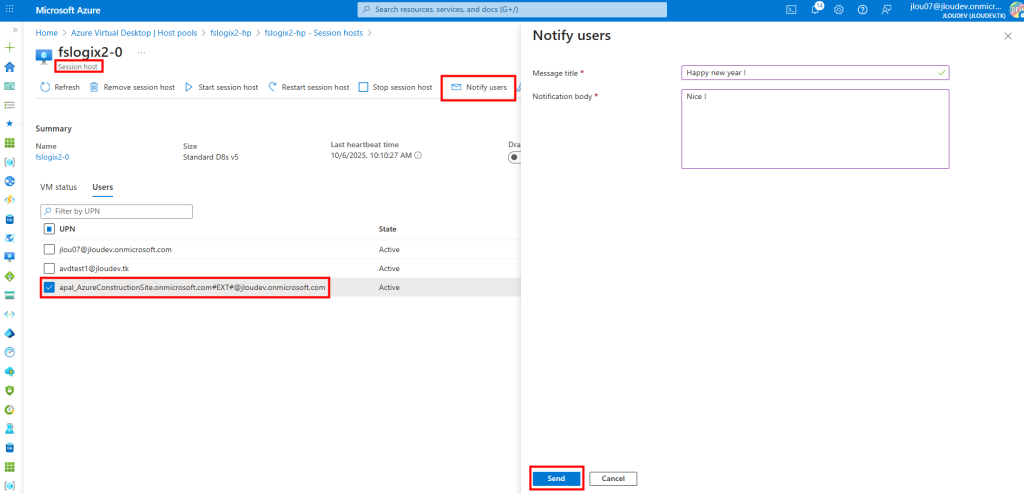
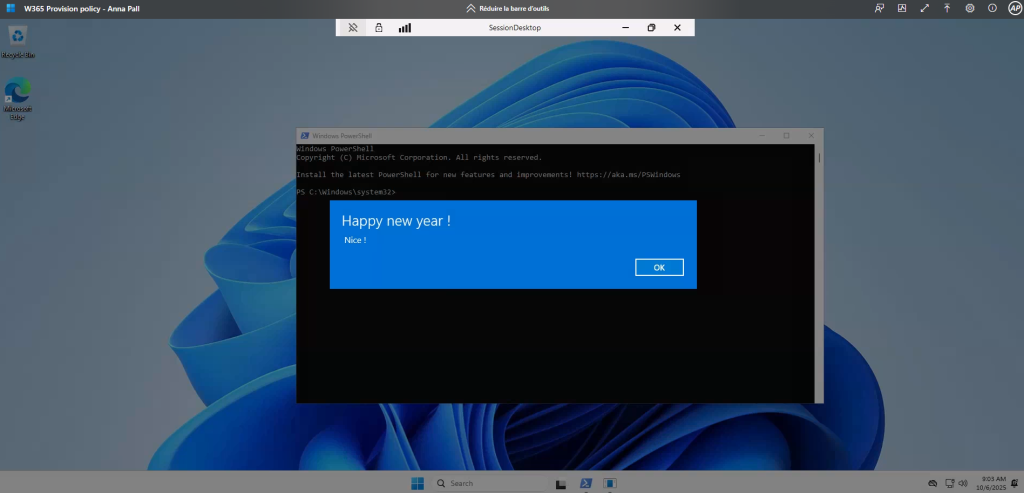
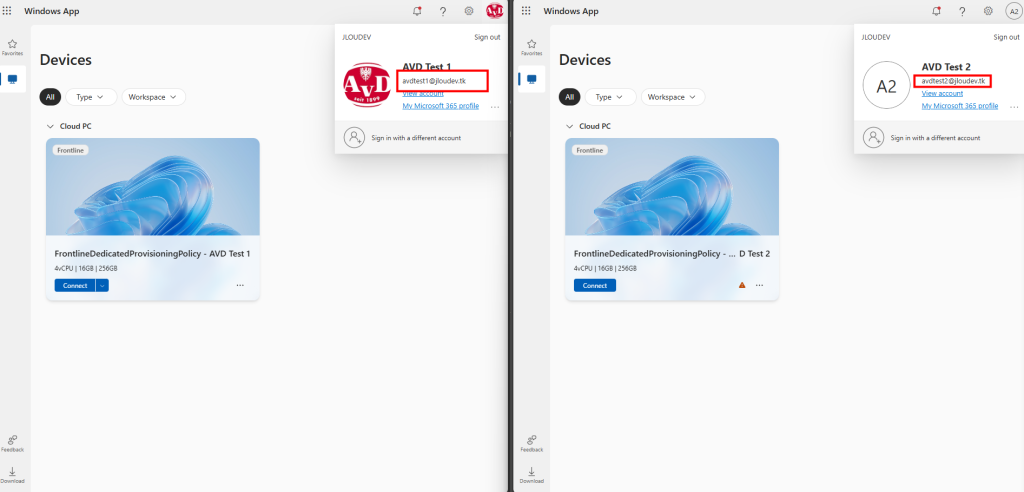
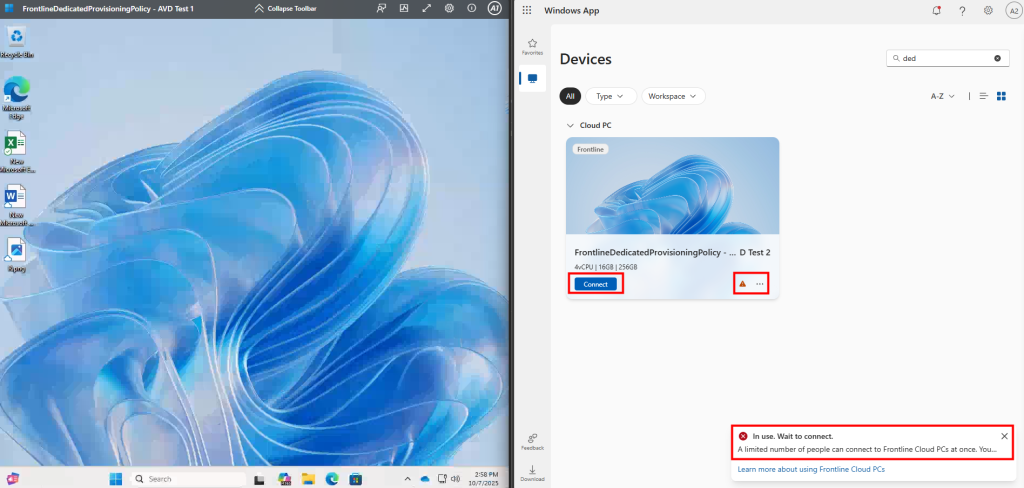
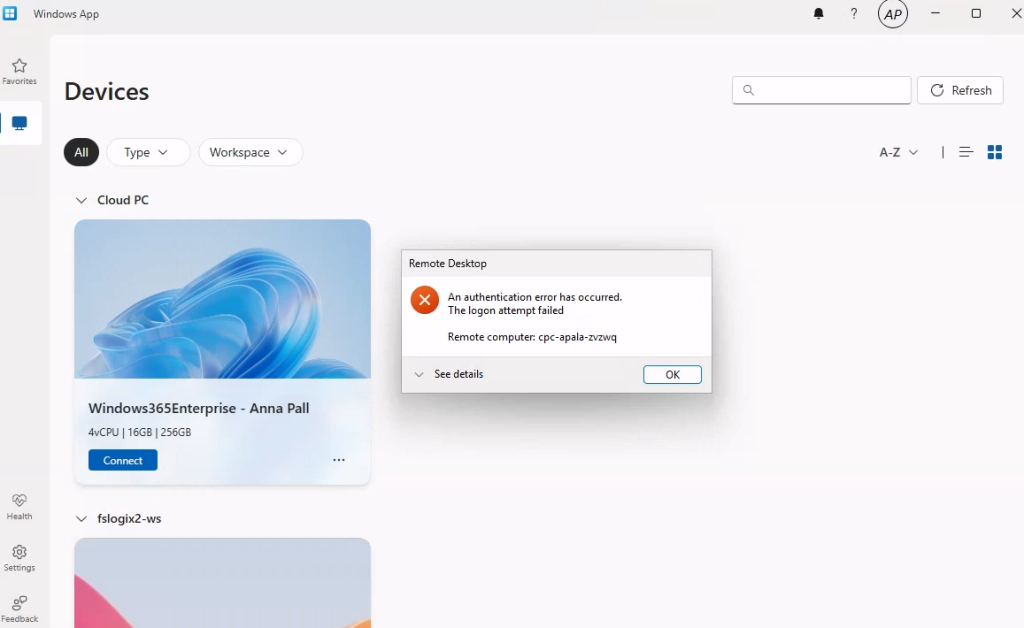
Je teste également la connexion Azure Virtual Desktop avec un utilisateur :
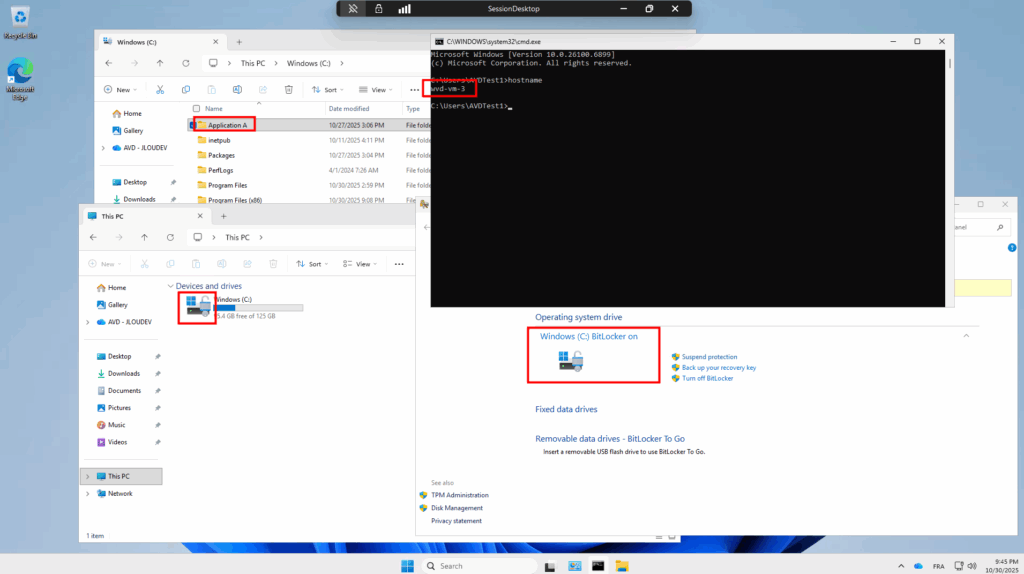
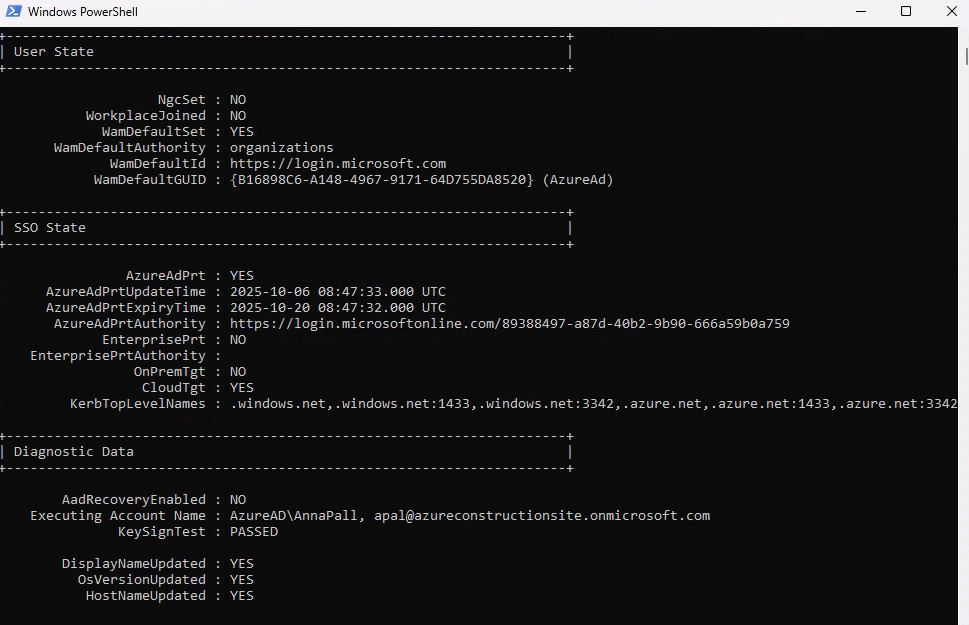
Enfin, comme mon environnement est liée à Entra ID, je constate également la remontée automatqiue de ma clef de secours BitLocker dans Entra ID :
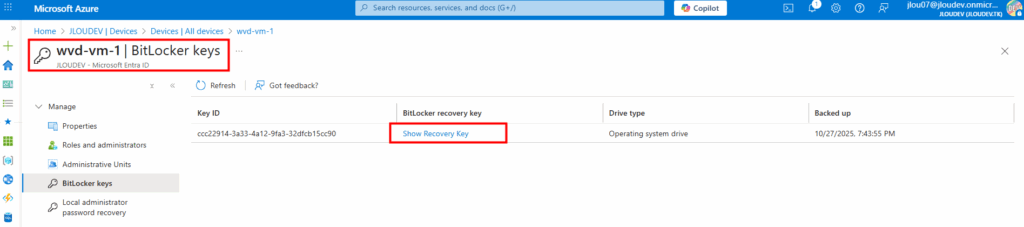
Conclusion
Cette expérience montre bien qu’une mise à jour in-place d’une image Windows 10/11 dans Azure n’est jamais anodine.
Entre la gestion du chiffrement BitLocker, les effets secondaires du Sysprep et les métadonnées Azure qui ne se mettent pas toujours à jour correctement, le risque d’image inutilisable est bien réel.
Le bon réflexe reste donc de désactiver BitLocker avant le Sysprep, de corriger la configuration BCD, puis de réactiver proprement la protection une fois la VM redéployée.
Cette approche garantit un chiffrement fonctionnel sans compromettre la capture ni le déploiement de l’image.
Mais il existe aujourd’hui une alternative plus élégante et performante : Encryption at Host.
Cette fonctionnalité permet de chiffrer les disques directement au niveau de l’hôte Azure, sans impliquer le service BitLocker à l’intérieur de la VM.
Résultat :
- Moins de charge CPU côté invité,
- Pas de dépendance au TPM virtuel,
- Et une gestion centralisée du chiffrement dans Azure, plus simple à auditer et à maintenir.
C’est cette approche, à la fois plus moderne et plus légère, que nous verrons dans le prochain article.
On parlera en détail de la mise en œuvre d’Encryption at Host, de son impact sur les performances et des bonnes pratiques pour combiner sécurité et efficacité énergétique dans vos environnements AVD.