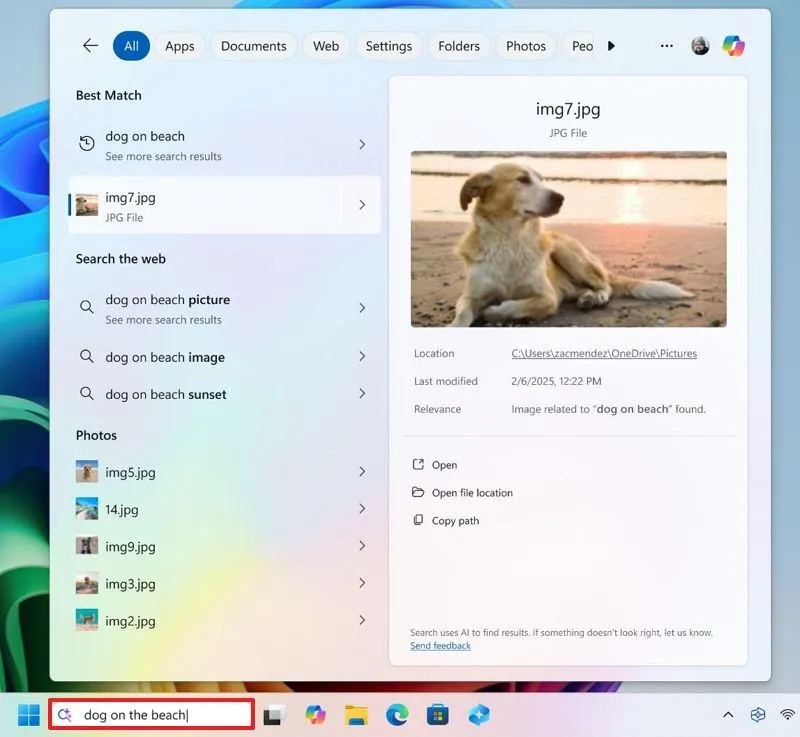
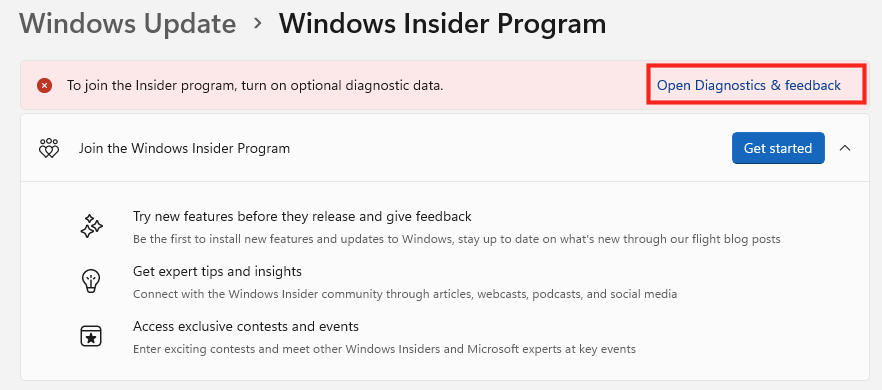
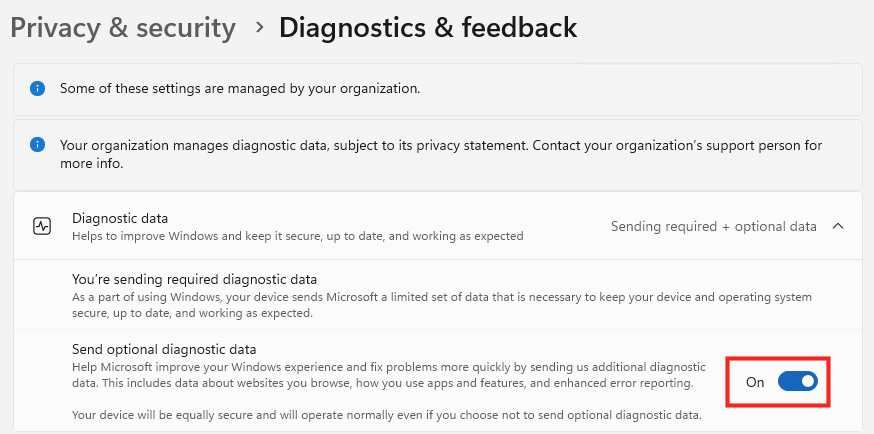
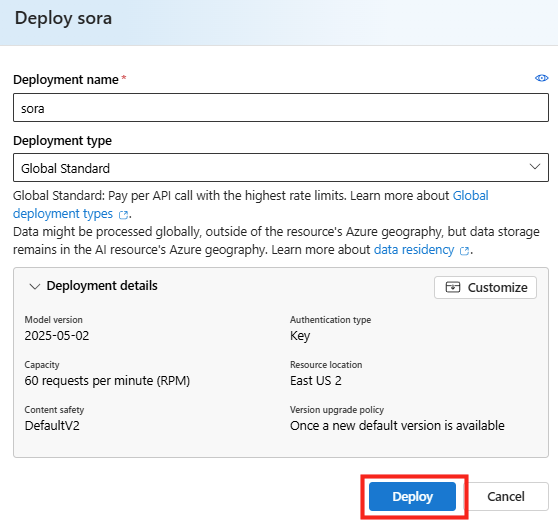
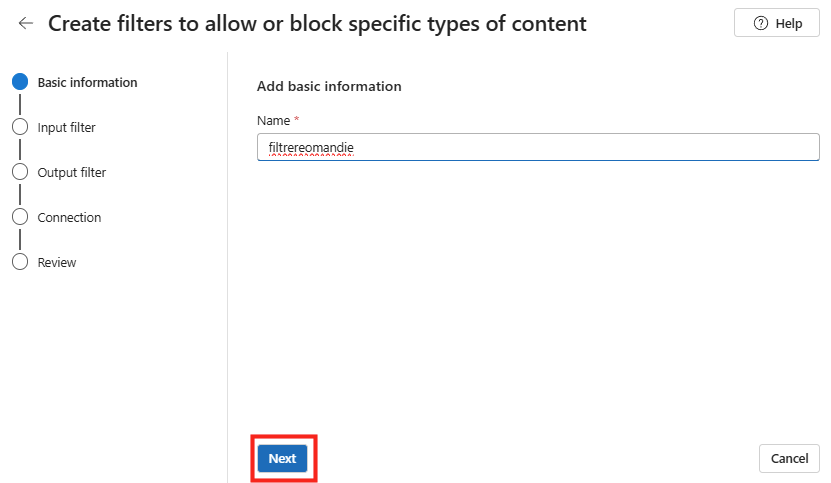
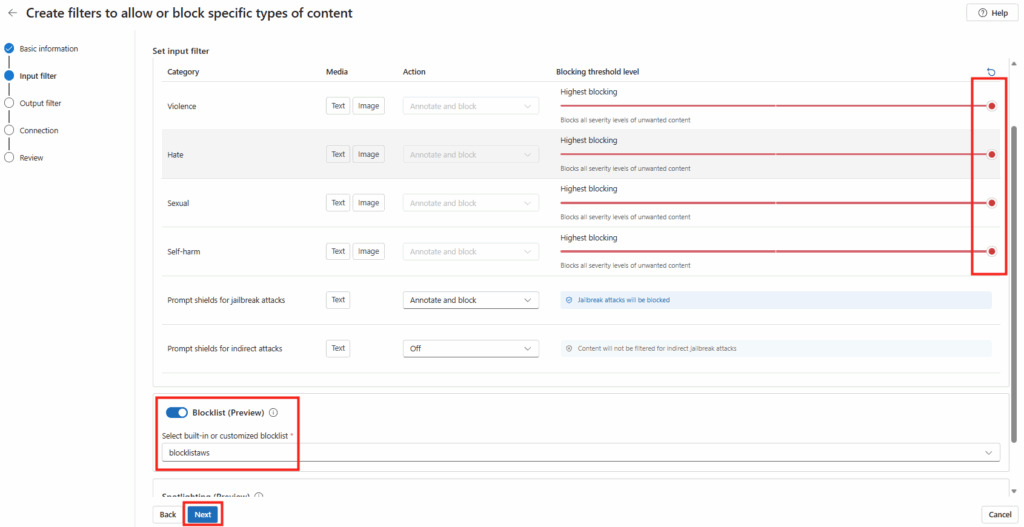
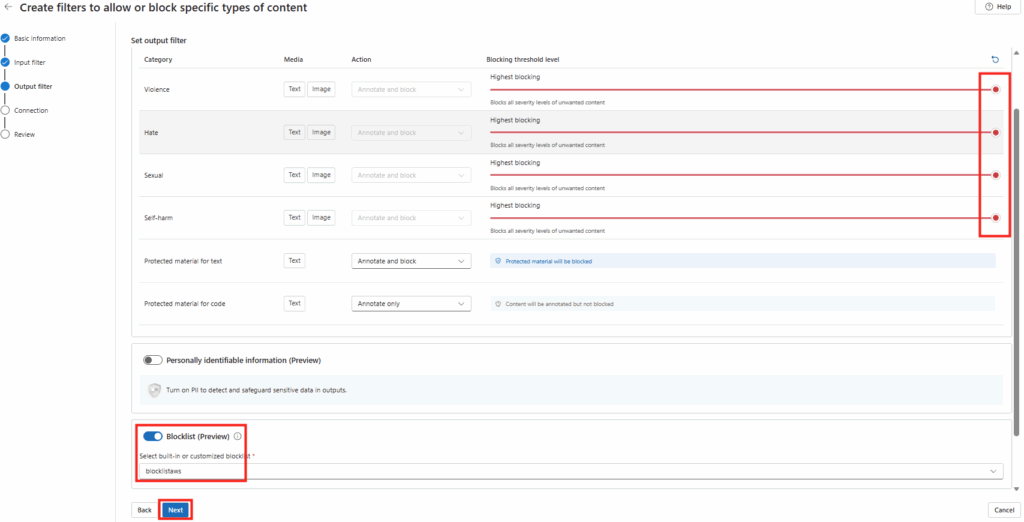
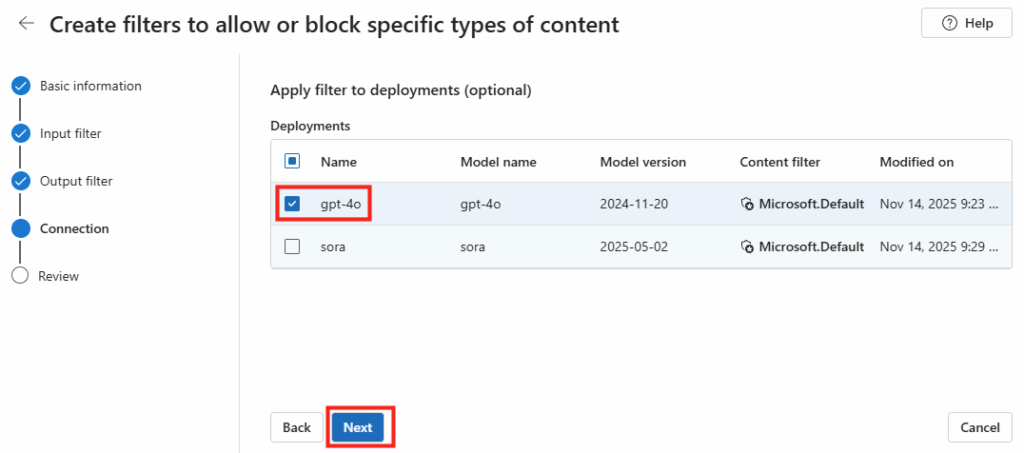
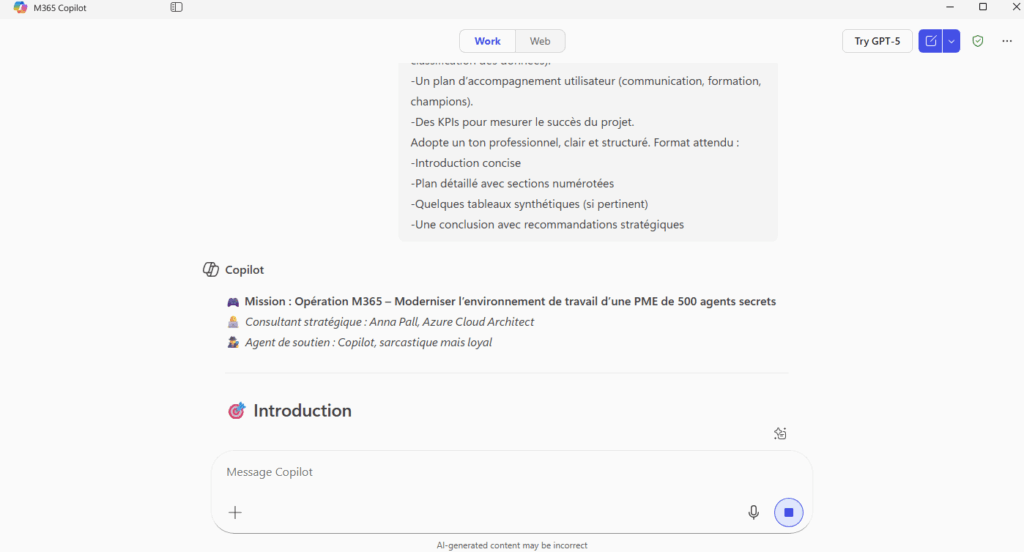
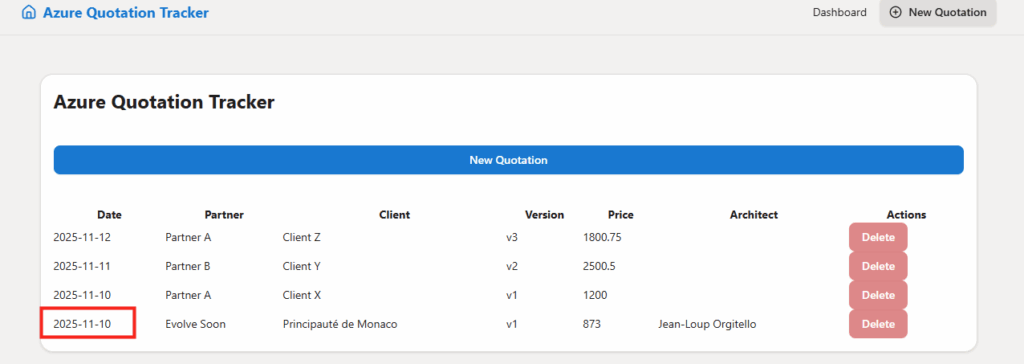
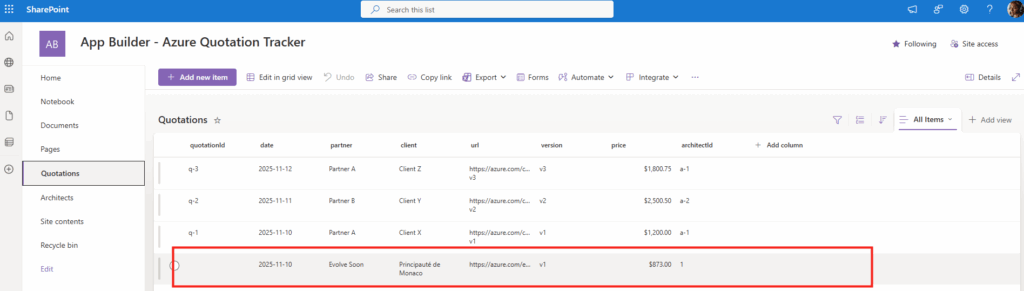
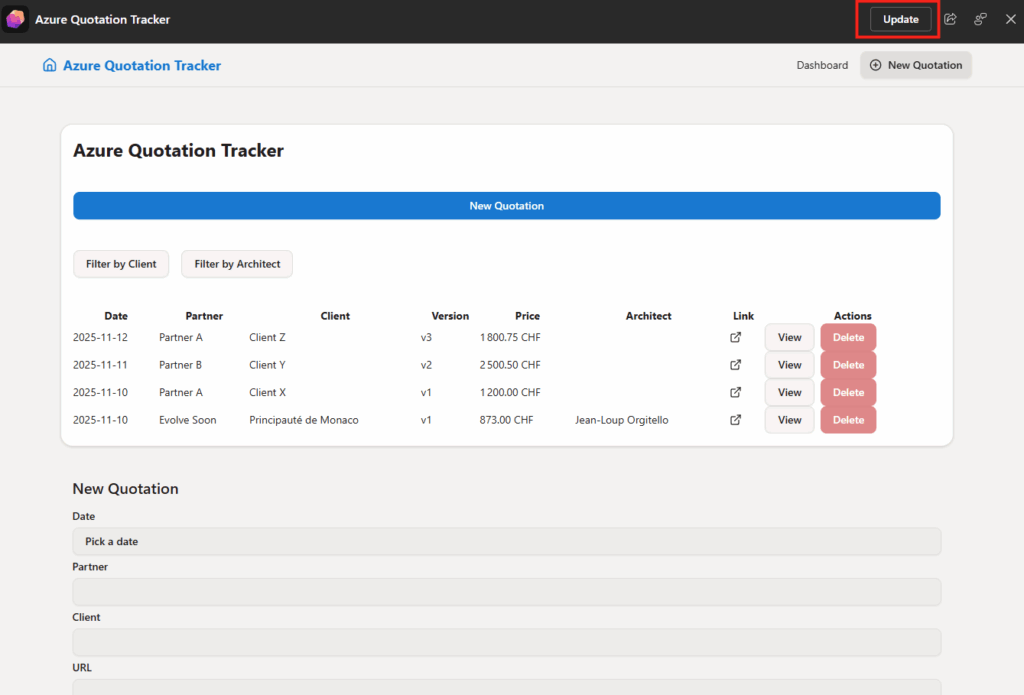
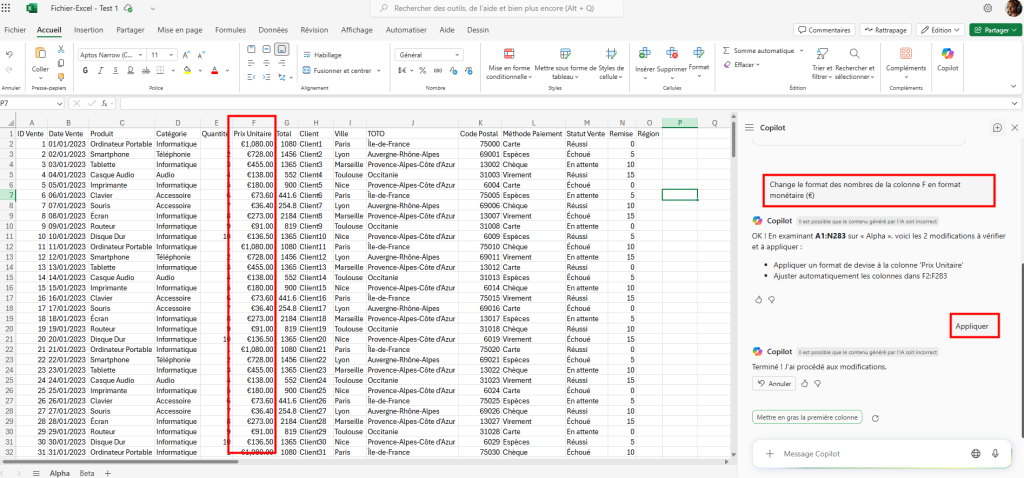
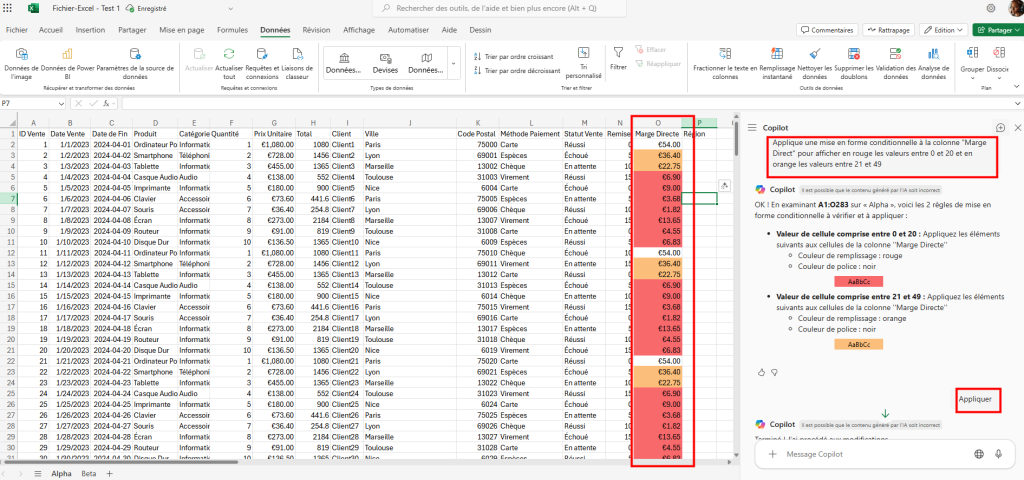
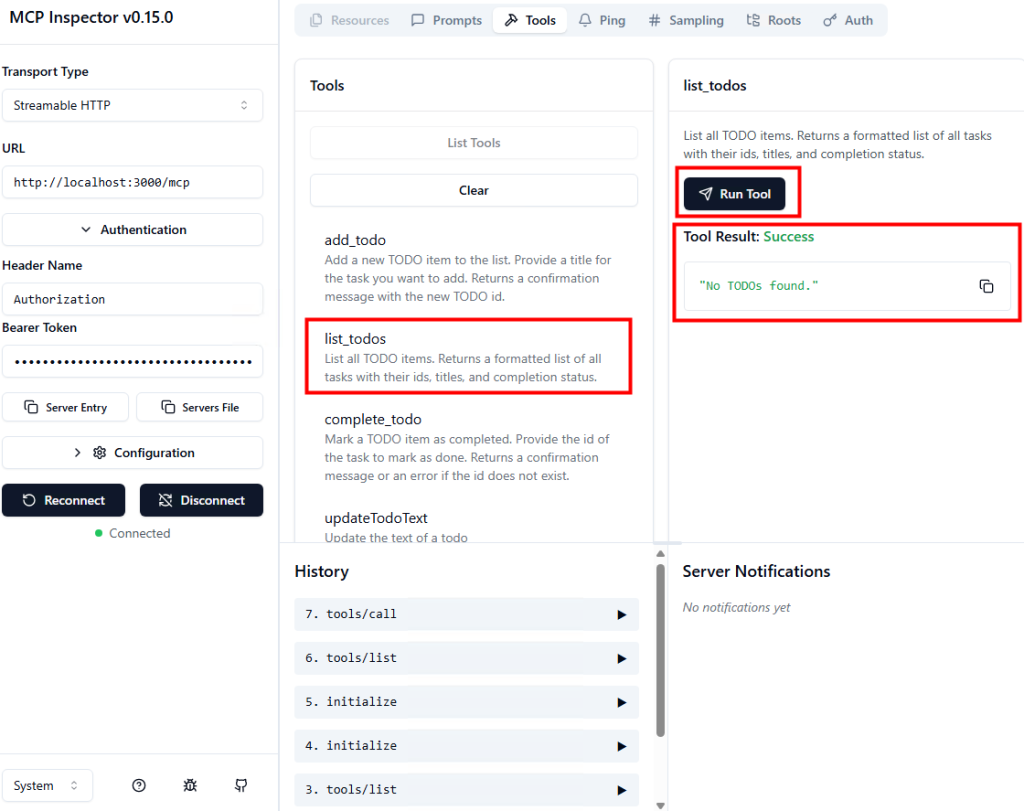
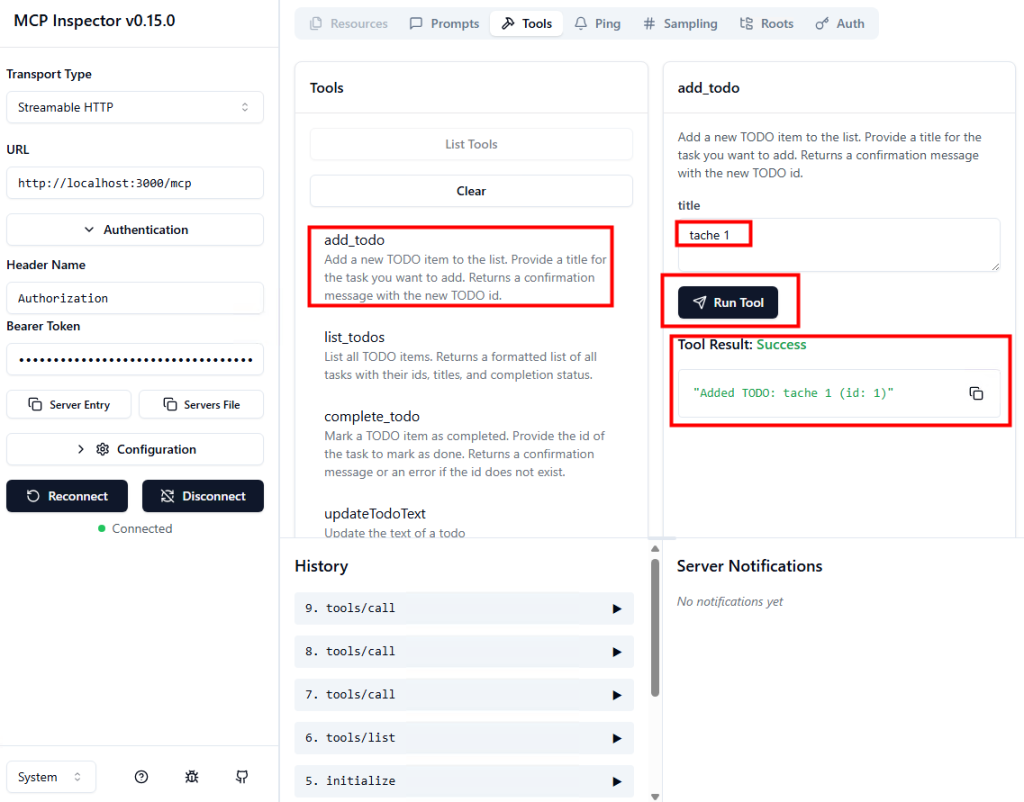
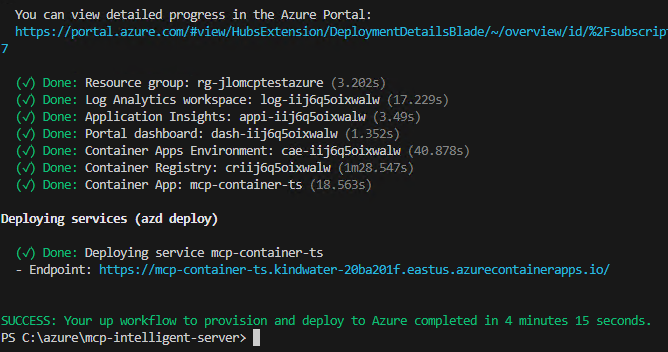
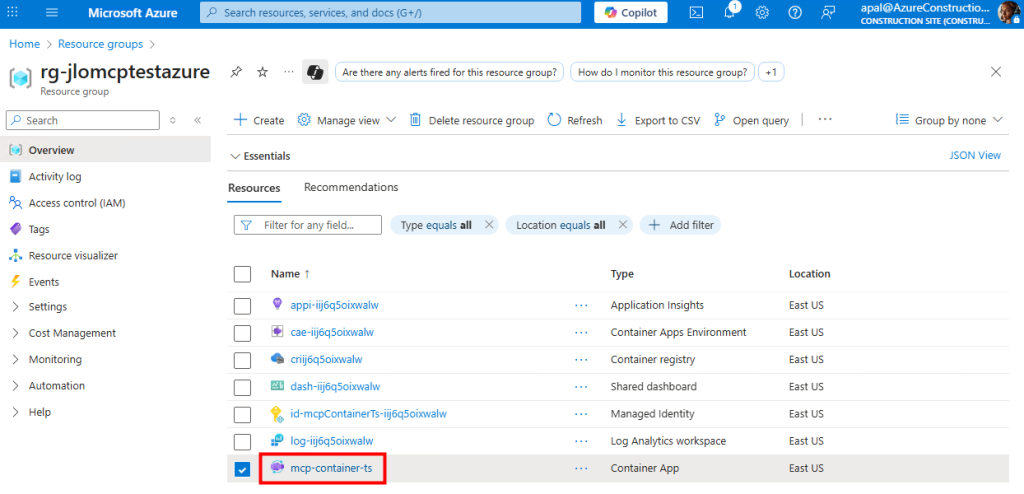
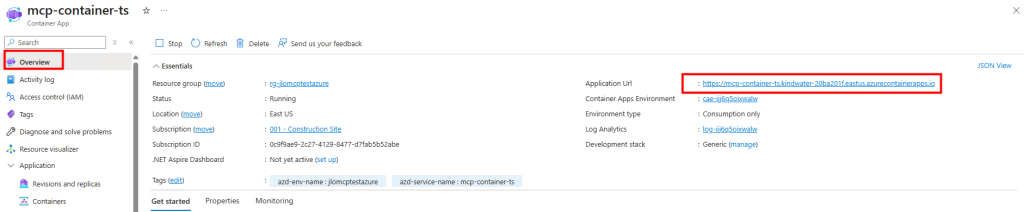
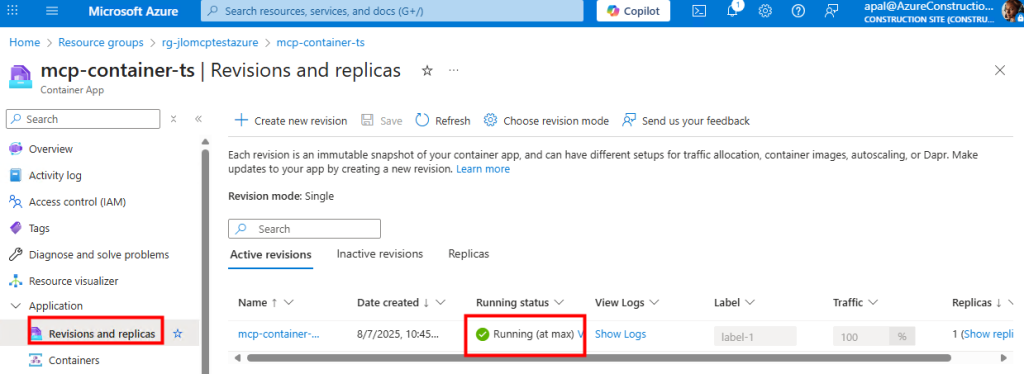
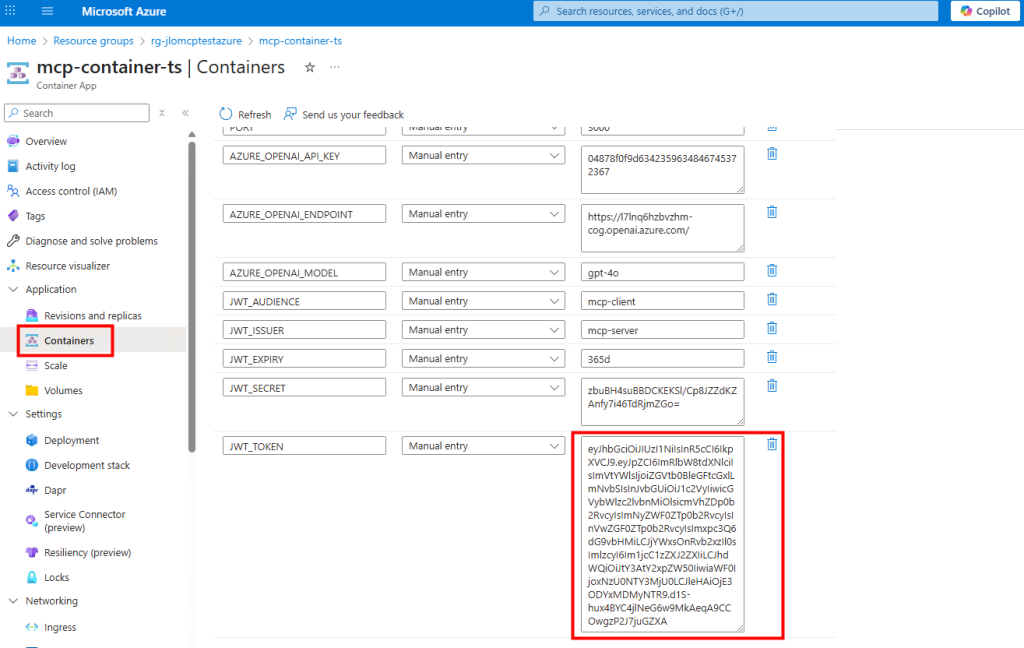
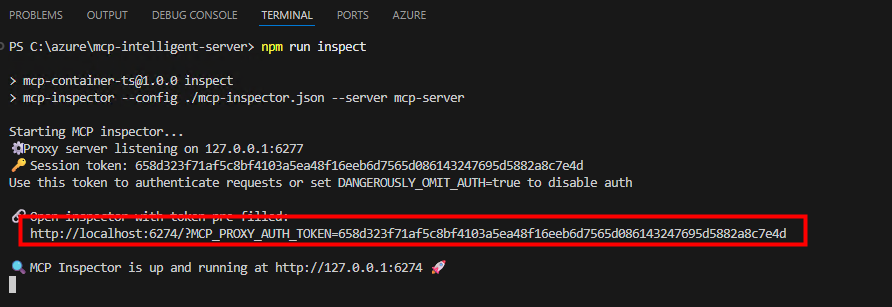
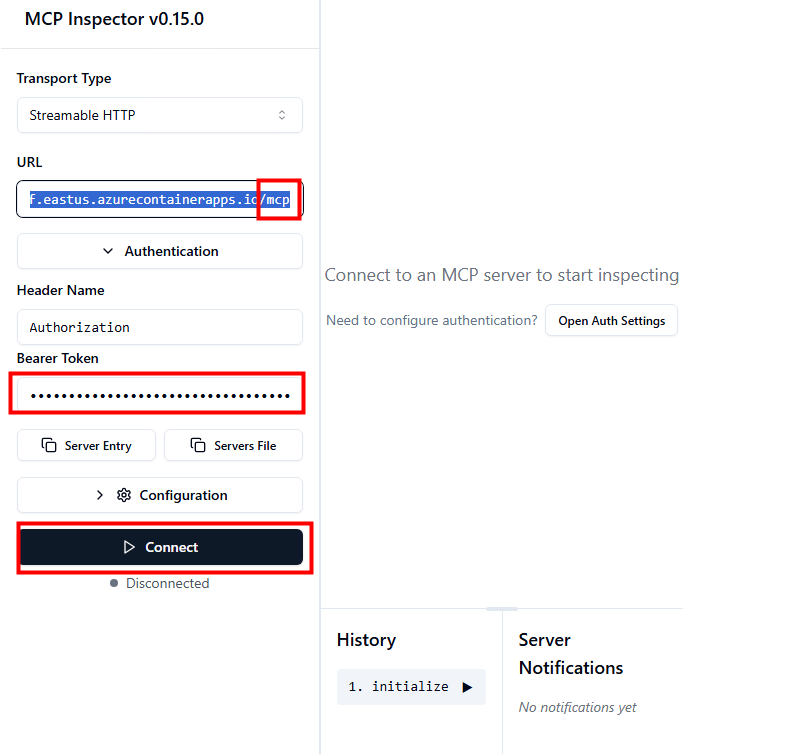
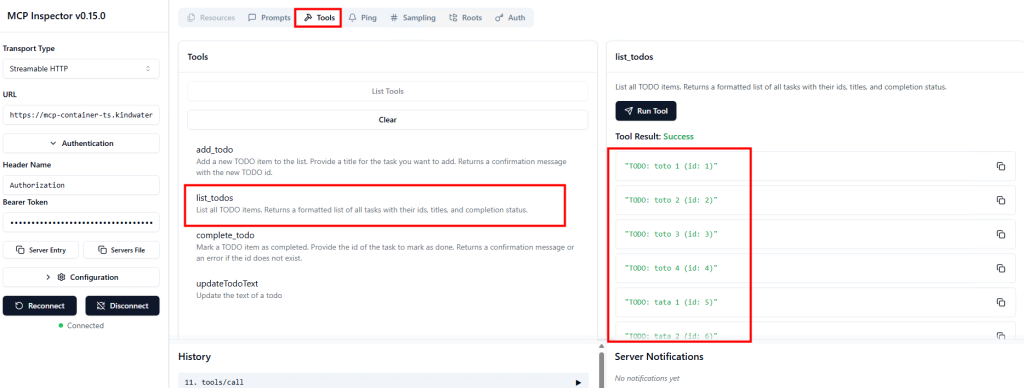
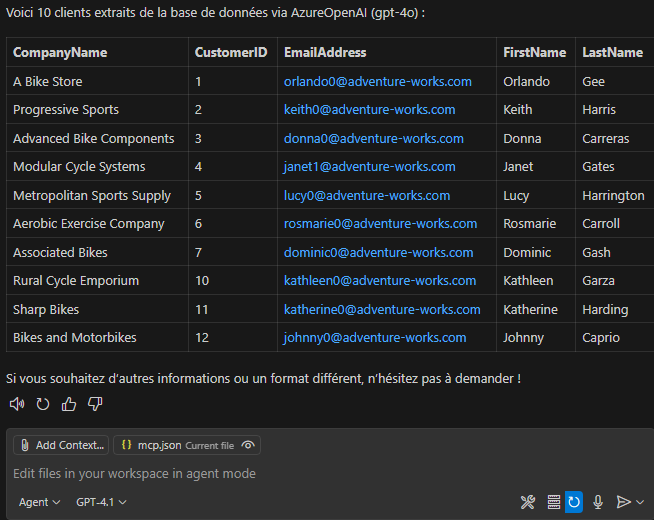
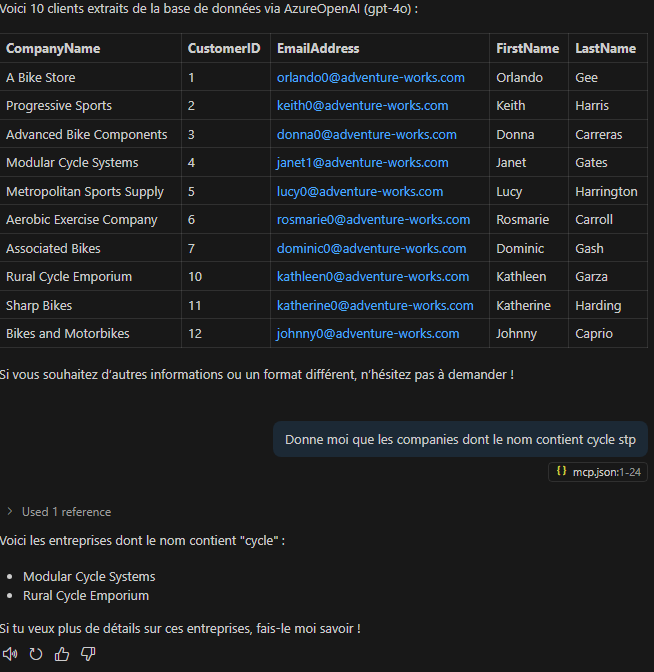
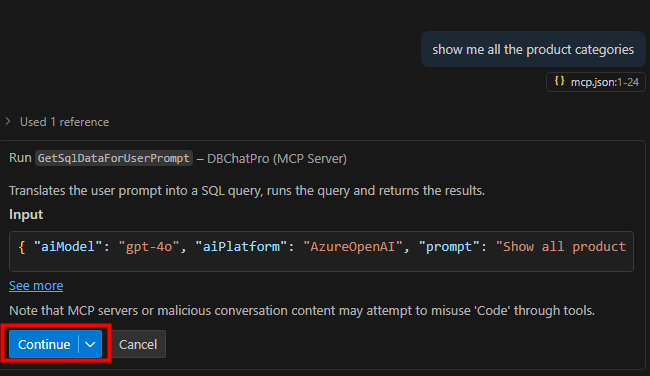
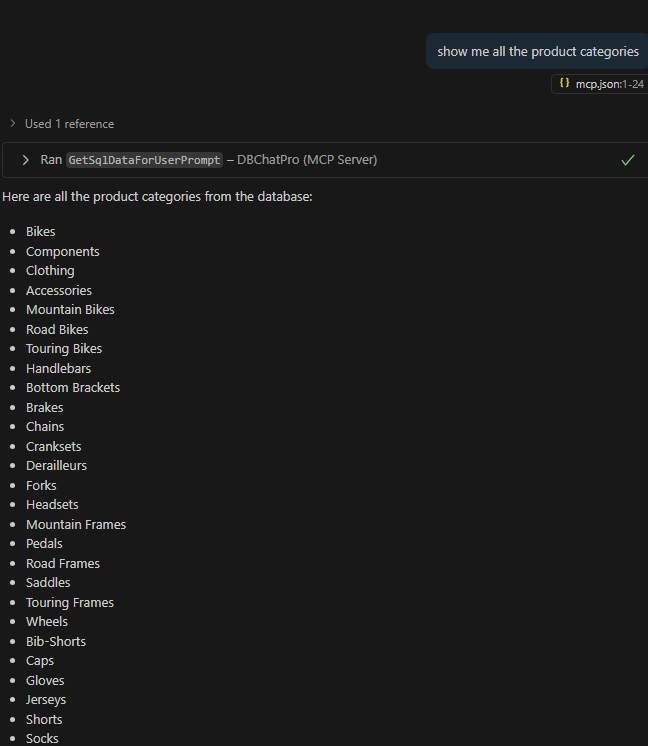
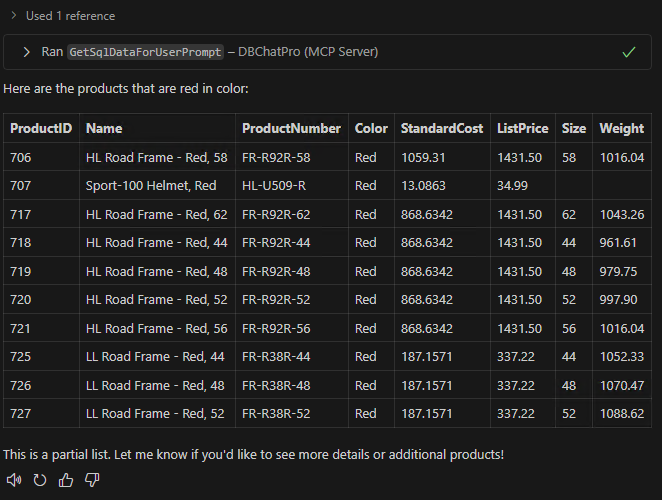
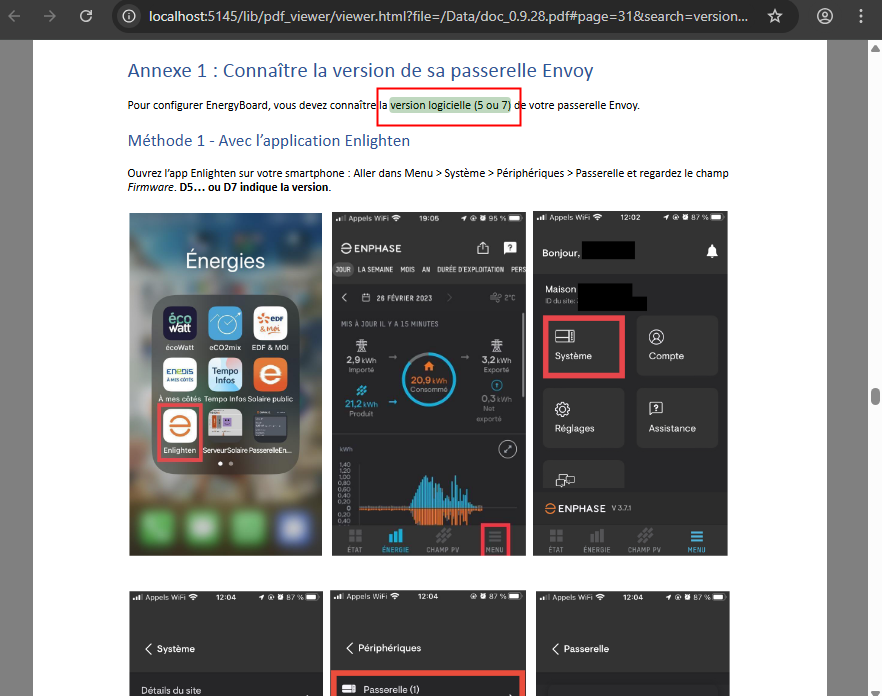
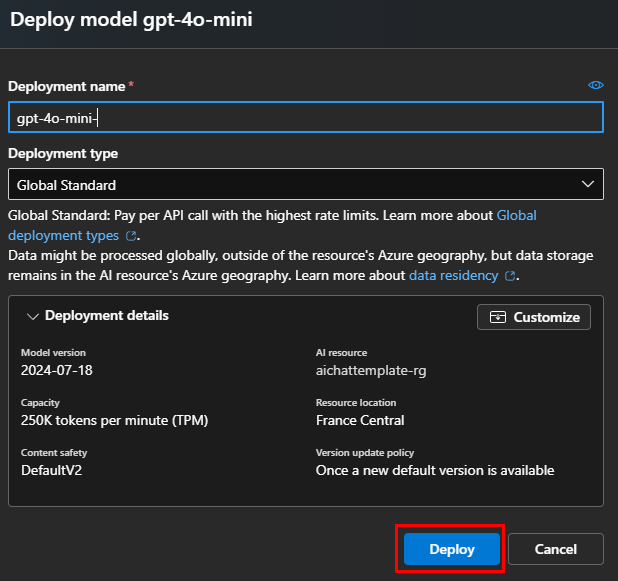
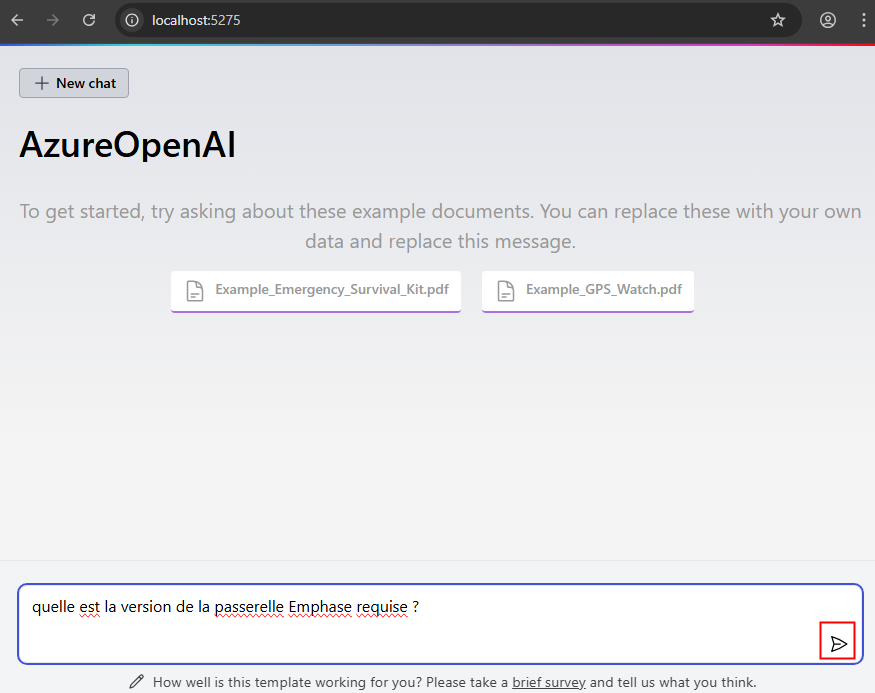
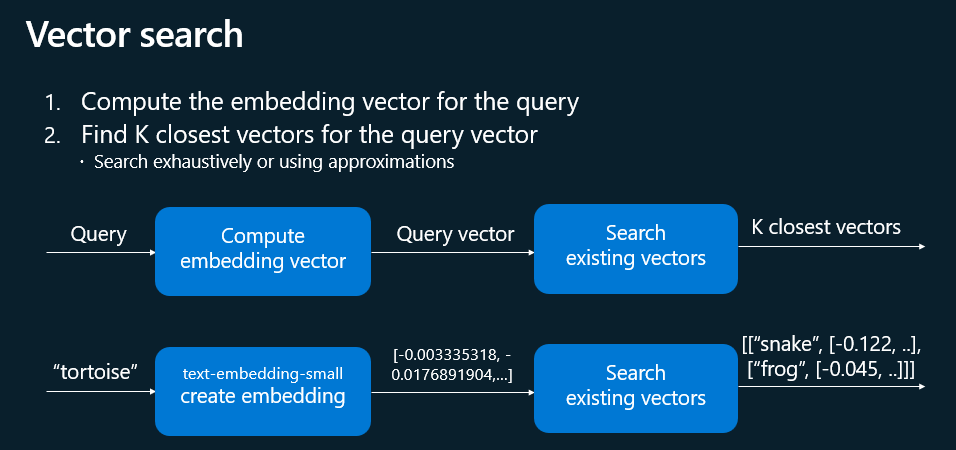
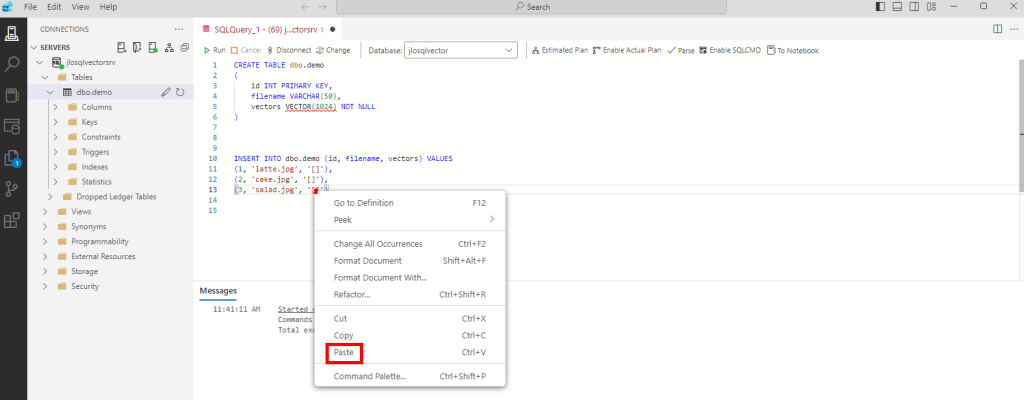
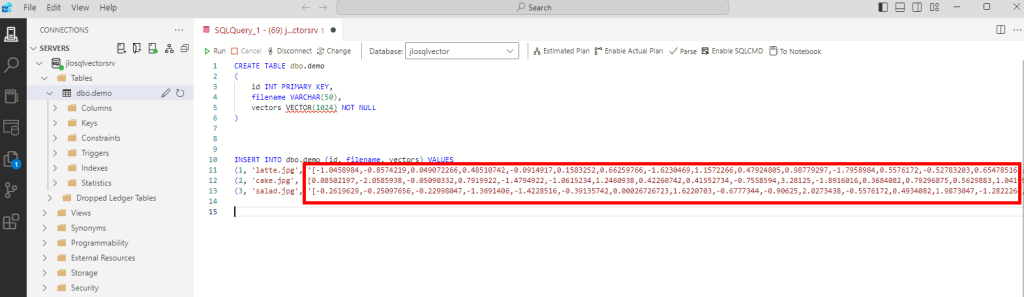
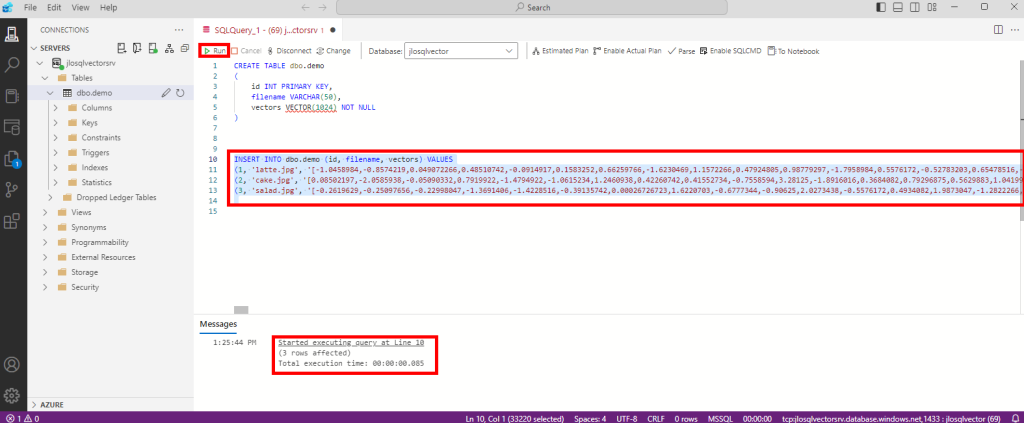
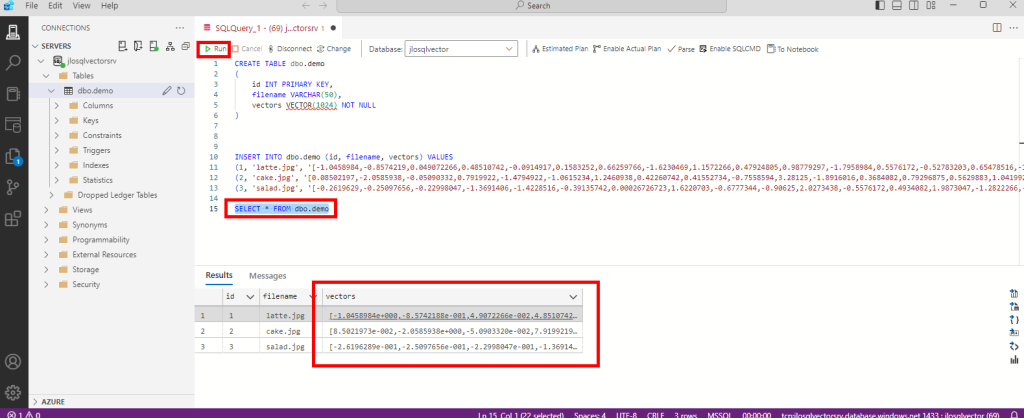
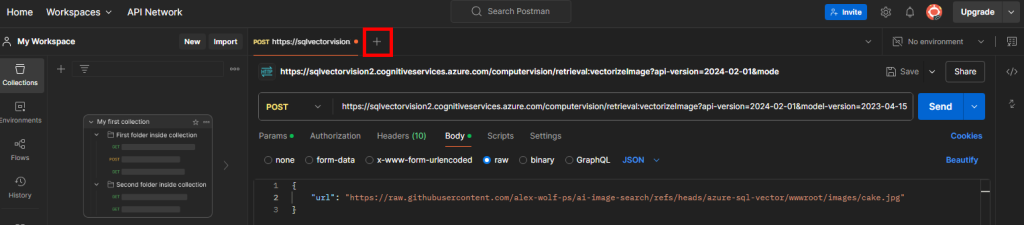
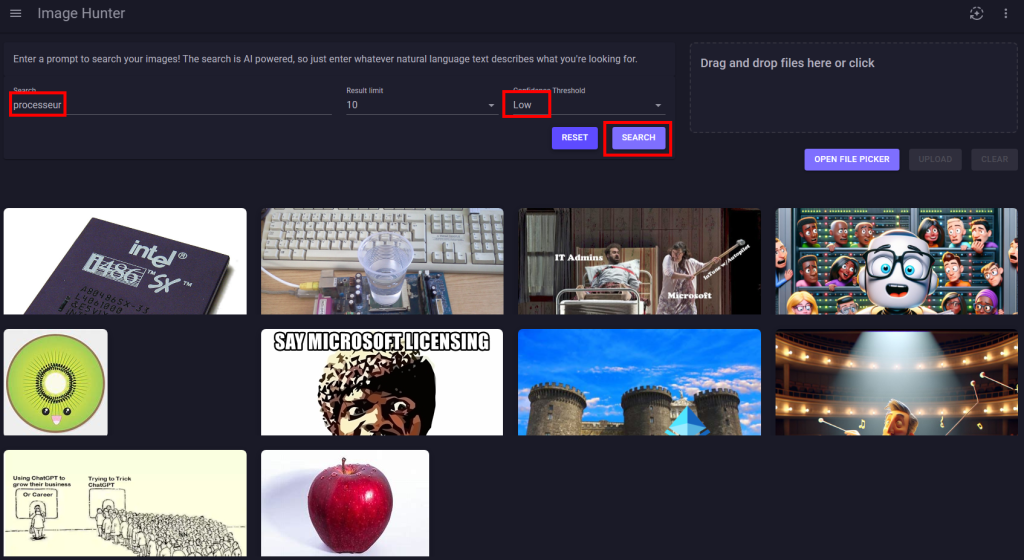
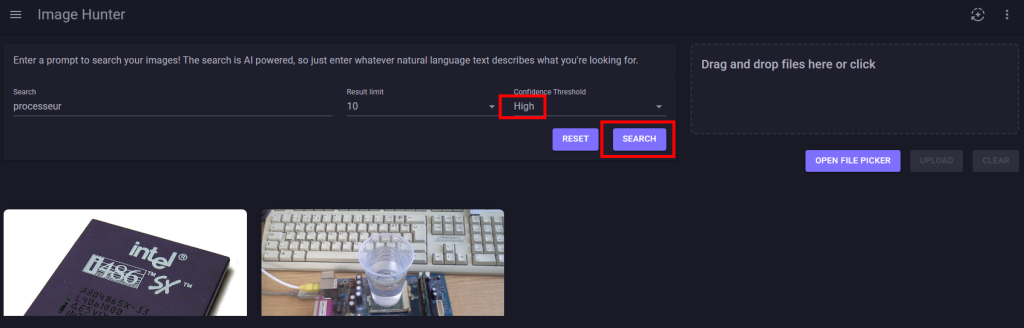
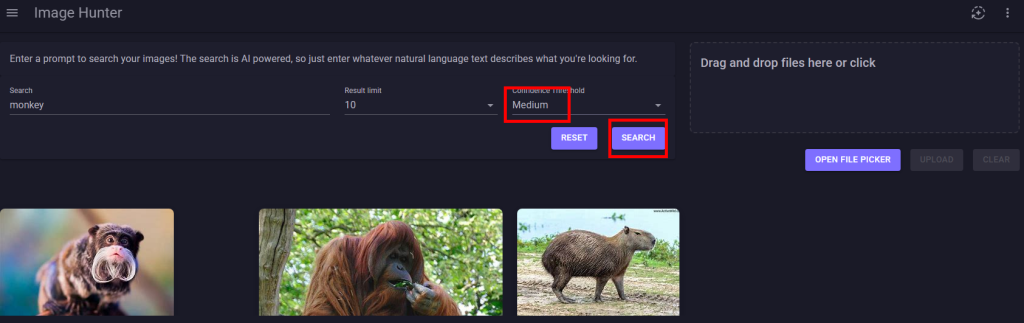
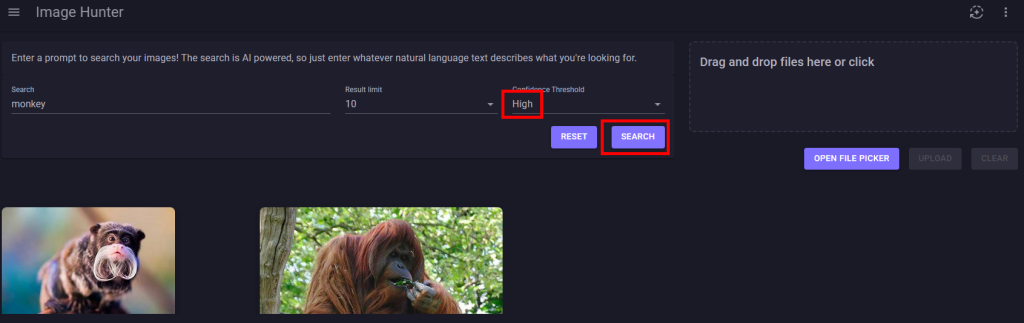
Ces derniers mois, on parle beaucoup d’agents IA, d’automatisation et de “copilots capables d’agir”. Mais dans la réalité du terrain, dès qu’un processus sort des APIs bien propres et documentées, tout s’arrête très vite. Formulaires web sans connecteurs, portails fournisseurs legacy, applications internes sans automatisation possible… C’est exactement là que, jusqu’à présent, l’IA savait quoi faire… mais ne pouvait rien exécuter. C’est précisément ce fossé entre “savoir quoi faire” et “pouvoir le faire” qu’Opal vient combler.

Avec Opal, Microsoft franchit un cap important : pour la première fois, un agent IA ne se contente plus de raisonner ou de proposer des actions : il dispose d’un véritable poste de travail Windows pour les exécuter.
Dans cet article, je vous propose un retour sur Opal, son lien étroit avec Windows 365, son mode de fonctionnement, ses limites actuelles, et surtout dans quels cas d’usage réels cette approche prend tout son sens.
Qu’est-ce que le projet Opal dans Microsoft 365 Copilot ?
Annoncé durant l’Ignite 2025, Opal est une nouvelle capacité de Copilot orientée vers l’automatisation de tâches concrètes et complexes, au-delà de la simple génération de texte ou de réponses. Cette fonctionnalité expérimentale est disponible via le programme Frontier de Microsoft 365 Copilot.
Opal n’est pas un nouveau Copilot de plus :
- Opal n’est ni un chatbot, ni un simple outil de RPA, ni une extension de Power Automate.
- C’est un agent IA qui opère dans un environnement Windows réel, avec les mêmes contraintes qu’un utilisateur humain.
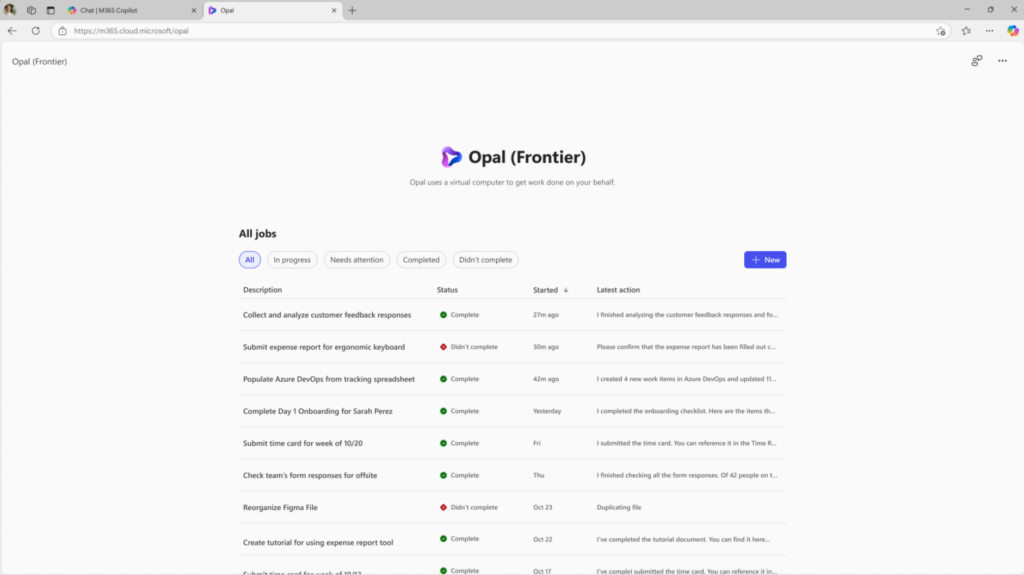
Pour faire simple, il s’agit d’un agent IA qui exécute pour vous des tâches réelles et multi-steps dans un environnement sécurisé, en utilisant un PC cloud Windows 365 pour interagir avec des applications web ou systèmes comme le ferait un humain (cliquer, remplir des formulaires, naviguer, etc.).
Toutes les organisations sont confrontées au défi des tâches manuelles répétitives, qui prennent un temps précieux et les détournent de leurs priorités stratégiques, de leur créativité et de leurs activités à fort impact.
Pensez au temps nécessaire pour rassembler des informations provenant de plusieurs sites et outils dans le cadre d’un audit de conformité, pour intégrer de nouveaux employés avec des commandes d’équipement et des accès au système, ou pour valider des bons de commande.
Toutes ces tâches importantes doivent être accomplies, et c’est précisément le type de travail pour lequel Opal a été conçu.
Microsoft met également une FAQ disponible juste ici.
Dans quels cas Opal peut être utile ?
Les entreprises disposent encore de dizaines d’applications sans API, sans connecteur et sans automatisation possible. Opal cible précisément ce vide. Quand aucune API n’existe, Power Automate s’arrête. Opal, lui, continue via l’interface utilisateur.
Opal n’est ni Power Automate, ni un RPA classique : c’est un agent IA capable d’interagir avec un PC cloud Windows 365 :
- Dès qu’un processus nécessite de cliquer dans une application web ou legacy
- Télécharger une facture depuis un portail fournisseur, la renommer, puis la déposer dans SharePoint est un scénario typique Opal.
Par contre, Opal n’est pas conçu pour les processus temps réel ni transactionnels critiques.
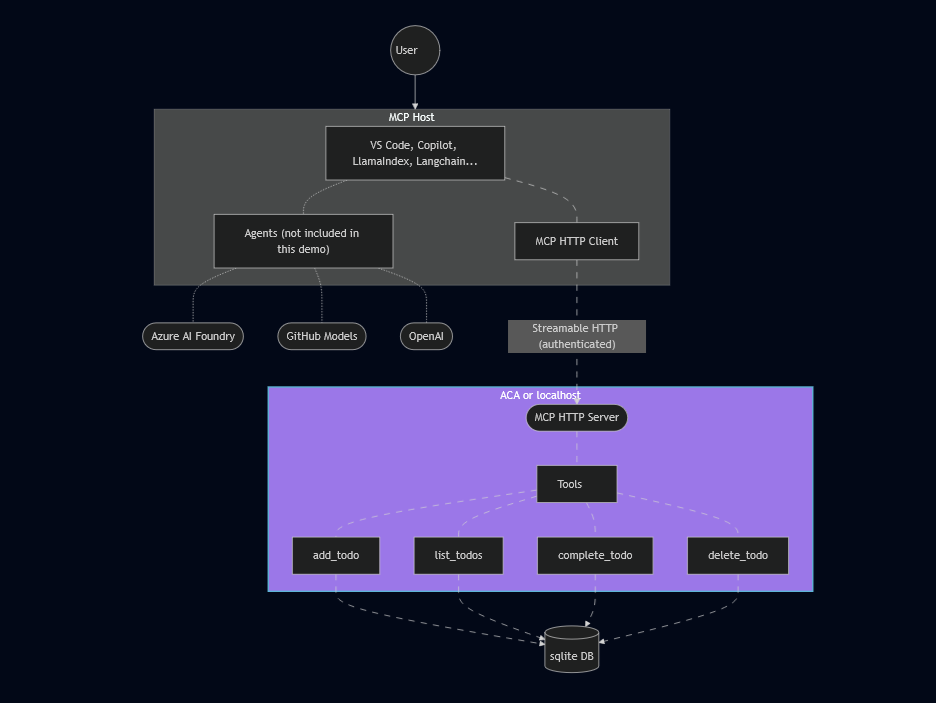
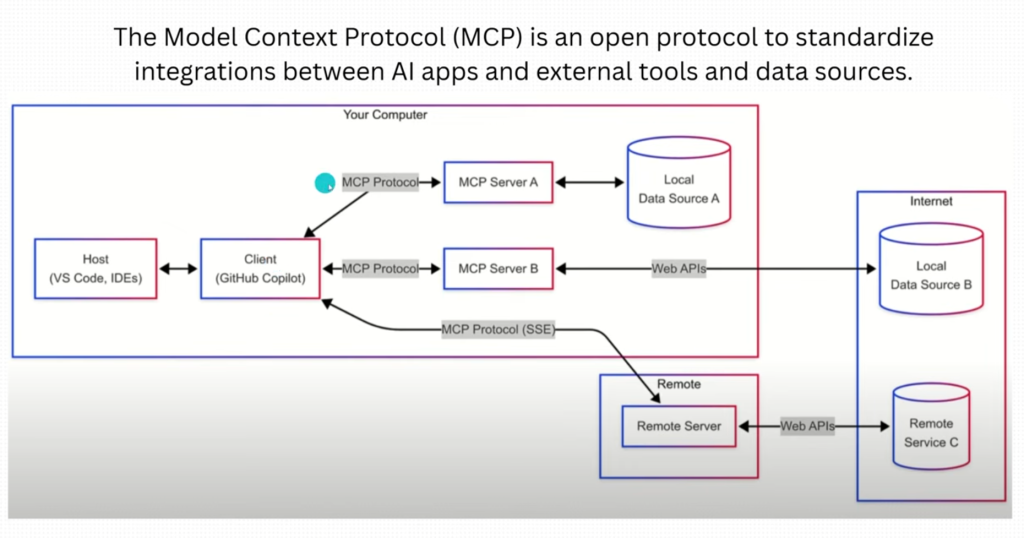
Quel est le lien entre Windows 365 et Opal ?
Microsoft 365 Copilot sait raisonner, analyser et décider, mais il ne peut pas exécuter d’actions réelles sans poste de travail. Le lien entre Windows 365 et Opal est alors fondamental : Opal a besoin d’un véritable environnement Windows pour pouvoir agir.
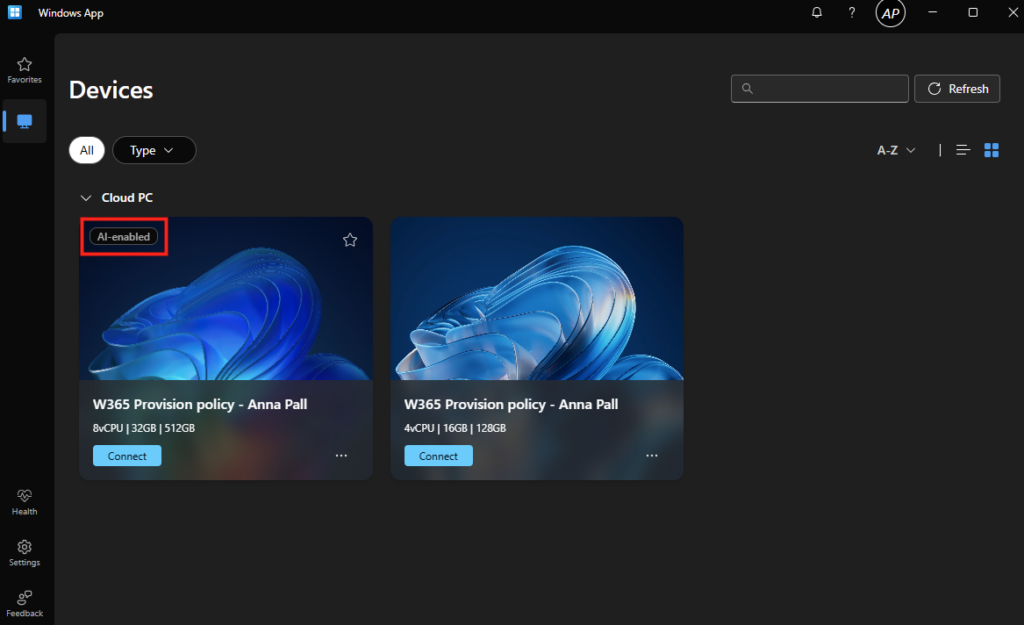
Les actions Opal sont exécutées dans un Cloud PC dédié, sans accès direct au poste de l’utilisateur. Le PC cloud Windows 365 sert donc d’environnement sécurisé et isolé pour les actions de l’agent.
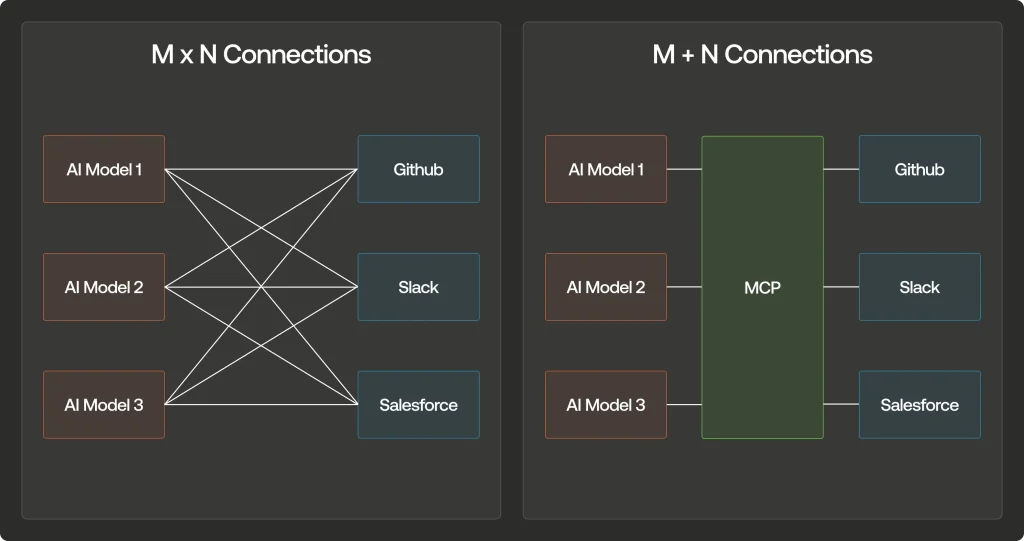
On peut résumer l’architecture ainsi :
- Windows 365 = le corps
- Opal = les mains
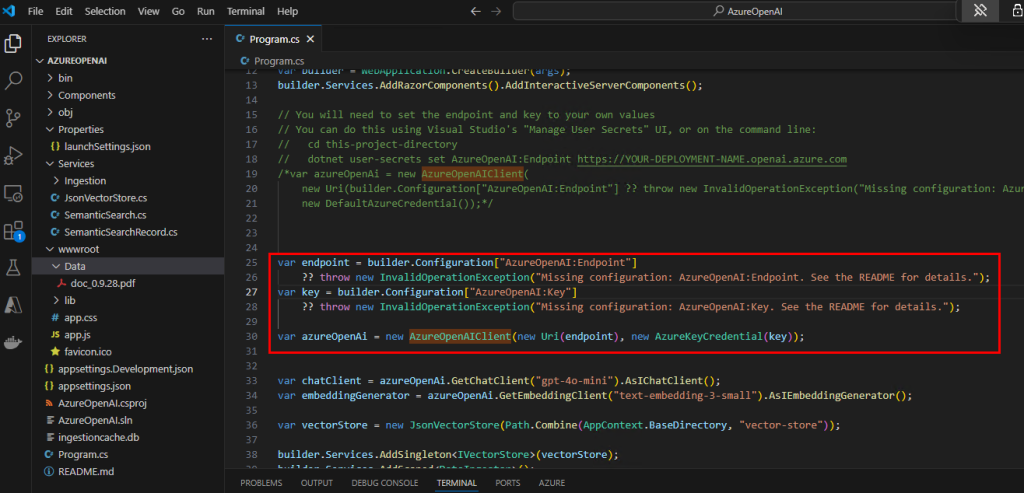
- Copilot = le cerveau
Ici, Windows 365 fournit à votre IA :
- une isolation complète du poste de l’utilisateur
- un PC cloud dédié à l’agent IA
- un navigateur Edge réel
- un système de fichiers Windows
- une session utilisateur contrôlée
- une identité Microsoft Entra associée
Pourquoi Microsoft n’utilise pas un simple navigateur sandbox ?
Un simple navigateur sandboxé ne permet pas de couvrir les scénarios ciblés par Opal.
Opal n’est pas conçu pour exécuter une action isolée, mais pour enchaîner des tâches complexes, multi-applications et persistantes dans le temps.
Les agents Opal doivent parfois :
- télécharger et stocker des fichiers localement,
- ouvrir et manipuler des fichiers Excel, PDF ou CSV,
- interagir avec plusieurs onglets et fenêtres,
- conserver un état entre plusieurs étapes,
- utiliser une identité utilisateur complète (cookies, sessions, certificats),
- fonctionner avec des extensions navigateur ou des paramètres Edge spécifiques.
Un navigateur isolé et éphémère ne permet pas cela de manière fiable. Un système d’exploitation Windows complet est donc nécessaire pour garantir la continuité, la stabilité et la sécurité de l’exécution.
À quoi à accès Opal sur ces postes Windows 365 ?
Par défaut, Opal n’a accès à aucun site web.
Toute navigation sortante est bloquée tant qu’aucune URL n’a été explicitement autorisée dans le portail d’administration Opal. Sans cette configuration :
- l’agent ne peut pas ouvrir de site web,
- il ne peut pas effectuer de recherche internet,
- il ne peut pas se connecter à une application SaaS.
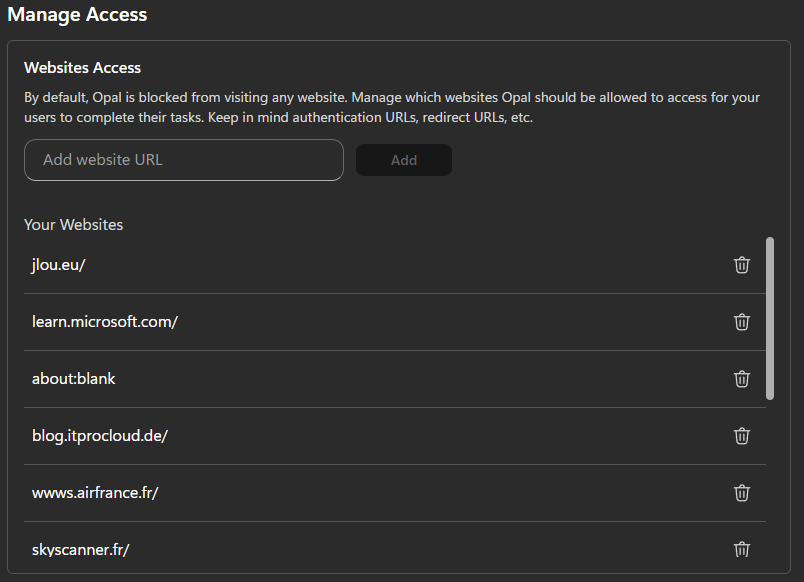
Ce modèle repose sur une approche deny by default, essentielle pour limiter le périmètre d’action de l’agent IA et éviter toute dérive ou accès non maîtrisé.
Chaque URL autorisée devient ainsi un périmètre fonctionnel clairement défini pour l’agent Opal.
Quels sont les prérequis pour activer Opal sur son tenant ?
Les prérequis exacts ne sont pas encore officiellement figés par Microsoft. À ce jour, Opal est uniquement disponible :
- dans le cadre du programme Microsoft 365 Copilot Frontier,
- avec une licence Microsoft 365 Copilot active pour les utilisateurs concernés.
Les dépendances techniques observées incluent également :
- Microsoft Intune (gestion des Cloud PC),
- Windows 365 (provisionnement des postes agents),
- Microsoft Entra ID (identité et accès),
- Microsoft Graph (onboarding automatisé).
Combien coûte Opal ?
Microsoft n’a communiqué aucun tarif dédié pour Opal à ce stade. Opal n’est pas facturé comme une licence distincte.
Il est inclus, pour le moment, comme fonctionnalité expérimentale du programme Frontier, accessible uniquement avec une licence Microsoft 365 Copilot valide.
Le coût indirect à prendre en compte reste principalement :
- les licences Windows 365 associées aux Cloud PC agents,
- les licences Intune,
- et la licence Microsoft 365 Copilot par utilisateur.
Où les utilisateurs trouvent-ils Opal ?
Les utilisateurs ne trouvent pas Opal comme une application classique dans leur menu Microsoft 365. Opal apparaît dans l’interface Copilot, une fois que l’administrateur a activé la fonctionnalité sur le tenant.
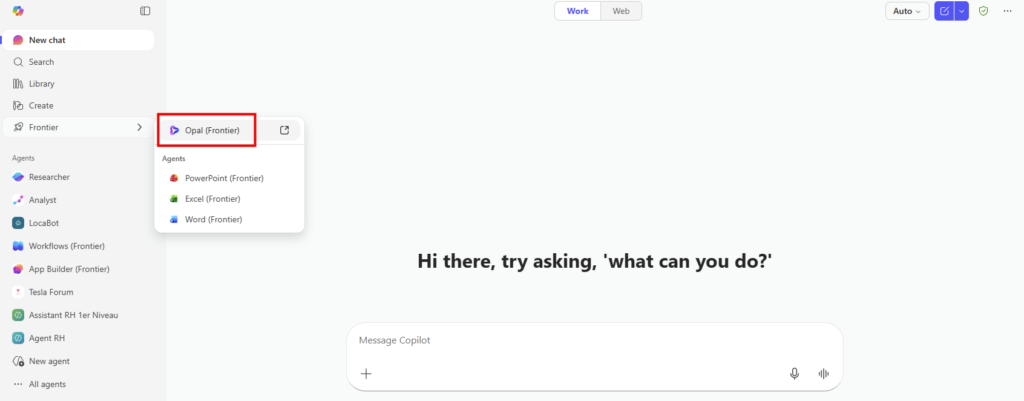
L’URL directe est https://opal.frontier.microsoft365.com peut aussi être utilisée.
Pas de promesses marketing ici : uniquement ce que j’ai pu tester, observer et configurer moi-même sur un tenant Microsoft 365 étape par étape :
- Etape 0 – Rappel des prérequis
- Etape I – Configuration du tenant
- Etape II – Configuration d’Opal
- Etape III – Configuration du pool de machines Windows 365
- Etape IV – Premiers tests d’Opal
- Etape V – Quelques remarques sur Opal
Etape 0 – Rappel des prérequis :
Avant toute chose, assurez-vous :
- d’avoir accès au programme Frontier,
- de disposer d’un compte Administrateur général,
- d’avoir Intune et Windows 365 fonctionnels sur le tenant,
- d’avoir des licences Microsoft 365 Copilot assignées.
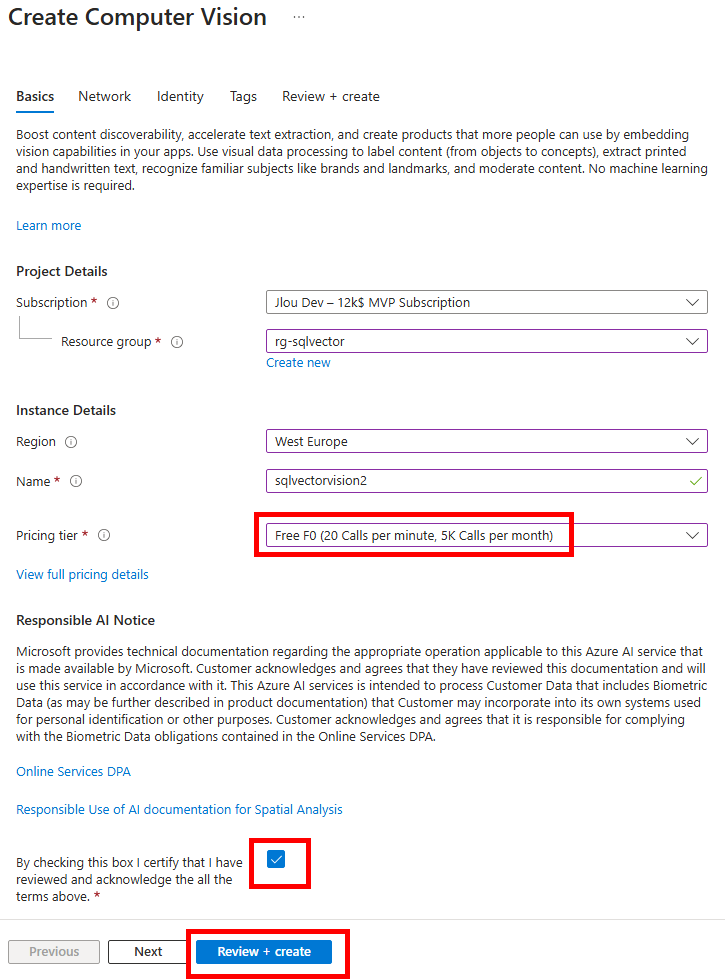
Etape I – Configuration du tenant :
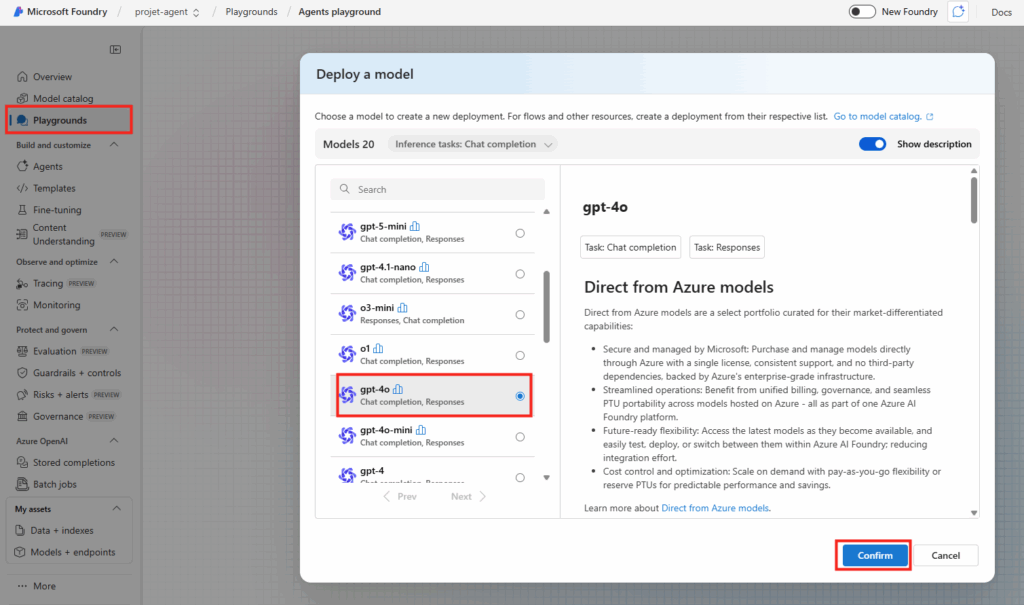
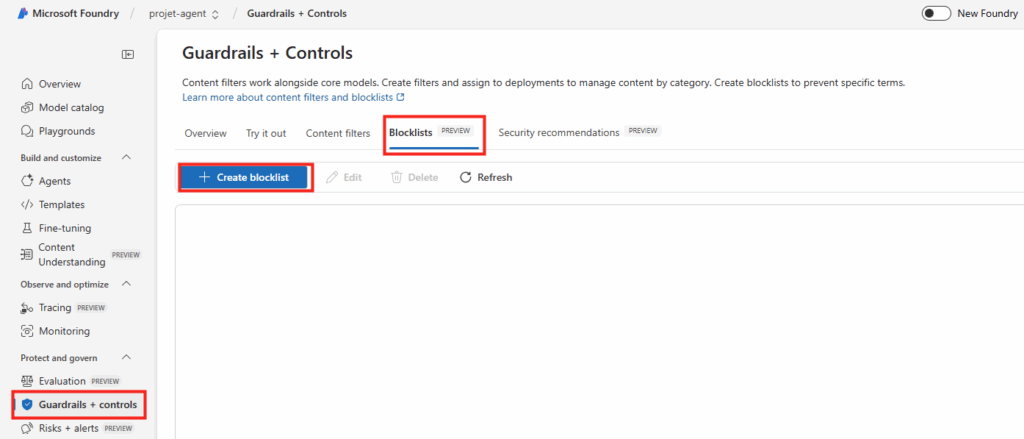
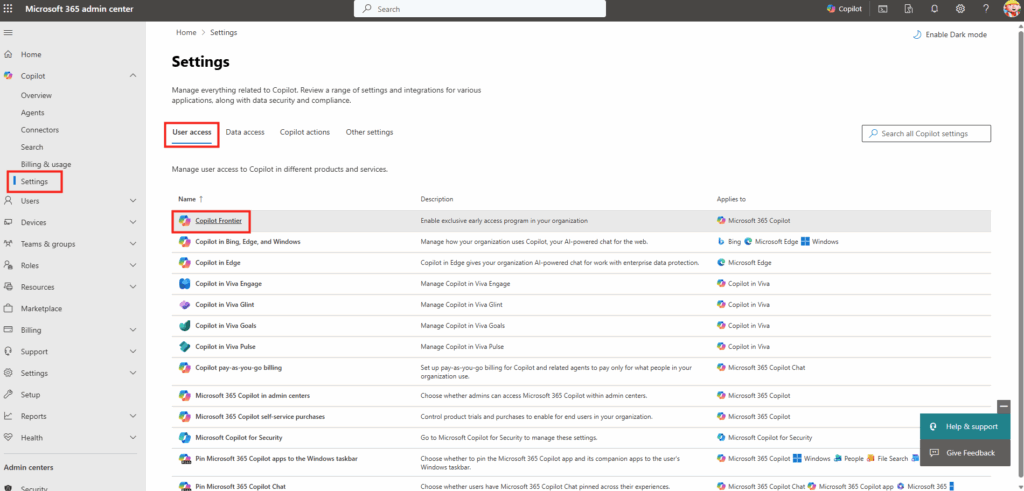
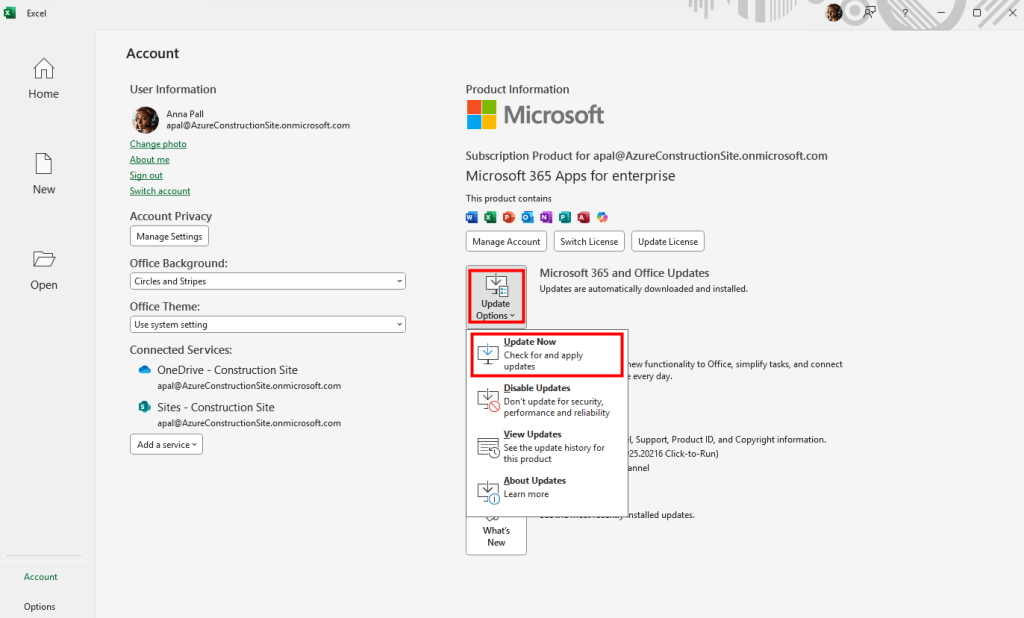
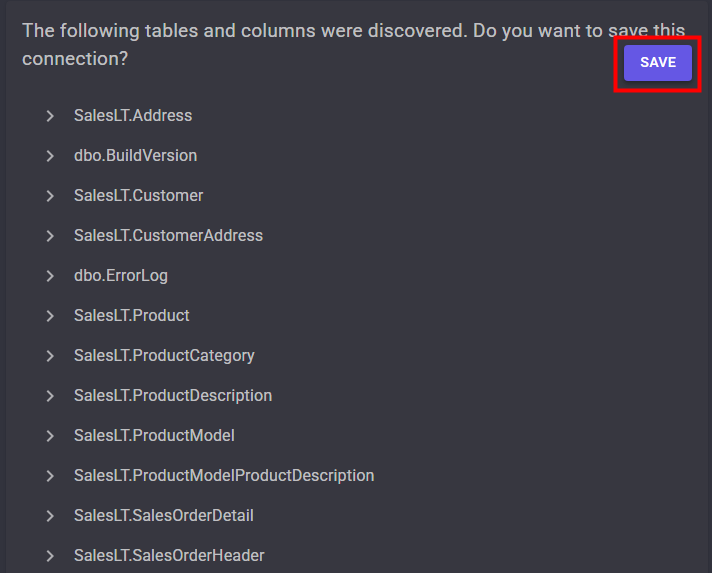
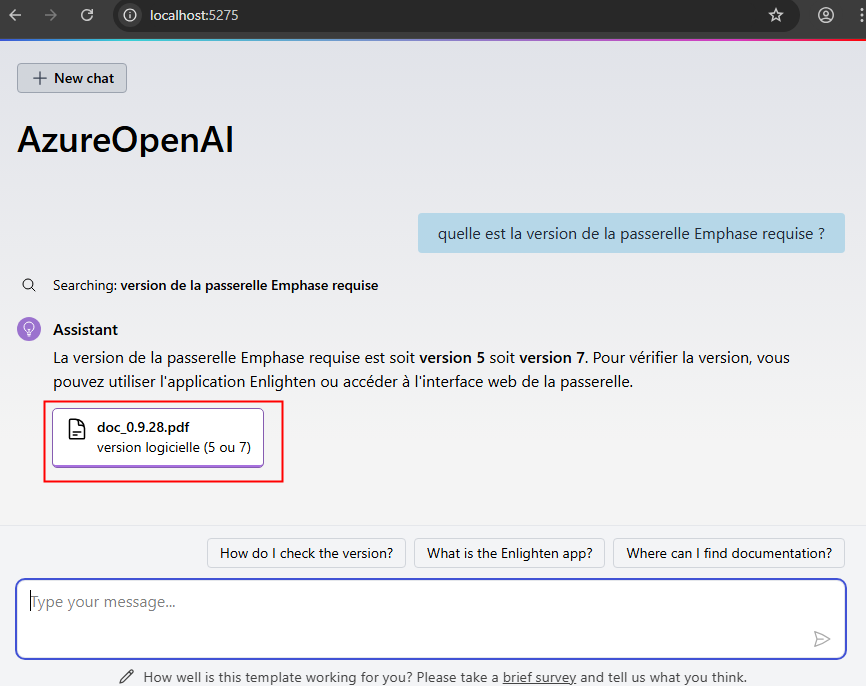
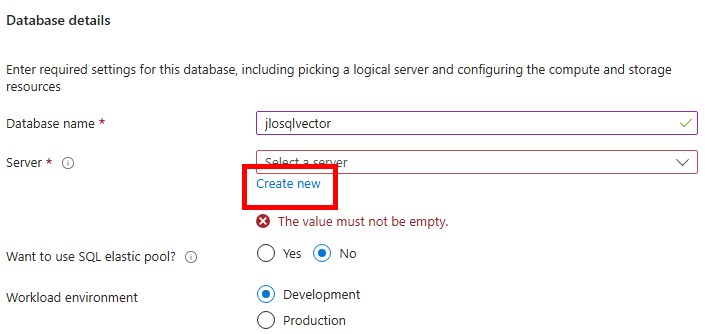
Connectez-vous au portail d’administration de Microsoft 365, et depuis le menu de gauche, ouvrez les paramétrages de Copilot, puis sélectionnez Opal (Frontier) dans la liste des fonctionnalités Copilot :
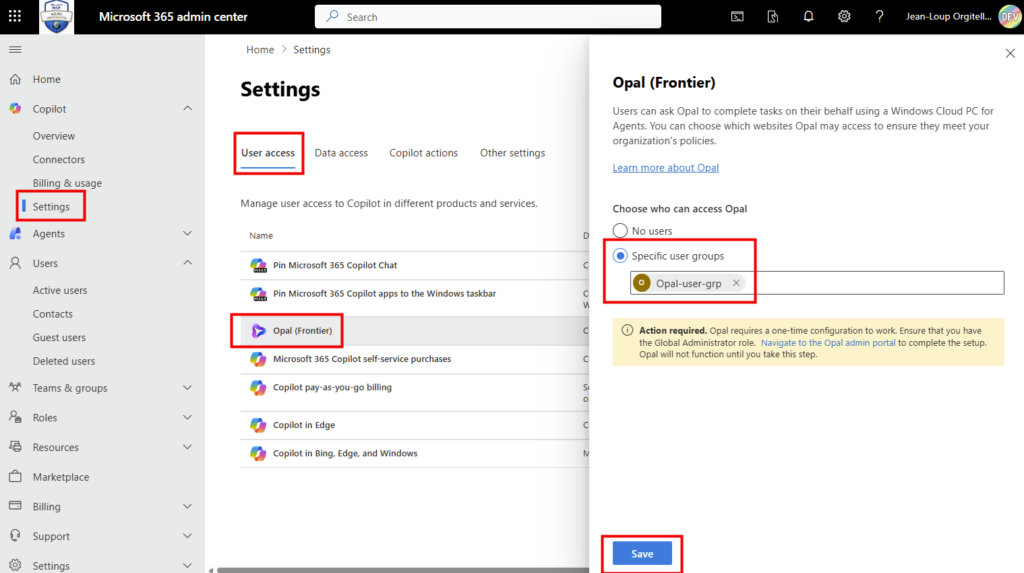
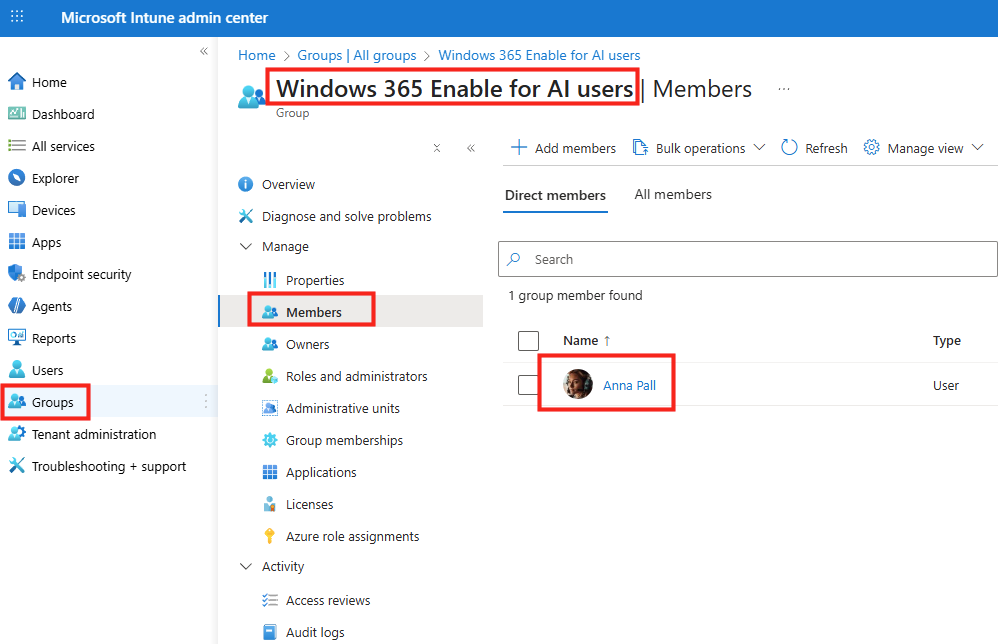
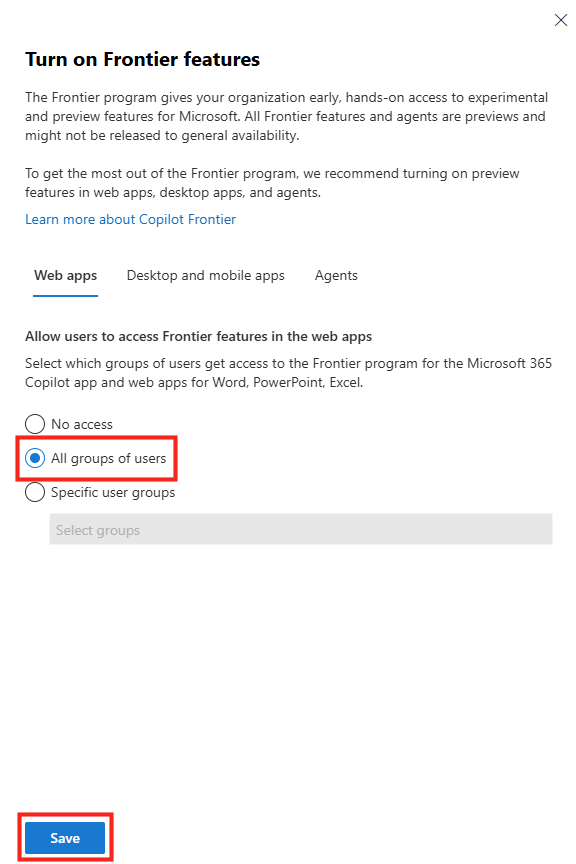
Dans le panneau de configuration Opal, l’option Specific user groups permet de restreindre l’accès à Opal à des groupes Microsoft Entra ID précis, puis sauvegardez :
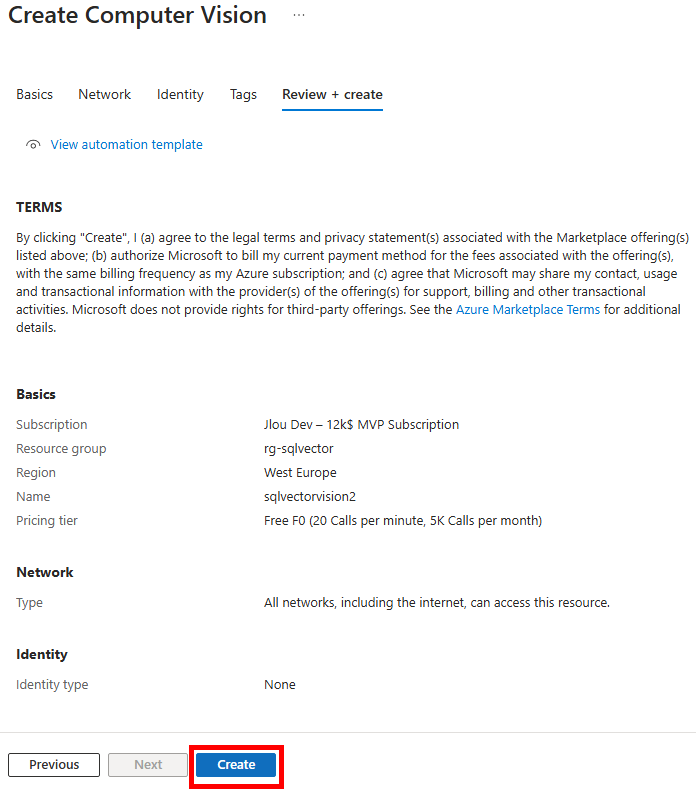
Etape II – Configuration d’Opal :
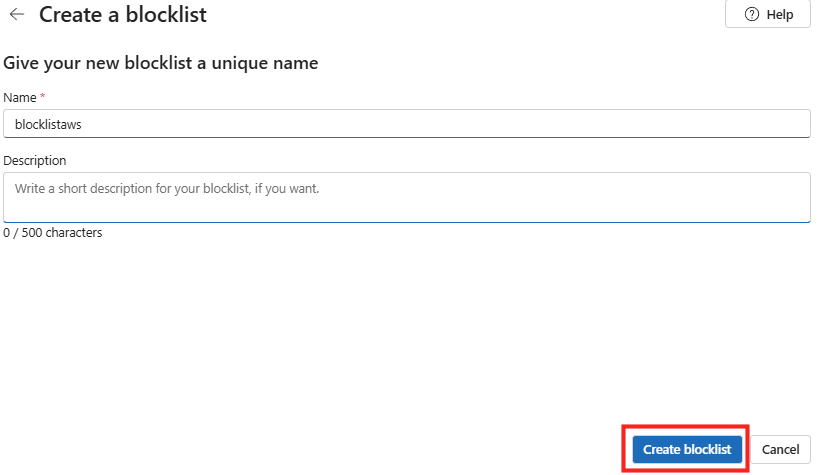
Puis cliquez ici pour vous rendre sur le portail d’administration d’Opal afin de continuer la suite de la configuration.
https://opal.frontier.microsoft365.com/admin
Si le message suivant apparaît, vérifiez que vous êtes bien authentifié avec un compte administrateur général, attendez quelques minutes, puis revenez sur le même portail :
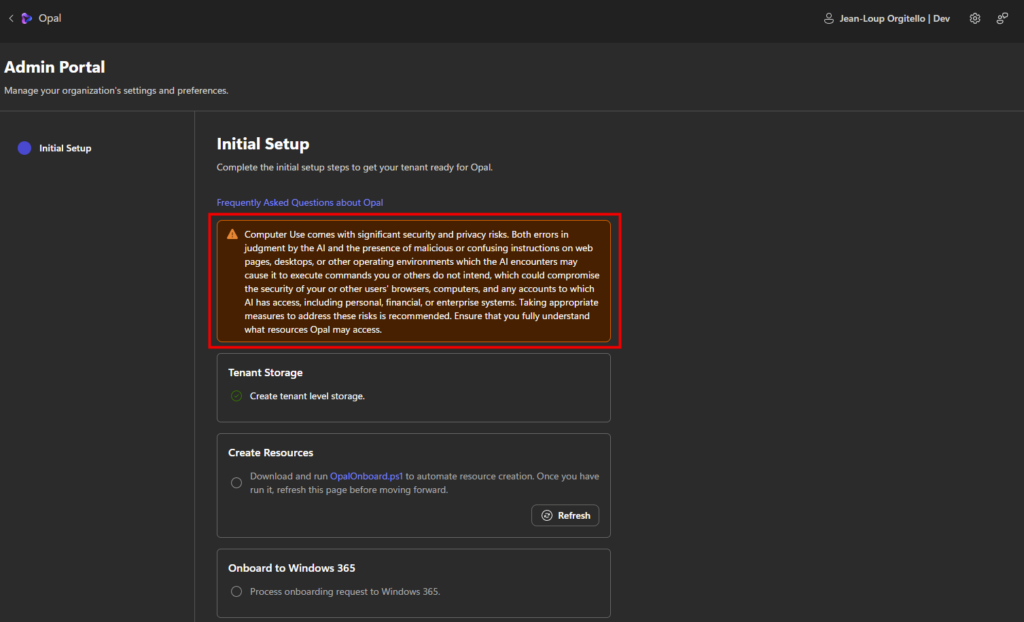
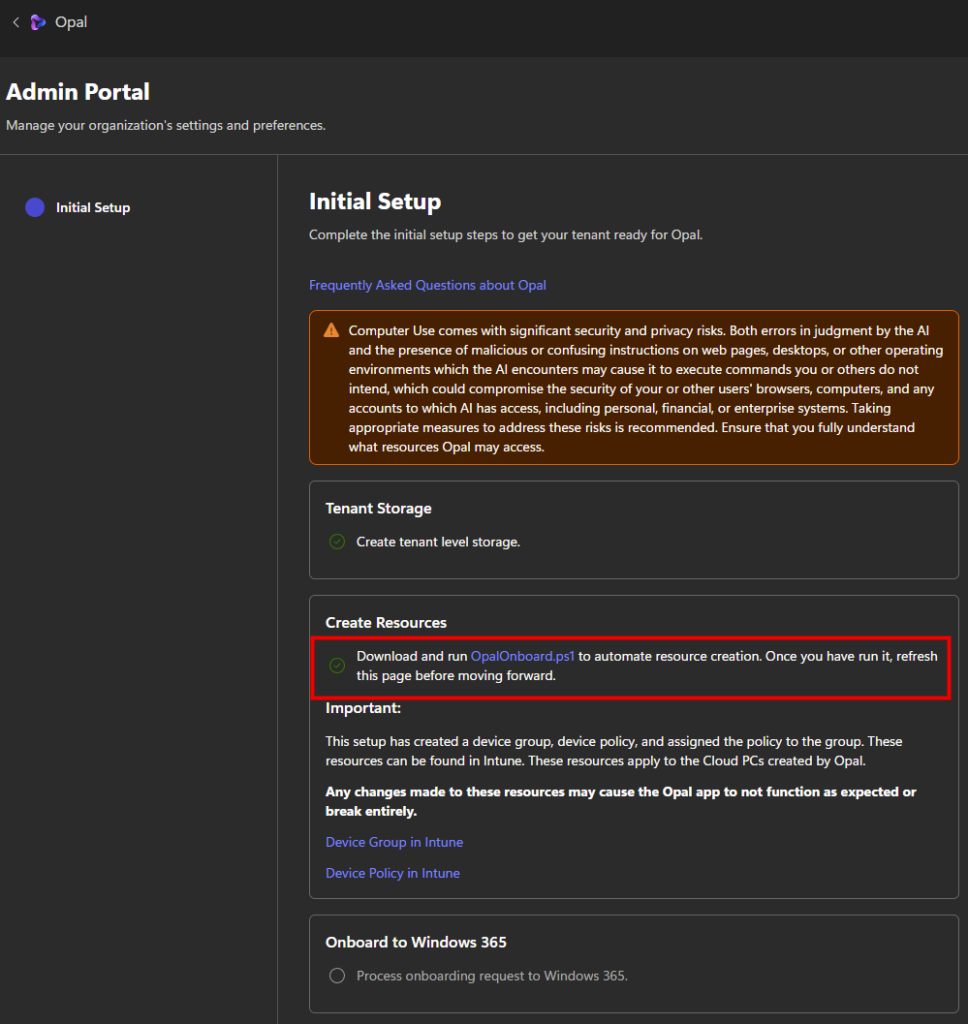
Une fois sur le portail d’administration d’Opal, avant d’aller plus loin, prenez le temps de lire le message d’avertissement affiché en évidence :
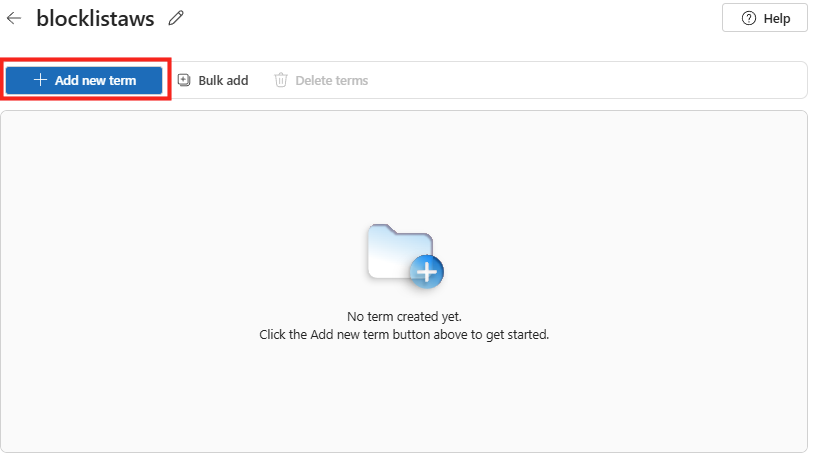
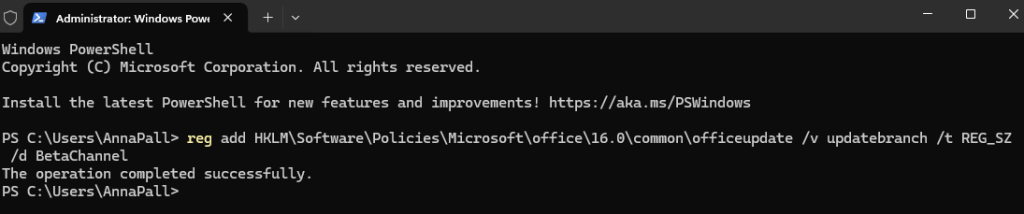
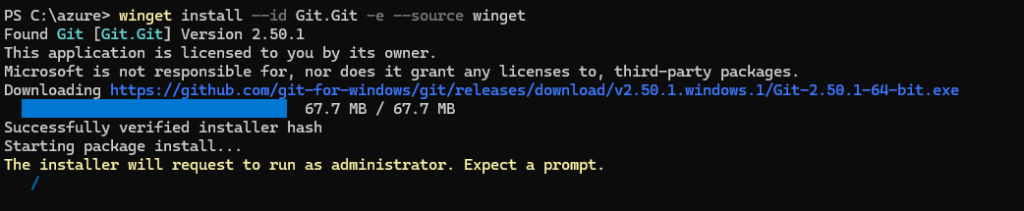
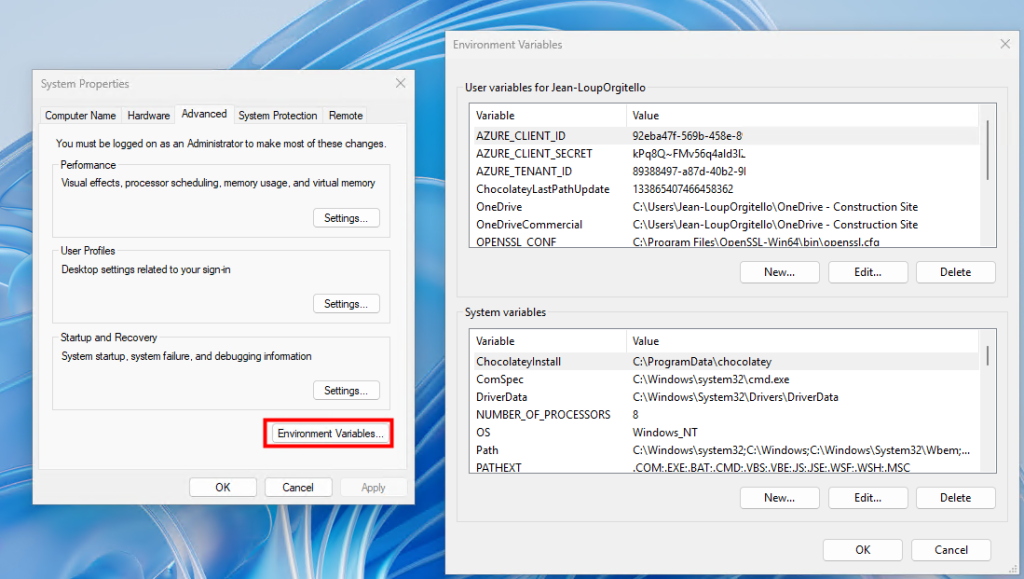
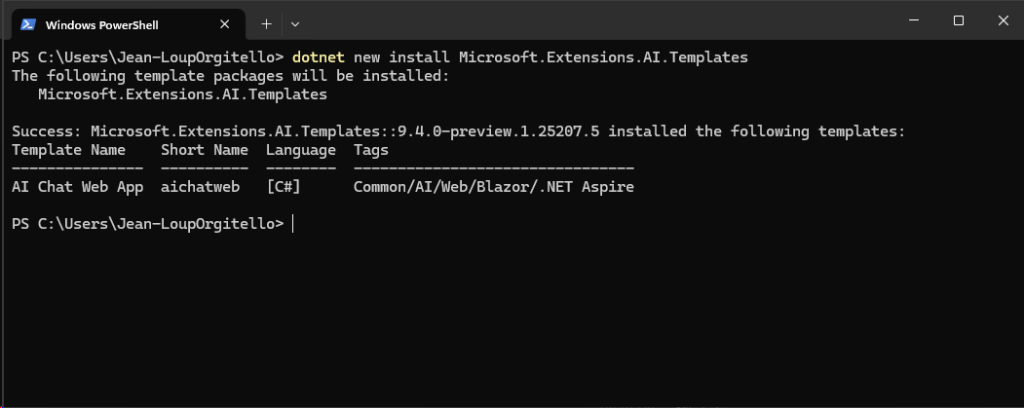
Afin de mettre en route Opal sur votre tenant Microsoft, téléchargez le script PowerShell suivant via un clic droit :
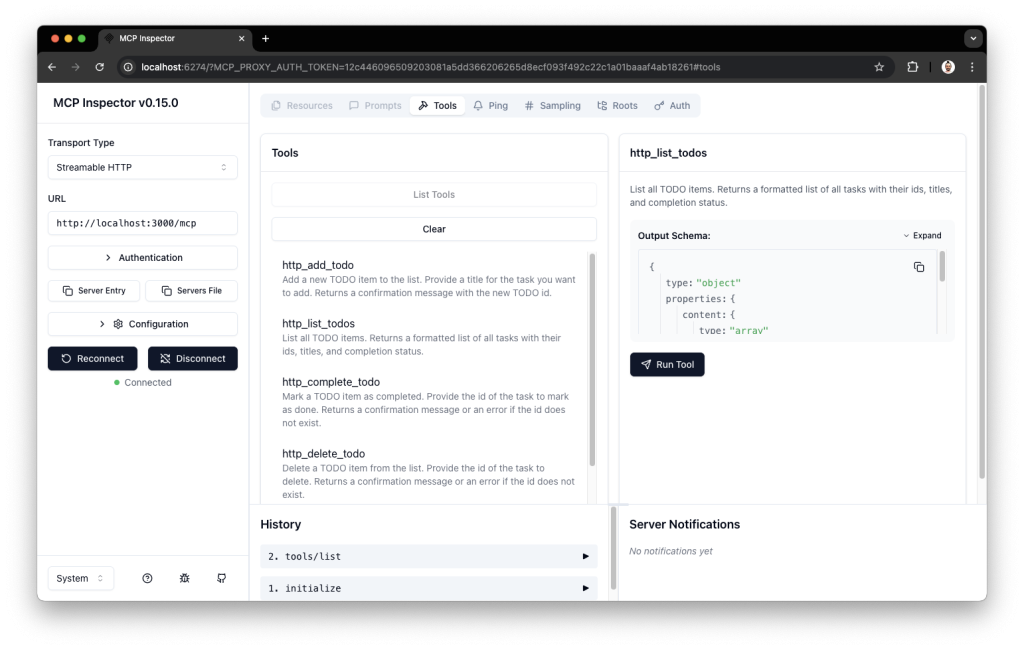
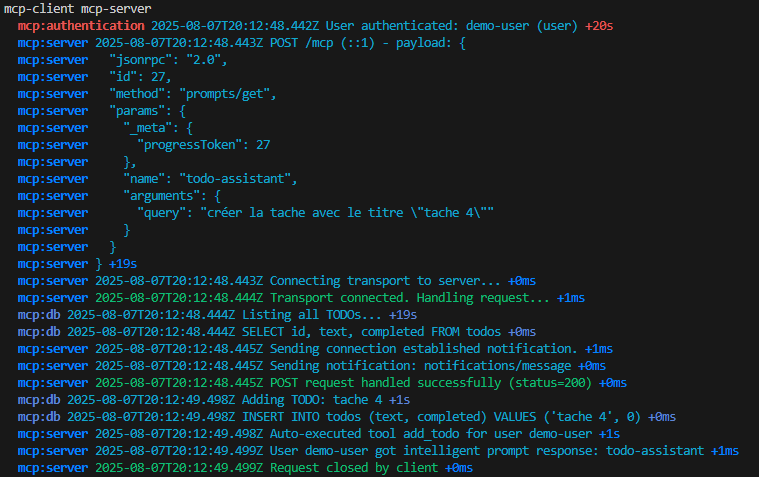
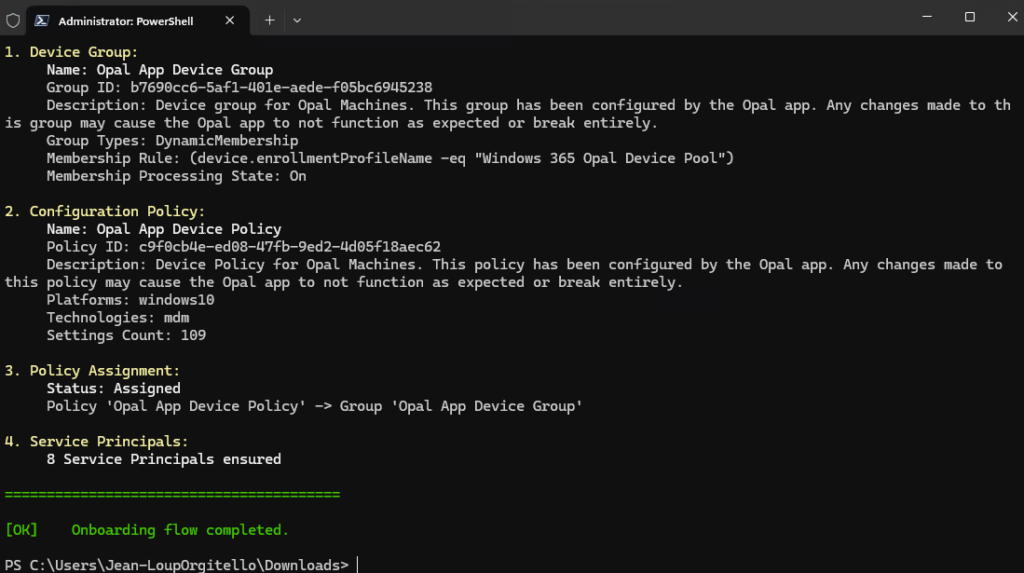
Le script OpalOnboard.ps1 automatise l’onboarding d’Opal dans un tenant Microsoft 365 via Microsoft Graph, il :
- installe/charge les modules Microsoft Graph nécessaires, puis se connecte à Graph avec des droits d’admin,
- crée (si absents) 8 service principals (Opal, Windows 365, AVD, Windows Cloud Login, etc.) pour que le tenant ait les identités applicatives requises,
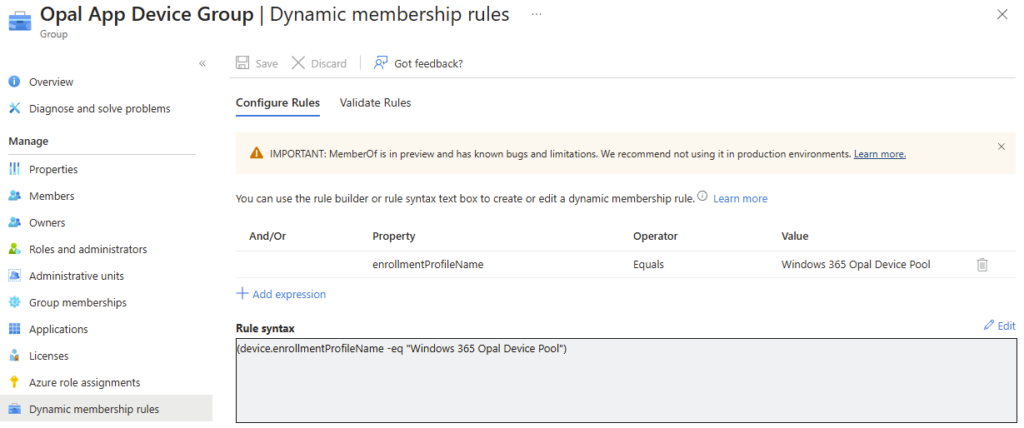
- crée un groupe dynamique de devices (“Opal App Device Group”) basé sur une règle de type enrollmentProfileName == « Windows 365 Opal Device Pool »,
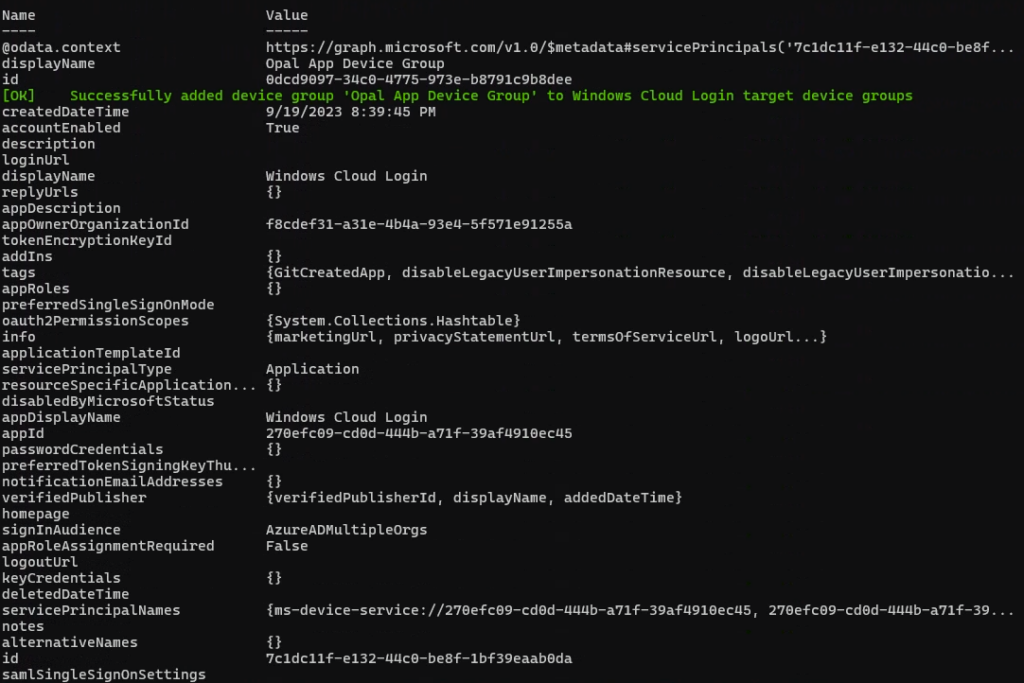
- configure le service principal “Windows Cloud Login” pour activer le RDP et cibler ce groupe de devices,
- télécharge une policy Edge au format JSON depuis une URL Microsoft, la crée côté Intune (Settings Catalog), puis assigne la policy au groupe de devices.
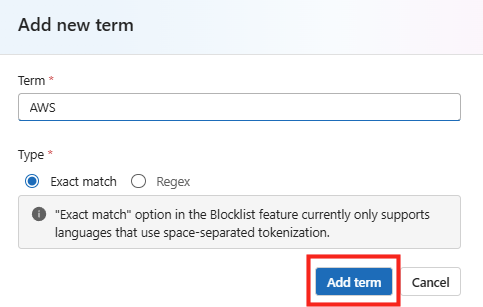
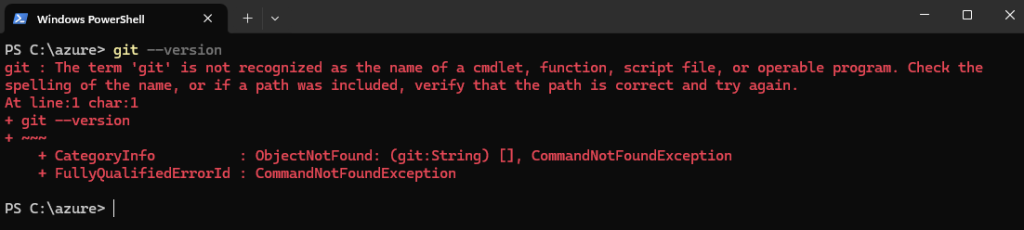
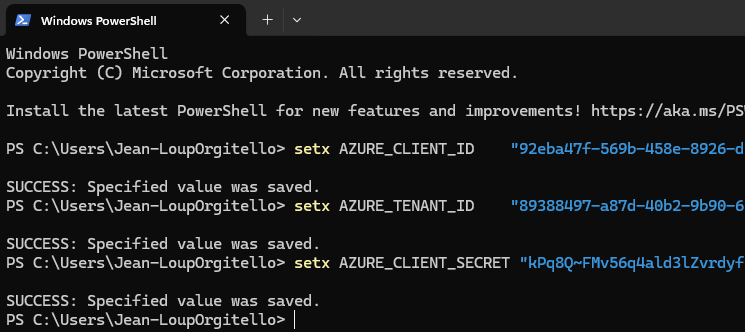
Sur votre poste local, installez et ouvrez PowerShell 7 :
winget search --id Microsoft.PowerShellOuvrez PowerShell 7 avec les droits d’administrateur, exécutez le script, confirmez l’action d’exécution, puis laissez-vous guider :
.\OpalOnboard.ps1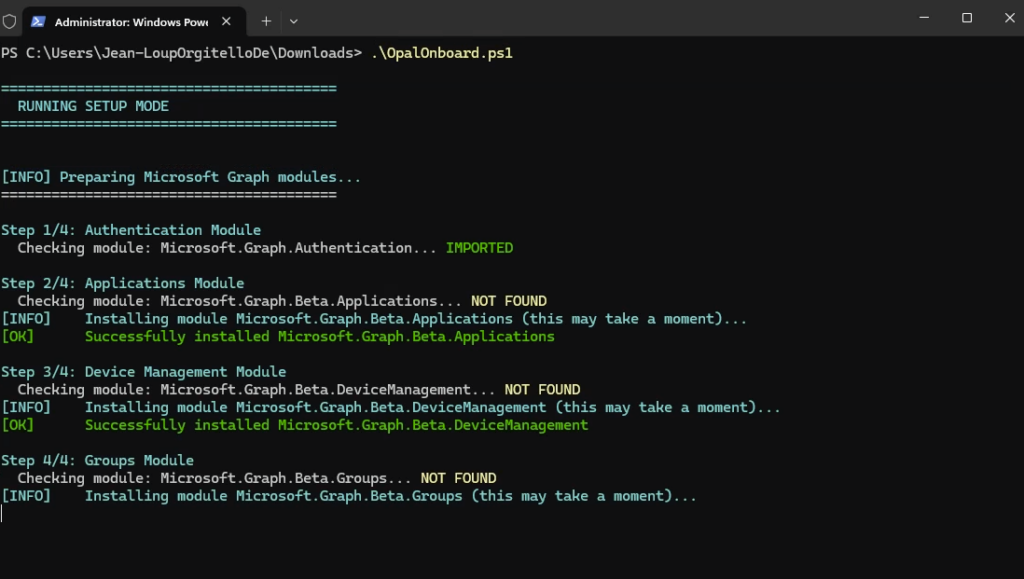
Après l’installation de module, le script se connecte à votre tenant grâce à un compte d’administrateur :
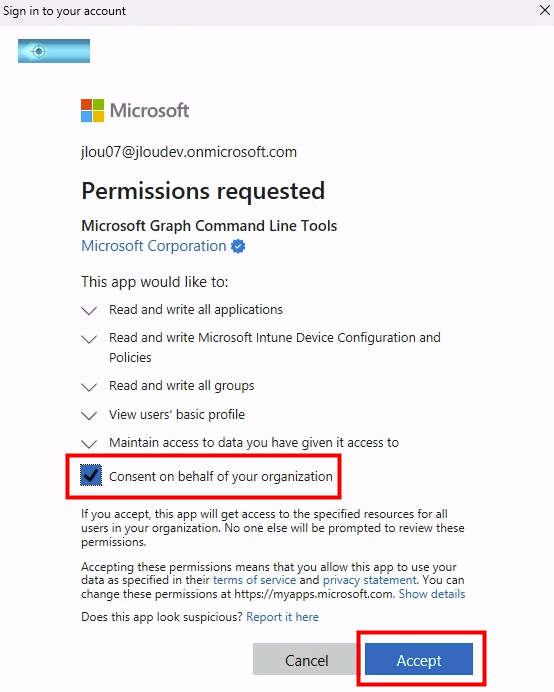
Acceptez les permissions nécessaires :
Si l’erreur suivante apparaît, fermez puis rouvrez simplement PowerShell :
Confirmez les actions d’exécution de création :
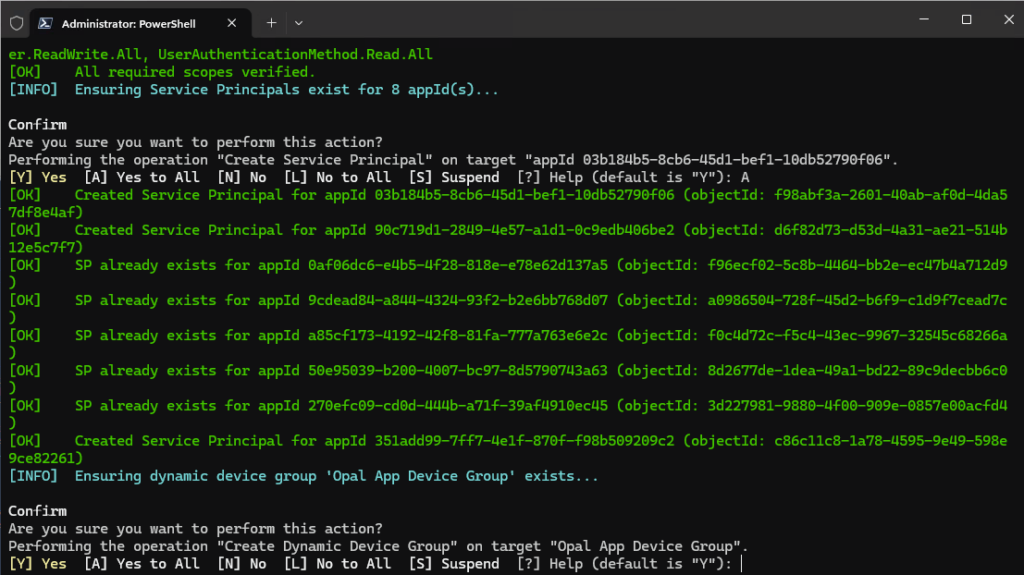
- Création de principaux de services, si absents :
- 03b184b5-8cb6-45d1-bef1-10db52790f06 Opal – Primary App
- 90c719d1-2849-4e57-a1d1-0c9edb406be2 Opal Native (On-box agent)
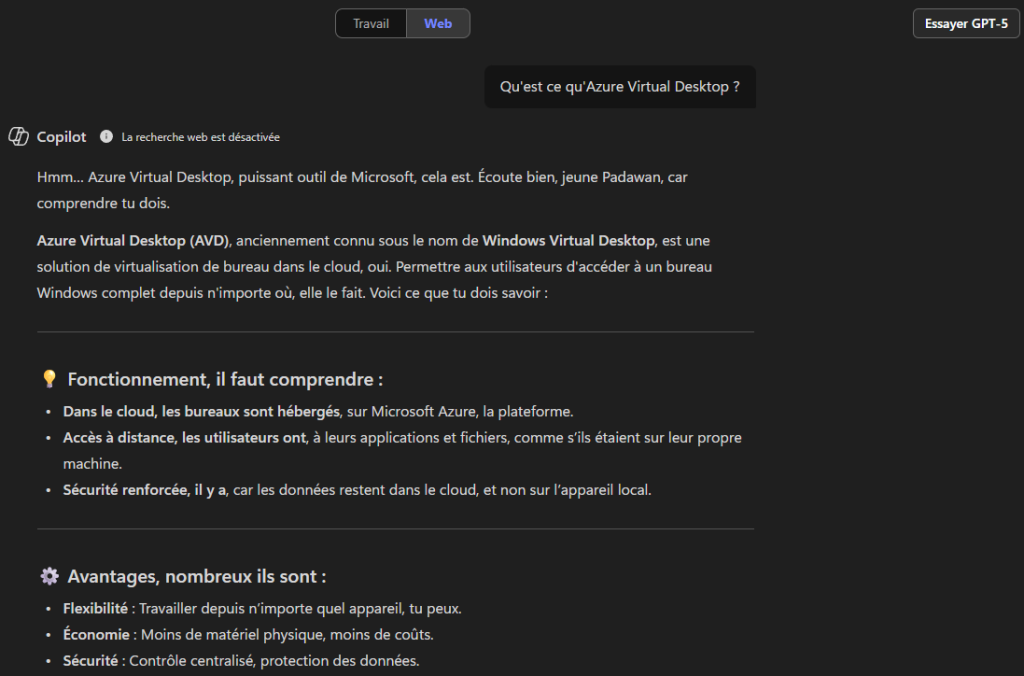
- 0af06dc6-e4b5-4f28-818e-e78e62d137a5 Windows 365
- 9cdead84-a844-4324-93f2-b2e6bb768d07 Azure Virtual Desktop
- a85cf173-4192-42f8-81fa-777a763e6e2c AVD Client
- 50e95039-b200-4007-bc97-8d5790743a63 AVD ARM Provider
- 270efc09-cd0d-444b-a71f-39af4910ec45 Windows Cloud Login
- 351add99-7ff7-4e1f-870f-f98b509209c2 Cloud Device Platform
- Création d’un groupe dynamique de machines :
- Nom ame: Opal App Device Group
- Type: groupe de sécurité
- (device.enrollmentProfileName -eq « Windows 365 Opal Device Pool »)
- Configuration du Windows Cloud Login avec notre nouveau groupe de machines :
- Création de la police Microsoft Edge via Intune :
- Assignation de la police au groupe dynamique de machines :
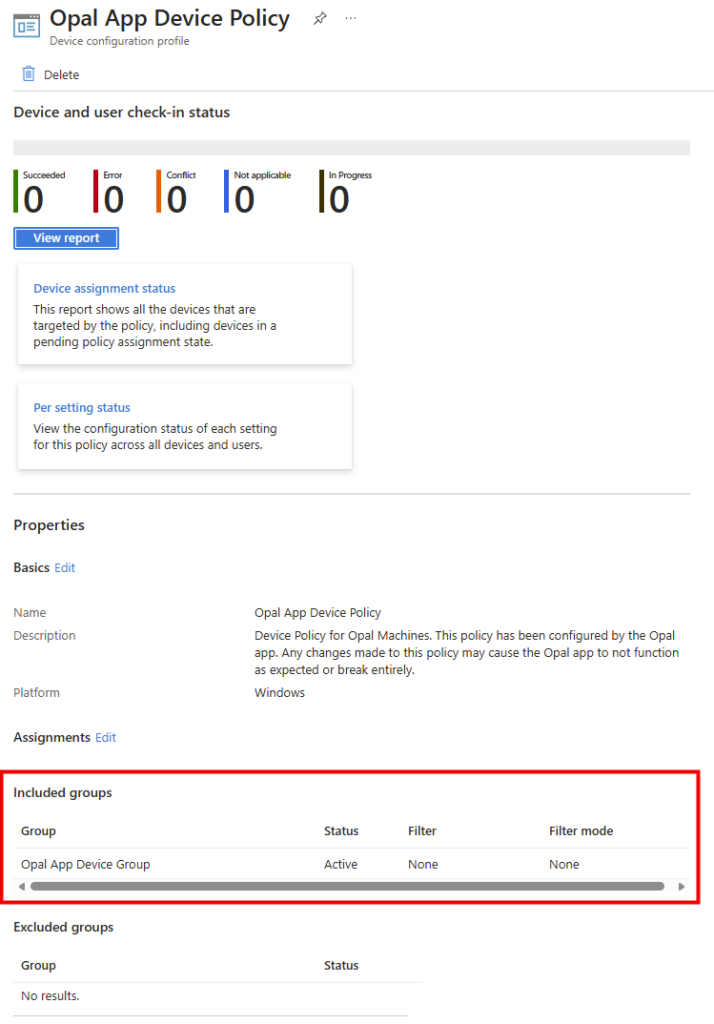
Une fois le processus correctement terminé, le message suivant apparaît :
Si cela n’est pas automatique, cliquez sur le bouton de rafraîchissement afin de constater la validation de cette étape :
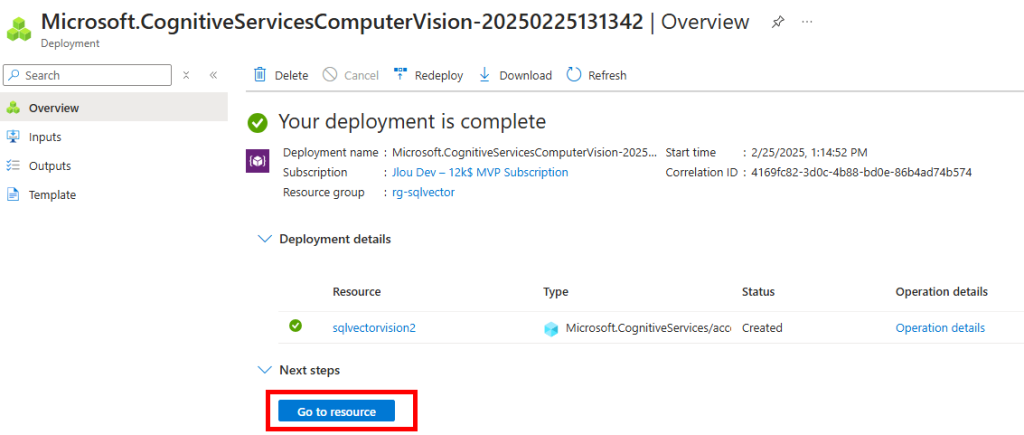
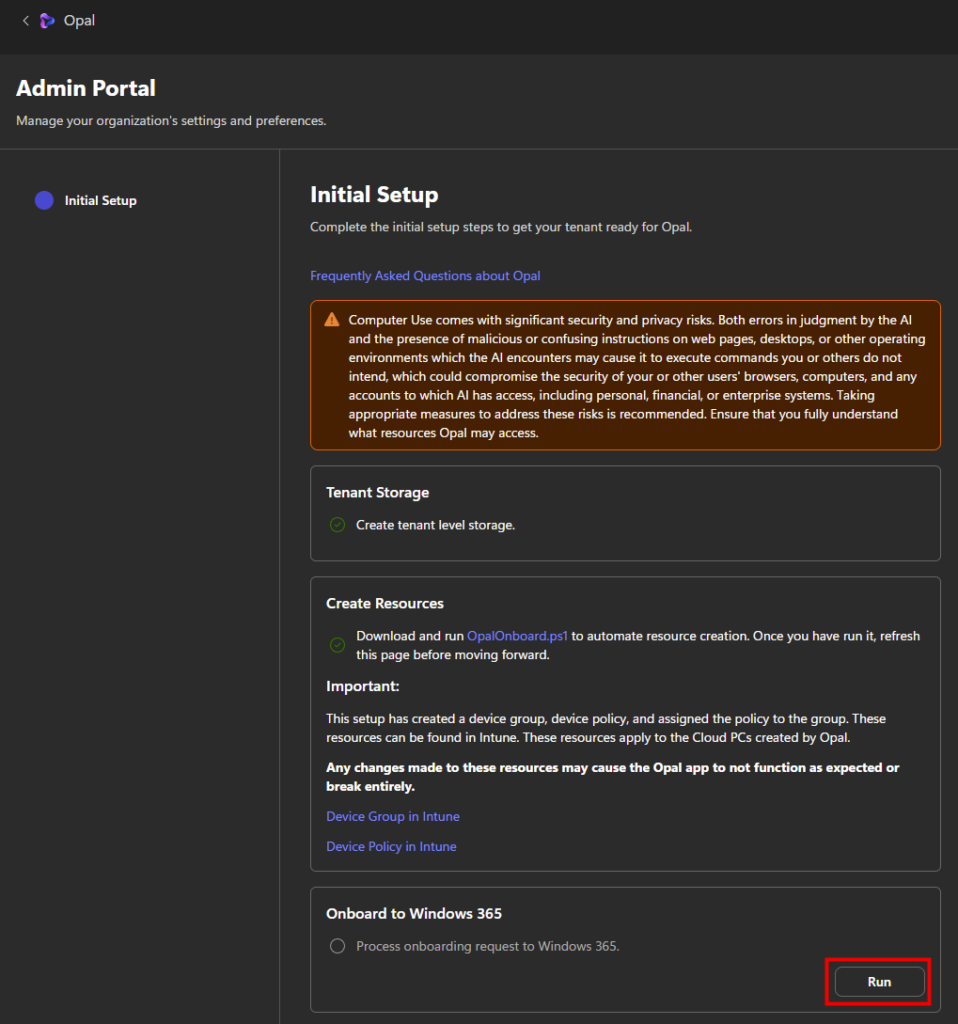
Enfin, lancez la dernière étape d’onboarding :
Attendez quelques minutes la fin de l’étape suivante :

Quelques minutes plus tard, constatez le succès final de l’étape d’onboarding, puis cliquez sur Suivant :
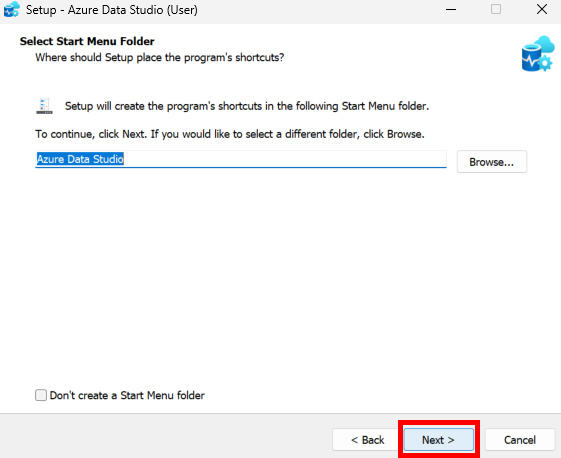
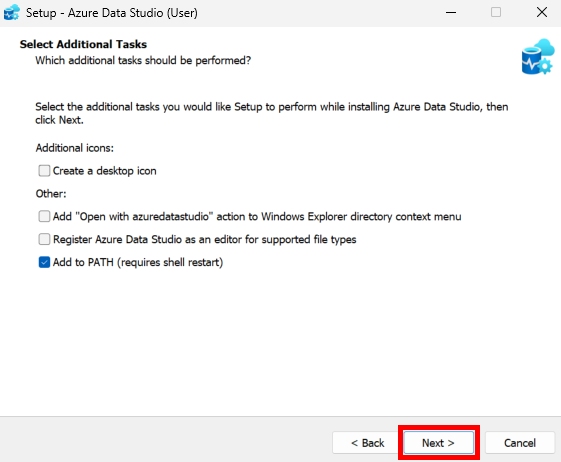
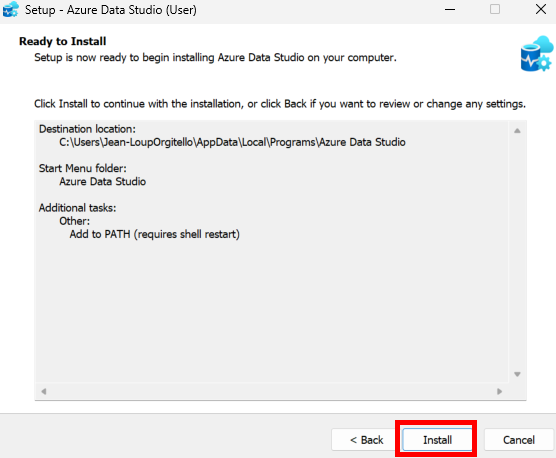
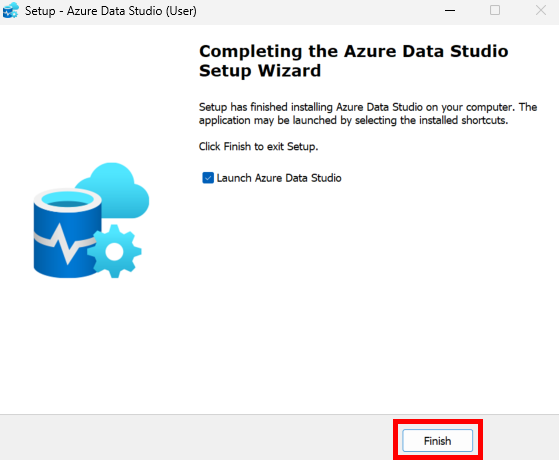
Une fois l’onboarding technique terminé, vous devez configurer le pool de Cloud PC Windows 365 qui sera utilisé par Opal pour exécuter les tâches.
Etape III – Configuration du pool de machines Windows 365 :
Quelques points importants à retenir :
- Le Cloud PC est le poste de travail de l’agent Opal, pas celui de l’utilisateur.
- Toutes les actions (navigation, clics, téléchargements) sont exécutées dans ces Cloud PC Windows 365.
- Les restrictions d’accès aux sites web permettent de contrôler précisément le périmètre d’action de l’agent.
Cette étape se réalise encore depuis le portail d’administration Opal.
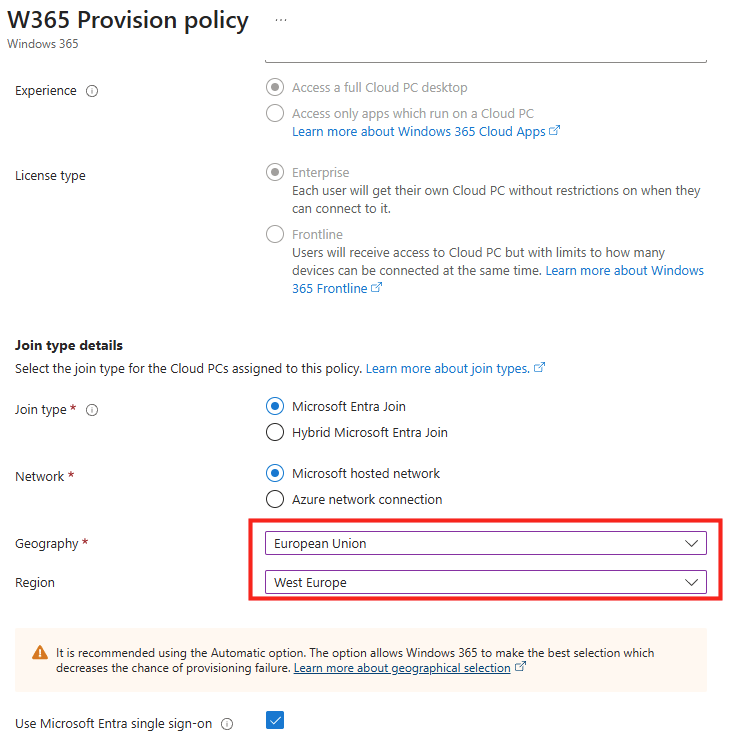
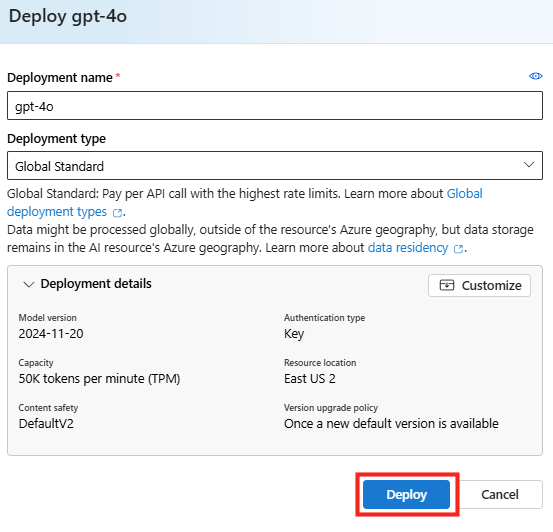
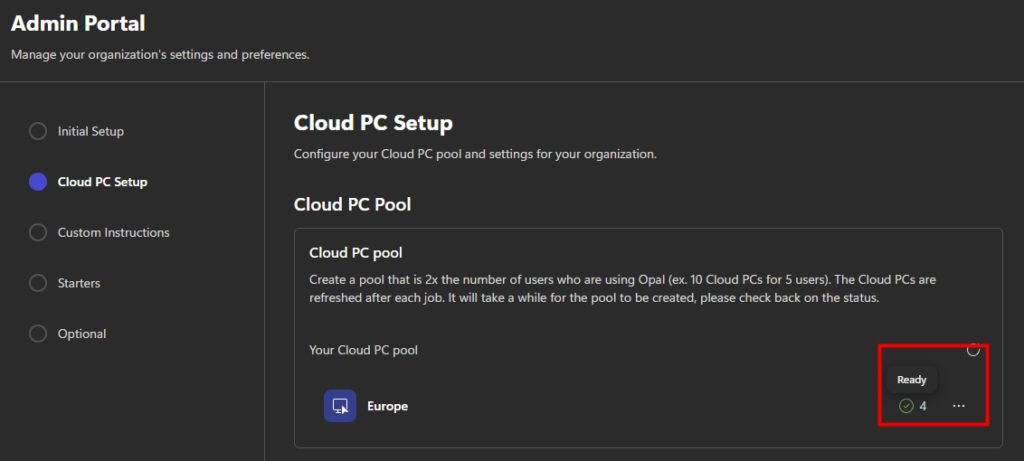
Cette première section permet de définir où seront hébergés les Cloud PC et combien de machines Windows 365 seront créées. Il est recommandé d’utiliser la même région que vos utilisateurs Microsoft 365 :
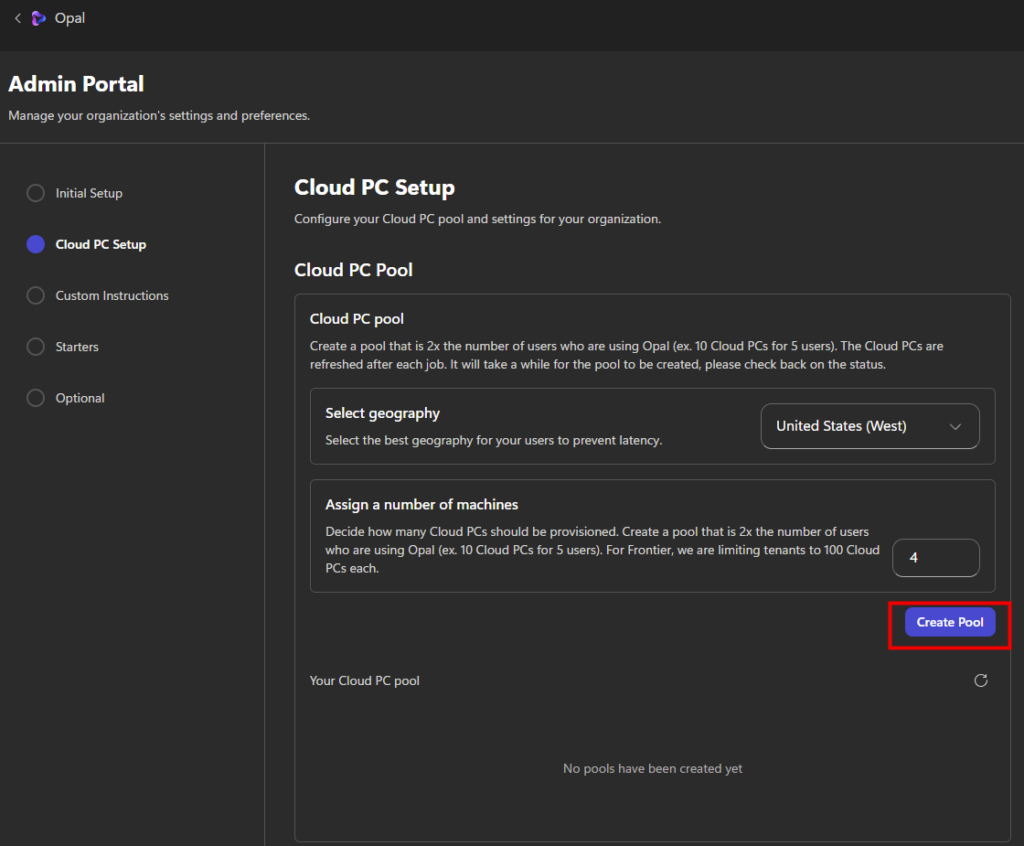
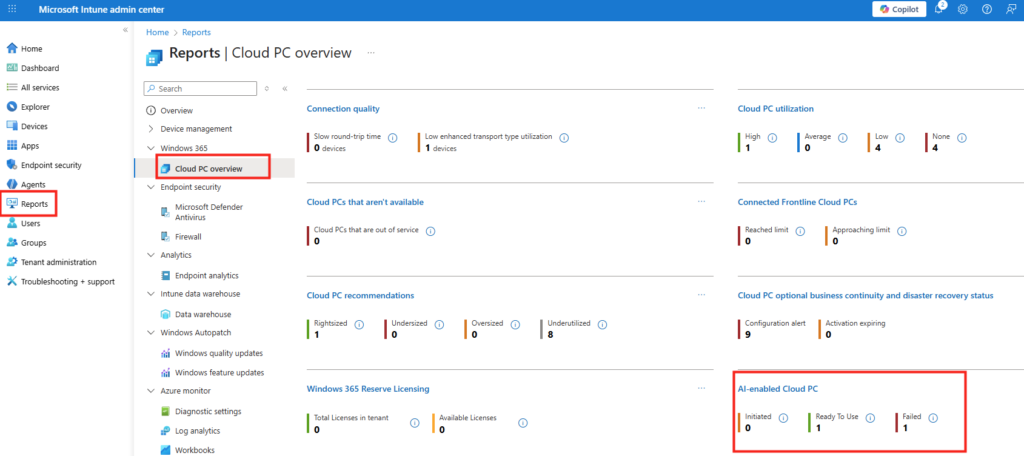
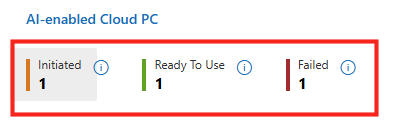
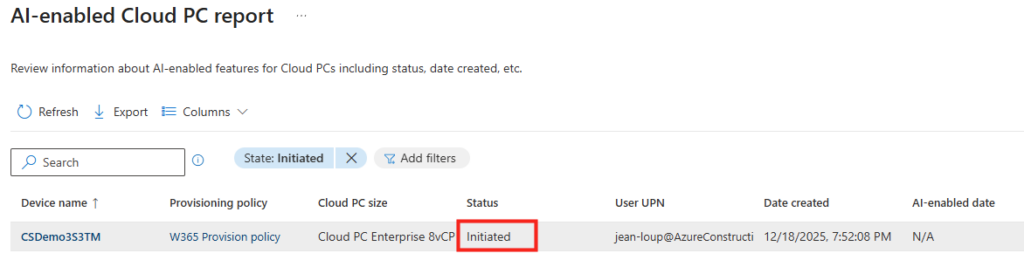
La création du pool de machines peut prendre plusieurs minutes. Vous pourrez suivre l’état d’avancement directement dans cette section. Ce pictogramme vous indique l’état en cours du provisionnement, ou du re-provisionnement quand un traitement Opal est terminé :
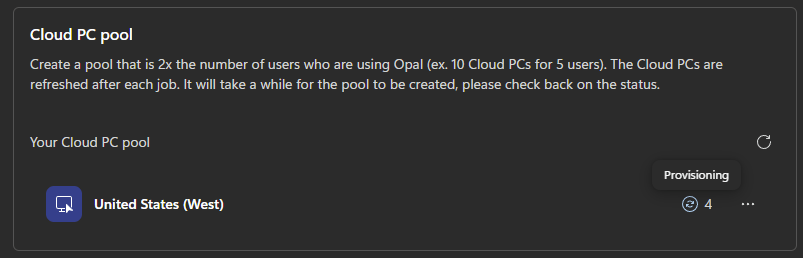
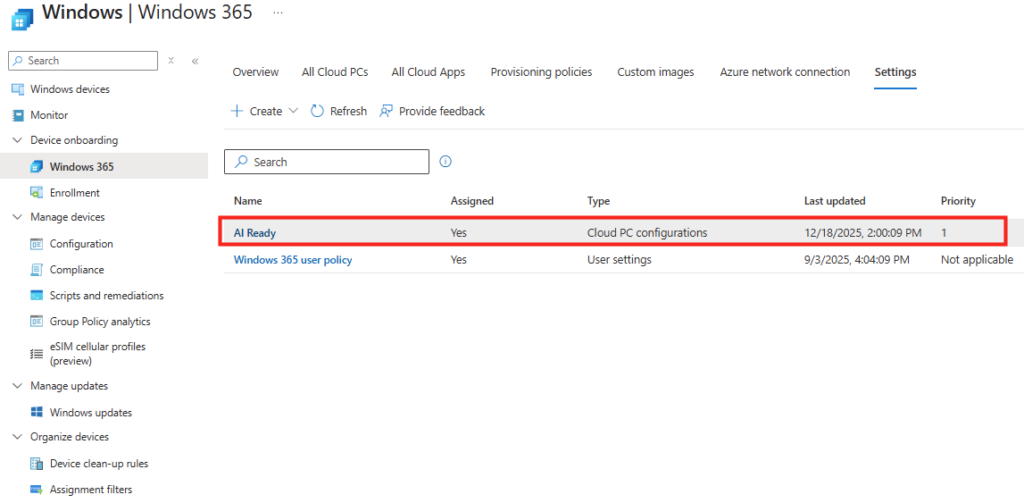
Environ 30 minutes plus tard, les machines Windows 365 sont provisionnées sur votre tenant :
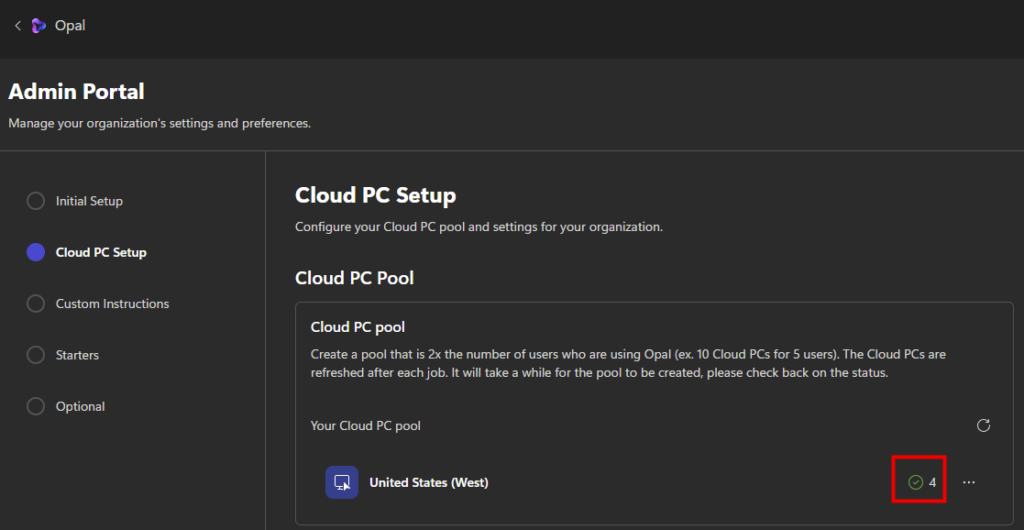
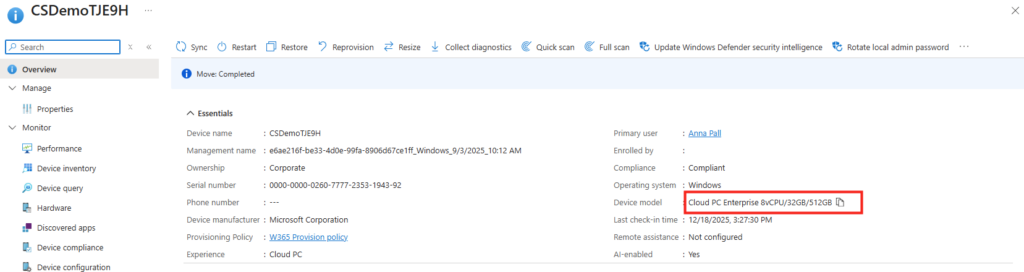
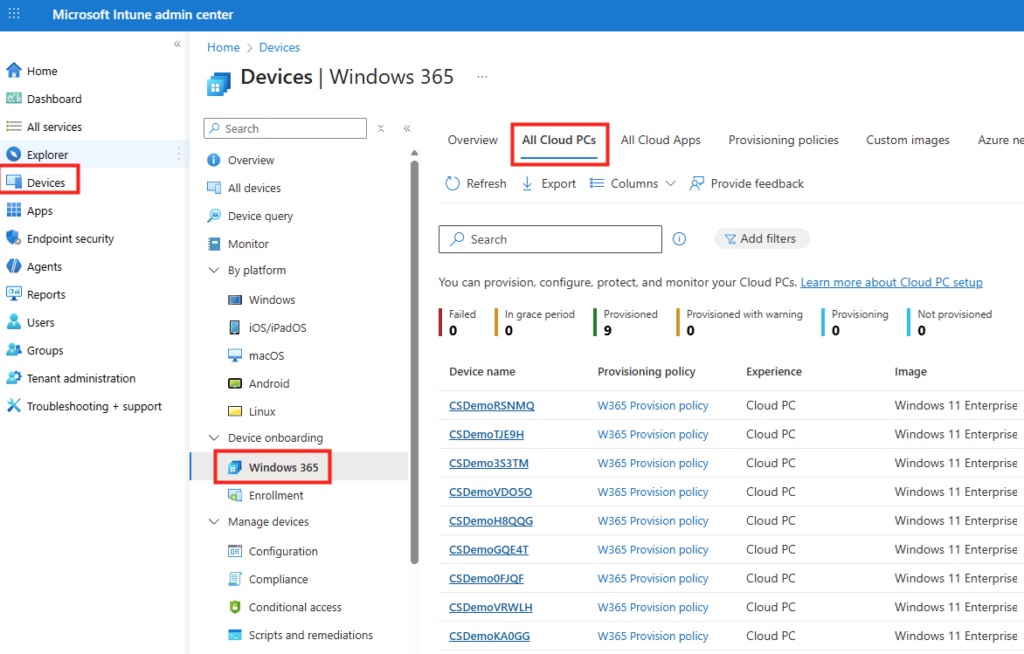
Vous pouvez même retrouver ces nouvelles machines Windows 365 sur votre portail Intune :
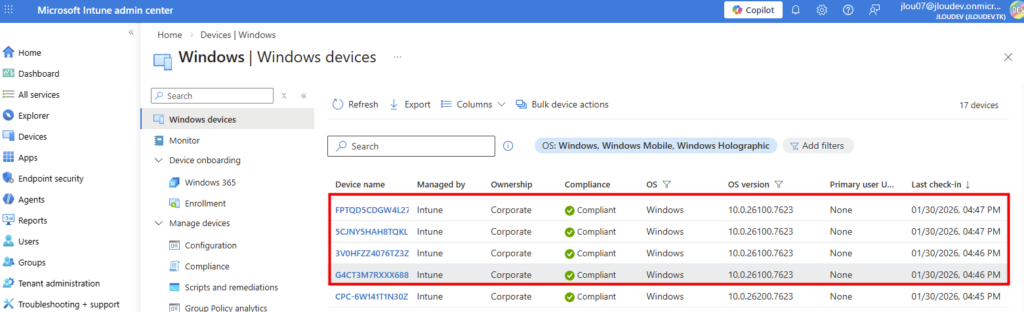
Le modèle de machines Windows 365 est d’ailleurs spécifique à ce service d’IA :
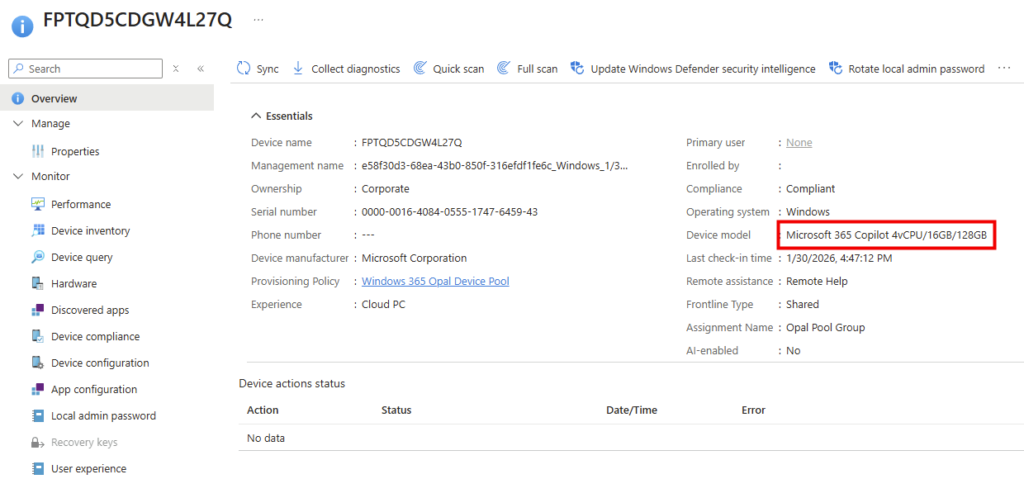
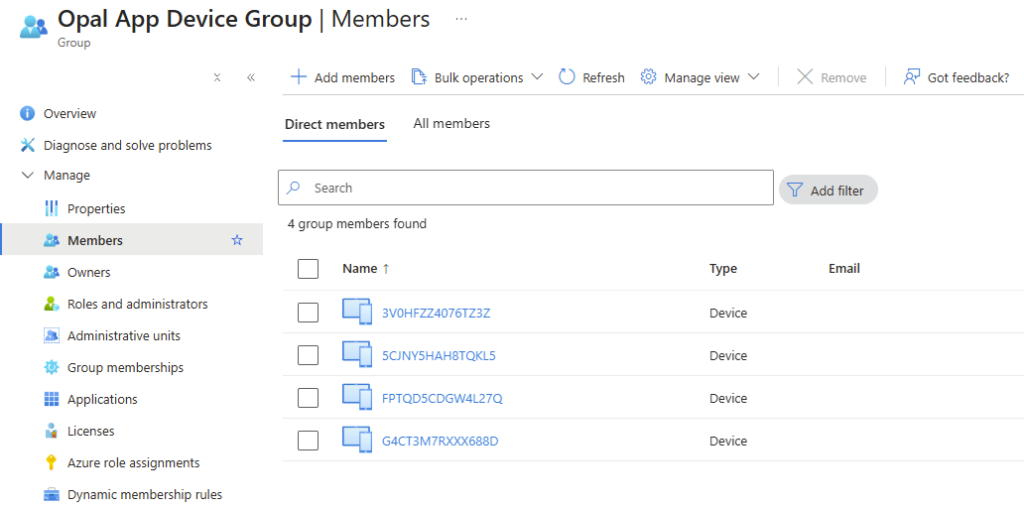
Comme attendu, le groupe dynamique de machines Windows 365 regroupe bien celles-ci :
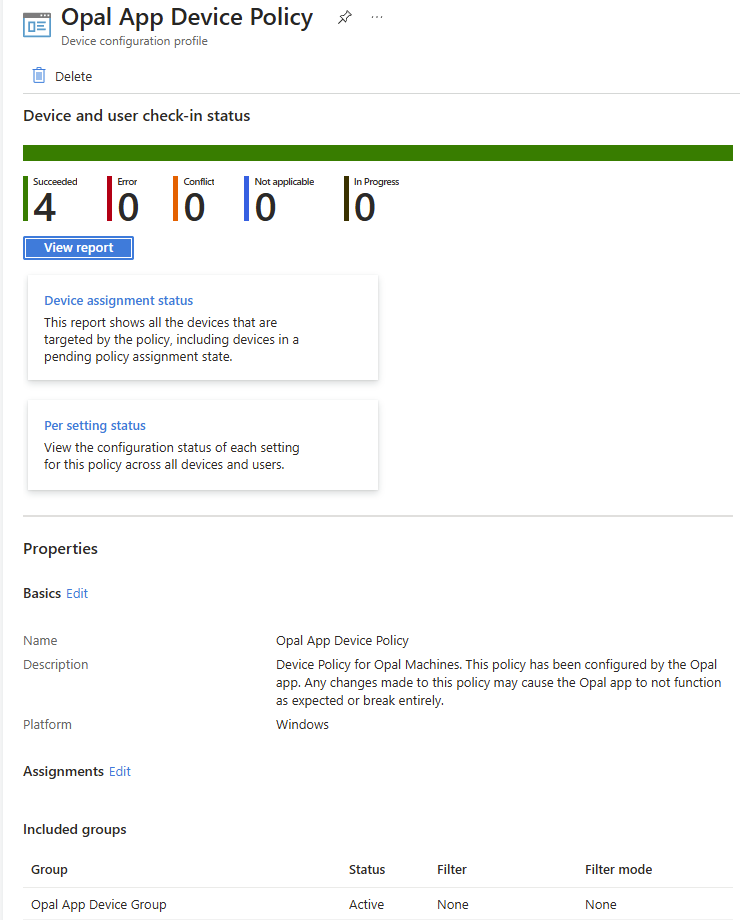
Et la police créée via le script d’onboarding s’affecte bien sur les machines Windows 365 :
De retour sur la console d’administration, ajoutez le ou les sites auxquels les machines auront accès pour effectuer leurs tâches. Dans mon test, je vais ajouter le site suivant :
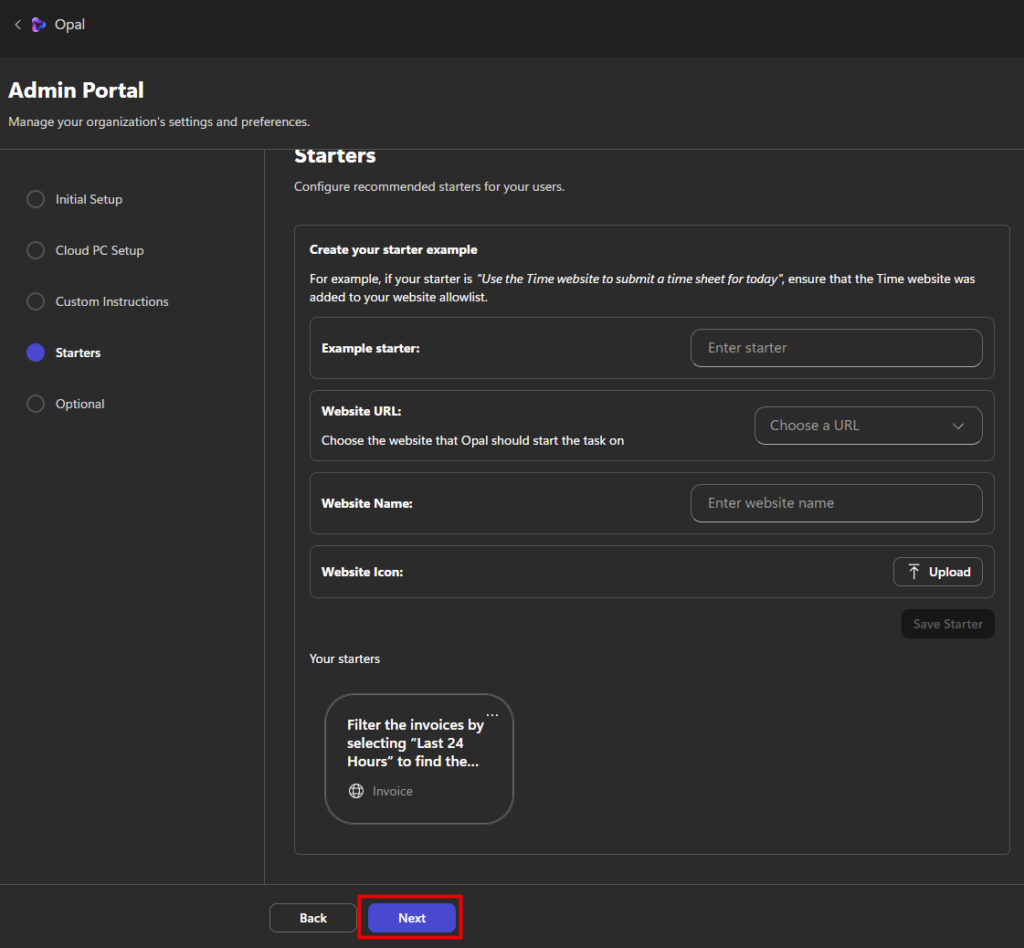
https://computerusedemos.blob.core.windows.netL’écran Starters permet de créer des actions prédéfinies proposées aux utilisateurs d’Opal. Un starter correspond à une instruction prête à l’emploi, associée à un site web précis, que l’utilisateur pourra lancer en un seul clic :
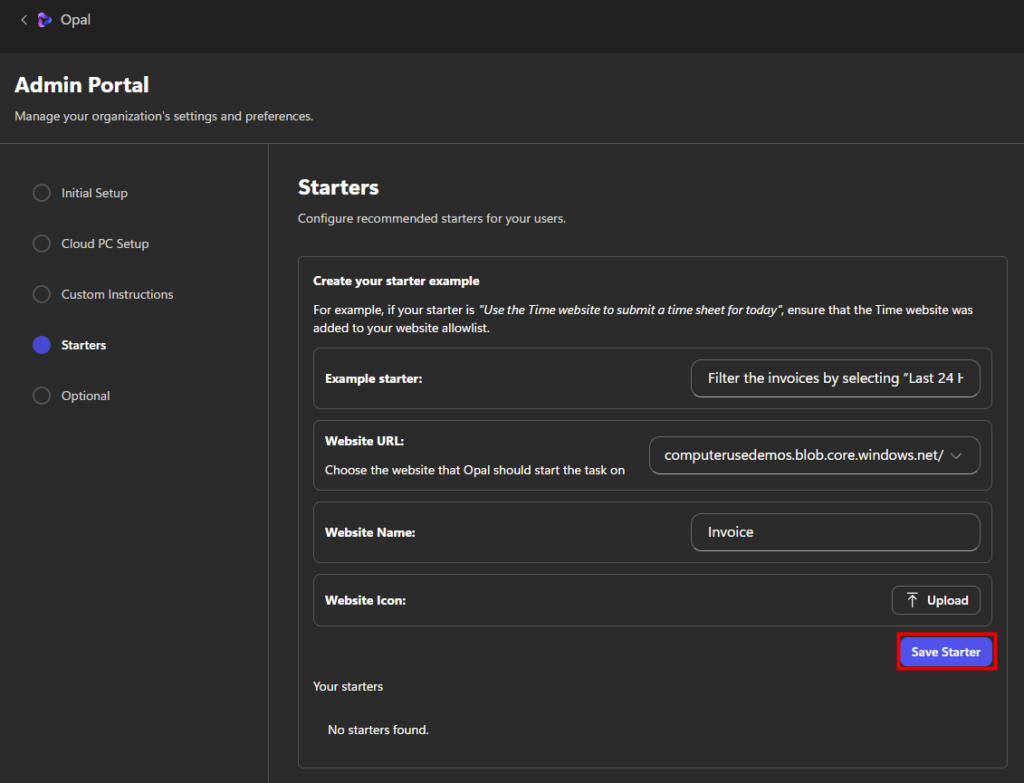
Une fois un premier Starter créé, cliquez sur Suivant :
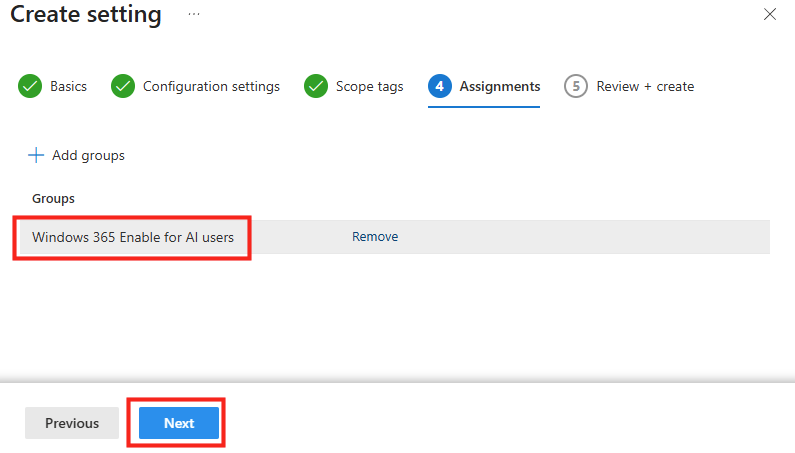
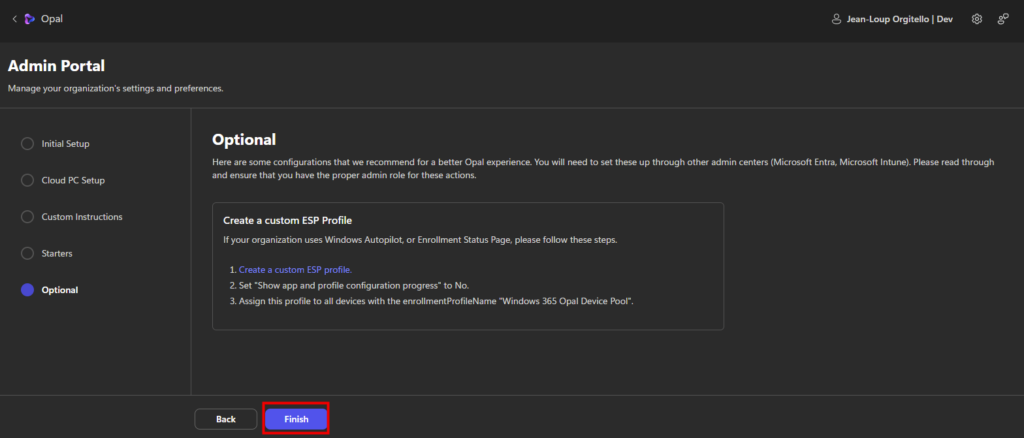
Microsoft recommande de créer un profil Enrollment Status Page (ESP) personnalisé, spécifiquement pour les machines Opal. Ce profil permet notamment de :
- réduire le temps d’initialisation du Cloud PC,
- éviter les écrans ESP bloquants,
- empêcher l’attente d’applications non nécessaires.
Le profil ESP doit être assigné aux appareils correspondant au pool Opal, à l’aide du critère :
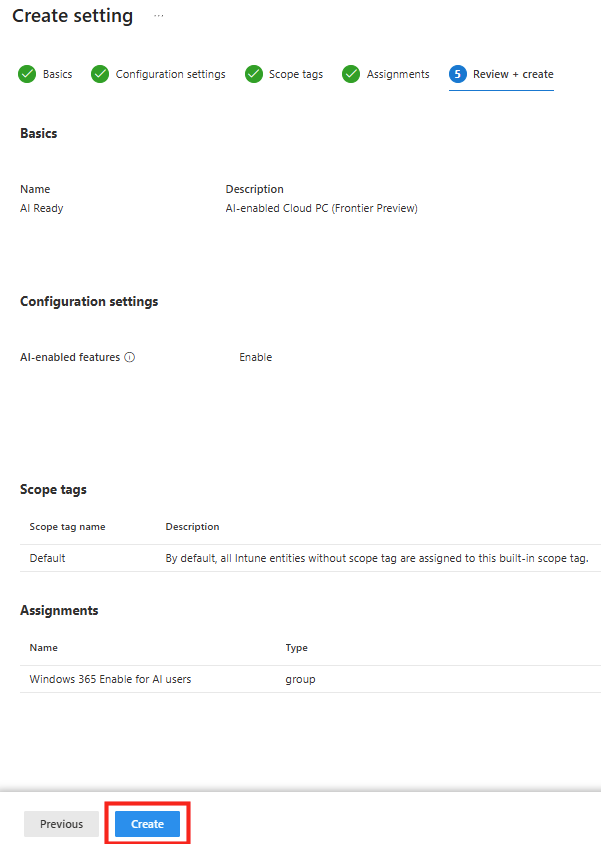
enrollmentProfileName = "Windows 365 Opal Device Pool"Une fois la configuration entièrement complétée, cliquez ici pour terminer le processus :
La suite consiste désormais à créer vos premiers scénarios métier afin de transformer Opal en véritable agent opérationnel capable d’exécuter des tâches concrètes sur des applications web réelles.
Etape IV – Premiers tests d’Opal :
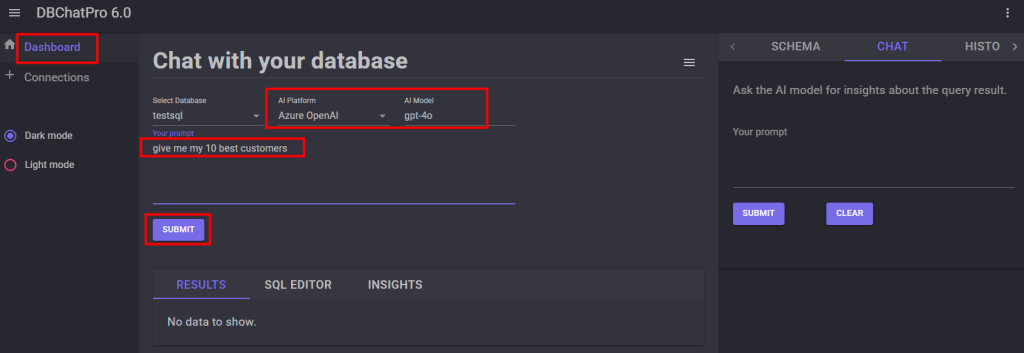
L’URL pour utiliser Opal est celle-ci :
https://opal.frontier.microsoft365.com
Il est aussi possible de retrouver Opal depuis la page d’accueil de Copilot :
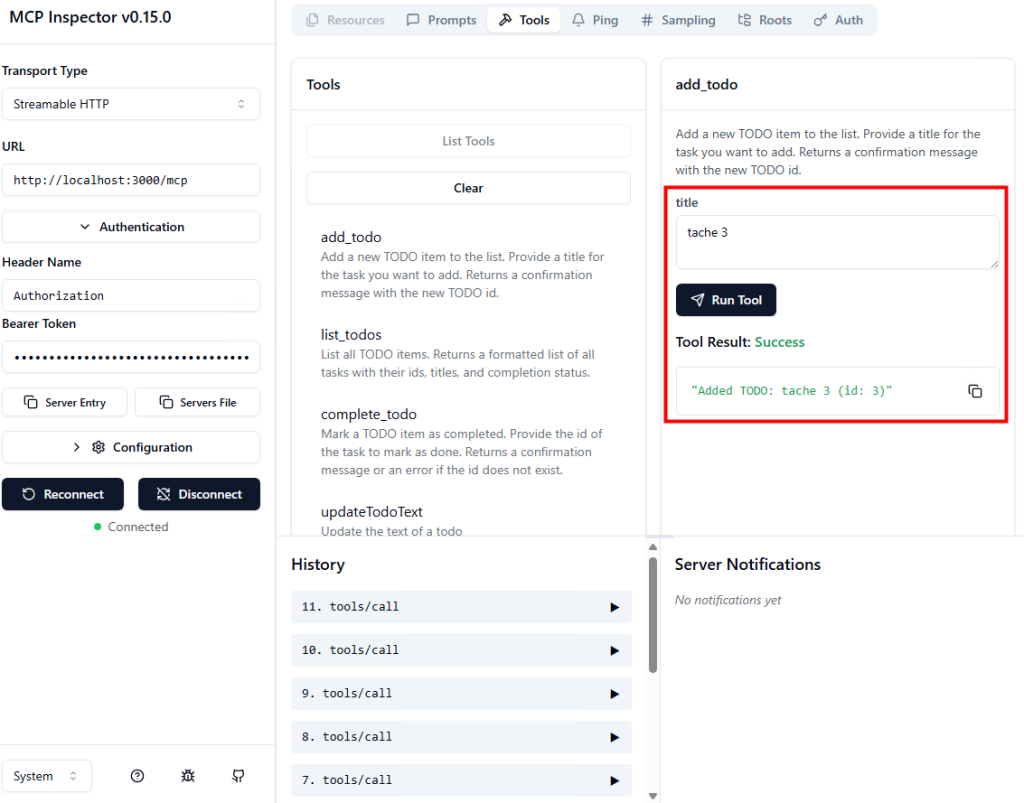
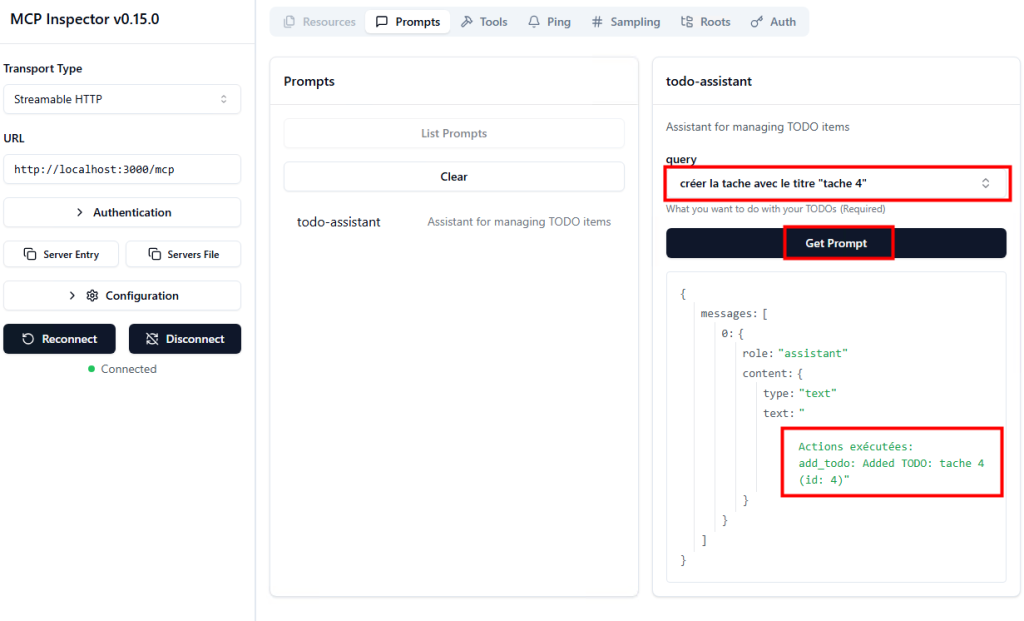
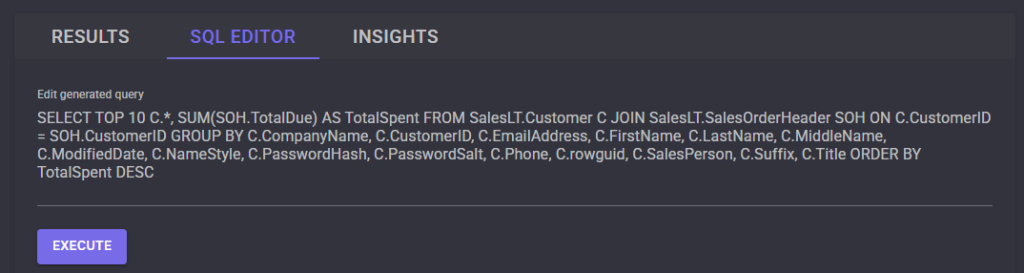
Sur Opal, saisissez le prompt suivant afin d’effectuer plusieurs actions, puis cliquez sur Démarrer :
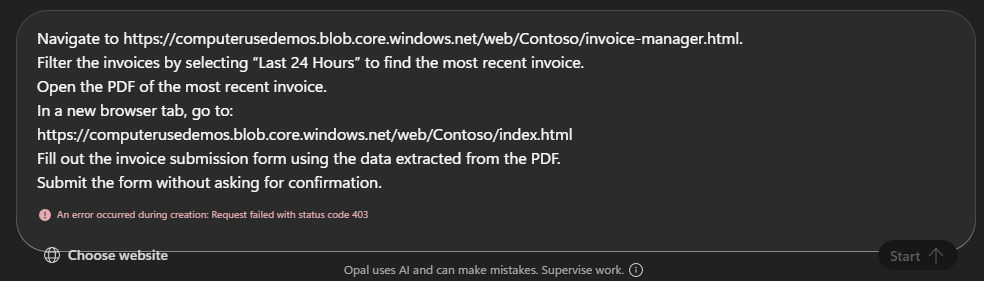
Navigate to https://computerusedemos.blob.core.windows.net/web/Contoso/invoice-manager.html. Filter the invoices by selecting "Last 24 Hours" to find the most recent invoice. Open the PDF of the most recent invoice. In a new browser tab, go to:
https://computerusedemos.blob.core.windows.net/web/Contoso/index.html Fill out the invoice submission form using the data extracted from the PDF. Submit the form without asking for confirmation.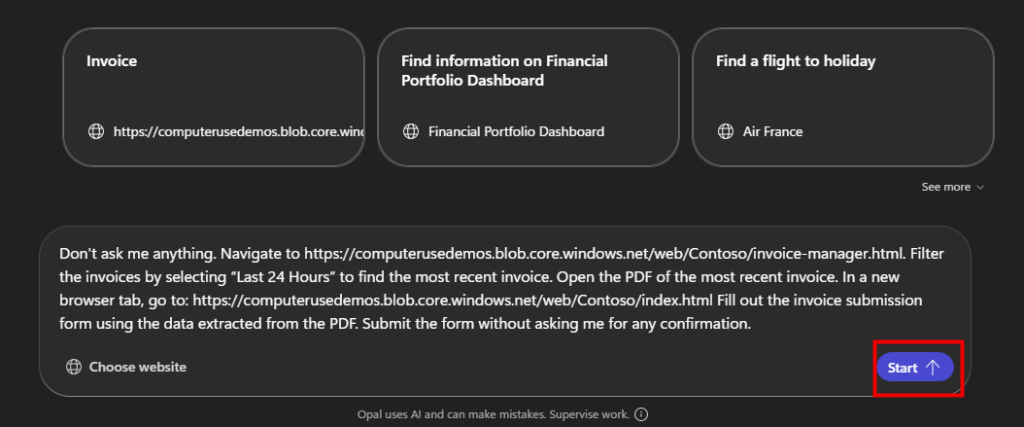
Opal commence par se connecter à une des machines Windows 365 préalablement provisionnées :
Opal attend ensuite que Windows 11 finalise sa configuration OS :
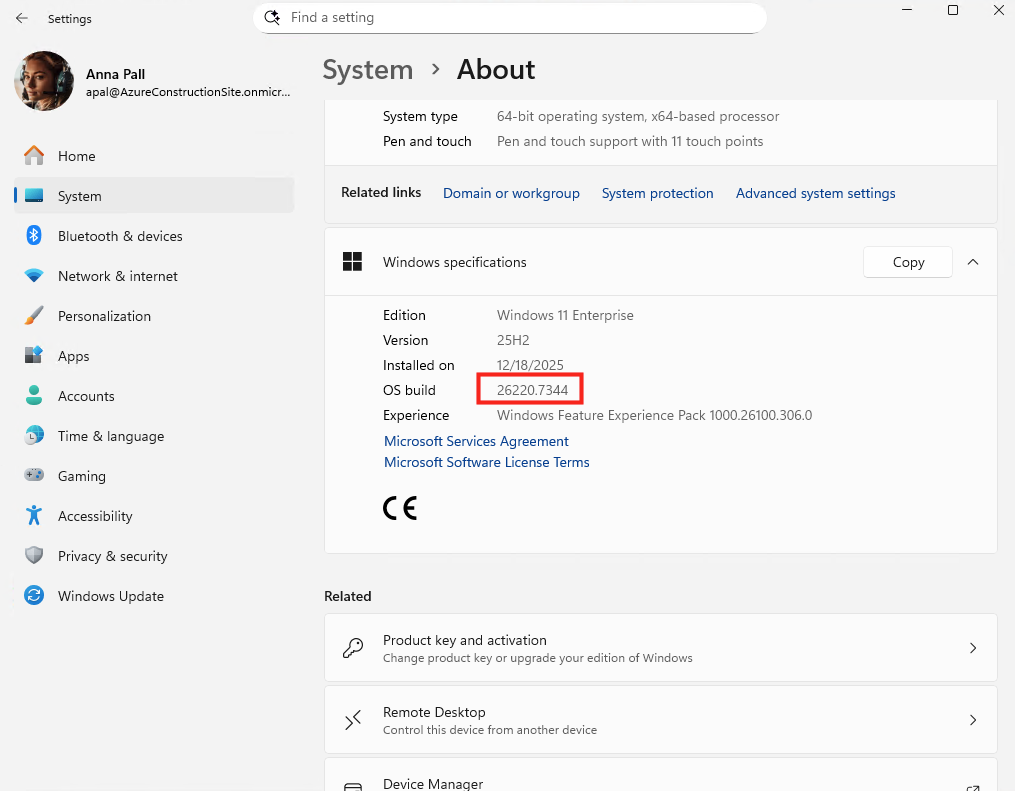
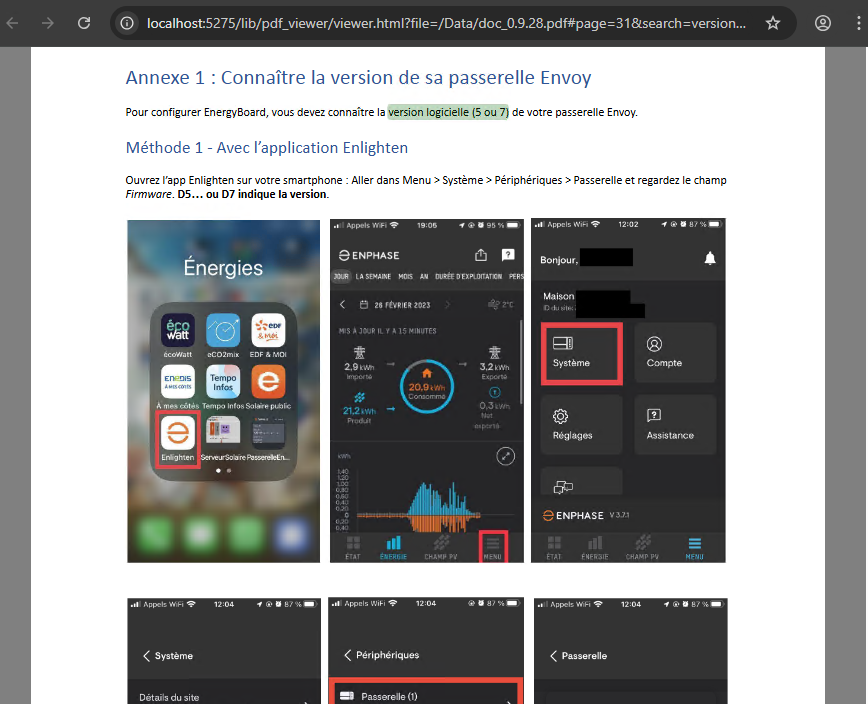
Si besoin, cliquez sur l’image de la VM pour avoir plus de détail. Comme ici, Edge s’ouvre et affiche le site web contenant les factures :
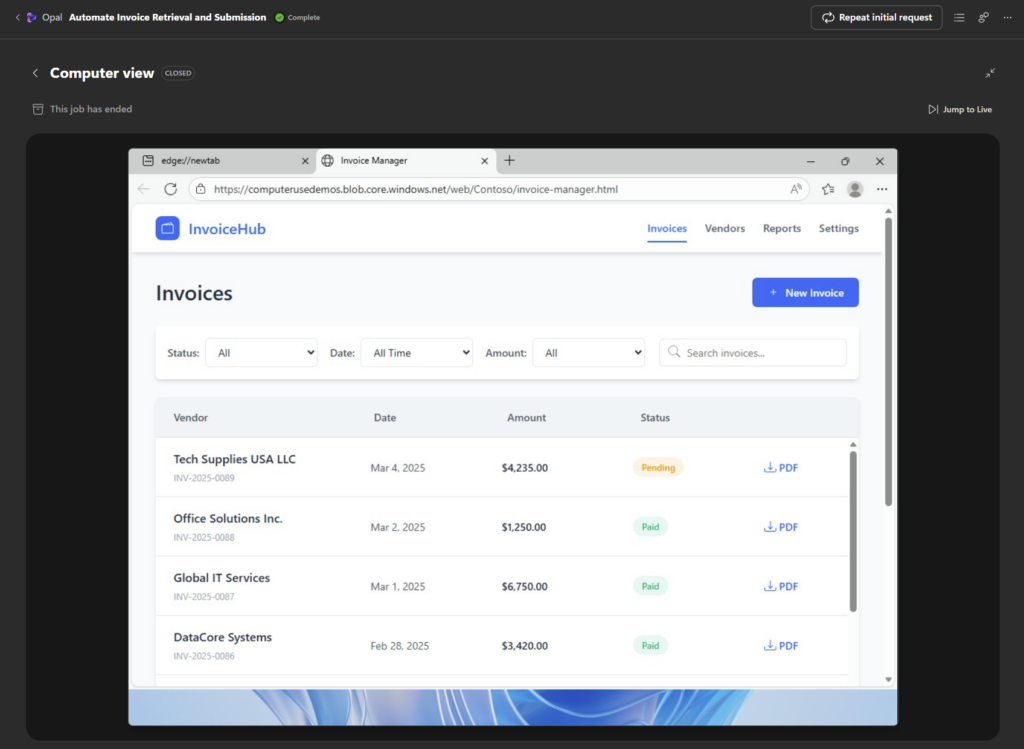
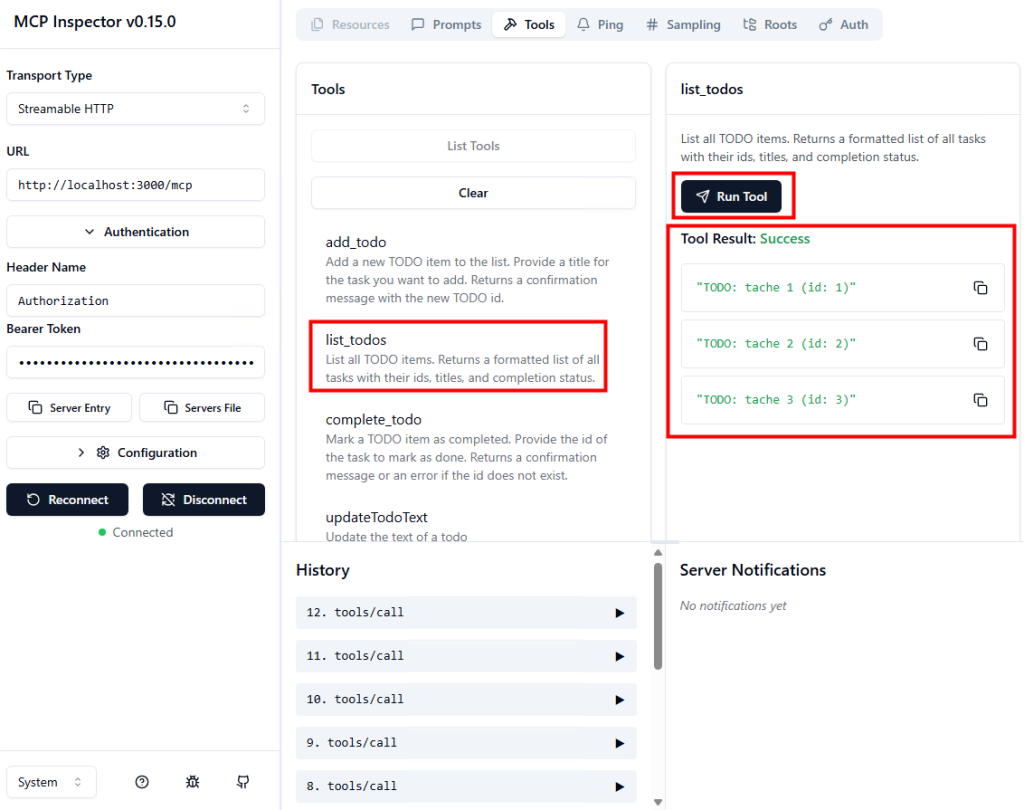
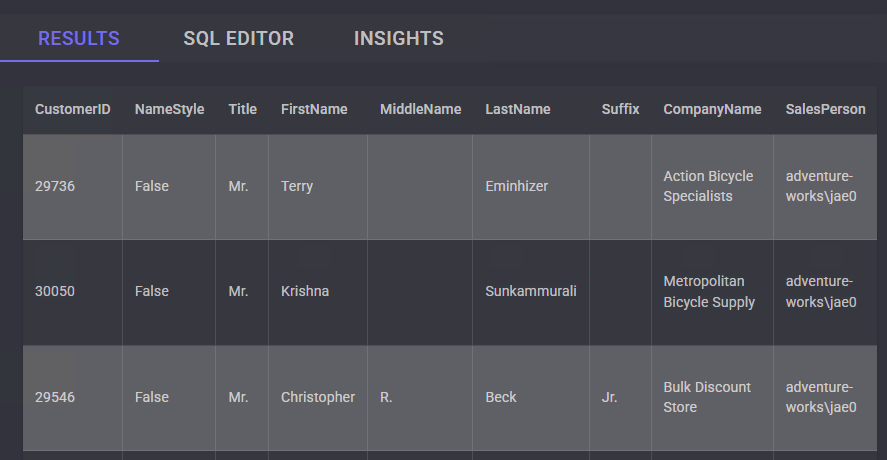
La dernière facture est ouverte pour y récupérer toutes les informations :
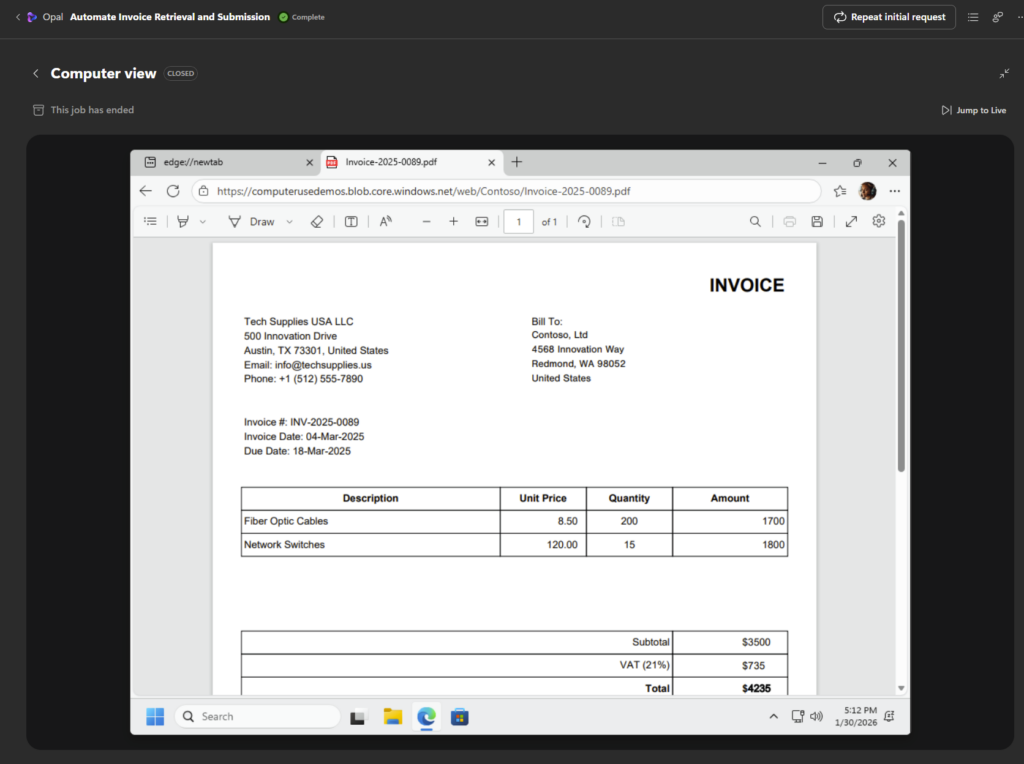
Un nouvel onglet s’ouvre dans Edge afin de saisir la nouvelle facture dans le système de comptabilité :
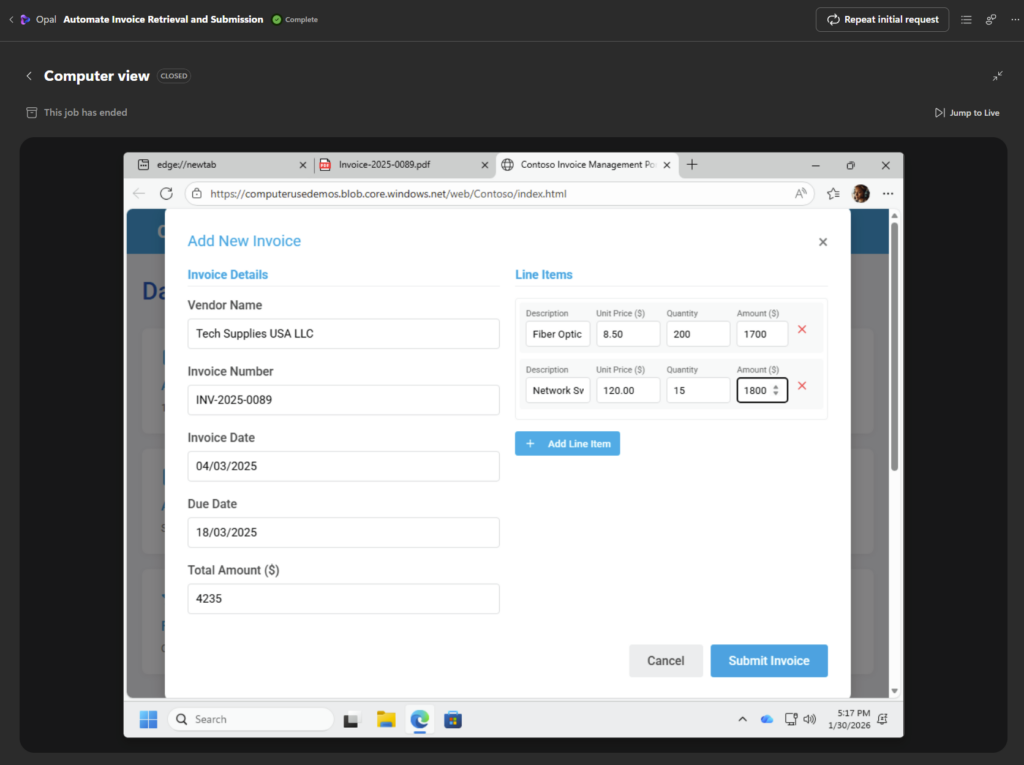
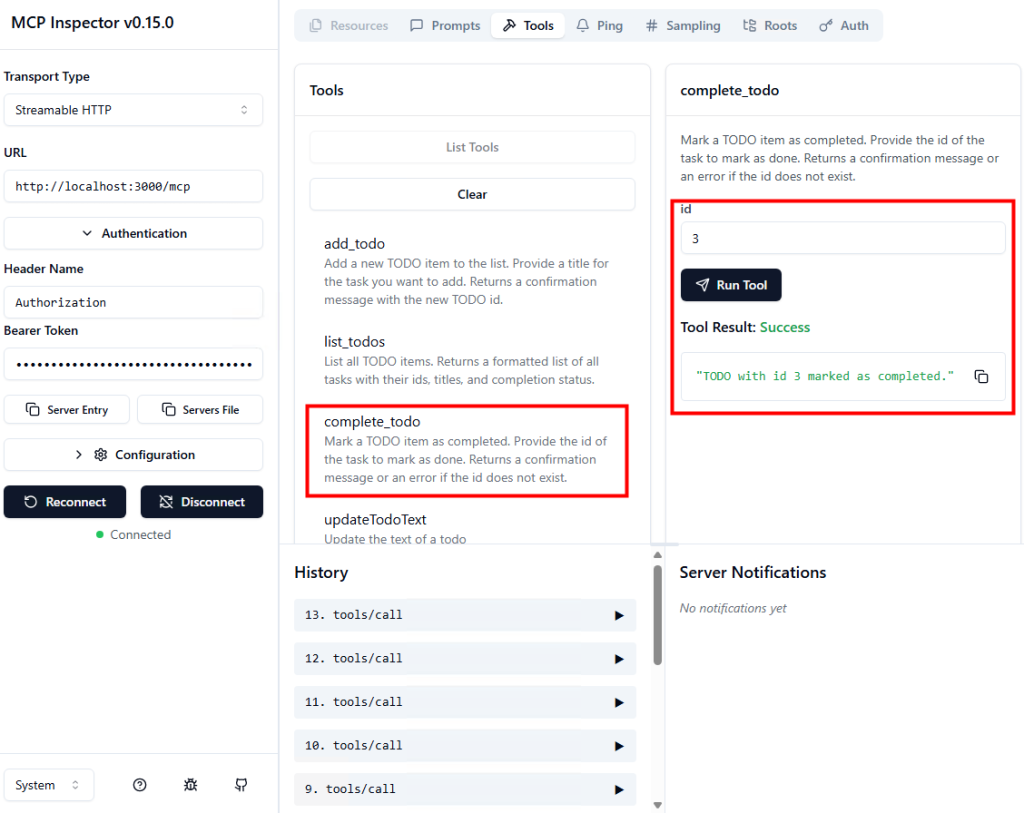
Une fois la saisie complète, une notification apparaît à la fin du traitement de saisie :
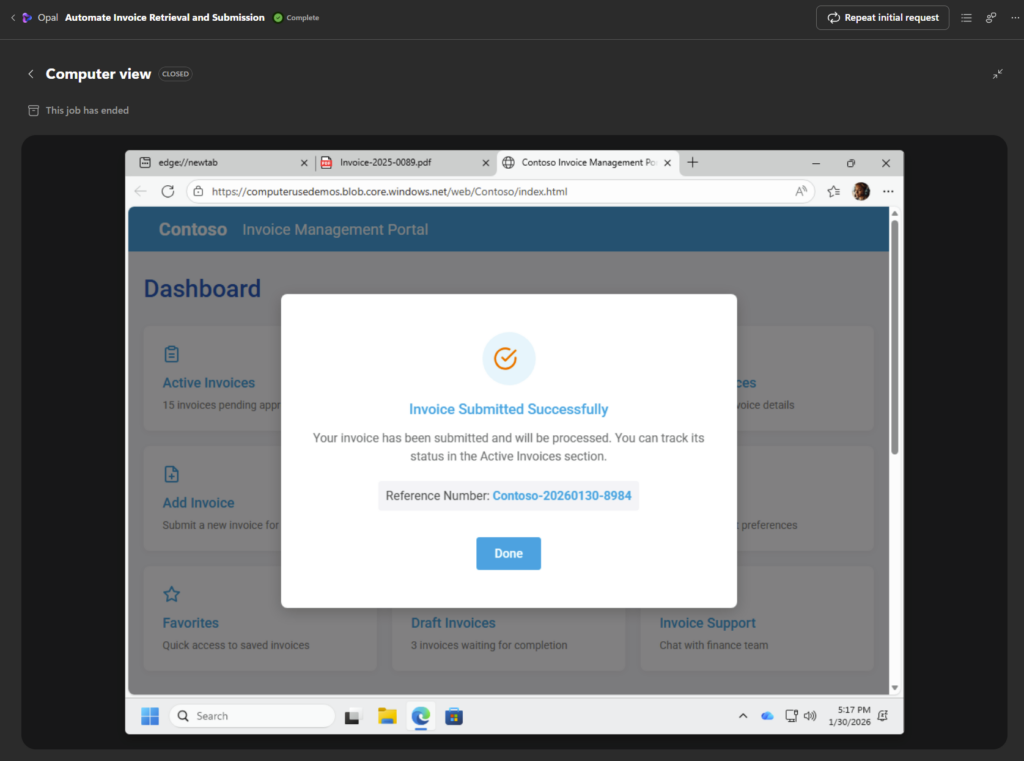
Opal compare l’état obtenu aux actions demandées :
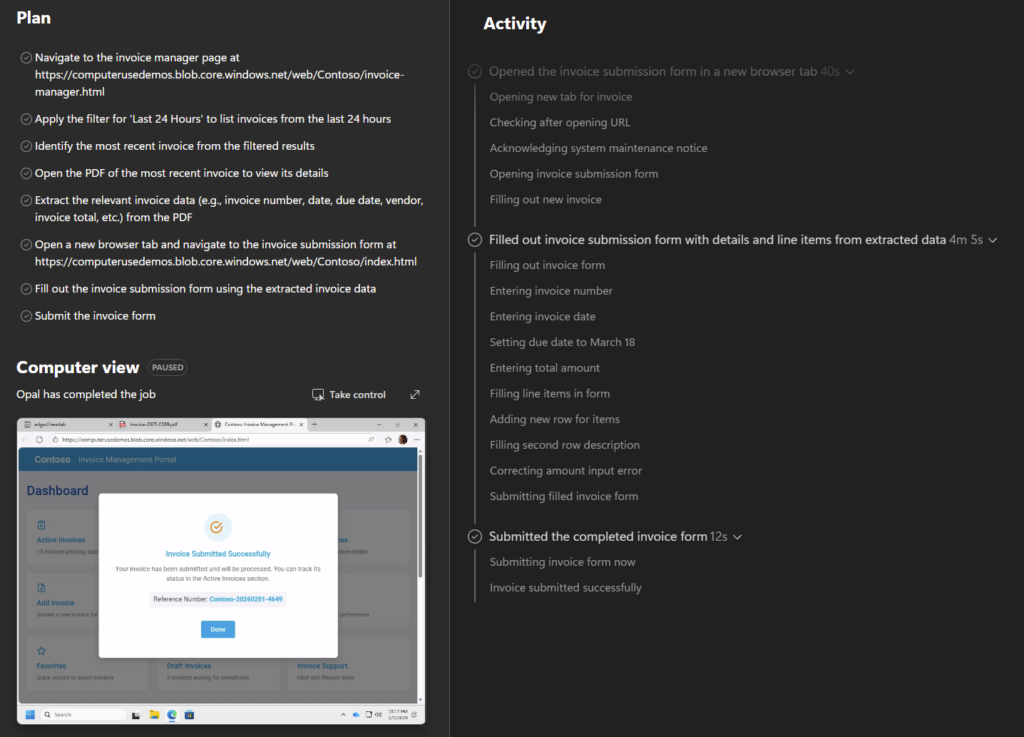
Une dernière phase de revue est déclenchée afin que l’utilisateur puisse contrôler le travail effectué :
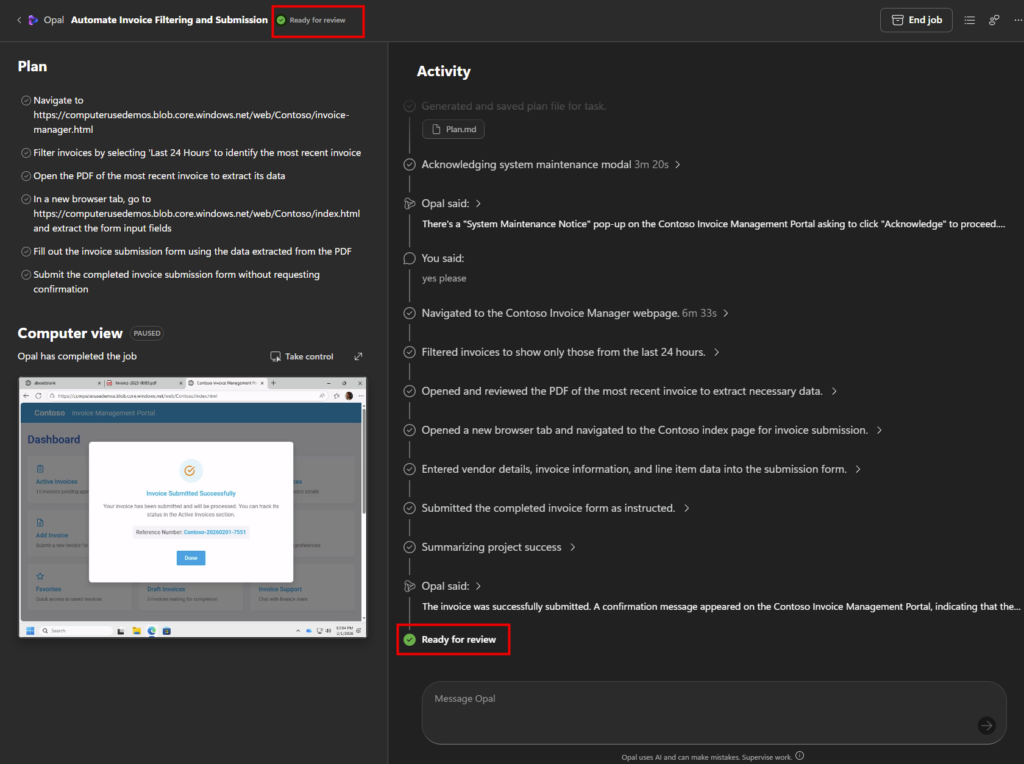
L’utilisateur n’a qu’à confirmer pour que le travail soit considéré comme terminé :

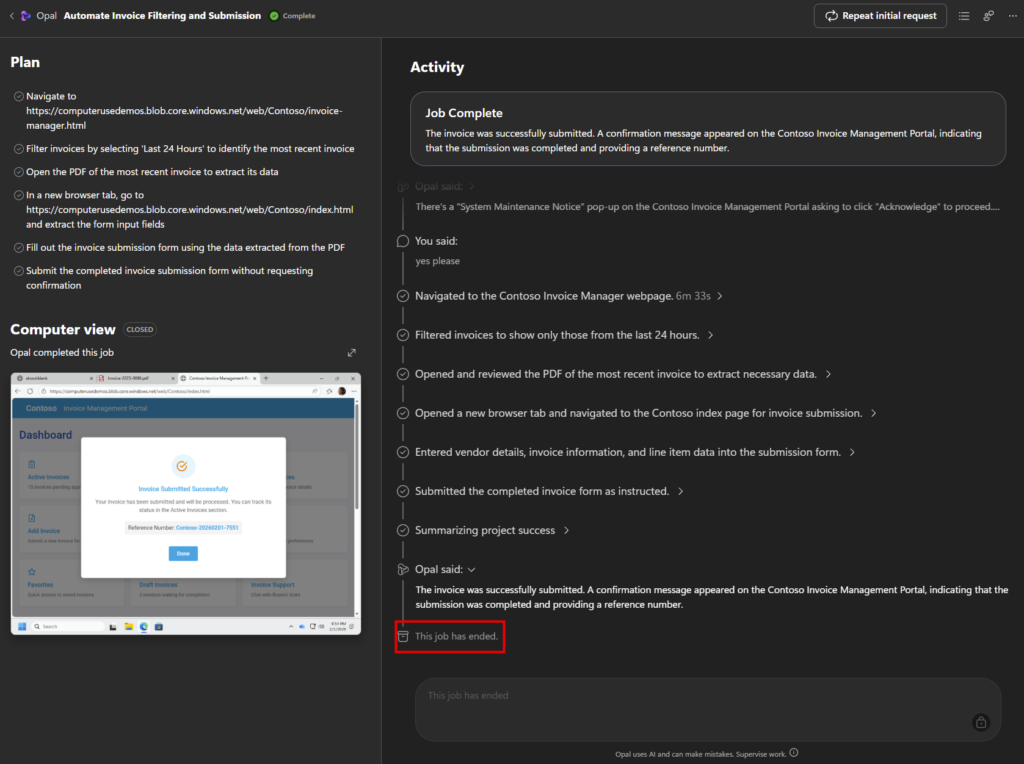
Afin de vous faire une meilleure idée du traitement effectué par Opal, le voici en fonctionnement :
Etape V – Quelques remarques sur Opal :
Au travers de différents tests, plusieurs points méritent d’être soulignés :
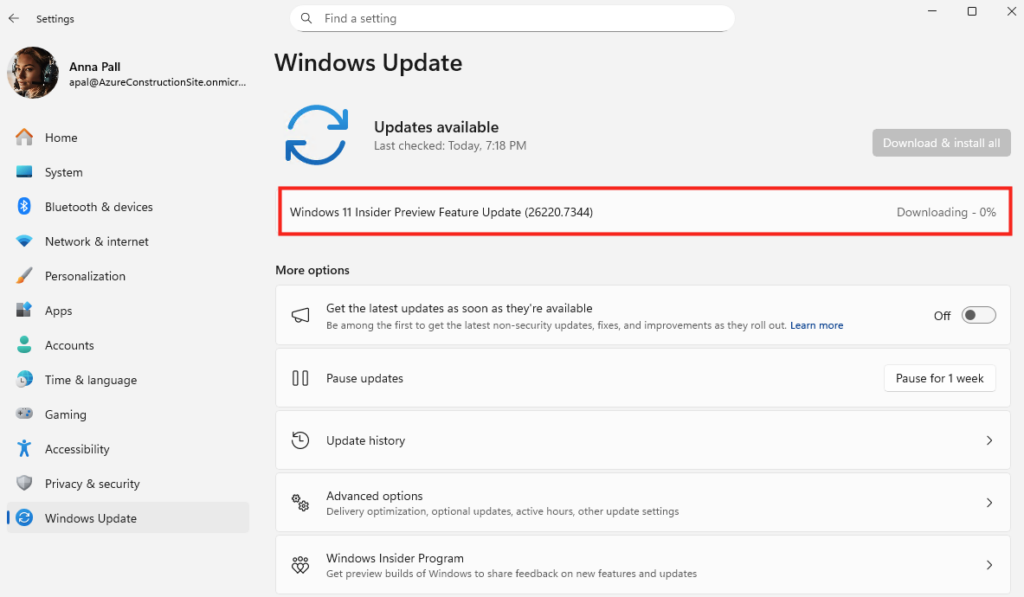
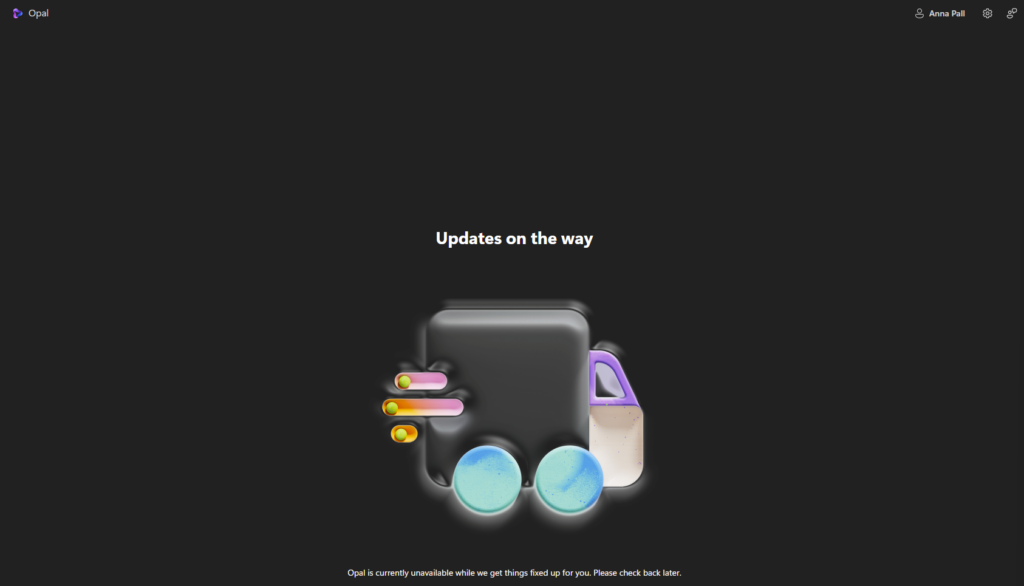
- Sans finalisation de la configuration d’Opal, le message suivant apparaît pour les utilisateurs :
- Sans licence Microsoft 365 Copilot, l’accès à Opal retourne une erreur 403 :
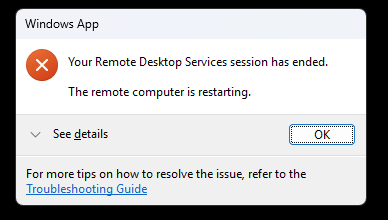
- Après chaque traitement, la machine Windows 365 utilisée est réinitialisée et repart sur un état propre :
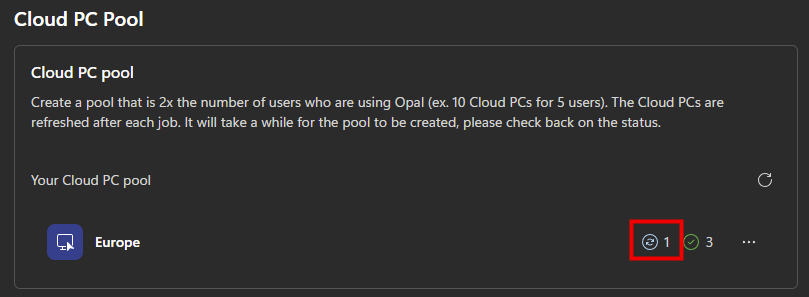
- Il faut attendre environ 15 minutes avant que la machine soit de nouveau disponible pour un autre traitement :
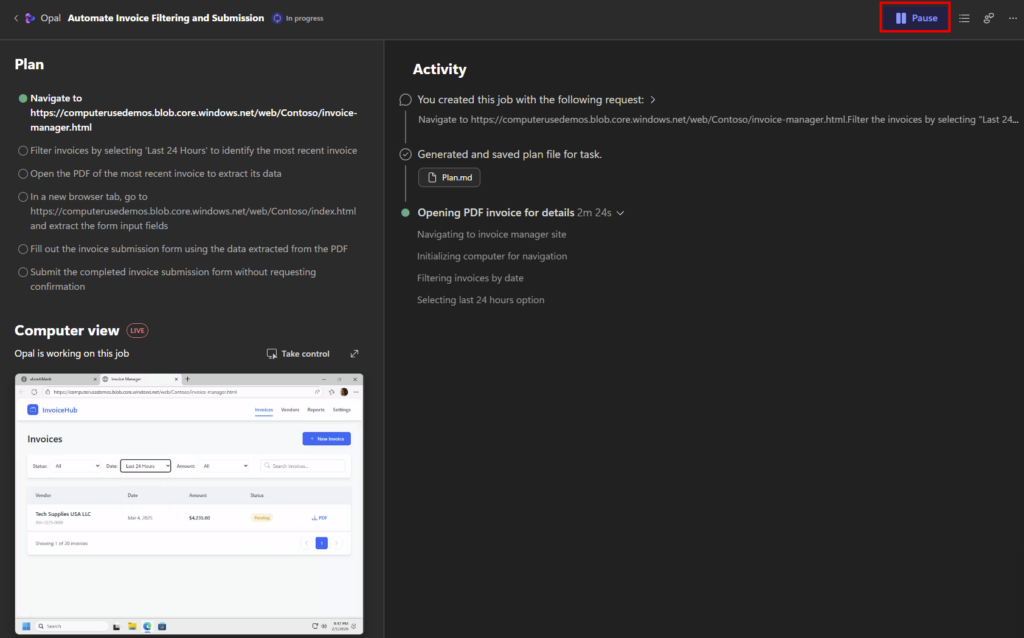
- Le bouton Pause permet de suspendre temporairement l’exécution sans annuler le scénario, tout en conservant le contexte courant. Cela est très utile si l’utilisateur souhaite reprendre la main quand l’agent part dans une mauvaise direction :
- l’agent arrête immédiatement d’exécuter des actions (clics, saisies, navigation, appels d’outils)
- le contexte et l’état courant sont conservés (où il en est dans la tâche)
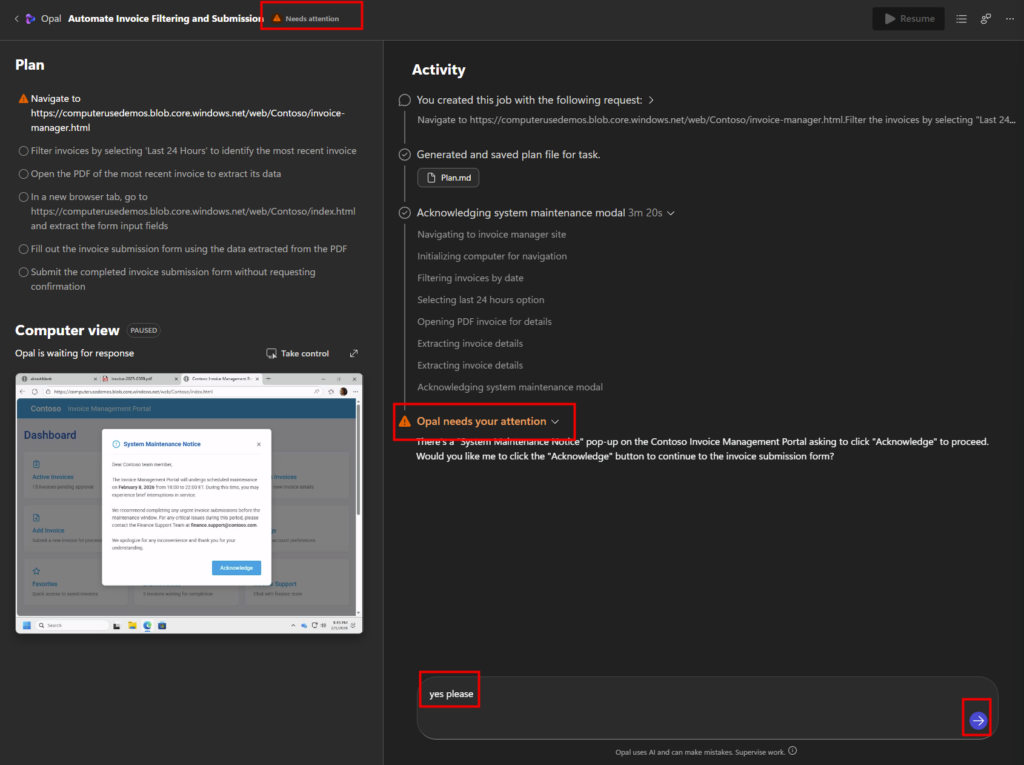
- Opal peut décider de s’arrêter de lui-même s’il rencontre une situation ambiguë ou non résoluble, et attend alors une instruction humaine.
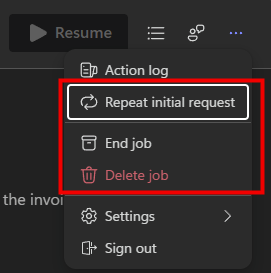
- Durant la phase de traitement d’Opal, 3 autres actions sont possibles :
- Répéter la requête initiale : Cette action relance exactement le même job depuis le début, en réutilisant la requête initiale, les mêmes instructions et le même contexte de départ. C’est comme cliquer sur “Rejouer le scénario”, sans modifier quoi que ce soit.
- Terminer le travail : Cette action met fin au job en cours et empêche toute poursuite de ce run, mais le job reste disponible dans l’interface.
- Supprimer le travail : Le job n’est plus visible ni relançable, mais cela ne désactive pas automatiquement un trigger externe (mail, événement, etc.) s’il existe.
Conclusion
Opal marque une rupture importante dans l’approche de l’automatisation chez Microsoft.
Là où Power Automate s’arrête faute d’API, Opal continue grâce à un véritable poste de travail Windows 365 piloté par une IA.
Nous ne sommes plus dans la simple génération de contenu, mais dans l’exécution réelle de tâches métier, au plus proche du travail humain.
Les premiers usages montrent un potentiel considérable, à condition de bien cadrer les périmètres, les accès et les scénarios. On ne parle pas encore d’autonomie totale, mais d’un changement profond dans la manière dont une IA peut interagir avec des systèmes existants.
Opal n’est pas encore prêt pour des processus critiques temps réel, mais il ouvre clairement la voie à une nouvelle génération d’agents opérationnels.