
Alex Wolf, de la chaîne YouTube The Code Wolf, continue de peaufiner son application DBChatPro version après version et dévoile la v6 ! Cette nouvelle version intègre maintenant un serveur MCP, exposant les fonctionnalités clés de DBChatPro à d’autres outils d’IA (GitHub Copilot, etc.) ou même à vos propres applications. Dans cet article, nous explorons les fondamentaux du MCP, puis nous détaillons l’installation du serveur MCP de DBChatPro.

Avant toute manipulation technique, et pour bien saisir l’intérêt d’une architecture MCP, je vous recommande la lecture de l’excellent billet disponible sur Digidop, écrit par Thibaut Legrand. Voici un extrait de ce billet qui illustre parfaitement l’avantage d’une architecture MCP :
Qu’est-ce que le Model Context Protocol (MCP) ?
Le Model Context Protocol (MCP) est un standard ouvert conçu par Anthropic (l’entreprise à l’origine de Claude) qui offre aux modèles d’IA un accès sécurisé à diverses sources de données et outils externes.
Il fonctionne comme un « USB-C universel » pour l’IA, facilitant la communication avec n’importe quel service ou base de données.
Pourquoi le MCP a été créé ?
Avant le MCP, relier un LLM à des sources externes était laborieux et non standardisé. Les grands modèles de langage (GPT, Claude, Gemini…) présentent deux limites majeures :
- Limite de contexte : Ils ne peuvent raisonner que sur les informations présentes dans leur contexte immédiat
- Impossibilité d’action : Ils peuvent générer du texte mais ne peuvent pas agir sur le monde extérieur
La métaphore du « problème M×N » illustre parfaitement cette situation : pour connecter un nombre M modèles d’IA à un nombre N outils externes, il fallait créer M×N intégrations différentes. Le MCP transforme cette équation en M+N, réduisant drastiquement la complexité d’intégration.
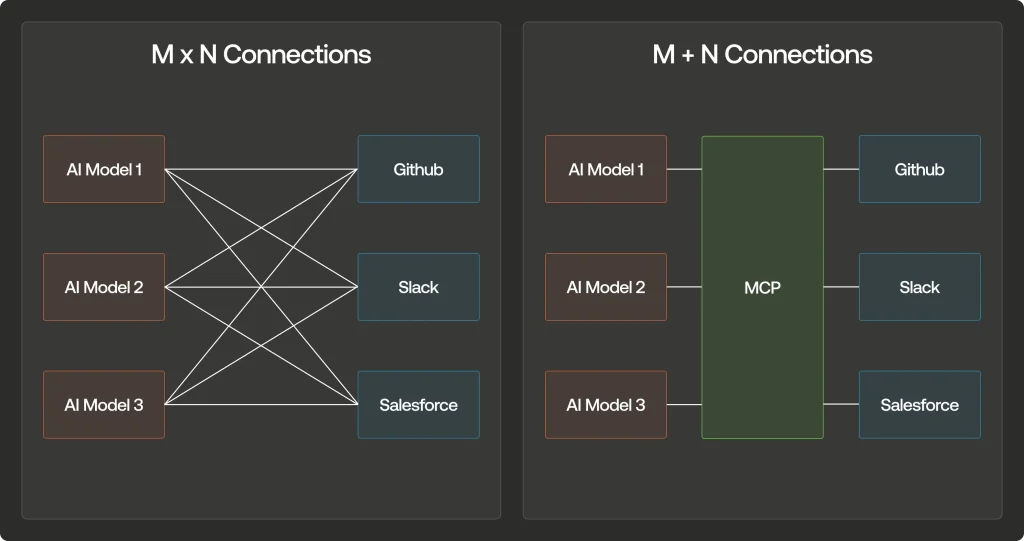
Prenons un exemple concret :
une entreprise utilisant 4 modèles d’IA différents (Claude, GPT-4, Gemini, Deepseek) qui souhaite les connecter à 5 services externes (GitHub, Slack, Google Drive, Salesforce, base de données interne).
Sans MCP, cela nécessiterait 4×5=20 intégrations personnalisées. Avec MCP, on passe à seulement 4+5=9 composants (4 clients MCP et 5 serveurs MCP), soit une réduction de 55% de la complexité et du temps de développement.
MCP vs API traditionnelles : quelles différences ?
Pour comprendre l’importance du MCP, comparons-le aux API REST traditionnelles :
| Caractéristique | MCP | API REST traditionnelles |
|---|---|---|
| Communication | Bidirectionnelle et en temps réel | Généralement requête-réponse unidirectionnelle |
| Découverte d’outils | Automatique et dynamique | Configuration manuelle nécessaire |
| Conscience du contexte | Intégrée | Limitée ou inexistante |
| Extensibilité | Plug-and-play | Effort d’intégration linéaire |
| Standardisation | Protocole unifié pour tous les modèles | Variable selon les services |
| Orientation | Conçu spécifiquement pour les modèles d’IA | Usage général |
Cette standardisation représente un changement de paradigme pour quiconque souhaite développer des applications IA véritablement connectées.
Architecture et fonctionnement du MCP
L’architecture du MCP repose sur trois composants principaux qui interagissent de façon coordonnée :
Les composants clés du MCP
- Hôtes MCP : Ce sont les applications qui intègrent l’IA et ont besoin d’accéder à des données externes. Par exemple, Claude Desktop, un IDE comme Cursor, ou toute application intégrant un LLM.
- Clients MCP : Ce sont des intermédiaires qui maintiennent les connexions sécurisées entre l’hôte et les serveurs. Chaque client est dédié à un serveur spécifique pour garantir l’isolation.
- Serveurs MCP : Ce sont des programmes externes qui fournissent des fonctionnalités spécifiques et se connectent à diverses sources comme Google Drive, Slack, GitHub, ou des bases de données.
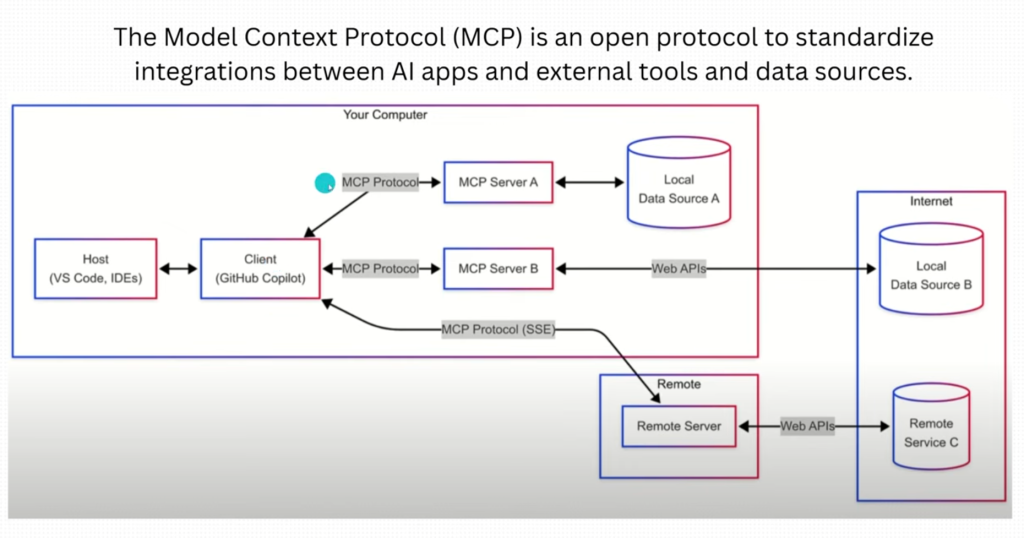
Le flux de communication MCP se déroule typiquement en quatre étapes bien définies :
- Découverte : L’hôte (comme Claude Desktop) identifie les serveurs MCP disponibles dans son environnement
- Inventaire des capacités : Les serveurs MCP déclarent leurs fonctionnalités disponibles (outils, ressources, prompts)
- Sélection et utilisation : Quand l’utilisateur pose une question nécessitant des données externes, l’IA demande l’autorisation d’utiliser un outil spécifique
- Exécution et retour : Le serveur MCP exécute l’action demandée (recherche web, accès à un fichier, etc.) et renvoie les résultats à l’IA qui peut alors formuler une réponse complète
Ce processus standardisé permet une communication fluide entre l’IA et les sources de données externes, tout en maintenant un contrôle transparent pour l’utilisateur.
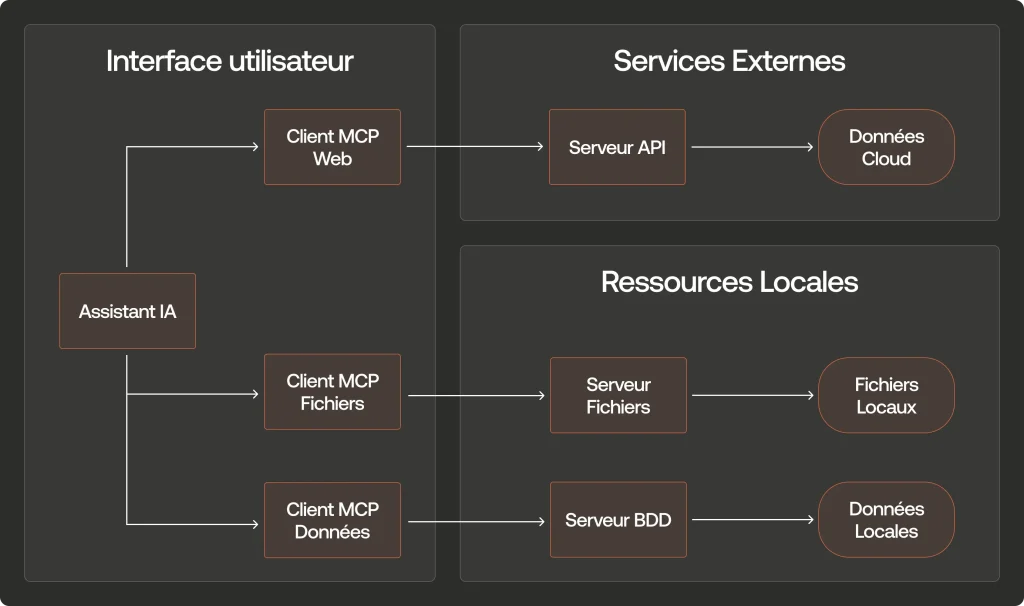
Serveurs MCP existants
Plutôt que de développer vos propres serveurs MCP depuis zéro, vous pouvez exploiter l’écosystème grandissant de serveurs préexistants. Ces solutions prêtes à l’emploi vous permettent d’intégrer rapidement des fonctionnalités avancées dans vos projets IA :
Serveurs officiels et communautaires
- GitHub : Ce serveur MCP vous permet d’interagir avec des dépôts de code directement depuis votre application IA. Vous pouvez rechercher des fichiers, créer des issues, analyser des pull requests, ou même générer des commits et du code. Idéal pour les assistants de développement qui nécessitent une compréhension du contexte du code.
- Google Drive : Offre un accès complet aux documents stockés sur Google Drive. Votre modèle d’IA peut ainsi lire, créer, modifier ou organiser des documents, présentations et feuilles de calcul, en conservant le contexte des informations partagées.
- Slack : Permet à vos modèles d’IA d’interagir avec les canaux et conversations Slack. Ils peuvent envoyer des messages, surveiller des chaînes spécifiques, ou même répondre automatiquement à certains types de requêtes, créant ainsi une intégration transparente dans les flux de communication d’équipe.
- Puppeteer : Un puissant serveur MCP qui apporte la capacité de naviguer sur le web. Vos modèles d’IA peuvent visiter des sites, remplir des formulaires, capturer des captures d’écran et extraire des données, ouvrant la voie à l’automatisation avancée des tâches web.
- Brave Search : Donne à vos modèles d’IA la capacité d’effectuer des recherches web en temps réel via le moteur Brave. Cela permet de répondre à des questions sur l’actualité récente ou d’accéder à des informations au-delà de la date limite de formation du modèle.
- PostgreSQL : Connecte vos modèles d’IA directement à vos bases de données PostgreSQL. Les modèles peuvent effectuer des requêtes SQL, analyser des données et même assister à la conception de schémas de base de données.
- SQLite : Variante plus légère pour les bases de données locales, particulièrement utile pour les applications de bureau ou les projets avec des exigences de stockage plus modestes.
- Qdrant : Serveur spécialisé pour les bases de données vectorielles, essentiel pour les applications IA nécessitant une recherche sémantique ou par similarité.
Afin de voir comment cela marche, voici les différentes étapes que nous allons suivre sur un environnement de test :
- Etape 0 – Rappel des prérequis
- Etape I – Création des ressources Azure
- Etape II – Déploiement et test de l’application DBChatPro
- Etape III – Déploiement du serveur MCP
Maintenant, il nous reste plus qu’à tester tout cela 😎
Etape 0 – Rappel des prérequis :
Pour réaliser cet exercice, il vous faudra disposer de :
- Un tenant Microsoft
- Une souscription Azure valide
Commençons par créer quelques ressources (IA et DB) sur Azure et Entra.
Etape I – Création des ressources Azure :
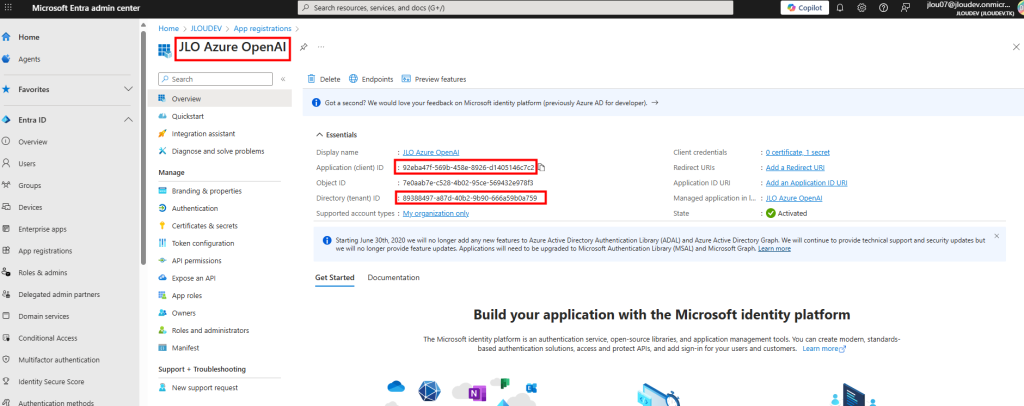
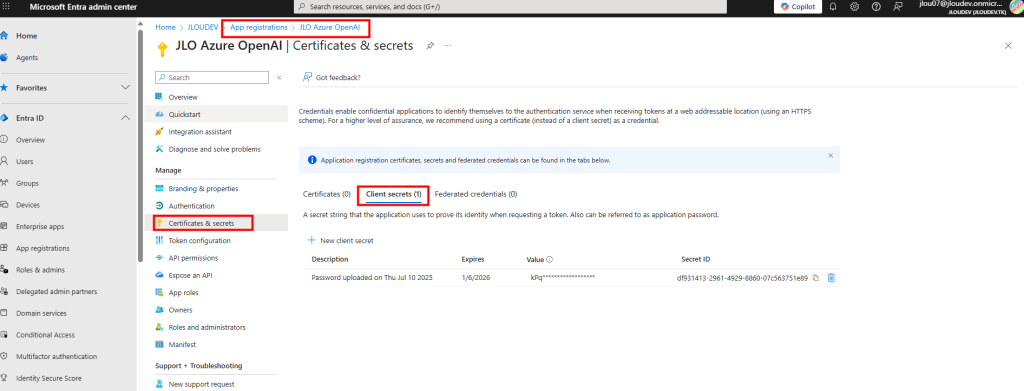
Connectez-vous au portail Entra Admin Center pour enregistrer une nouvelle application, puis récupérez ensuite l’Application ID et le Tenant ID :
Créez un secret client puis copiez immédiatement sa valeur car elle ne sera plus visible par la suite :
Ouvrez une session Windows PowerShell, puis définissez trois variables d’environnement pour l’App ID, le Directory ID et le Client Secret :
setx AZURE_CLIENT_ID "xxx"
setx AZURE_TENANT_ID "yyy"
setx AZURE_CLIENT_SECRET "zzz"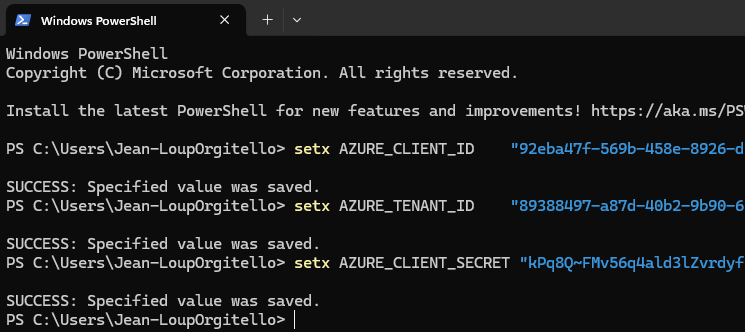
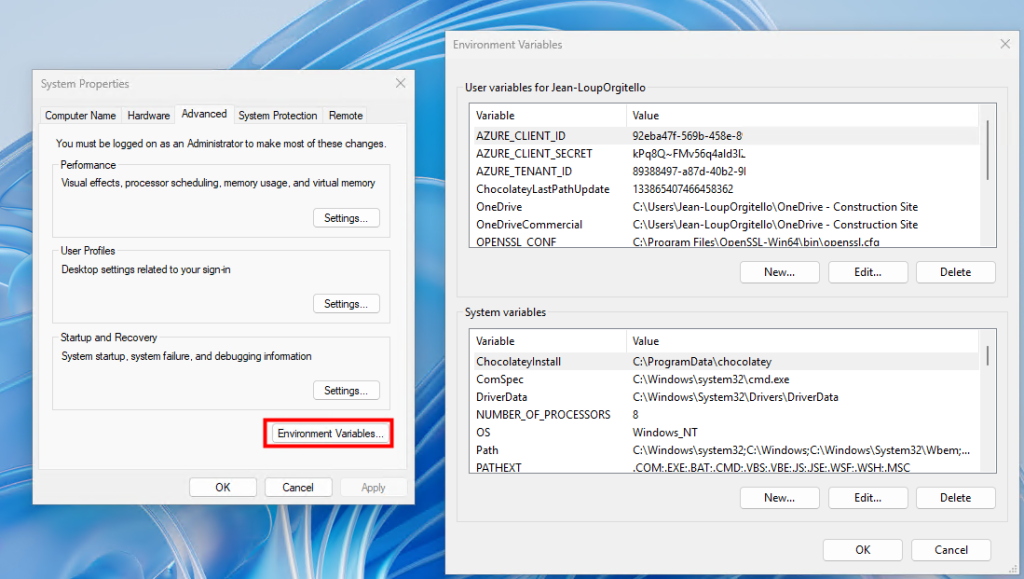
Vérifiez ces variables dans les Propriétés système de Windows, section « Variables d’environnement », afin de confirmer leur bonne configuration :
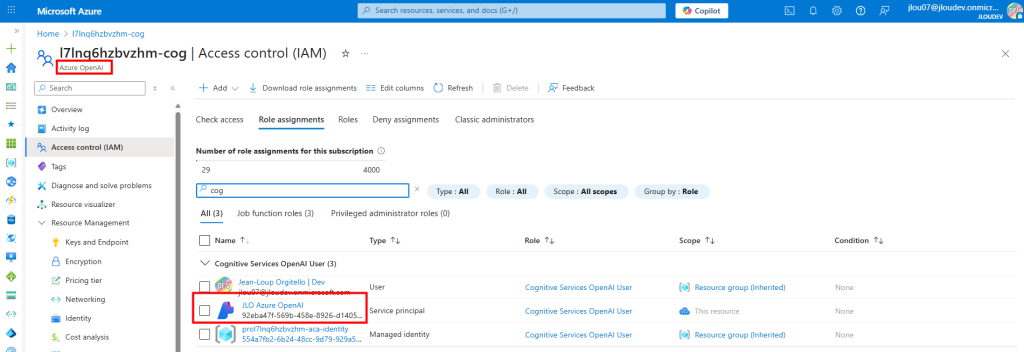
Créez un service Azure OpenAI depuis le portail Azure, puis ajoutez votre application en tant que « Cognitive Services OpenAI User » dans « Contrôle d’accès (IAM) » :
Revenez à la page principale de votre service Azure OpenAI, puis cliquez sur Ouvrir dans la Fonderie pour accéder à l’interface de déploiement :
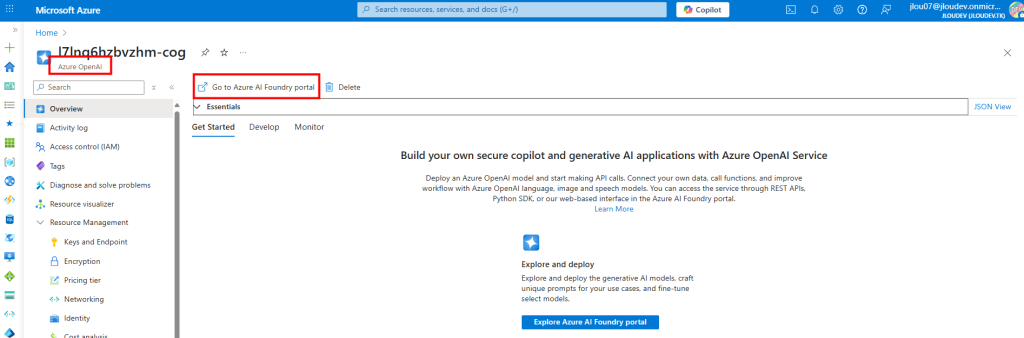
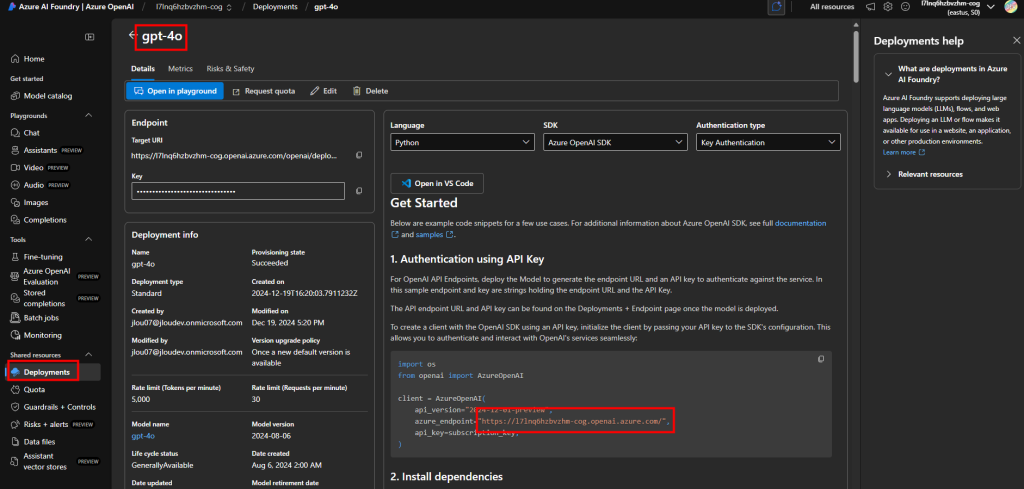
Dans la Fonderie, ouvrez l’onglet Déploiements et cliquez sur Nouveau déploiement, puis nommez-le (par ex : gpt-4o) et copiez l’URL de l’endpoint :
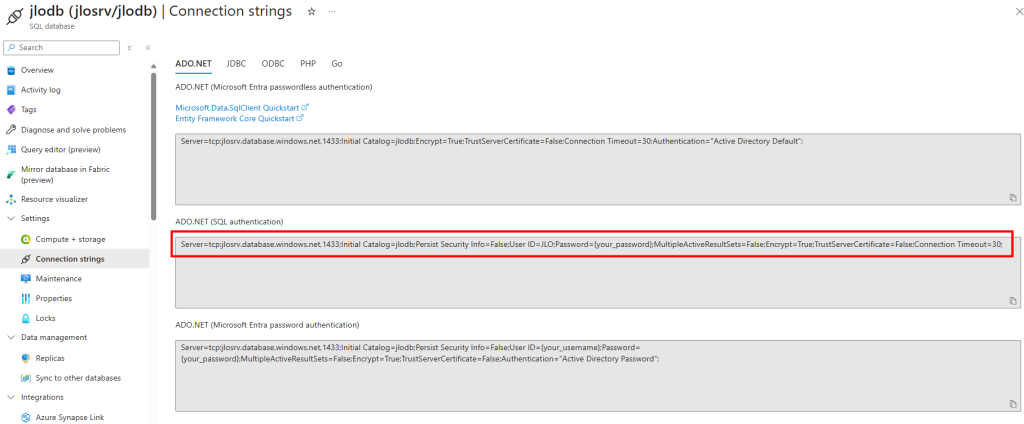
Créez une base de données Azure SQL Database avec des données en exemple, puis copiez la chaîne de connexion complète pour la réutiliser plus tard :
Notre environnement Azure est prêt. Nous allons maintenant pouvoir déployer l’application DBChatPro sur notre poste en local.
Etape II – Déploiement et test de l’application DBChatPro :
Accédez au dépôt GitHub de l’application via le lien, puis téléchargez l’archive ZIP sur votre poste :
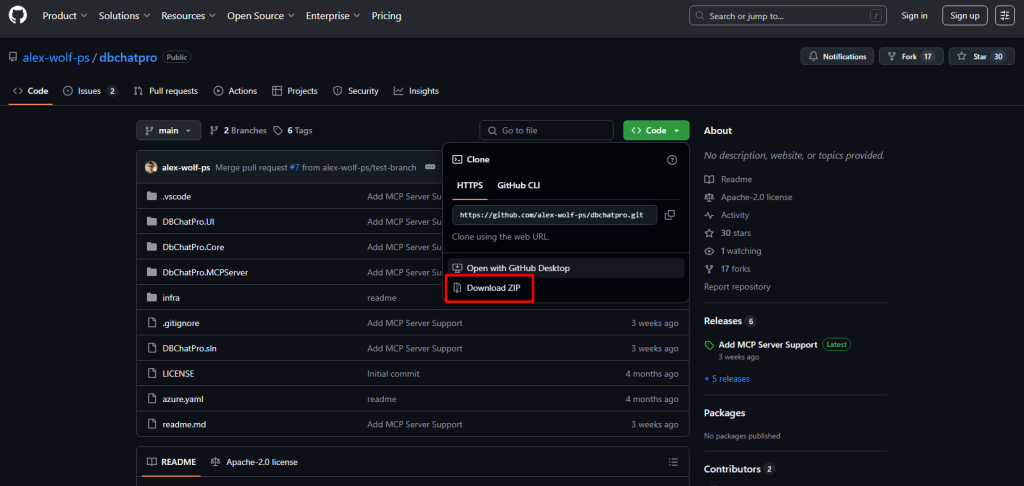
Extrayez l’archive ZIP, puis placez-vous dans le dossier extrait pour préparer l’ouverture du projet :
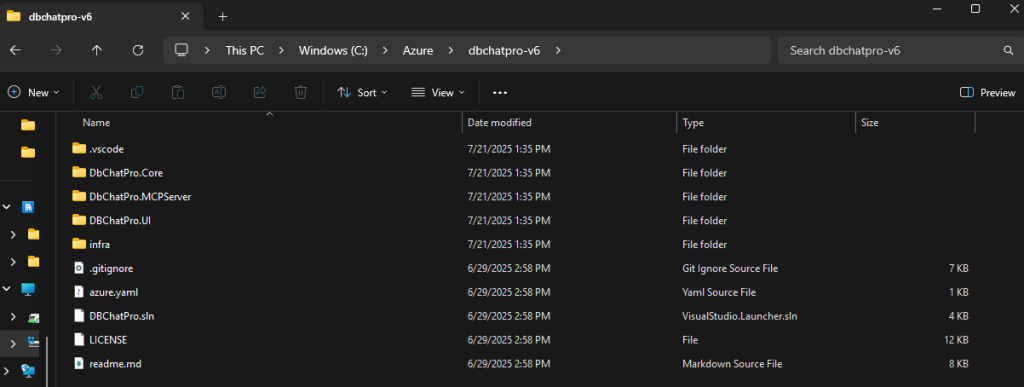
Lancez Visual Studio Code, puis cliquez ici pour sélectionner le dossier du projet :
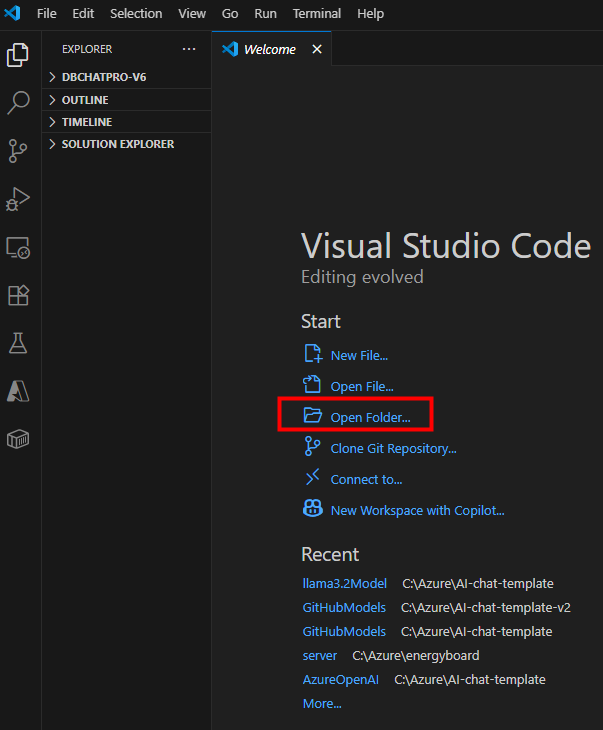
Sélectionnez le dossier extrait contenant le projet, puis validez pour l’ouvrir dans VS Code :
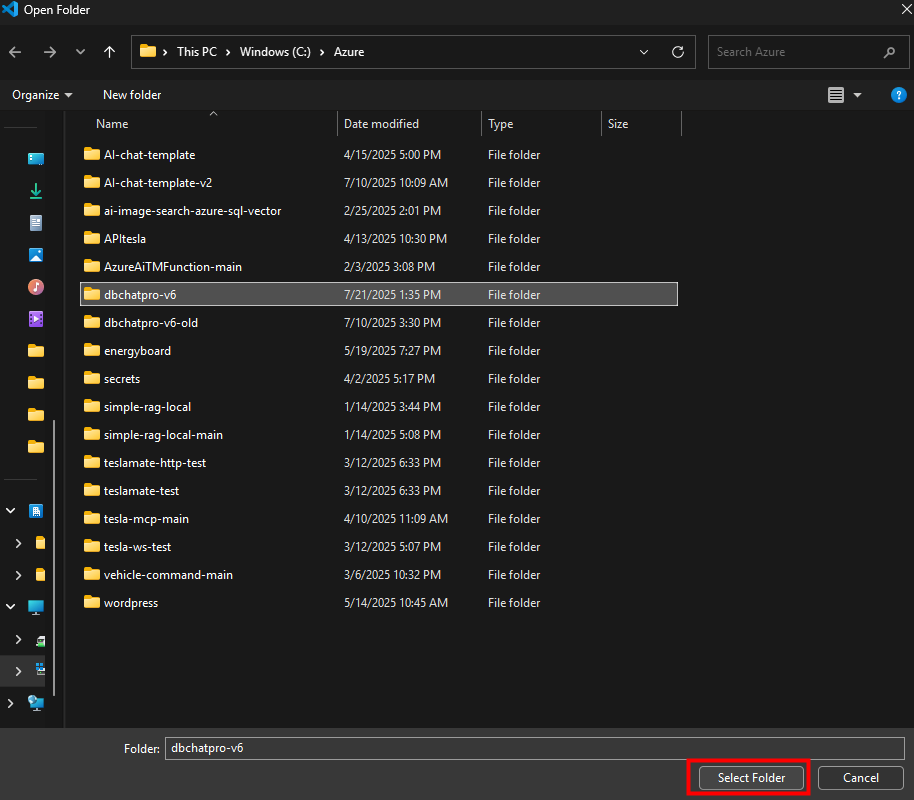
Observez la nouvelle architecture de DBChatPro avec la partie MCP distincte de l’interface graphique, puis passez à la configuration UI :
Commencez par l’interface graphique en renseignant les endpoints de votre choix dans le fichier de configuration, puis sauvegardez vos modifications :
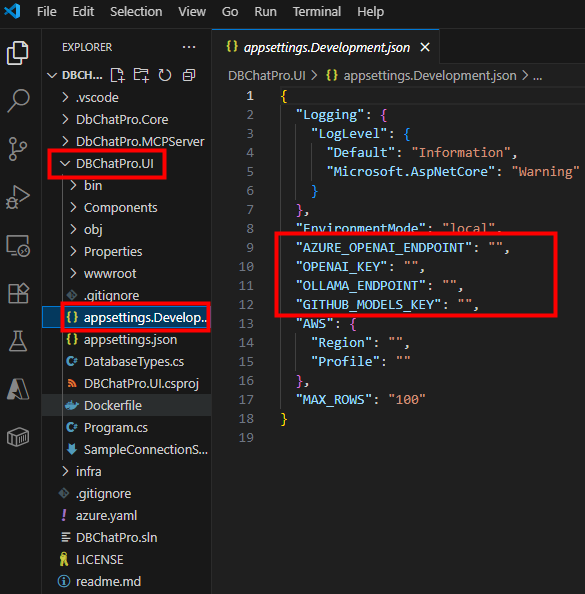
Dans mon cas, j’ai utilisé le modèle Azure OpenAI :
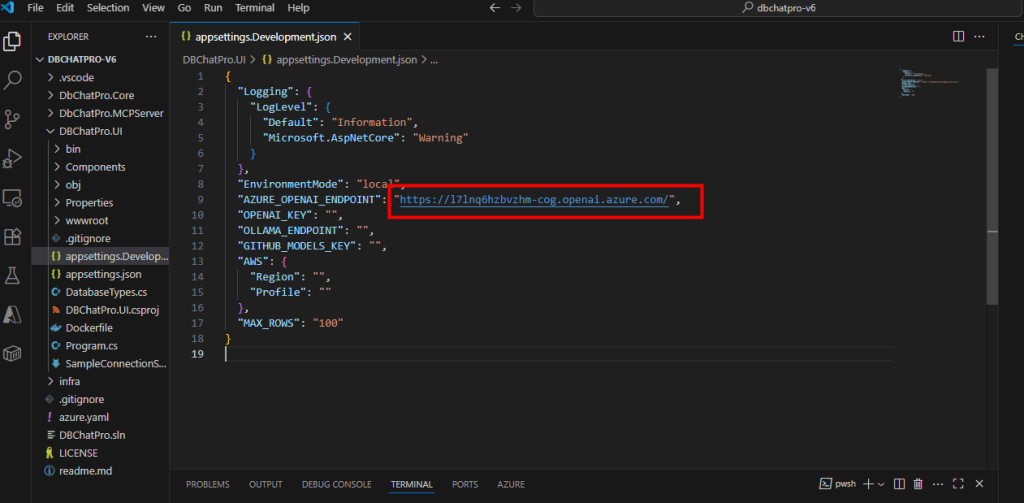
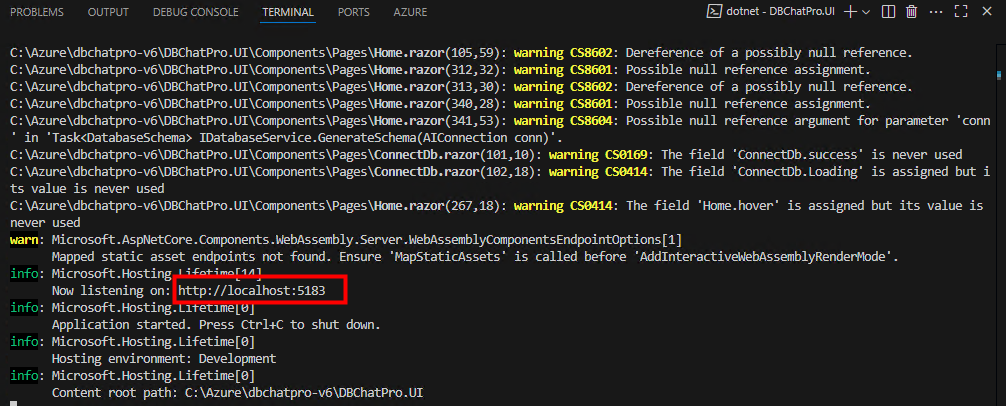
Ouvrez la console intégrée Terminal de VS Code, positionnez-vous dans le dossier racine de l’application, lancez l’application, puis patientez quelques secondes pour que le serveur local démarre :

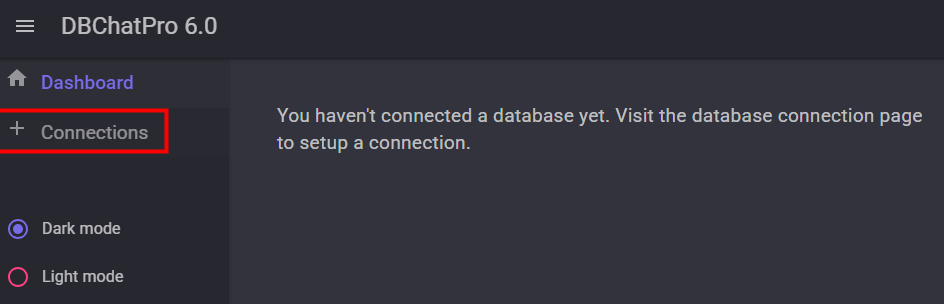
Copiez l’URL locale générée par l’application, puis ouvrez-la dans votre navigateur préféré :
Dans le navigateur, constatez que la base de données n’est pas encore configurée, puis cliquez sur Connexion :
Collez votre chaîne de connexion SQL en modifiant le mot de passe, puis cliquez sur Check Connection pour tester la liaison :
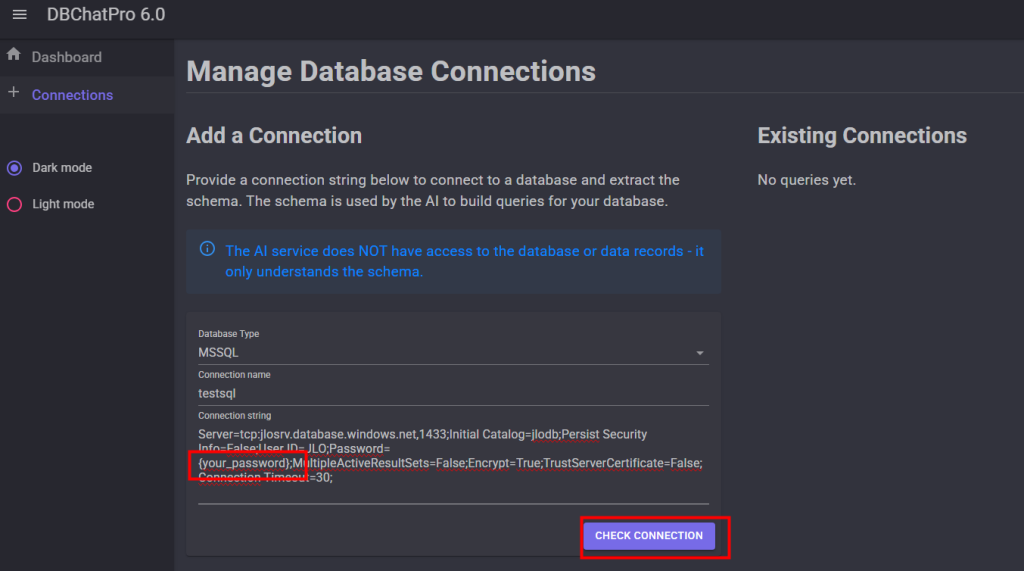
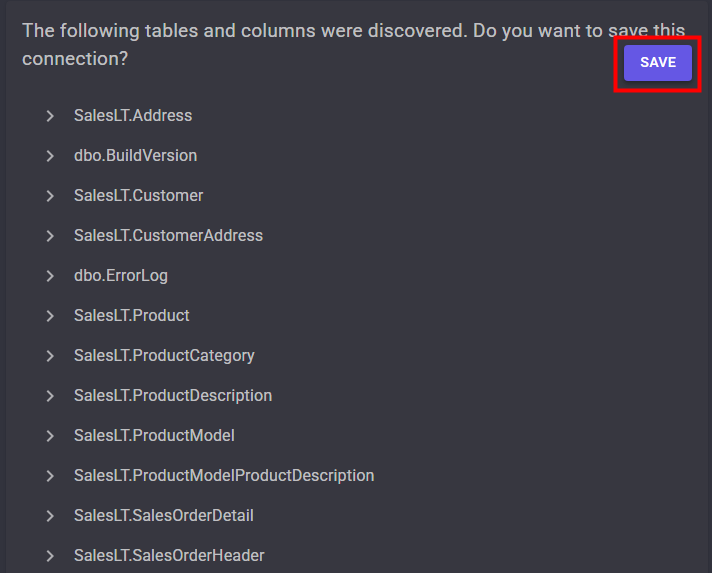
Vérifiez la découverte automatique du schéma de la base de données, puis cliquez ici pour sauvegarder pour valider l’import :
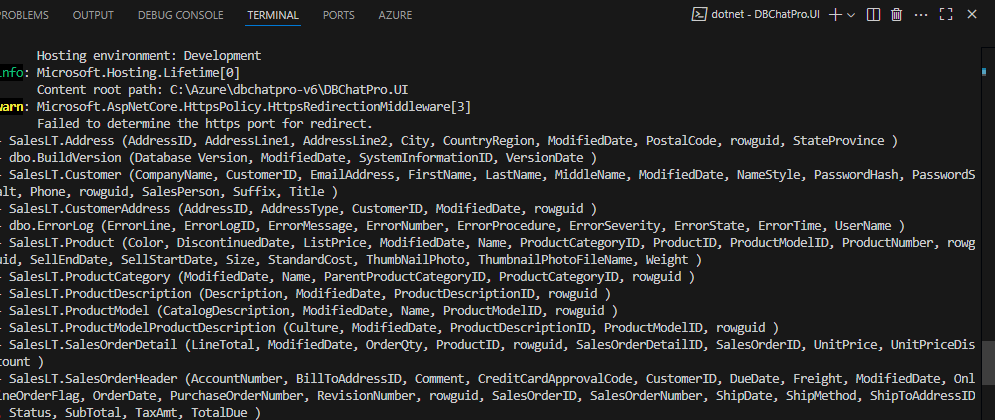
Dans le terminal, observez également l’import du plan et du schéma de votre base SQL :
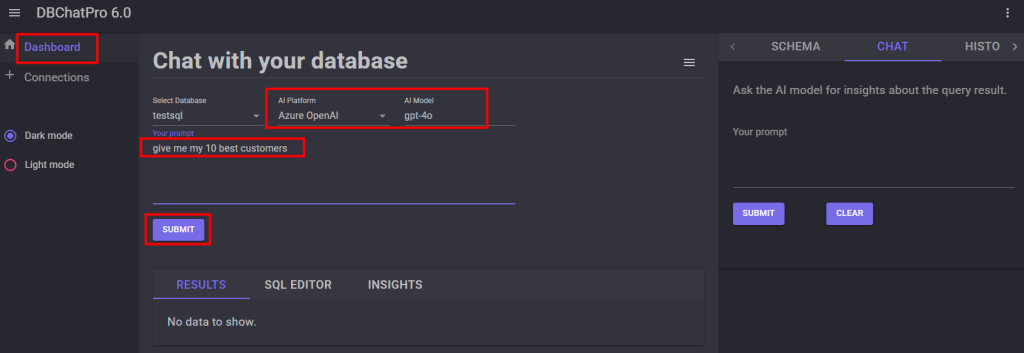
Sur la page principale de l’application, sélectionnez le modèle et la plateforme d’IA, puis saisissez votre prompt :
Patientez quelques secondes pour afficher le résultat généré par le modèle :
Consultez l’onglet Insight pour obtenir des informations complémentaires sur la réponse, puis analysez les données fournies :

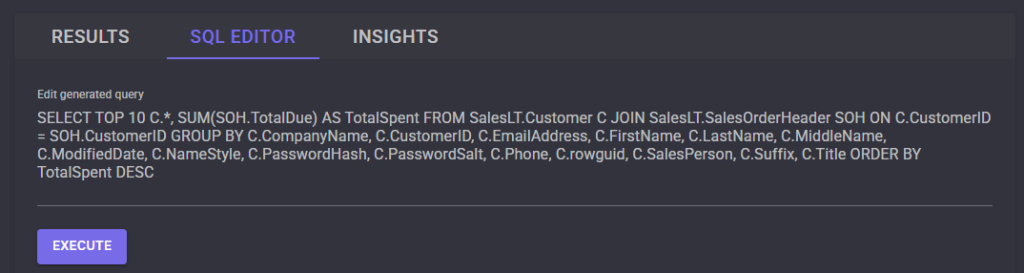
Sur l’onglet SQL Editor, constatez la transformation de votre requête en SQL :
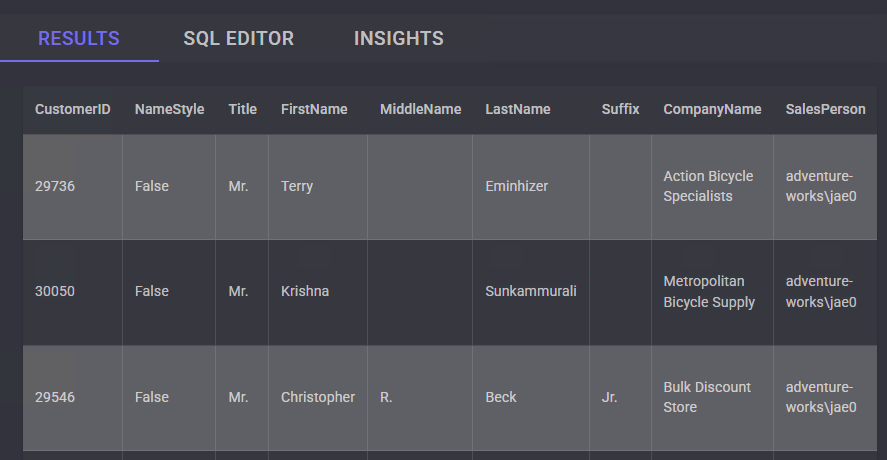
Observez les résultats sous forme de tableau retournés par la requête SQL :
Accédez à l’historique des requêtes exécutées, puis identifiez celles que vous souhaitez réutiliser :
La fonction Chat vous permet de relancez une seconde requête basée sur les résultats de la première :
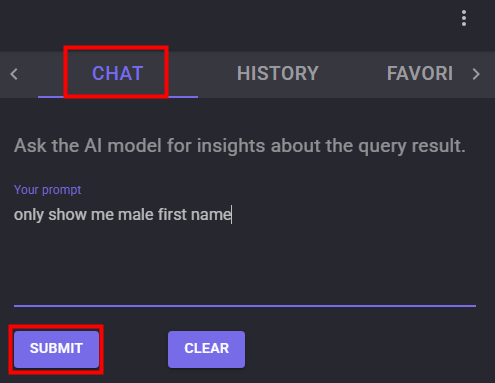
Testez cette seconde requête et constatez les résultats :
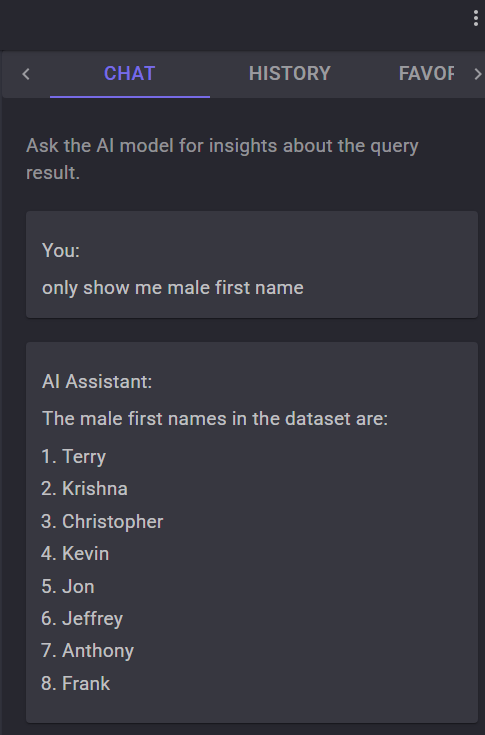
Au final, on constate que l’interface graphique de DBChatPro ne cesse d’évoluer pour offrir plus de facilité et une meilleure gestion des bases de données.
Passons maintenant à la partie MCP qui nous intéresse également.
Etape III – Déploiement du serveur MCP :
Revenez sur Visual Studio Code dans le programme MCP afin de paramétrer l’endpoint Azure OpenAI :
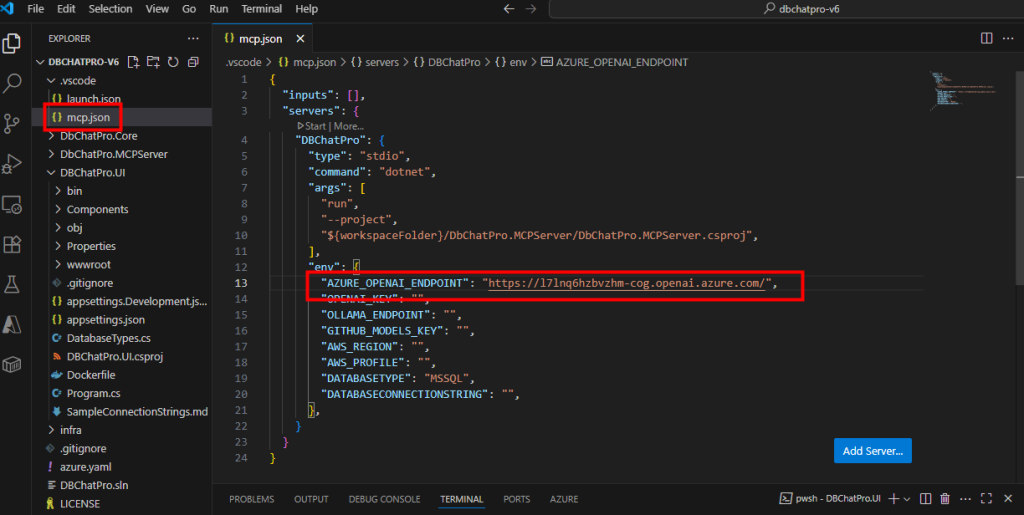
Collez également votre connexion SQL complète :
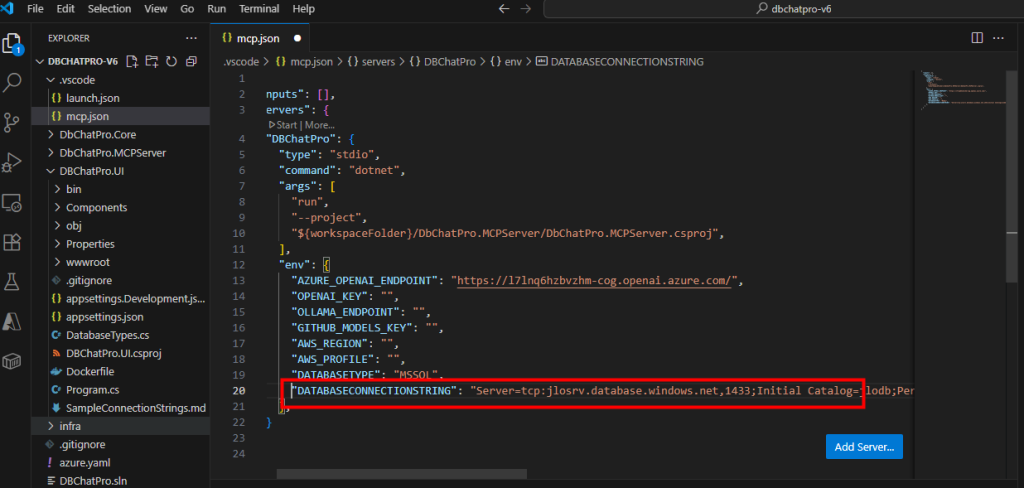
Cliquez sur le bouton Démarrer pour lancer le serveur MCP, puis patientez quelques instants :
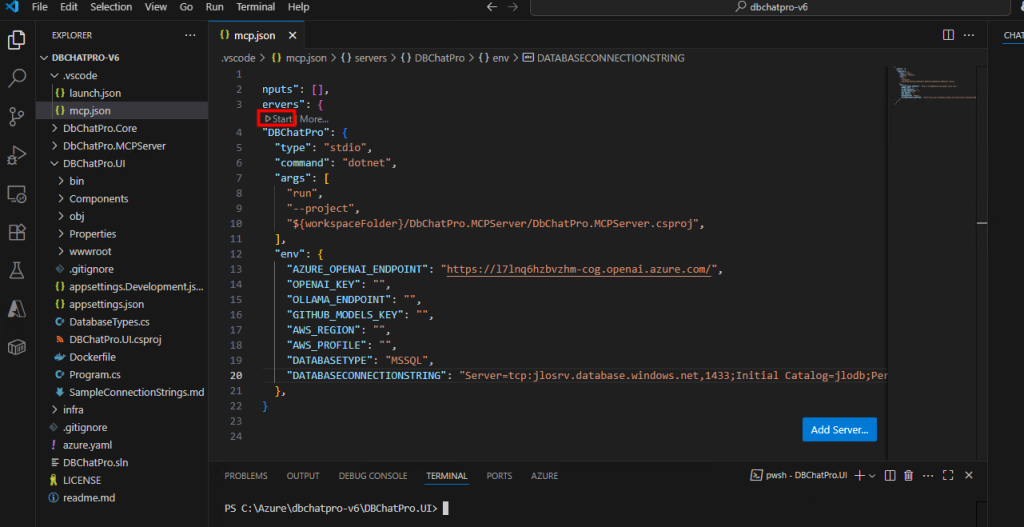
Vérifiez que le serveur est démarré et affiche l’état Running :
Ouvrez la fenêtre Chat dans Visual Studio Code :
Assurez-vous que vous êtes en mode agent pour l’intelligence artificielle :
Dans la boîte à outils, confirmez que le serveur MCP et ses sous-modules sont actifs, puis refermez le panneau :
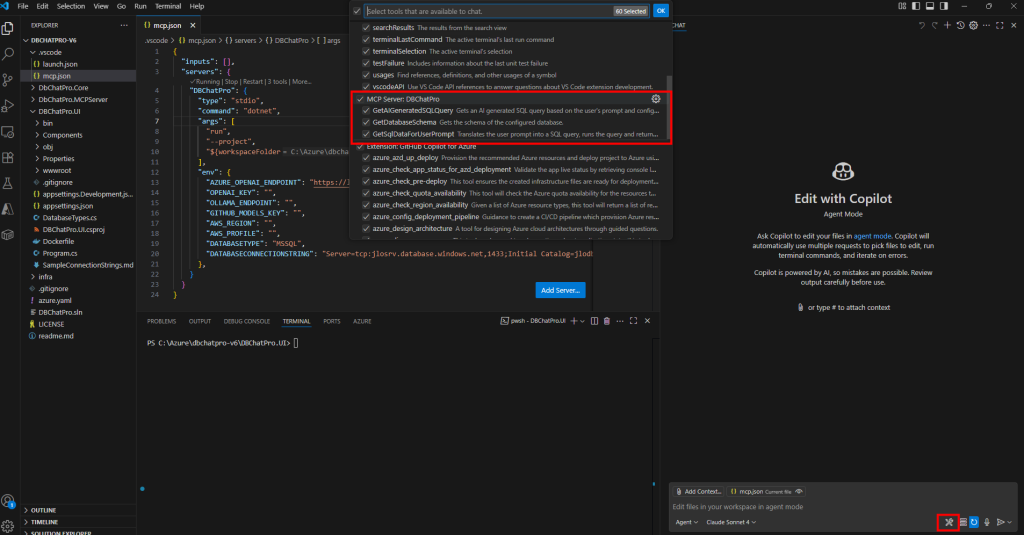
Effectuez un test de base pour vérifier que l’IA vous répond :
Lancez un prompt en spécifiant l’utilisation de DBChatPro avec un modèle et une plateforme AI, puis validez l’alerte :
use DbChatPro to get 10 customers from the database using AzureOpenAI and gpt-4o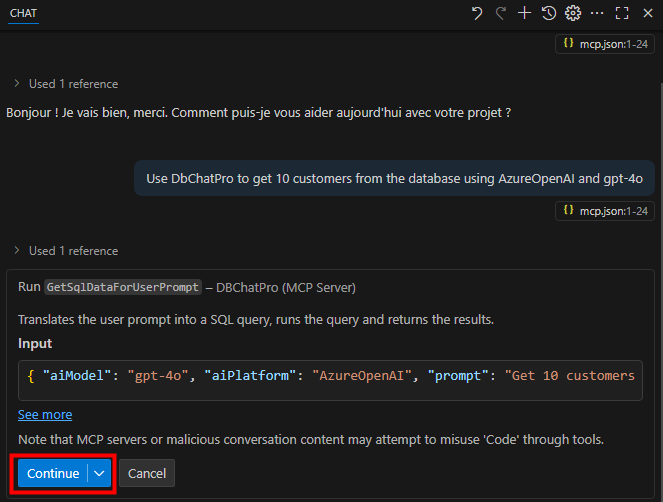
Constatez que la connexion à la base de données et au modèle a bien fonctionné :
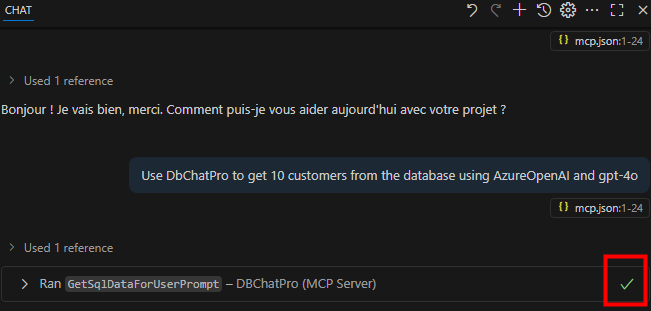
Observez en chat l’input et l’output de la requête :
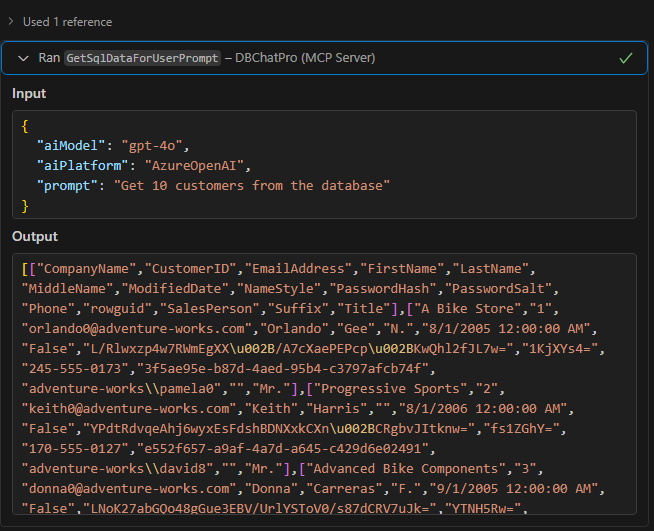
Visualisez le résultat sous forme de tableau retourné par l’IA :
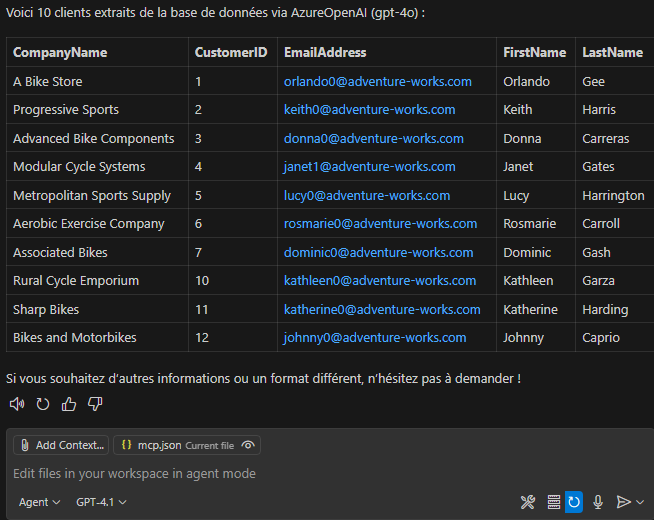
Lancez un second prompt sans redéfinir les paramètres du modèle, puis constatez que la réponse est tout de même générée :
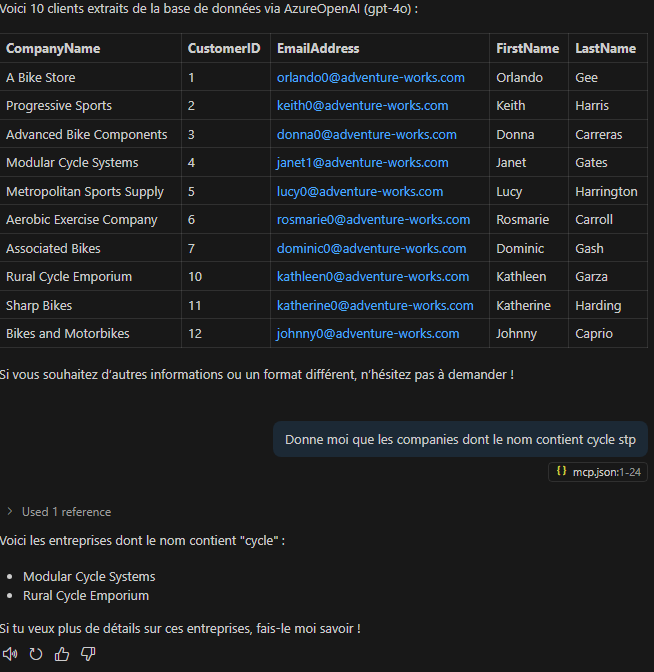
Effectuez un autre test avec un prompt différent sur la même base :
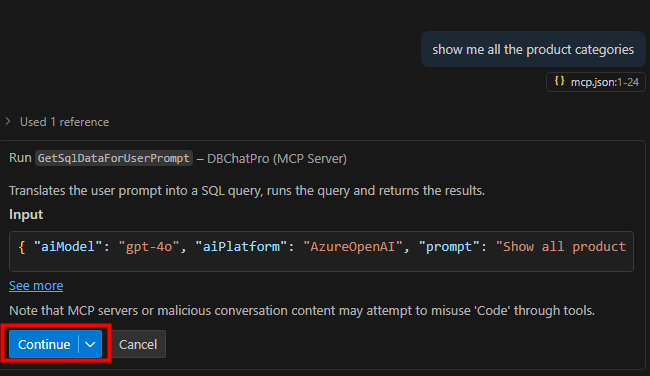
Observez le résultat structuré cette fois en liste :
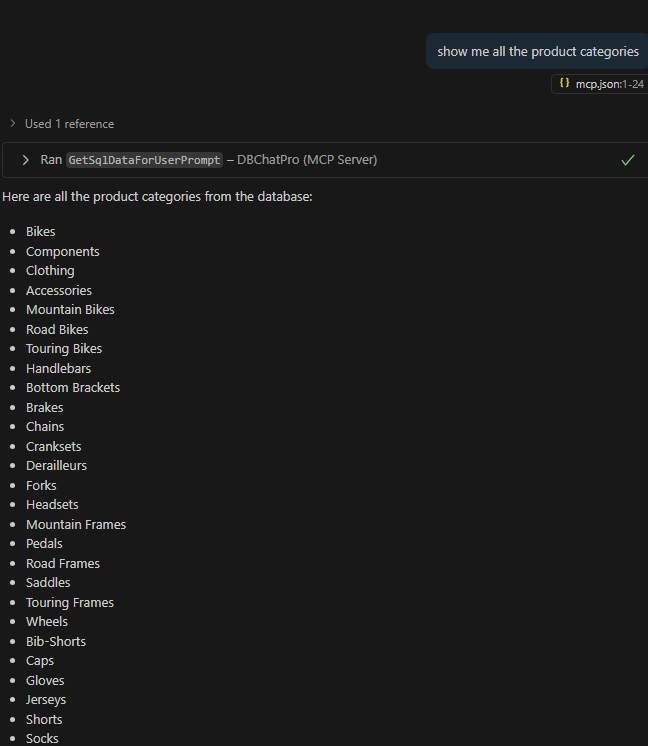
Si vous le souhaitez, testez la plateforme IA de GitHub en paramétrant un token d’accès sur cette page, puis copiez-le :
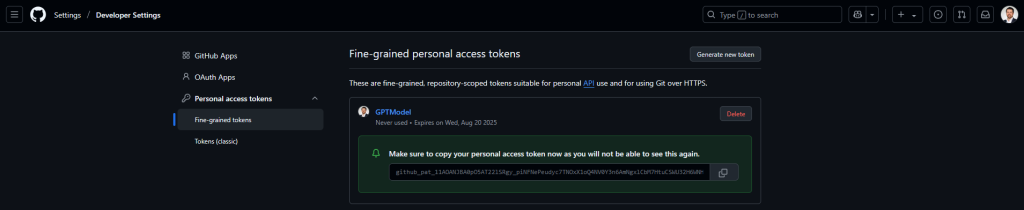
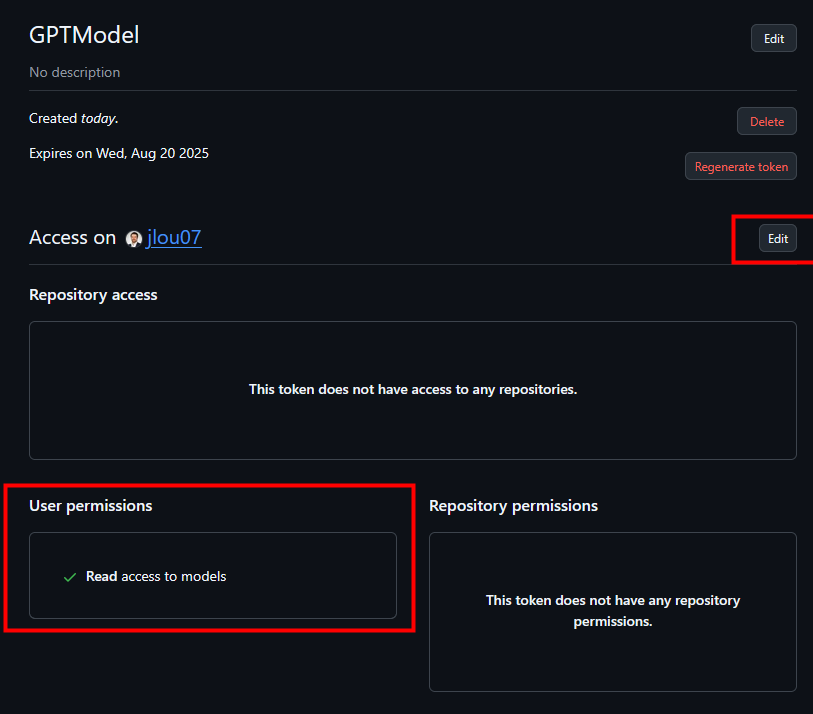
Sur ce token, autorisez l’accès en lecture pour interroger les modèles GitHub Copilot, puis confirmez cette permission :
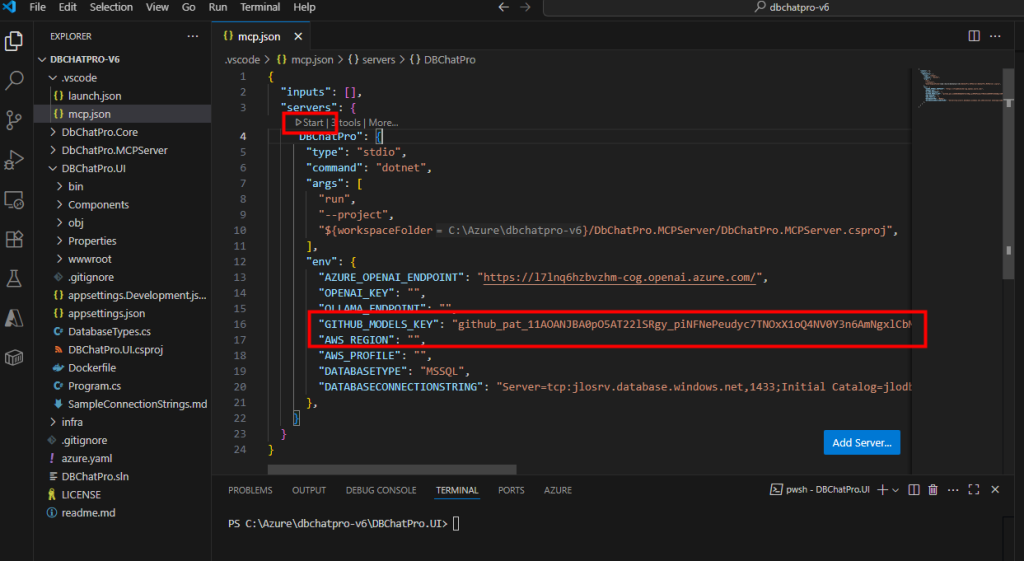
Renseignez le modèle GitHub dans la configuration MCP et redémarrez le serveur, puis patientez quelques instants :
Relancez un prompt en utilisant le modèle GitHub Copilot comme plateforme IA :
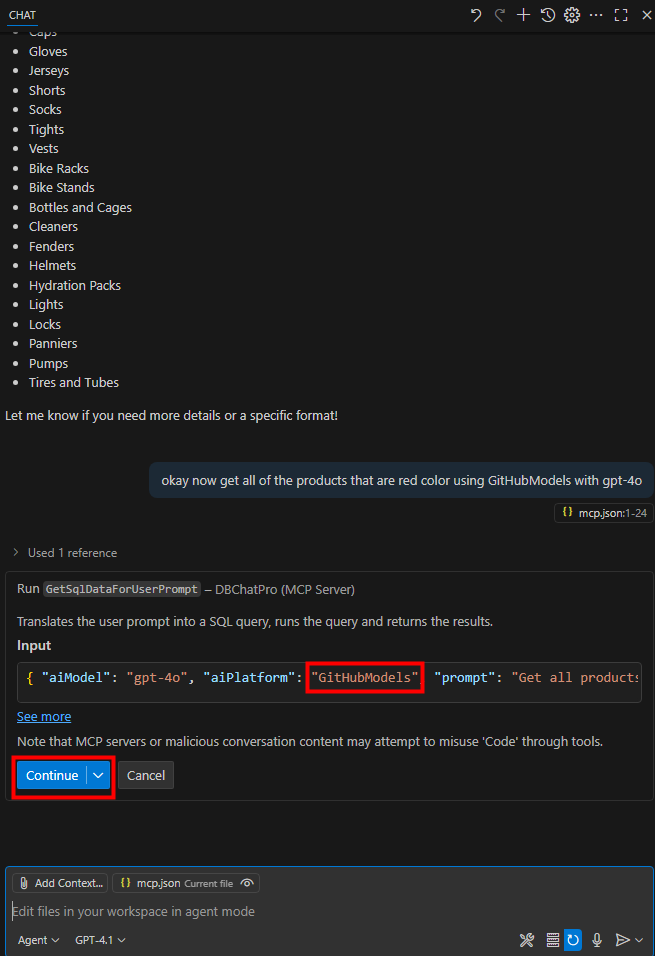
Constatez le retour de résultats :
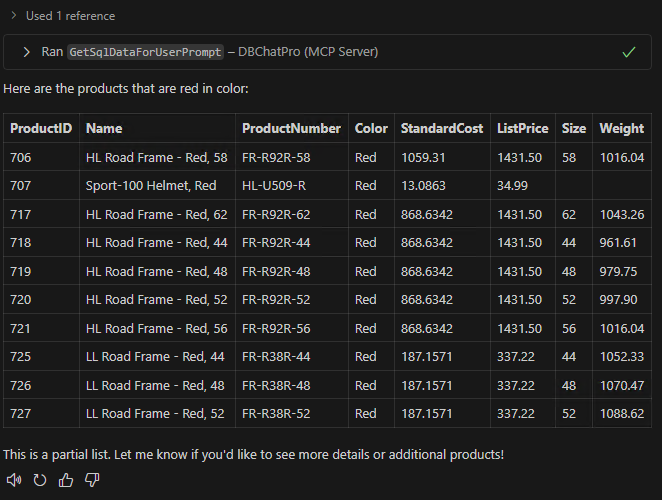
Envoyez cette fois un prompt combiné, interrogeant le serveur MCP via les deux modèles d’IA, puis constatez la fusion des réponses :
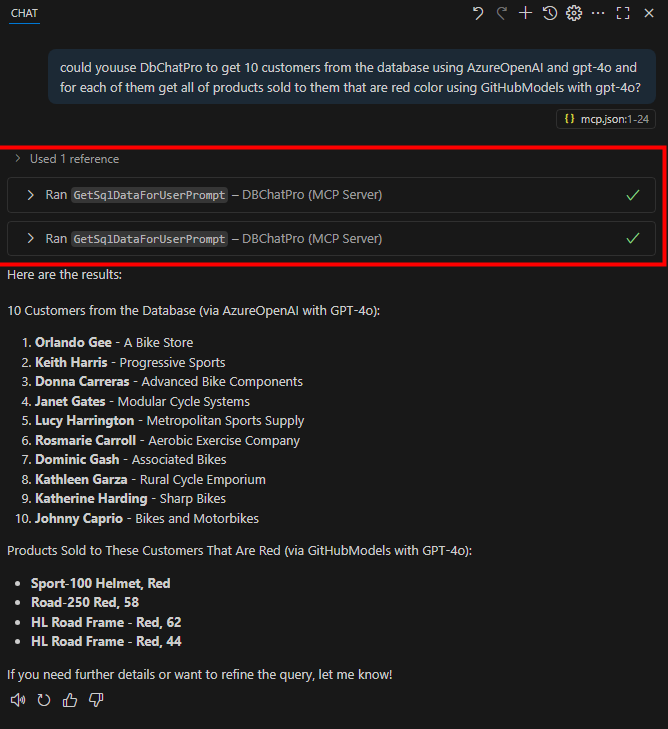
Enfin, découvrez sur sa vidéo, toujours depuis Visual Studio Code, des fonctions de troubleshooting très pratiques :
Conclusion
L’intégration du MCP transforme votre assistant en un véritable pont entre l’IA et le monde réel. Fini les intégrations sur mesure : grâce à ce protocole standard, un modèle peut interagir avec des bases de données, GitHub Copilot ou tout autre outil compatible.
On passe d’une complexité M×N à un système modulaire, extensible et sécurisé.
En adoptant le Model Context Protocol dès aujourd’hui, vous préparez vos solutions à l’IA de demain : une IA connectée, actionnable et interopérable, capable de faire bien plus que répondre, mais également d’interagir.