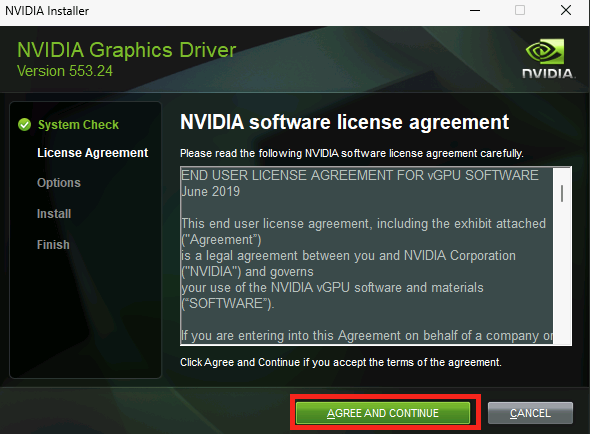
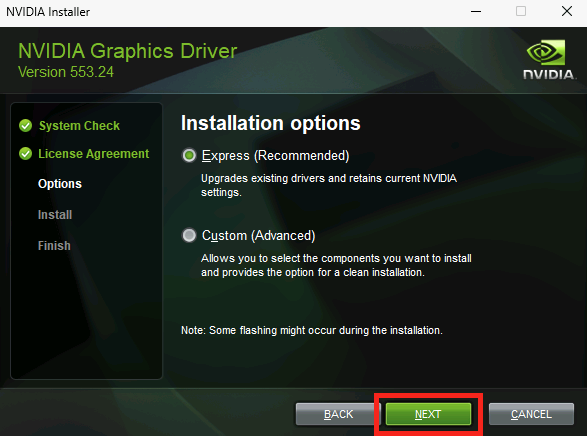
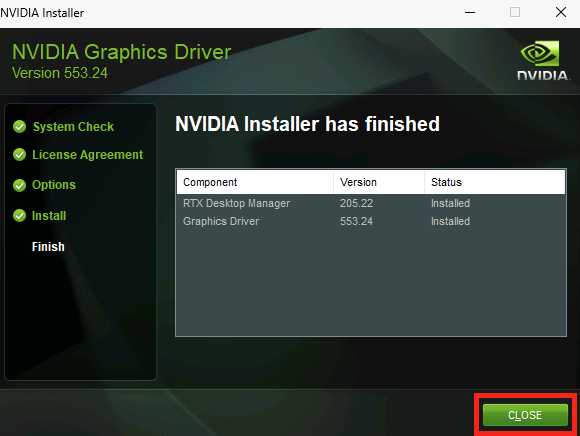
Microsoft continue d’aider la communauté des développeurs AI et propose désormais de nouveaux modèles d’applications Chat IA développé en .NET. Avec ces modèles d’application comme point de départ, vous pouvez rapidement créer des applications web de chat avec un ou des modèles d’intelligence artificielle dédiés. Tous ces modèles d’application AI en .NET sont désormais disponibles en préversion depuis mars 2025.

Vous souhaitez vous lancer dans le développement de l’IA, mais vous ne savez pas par où commencer ? J’ai un cadeau pour vous : nous avons un nouveau modèle d’application Web de chat sur l’IA qui est maintenant disponible en avant-première. 😊 Ce modèle fait partie de nos efforts continus pour faciliter la découverte et l’utilisation du développement de l’IA avec .NET
A quoi sert une application développée pour du chat IA ?
Une application de chat IA ne se contente pas de générer des réponses : elle les enrichit à partir de contenus existants (comme du code, des documents, etc.).
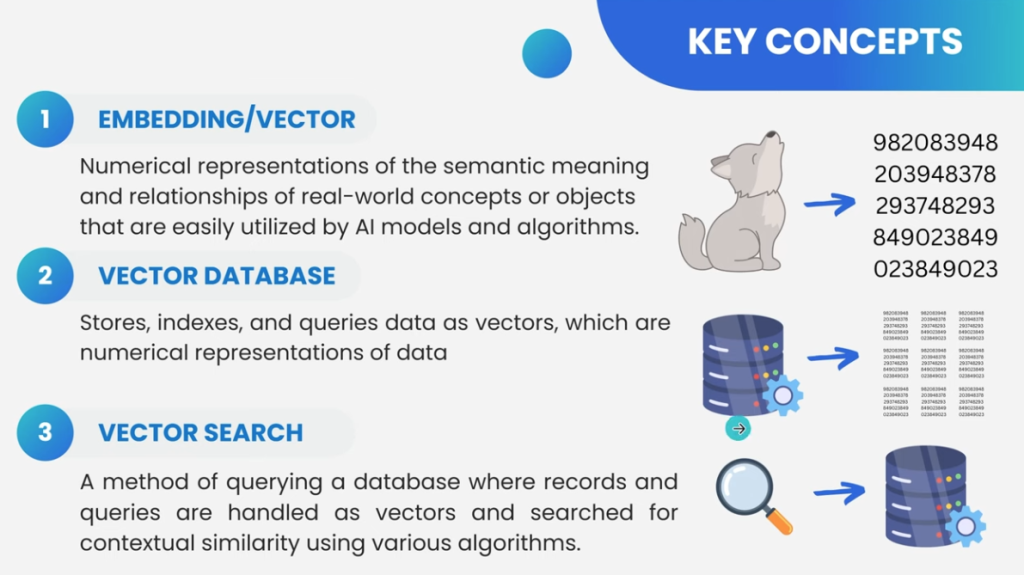
- Un modèle d’embedding, qui transforme des textes en vecteurs numériques.
→ Il est utilisé pour rechercher les passages les plus pertinents dans une base de connaissances locale ou distante. - Un modèle génératif, qui prend ces passages et génère une réponse claire et naturelle, dans le style d’un assistant conversationnel.
Deux modèles, deux usages ?
Quand on développe une application en relation avec des modèles l’intelligence artificielle intégrant de la données, il est important de comprendre la différence entre deux grandes catégories de modèles d’IA :
1. Modèle de génération de texte (aussi appelés LLM – Large Language Models)
🔹 Objectif : Générer du texte naturel en réponse à une consigne
🔹 Entrée : Une instruction, un prompt ou une question
🔹 Sortie : Une réponse en langage humain, souvent contextualisée
🔹 Cas d’usage :
- Assistants conversationnels (chatbots)
- Rédaction automatique de contenu
- Résumé ou reformulation de documents
- Réponse à des questions en langage naturel
🧪 Exemple d’interaction :
Entrée : “Explique-moi le fonctionnement d’un moteur thermique.”
Sortie : “Un moteur thermique fonctionne en convertissant la chaleur issue de la combustion d’un carburant en énergie mécanique…”
2. Modèle d’embedding (encodage vectoriel)
🔹 Objectif : Représenter un texte sous forme de vecteur numérique pour comparaison sémantique
🔹 Entrée : Une phrase, un document, une question, etc.
🔹 Sortie : Un vecteur (tableau de nombres) capturant le sens du texte
🔹 Cas d’usage :
- Recherche sémantique (trouver un document similaire)
- Détection de doublons ou de similarité
- Indexation pour des bases vectorielles
- Classement ou regroupement de contenus (clustering)
🧪 Exemple d’interaction :
Entrée : “Comment entretenir une voiture électrique ?”
Sortie :[0.12, -0.03, 0.57, ...](vecteur utilisable pour comparer avec d’autres)
Comment ce modèle d’application est-il construit ?
Architecture et technologies :
- Application web Blazor (.NET) avec des composants Razor interactifs côté serveur
- Base de données SQLite utilisée pour le cache d’ingestion via Entity Framework Core
- Intégration avec les modèles d’IA d’Azure OpenAI Service
Fonctionnalités principales :
- Chat avec IA augmentée par récupération (RAG)
- Utilise un modèle d’IA pour générer des réponses intelligentes
- Les réponses sont enrichies par des données extraites de documents
- Traitement de documents
- Ingère des fichiers PDF (stockés dans Data)
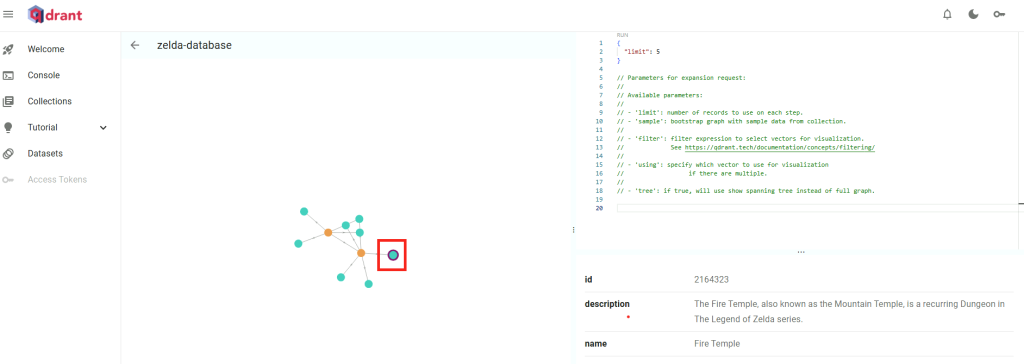
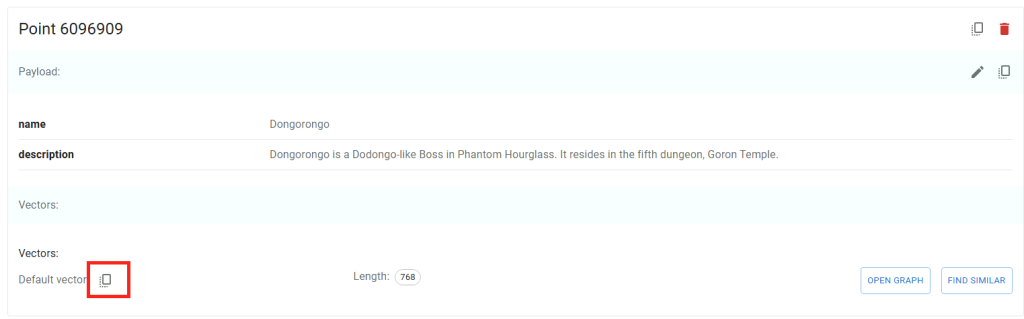
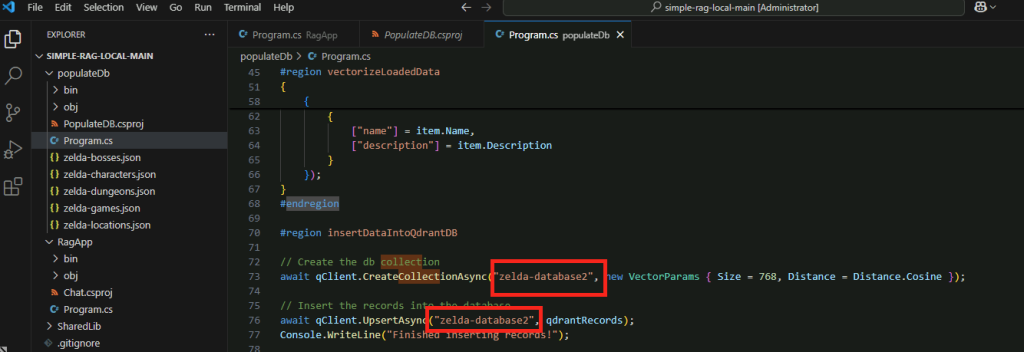
- Extrait le texte et crée des embeddings vectoriels via un modèle de type embedding
- Stocke les vecteurs dans un JsonVectorStore pour les recherches sémantiques
- Interface utilisateur
- Composants de chat interactifs (ChatMessageList, ChatInput)
- Rendu Markdown et sanitisation HTML via les bibliothèques JavaScript
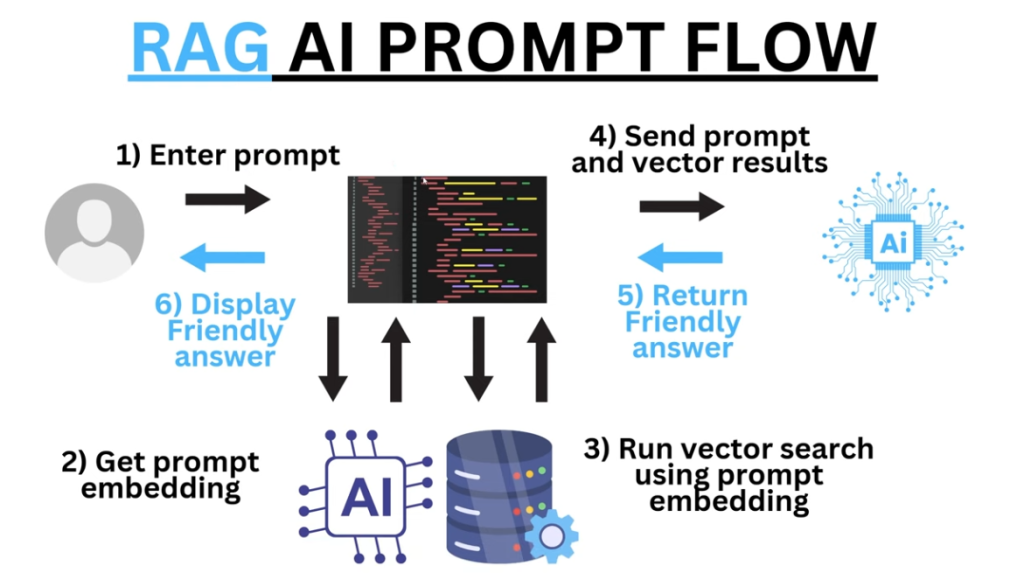
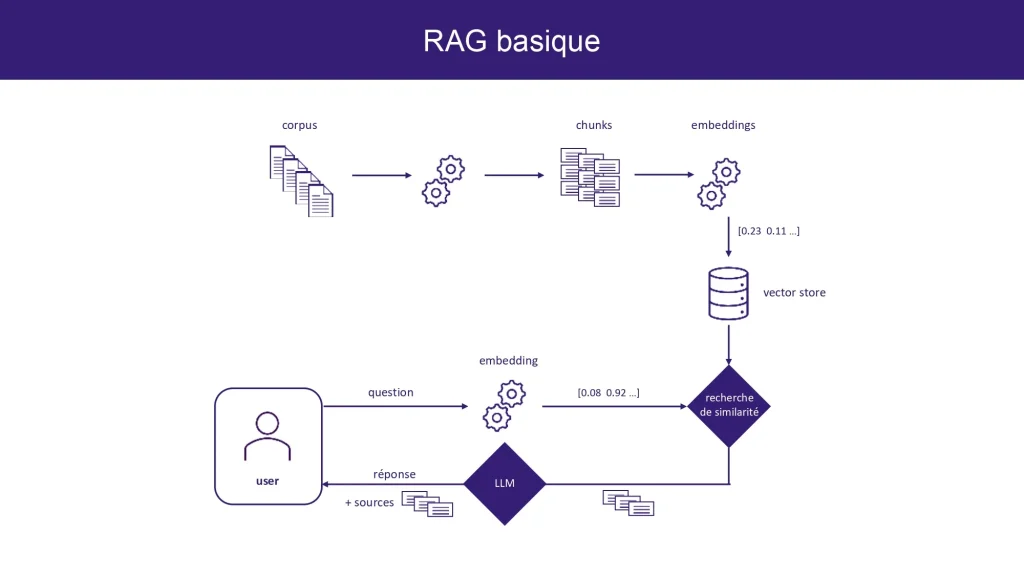
Workflow :
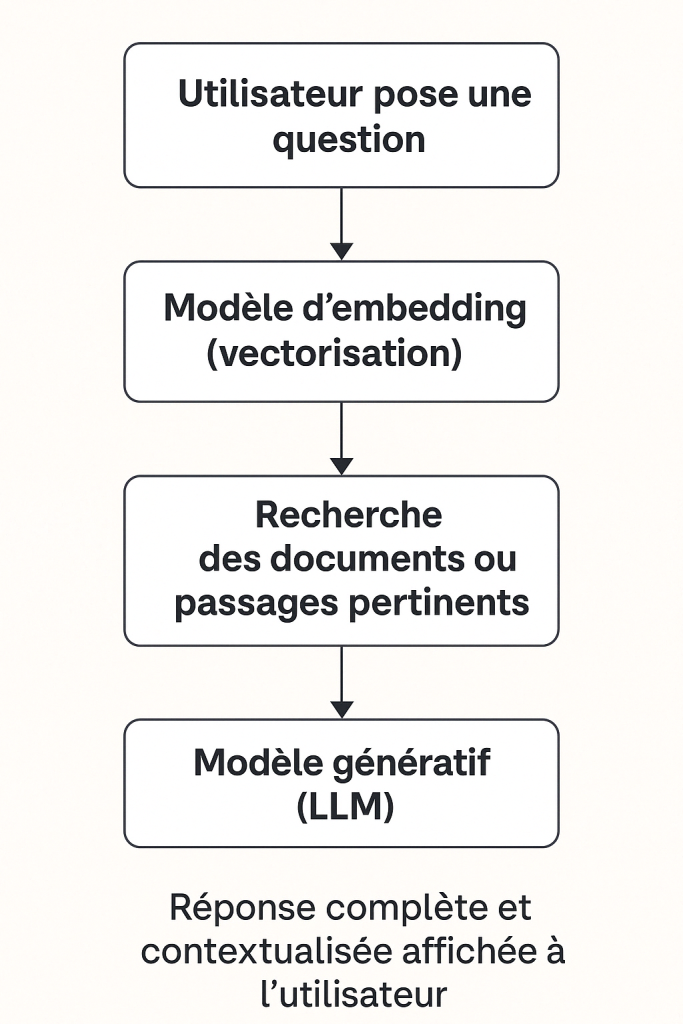
- Au démarrage, l’application ingère les documents (par exemple des fichiers PDF), les découpe en fragments, puis les encode sous forme de vecteurs numériques grâce au modèle d’embedding (Modèle 2).
- L’utilisateur interagit via l’interface de chat, en posant une question en langage naturel. Cette requête est ensuite traitée par le modèle génératif (Modèle 1), mais pas directement…
- Avant de répondre, le système utilise le modèle d’embedding (Modèle 2) pour retrouver les passages les plus pertinents dans les documents indexés, en comparant leur sens avec celui de la question.
- Enfin, le modèle génératif (Modèle 1) s’appuie à la fois sur ces passages trouvés et sur ses propres connaissances générales pour générer une réponse complète, claire et contextualisée.
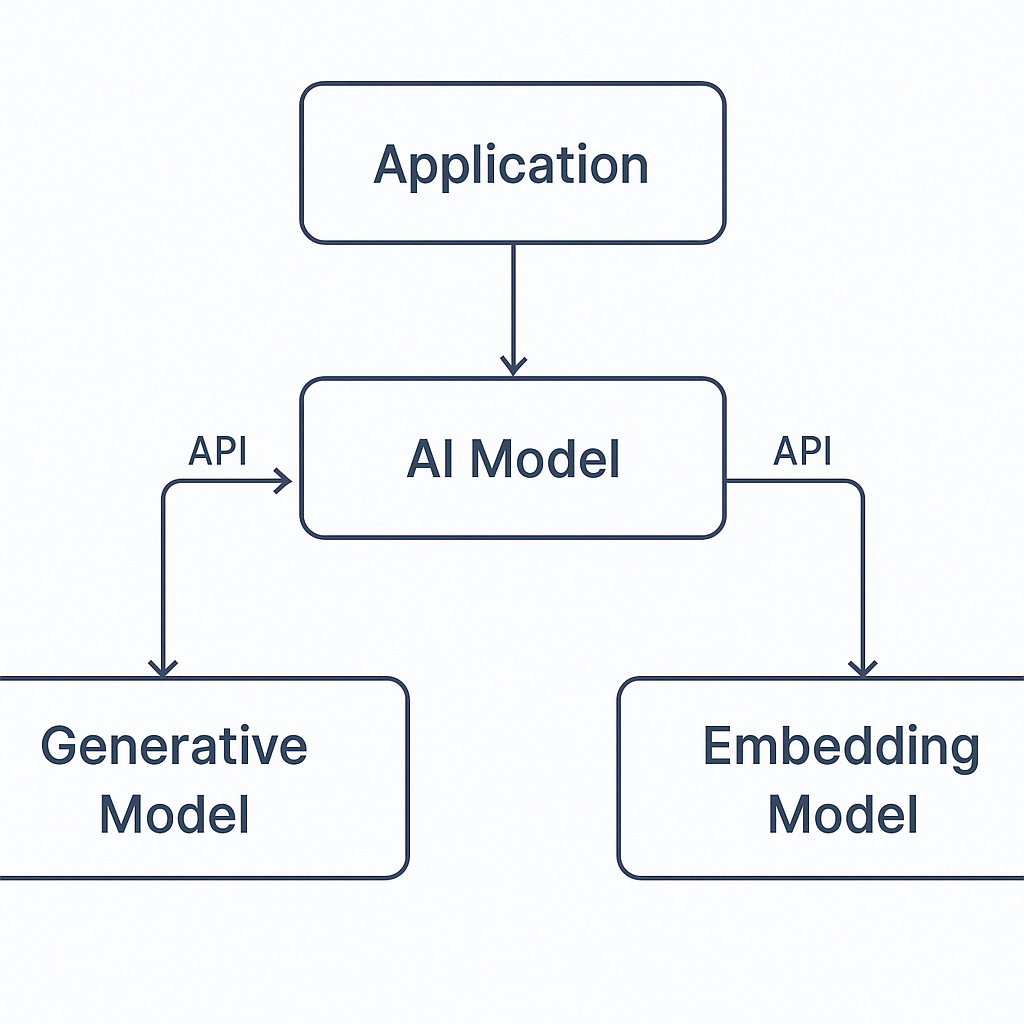
Comment connecte-t-on cette application avec un modèle d’IA ?
Ces exemples d’application ne contiennent pas l’intelligence artificielle elle-même, mais elle interagit avec un modèle IA externe (hébergé dans le cloud, en local ou dans un container).
Enfin, découvrez le dernier épisode du stand-up de la communauté .NET AI, dans lequel Alex, Bruno et Jordan présentent les nouveaux modèles :
Dans cet article, je vous propose de tester l’application en connectant celle-ci vers 3 modèles d’IA :
- GitHub
- Azure OpenAI
- Ollama
Voici les différentes étapes que nous allons suivre :
- Etape 0 – Rappel des prérequis
- Etape I – Préparation du poste local
- Etape II – Test de l’application avec le modèle GitHub
- Etape III – Test de l’application avec le modèle Azure OpenAI
- Etape IV – Test de l’application avec le modèle Ollama
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
Etape 0 – Rappel des prérequis :
Afin de tester les différents modèles AI en .NET, nous allons avoir besoin de :
- Un poste local
- Un compte GitHub des modèles GitHub Models
- Une souscription Azure si utilisation du service Azure OpenAI
Commençons par créer préparer le poste local.
Etape I – Préparation du poste local :
Rendez-vous sur la page suivante afin de télécharger Visual Studio Code :

Une fois téléchargée, lancez l’installation de ce dernier :
Rendez-vous sur la page suivante afin de télécharger la version 9.0 de .NET :

Une fois téléchargée, lancez l’installation :
Une fois l’installation réussie, fermez celle-ci :
Enfin, redémarrez le poste local :
Une fois le poste local redémarré, ouvrez Windows Terminal :
Installer les modèles de projet pour l’extension .NET liée à Microsoft.Extensions.AI, qui fait partie de l’écosystème Semantic Kernel :
dotnet new install Microsoft.Extensions.AI.Templates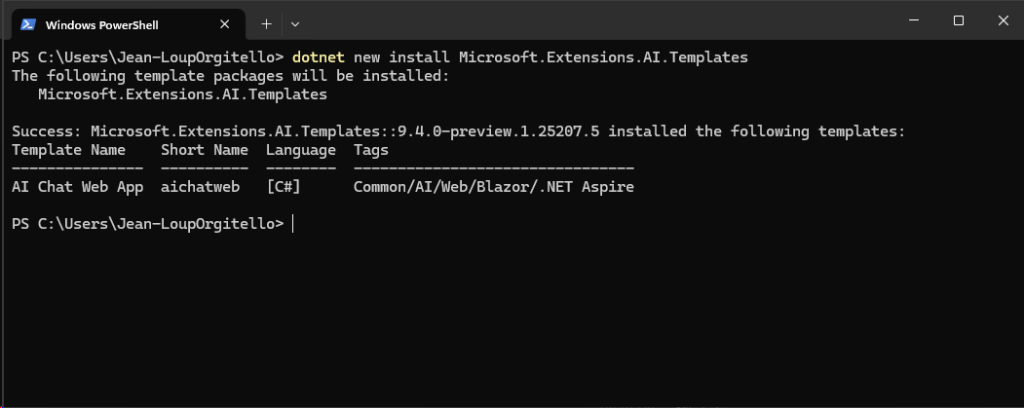
Créez un dossier sur votre poste, puis positionnez-vous dedans :
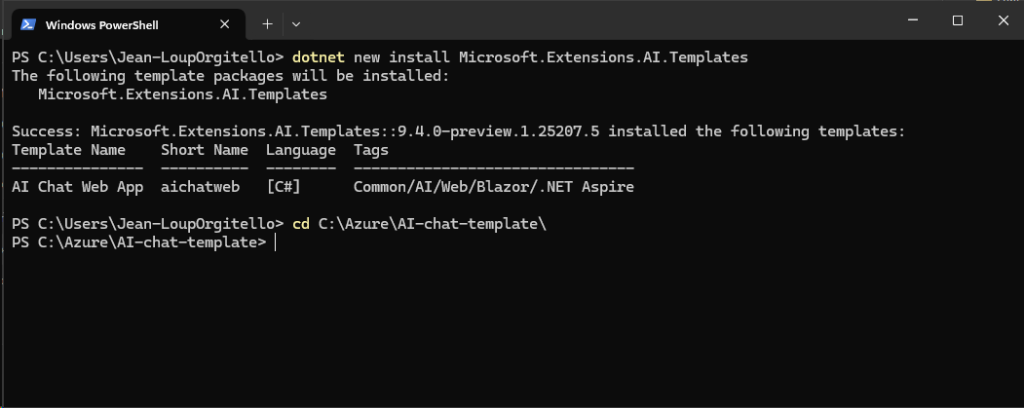
Ne fermez pas cette fenêtre Windows PowerShell.
Notre environnement local est prêt. Avant de déployer des applications basées sur les templates d’IA, nous avons besoin de récupérer les identifiants de connexion (token) de certains modèles IA. Commençons par le plus simple : GitHub.
Etape II – Test de l’application avec le modèle GitHub :
Rendez-vous sur la page d’accueil de GitHub, puis authentifiez-vous, ou créez un compte au besoin :

Cliquez sur votre photo de profil en haut à droite, puis cliquez sur le bouton des Paramètres :
Tout en bas, cliquez sur le menu des paramètres suivant :
Créez un token à granularité fine, pour une utilisation personnelle de l’API GitHub :
Nommez ce token, puis choisissez une date d’expiration :
Cliquez-ici pour générer ce token :
Confirmez votre choix :
Copiez la valeur du token GitHub :
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le modèle GitHub :
dotnet new aichatweb -n GitHubModels --provider githubmodels --vector-store local
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier ainsi que le code de l’application :
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
Ouvrez la fenêtre Terminal :
Stockez un secret utilisateur localement (ici un token) de manière sécurisée pour notre projet .NET :
dotnet user-secrets set GitHubModels:Token github...
Affichez tous les secrets stockés localement pour le projet courant :
dotnet user-secrets list
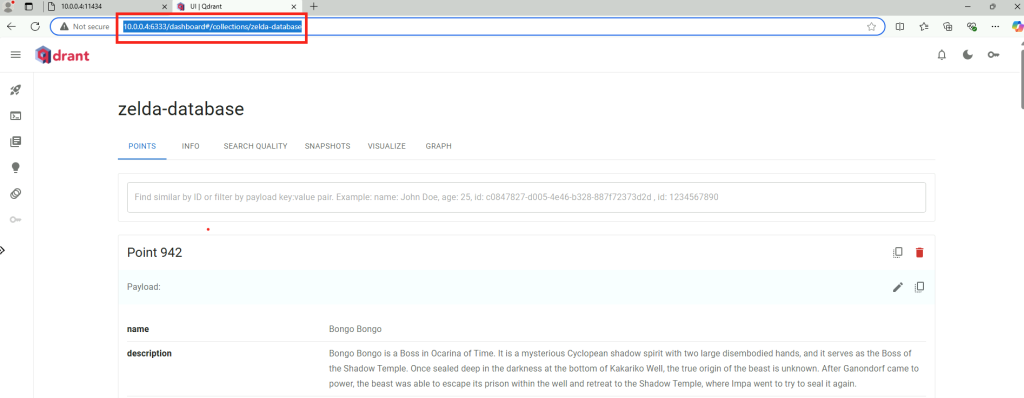
Ajoutez ou retirer au besoin des fichiers PDF utilisés durant la phase d’indexation sémantique)
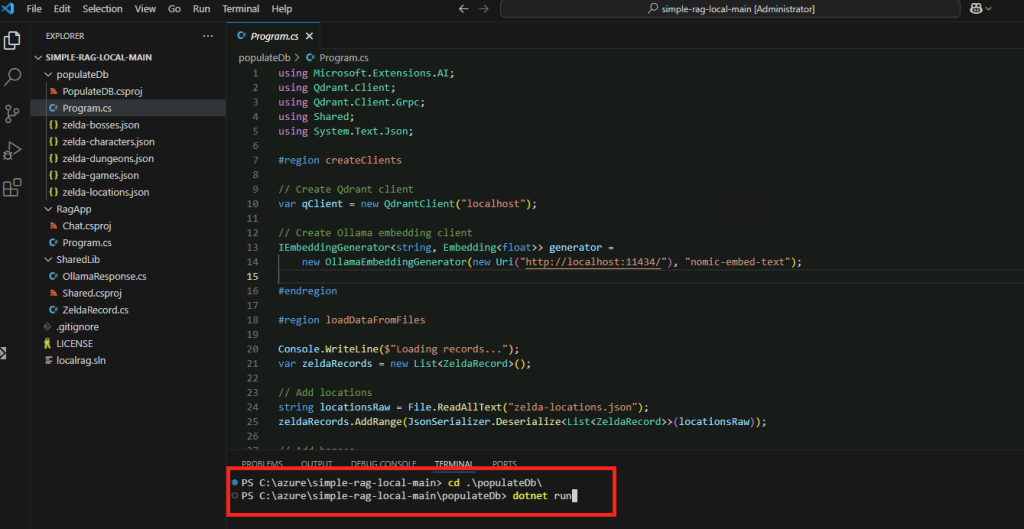
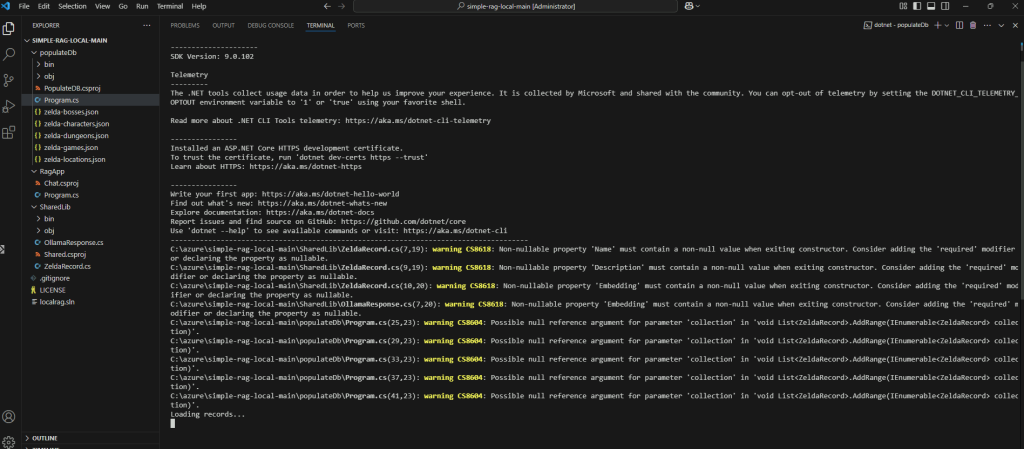
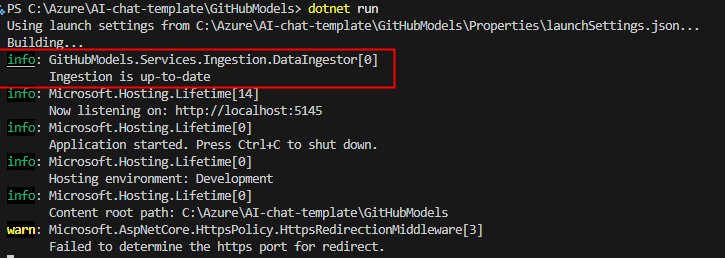
Compilez et exécutez l’application .NET dans le dossier courant :
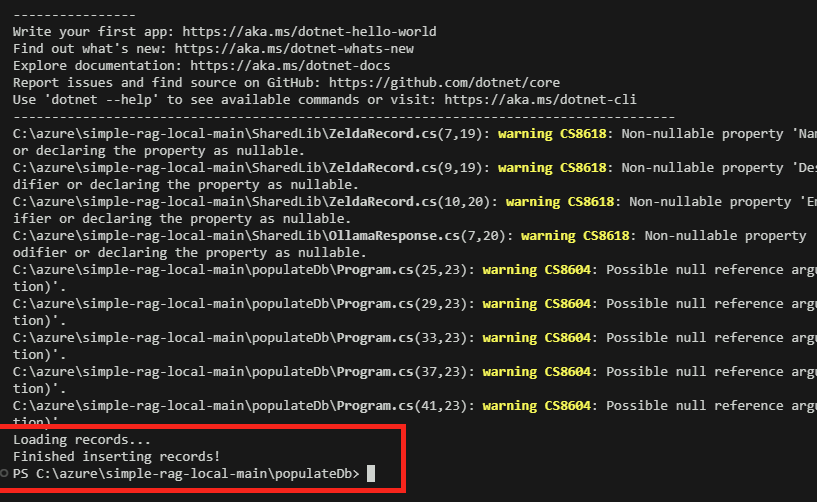
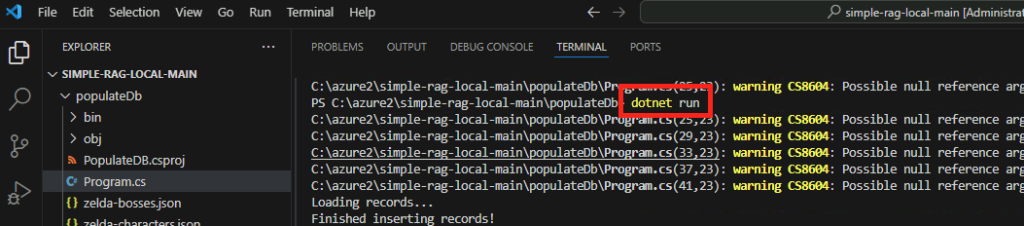
dotnet runL’application vérifie dans les sources de données si nouveau documents sont à indexer ou vectoriser :
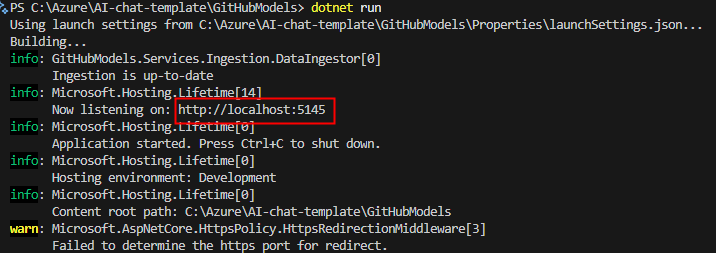
Ce message vous indique que l’application tourne localement sur le port 5145 :
Ouvrez un navigateur web à cette adresse:port, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ingérés :
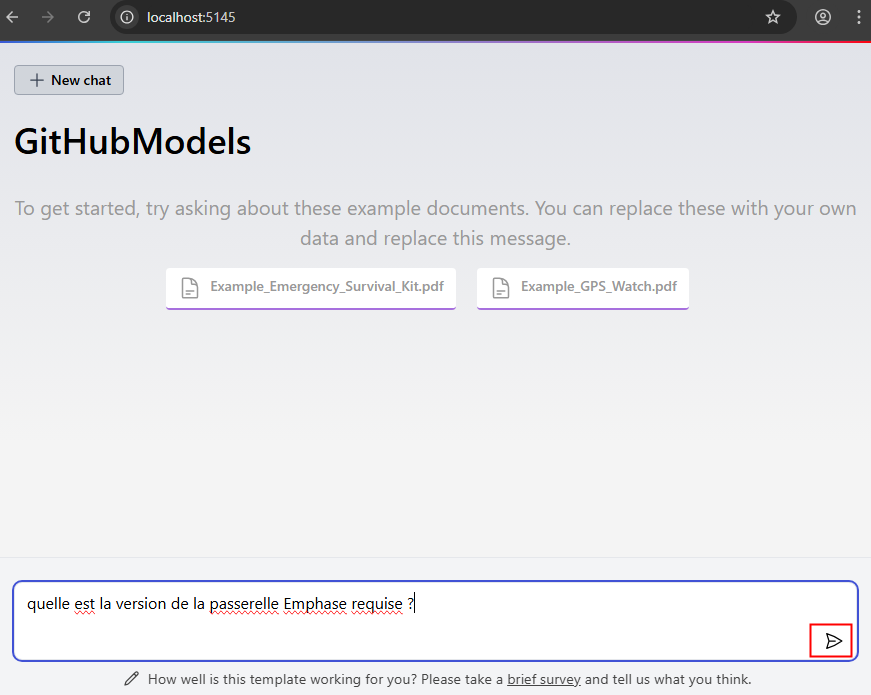
Constatez la rapidité du résultat et la ou les sources associés, puis cliquez dessus :
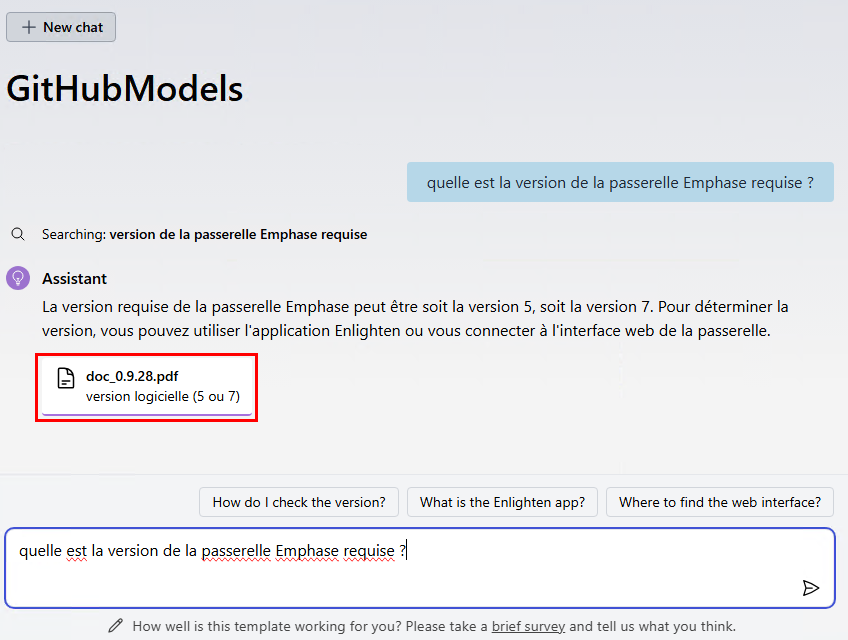
Constatez la sélection de texte en correspondance avec la question posée à l’IA :
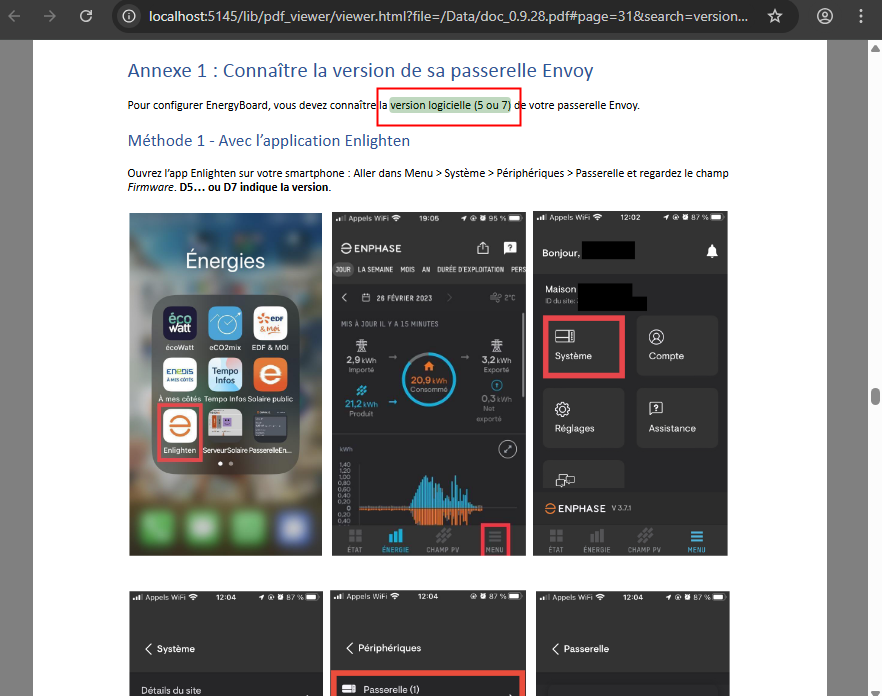
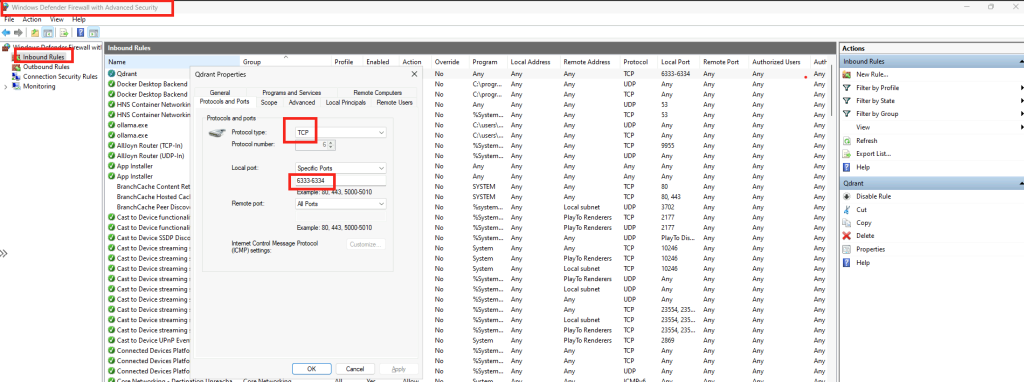
Le test avec le modèle GitHub a bien fonctionné, pensez à détruire le token sur le portail de GitHub pour des questions de sécurité
Continuons les tests de l’application de chat IA avec le modèle Azure OpenAI.
Etape III – Test de l’application avec le modèle Azure OpenAI :
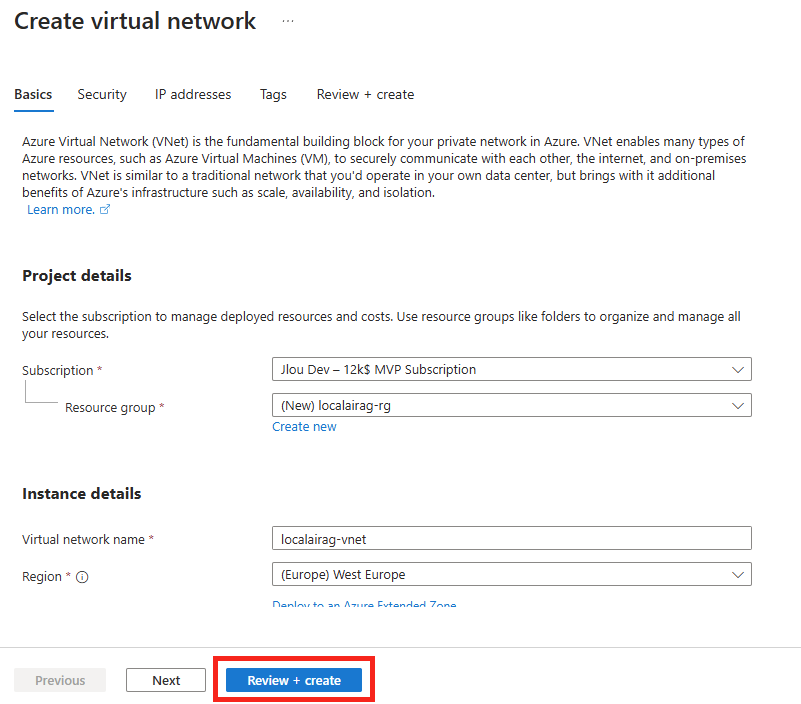
Depuis le portail Azure, commencez par rechercher le service Azure OpenAI :
Cliquez-ici pour créer un nouveau service :
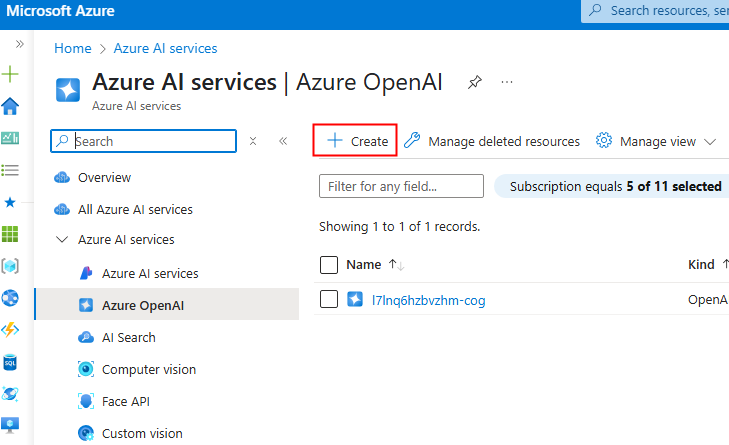
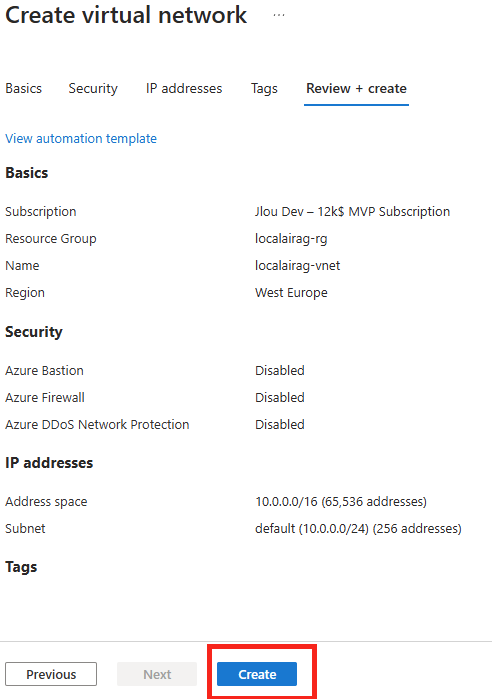
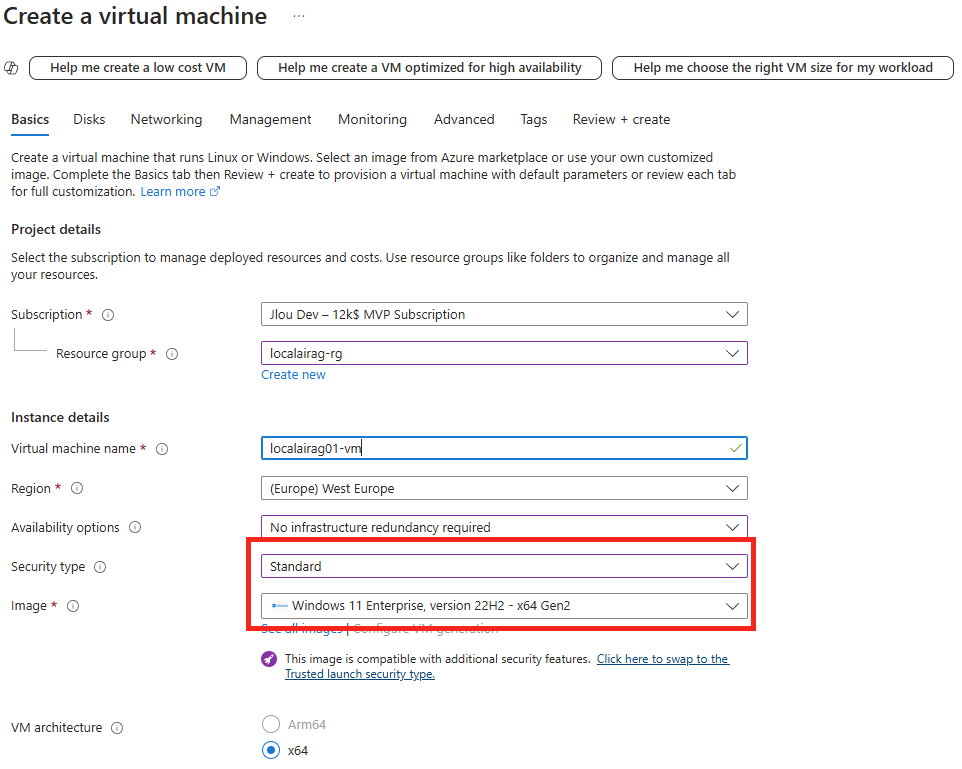
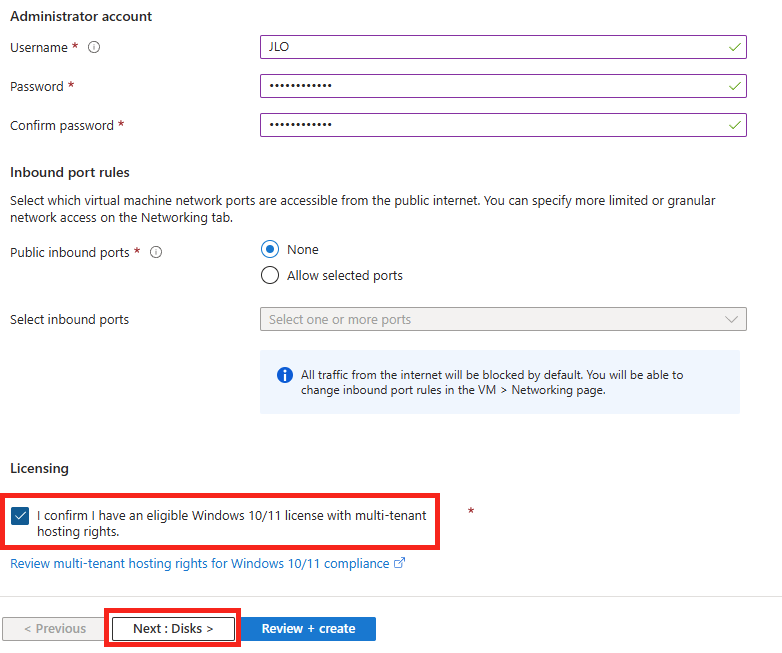
Renseignez toutes les informations, conservez le modèle de prix S0 (suffisant pour nos tests), puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
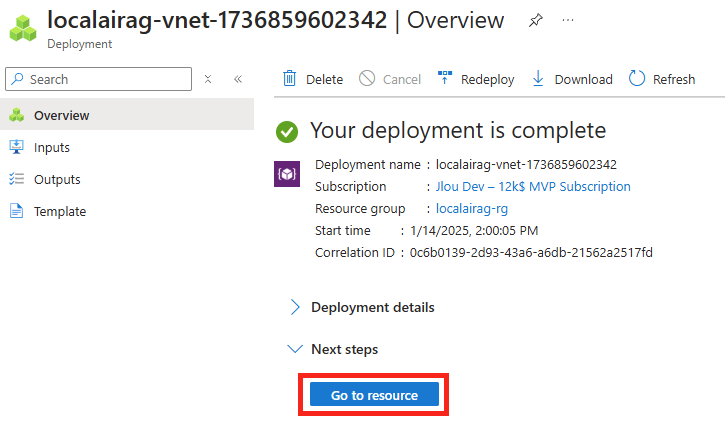
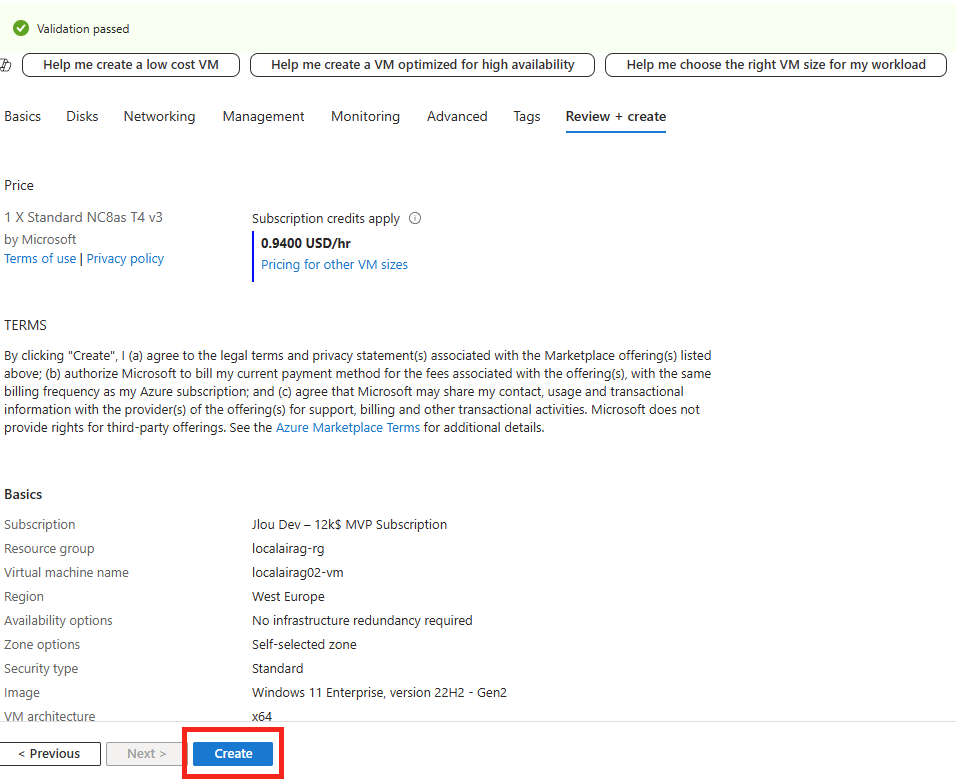
Cliquez sur Créer :
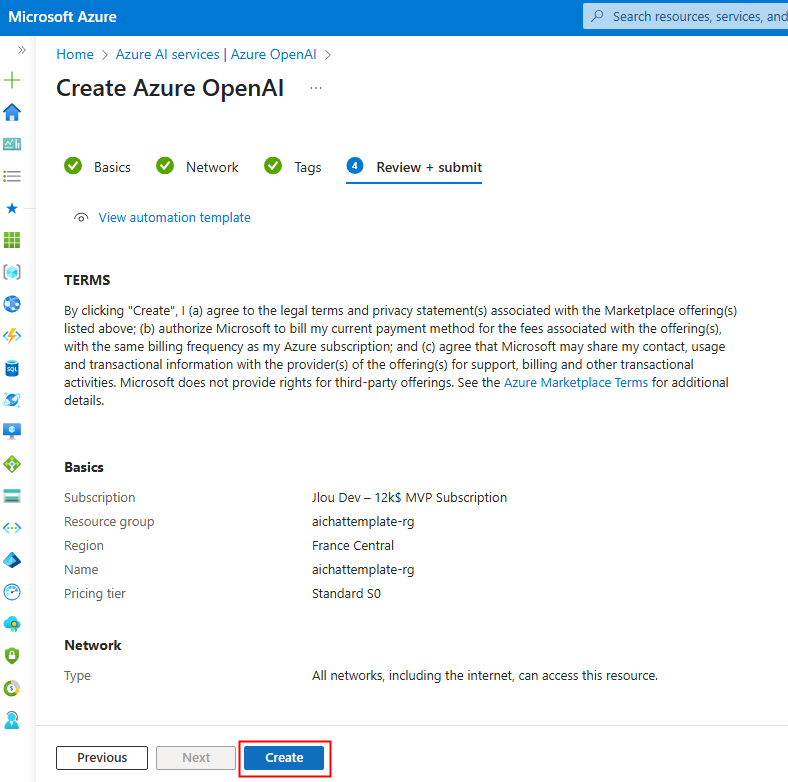
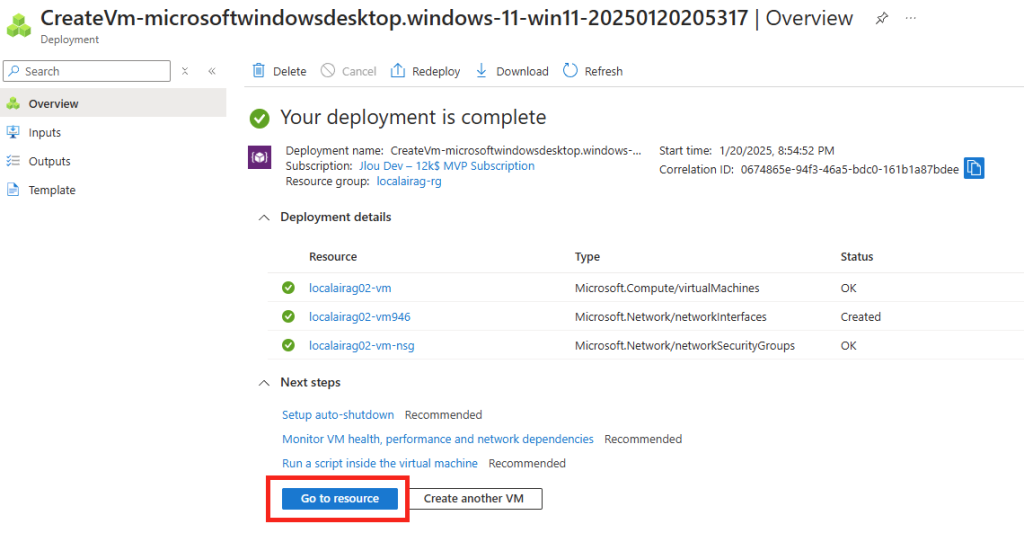
Une fois le déploiement terminé, cliquez-ici :
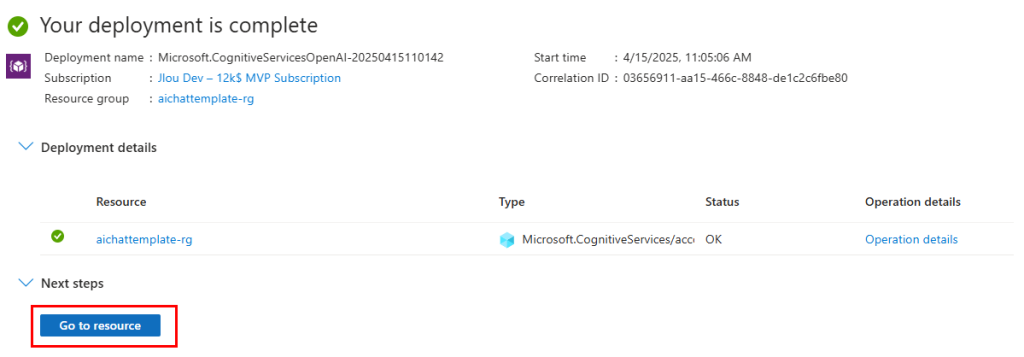
Copiez les 2 informations suivantes dans votre bloc-notes afin de vous y connecter plus tard à via API :
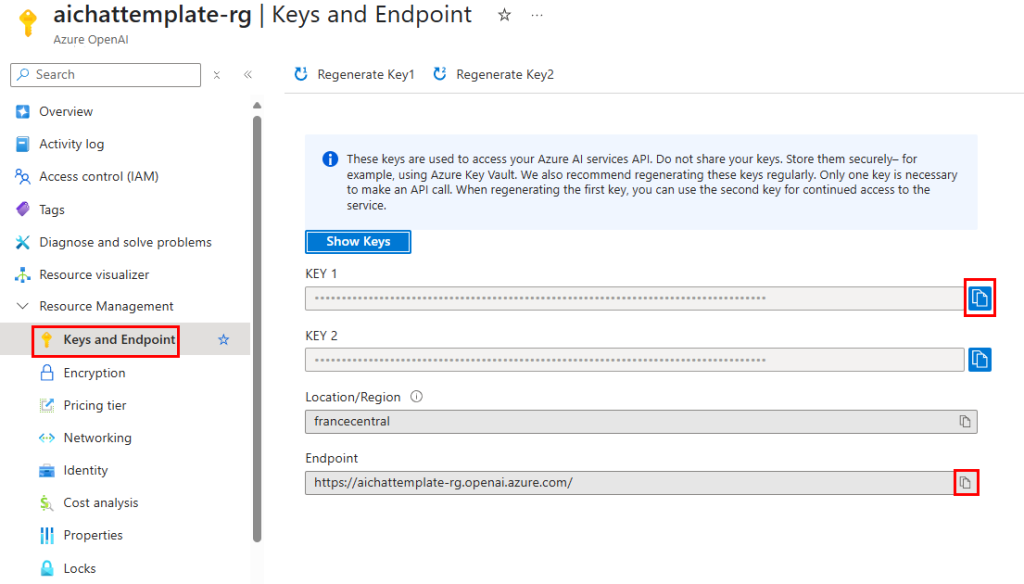
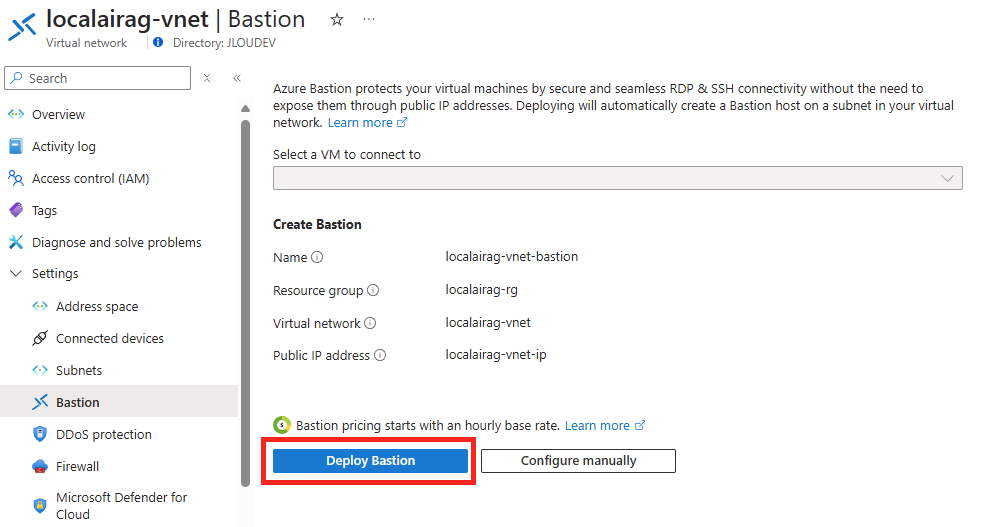
Afin de créer les deux modèle d’IA nécessaires au travers d’Azure, cliquez-ici pour ouvrir le portail Microsoft AI Foundry :
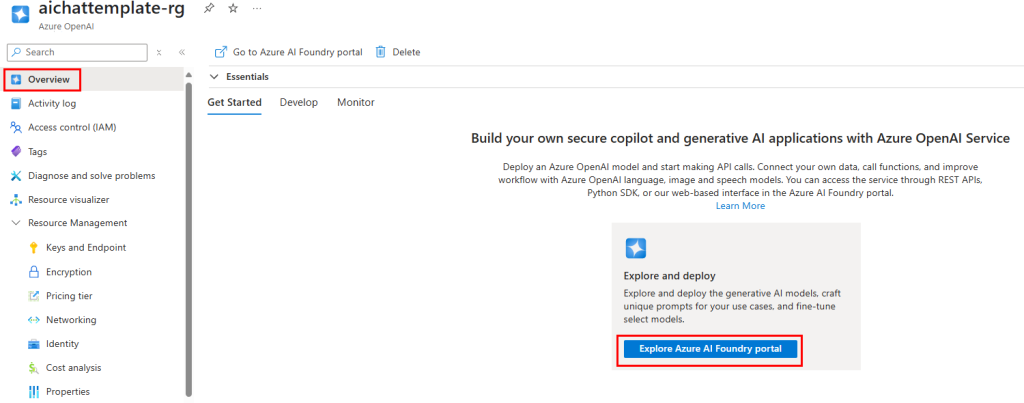
Sur ce portail, commencez par rechercher le premier modèle d’IA nécessaire à notre application :
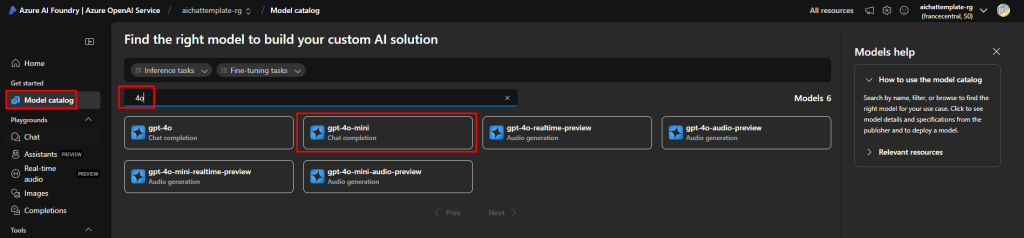
Cliquez sur Déployer :
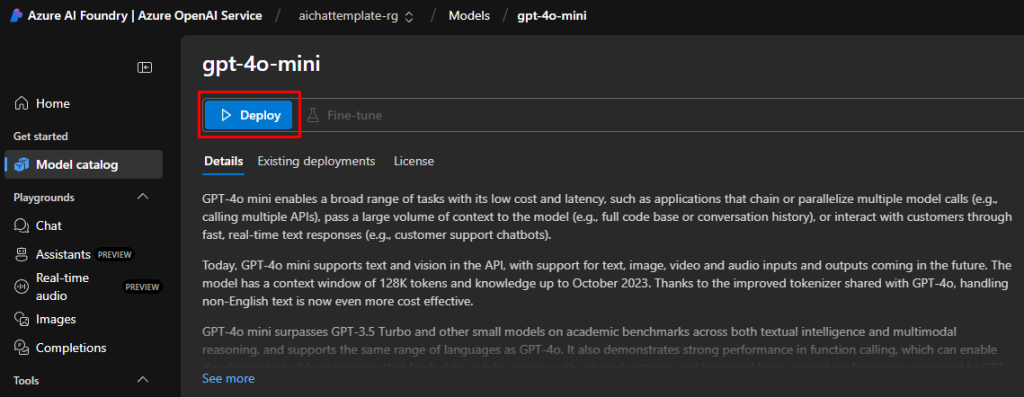
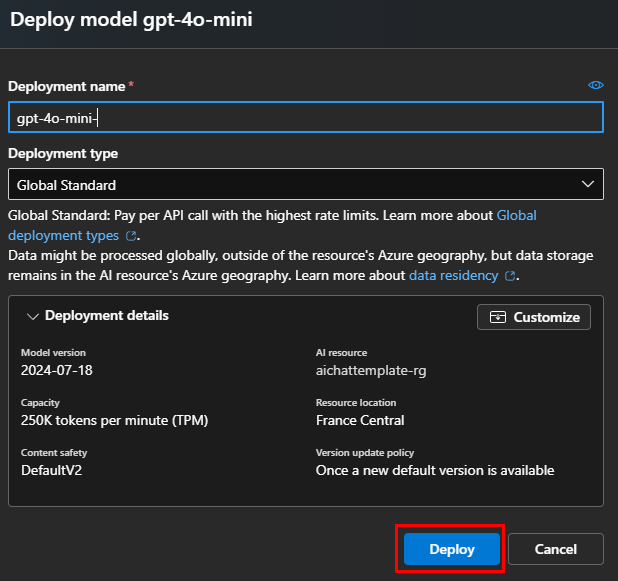
Conservez le nom d’origine, puis cliquez sur Déployer :
Retournez sur le catalogue des modèles d’IA, puis recherchez le second modèle d’IA nécessaire à notre application :
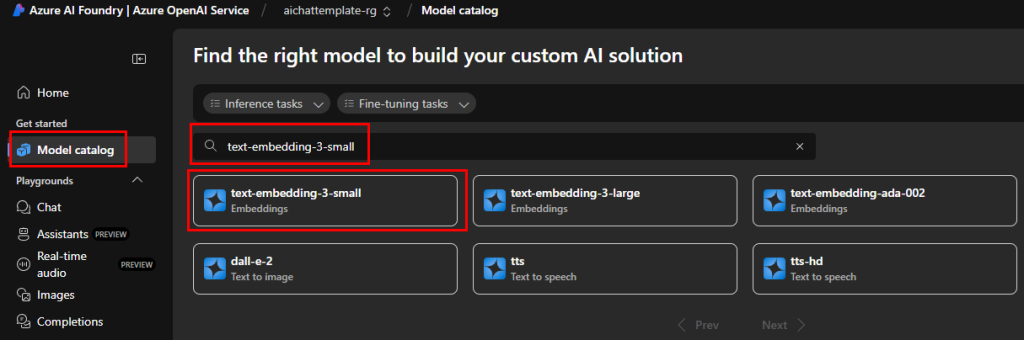
Cliquez sur Déployer :
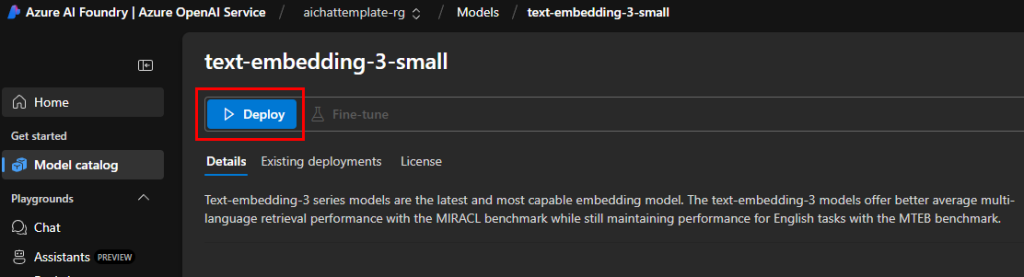
Conservez le nom d’origine, puis cliquez sur Déployer :
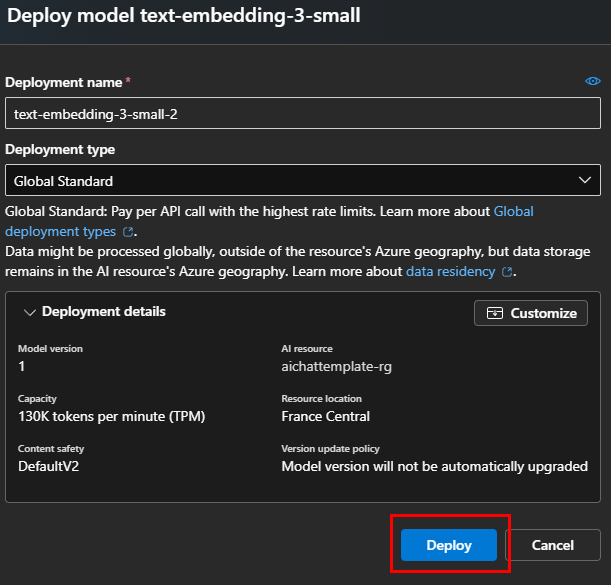
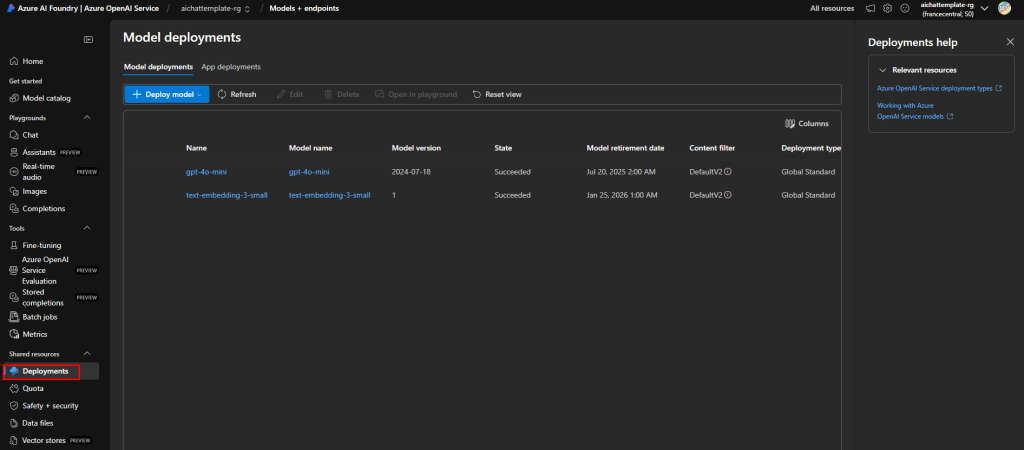
Vérifiez la présence des 2 modèles déployés dans le menu suivant :
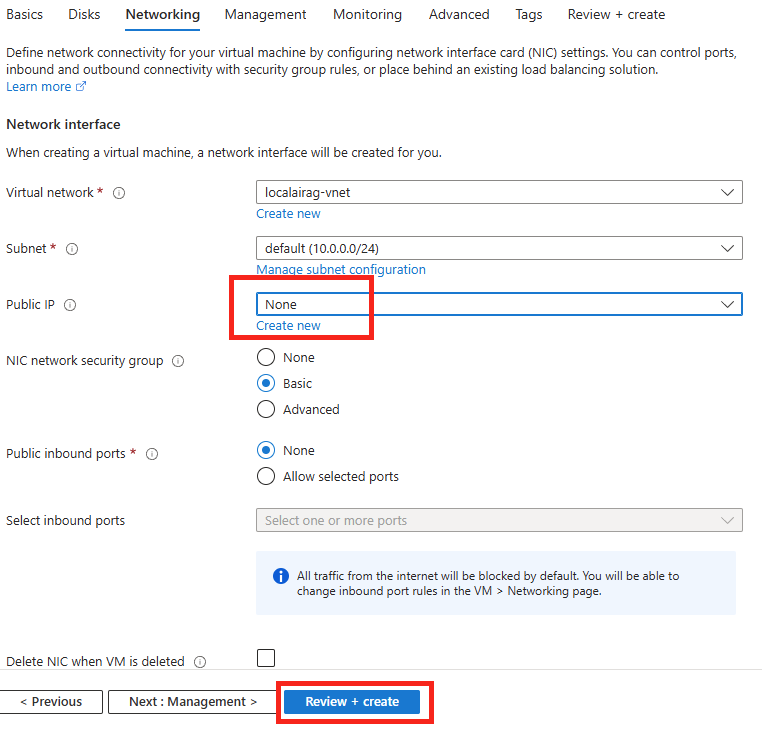
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le service AzureOpenAI :
dotnet new aichatweb -n AzureOpenAI --provider azureopenai --vector-store local
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier :
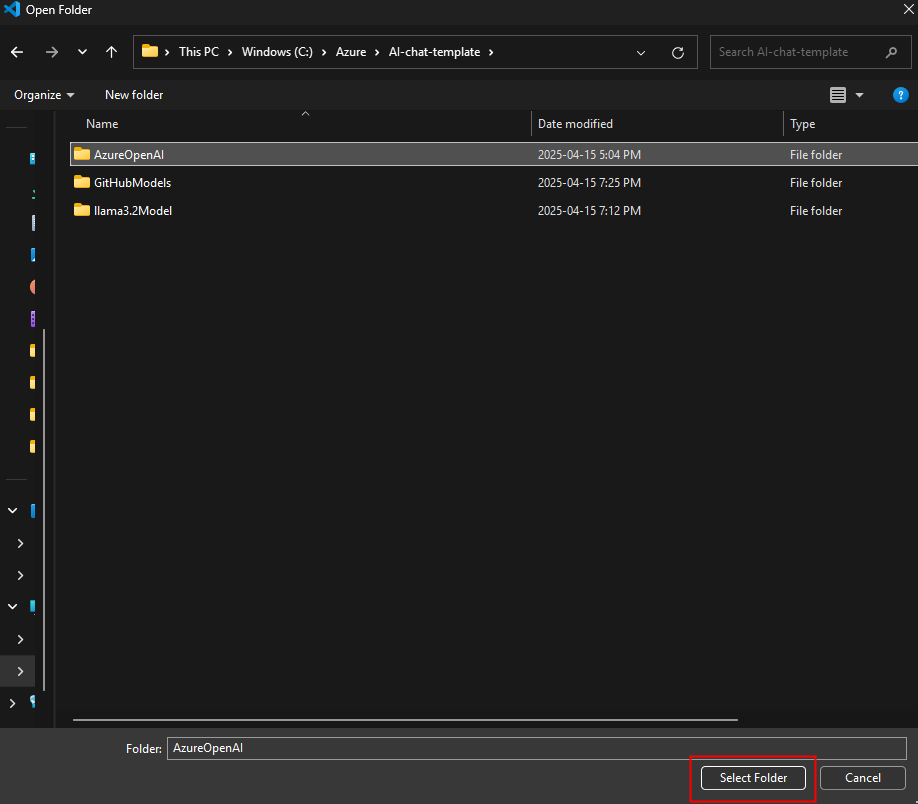
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
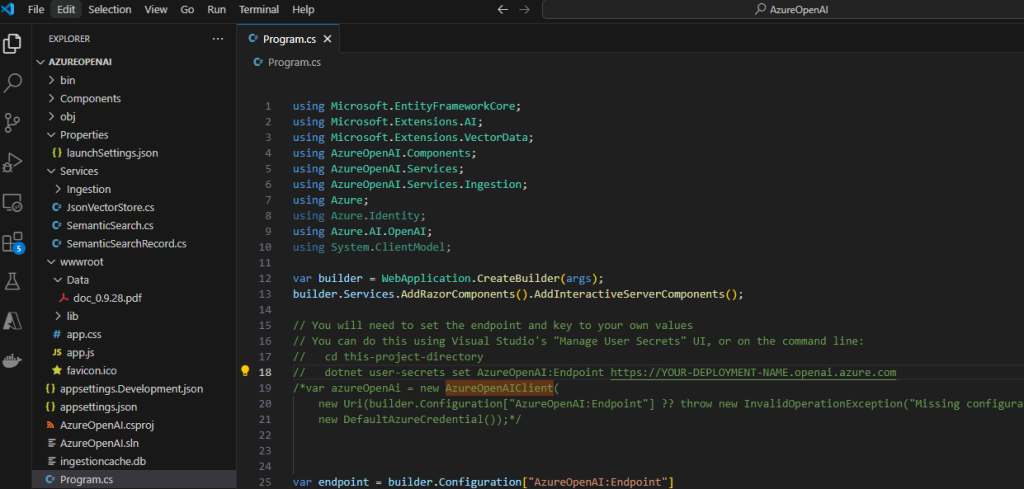
Afin de passer d’une authentification basée sur une identité Azure (DefaultAzureCredential) à une authentification explicite par clé API (AzureKeyCredential), remplacer le code suivant :
var azureOpenAi = new AzureOpenAIClient(
new Uri(builder.Configuration["AzureOpenAI:Endpoint"] ?? throw new InvalidOperationException("Missing configuration: AzureOpenAi:Endpoint. See the README for details.")),
new DefaultAzureCredential());Par celui-ci, puis sauvegardez le fichier Program.cs :
var endpoint = builder.Configuration["AzureOpenAI:Endpoint"]
?? throw new InvalidOperationException("Missing configuration: AzureOpenAI:Endpoint. See the README for details.");
var key = builder.Configuration["AzureOpenAI:Key"]
?? throw new InvalidOperationException("Missing configuration: AzureOpenAI:Key. See the README for details.");
var azureOpenAi = new AzureOpenAIClient(new Uri(endpoint), new AzureKeyCredential(key));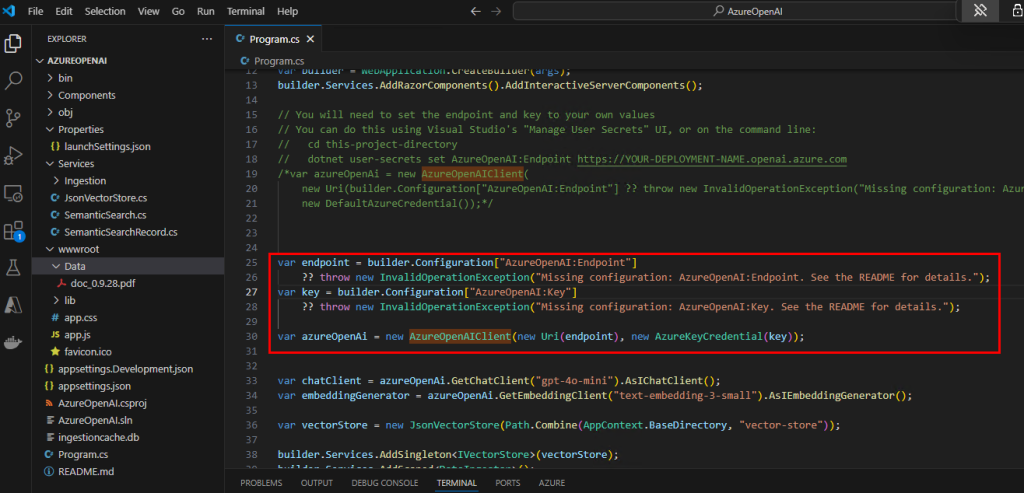
Ouvrez la fenêtre Terminal :
Enregistrez localement (et de manière sécurisée) le point de terminaison de l’instance Azure OpenAI :
dotnet user-secrets set AzureOpenAI:Endpoint https://aichattemplate-rg.openai.azure.coEnregistrez de manière sécurisée la clé API de l’instance Azure OpenAI dans les secrets utilisateur de .NET :
dotnet user-secrets set AzureOpenAI:Key 1zF4OGPseV...Affichez tous les secrets stockés localement pour le projet courant :
dotnet user-secrets list
Ajoutez ou retirer au besoin des fichiers PDF utilisées durant la phase d’indexation sémantique)
Compilez et exécutez l’application .NET dans le dossier courant :
dotnet run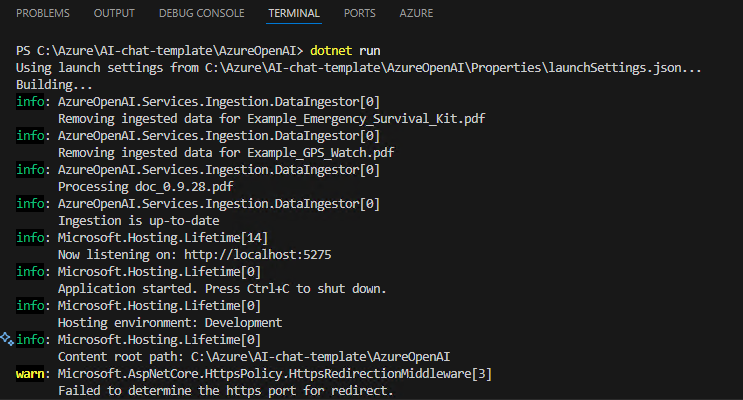
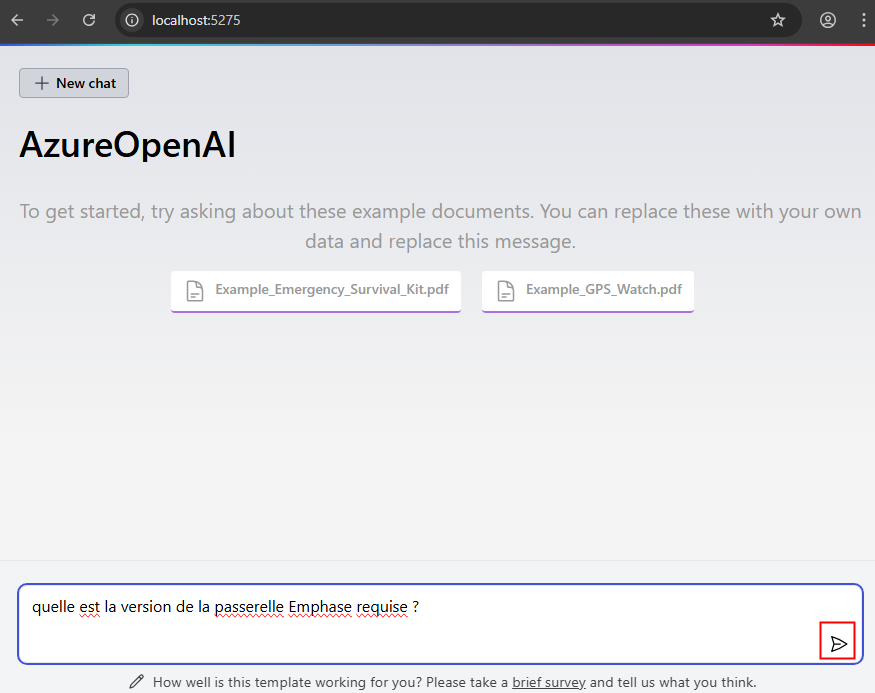
Ouvrez un navigateur web à cette adresse:port indiqué, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ajoutés :
Constatez la rapidité du résultat et la ou les sources associés, puis cliquez dessus :
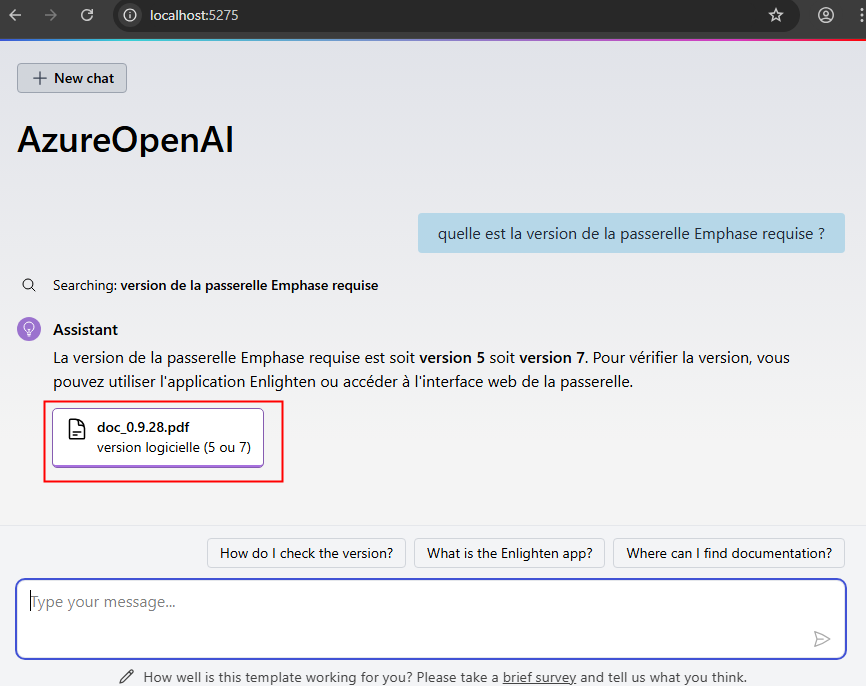
Constatez la sélection de texte en correspondance avec la question posée :
Le test avec le service Azure OpenAI a bien fonctionné, pensez à détruire le service une fois les tests terminés.
Terminons les tests de l’application de chat IA avec le modèle local Ollama.
Etape IV – Test de l’application avec le modèle Ollama :
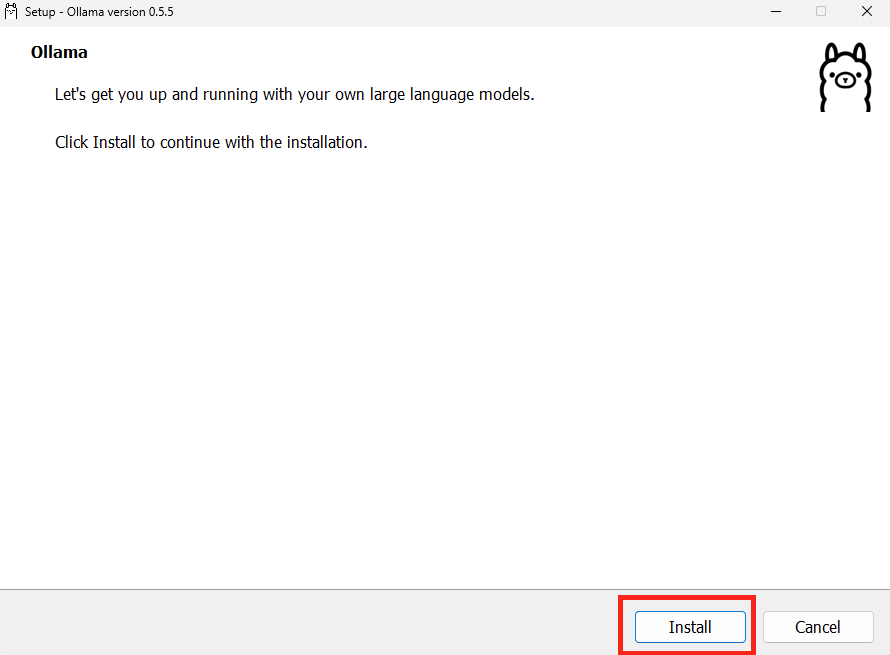
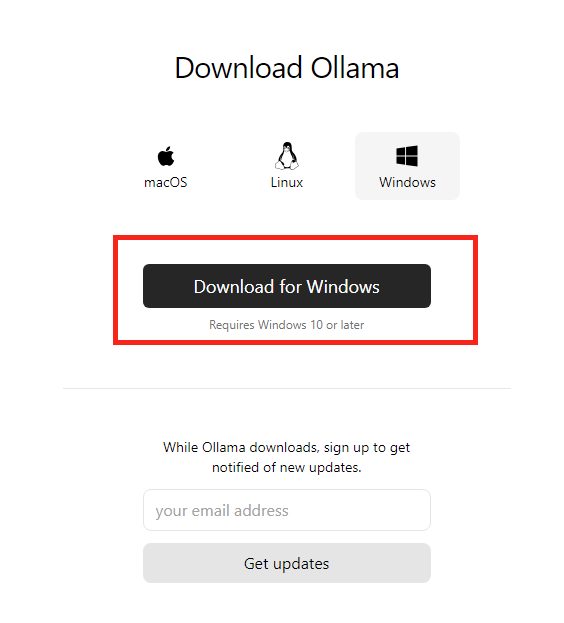
Rendez-vous sur la page suivante afin de télécharger Ollama :
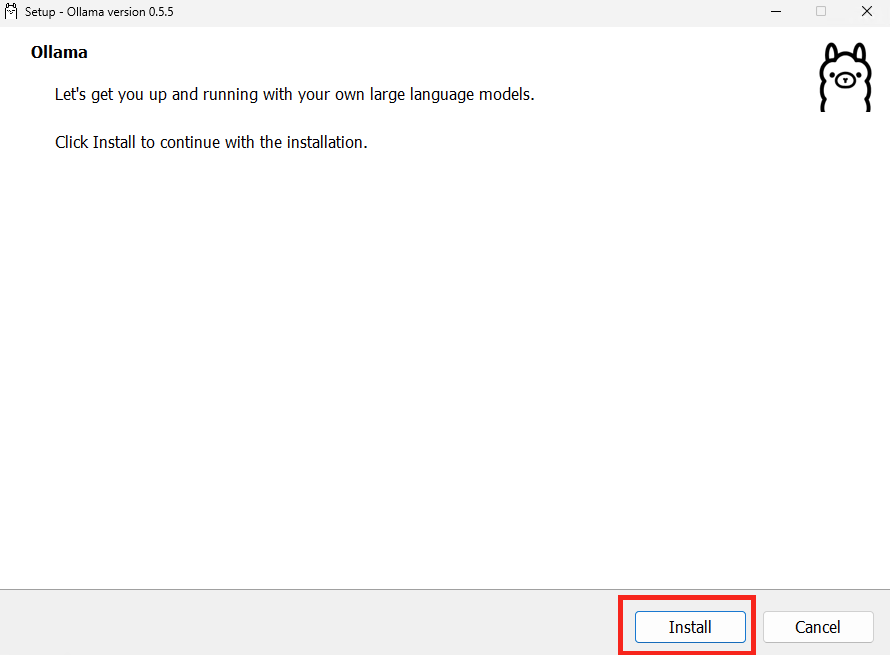
Une fois téléchargée, lancez l’installation :
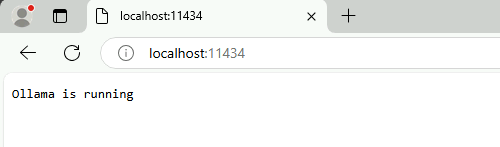
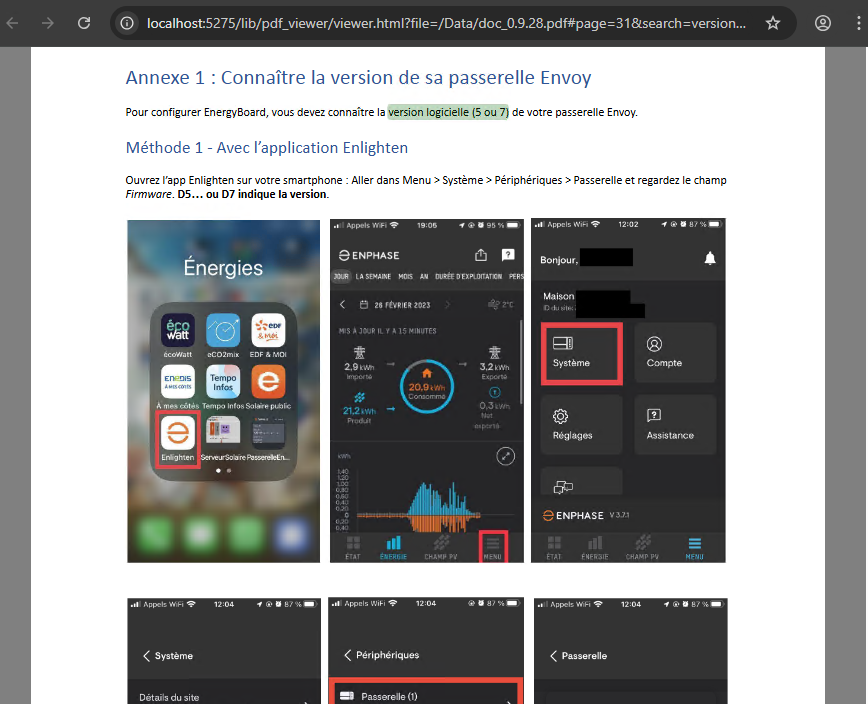
Une fois l’installation réussie, vérifiez via l’URL suivante le bon fonctionnement du service :
http://localhost:11434/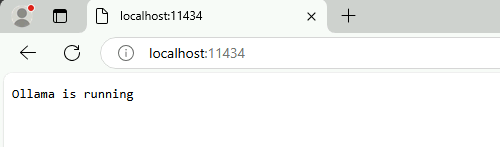
Depuis le menu Démarrer, ouvrez l’application CMD, puis lancez la commande suivante :
ollama pull llama3.2Ollama télécharge alors la version mini de Phi3 d’environ 2 Go

ollama pull all-minilmOllama télécharge alors un modèle ouvert d’environ 270 Mo :

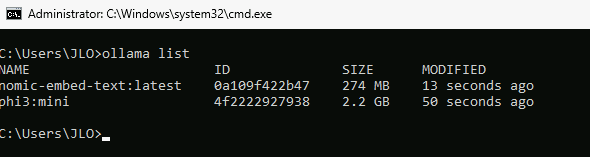
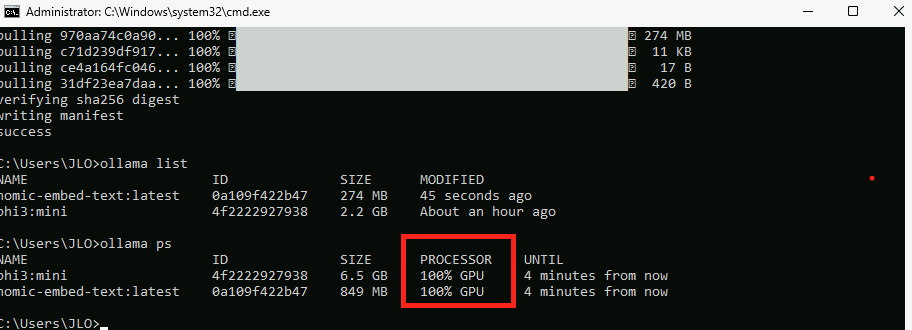
Vérifiez la liste des modèles en place avec la commande suivante :
ollama list
Retournez sur la fenêtre Windows PowerShell ouverte précédemment, puis lancez la commande suivante afin d’utiliser le template aichatweb pour créer une application web de chat IA en lien avec le modèle Ollama :
dotnet new aichatweb -n llama3.2Model --provider ollama --vector-store local
Ouvrez l’explorateur Windows afin de constater la création d’un nouveau dossier ainsi que le code de l’application :
Sur votre poste local, ouvrez Visual Studio Code, puis choisissez l’action d’ouverture d’un dossier :
Sélectionnez le dossier créé par l’application IA :
Constatez l’ouverture de l’application dans Visual Studio Code :
Ouvrez la fenêtre Terminal :
Ajoutez ou retirer au besoin des fichiers PDF utilisées durant la phase d’indexation sémantique)
Compilez et exécutez l’application .NET dans le dossier courant :
dotnet run
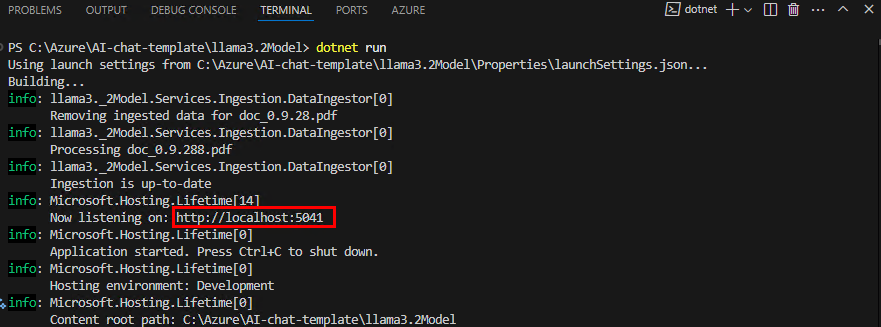
L’application vérifie dans les sources de données configurées si nouveau documents sont à indexer ou vectoriser :

Cette ligne vous indique que l’application tourne localement sur le port 5145 :
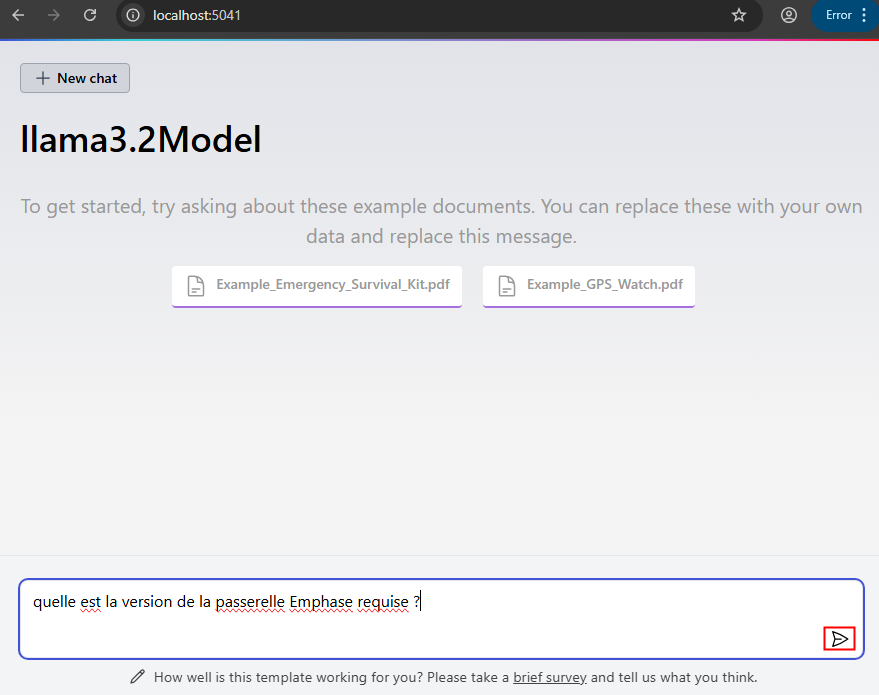
Ouvrez un navigateur web à cette adresse:port, puis posez une question à l’IA sur un sujet d’ordre général ou propre aux documents ajoutés :
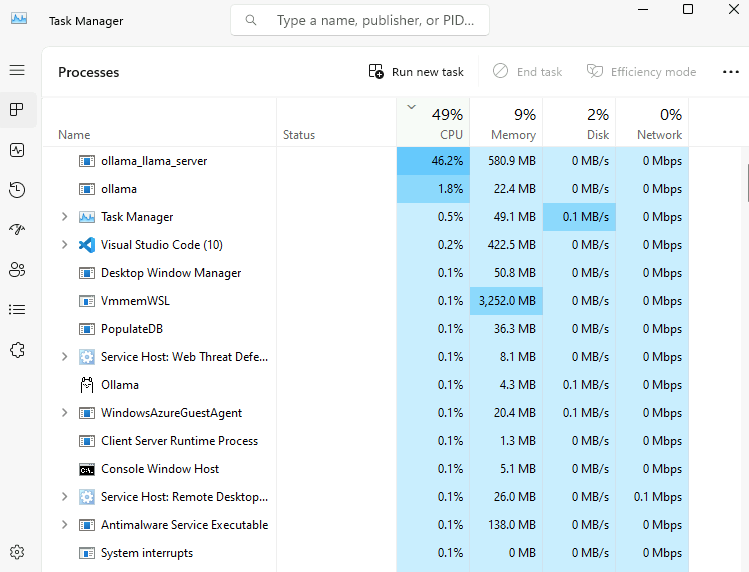
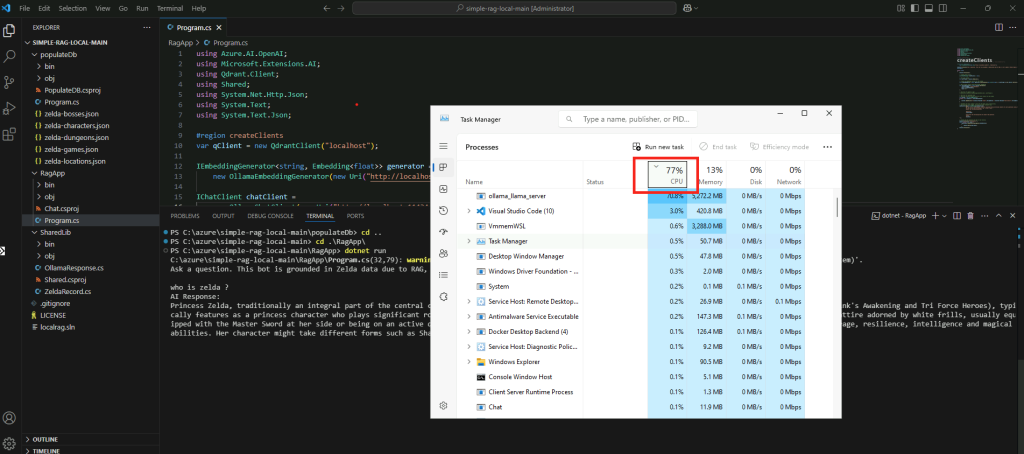
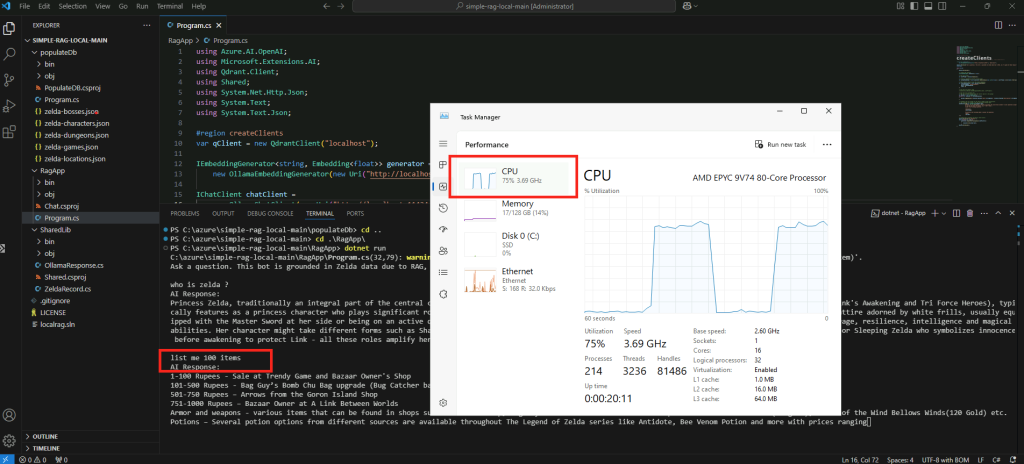
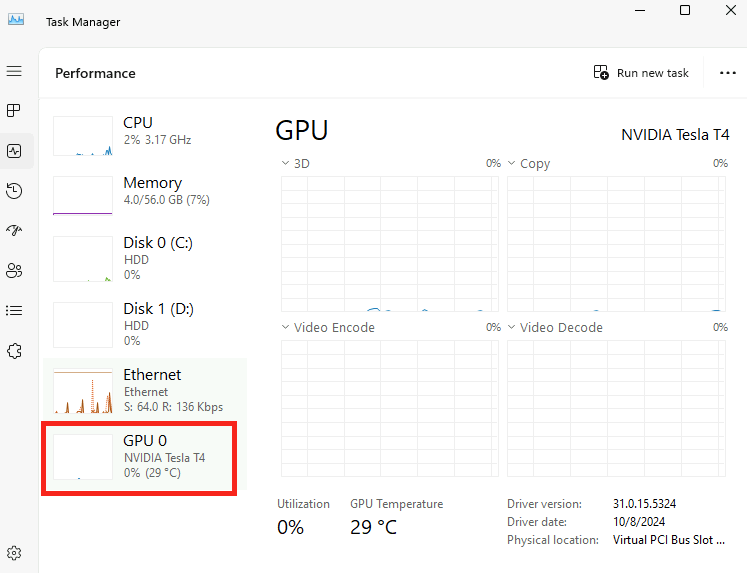
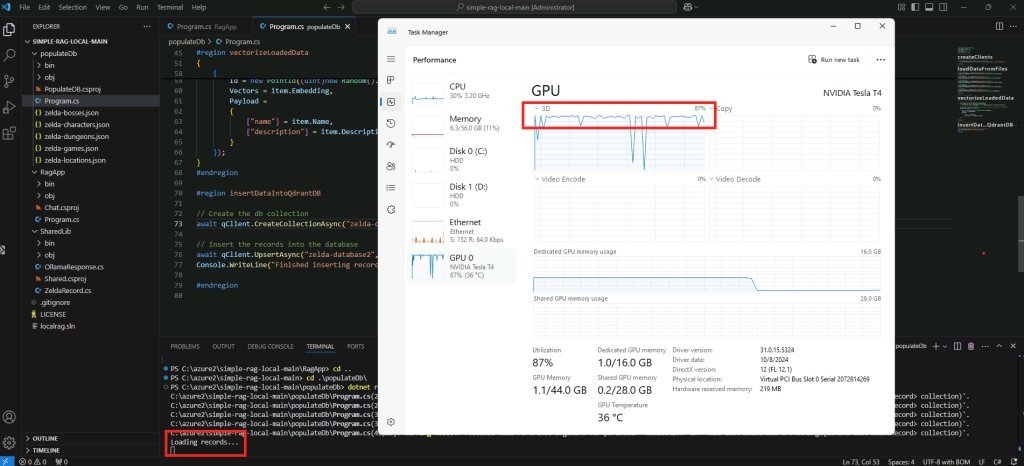
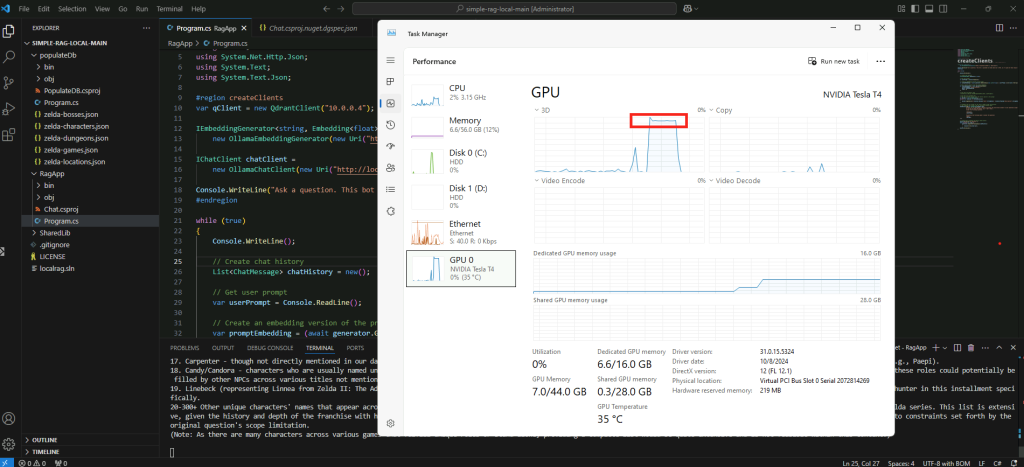
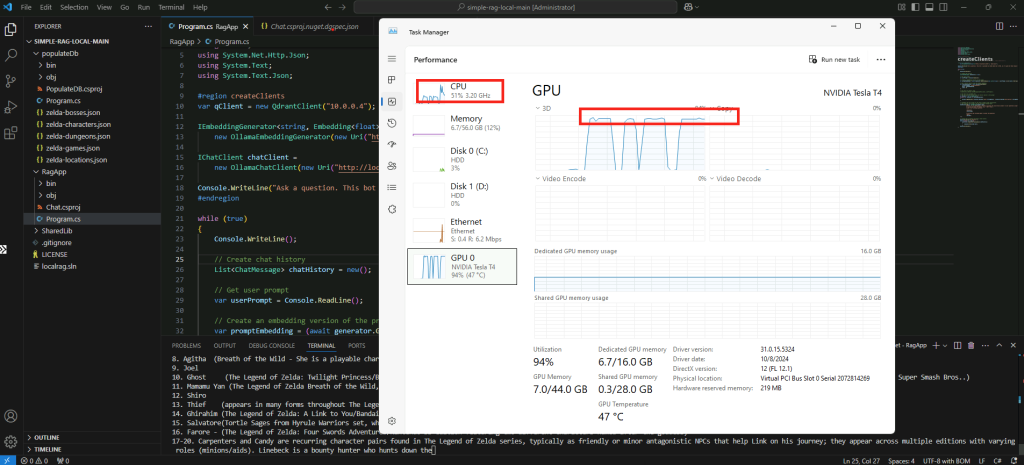
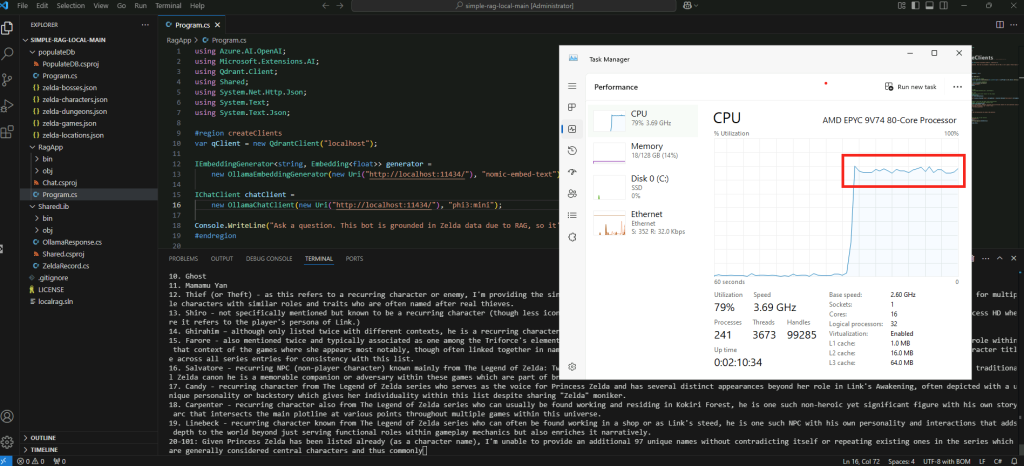
Constatez le pic d’usage du CPU/GPU selon la configuration matérielle de votre poste local :
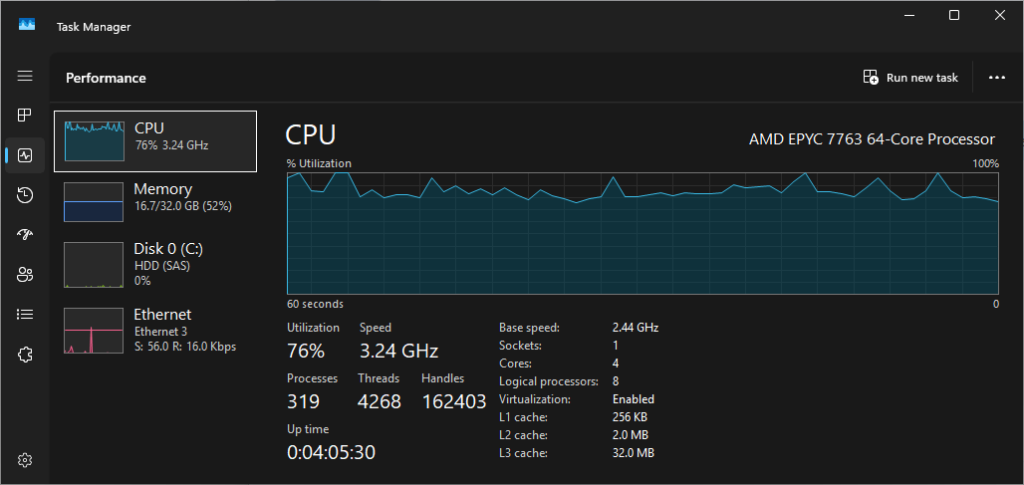
Constatez la rapidité/lenteur du résultat :
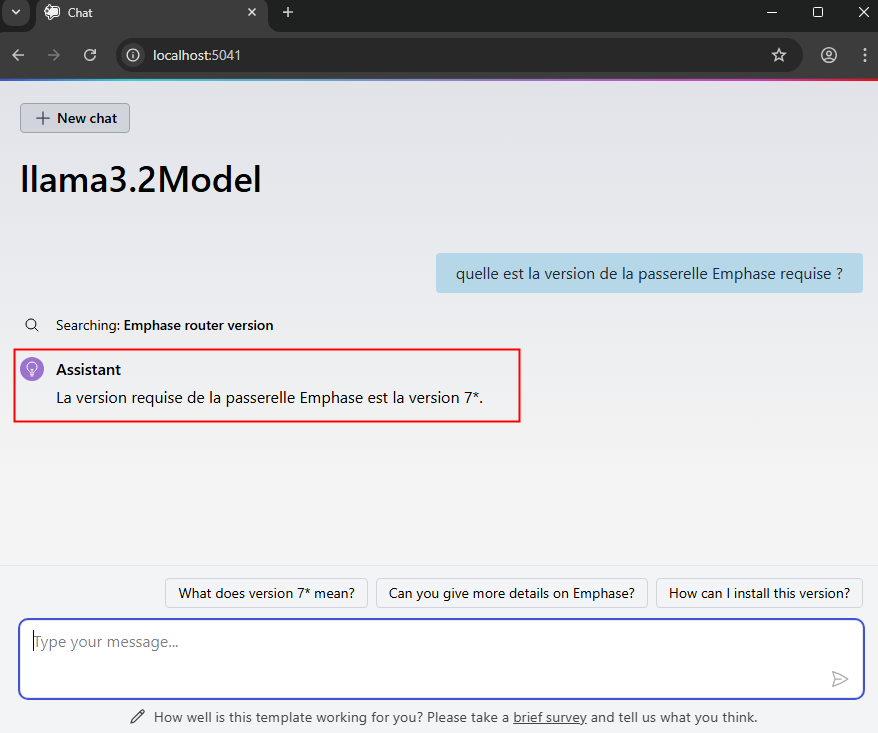
Conclusion
Avec l’arrivée des nouveaux templates .NET dédiés à l’intelligence artificielle, il n’a jamais été aussi simple de créer des applications web de chat connectées à des modèles IA.
Que vous choisissiez un modèle cloud (comme Azure OpenAI), un modèle public (via GitHub), ou même un modèle local (comme ceux proposés par Ollama), l’infrastructure est prête à l’emploi et parfaitement intégrée à l’écosystème .NET.