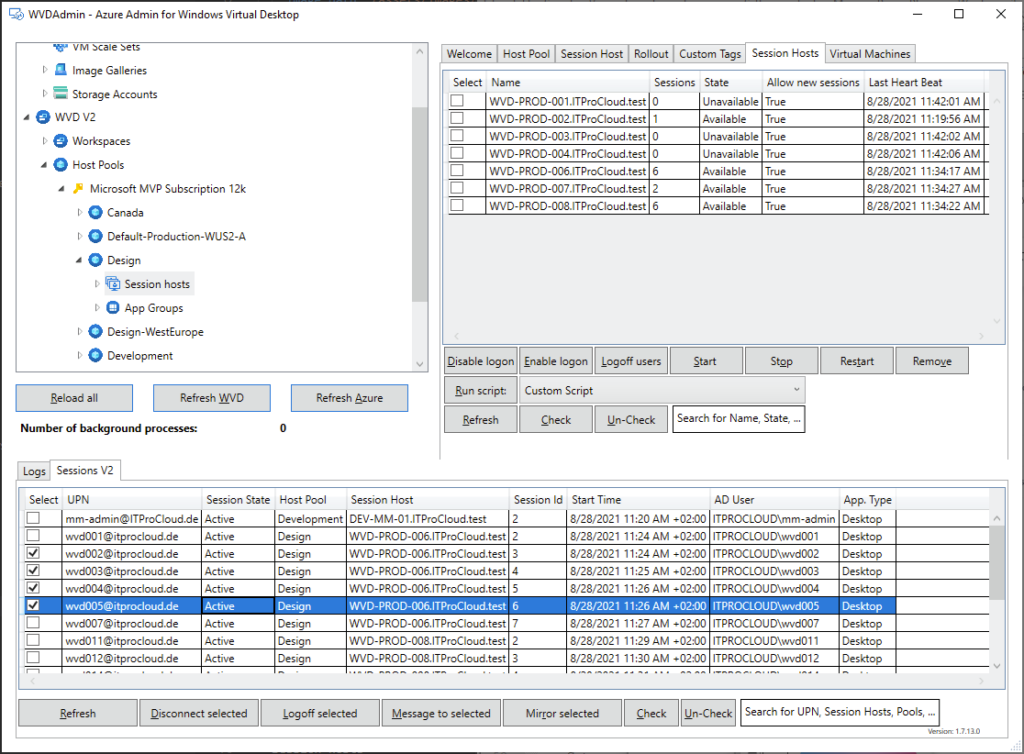
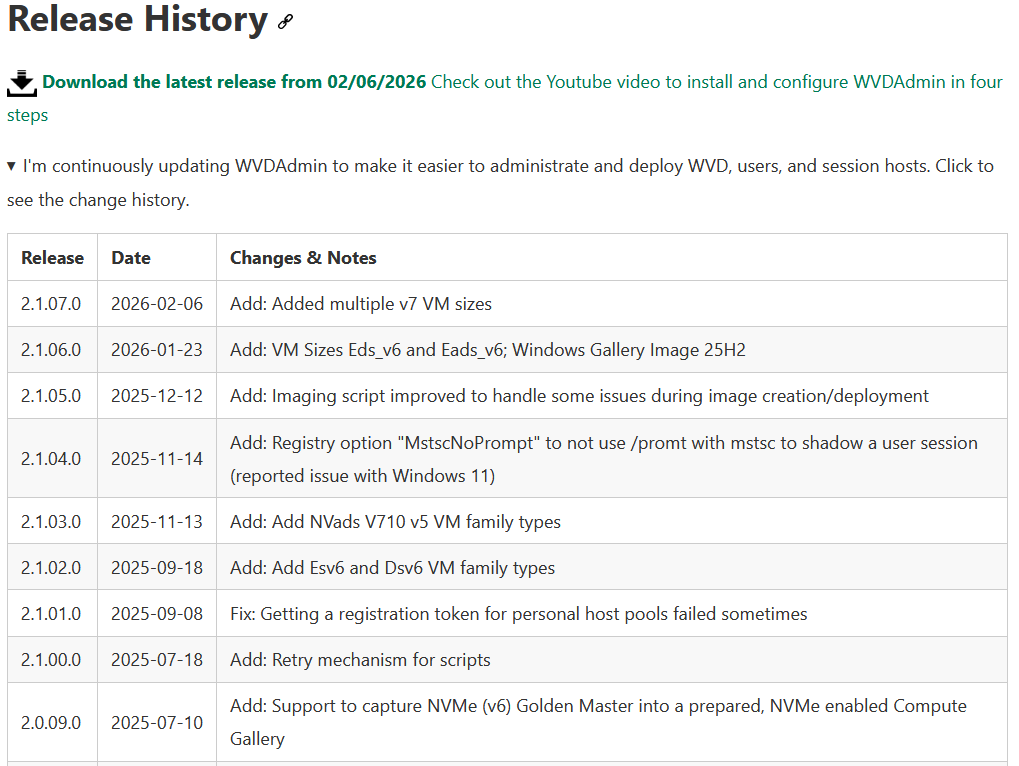
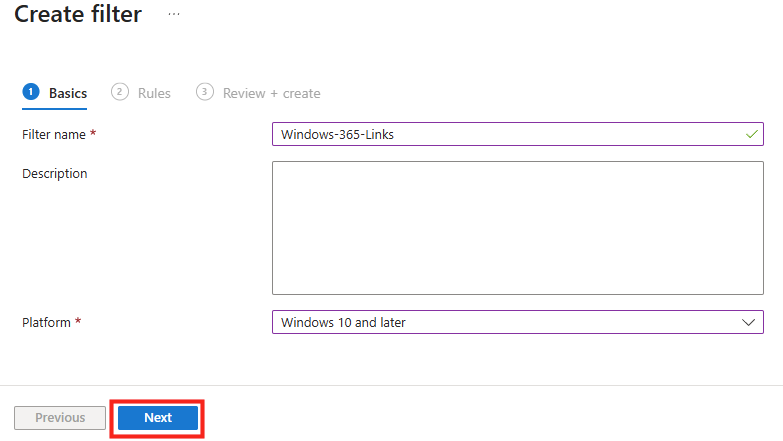
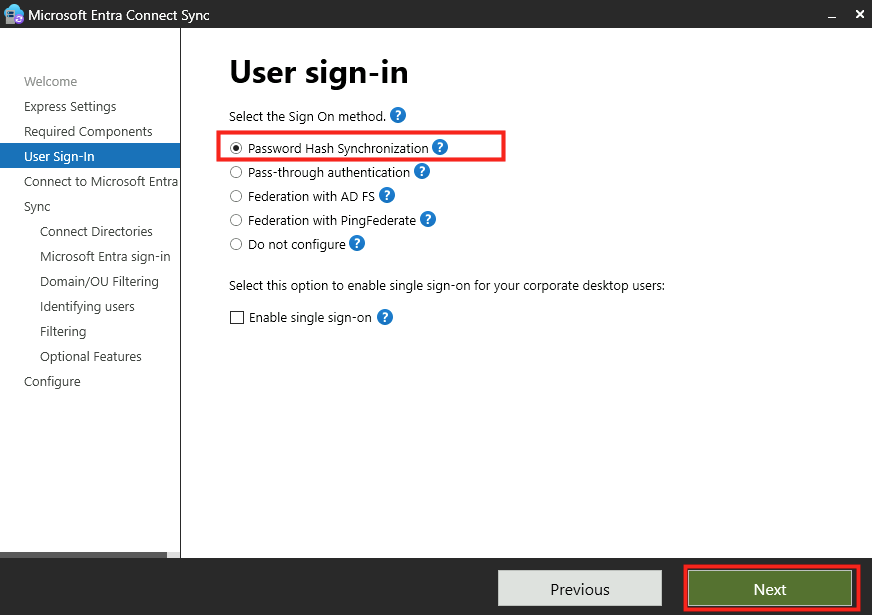
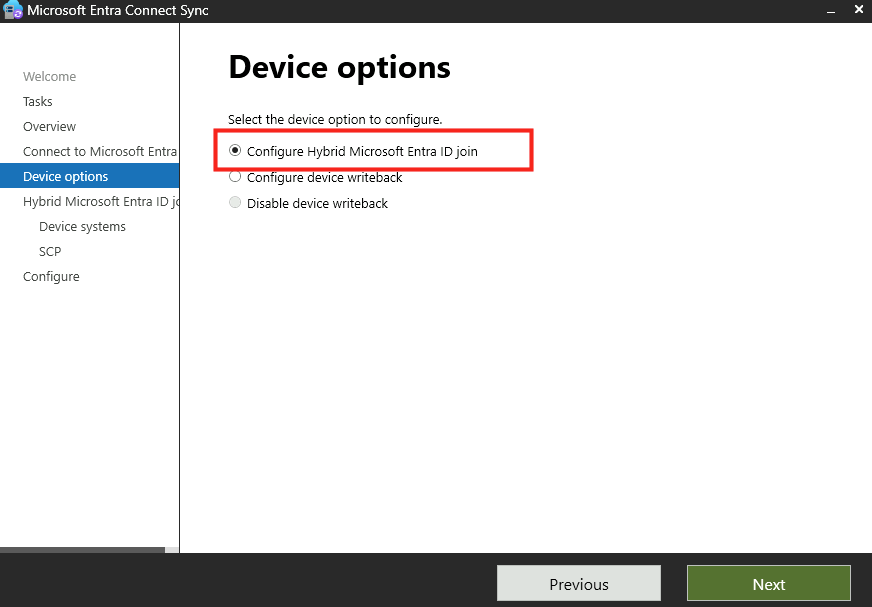
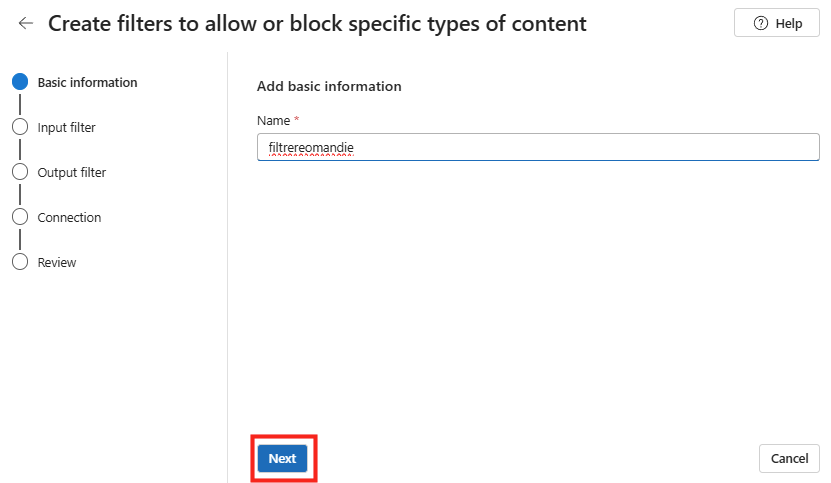
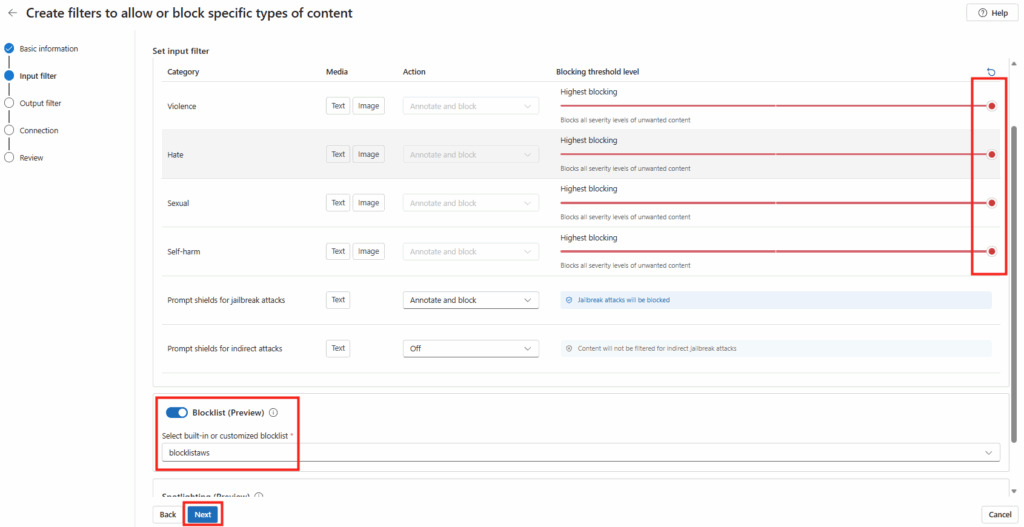
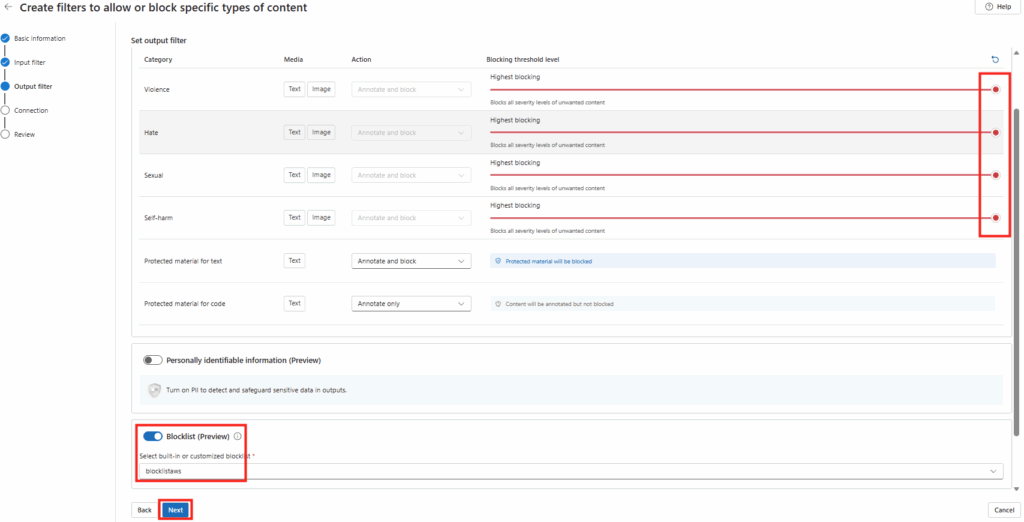
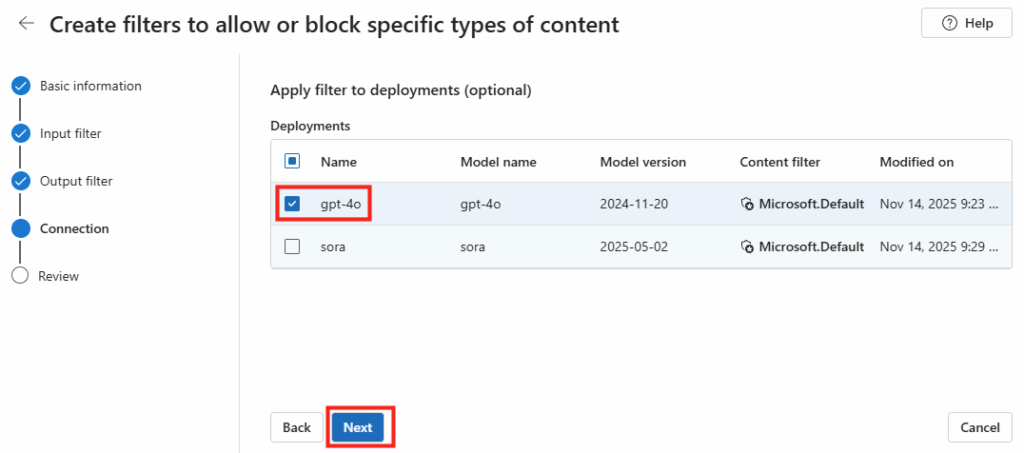
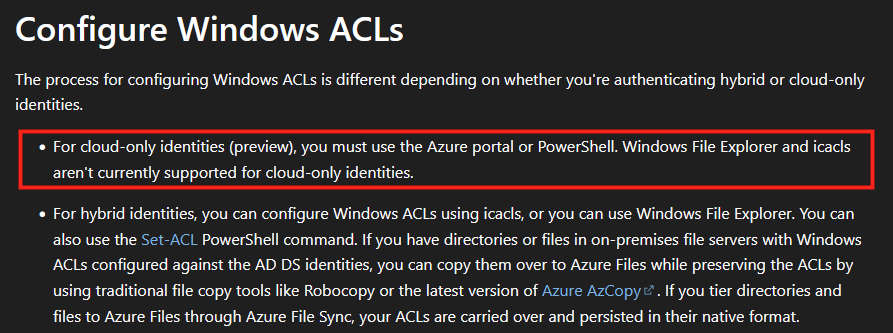
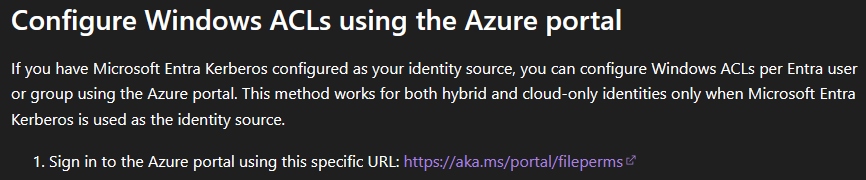
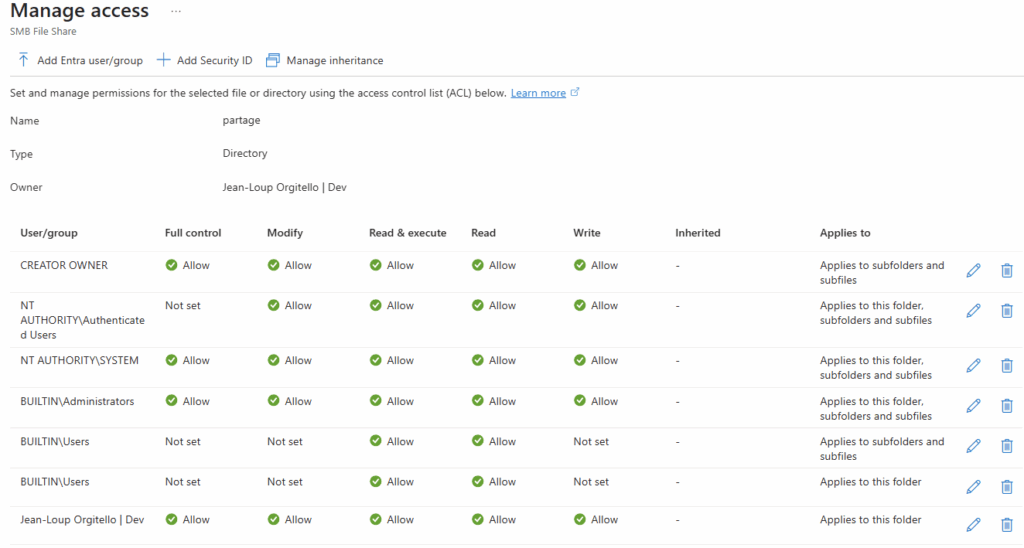
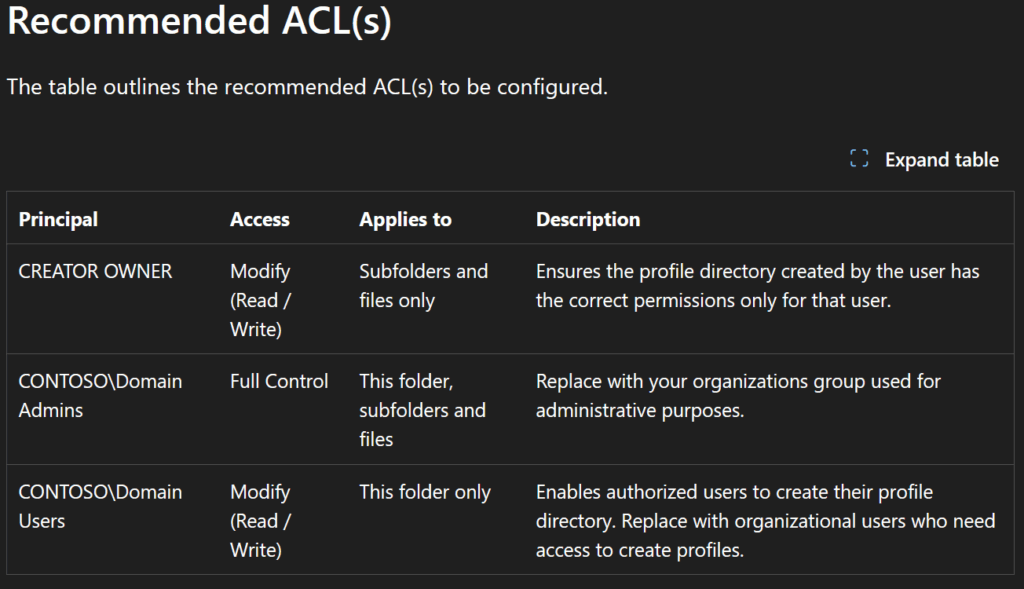
Le rachat de VMware par Broadcom a agi comme un électrochoc. Aujourd’hui, la question n’est plus faut-il migrer? , mais comment migrer sans tout casser ou y perdre tous ses cheveux?. Entre les solutions tierces payantes et les méthodes manuelles risquées, Microsoft a discrètement sorti une arme redoutable : l’extension VM Conversion pour Windows Admin Center (WAC).

Après avoir testé l’outil encore en préversion, je voulais partager avec vous mon expérience. Et pour vous guider plus facilement dans cet article très long, voici des liens rapides :
- FAQ
- Pourquoi quitter VMware ?
- Qu’est-ce que Windows Admin Center ?
- Qu’est-ce que l’extension VM Conversion ?
- Combien coûte VM Conversion ?
- Quelles versions d’OS sont supportées ?
- Quels sont les prérequis pour VM Conversion ?
- Combien de VM puis-je migrer simultanément ?
- Comment l’outil VM Conversion marche ?
- Quid du temps d’arrêt ?
- Que devient VMware Tools sur le VM migré ?
- Test de migration
- Etape 0 – Rappel des prérequis
- Etape I – Installation de Windows Admin Center
- Etape II – Installation de prérequis WAC
- Etape III – Connexion à Hyper-V depuis WAC
- Etape IV – Test Windows : Synchronisation de la VM
- Etape V – Test Windows : Migration de la VM
- Etape VI – Test Linux : Synchronisation de la VM
- Etape VII – Test Linux : Migration de la VM
Pourquoi quitter VMware ?
Le rachat de VMware par Broadcom a agi comme un électrochoc. Beaucoup de clients ont vu les coûts augmenter fortement après le rachat, car Broadcom a changé le modèle de licences (par exemple passage d’une licence perpétuelle à un modèle d’abonnement) et restructuré les offres. Certains ont reçu des renouvellements jusqu’à plusieurs fois plus chers qu’avant pour les mêmes besoins.
Ces changements rapides dans la structuration des produits, des bundles et du support ont créé de l’incertitude sur la roadmap et l’avenir des produits VMware, ce qui amène les DSI à repenser leurs choix technologiques à long terme
On retrouve d’ailleurs pas mal de blogueurs parlant de cet exode :
- Why Leave VMware in 2025? Alternatives and Migration Guide
- Navigating the VMware Exit: Why OpenStack is the Smart Alternative for 2025 and Beyond | OpenMetal IaaS
- VMware : 6 options pour en sortir, 1 piste pour y rester
- Life After VMware: Accelerating VMware Exits with In-Place Migration • Platform9
- Hyper-V 2026: Not the Same Beast You Ditched in 2012 (And That’s a Good Thing) | by Mr.PlanB | Jan, 2026 | Medium
- Ditching Broadcom, Hyper-V Server, & Live Migrations | by Rich | Medium
Qu’est-ce que Windows Admin Center ?
Présent depuis des années, Windows Admin Center (souvent abrégé WAC) est un outil d’administration web développé par Microsoft pour gérer des serveurs Windows, des clusters et des environnements hyperconvergés, depuis une interface moderne accessible via navigateur.
Concrètement, Windows Admin Center vous permet d’administrer, sans passer par du RDP, un grand nombre de services Microsoft :
- Windows Server
- Hyper-V
- Clusters (Failover Clustering)
- Machines virtuelles
- Serveurs distants (on-prem ou Azure)
- Stockage (Storage Spaces Direct)
Qu’est-ce que l’extension VM Conversion ?
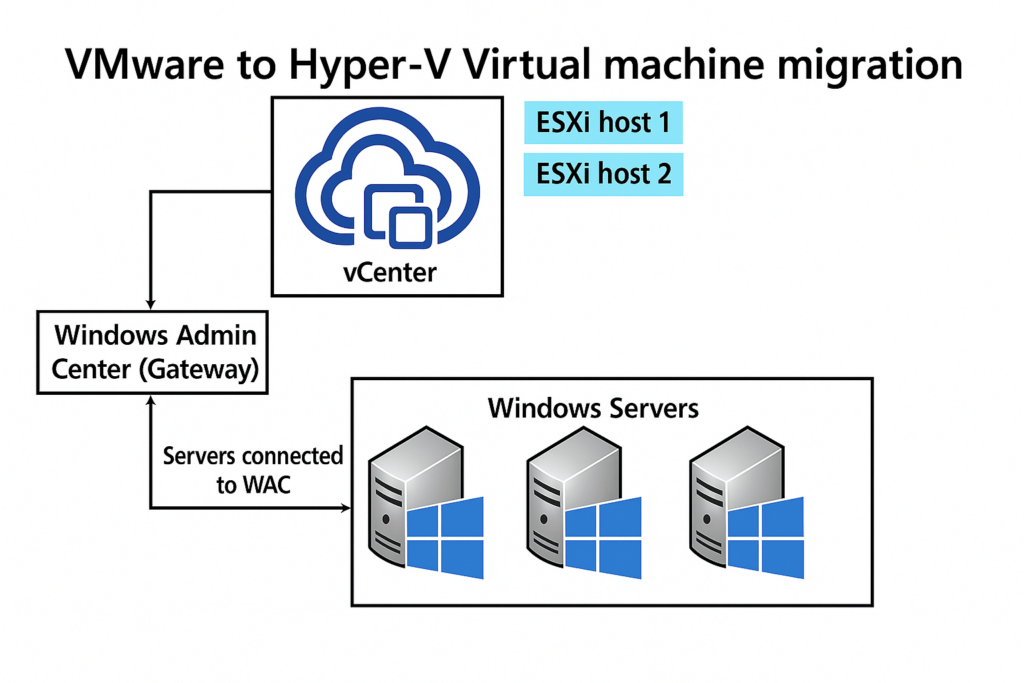
C’est un nouvel outil Microsoft intégré à Windows Admin Center qui permet de migrer des machines virtuelles depuis VMware vCenter/ESXi vers Hyper-V, en mode agentless :
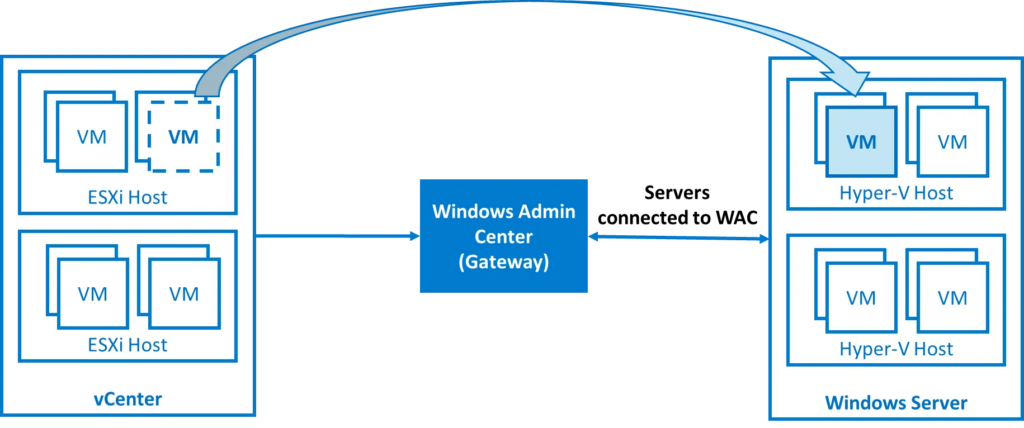
Actuellement, Il s’agit d’une extension prévue pour minimiser le temps d’arrêt grâce à la réplication en ligne des disques.
Attention, cette extension n’est pas pour but de migrer vers Azure Local. Un autre article déjà écrit il y a plusieurs mois traite de ce type de migration : de VMware à Azure Local.
Combien coûte VM Conversion ?
L’extension est actuellement en préversion. Son usage n’implique aucun coût de licence supplémentaire, mais pas non plus de support garanti par Microsoft.
Quelles versions d’OS sont supportées ?
Microsoft annonce une large liste sur la compatibilité :
- Tous les vCenter VMware 6.x, 7.x et 8.x sont pris en charge
- Côté OS invités :
- Windows Server 2025, 2022, 2019, 2016, 2012 R2
- Windows 10/11
- Ubuntu 20.04, 24.04
- Debian 11, 12
- Alma Linux
- CentOS
- Red Hat Linux 9.0
L’extension fonctionne également dans un environnement Hyper-V en cluster (WSFC) : elle est cluster-aware et détecte correctement les nœuds et ressources.
Il supporte la migration de VM depuis ESXi vers des clusters Windows Server Failover (WSFC) sous Hyper-V. Vous pouvez donc distribuer les VM migrées sur plusieurs nœuds Hyper-V pour HA ou performances.
Quels sont les prérequis pour VM Conversion ?
- Côté Windows Admin Center :
- WAC en version au moins v2410 build 2.4.12.10 ou supérieure
- PowerShell et PowerCLI installés
- VMware VDDK version 8.0.3 installé
- Visual Studio 2013 et 2015 installés
- Côté Hyper-V :
- le rôle Hyper-V doit être installé sur le (s) hôte (s) cible
- Le compte utilisé durant le processus doit être administrateur local ou membre du groupe Hyper-V Administrators).
- Si des VMs migrées sont sous Linux, les modules Hyper-V (hv_vmbus, hv_netvsc, hv_storvsc) et Linux Integration Services (hyperv-daemons ou linux-cloud-tools) doivent être pré-installés dans l’initramfs avant migration.
Combien de VM puis-je migrer simultanément ?
Jusqu’à 10 machines virtuelles par lot. On peut grouper ces machines selon leur dépendance applicative, leur placement dans un cluster ou même selon des critères métier (ex : séparer environnement de test/prod). Cela facilite les migrations massives par workload.
Comment l’outil VM Conversion marche ?
Microsoft explique bien les deux phases présentes dans l’outil VM Conversion :
Synchronisation : l’extension effectue une copie complète initiale des disques de la machine virtuelle pendant que la VM source continue de fonctionner. Cette phase minimise les temps d’arrêt en vous permettant de planifier la migration finale à un moment qui vous convient.
Migration : l’extension utilise la fonctionnalité Change Block Tracking (CBT) pour rechercher et répliquer uniquement les blocs modifiés depuis la dernière synchronisation. Pendant la transition, la machine virtuelle source est mise hors tension et une synchronisation delta finale capture toutes les modifications restantes avant d’importer la machine virtuelle dans Hyper-V.
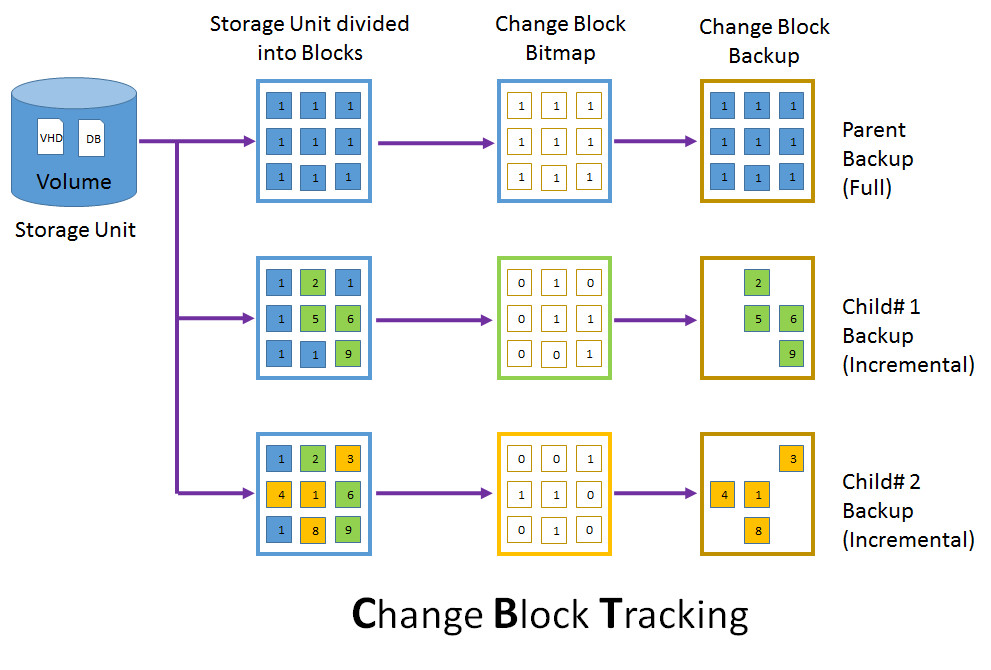
Quid du temps d’arrêt ?
Pendant la phase de synchronisation, la VM source continue de tourner, pendant qu’une copie initiale des disques est envoyée sur l’hôte Hyper-V, via la création d’un snapshot pour suivre les changements.
Au moment de la bascule, la VM source est arrêtée pour un dernier delta-sync avant import; ce processus réduit donc au minimum la fenêtre d’arrêt.
Que devient VMware Tools sur le VM migré ?
La présence de VMware Tools dans une VM sous Hyper-V peut provoquer des conflits de pilotes, donc il vaut mieux les retirer.
- Initialement, il fallait supprimer les outils VMware Tools manuellement après la bascule vers Hyper-V.
- Depuis la version 1.8.0, l’extension supprime automatiquement VMware Tools sur les VM Windows migrées en fin de processus.
- Pour les VM Linux, il est recommandé de ne pas réinstaller open-vm-tools sur la cible Hyper-V (on s’appuie uniquement sur les pilotes Hyper-V ajoutés).

Et enfin, comme toujours, je vous propose dans la suite de cet article d’effectuer ensemble un pas à pas pour couvrir la migration de machines virtuelles hébergées sur VMware vers Hyper-V :
- Etape 0 – Rappel des prérequis
- Etape I – Installation de Windows Admin Center
- Etape II – Installation de prérequis WAC
- Etape III – Connexion à Hyper-V depuis WAC
- Etape IV – Test Windows : Synchronisation de la VM
- Etape V – Test Windows : Migration de la VM
- Etape VI – Test Linux : Synchronisation de la VM
- Etape VII – Test Linux : Migration de la VM
Etape 0 – Rappel des prérequis :
Des prérequis sont nécessaires pour réaliser cet exercice dédié à la migration d’une machine virtuelle hébergée sur VMware vers Hyper-V via Windows Admin Center. Pour tout cela, j’ai utilisé :
- Un environnement VMware
- Un environnement Hyper-V
- Une connexion réseau entre le réseau les deux hyperviseurs
Commençons par l’installation de Windows Admin Center sur une nouvelle machine hébergée sur VMware.
Etape I – Installation de Windows Admin Center :
Sur une machine virtuelle dédiée dans votre environnement VMware, téléchargez la dernière version de Windows Admin Center depuis la page officielle de Microsoft :
Choisissez l’installation avec l’option Express :
Dans cette démonstration, utilisez un certificat temporaire :
Lancez l’installation :
Une fois l’installation terminée, ouvrez la page de Windows Admin Center, puis authentifiez-vous avec votre compte :
Une fois connecté dans la console Windows Admin Center, attendez quelques minutes la fin de l’installation des extensions préinstallées :
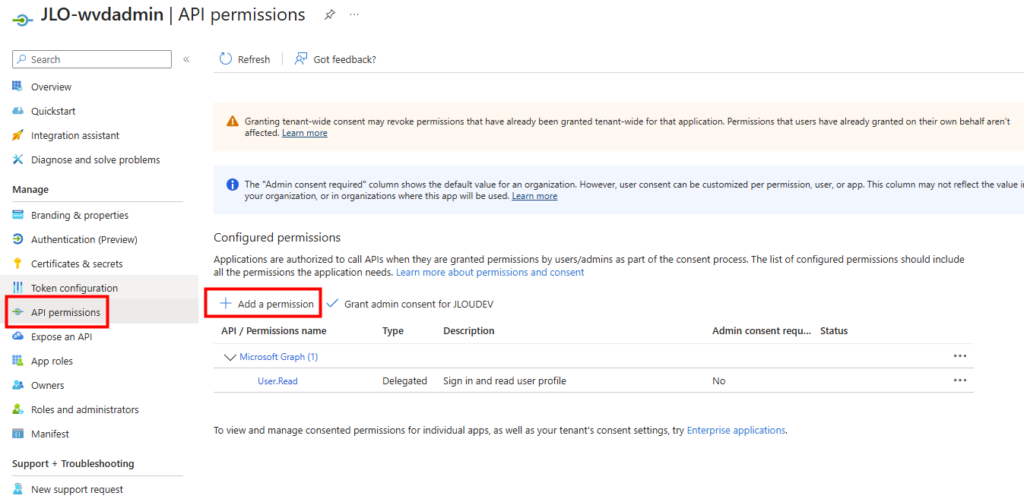
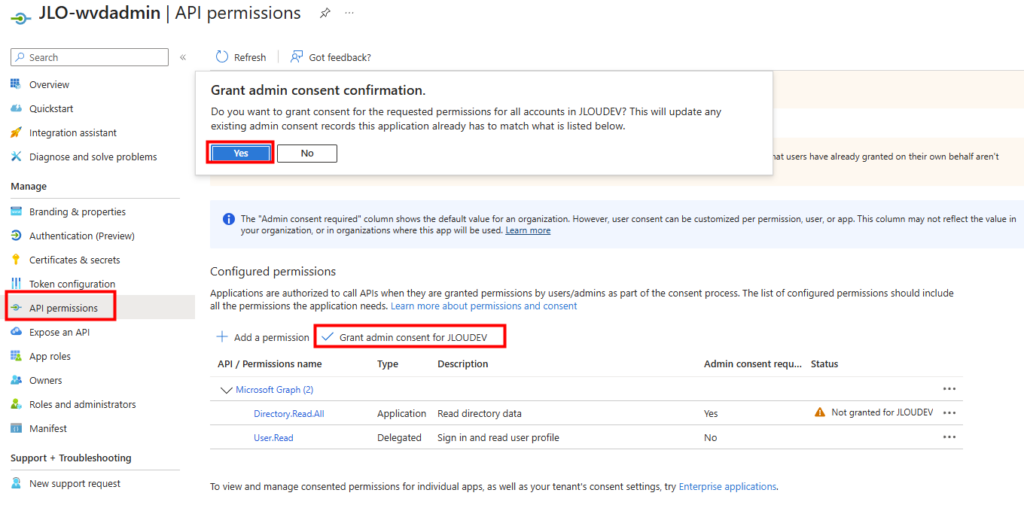
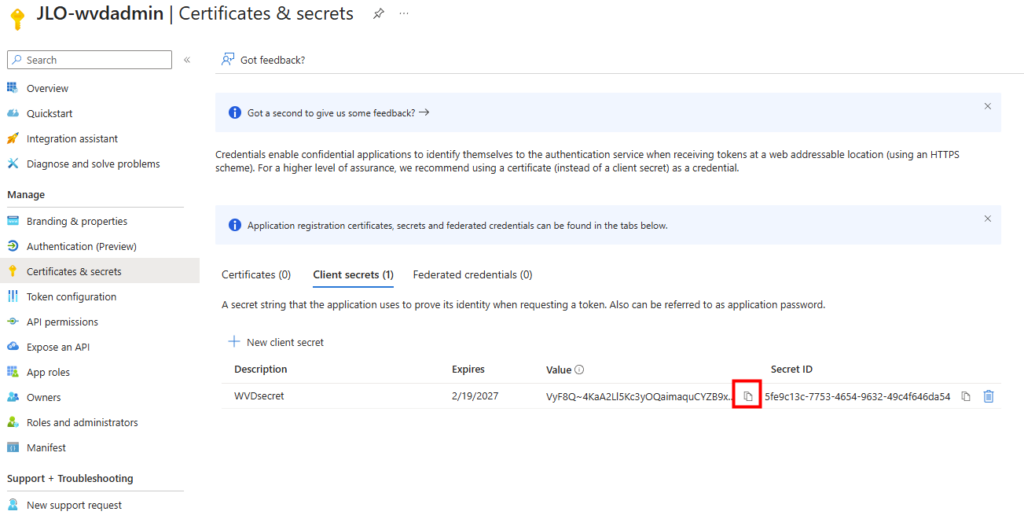
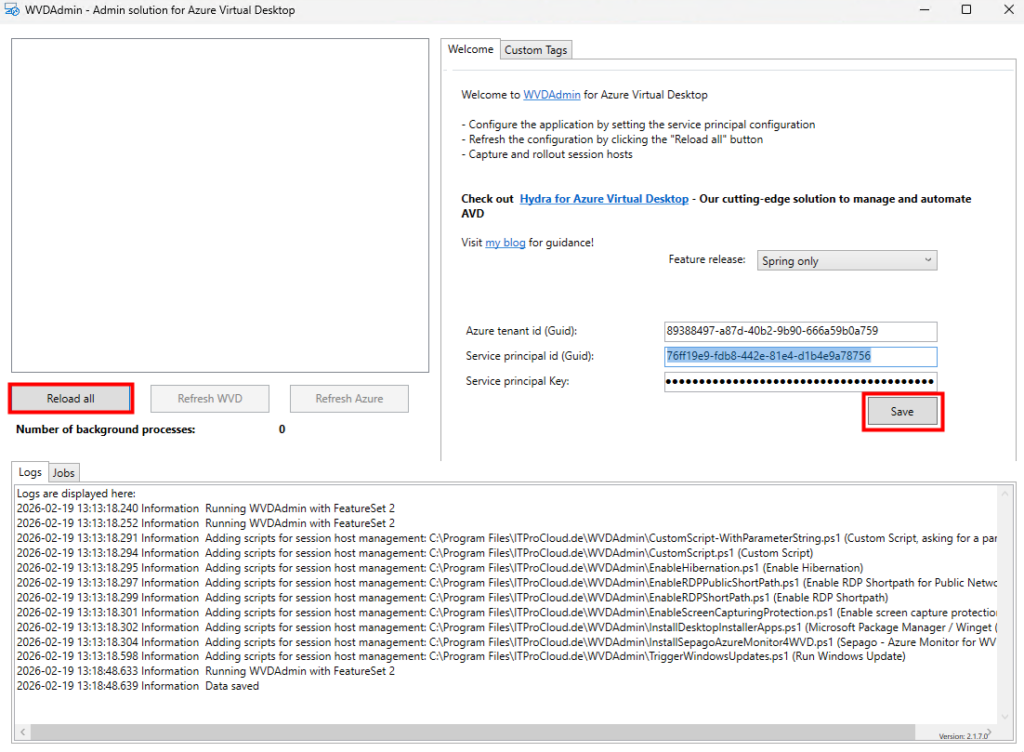
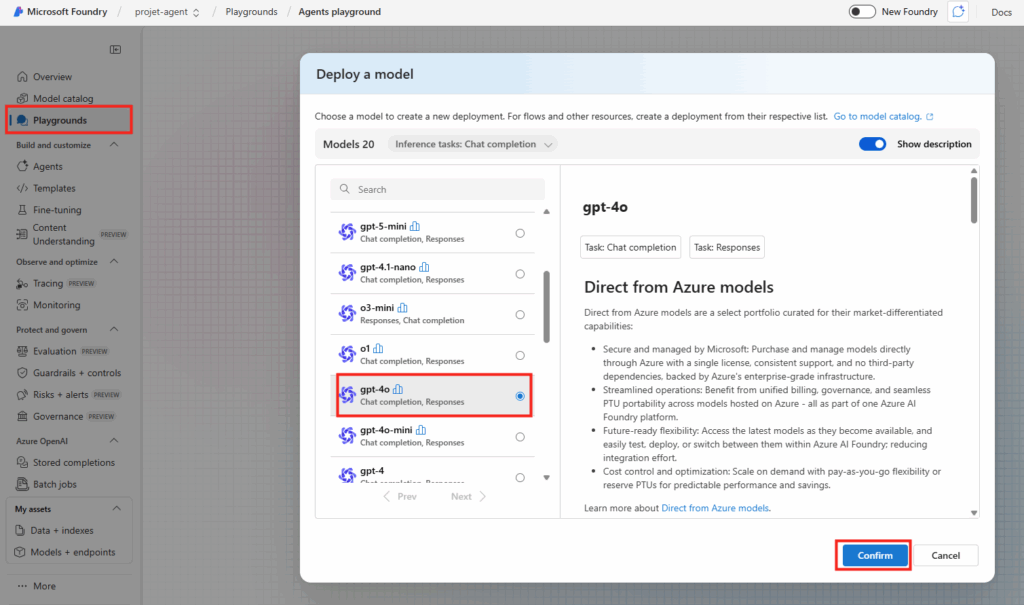
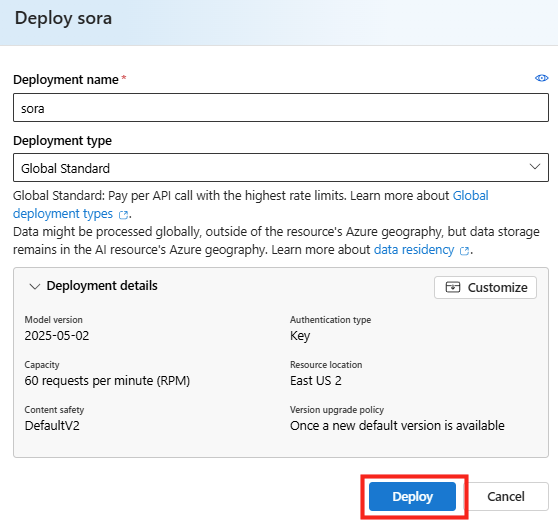
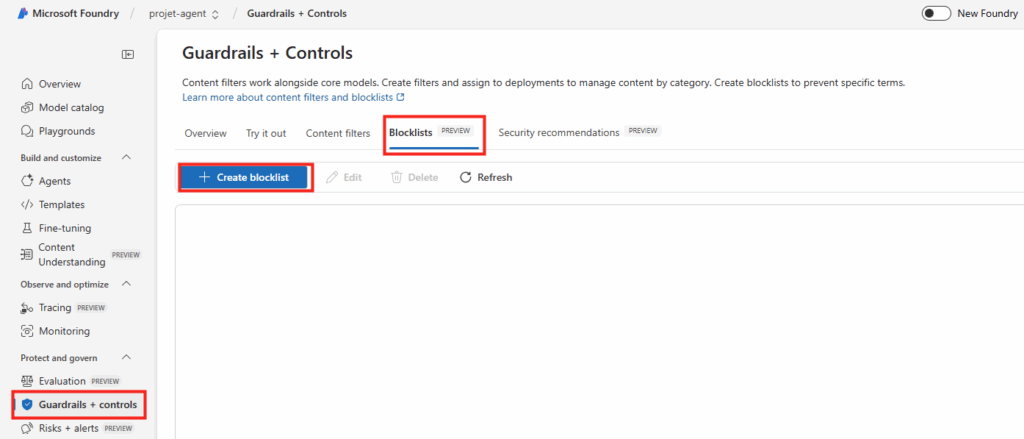
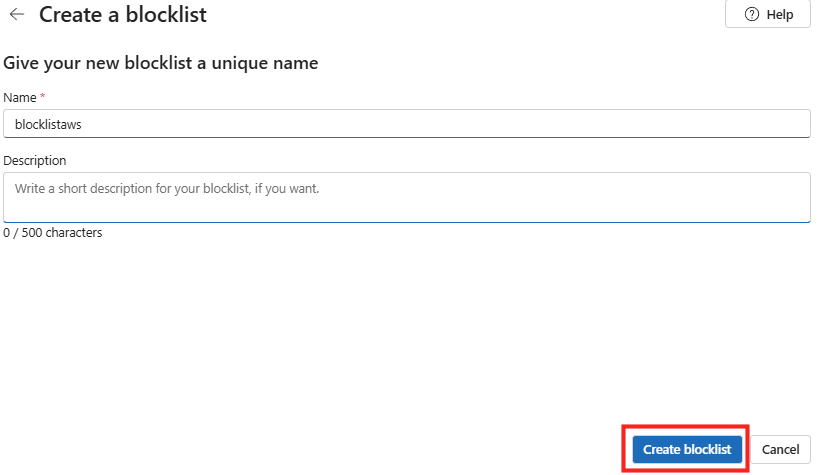
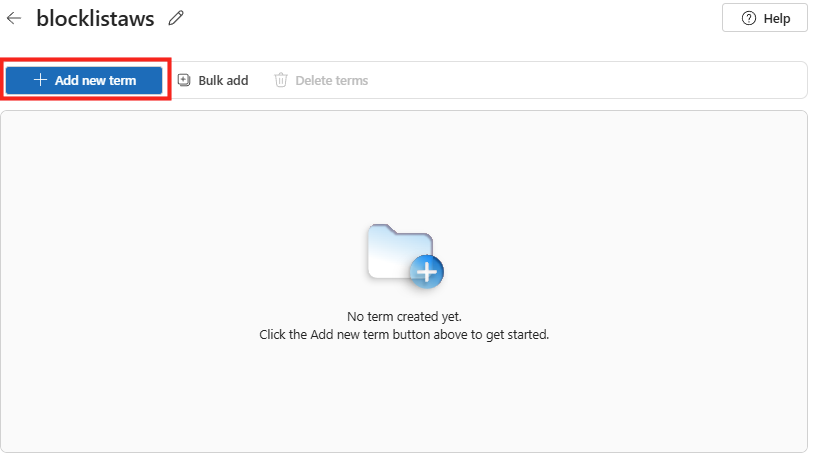
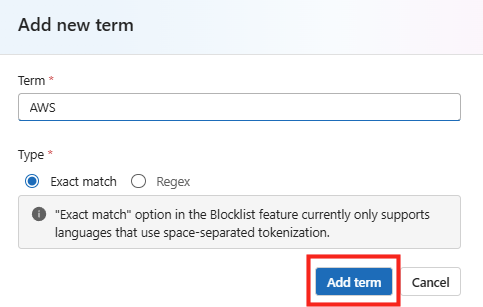
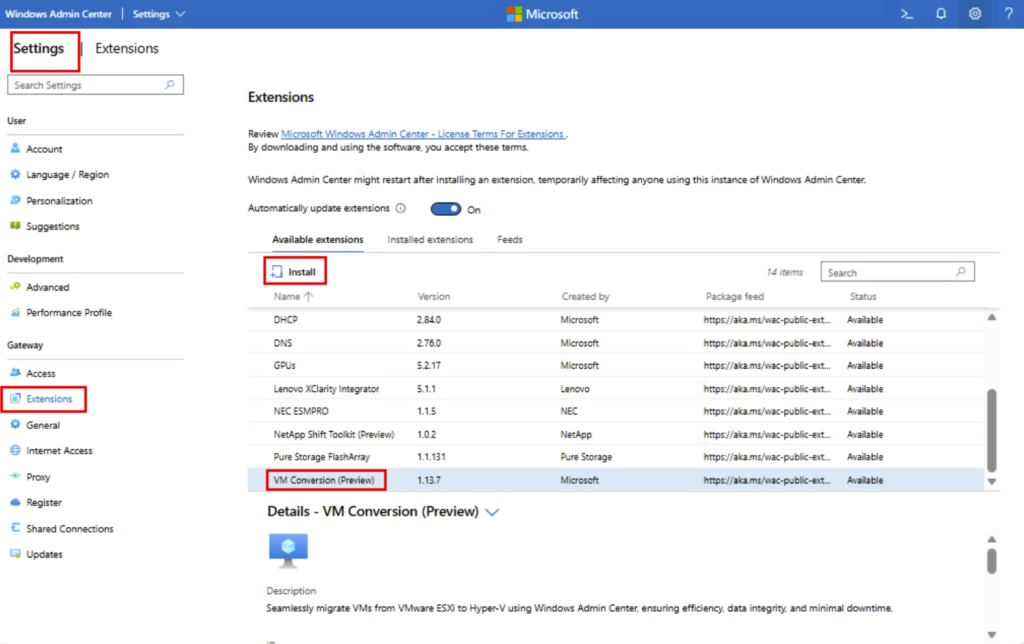
Rendez vous dans les paramétrages dans WAC afin d’ajouter l’extension dédiée à la migration :
Etape II – Installation de prérequis WAC :
Comme indiqué dans la documentation Microsoft, certains prérequis doivent être installés sur la machine de Windows Admin Center.
Commencez par installer Visual C++ Redistributable Packages for Visual Studio 2013
Continuez en installant également Visual C++ 2015-2022 Redistributable 14.50.35719.0 :
Récupérez et décompressez VMware Virtual Disk Development Kit (VDDK), en version 8.0.3, dans le dossier WAC suivant :
Redémarrez ensuite votre machine virtuelle contenant Windows Admin Center.
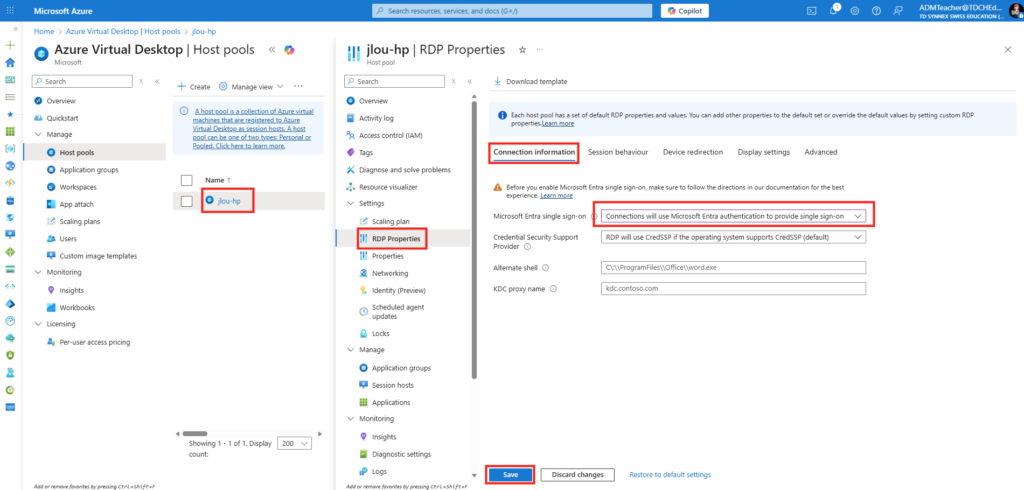
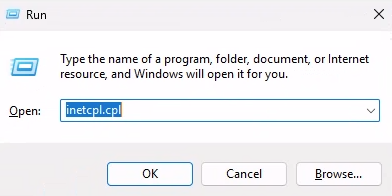
Etape III – Connexion à Hyper-V depuis WAC :
Une fois la machine virtuelle WAC redémarrée, rouvrez la console, puis cliquez ici pour ajouter une connexion vers votre serveur Hyper-V :

Cliquez sur Ajouter :
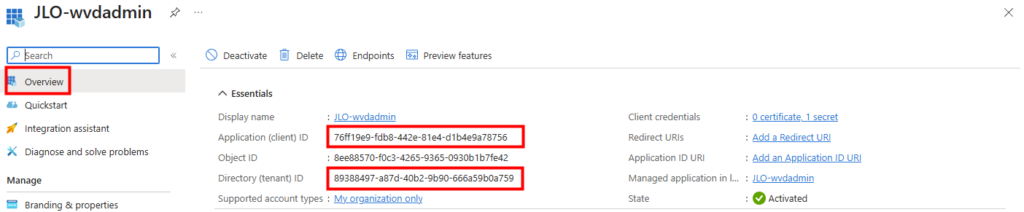
Renseignez l’adresse IP de votre Hyper-V, les éléments d’identification, puis cliquez sur Ajouter :
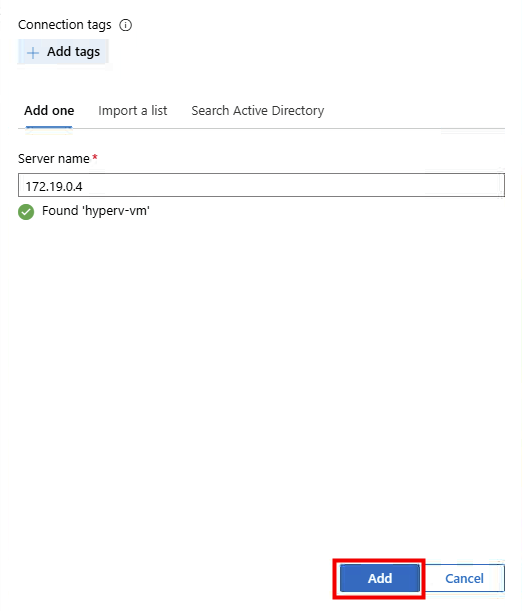
La connexion est établie, cliquez dessus pour l’ouvrir :

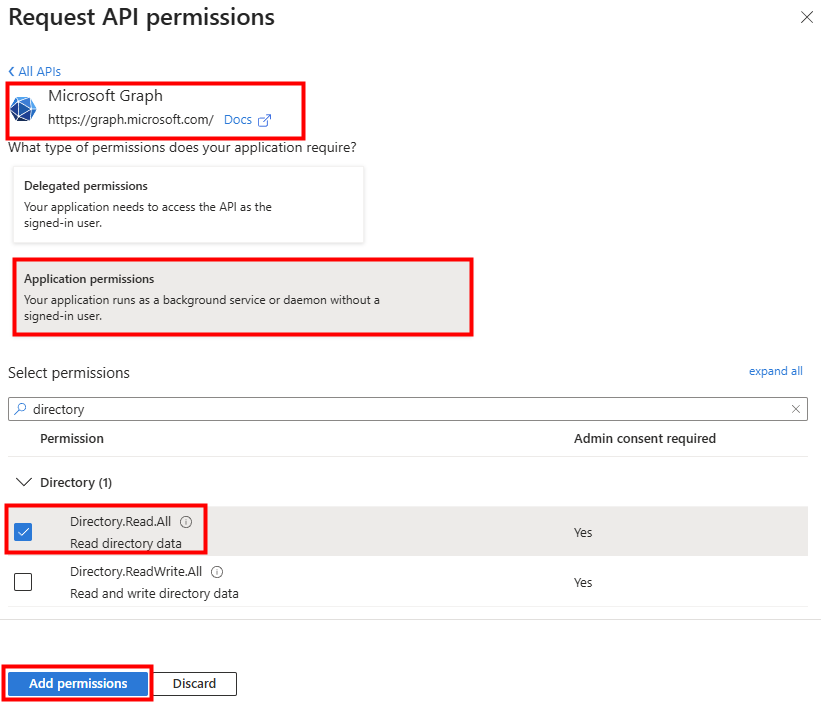
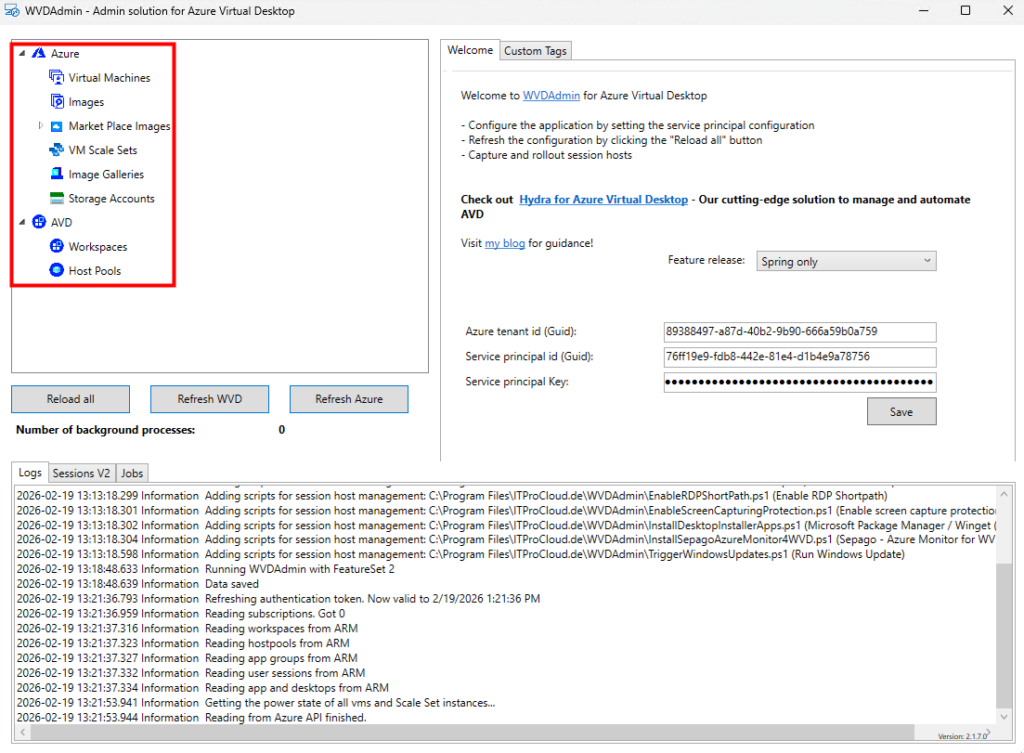
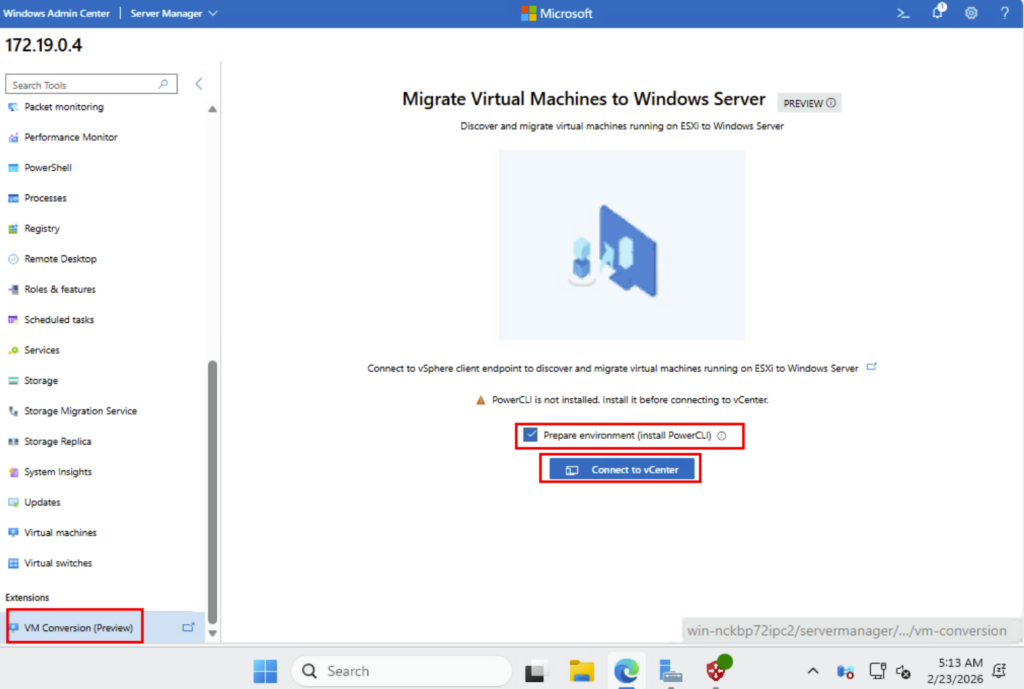
Dans le menu de gauche, cherchez l’extension consacrée à la migration, cochez la case suivante pour installer PowerCLI, puis cliquez ici :
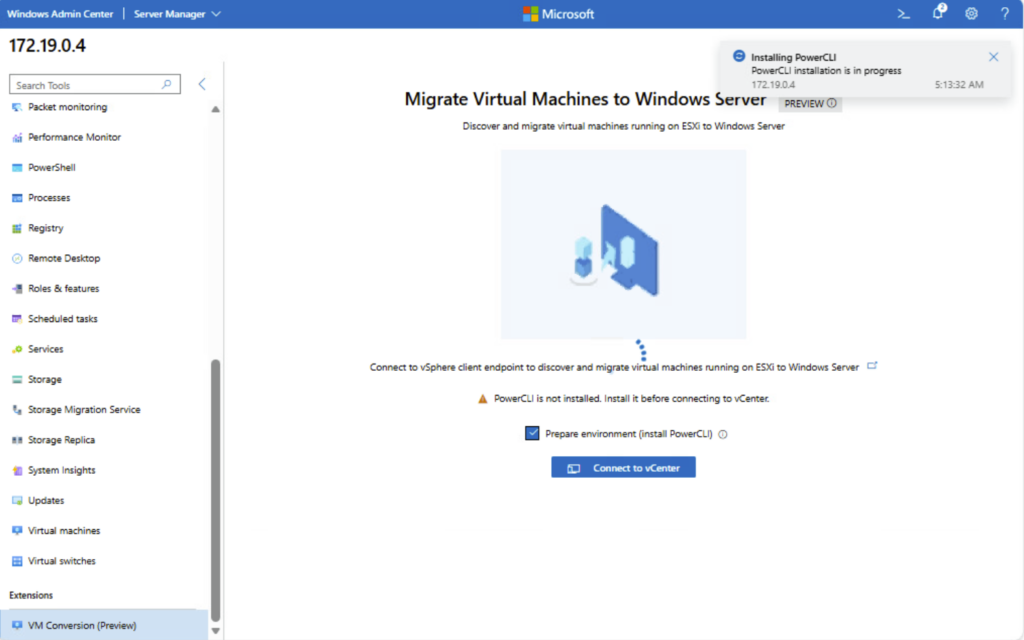
Attendez la fin de l’installation de PowerCLI :
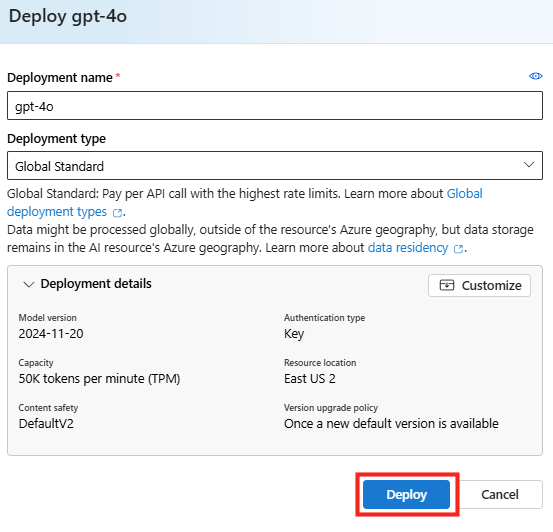
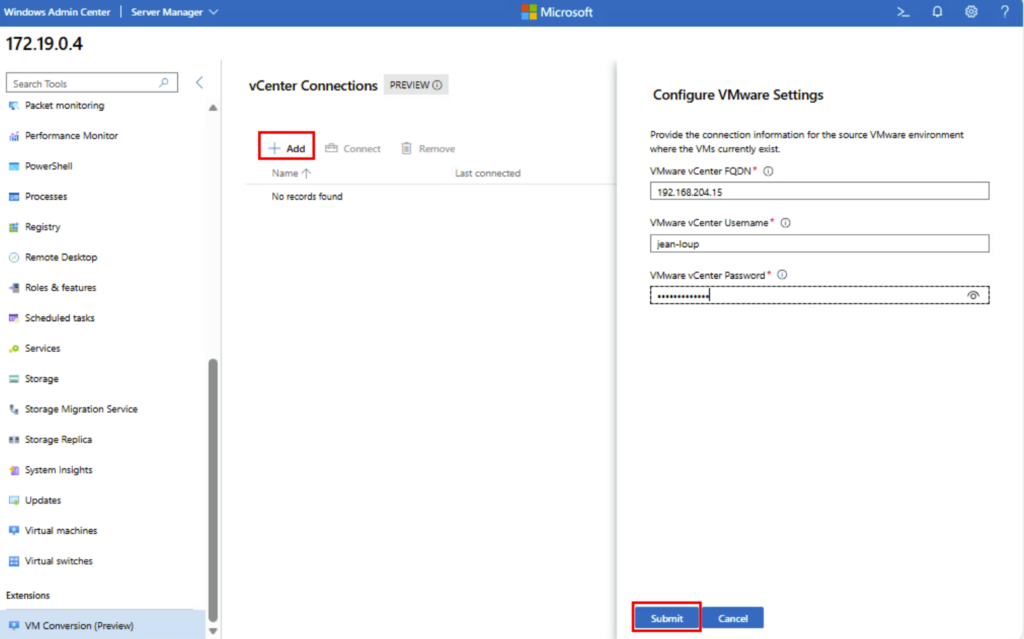
Une fois l’installation terminée, cliquez ici ajouter une connexion à votre vCenter, renseignez vos informations de connexion, puis cliquez ici :
Une fois la connexion établie avec vCenter, les machines virtuelles s’afficheront :
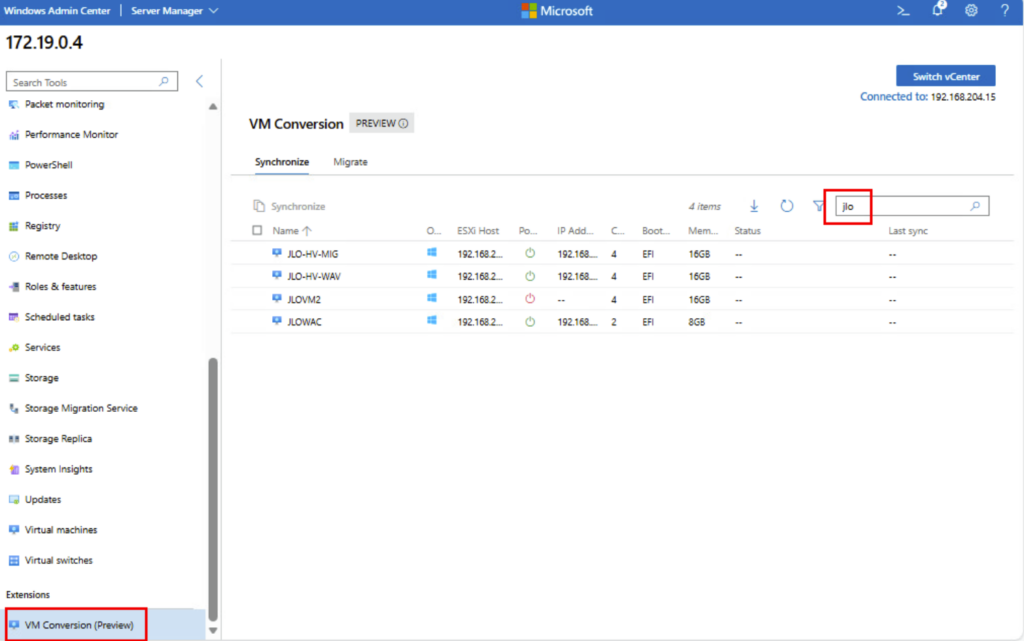
Le protocole de test est maintenant en place. Commençons les tests par la migration d’une machine virtuelle fonctionnant sous Windows Server.
Etape IV – Test Windows : Synchronisation de la VM :
Toujours dans la liste des machines virtuelles, cochez sur une des VMs Windows disponibles, puis cliquez ici pour démarrer la synchronisation :
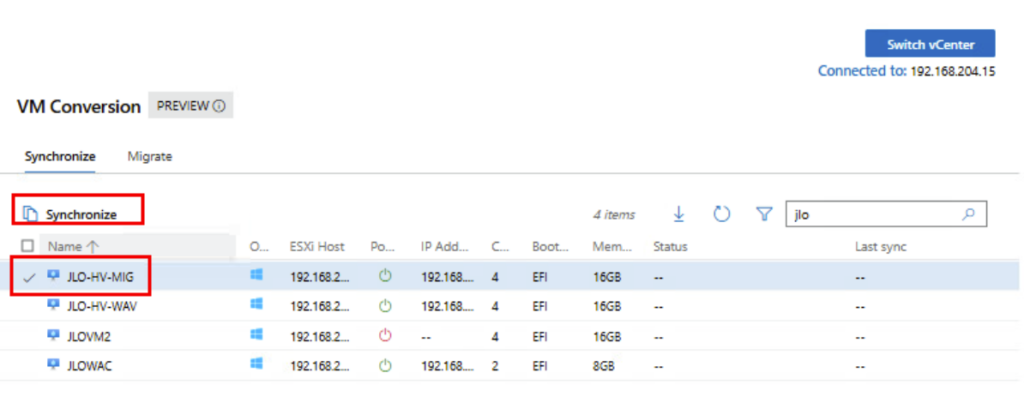
Renseignez le dossier de destination sur votre serveur Hyper-V, puis cliquez sur Synchroniser :
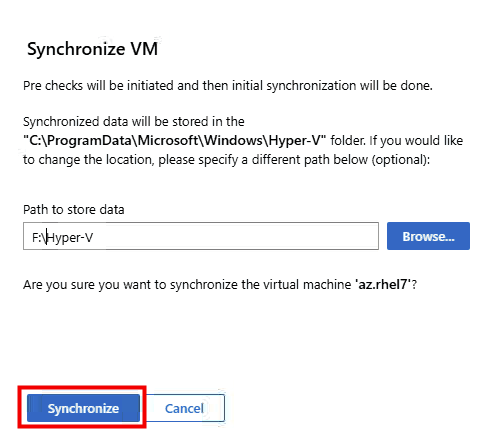
La phase de vérification préalable à la migration vient de démarrer (accessibilité, compatibilité matérielle, compatibilité OS, configuration réseau, …) :
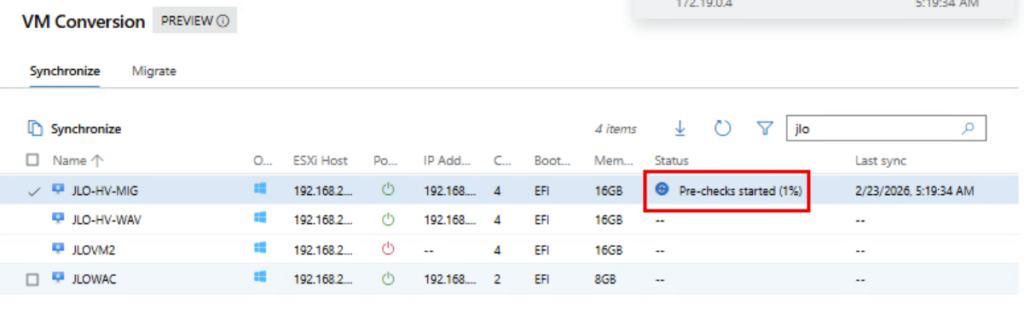
La première copie des disques VMDK vers Hyper-V est en cours pour la création des fichiers VHDX par la suite :
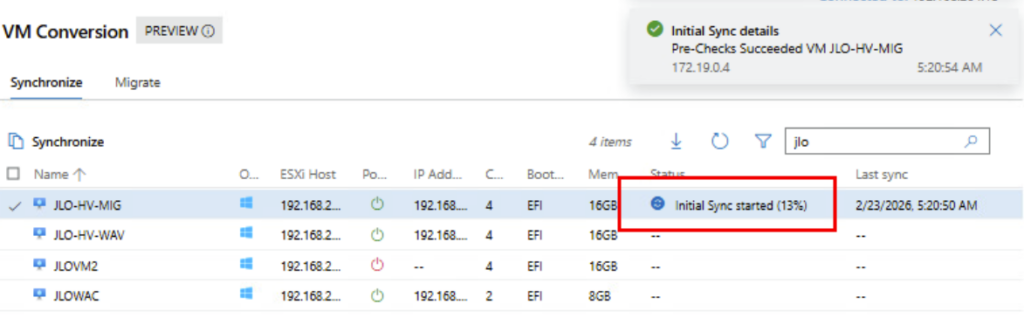
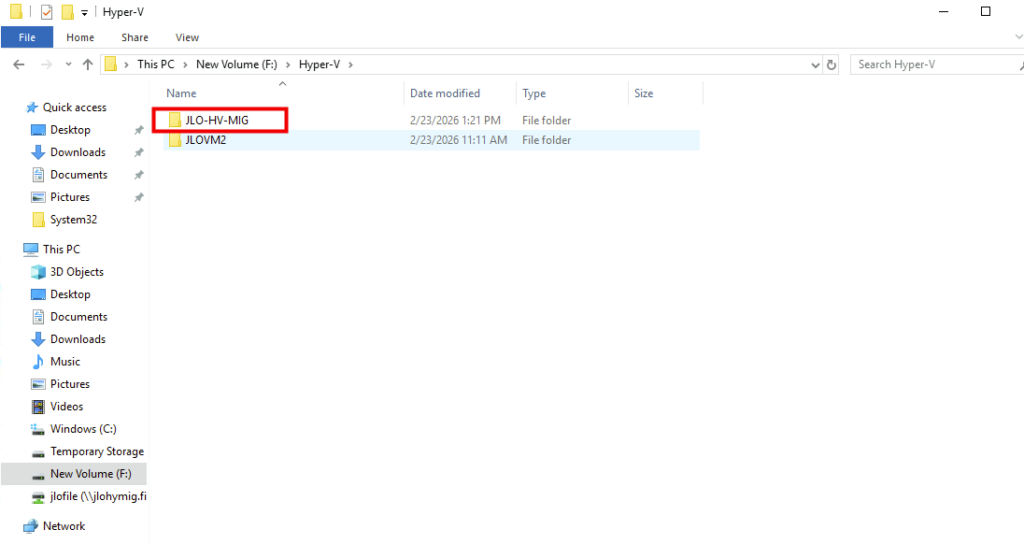
Constatez d’ailleurs la création du dossier sur le serveur Hyper-V :
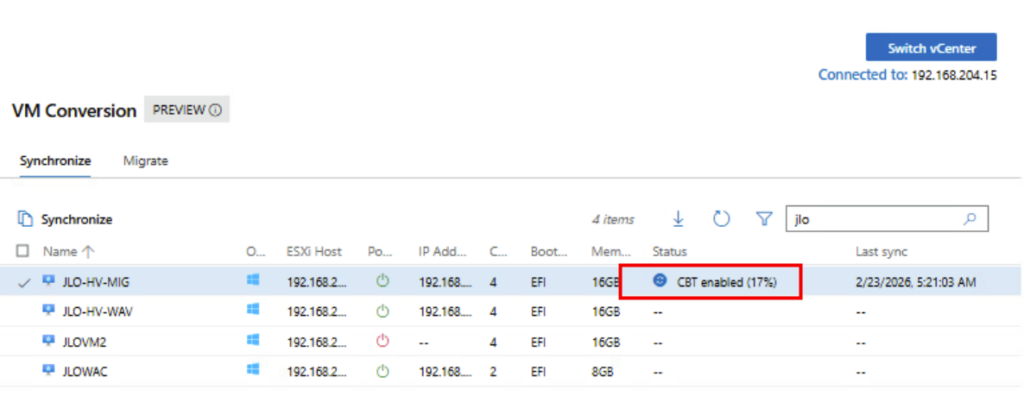
La migration passe en mode synchronisation différentielle afin de ne copier que les blocs modifiés depuis la synchronisation initiale, réduisant ainsi le volume de données à transférer avant le cutover :
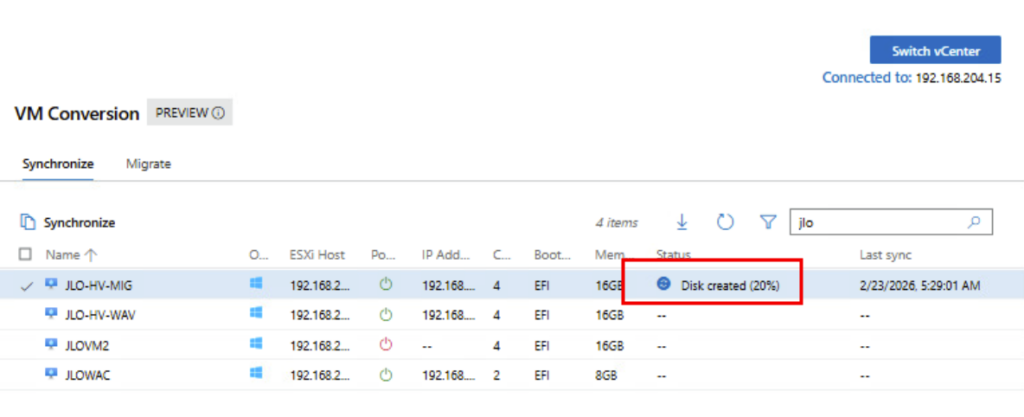
Provisioning du disque cible Hyper-V (VHDX) : l’infrastructure prépare le stockage avant l’application des blocs synchronisés issus de la VM VMware :
Phase de delta sync : les blocs modifiés identifiés via CBT sont appliqués au disque Hyper-V afin d’aligner la VM cible avec l’état courant de la VM source :
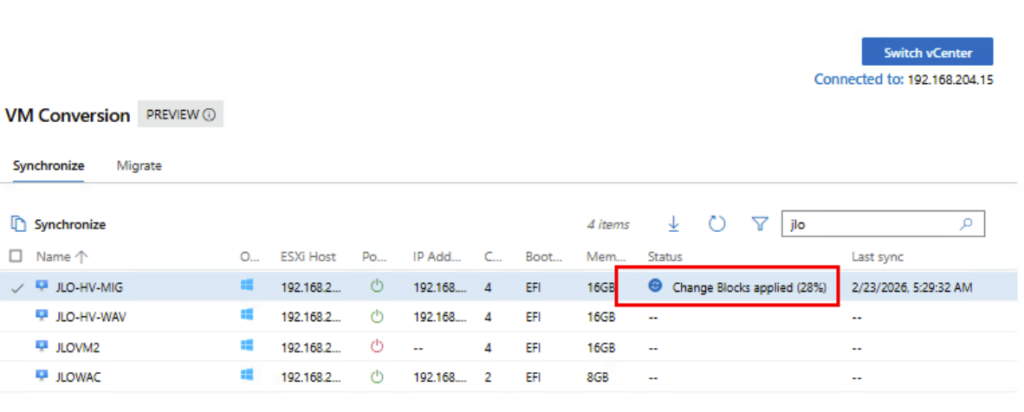
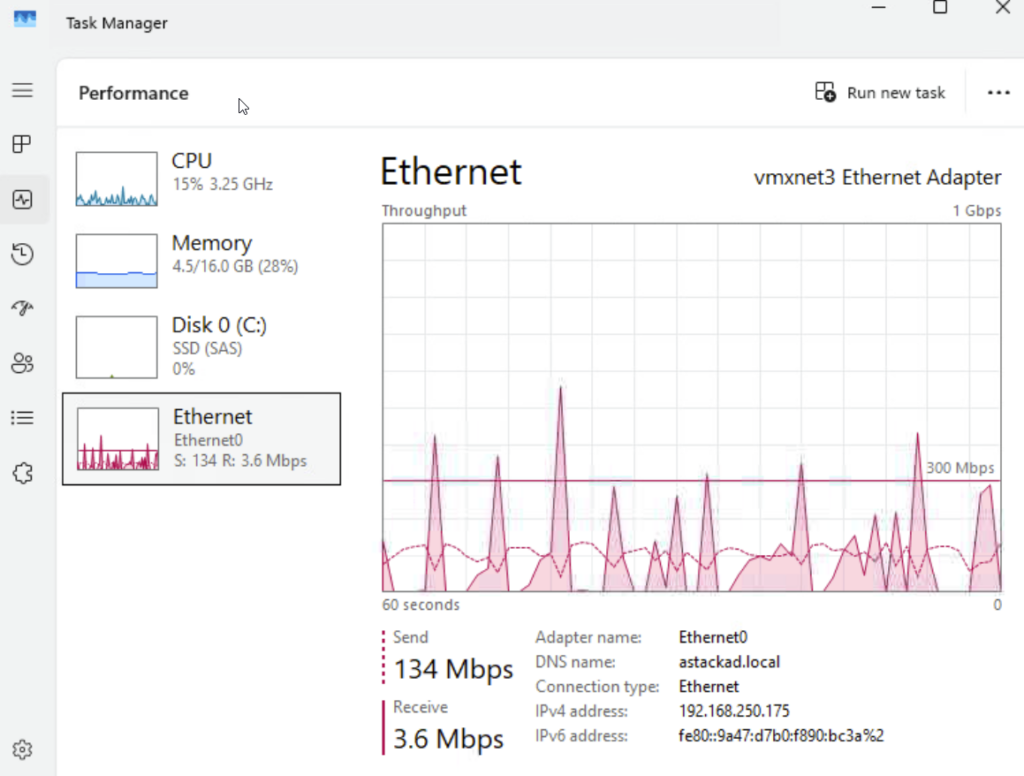
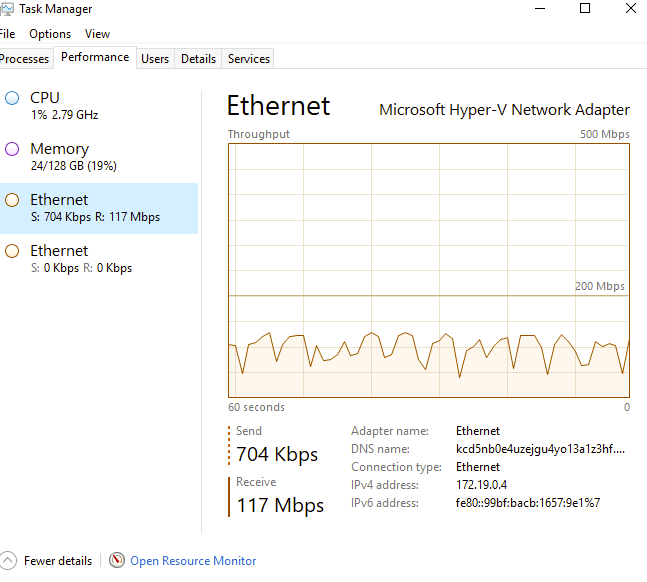
Le monitoring de la carte réseau montre bien le transfert des données :
Synchronisation complète (100 %) : l’intégralité des données de la VM source est maintenant répliquée côté Hyper-V :
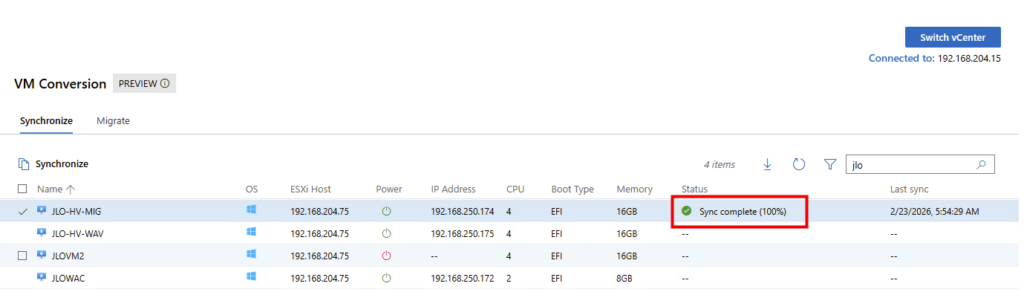
La VM cible est maintenant entièrement alignée avec la VM VMware et peut être basculée vers Hyper-V avec un dernier delta minimal.
Nous allons pouvoir procéder à la migration.
Etape V – Test Windows : Migration de la VM :
A ce stade, la machine virtuelle sous VMware est toujours allumée :
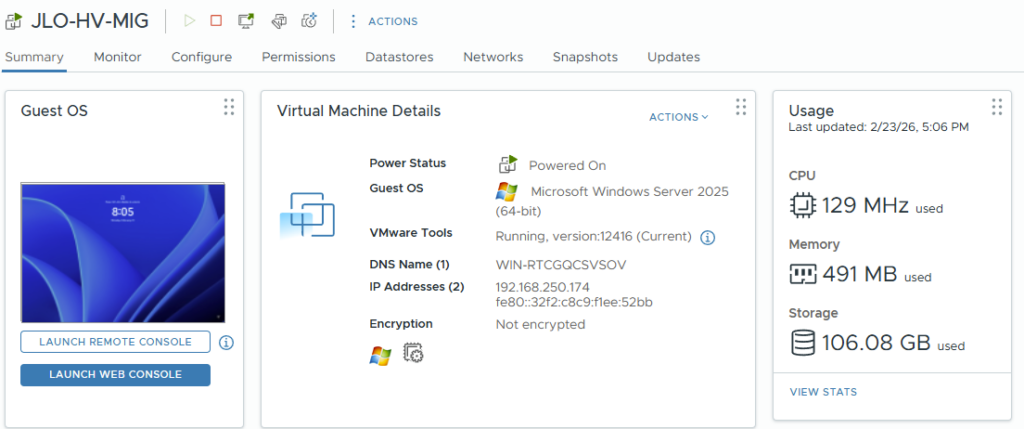
Testez le delta de migration en rajoutant sur votre machine virtuelle source de nouveaux fichiers :
Retournez ensuite sur Windows Admin Center afin de lancer la migration de celle-ci :
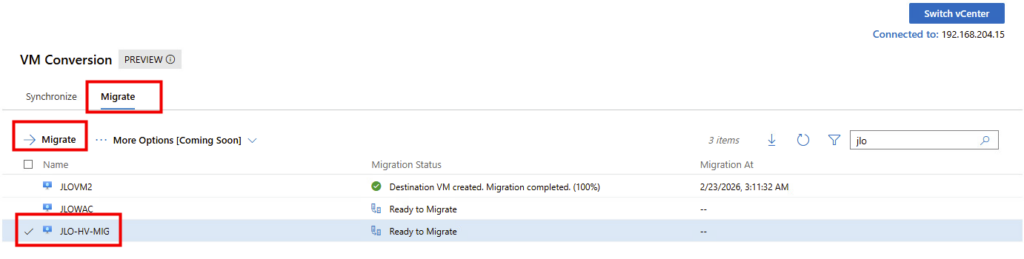
Choisissez ou non de désinstaller les outils VMware, puis cliquez ici :
Lancement de la migration : exécution des vérifications préalables avant bascule définitive vers la VM Hyper-V cible :
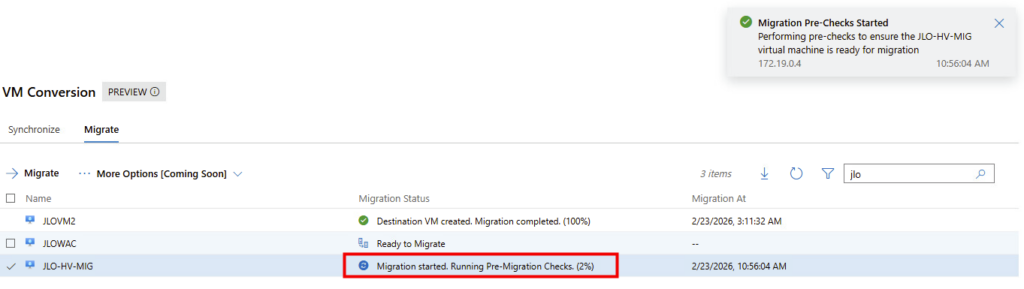
Vérifications pré-migration terminées : la synchronisation finale des blocs modifiés (delta sync) est en cours avant l’arrêt et la bascule de la VM :
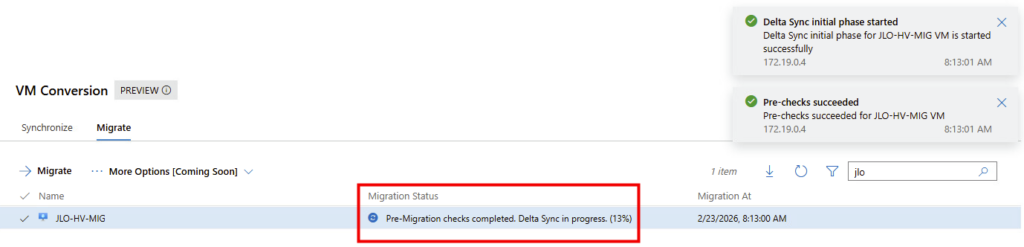
Un snapshot est bien créé côté VMware :
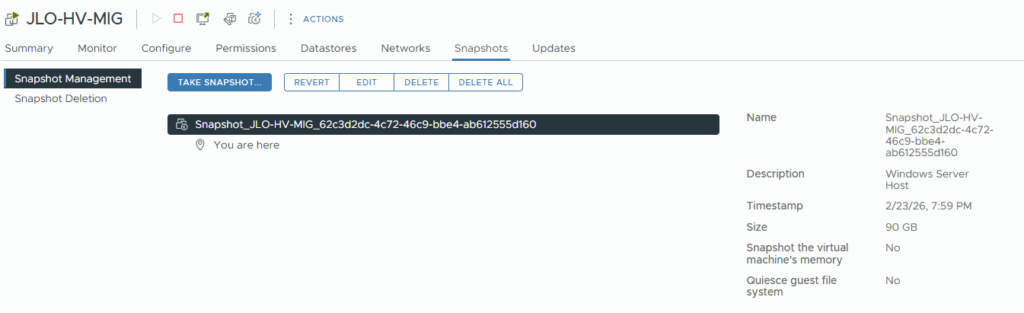
Delta Sync en cours : application des derniers blocs modifiés afin d’aligner définitivement la VM cible avant le cutover final vers Hyper-V.
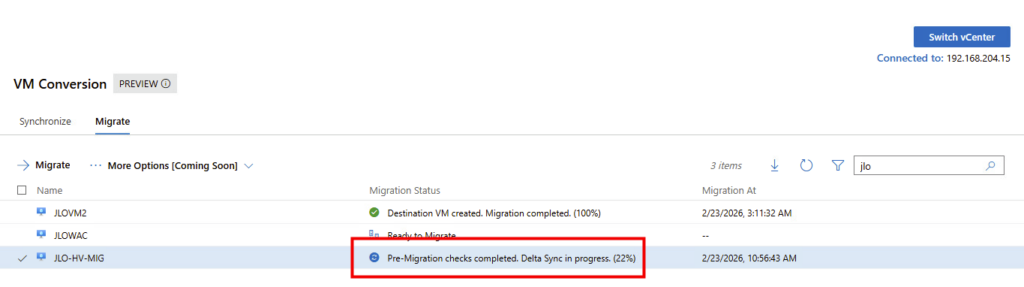
Arrêt de la VM source : la machine VMware est éteinte et la phase finale de synchronisation est lancée avant le démarrage côté Hyper-V :
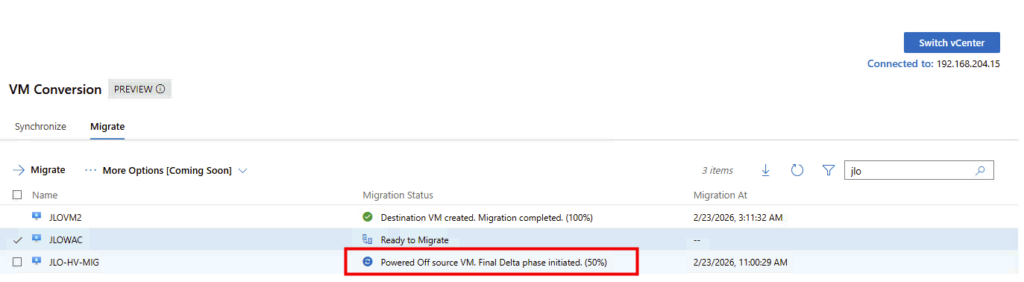
La machine virtuelle est bien arrêtée côté VMware :
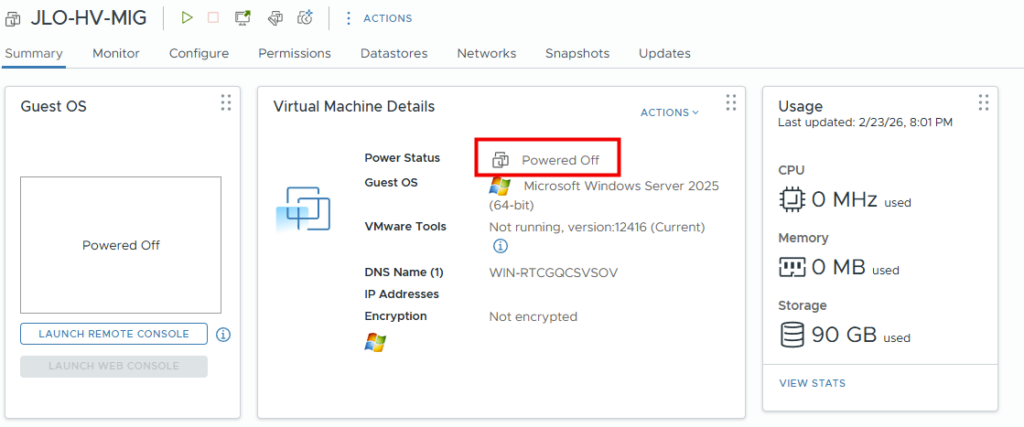
Migration terminée (100 %) : la VM cible Hyper-V est créée, synchronisée et prête à être démarrée en production :
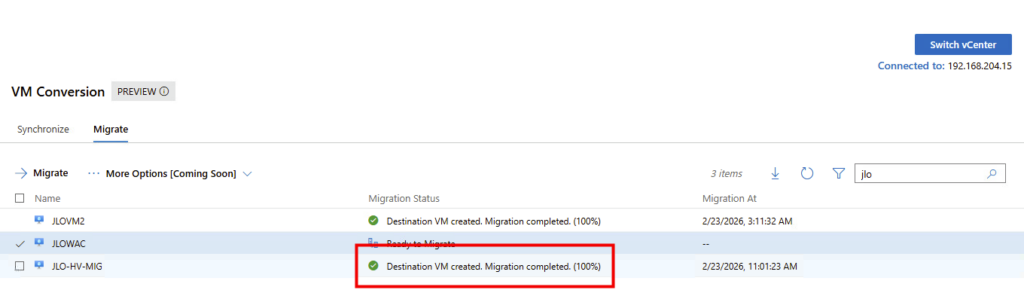
La VM migrée s’exécute désormais sur Hyper-V, confirmant le succès du cutover depuis l’environnement VMware :
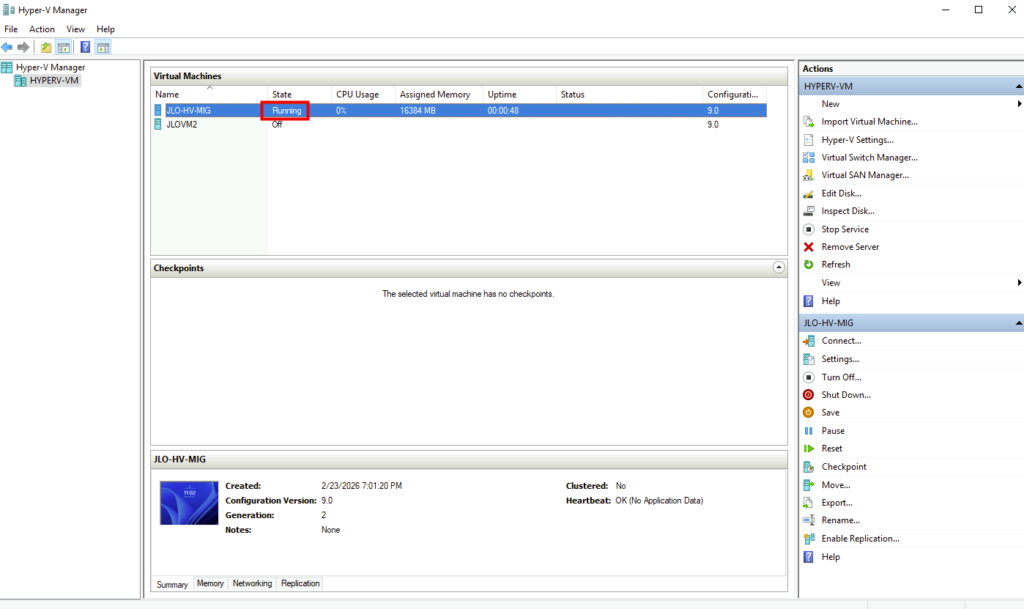
Windows détecte un arrêt inattendu lié au cutover, confirmant que la VM a bien été basculée depuis l’environnement VMware vers Hyper-V :
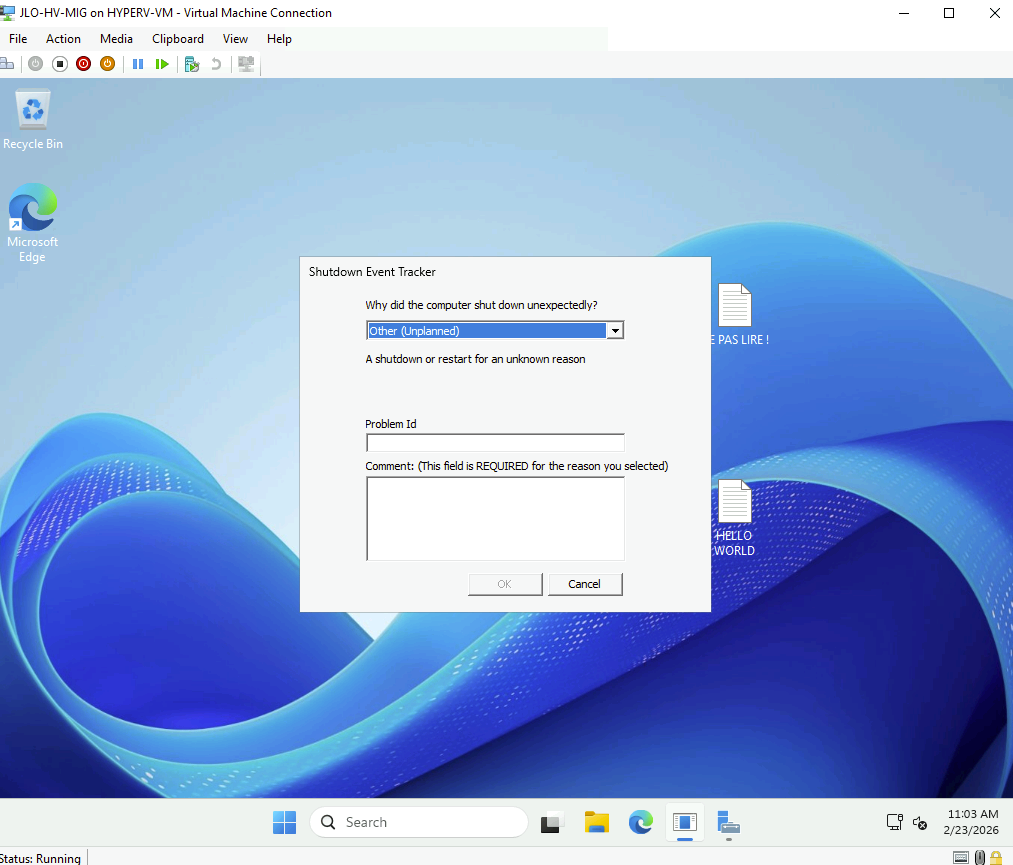
Erreur VMware Tools au premier démarrage : les anciens composants VMware, désormais incompatibles sous Hyper-V, doivent être désinstallés après la migration :
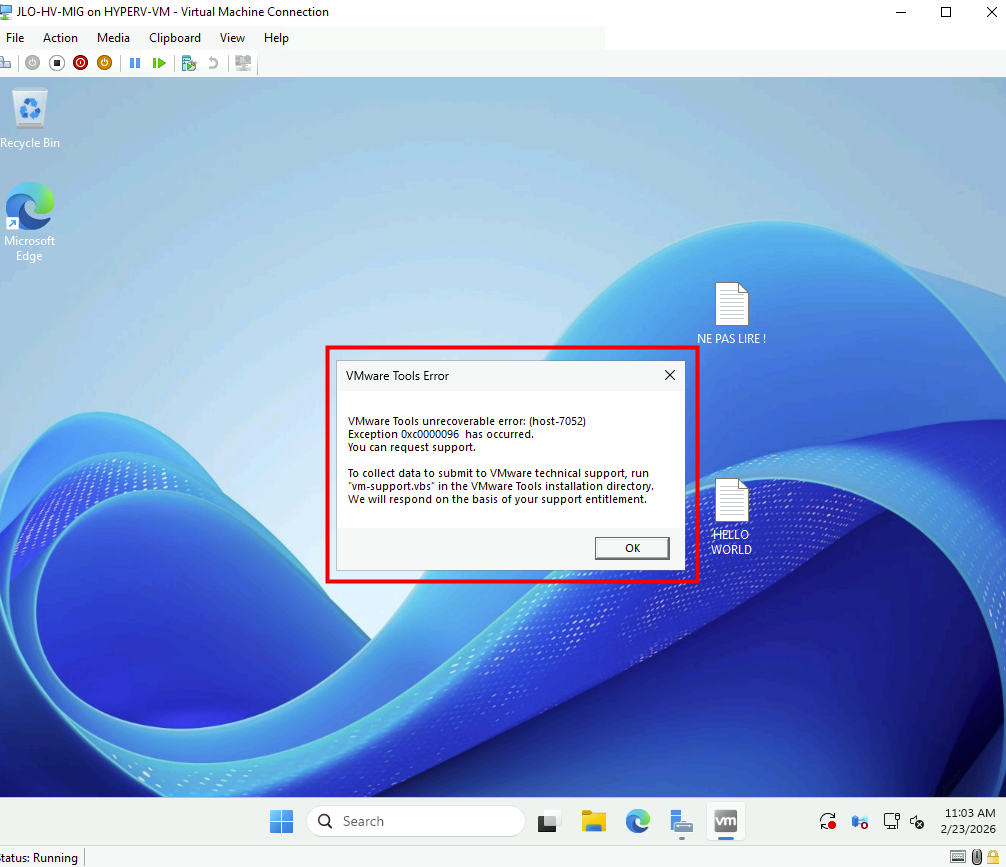
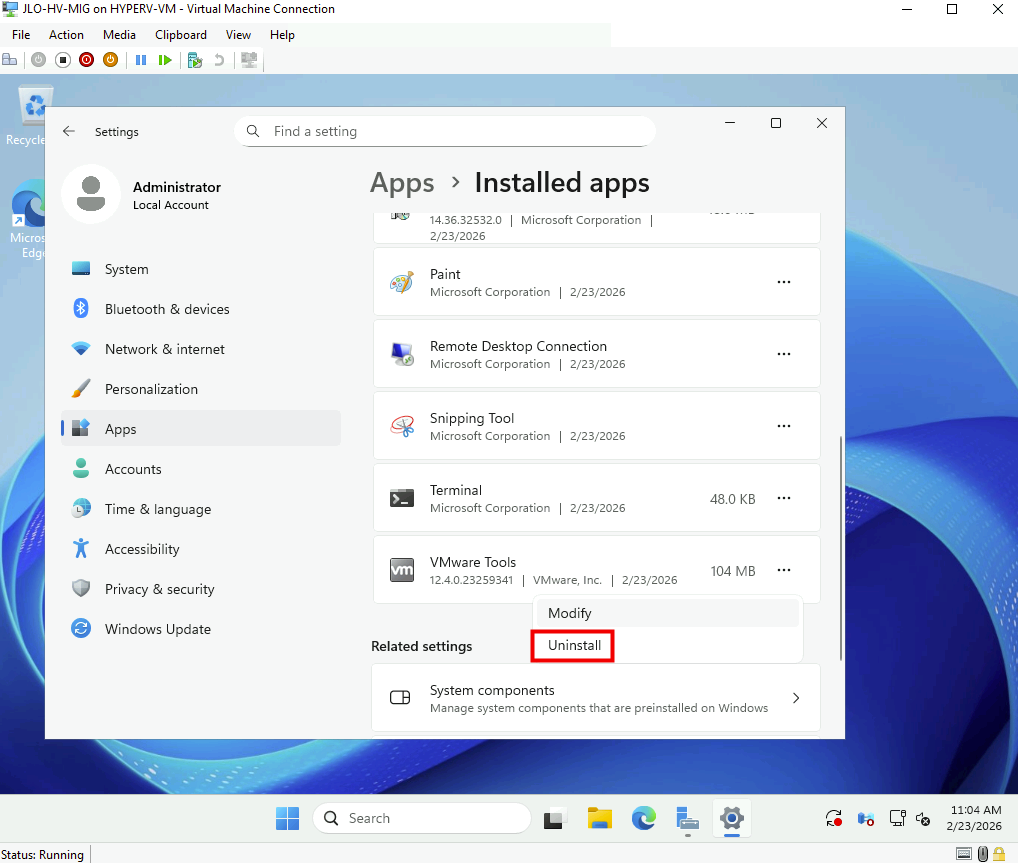
Désinstallez les VMware Tools devenus inutiles après le passage de la VM sous Hyper-V :
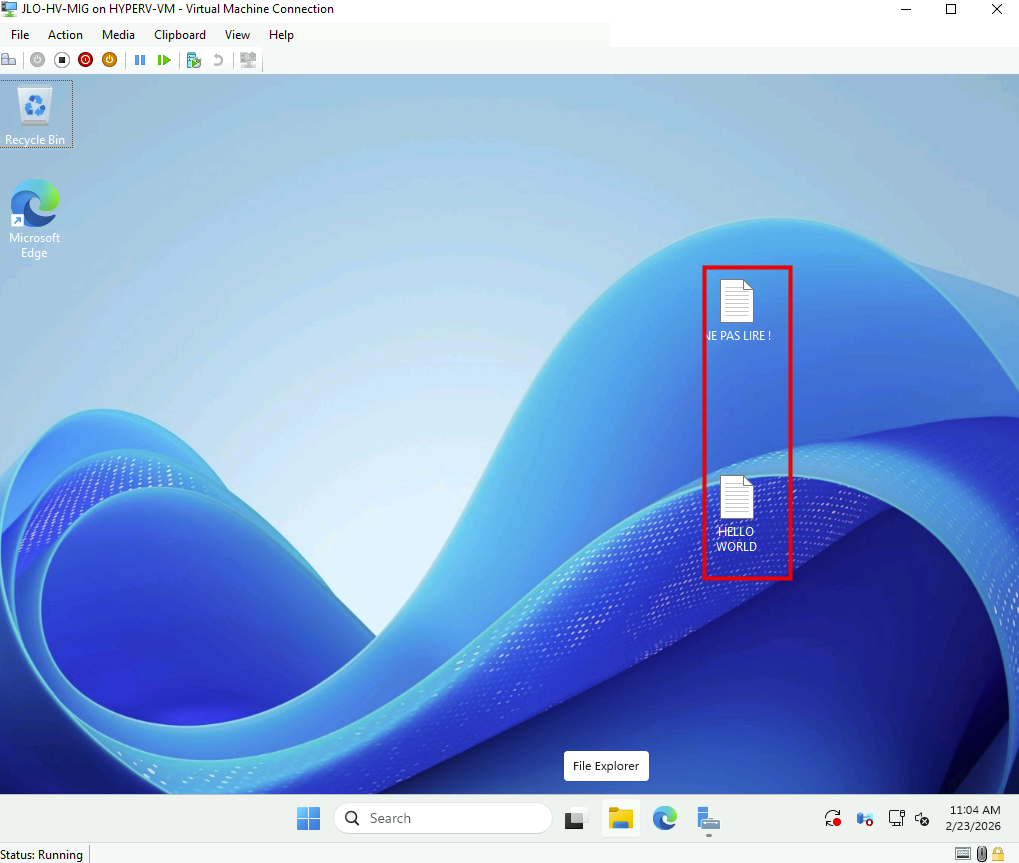
Les fichiers créés avant la commande Migrate sont bien présents après la bascule, confirmant l’intégrité de la synchronisation finale :
Notre serveur Windows a bien été migré depuis VMware vers Hyper-V avec succès. Testons maintenant la même opération avec un serveur Linux.
Etape VI – Test Linux : Synchronisation de la VM :
Exemple réalisé ici sur AlmaLinux / RHEL-like. Le but étant de :
- Désinstaller VMware Tools
- Installer composants Hyper-V
- Recréer initramfs si nécessaire
- Reboot
Pour cela créez une machine virtuelle Linux dont l’OS est compatible avec l’outil de Migration :
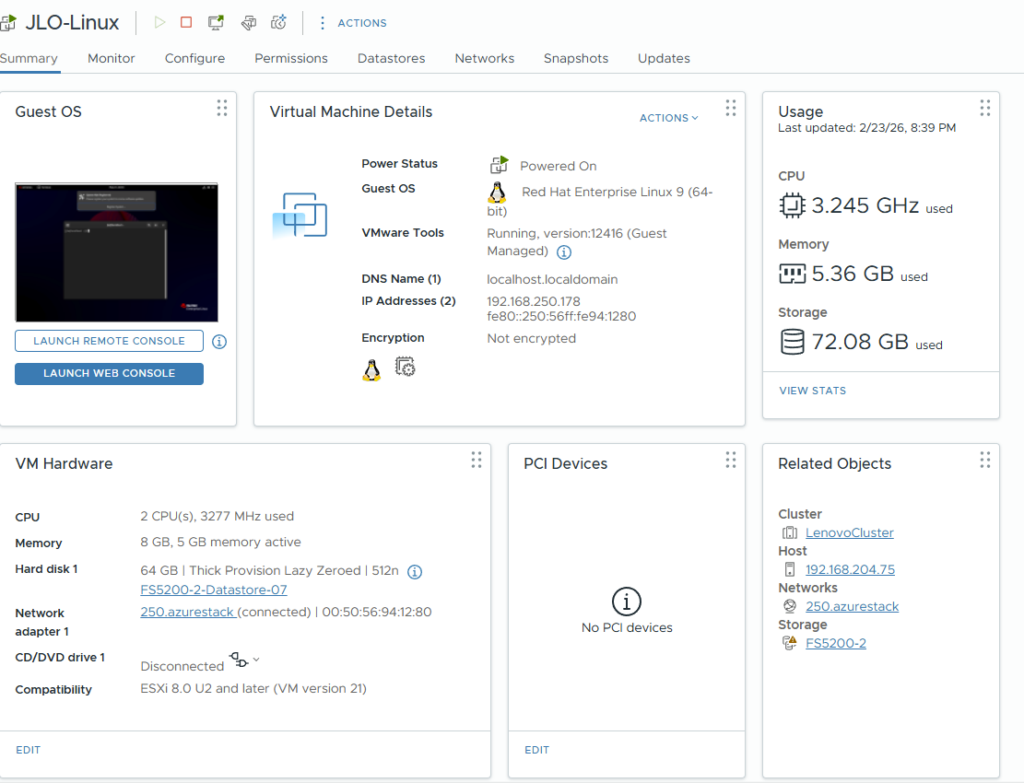
Avant la migration, ajoutez les pilotes Hyper-V à l’initramfs, reconstruction avec dracut, puis redémarrage pour assurer un démarrage correct sous Hyper-V.
echo 'add_drivers+=" hv_vmbus hv_storvsc hv_netvsc "' | sudo tee /etc/dracut.conf.d/hyperv.conf
sudo dracut -f --regenerate-all
sudo rebootToujours avant la migration, installez des services d’intégration Hyper-V (hyperv-daemons) afin d’optimiser les performances et l’interaction entre la VM Linux et l’hôte Hyper-V.
Exemple réalisé sur une distribution RHEL-like (AlmaLinux / Rocky / RHEL). (Adaptez la commande si vous êtes sur Ubuntu ou Debian) :
sudo dnf install hyperv-daemons -y
Vérifiez le chargement des modules Hyper-V (hv_*) dans le noyau Linux afin de confirmer la bonne prise en charge de l’environnement Hyper-V :

Toujours dans la liste des machines virtuelles, cochez sur une des VMs Linux disponibles, puis cliquez ici pour démarrer la synchronisation :
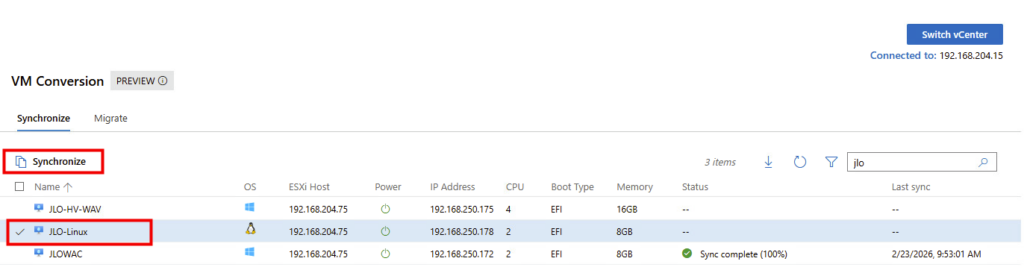
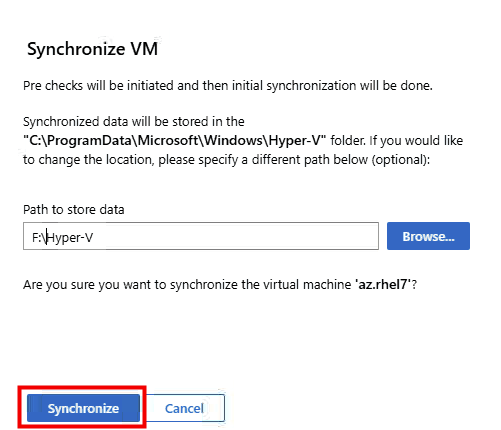
Renseignez le dossier de destination sur votre serveur Hyper-V, puis cliquez sur Synchroniser :
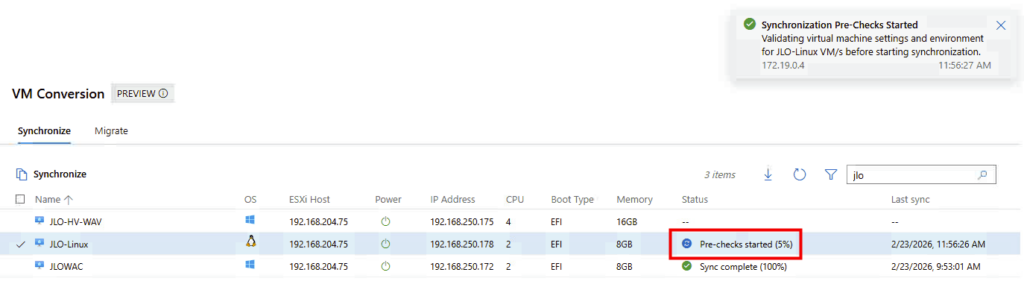
La phase de vérification préalable à la migration vient de démarrer (accessibilité, compatibilité matérielle, compatibilité OS, configuration réseau, …) :
La première copie des disques VMDK vers Hyper-V est en cours pour la création des fichiers VHDX par la suite :
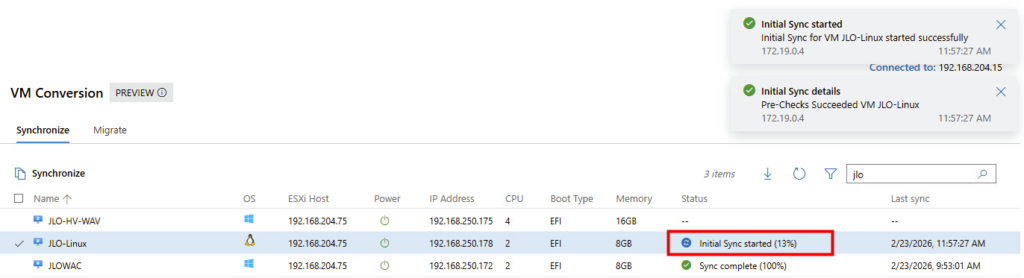
Constatez d’ailleurs la création du dossier sur le serveur Hyper-V :
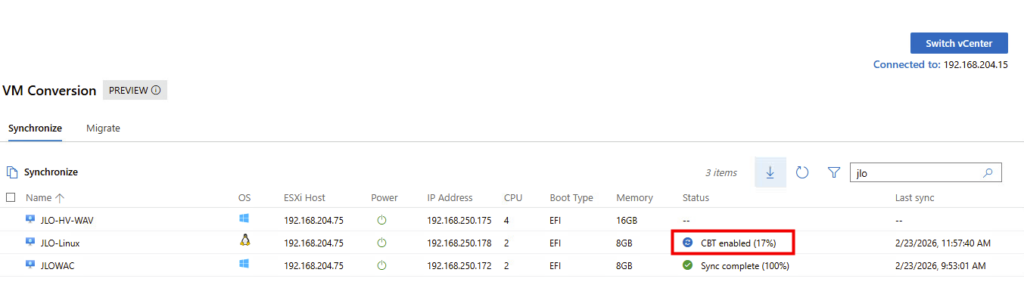
La migration passe en mode synchronisation différentielle afin de ne copier que les blocs modifiés depuis la synchronisation initiale, réduisant ainsi le volume de données à transférer avant le cutover :
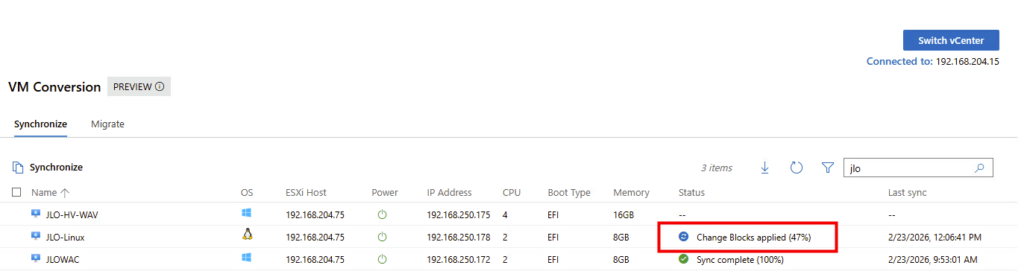
Phase de delta sync : les blocs modifiés identifiés via CBT sont appliqués au disque Hyper-V afin d’aligner la VM cible avec l’état courant de la VM source :
Le monitoring de la carte réseau montre bien le transfert des données :
Synchronisation complète (100 %) : l’intégralité des données de la VM source est maintenant répliquée côté Hyper-V :
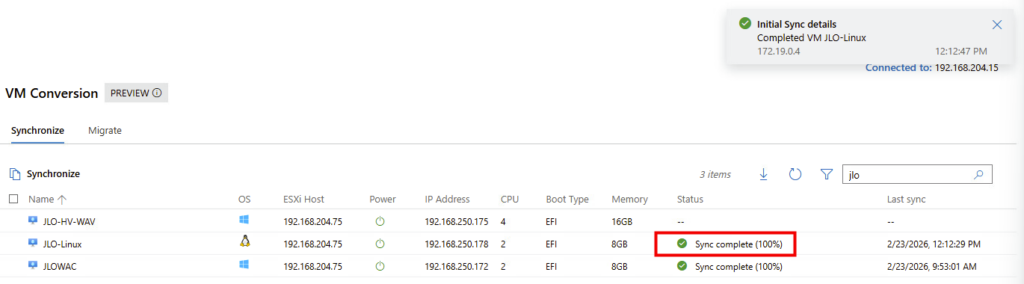
La VM cible est maintenant entièrement alignée avec la VM VMware et peut être basculée vers Hyper-V avec un dernier delta minimal.
Nous allons pouvoir procéder à la migration.
Etape VII – Test Linux : Migration de la VM :
Retournez ensuite sur Windows Admin Center afin de lancer la migration de celle-ci :
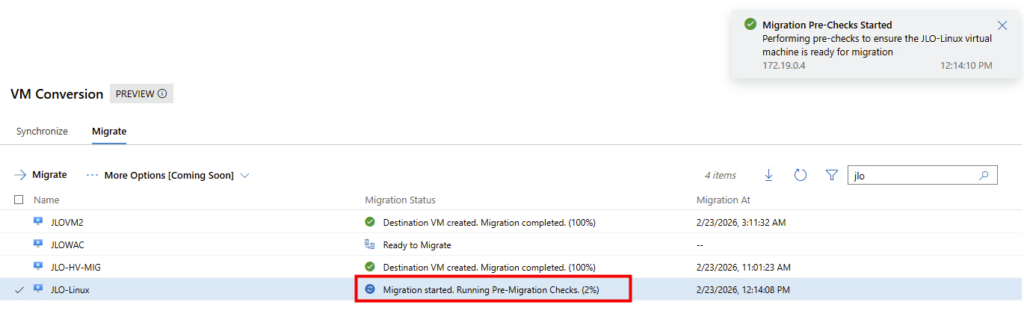
Lancement de la migration : exécution des vérifications préalables avant bascule définitive vers la VM Hyper-V cible :
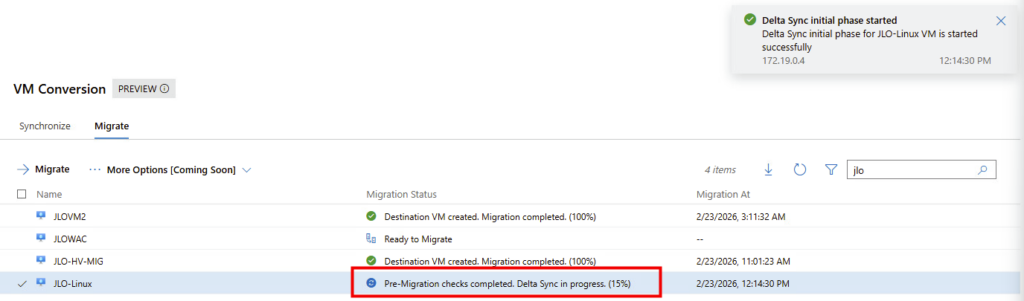
Arrêt de la VM source : la machine VMware est éteinte et la phase finale de synchronisation est lancée avant le démarrage côté Hyper-V :
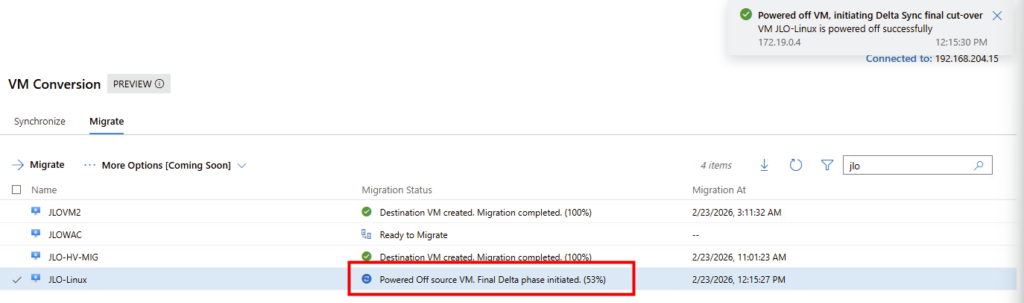
La machine virtuelle est bien arrêtée côté VMware :
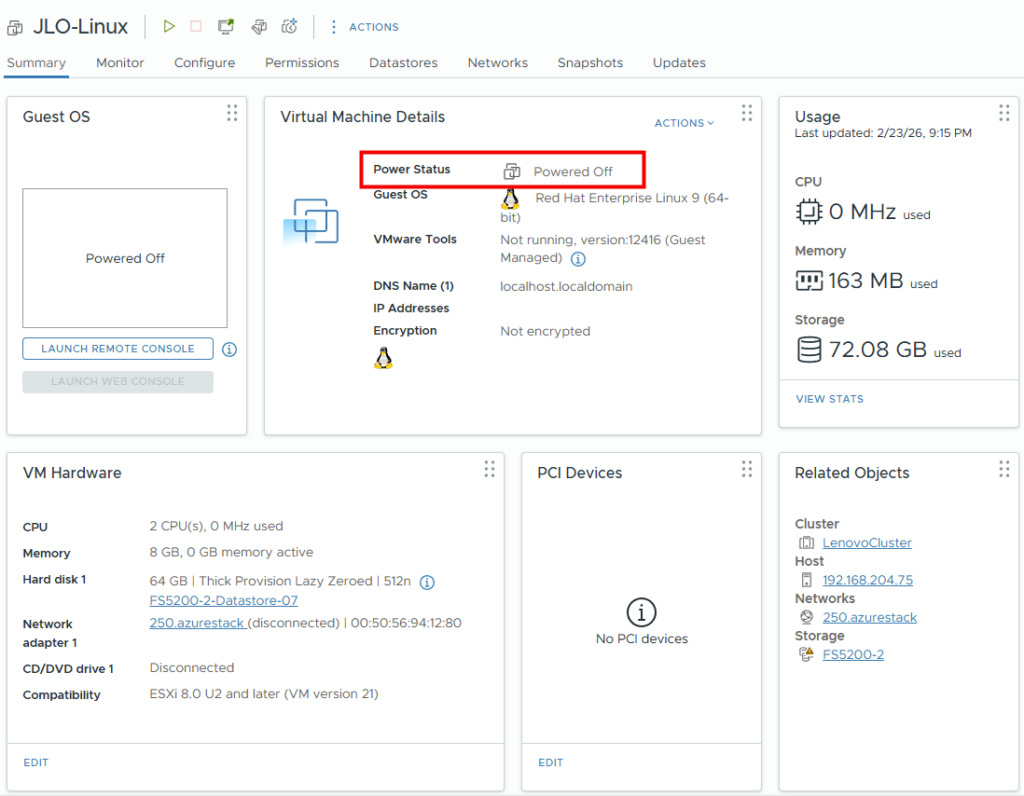
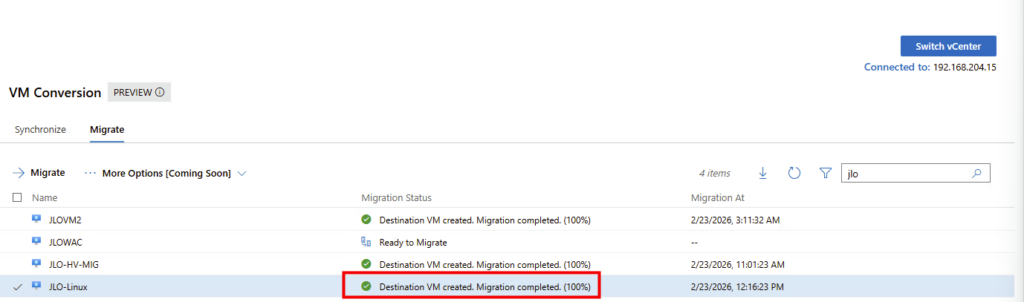
Migration terminée (100 %) : la VM cible Hyper-V est créée, synchronisée et prête à être démarrée en production :
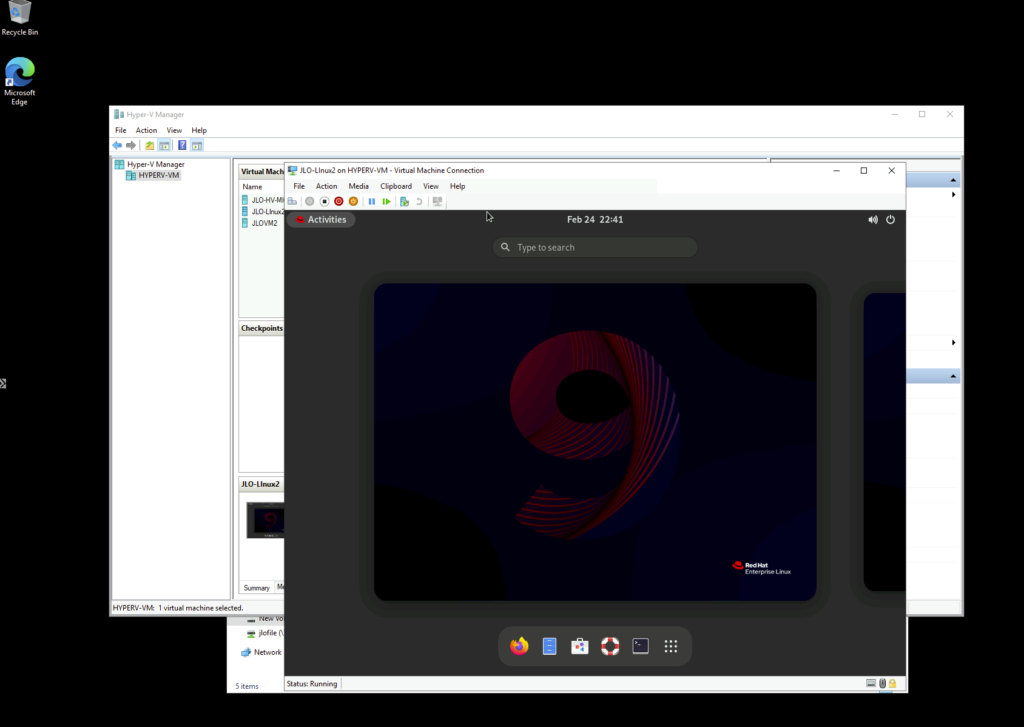
La VM migrée s’exécute désormais sur Hyper-V, confirmant le succès du cutover depuis l’environnement VMware :
Conclusion
La migration d’un environnement VMware vers Hyper-V n’est jamais une décision anodine. Elle est souvent motivée par des enjeux économiques, stratégiques ou organisationnels. Mais quelle qu’en soit la raison, elle doit rester avant tout une opération maîtrisée, structurée et techniquement fiable.
L’extension VM Conversion de Windows Admin Center n’est pas un simple assistant graphique. Elle propose une approche orchestrée et cohérente : synchronisation initiale, delta via CBT, puis phase de bascule contrôlée. Ce n’est pas “magique” et cela ne dispense pas d’une préparation sérieuse. En revanche, l’outil apporte un cadre clair qui simplifie fortement un processus historiquement complexe.
Dans mes tests, l’expérience s’est révélée stable et lisible. La gestion des clusters Hyper-V (WSFC), la logique de synchronisation progressive et l’interface unifiée dans WAC rendent la migration bien plus accessible qu’avec des méthodes artisanales. Cela reste une extension en preview, donc à évaluer sérieusement en environnement de test avant toute utilisation en production, mais la base technique est solide.
Ce qui est certain, c’est qu’une alternative crédible existe désormais pour les organisations qui souhaitent diversifier ou repositionner leur stratégie d’hyperviseur. La migration ne doit plus être perçue comme un saut dans l’inconnu, mais comme un projet structuré, pilotable et documenté.