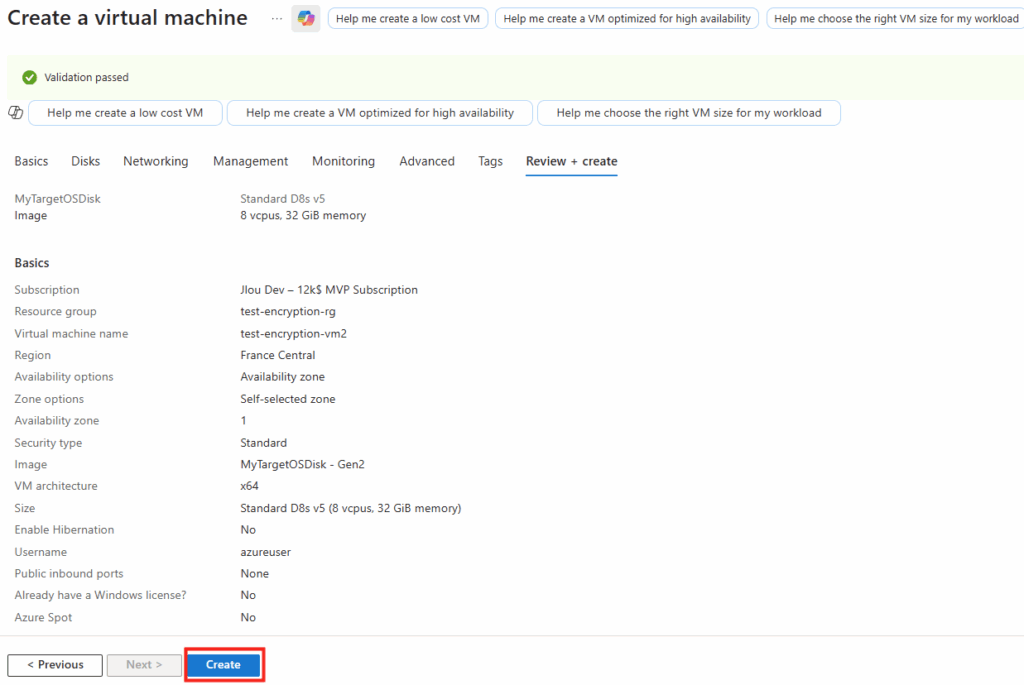
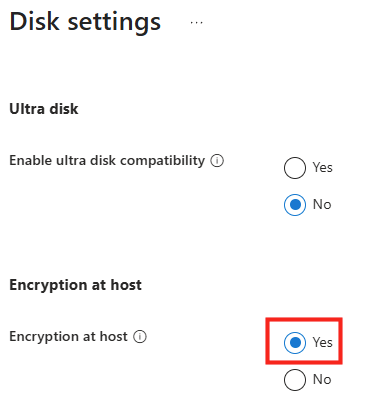
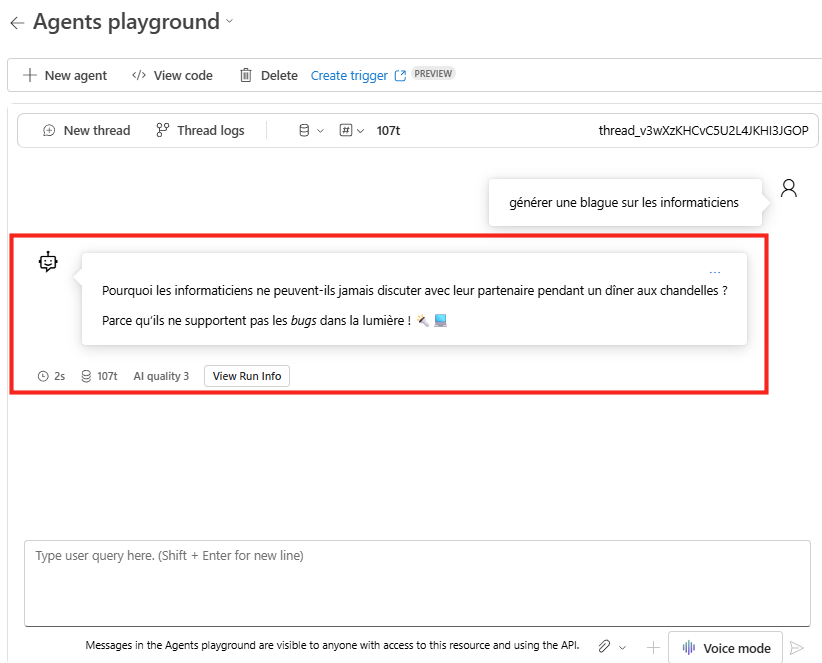
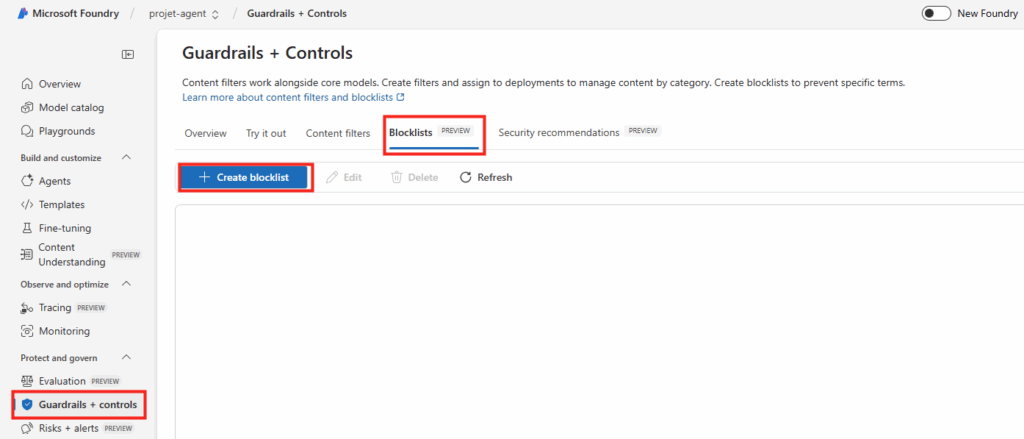
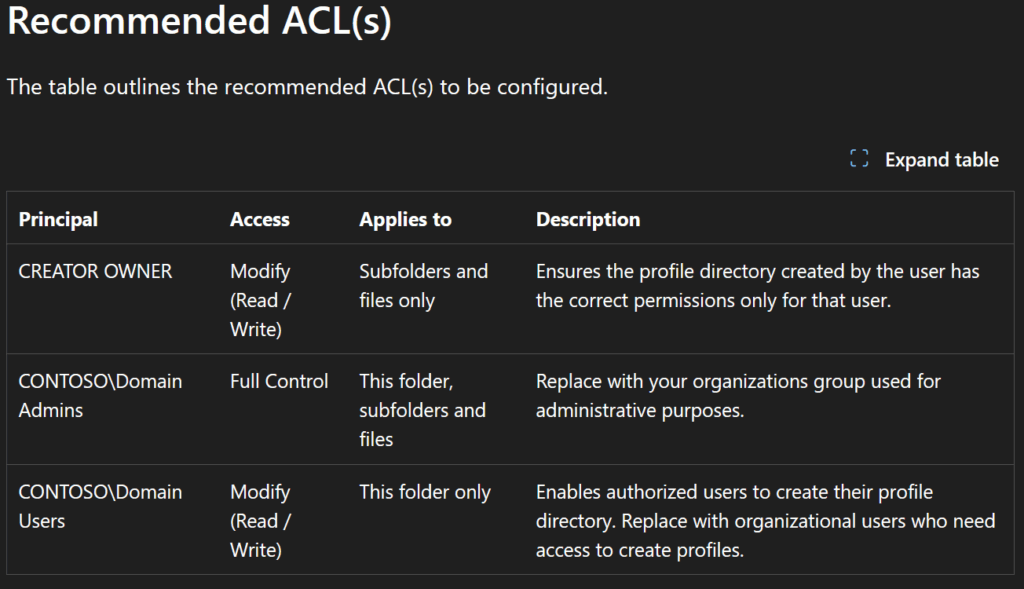
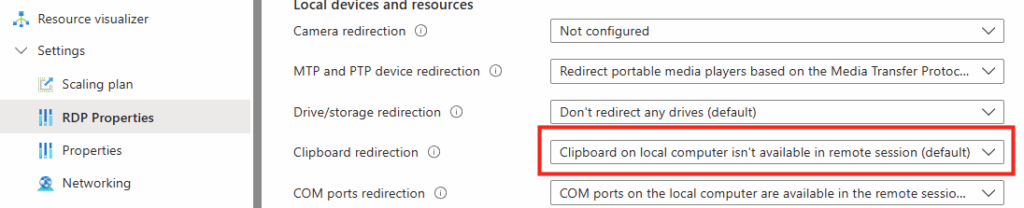
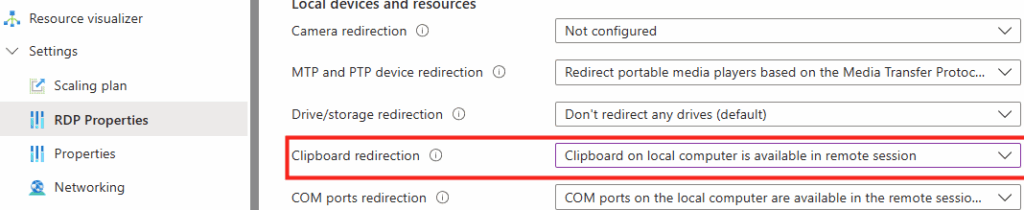
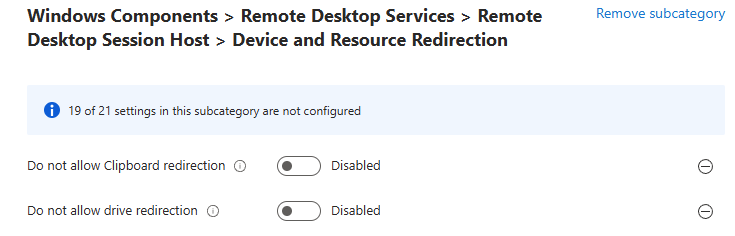
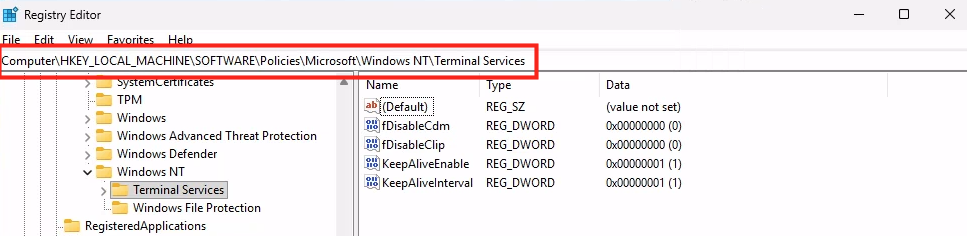
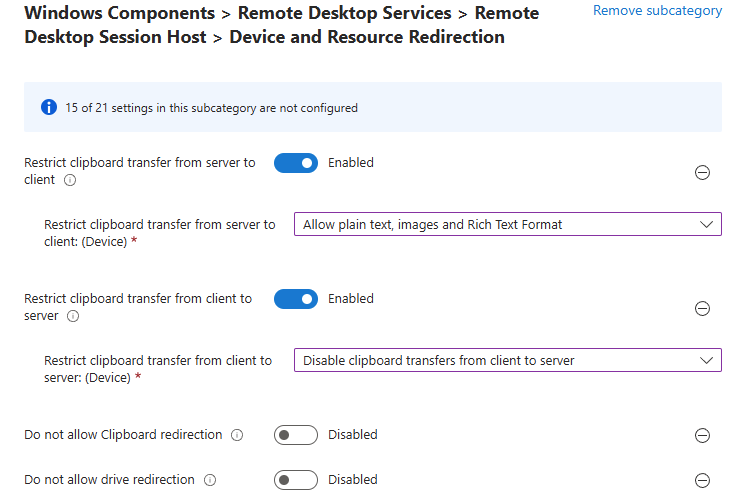
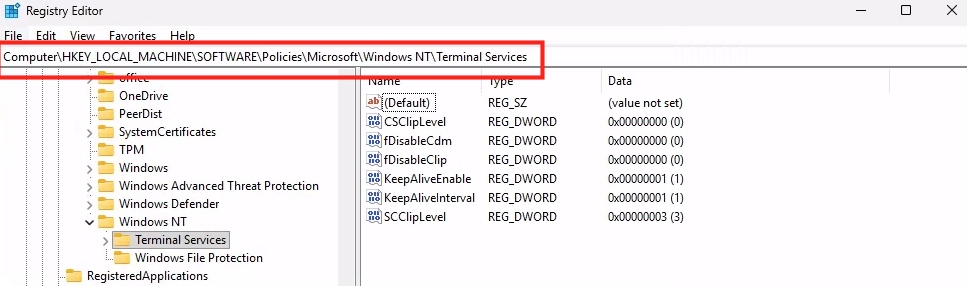
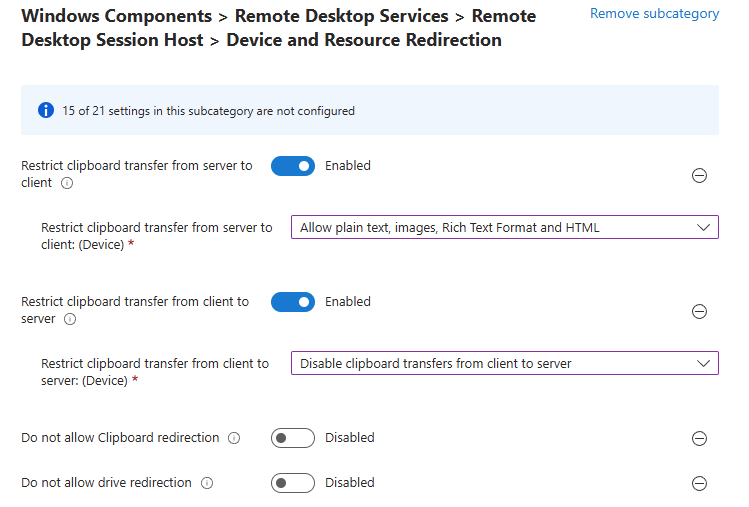
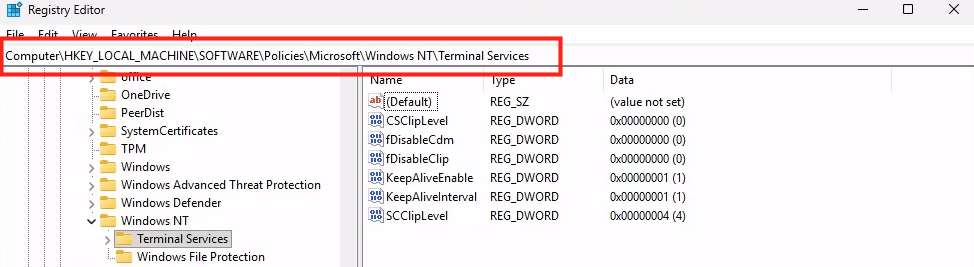
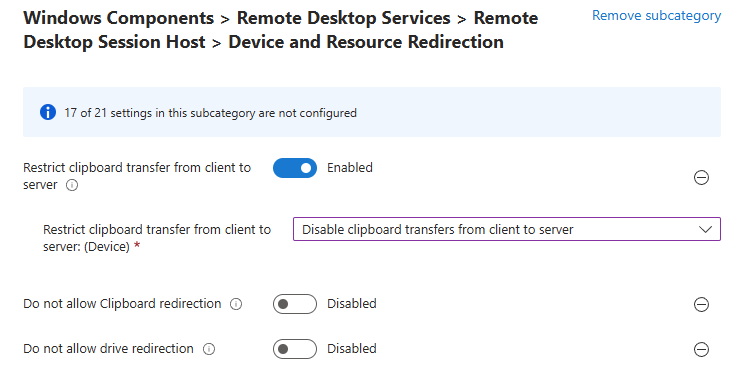
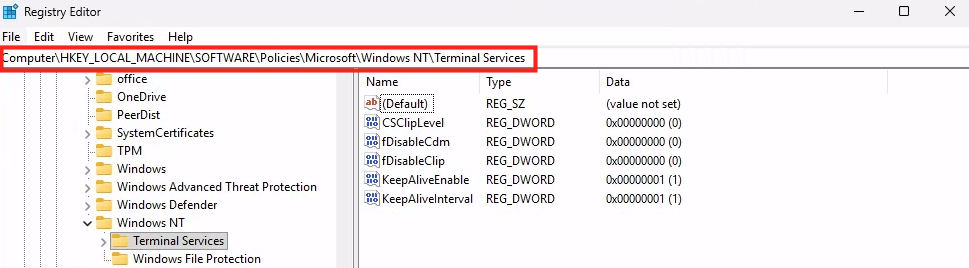
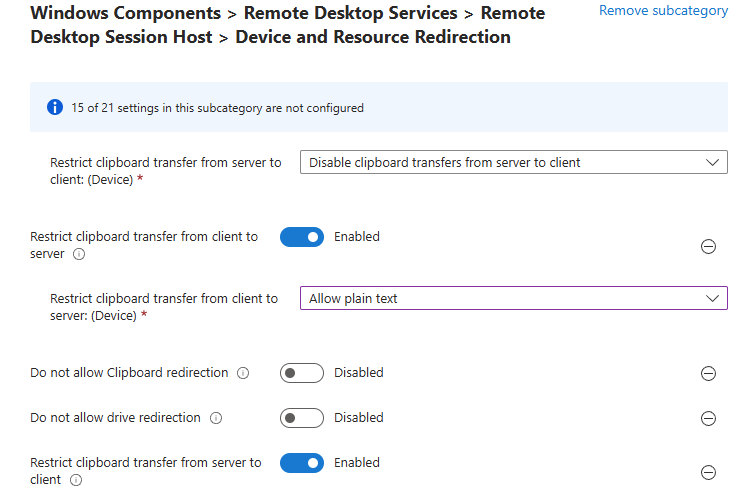
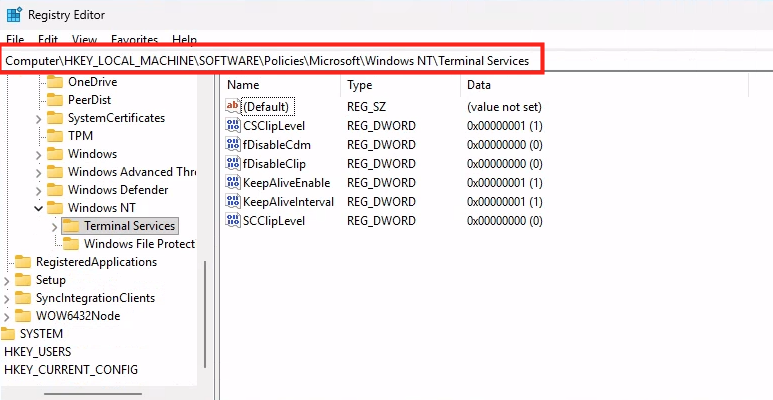
Combien de clics faut-il réellement pour capturer proprement une image AVD, la versionner dans une galerie, puis redéployer 10 hôtes sans erreur ? Si vous administrez Azure Virtual Desktop au quotidien, vous connaissez la réalité : le portail Azure fonctionne très bien… mais l’opérationnel est répétitif, chronophage, et parfois fragile. Image → Sysprep → Snapshot → Galerie → Version → Déploiement → Intégration au pool → Vérifications. Et on recommence !
Azure Virtual Desktop a énormément évolué ces dernières années. Builder, améliorations ARM/Bicep, automatisations natives… mais malgré tout, dans la vraie vie d’un admin ou d’un architecte, on cherche surtout à raccourcir la boucle opérationnelle.
C’est exactement là que WVDAdmin entre en jeu. Un outil communautaire, simple, direct, qui ne cherche pas à réinventer AVD, mais à compresser le quotidien.
Et pour vous guider plus facilement dans cet article très long, voici des liens rapides :
WVDAdmin est un outil graphique communautaire pour administrer Azure Virtual Desktop (anciennement Windows Virtual Desktop) via une application installée localement. WVDAdmin a été développé par Marcel Meurer et est disponible via son blog ITProCloud.
Qui est Marcel Meurer ?
Marcel Meurer est un expert allemand spécialisé dans Azure Virtual Desktop (AVD) et l’automatisation Azure. Il a reçu une double nomination en tant que Microsoft MVP, et il fait partie de ce prestigieux programme depuis plus de onze années.
Marcel Meurer est également le créateur de Hydra for Azure Virtual Desktop. Nous reviendrons sur Hydra for Azure Virtual Desktop dans un prochain article.
Que peut-on faire avec WVDAdmin ?
Une bonne manière de comprendre WVDAdmin est la suivante : il ne cherche pas à « remplacer Azure Virtual Desktop », mais à compresser la boucle opérationnelle (image → déploiement → exploitation → mise à jour) en moins de clics et dans une interface unique.
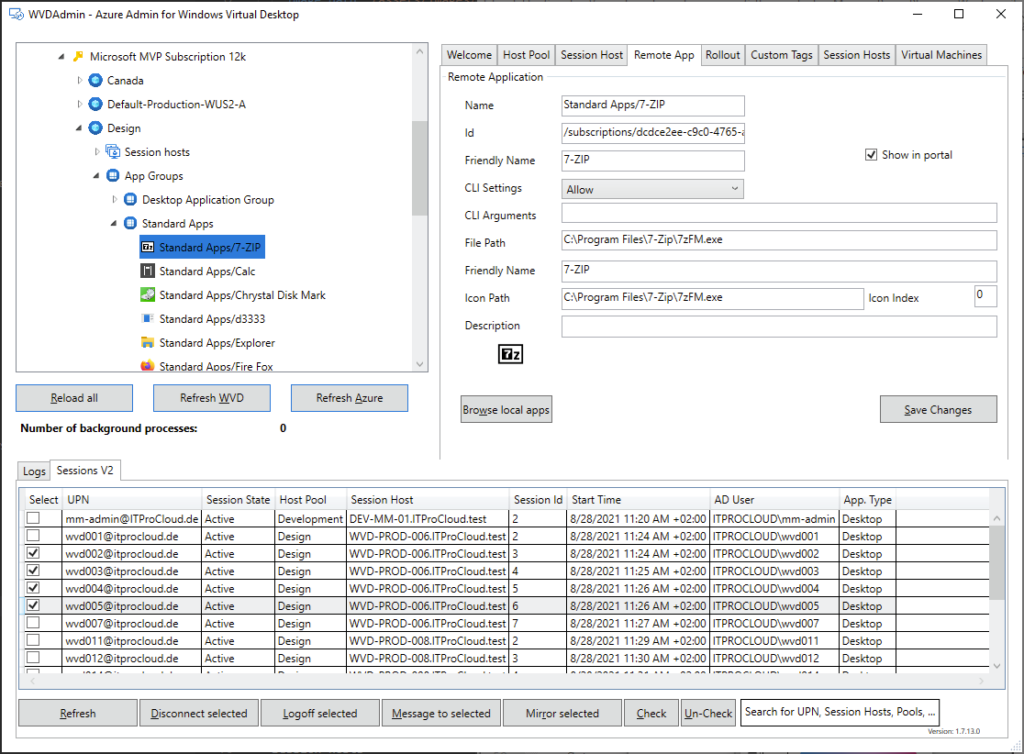
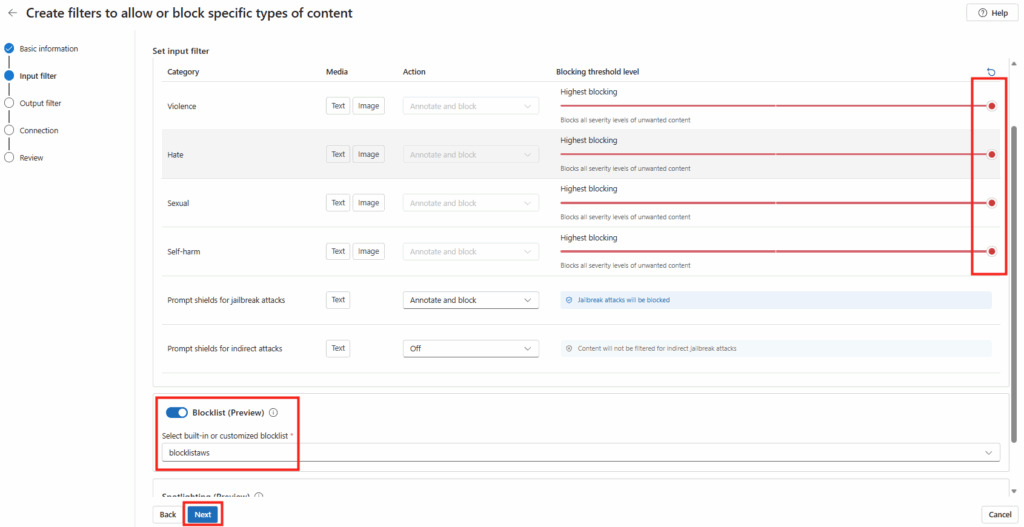
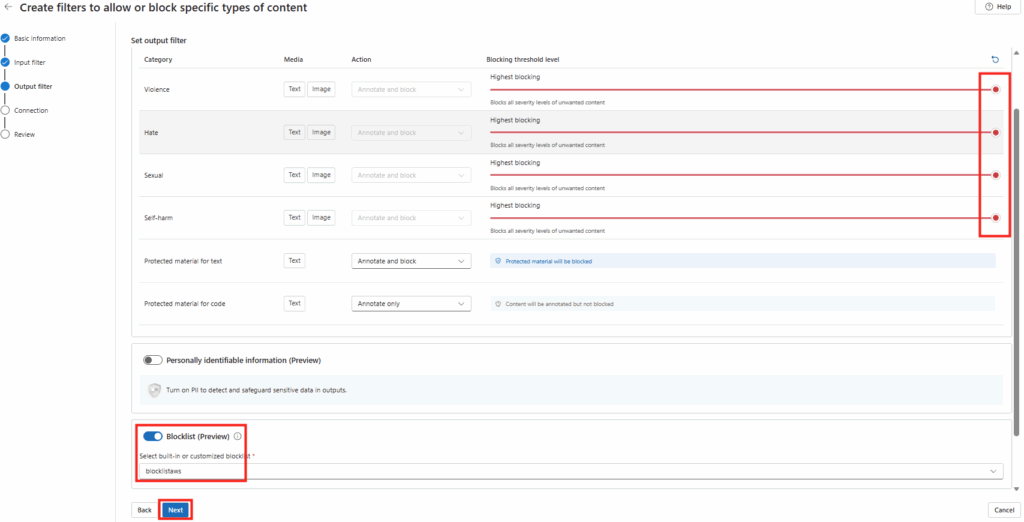
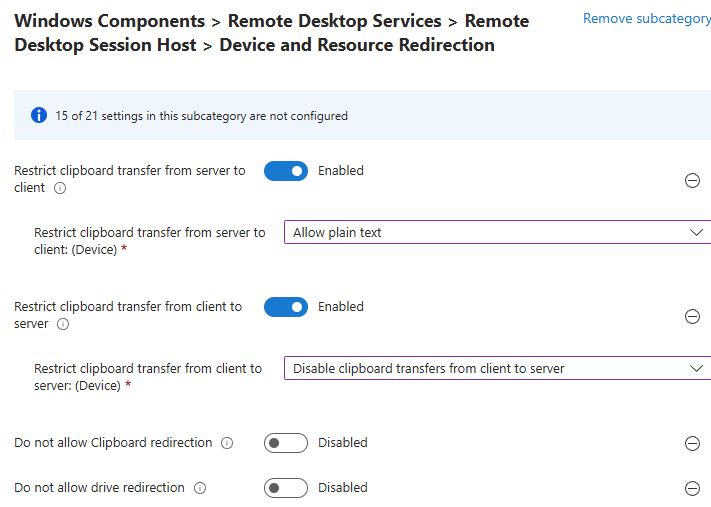
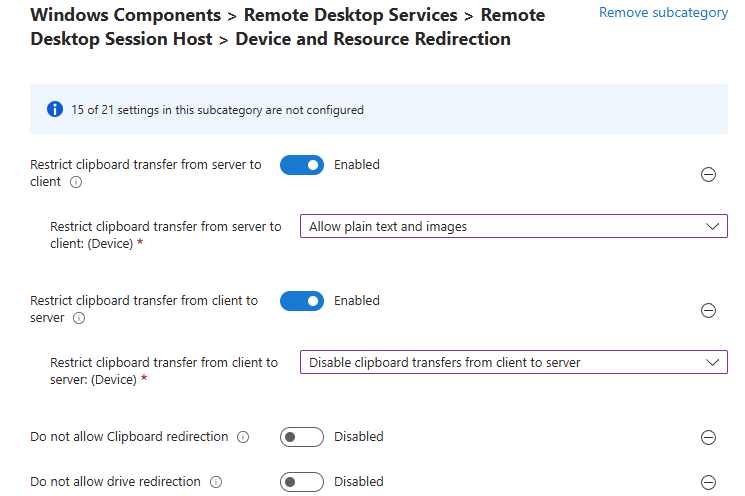
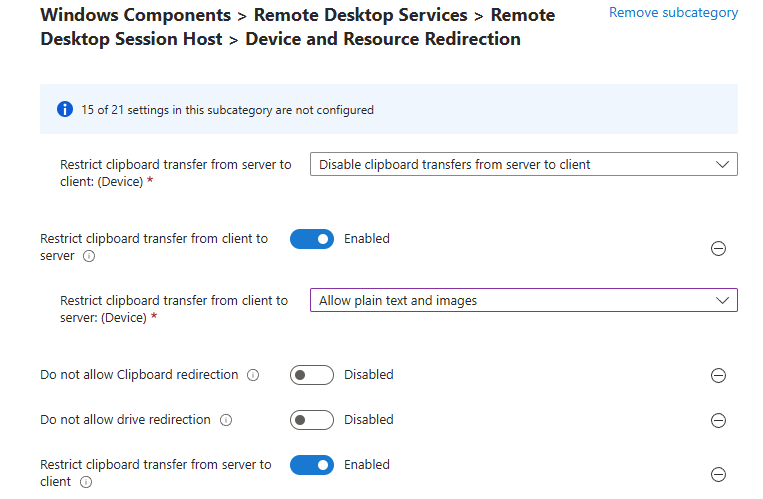
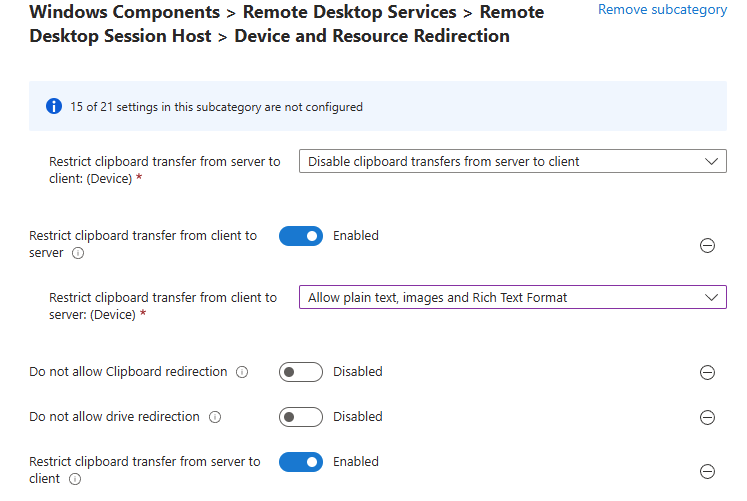
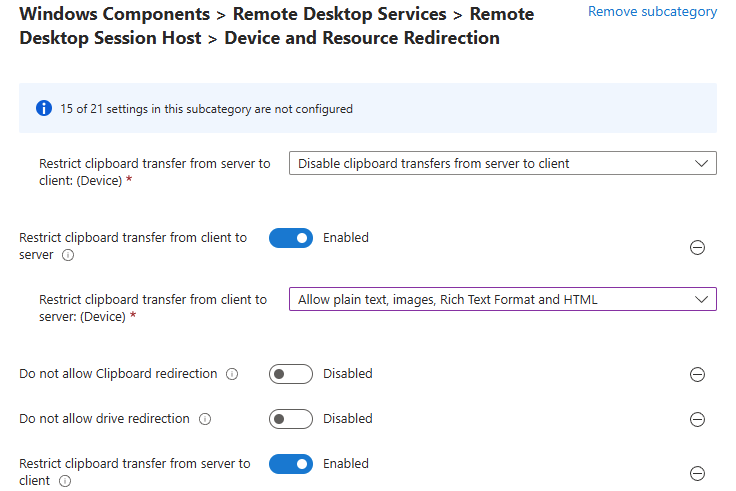
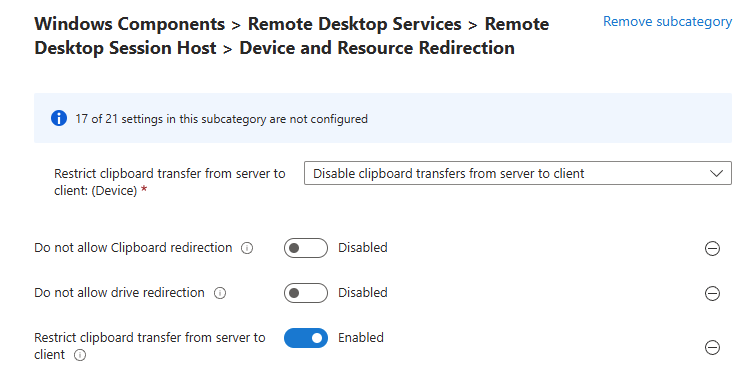
Workflow d’image golden : création d’images à partir d’un « golden master » sans détruire la VM maître/modèle, avec gestion de Sysprep, des applications modernes et des opérations de nettoyage.
Déploiement (rollout) : déploiement de plusieurs hôtes de session, choix des tailles de VM par déploiement, prise en charge des disques éphémères, et options telles que « AAD only / joint à MEM/Intune » (selon l’auteur).
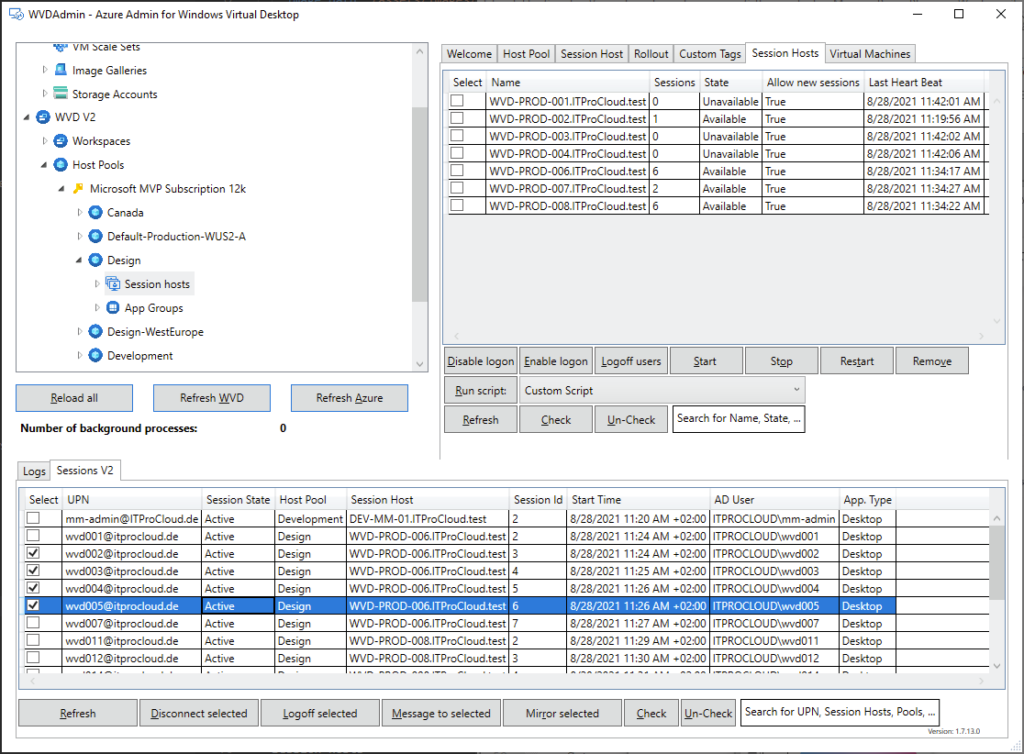
Opérations sur les ressources AVD : création, ajout et suppression de pools d’hôtes, groupes d’applications, espaces de travail et hôtes de session.
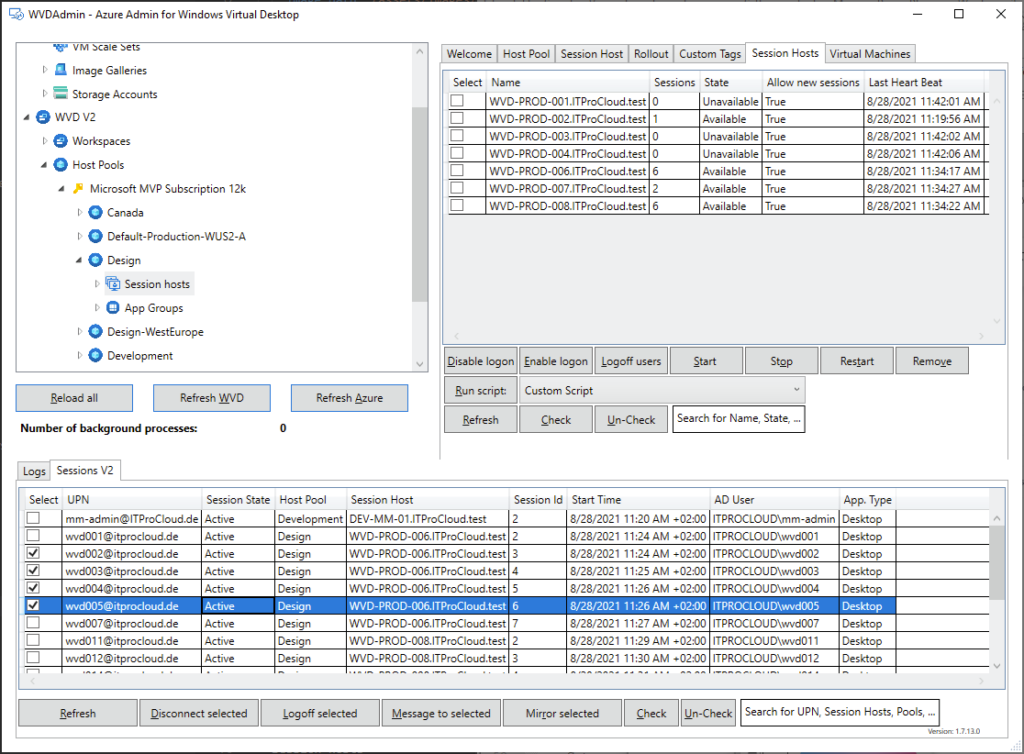
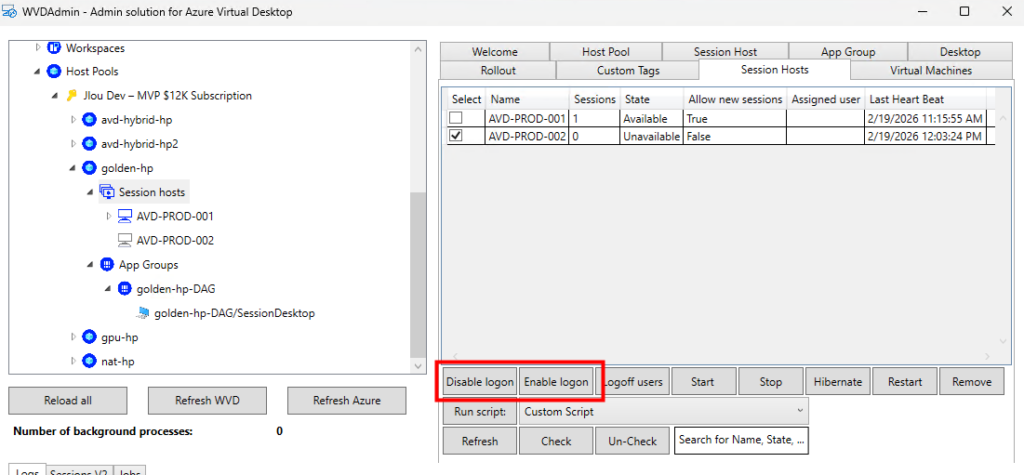
Opérations sur les sessions : déconnexion, délogage, envoi de messages et shadowing.
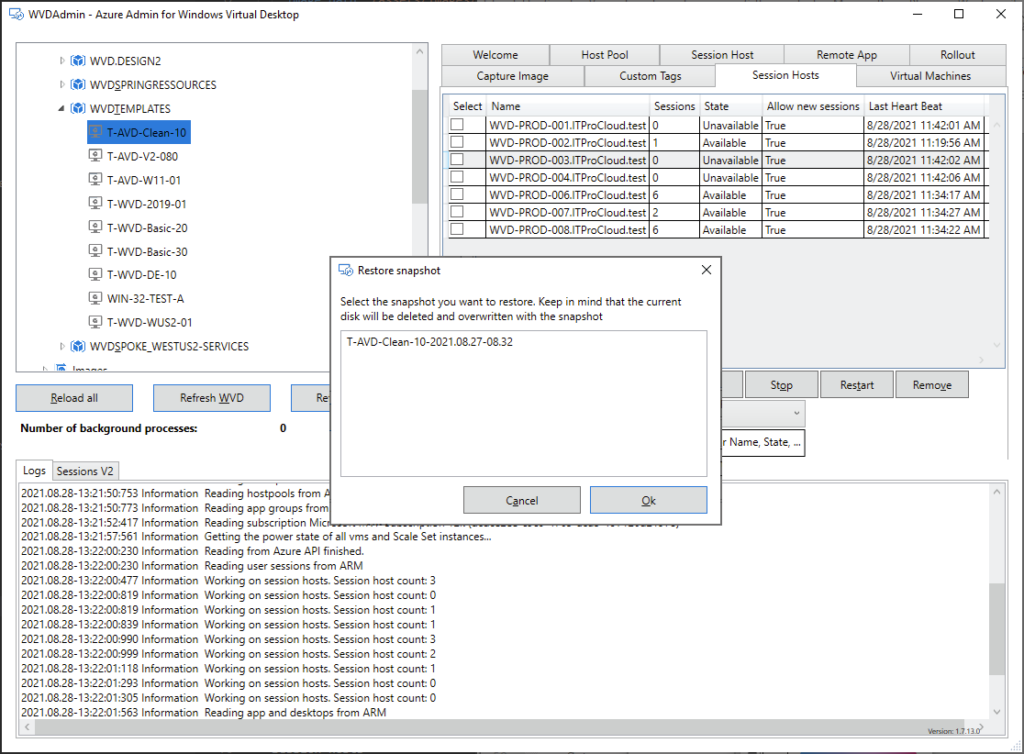
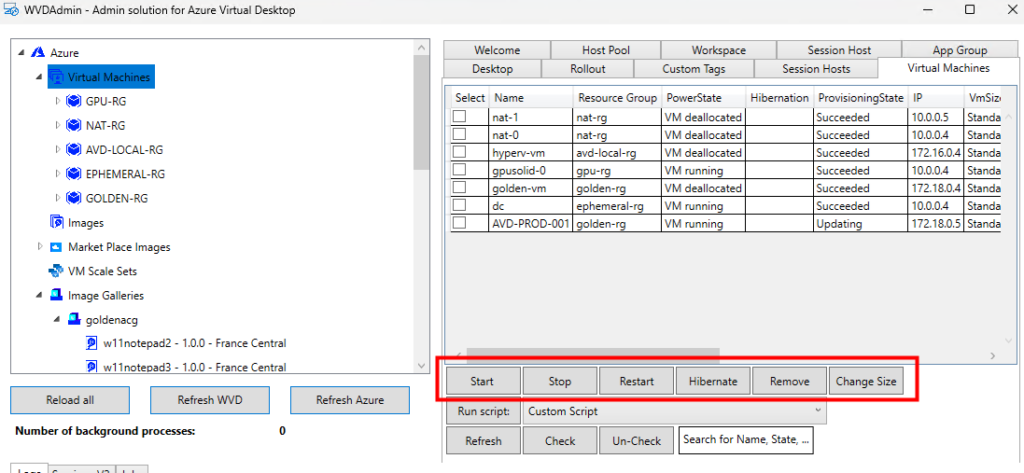
Opérations générales sur les VM Azure : inventaire des VM sur plusieurs abonnements (via Azure Resource Graph, avec un délai signalé), exécution de scripts à distance, snapshots/restaurations, et même réduction de la taille des disques OS.
Opérations en simultané : WVDAdmin supporte plusieurs tâches en simultané afin de gagner en efficacité.
WVDAdmin vs Hydra for AVD ?
WVDAdmin est à l’origine un outil communautaire gratuit pour Azure Virtual Desktop. WVDAdmin est intéressant lorsqu’on cherche une méthode rapide pour faire de l’imaging et du déploiement AVD. C’est une application Windows utilisée de manière interactive, donc sans automatisation planifiée.
Hydra en est une évolution plus avancée et orientée production (autoscaling, multi-tenant, orchestration plus poussée, etc.). Hydra apporte l’automatisation complète, l’optimisation des coûts, le monitoring via l’Hydra Agent, et supporte aussi des scénarios Azure Local.
WVDAdmin est donc un choix pertinent si l’on veut éviter de déployer des ressources supplémentaires Azure comme celles nécessaires pour Hydra.
Critère
WVDAdmin
Hydra
Type
Outil GUI local
Plateforme SaaS
Autoscaling
❌
✅
Multi-tenant
Limité
Oui
Coût
Gratuit
Payant
Infrastructure supplémentaire
Non
Oui
Est-ce que WVDAdmin est toujours maintenu ?
L’outil WVDAdmin existe maintenant depuis au moins 5 ans. WVDAdmin est toujours maintenu, mais n’est peut-être plus aussi activement développé comme avant (les efforts d’amélioration sont principalement concentrés sur Hydra).
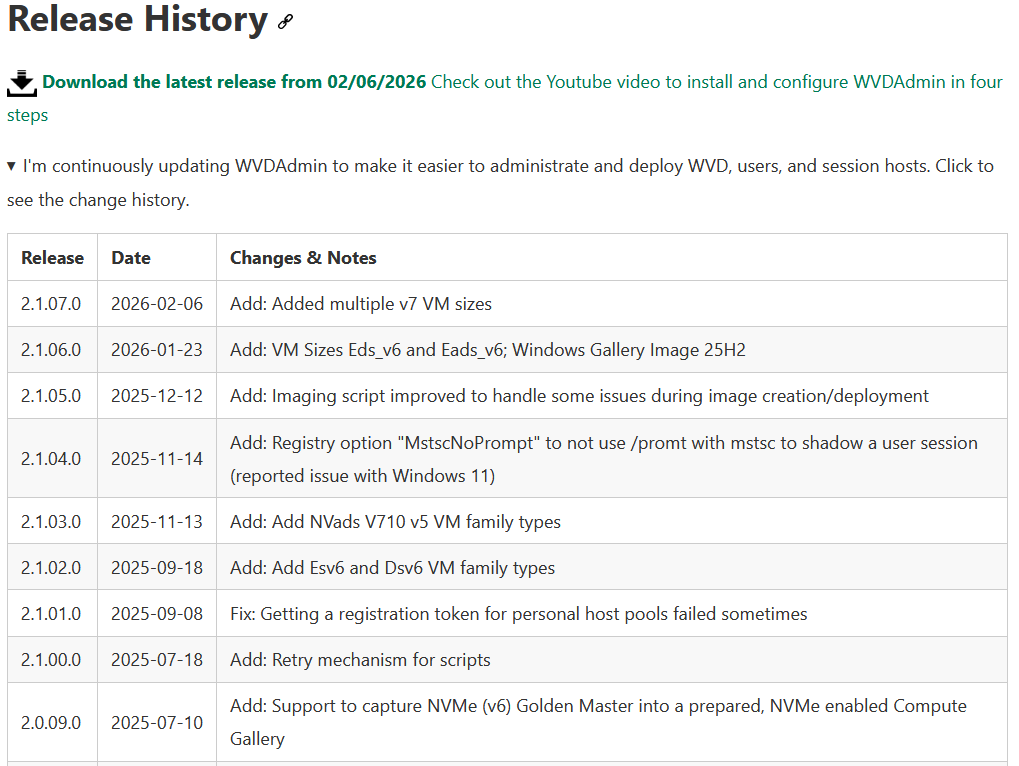
Il reçoit encore des mises à jour, principalement pour prendre en compte les nouveaux SKUs Azure, corriger des bugs ou assurer la compatibilité avec certains changements d’API :
Quoi qu’on en dise, plusieurs dernières releases de WVDAdmin sont sorties en 2026, avec une dernière version publiée le 06/02/2026 :
Combien coûte WVDAdmin ?
Là encore nous pouvons lui dire merci, car WVDAdmin un outil licence-free pour Azure Virtual Desktop, utilisable sans frais supplémentaires pour l’administration des ressources AVD via une application Windows.
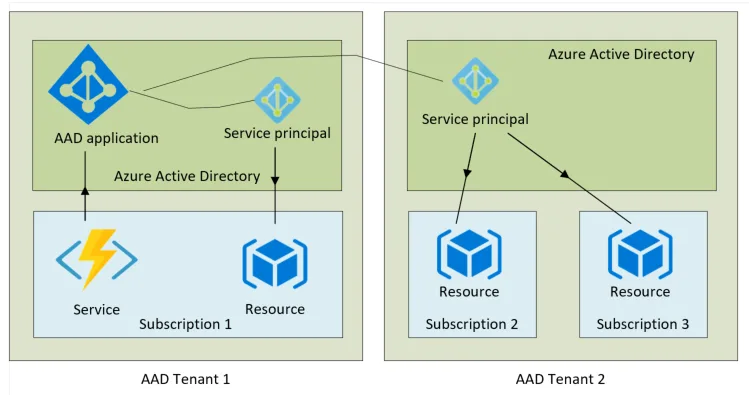
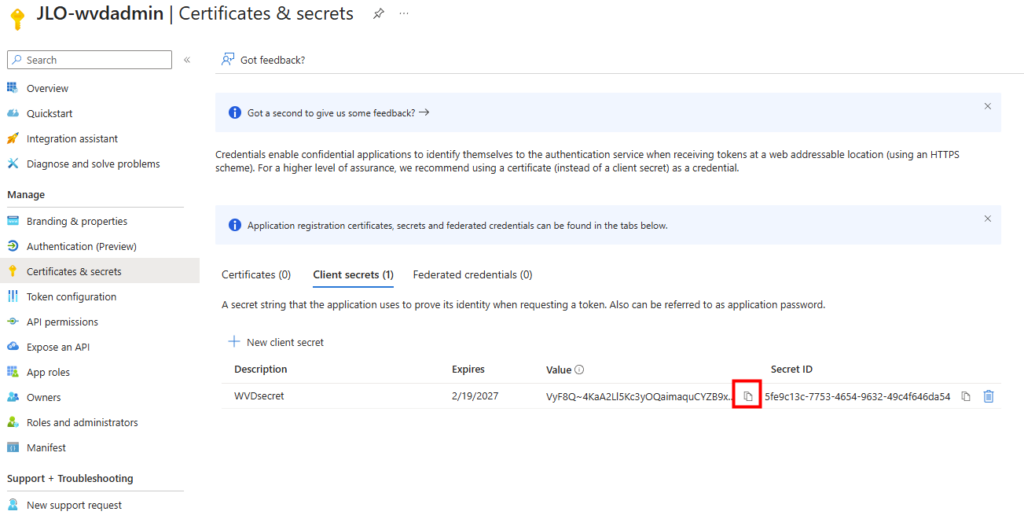
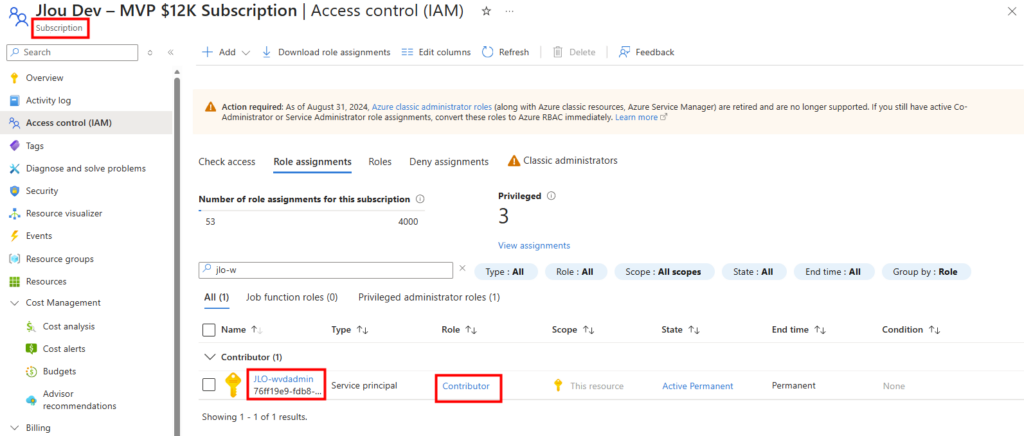
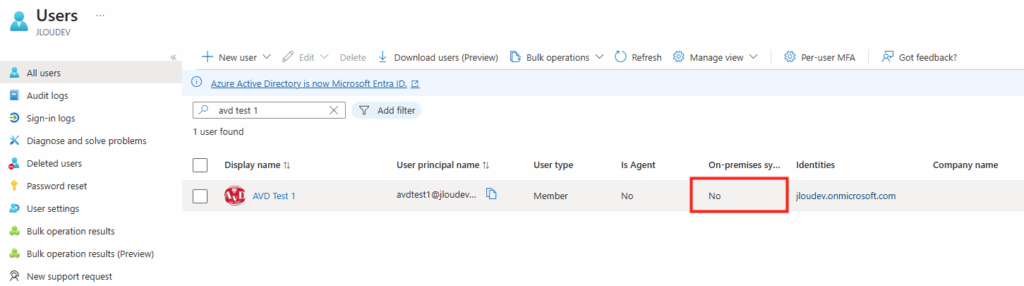
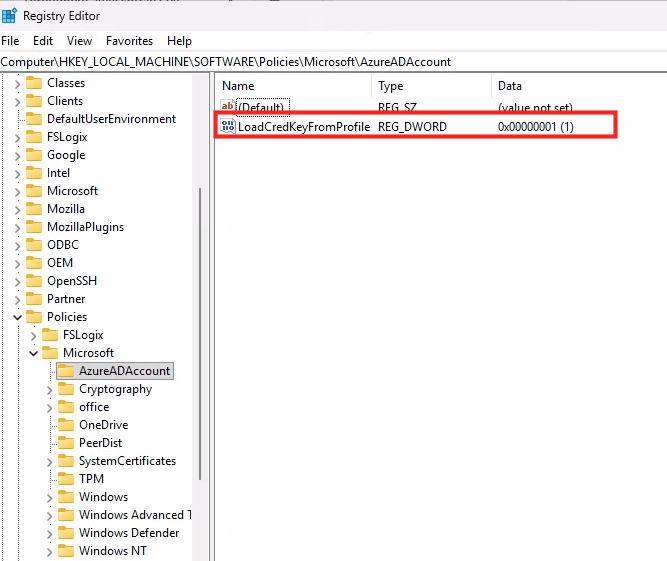
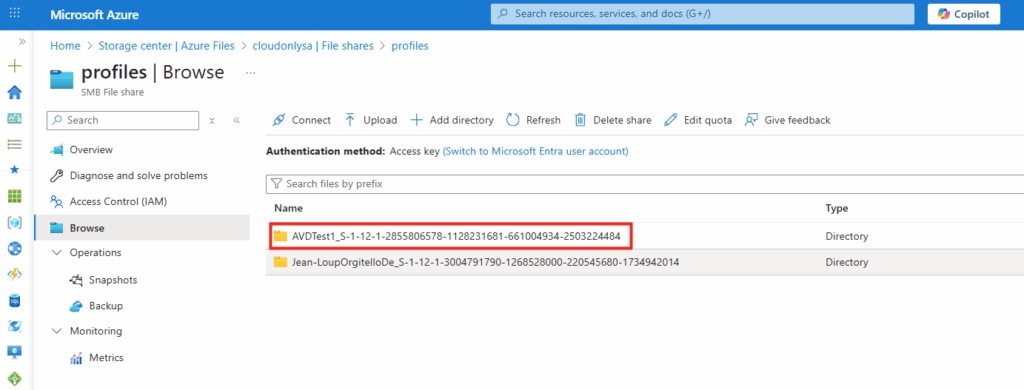
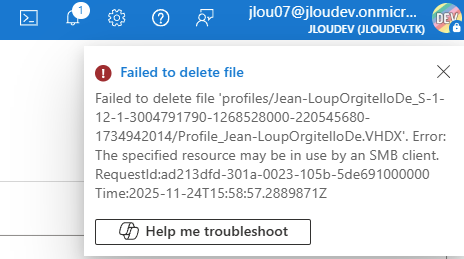
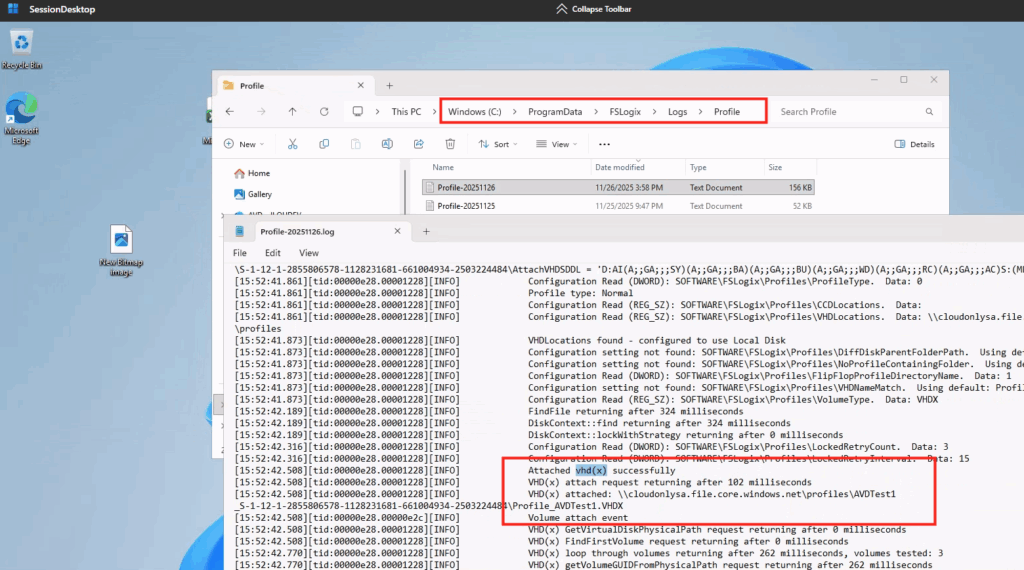
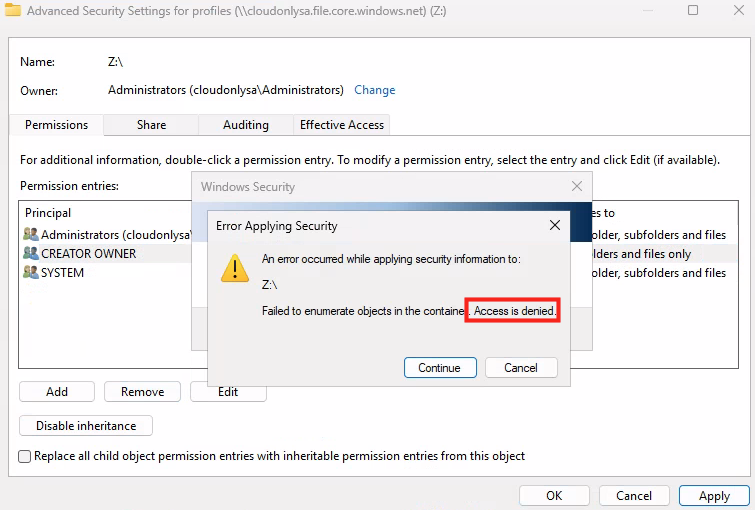
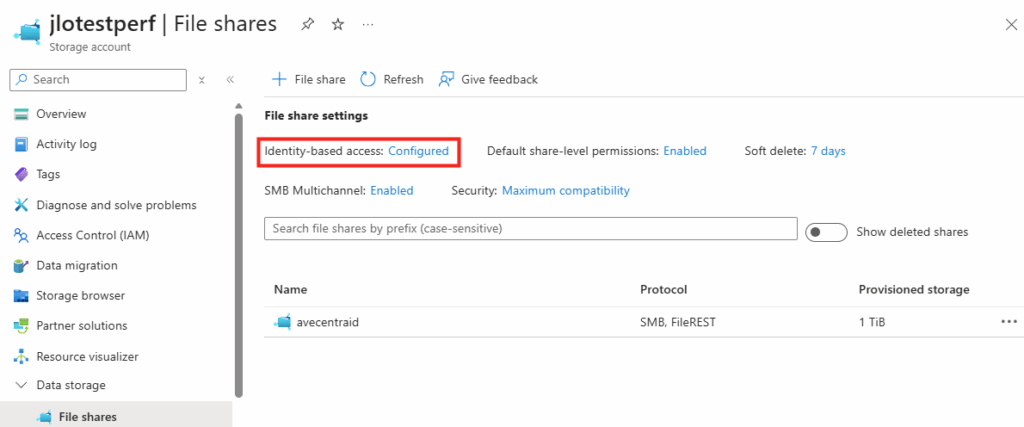
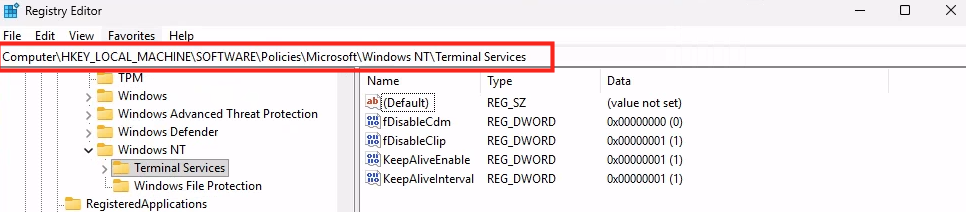
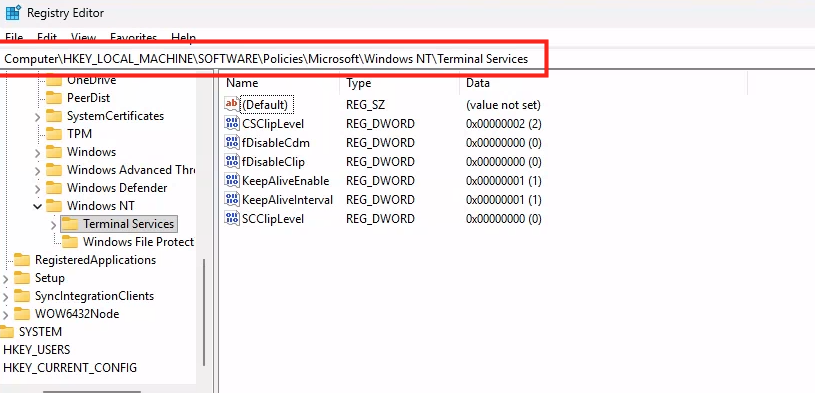
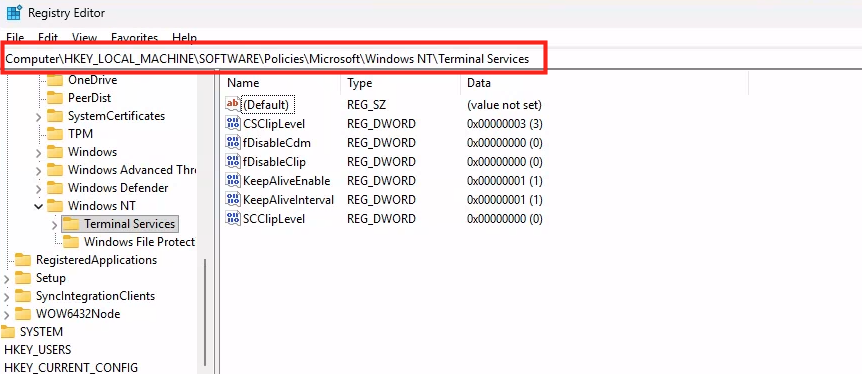
WVDAdmin accès aux ressources Azure par le biais d’un principal de service, protégé par un secret. Celui-ci dispose de permissions sur AVD et sur les ressources Azure. L
’objectif est notamment d’éviter toute confusion lorsque l’administrateur IT est un compte invité dans un tenant client et doit changer régulièrement de tenant.
Voici d’ailleurs un exemple de fonctionnement dans le cadre de plusieurs tenants :
Comment WVDInfra marche ?
Au travers de sa chaîne YouTube, Marcel a mis à disposition une playlist spécifiquement consacré à WVDInfra, de son installation à différentes qu’il peut faire sur votre environnement Azure Virtual Desktop :
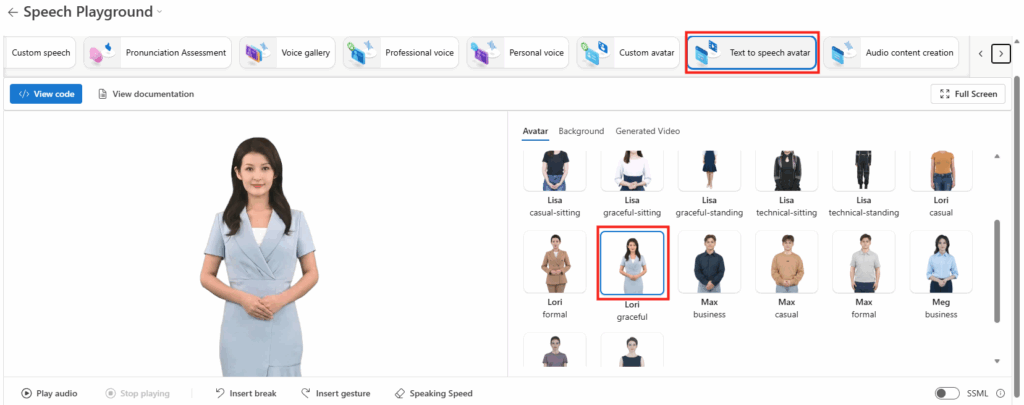
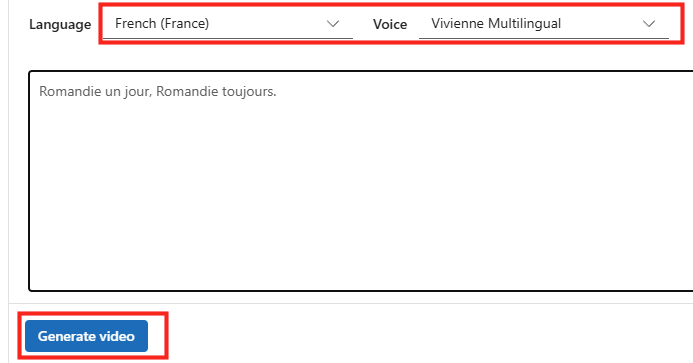
Et enfin, comme toujours, je vous propose dans la suite de cet article d’effectuer ensemble un pas à pas pour couvrir l’installation de WVDInfra, sa mise en service, la capture d’une image Windows 11 custom et enfin la création d’une hôte dans un environnement AVD :
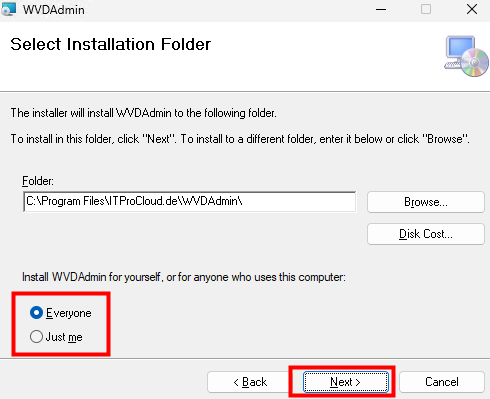
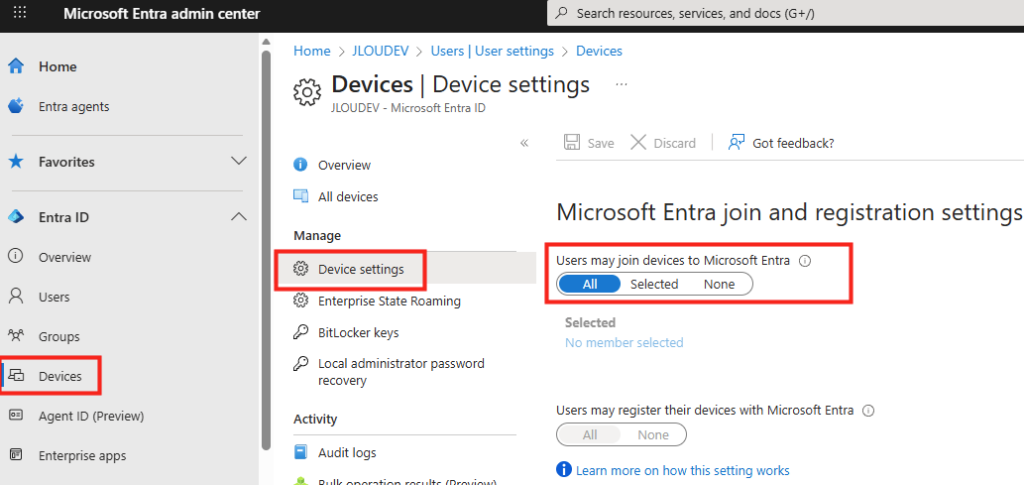
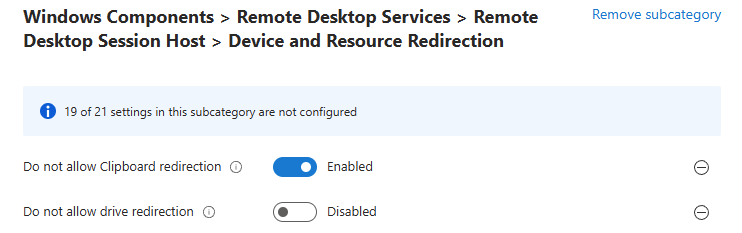
Lancez l’installation en spécifiant le contexte d’utilisation de celle-ci, puis cliquez sur Suivant :
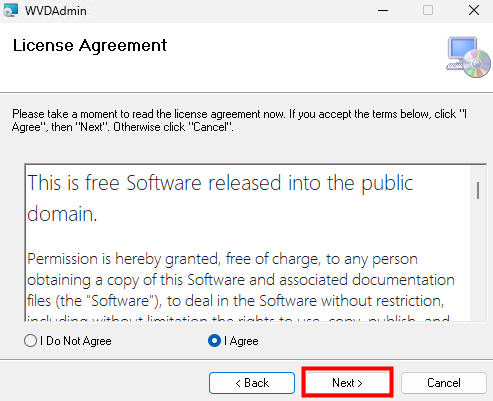
Acceptez les termes et conditions, puis cliquez sur Suivant :
Cliquez sur Suivant pour démarrer l’installation :
Une fois l’installation réussie, cliquez ici pour fermer :
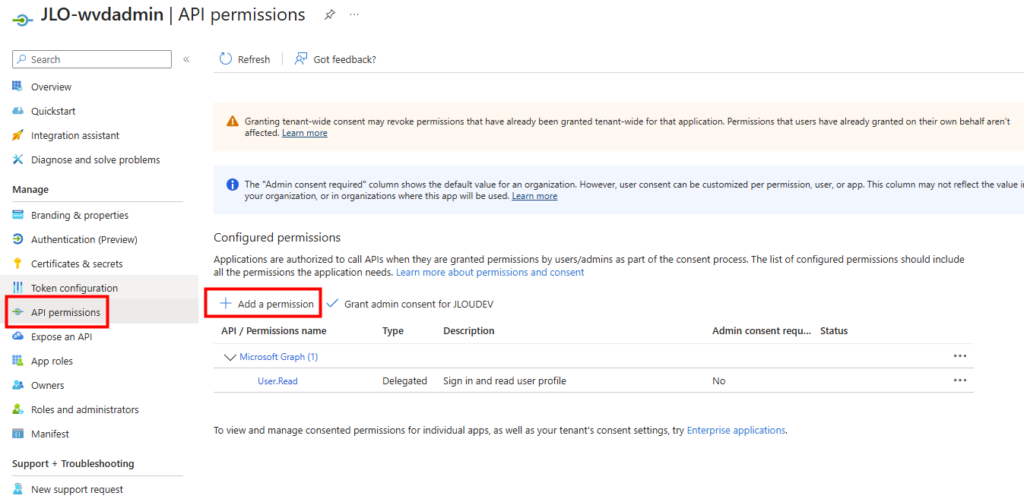
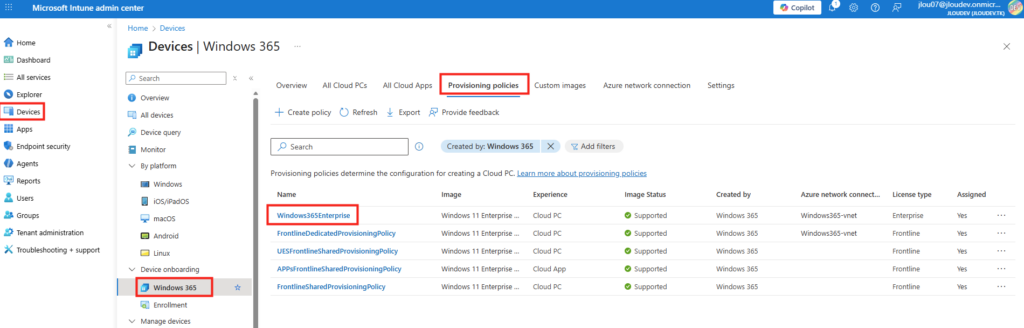
Cliquez sur WVDAdmin présent dans dans le menu Démarrer :
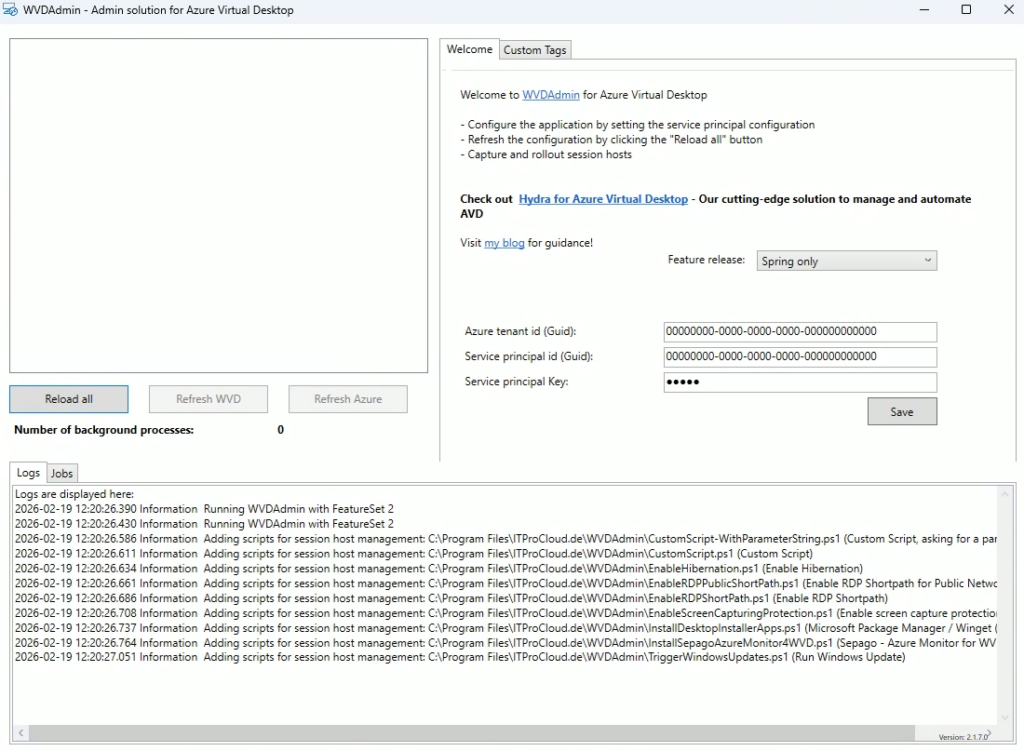
WVDAdmin se charge et n’affiche pour le moment aucune ressource ou information de l’environnement Azure :
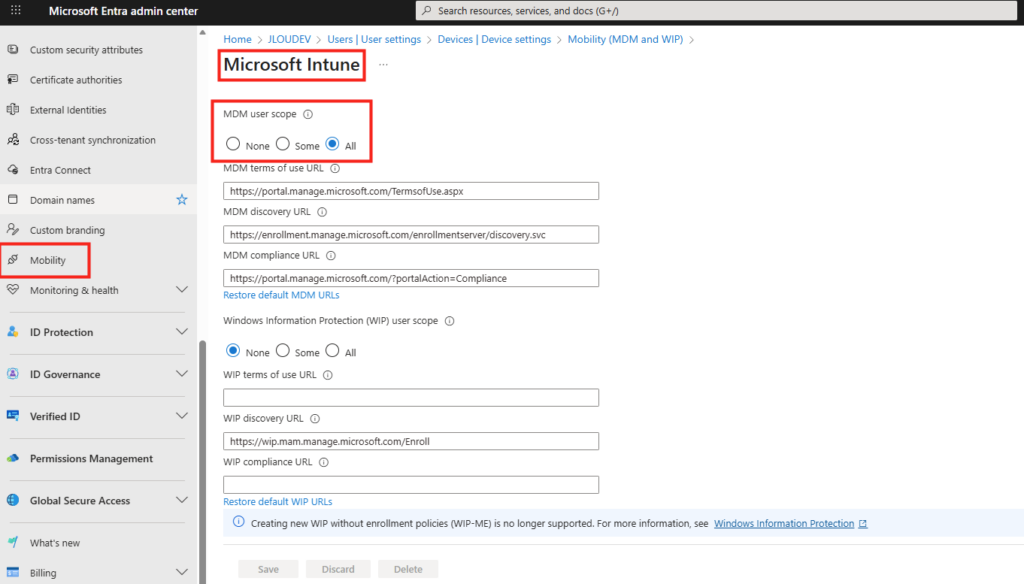
Pour cela WVDInfra vous demande les informations suivantes sur l’onglet « Welcome » :
l’ID de tenant
le secret client
l’ID client du principal de service
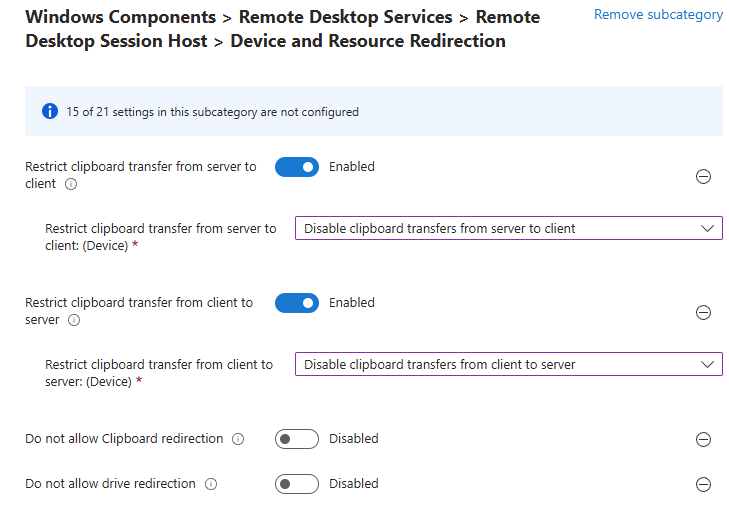
Mais avant d’aller plus loin, il est nécessaire de configurer ce nouveau principal de service sur votre tenant afin de donner à WVDInfra un moyen de s’y authentifier :
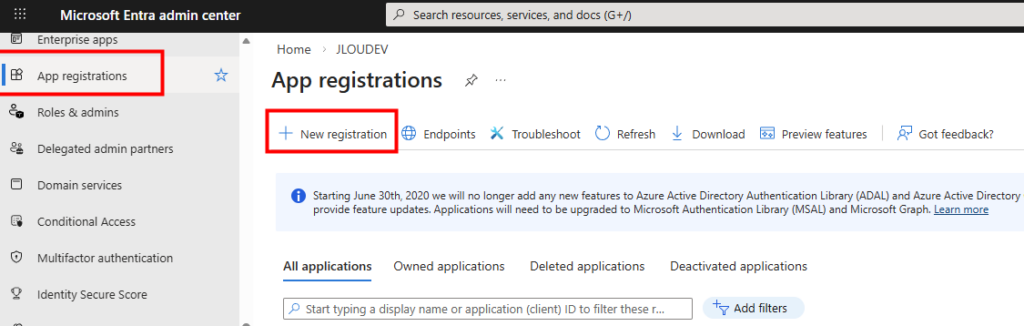
Etape II – Configuration Entra :
La création du principal de service via le centre d’administration Entra :
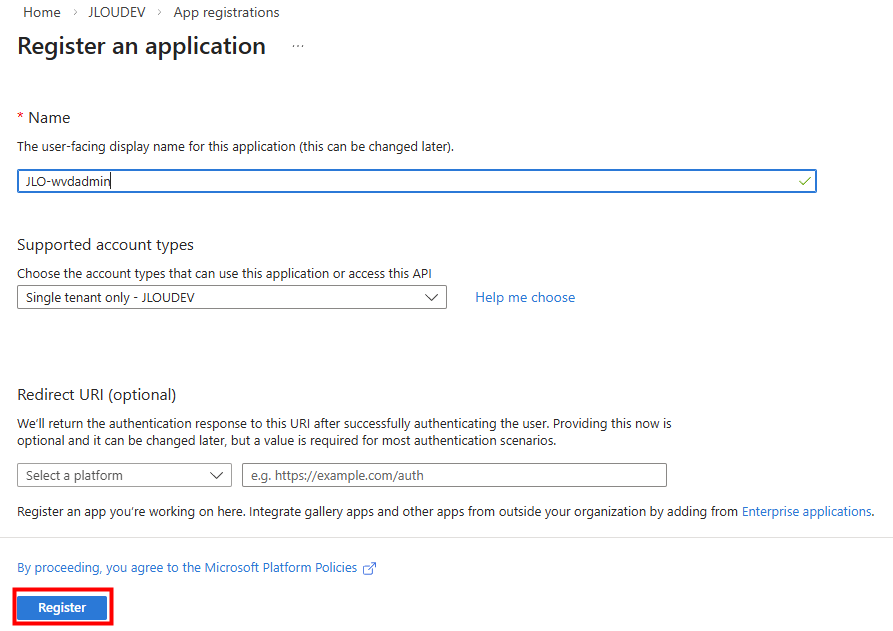
Nommez votre application, puis cliquez ici :
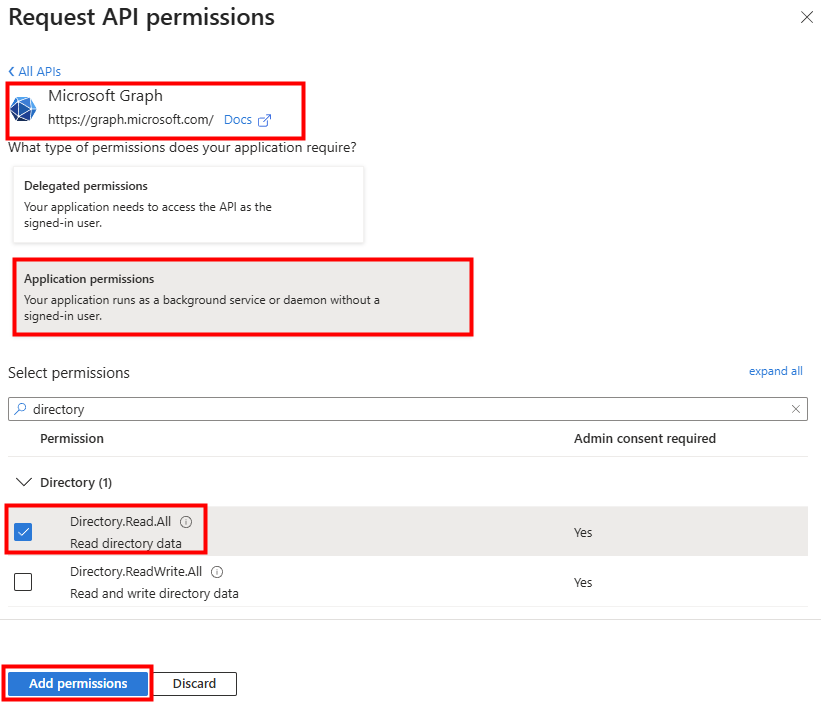
Pour permettre la résolution des utilisateurs et groupes, des permissions doivent être rajoutées :
Cherchez la permission suivante, puis cliquez sur Ajouter :
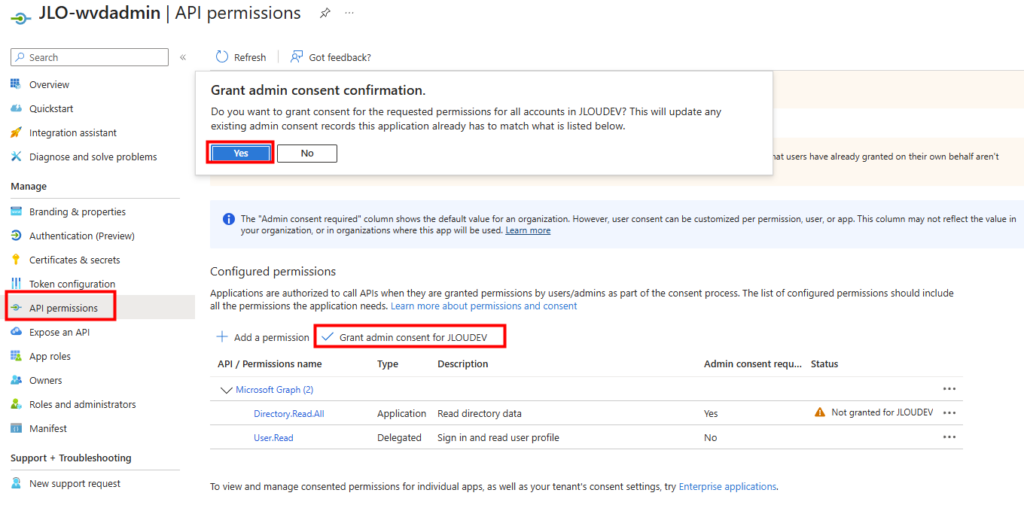
WVDInfra a besoin d’un consentement administration afin d’accorder les permissions demandées au nom de toute l’organisation :
Vérifiez le changement de statut des permissions :
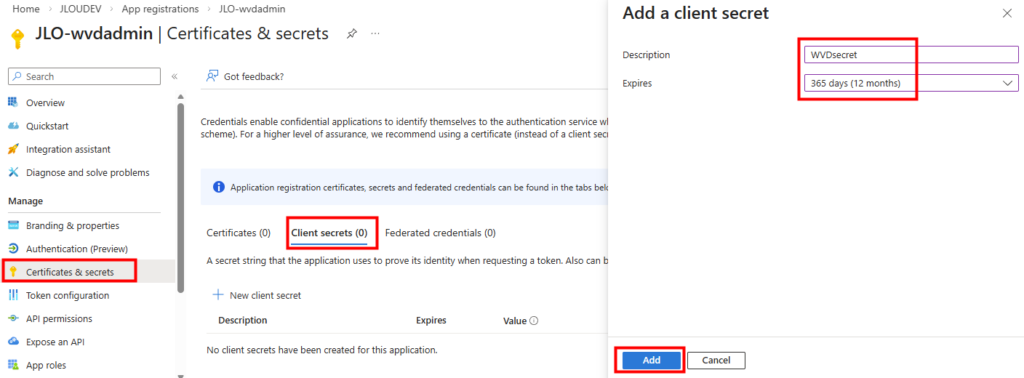
Le client secret est l’équivalent d’un mot de passe pour l’application. Il sert à authentifier l’application lorsqu’elle demande un token OAuth à Microsoft Entra ID. Ajoutez un secret à votre application WVDInfra :
Copiez la valeur de votre secret immédiatement lors de sa création, car il ne sera plus affiché par la suite :
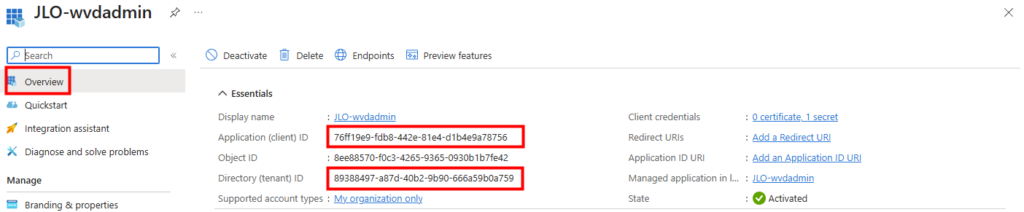
L’ID d’application (client) et l’ID du tenant doivent être conservés pour la suite :
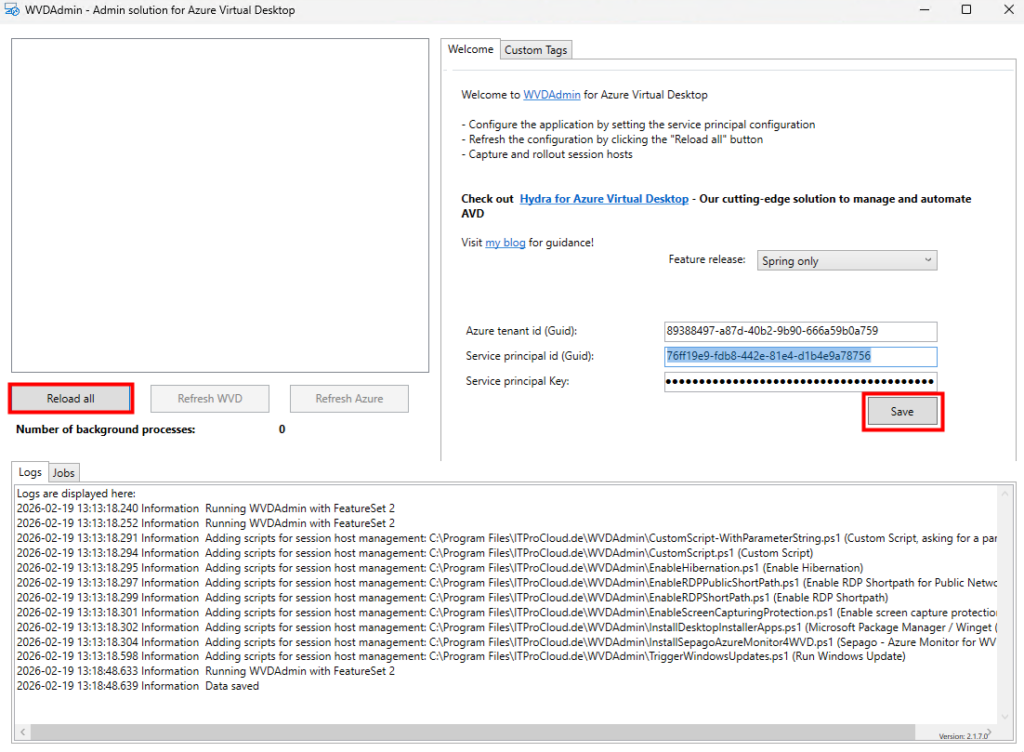
Collez ces trois valeurs dans l’interface de WVDInfra, sauvegardez, puis lancez un rechargement de l’inventaire :
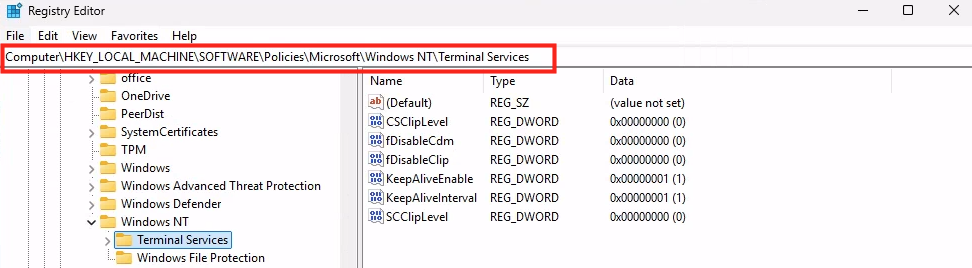
A ce stade, WVDInfra a bien accès au tenant mais pas encore au ressource Azure :
En l’état, l’application WVDInfra a le service principal, avec qui il peut s’authentifier avec son client ID et son secret, mais n’a par défaut aucun droit sur les ressources Azure. Il peut demander un token, mais ce token ne lui permet rien tant qu’on ne lui attribue pas un rôle RBAC.
Etape III – Configuration Azure :
WVD infra doit modifier des ressources Azure. Et attribuer un rôle RBAC au service principal WVDInfra revient à dire : “Cette application a le droit de faire telle action, sur tel périmètre.”
Pour cela, configurez avec le rôle RBAC de Contributeur sur l’application WVDInfra :
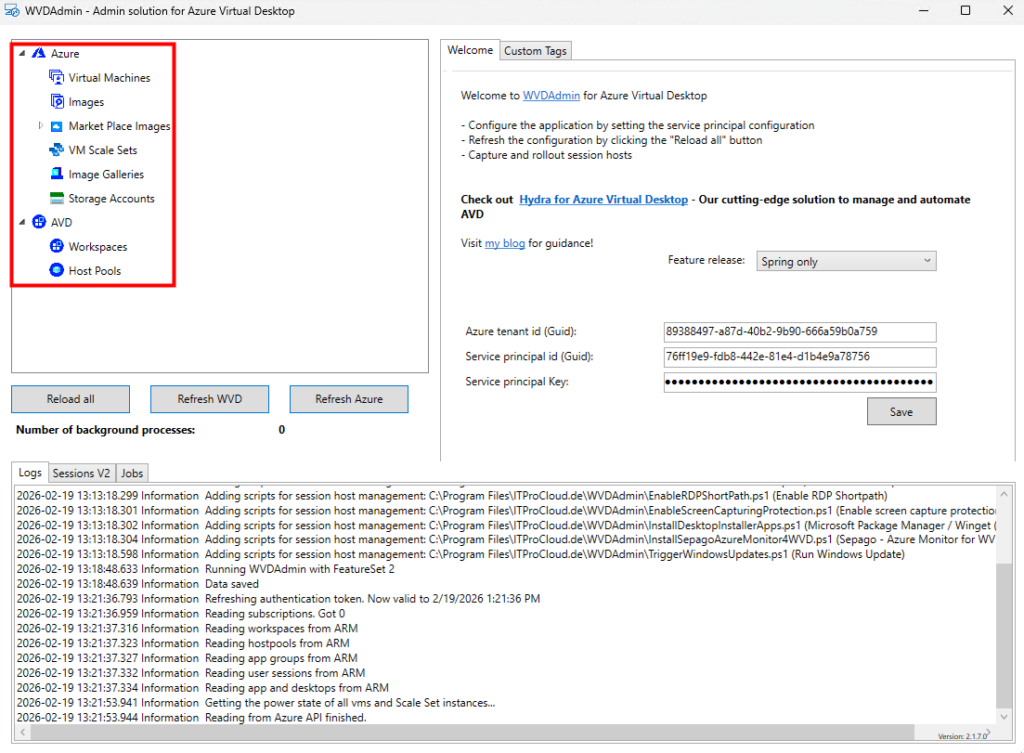
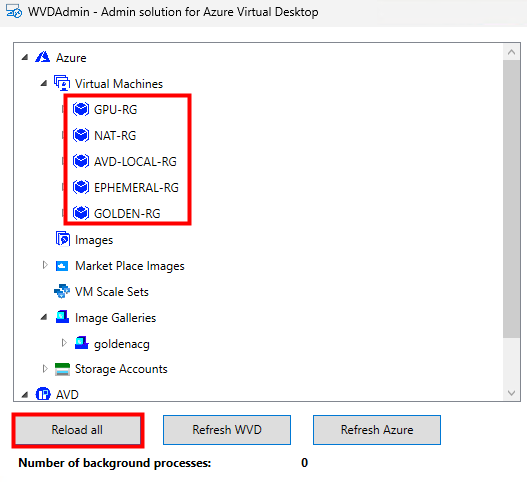
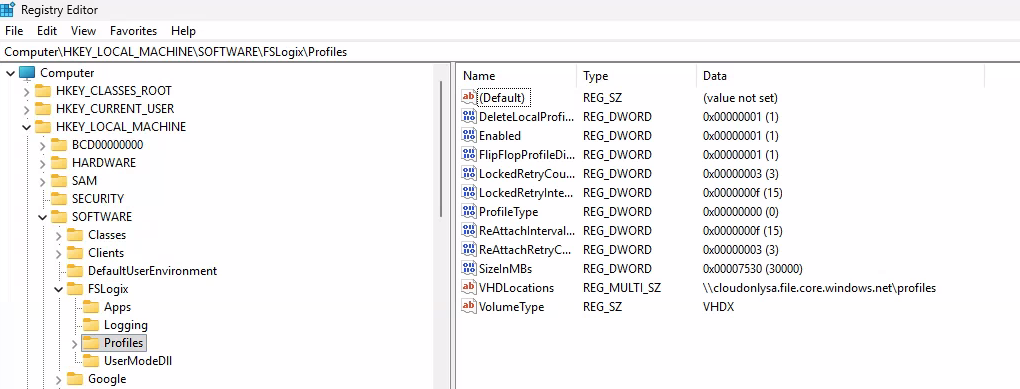
Sur WVDInfra, relancez un rechargement afin de voir apparaître l’inventaire des groupes de ressources et des VMs :
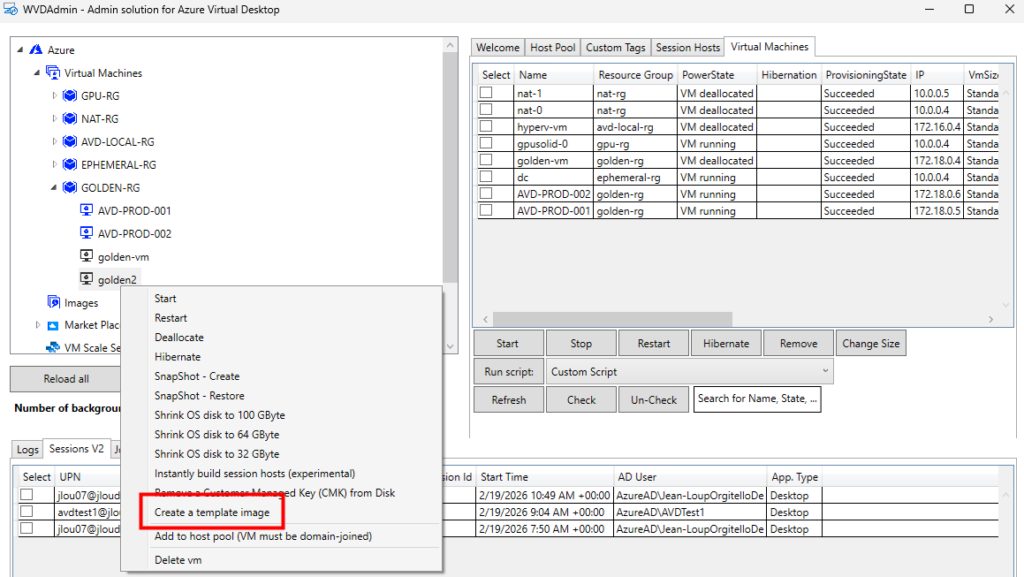
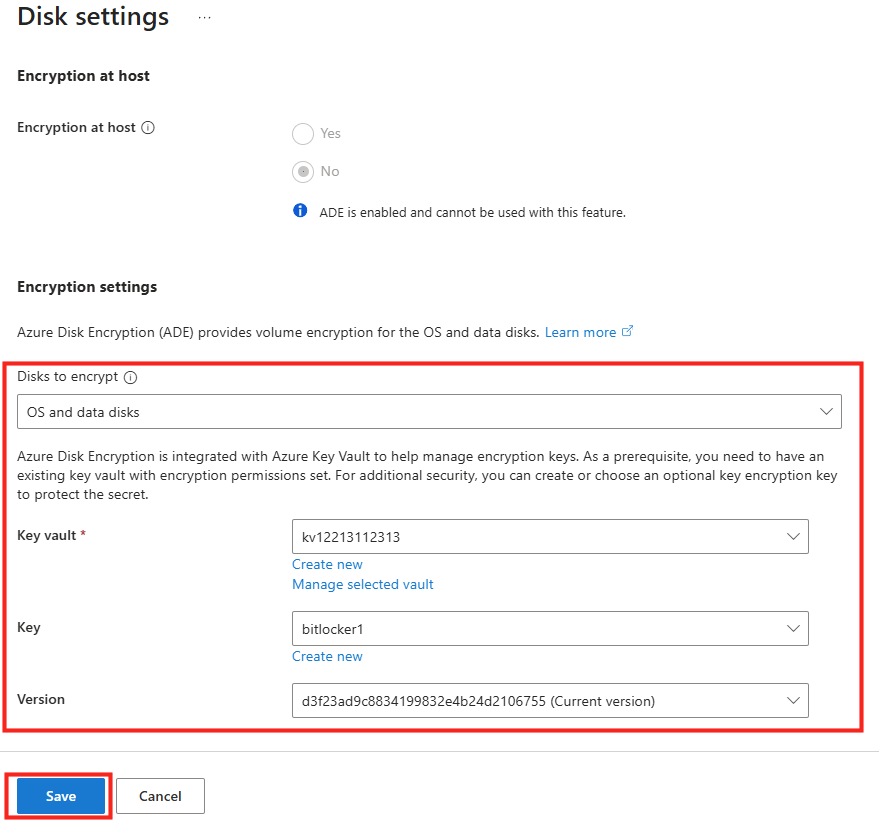
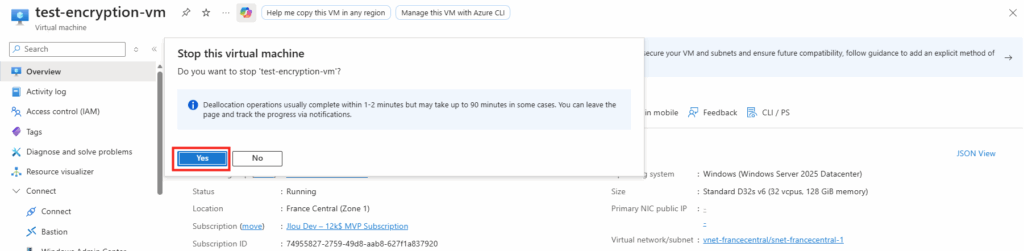
Etape IV – Test de capture d’une VM :
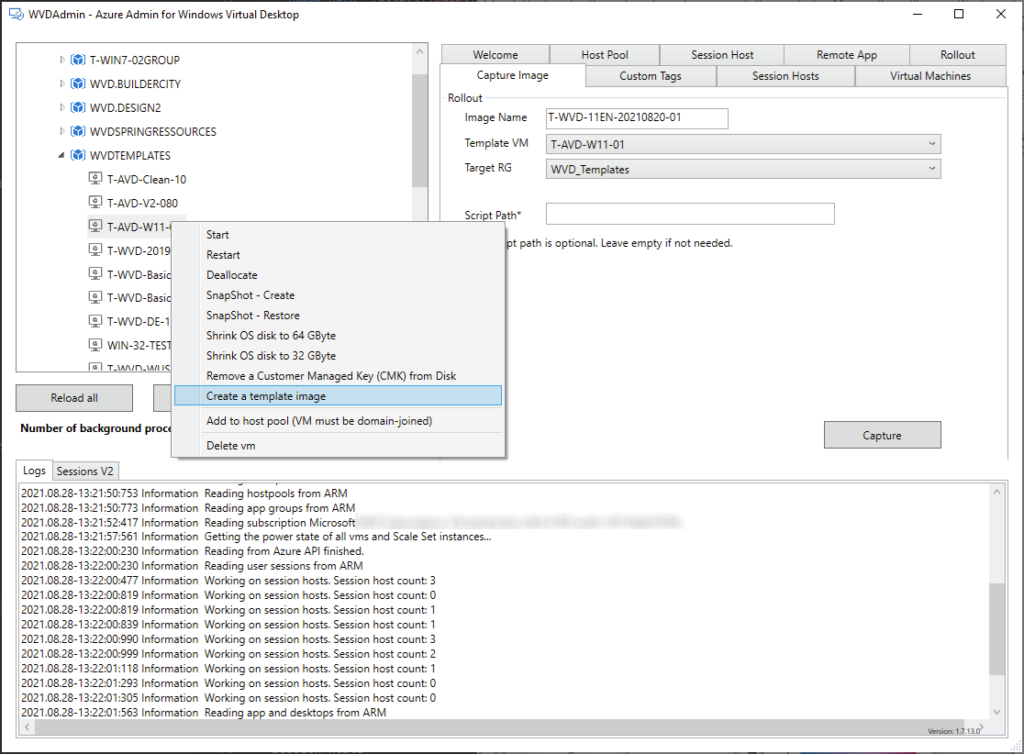
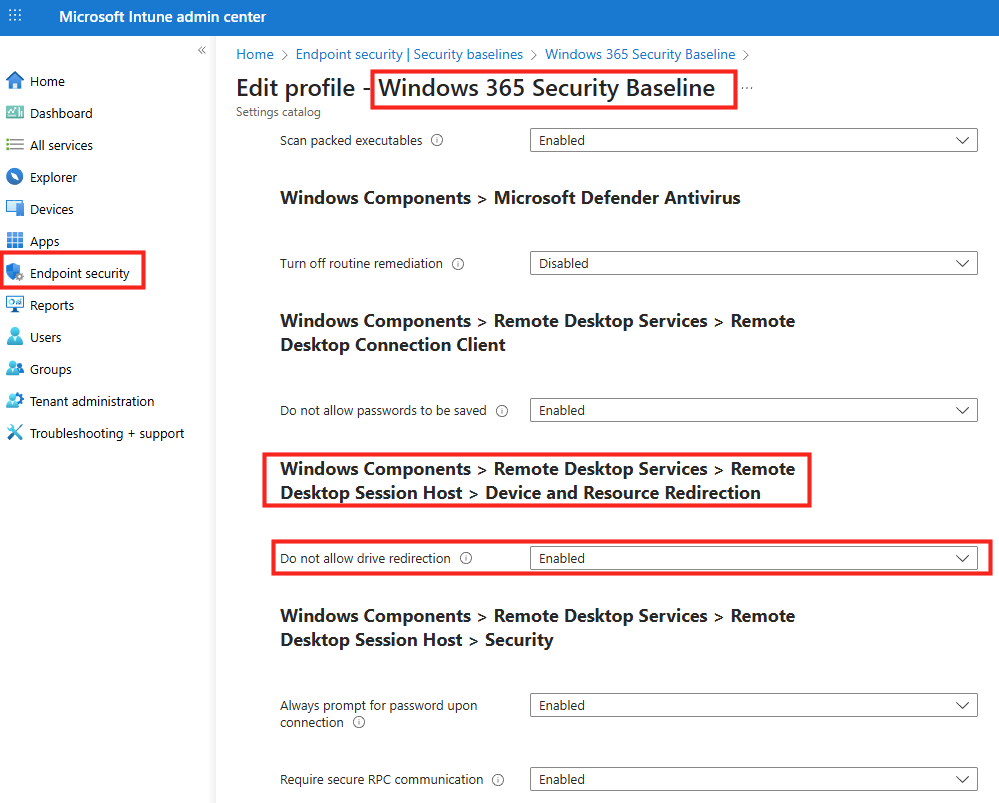
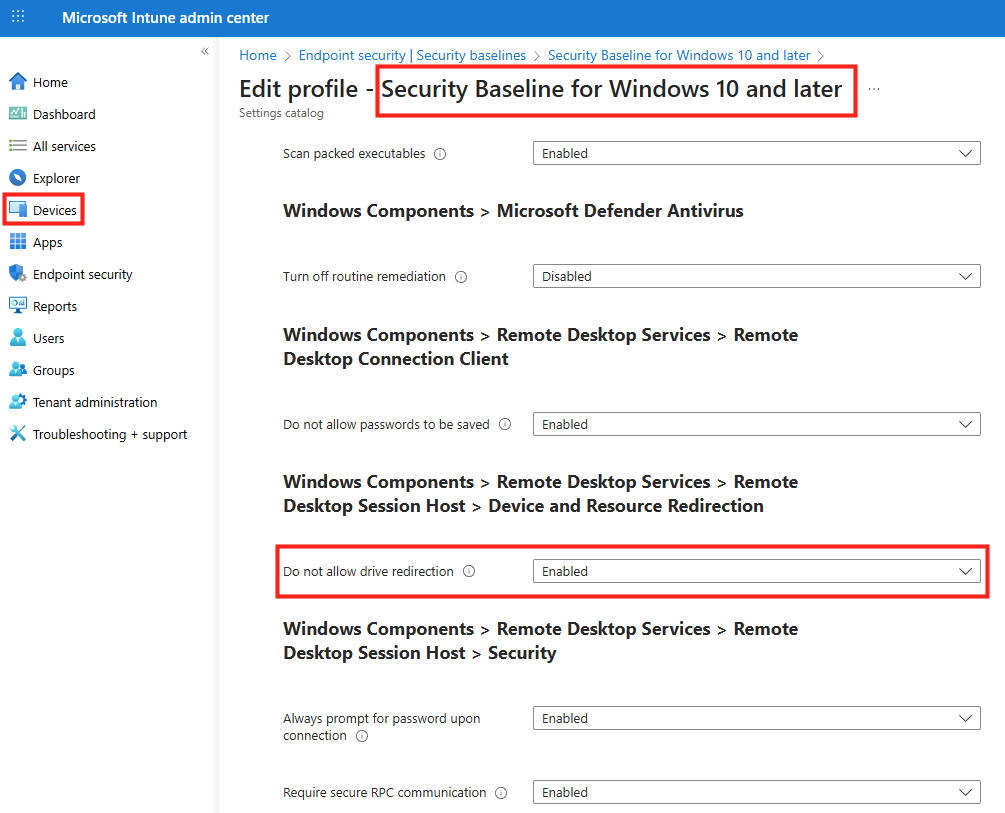
Microsoft recommande que tous les hôtes de session d’un pool soient issus de la même image afin de garantir une expérience utilisateur cohérente. WVDAdmin positionne l’imagerie comme une fonctionnalité centrale : création d’images à partir d’un golden master sans détruire la VM source.
Créez une machine virtuelle Azure :
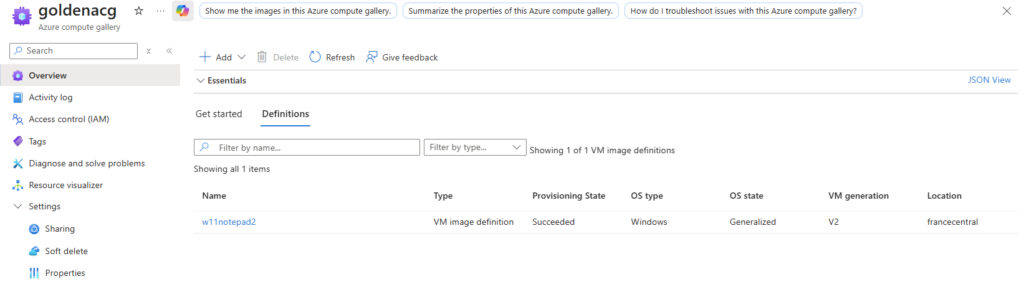
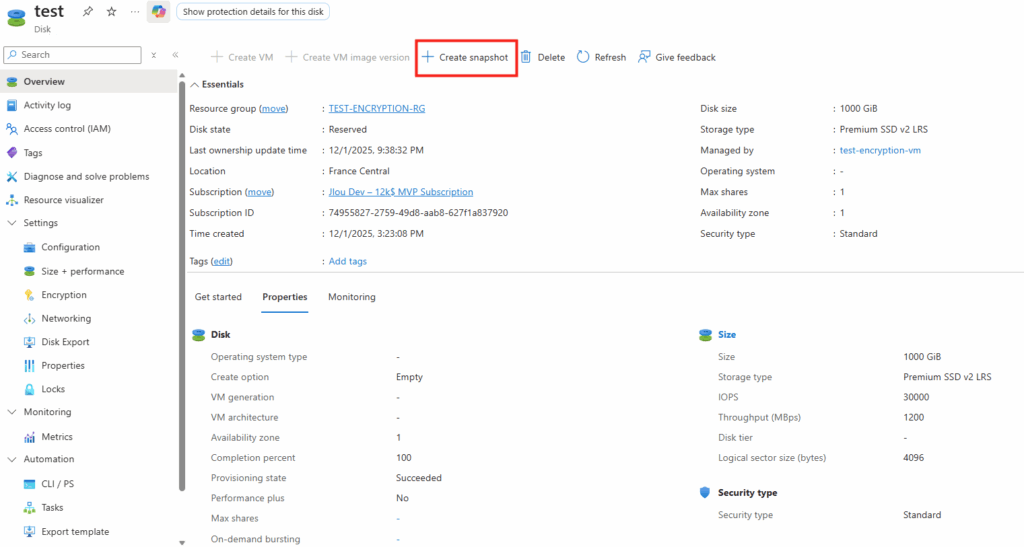
Créez également une galerie d’images :
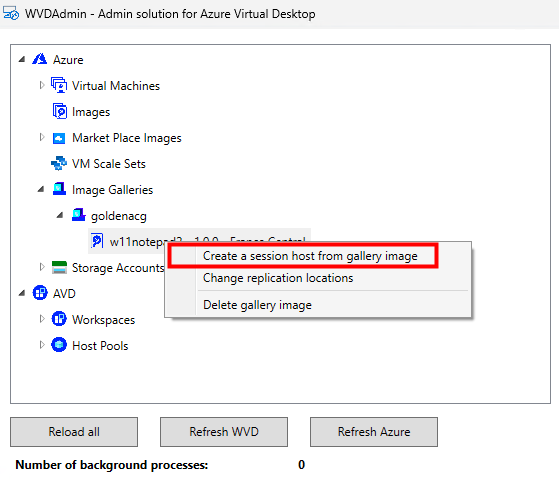
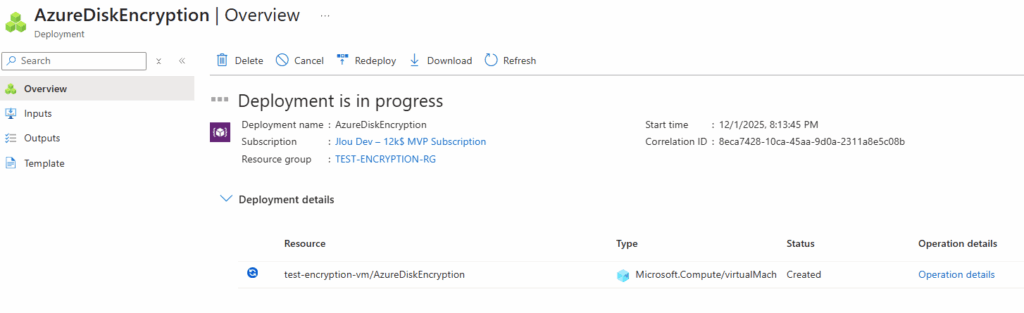
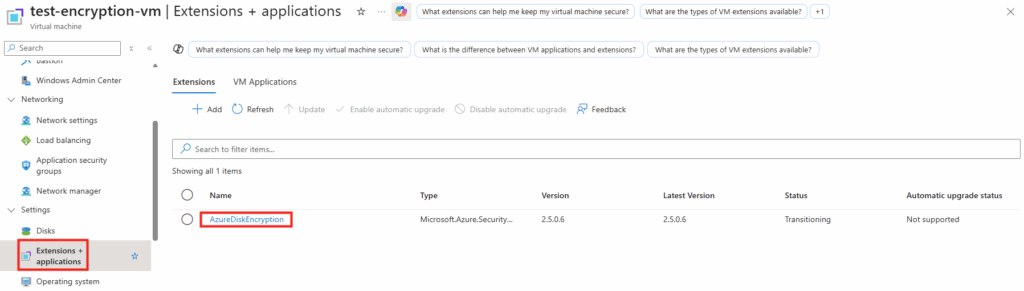
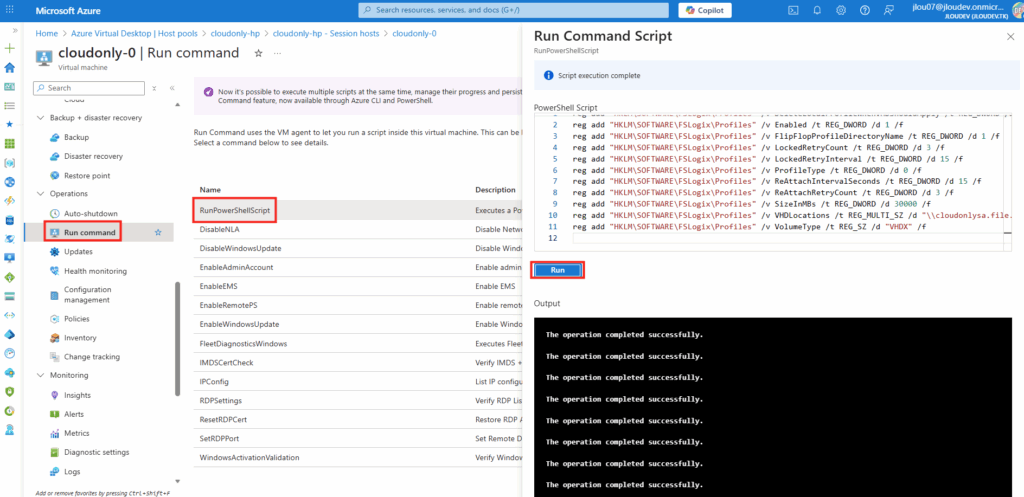
Sur WVDInfra, lancez la création d’image depuis votre machine virtuelle :
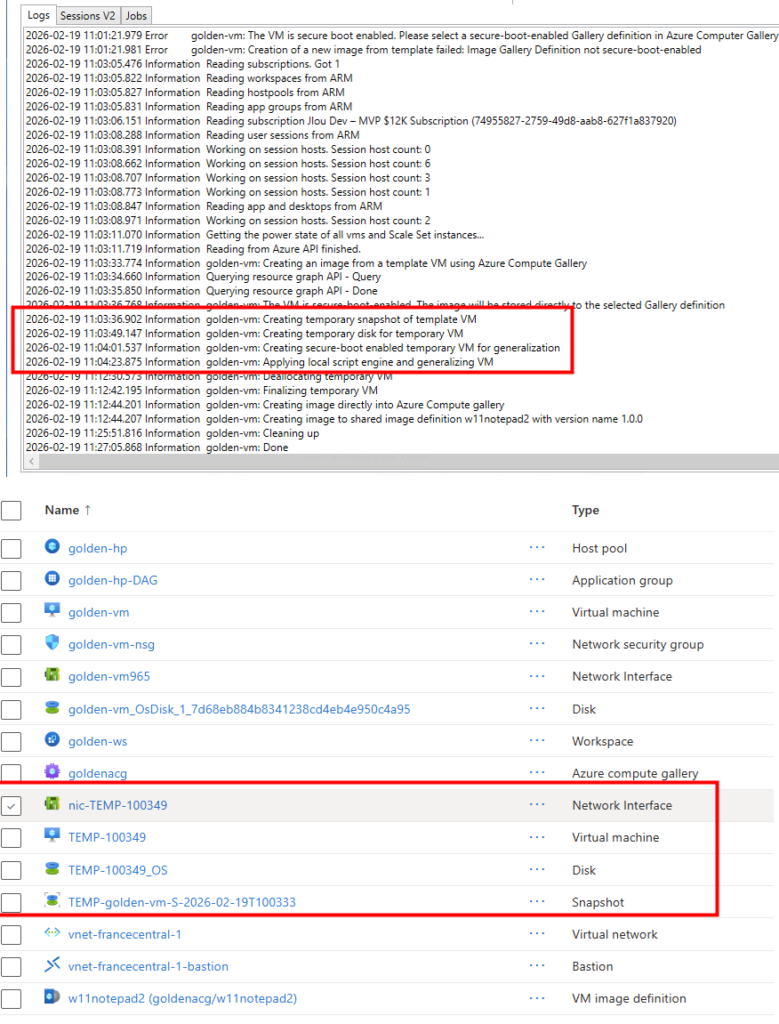
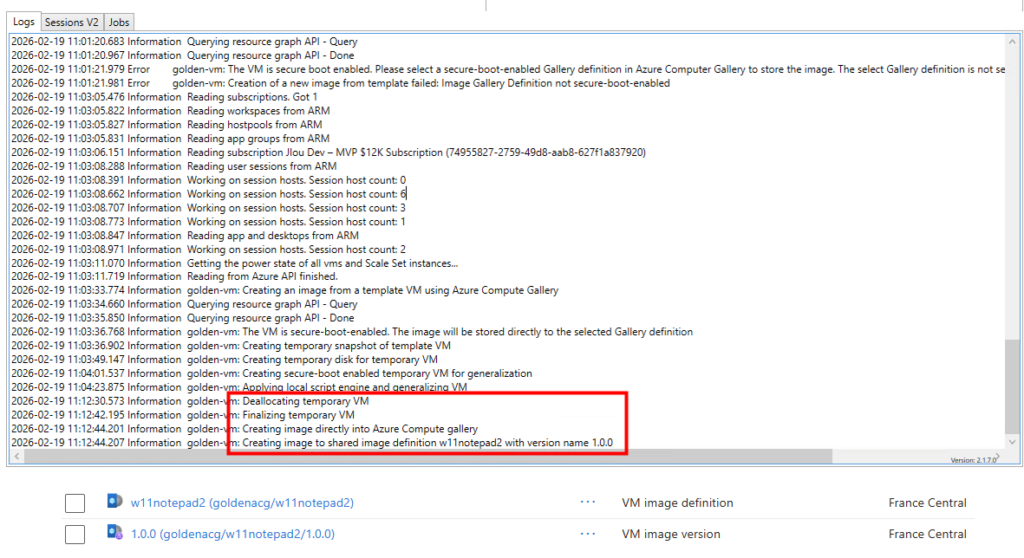
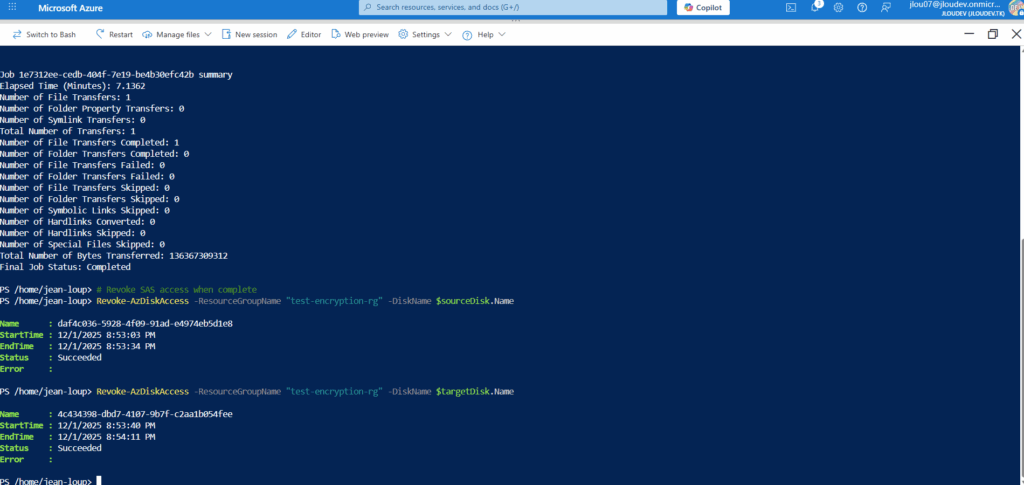
Les journaux de WVDInfra commence par montrer la création de ressources Azure temporaires (snapshot, VM temporaire, disque temporaire) :
Par la suite, les journaux de WVDInfra montre la généralisation de l’image, la création de la version dans la galerie :
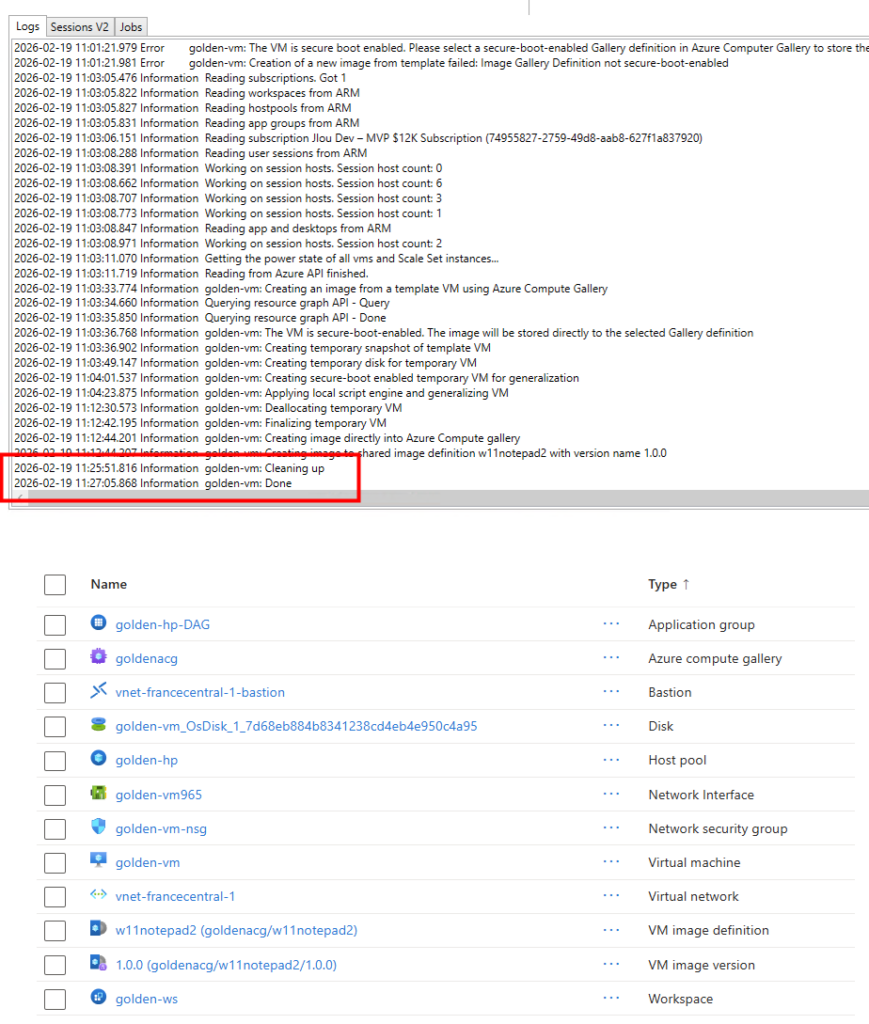
Enfin, les journaux de WVDInfra montre le nettoyage complet des ressources Azure temporaires :
En quelques clics, nous avons une image prête à être déployée sur votre environnement Azure Virtual Desktop. La suite des étapes se fait toujours dans WVDInfra.
Etape V – Test de création d’un hôte :
Avant cela, créez les objets AVD de base (pools d’hôtes, groupes d’applications, espaces de travail) :
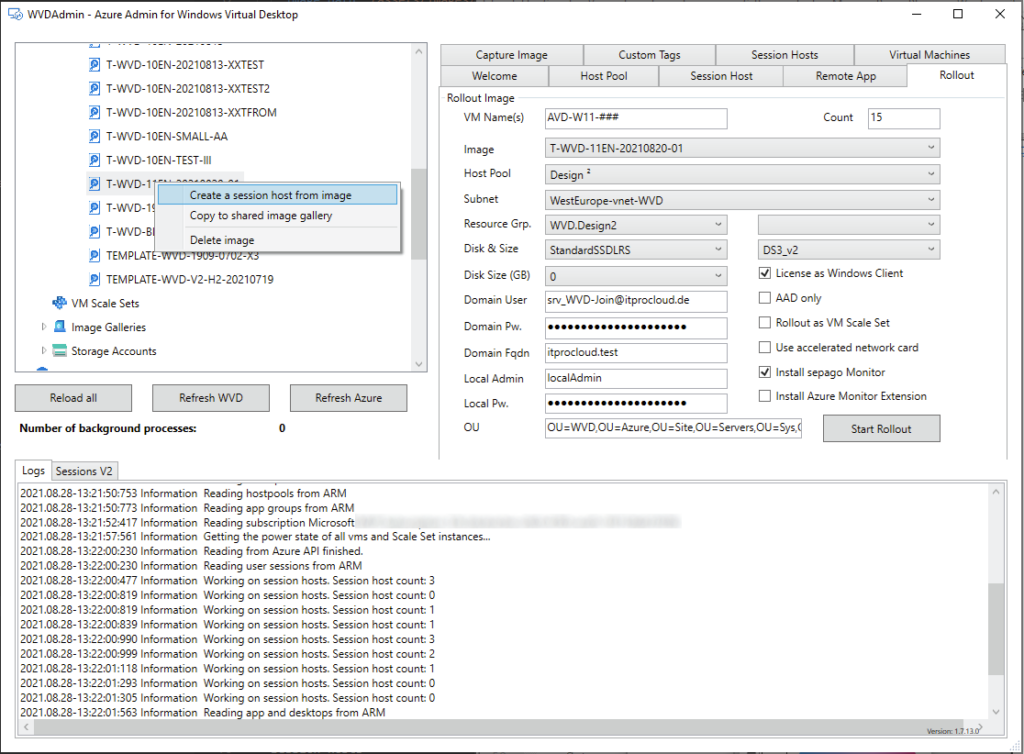
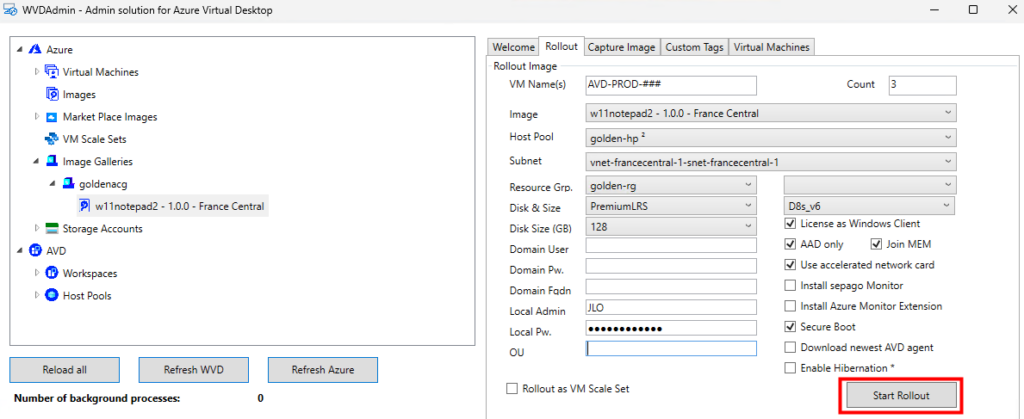
Retournez sur WVDInfra, sélectionnez la version d’image, puis lancez le processus de création d’hôtes AVD :
Renseignez le formulaire de déploiement :
le nommage des VM,
le nombre d’hôtes,
la version d’image,
le pool d’hôtes,
le sous-réseau,
les paramètres de disque,
la taille des VM,
les options de jointure Entra / Intune.
Puis lancez la création des machines virtuelle AVD :
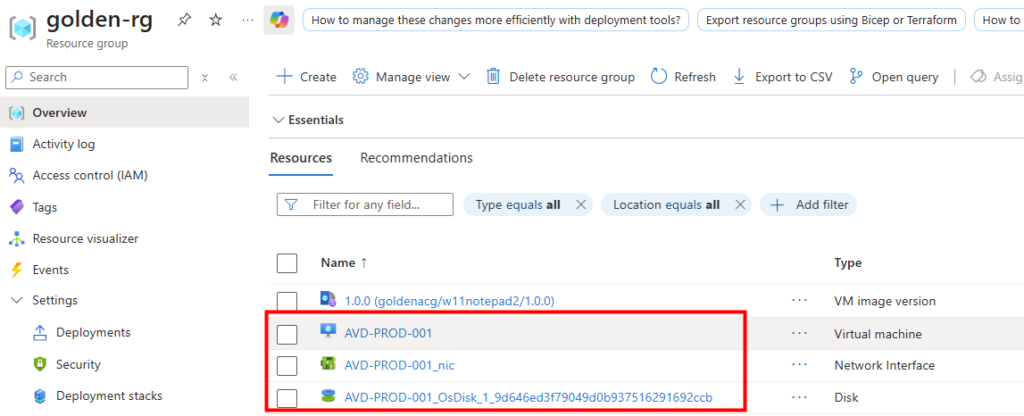
Les journaux confirment la création de la VM et de son intégration au pool d’hôtes :
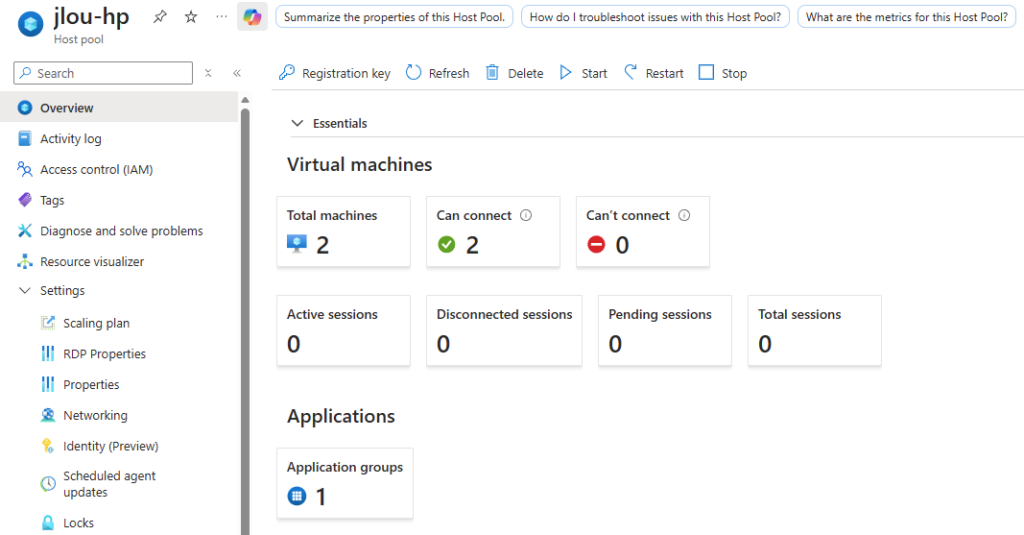
Constatez sur le portail Azure la création de ressources :
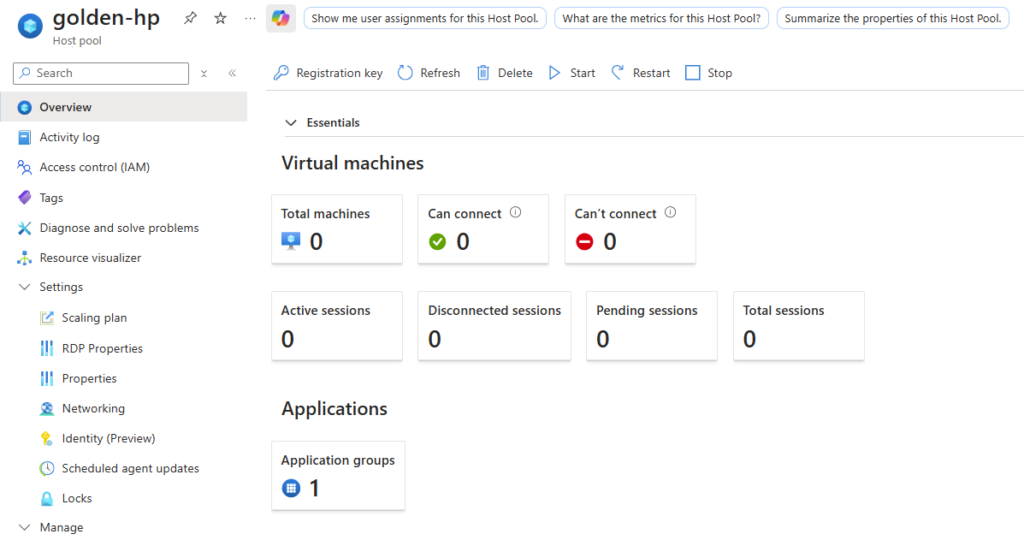
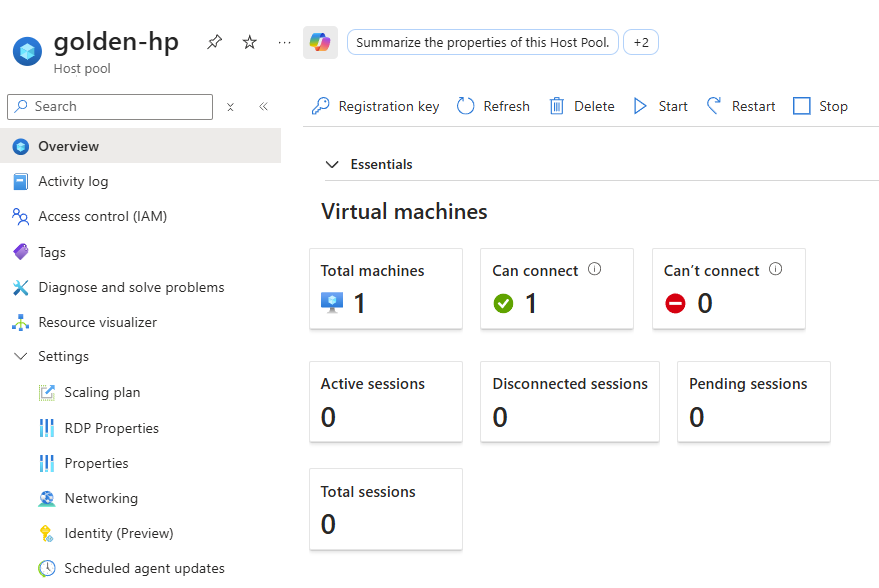
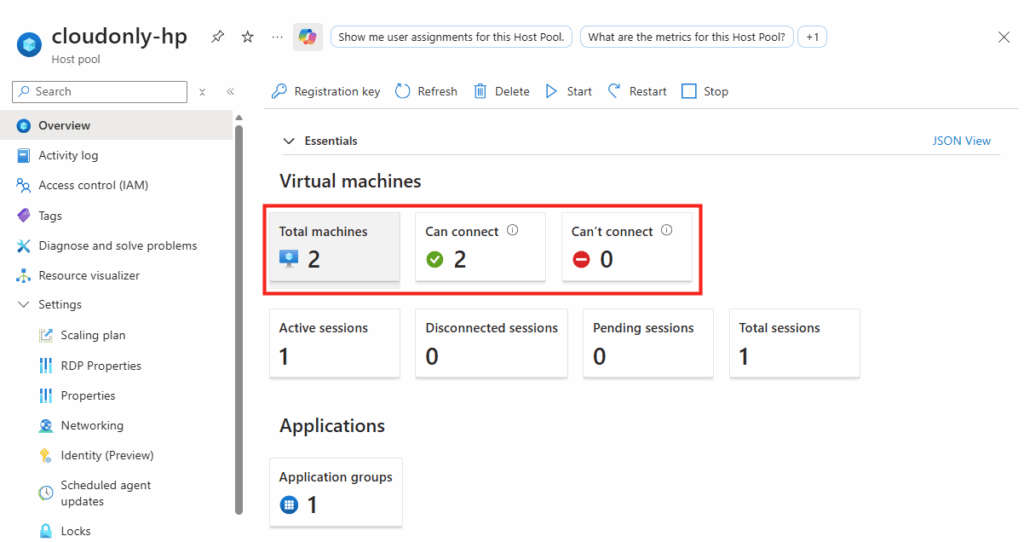
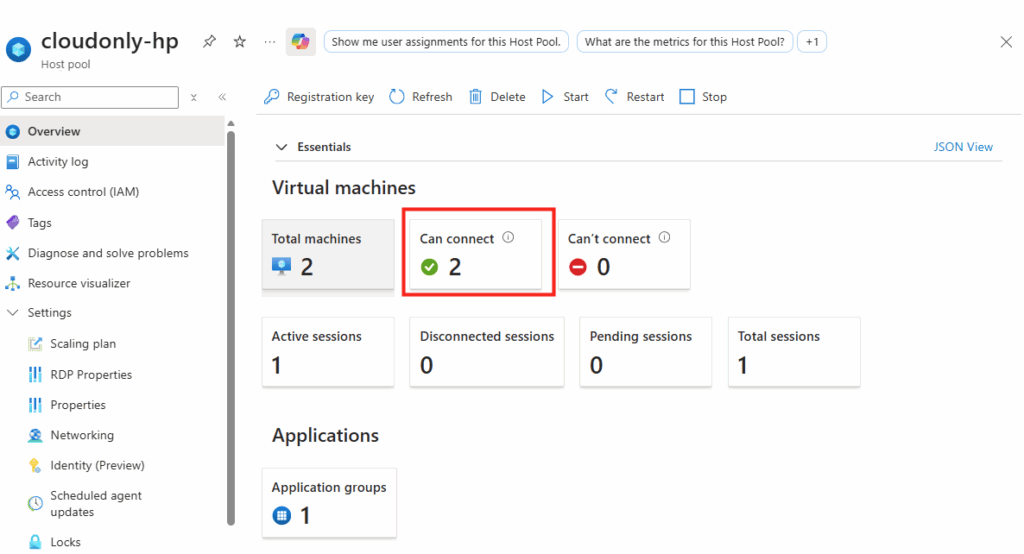
Votre pool d’hôtes affiche la nouvelle capacité disponible :
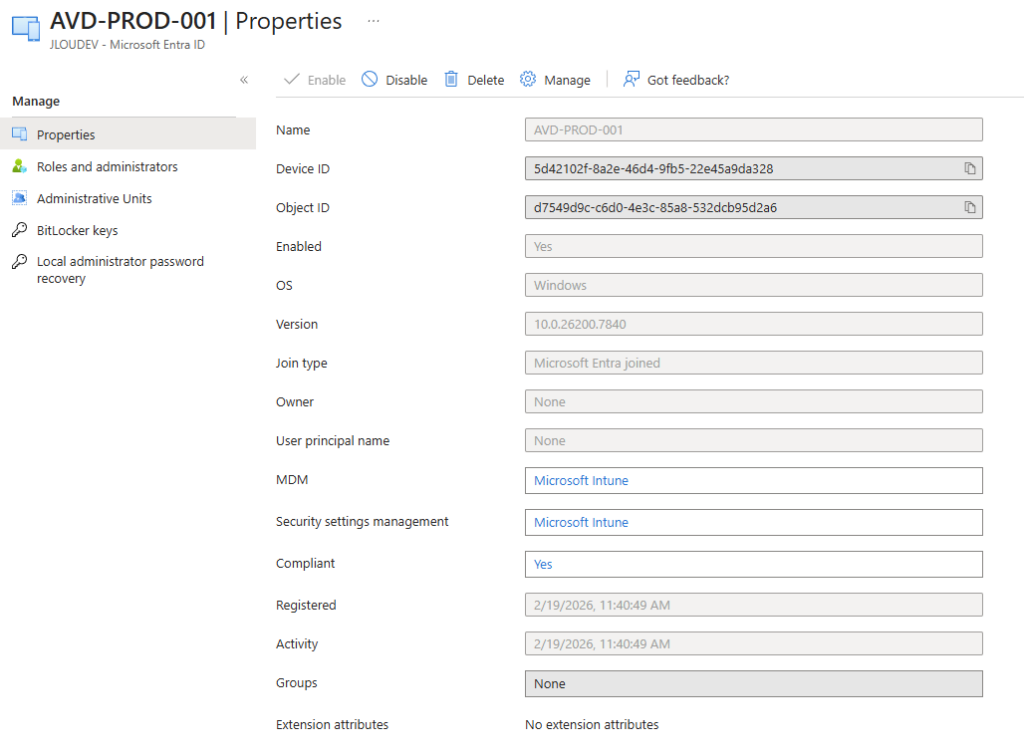
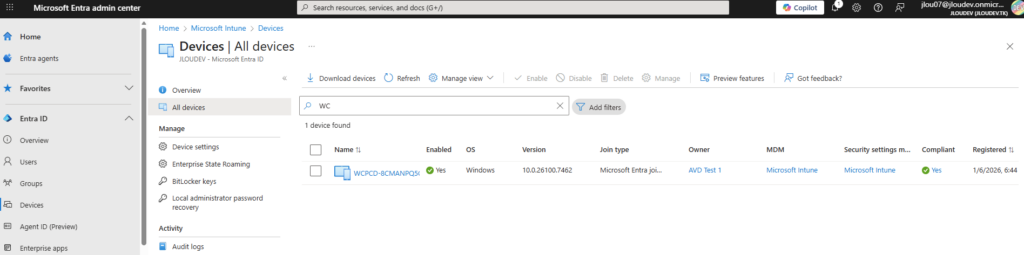
Dams mon cas, l’hôte de session apparait comme appareil joint à Entra ID :
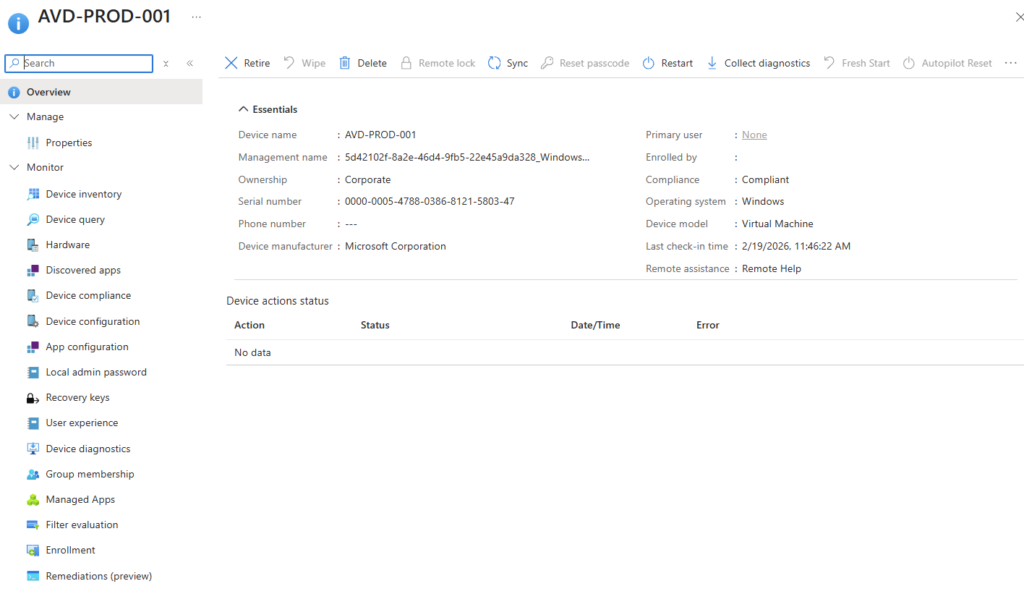
Cette hôte de session est également enrôlés dans Intune :
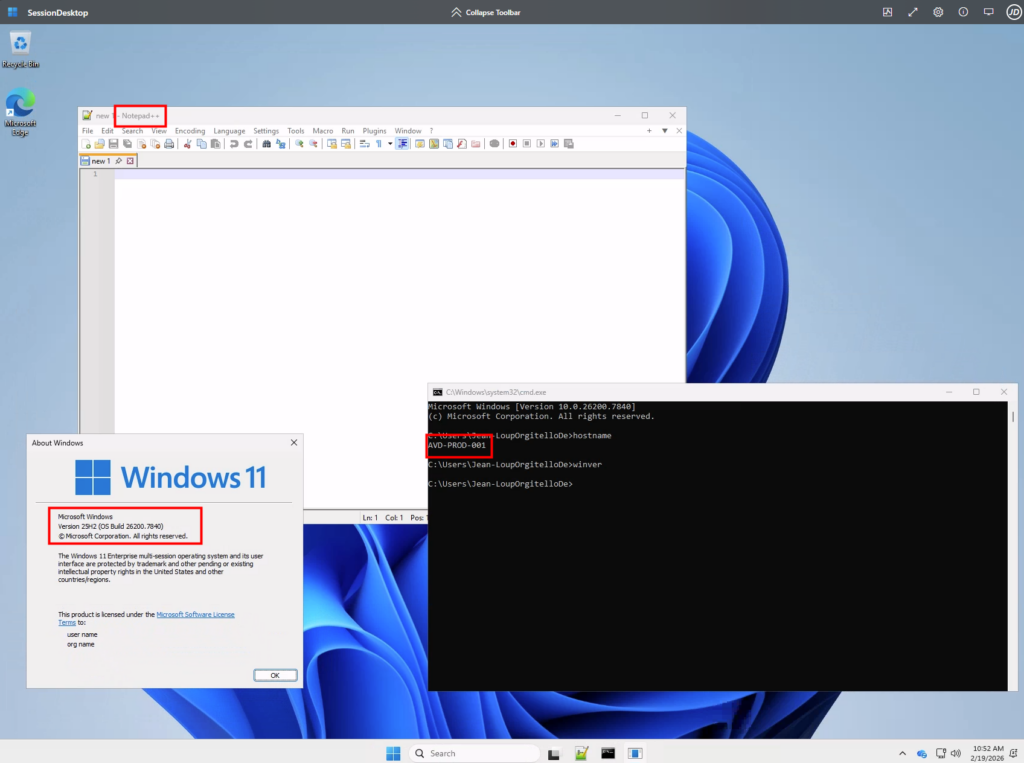
Un test en session (nom de machine, version de l’OS, application installée) valide le bon fonctionnement :
Etape VI – Fonctionnalités annexes :
WVDAdmin couvre également beaucoup d’opérations IT sur les machines virtuelles Azure :
démarrage, arrêt, redémarrage, hibernation
changement de taille de la VM
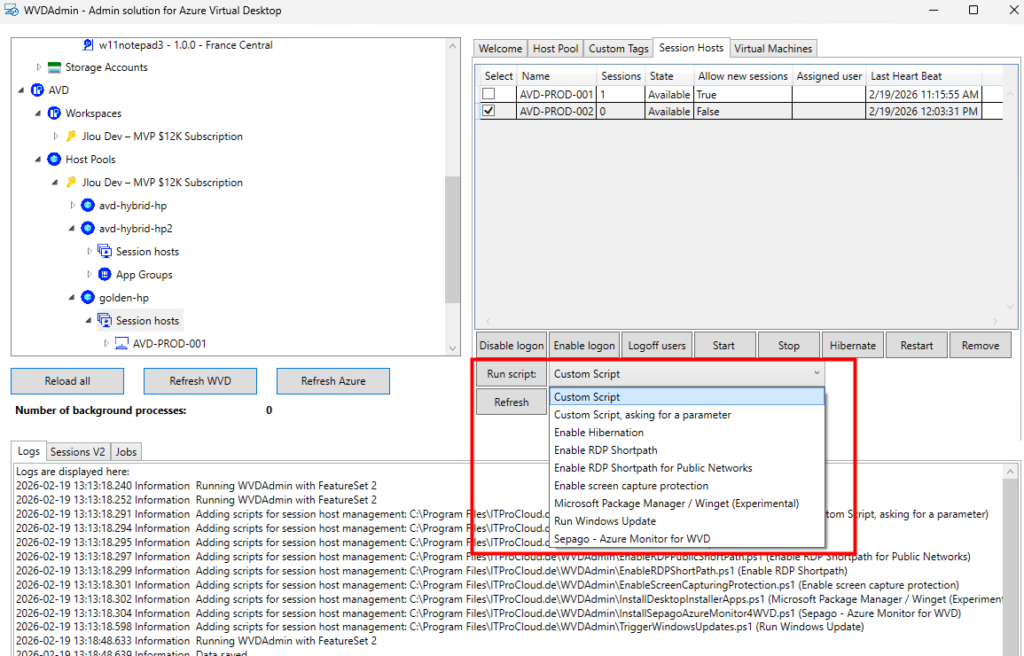
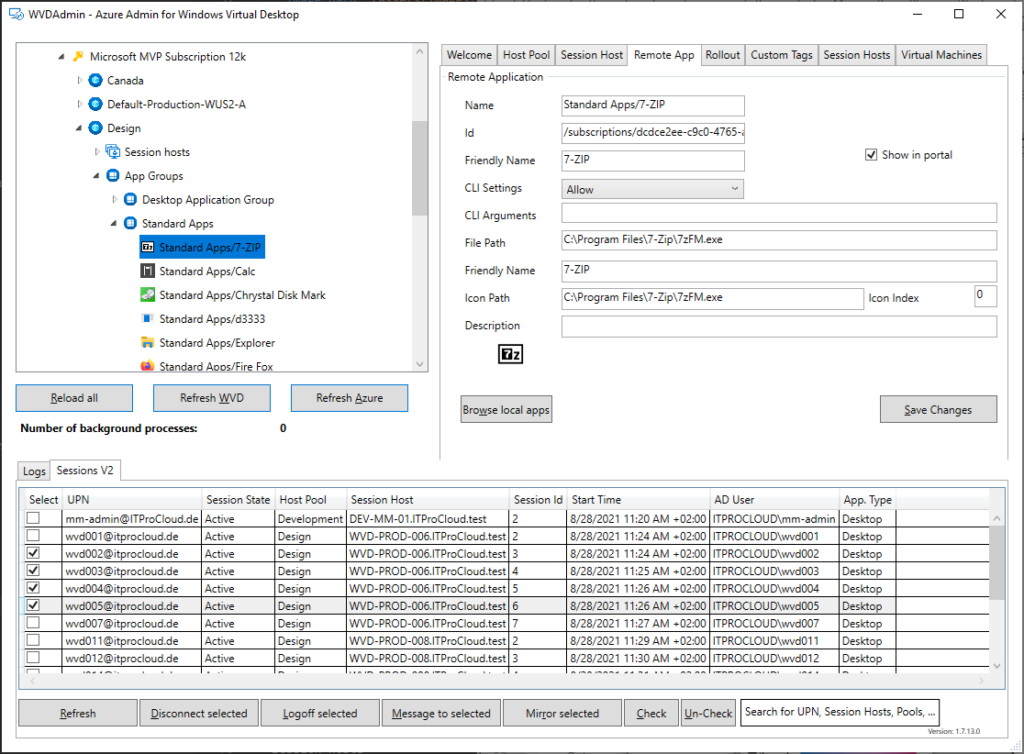
Certains actions particulières, comme l’exécution de scripts, sont possibles :
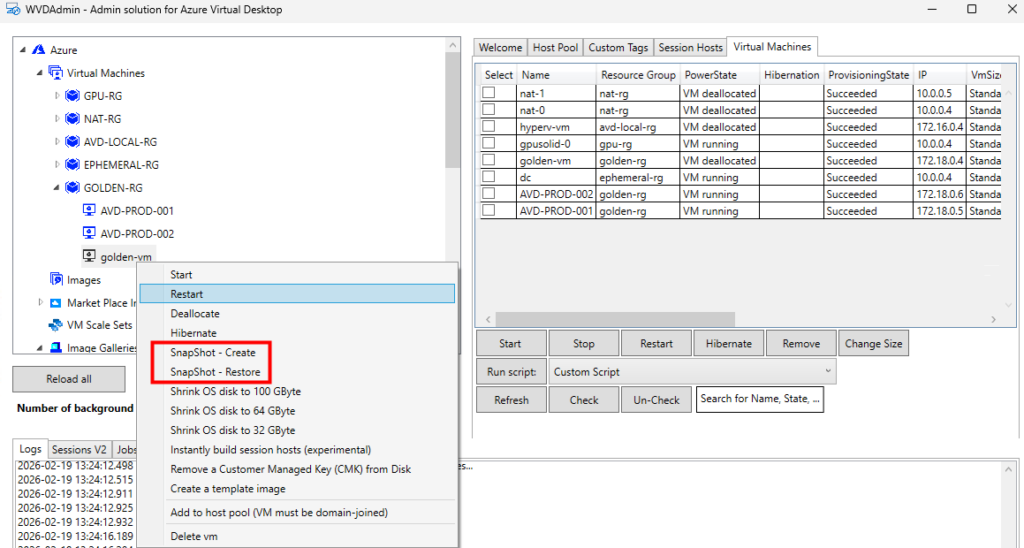
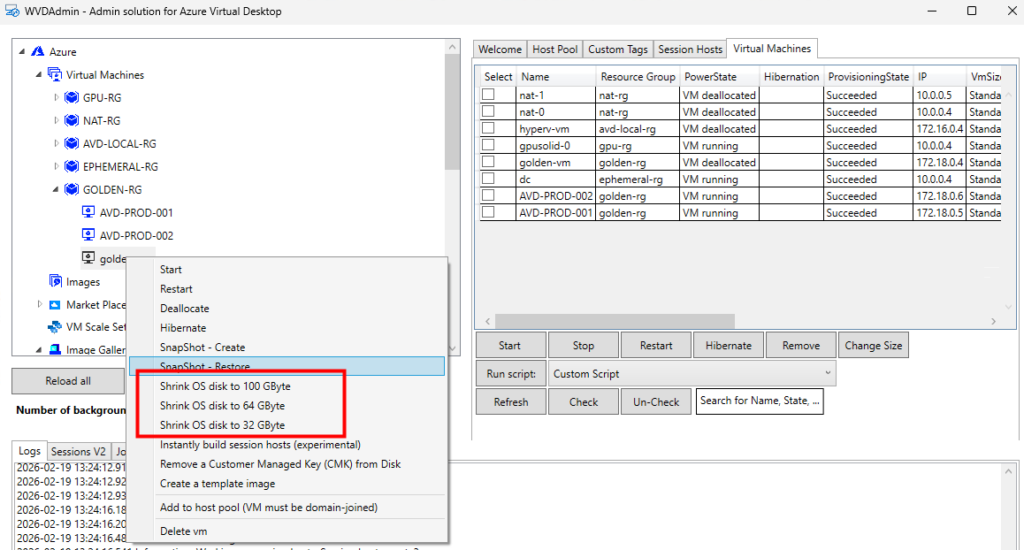
Ou encore la création de snapshot ou le redimensionnement de disque OS :
D’autres sont propres aux machines virtuelles AVD :
gestion du mode drain
actions sur les sessions
suppression complète de l’hôte
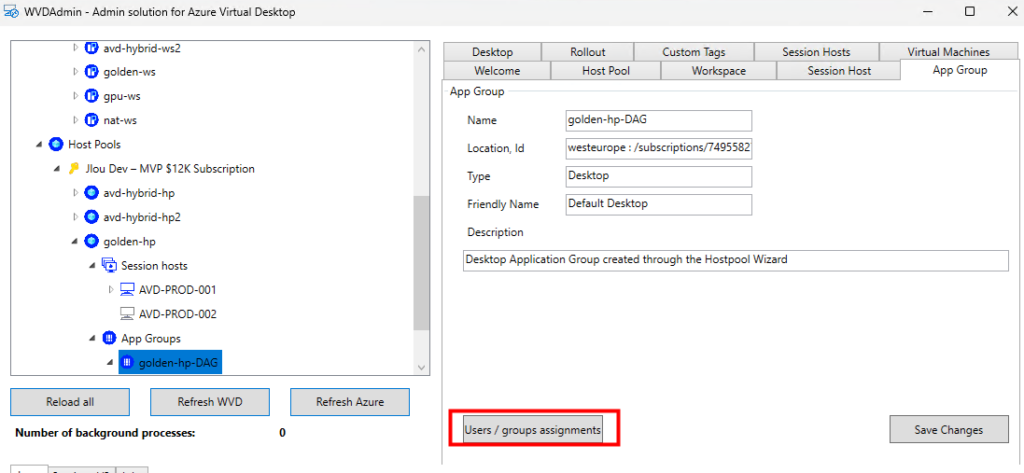
Il permet aussi de modifier les affectations se font au niveau des groupes d’applications :
La gestion des applications publiées aussi possible :
Mon avis personnel
Je vais être clair. WVDAdmin n’est pas un remplacement du portail d’Azure Virtual Desktop. Ce n’est pas non plus une solution d’architecture d’entreprise complète. C’est un accélérateur opérationnel.
Et dans certains un contextes, WVDAdmin est redoutablement efficace :
Lab
PoC
Environnement SMB
Client où l’on veut éviter de déployer une surcouche d’automatisation complète
Équipe IT réduite
La capture d’image est propre, le déploiement est rapide, L’interface centralise ce que le portail disperse. Besoin de plus ? Hydra for AVD sera peut être votre réponse.
Conclusion
Azure Virtual Desktop continue de se moderniser, les outils natifs progressent et l’automatisation devient centrale.
Mais entre la théorie et le terrain, il y a toujours l’opérationnel quotidien. WVDAdmin n’a jamais prétendu pas transformer votre architecture, mais il simplifie votre quotidien. Il évite les allers-retours dans le portail, réduit la friction et accélère les tâches répétitives.
Dans un monde où l’on parle beaucoup d’IA, d’automatisation avancée et de plateforme complexe, parfois un bon outil bien conçu fait simplement gagner du temps.
Et en tant qu’architecte AVD, je préfère toujours une solution claire, maîtrisée et comprise, plutôt qu’une sur-ingénierie inutile.
WVDAdmin ne remplace pas une stratégie, il optimise l’exécution. Et ça, pour un admin AVD, ça a énormément de valeur.
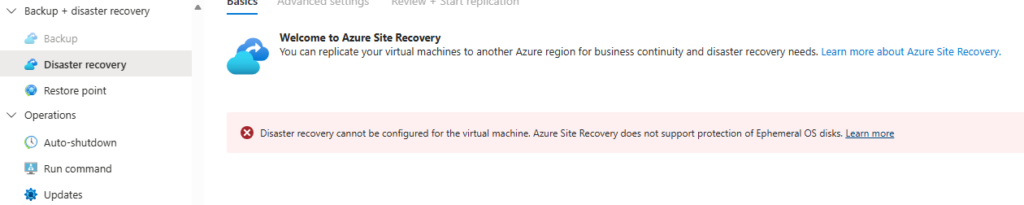
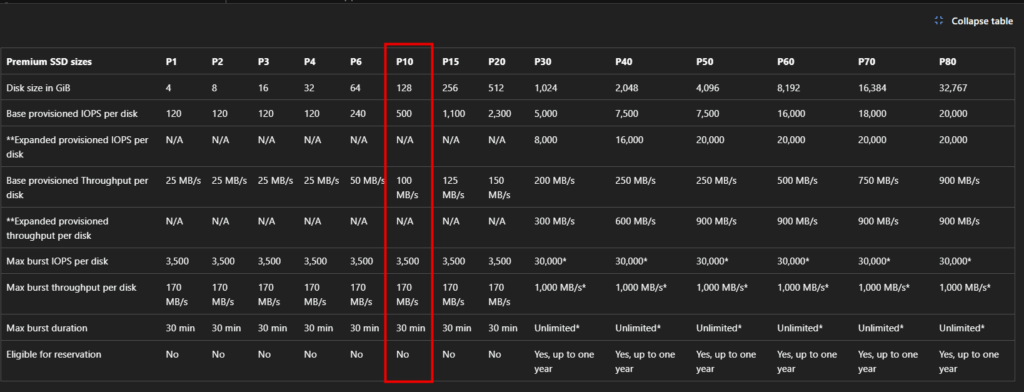
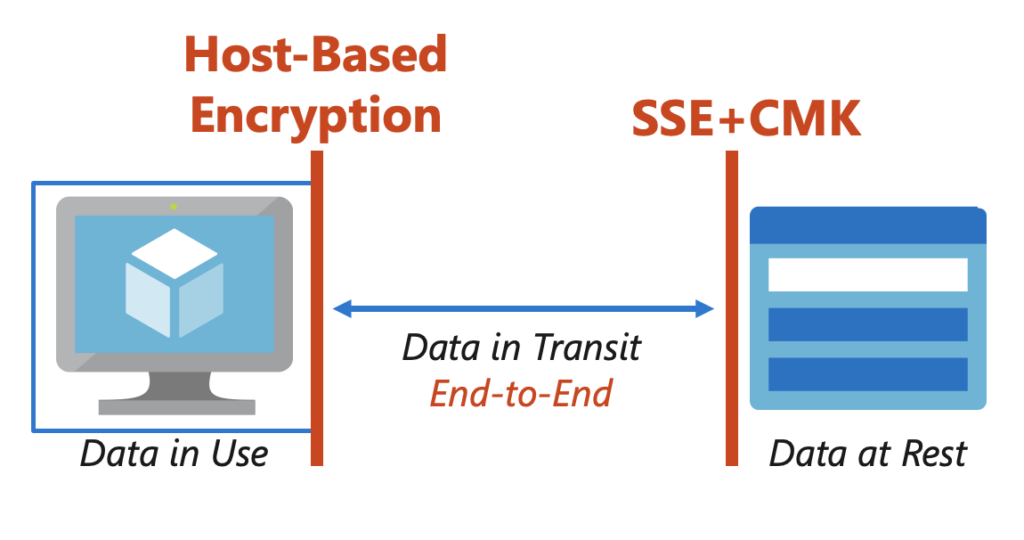
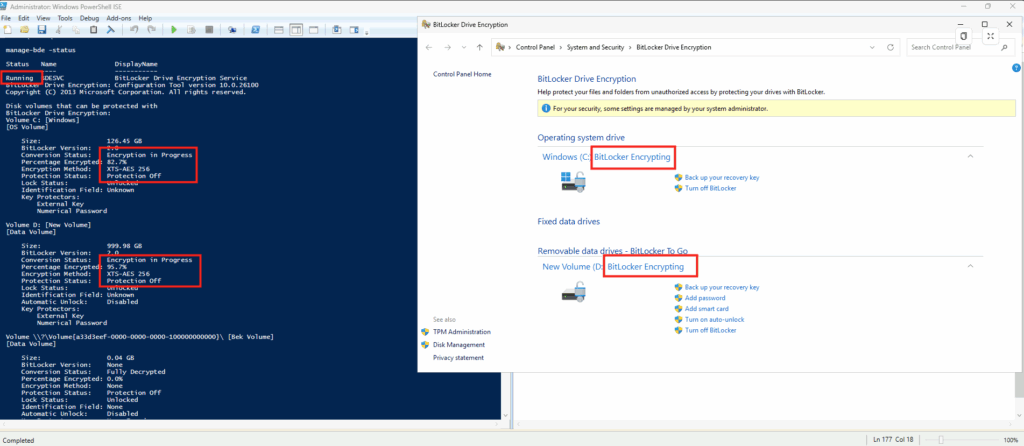
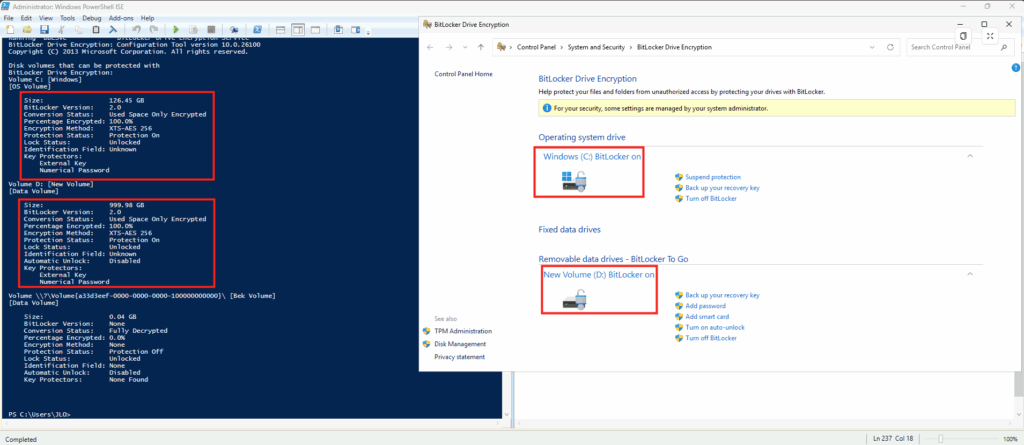
Je voulais vérifier un point : un disque OS éphémère (Ephemeral OS Disk) peut être placé sur Temp, NVMe ou Cache selon la série de votre VM. La documentation Microsoft indique que l’option de placement ne change pas la performance ni le coût de l’Ephemeral OS Disk, car la perf dépend du stockage local disponible sur le SKU.
Dans la vraie vie (et dans mes chiffres) : même si les trois restent “OS + éphémère”, le placement change le chemin I/O réel, et donc le comportement sous pression : la différence la plus visible n’est pas toujours l’IOPS moyen, mais la distribution de latence (p95/p99/p99.9) et la stabilité en charge soutenue.
Plusieurs articles ont déjà été écrits sur les performances de stockages Azure :
Mais avant d’aller directement dans les tests, prenons le temps de parcourir ensemble quelques notions concernant le stockage temporaire local attaché une machine virtuelle.
Qu’est-ce qu’un stockage temporaire local ?
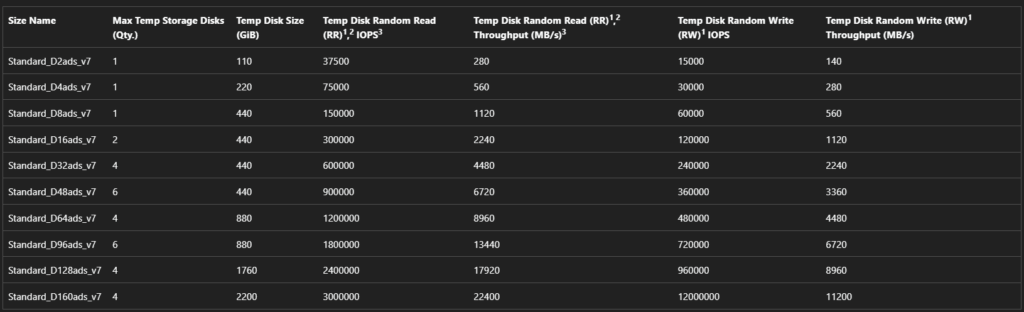
Certaines tailles de machine virtuelle Azure incluent un stockage local temporaire éphémère, certaines des tailles les plus récentes utilisant des disques NVMe locaux temporaires.
Le stockage temporaire local utilise des disques supplémentaires approvisionnés directement en tant que stockage local sur un hôte de machine virtuelle Azure, plutôt que sur le stockage Azure distant. Ce type de stockage convient le mieux aux données qui n’ont pas besoin d’être conservées définitivement, telles que les caches, les mémoires tampons et les fichiers temporaires.
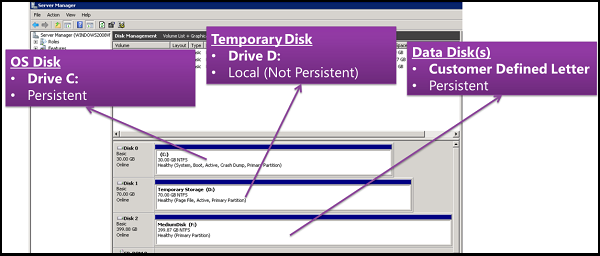
Le disque temporaire (souvent D: sous Windows) est un disque local éphémère classique : les données sont potentiellement perdues en si maintenance/redeploy/deallocate. Un disque OS éphémère peut être placé dessus (Temp placement, NVMe, ou sur le cache disk) selon le SKU de la machine virtuelle :
Étant donné que les données stockées sur ces disques ne sont pas sauvegardées, elles sont perdues lorsque la machine virtuelle est libérée ou supprimée. Le stockage éphémère est recréé au démarrage. Les disques éphémères locaux sont différents des disques de système d’exploitation éphémères.
Un disque OS éphémère est un disque système stocké localement sur l’hôte Azure, et non sur un stockage distant Azure Storage. Le point le plus important est que celui-ci est non persistant : en cas de redéploiement, de recréation, le disque OS éphémère revient toujours à l’image de départ.
Les disques de système d’exploitation éphémères sont créés sur le stockage local de la machine virtuelle (VM) et ne sont pas enregistrés dans le Stockage Azure à distance.
Le premier avantage concerne le prix : On ne paye pas le volume de stockage du disque éphémère. Celui-ci est intégré au prix de la machine virtuelle. De plus, les performances sont bien meilleures que la plupart des disques :
Les disques OS éphémères conviennent parfaitement aux charges de travail sans état, dans lesquelles les applications tolèrent les pannes de machines virtuelles individuelles tout en restant sensibles aux délais de mise en service ou à la réimagerie d’instances spécifiques.
Comparé à un disque de système d’exploitation standard, un disque éphémère offre une latence plus faible pour les opérations de lecture/écriture et permet une réinitialisation plus rapide des machines virtuelles.
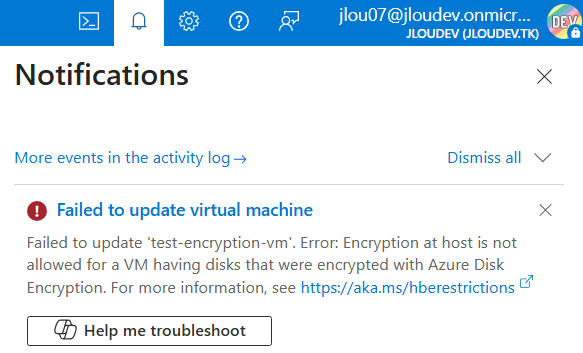
Comme annoncé plus haut, le disque OS éphémère ne doit pas contenir de la donnée critique. De plus, des fonctionnalités basiques ne sont pas disponibles :
Arrêt / Démarrage de la VM
Capture d’image VM
Captures instantanées de disque
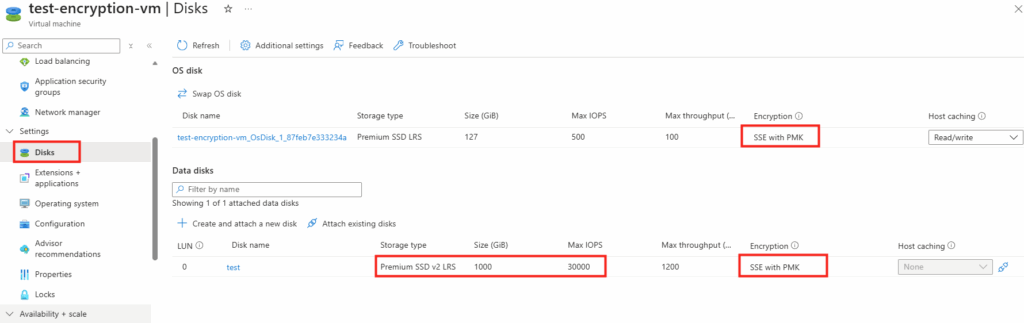
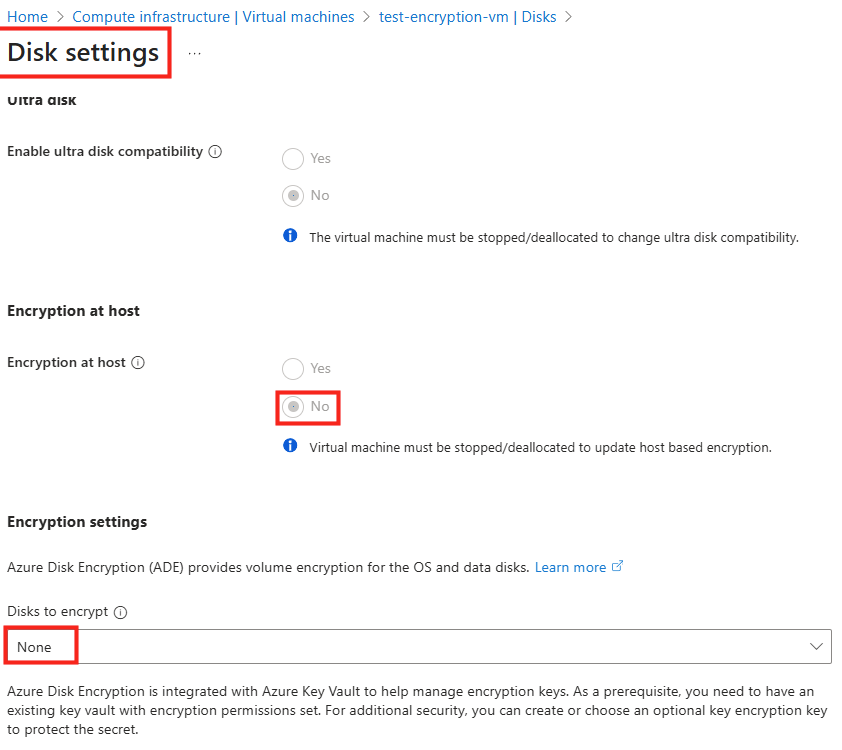
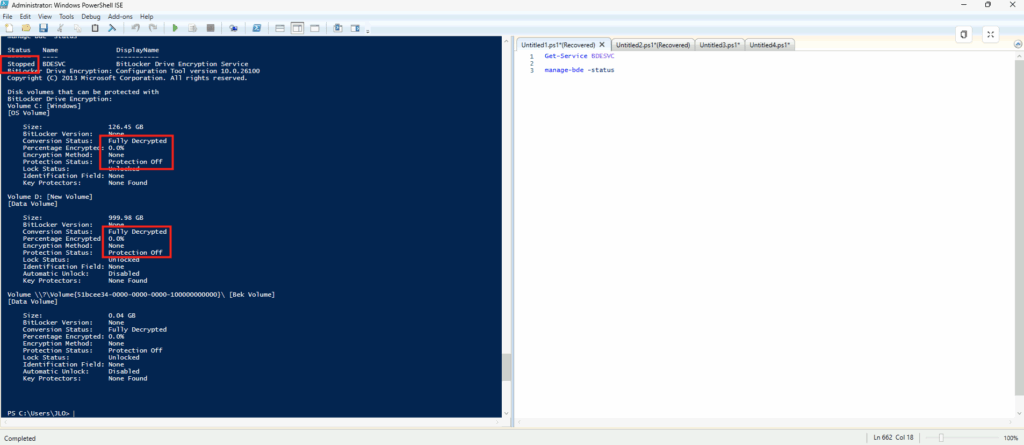
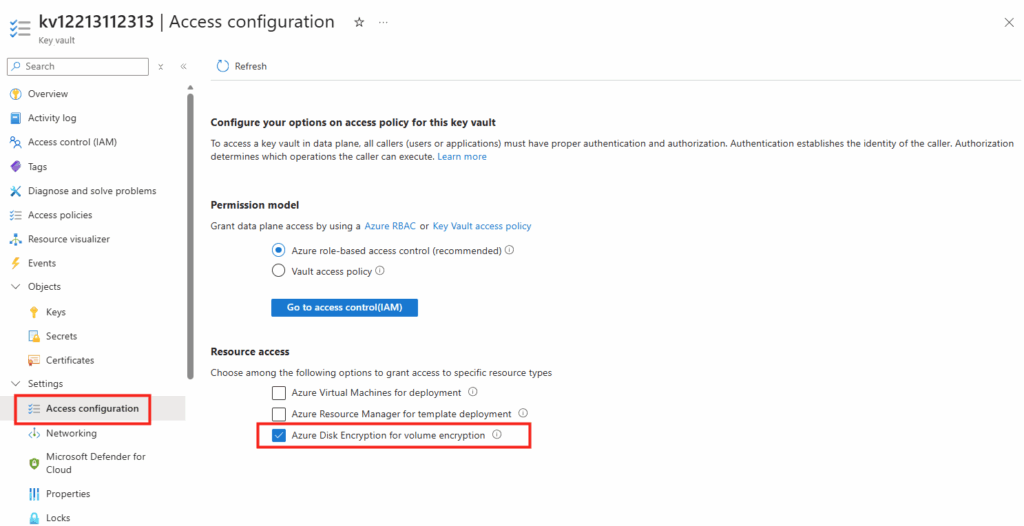
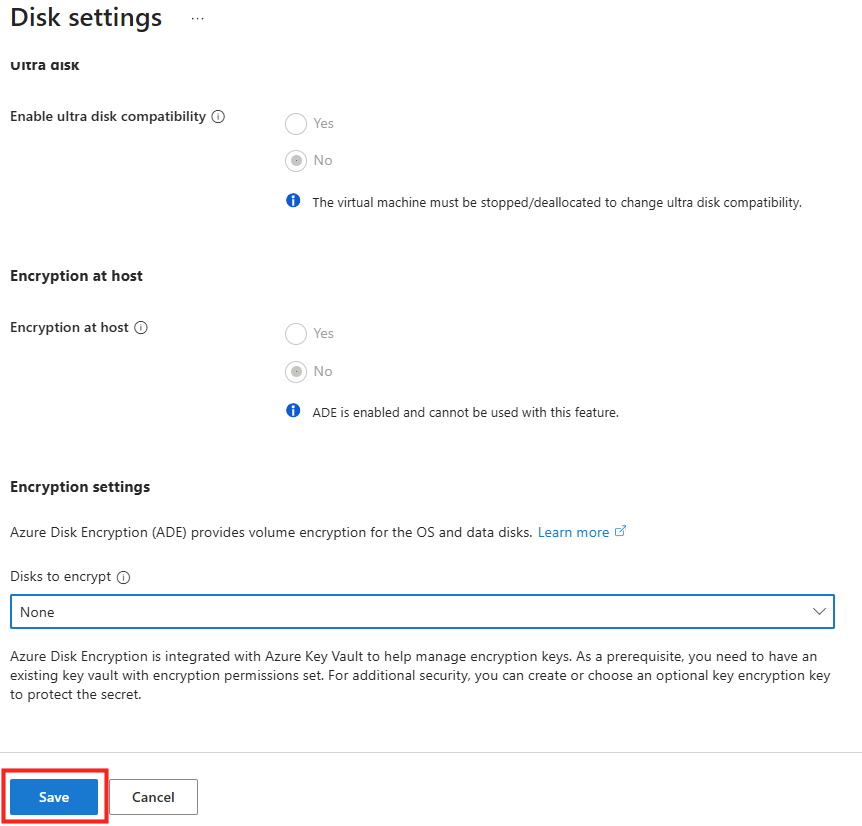
Azure Disk Encryption
Échanges de disques système d’exploitation
Sur le portail Azure, certains menus sont tout simplement grisés pour ce type de VM :
Les fonctionnalités de sauvegarde et de reprise d’activité après sinistres sont elles aussi désactivés :
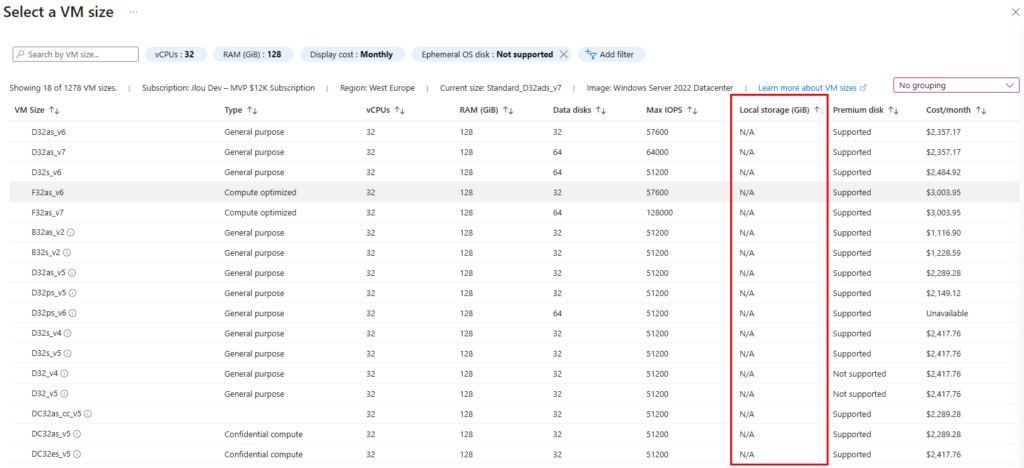
Comment savoir si le SKU de ma VM dispose d’un stockage temporaire local ?
La doc détaille trois placements possibles selon les VM :
NVMe Disk Placement (GA sur des séries récentes v6+)
Temp Disk / Resource Disk Placement
Cache Disk Placement
La nature et le volume du stockage temporaire local dépend en effet de la famille et du SKU de votre machine virtuelle :
Quid de la SLA d’une VM avec un disque OS éphémère ?
Le base disk influence l’engagement contractuel et certaines phases de provisioning, mais il ne modifie pas le chemin I/O steady-state de l’OS.
Depuis peu, Azure permet de choisir le type de “base disk” associé à un disque OS éphémère : Standard HDD, Standard SSD ou Premium SSD.
Attention cependant, ce “base disk” ne correspond pas au support physique sur lequel l’OS s’exécute.
Dans le cas d’un disque OS éphémère, le système fonctionne toujours sur le stockage local de l’hôte (NVMe / Temp / Cache selon le placement). Le type de base disk désigne le type de disque managé logique utilisé par Azure lors du provisioning et pour l’engagement contractuel.
La prise en charge SSD est une nouvelle option qui permet aux clients de choisir le type de disque principal utilisé pour le disque d’OS éphémère. Auparavant, le disque de base ne pouvait être qu’un HDD standard. À présent, les clients peuvent choisir entre les trois types de disques : HDD Standard (Standard_LRS), SSD Standard (StandardSSD_LRS) ou SSD Premium (Premium_LRS). En utilisant SSD avec disque de système d’exploitation éphémère, les clients peuvent bénéficier des améliorations suivantes :
Contrat SLA amélioré : les machines virtuelles créées avec SSD Premium fournissent un contrat SLA supérieur à celui des machines virtuelles créées avec hDD Standard. Les clients peuvent améliorer le contrat SLA pour leurs machines virtuelles éphémères en choisissant SSD Premium comme disque de base.
Le choix du base disk peut améliorer la SLA contractuelle de la VM.
Il peut également influer sur certaines phases spécifiques (provisioning, re-imaging, lectures liées au backing managed disk).
En revanche, il ne modifie pas les performances steady-state du stockage local sur lequel tourne réellement l’OS.
Autrement dit :
Choisir Premium SSD comme base disk améliore la SLA et certains scénarios liés au provisioning, mais ne transforme pas un placement NVMe ou Temp en Premium SSD local.
Pourcentage de disponibilité (SSD Premium, SSD Premium v2 et Ultra Disk)
Pourcentage de disponibilité (disque géré SSD standard)
Pourcentage de disponibilité (disque géré HDD standard)
Avoir Service
< 99,9 %
< 99,5 %
< 95 %
10 %
< 99 %
< 95 %
< 92 %
25 %
< 95 %
< 90 %
< 90 %
100 %
Quid des performances d’une VM avec un disque OS éphémère ?
Le disque OS éphémère exploite le stockage local intégré à la machine virtuelle. Étant donné que différentes machines virtuelles ont différents types de stockage local (disque de cache, disque temporaire et disque NVMe), l’option de placement définit l’emplacement où le disque de système d’exploitation éphémère est stocké. Le choix du placement n’influence ni les performances ni le coût du disque OS éphémère. Ses performances reposent sur le stockage local de la machine virtuelle. Selon le type de machine virtuelle, trois modes de placement sont proposés.
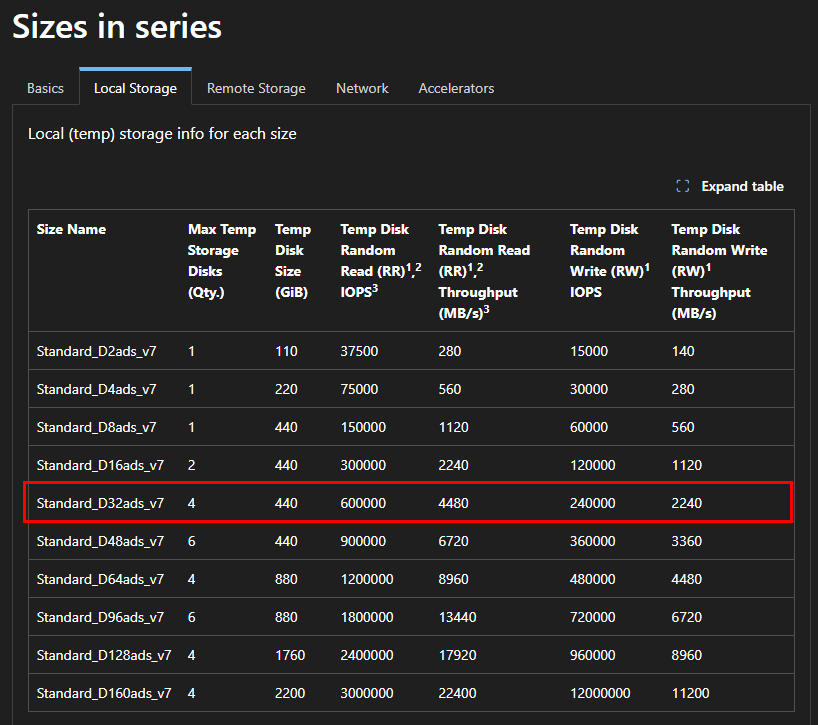
Placement de disque NVMe (généralement disponible) : le type de placement de disque NVMe est désormais en disponibilité générale (GA) sur la dernière série de machines virtuelles v6 de la dernière génération, comme Dadsv6, Ddsv6, Dpdsv6, etc.
Placement de disque temporaire (également appelé Placement de disque de ressources) : le type de placement de disque temporaire est disponible sur les machines virtuelles avec un disque temp comme Dadsv5, Ddsv5, etc.
Emplacement du disque de cache : le type de placement du disque de cache est disponible sur les anciennes machines virtuelles qui avaient un disque de cache tel que Dsv2, Dsv3, etc.
La performance théorique dépend du SKU, pas du placement. En revanche, comme chaque placement repose sur un support physique différent (NVMe, temp disk, cache disk), le comportement réel sous charge peut varier sensiblement.
Mais cette seconde partie de la documentation Microsoft m’intrigue quand même :
Amélioration des performances : en choisissant SSD Premium comme disque de base, les clients peuvent améliorer les performances de lecture du disque de leurs machines virtuelles. Bien que la plupart des écritures se produisent sur le disque temporaire local, certaines lectures sont effectuées à partir de disques managés. Les disques SSD Premium fournissent 8 à 10 fois plus d’IOPS que hDD Standard.
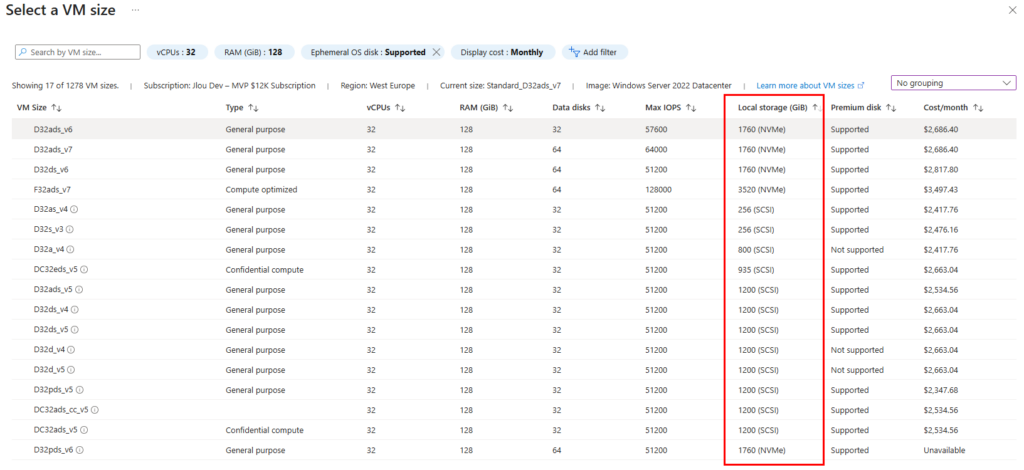
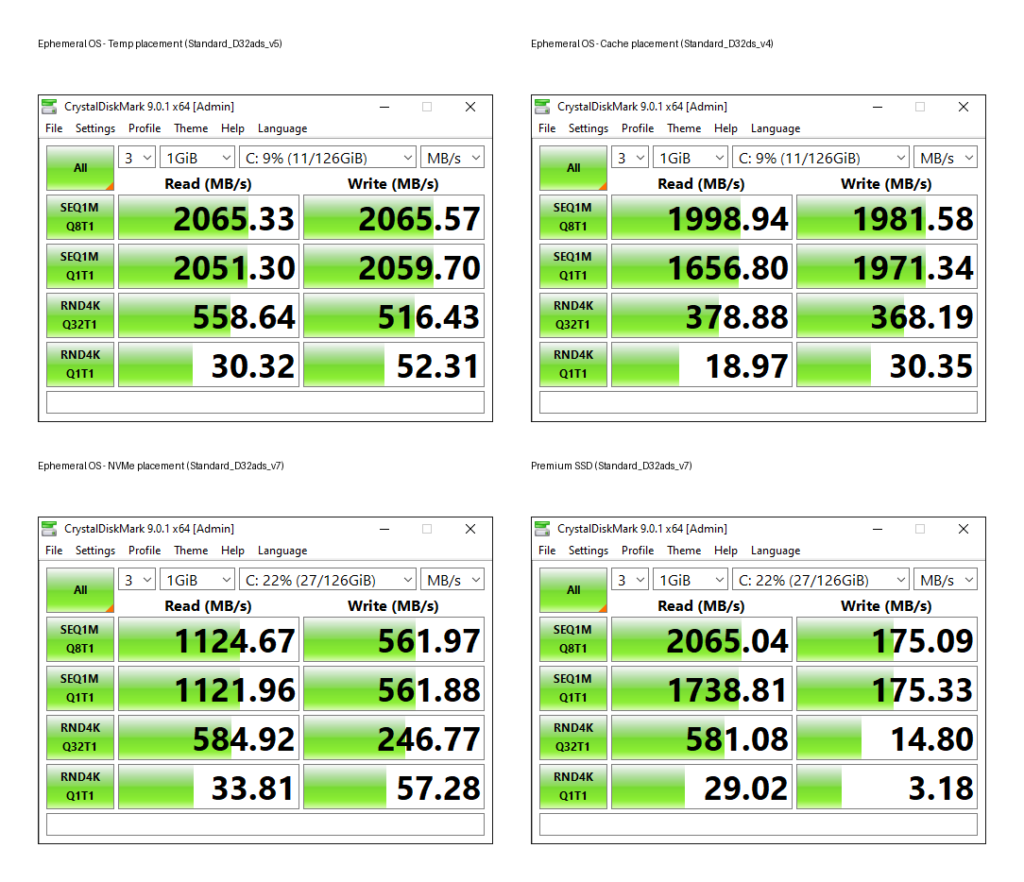
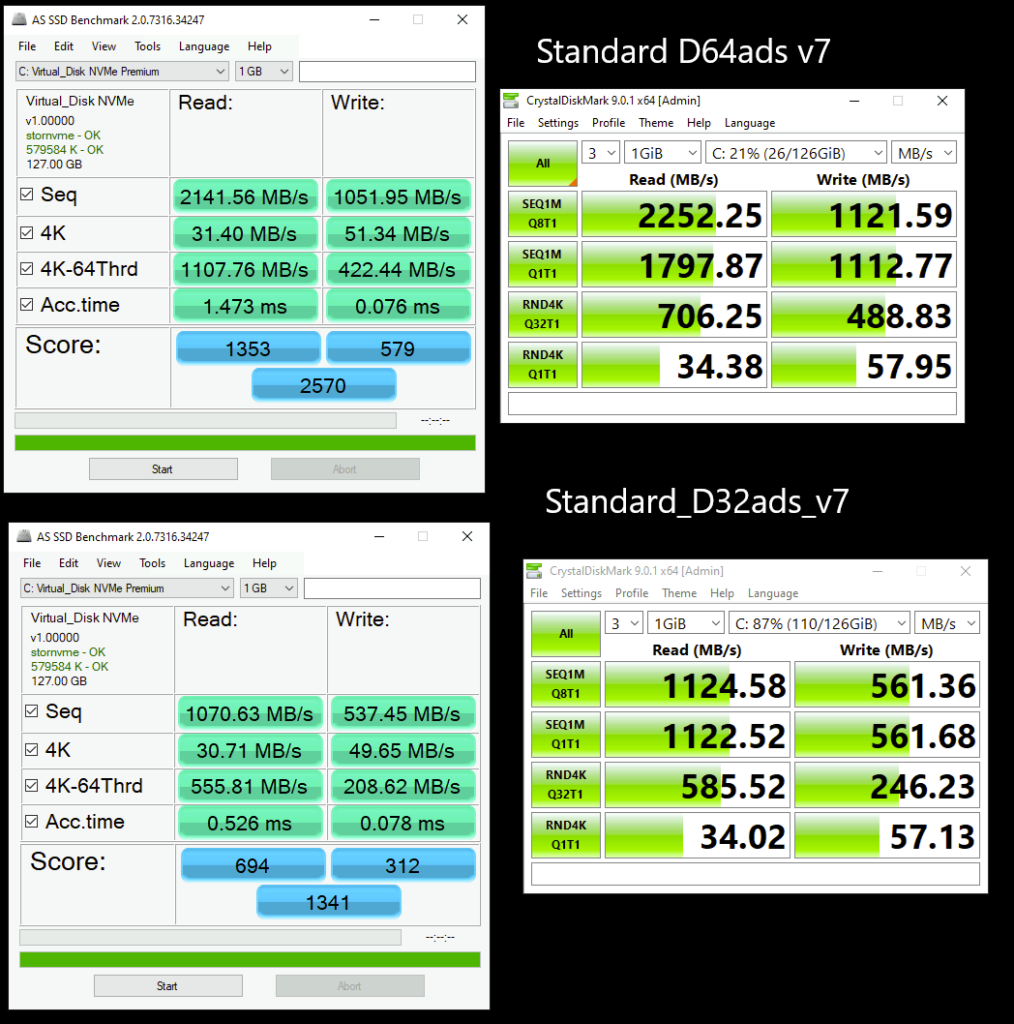
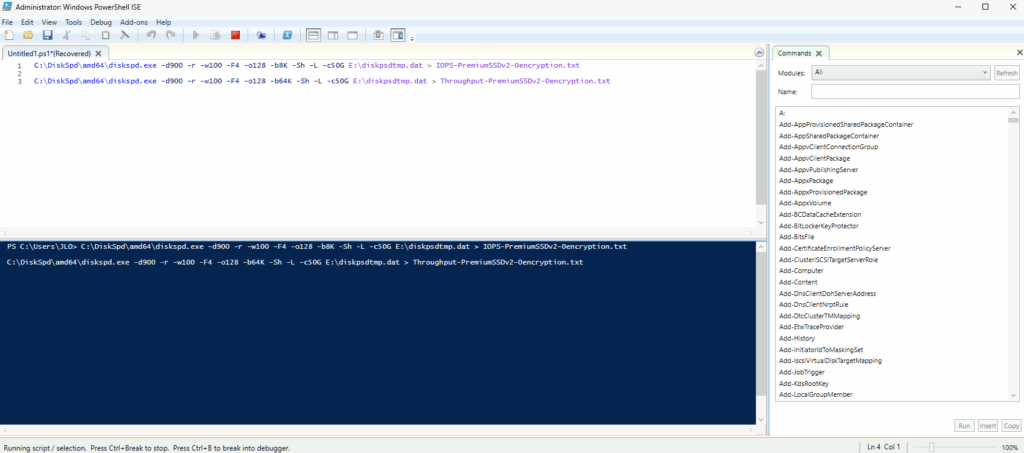
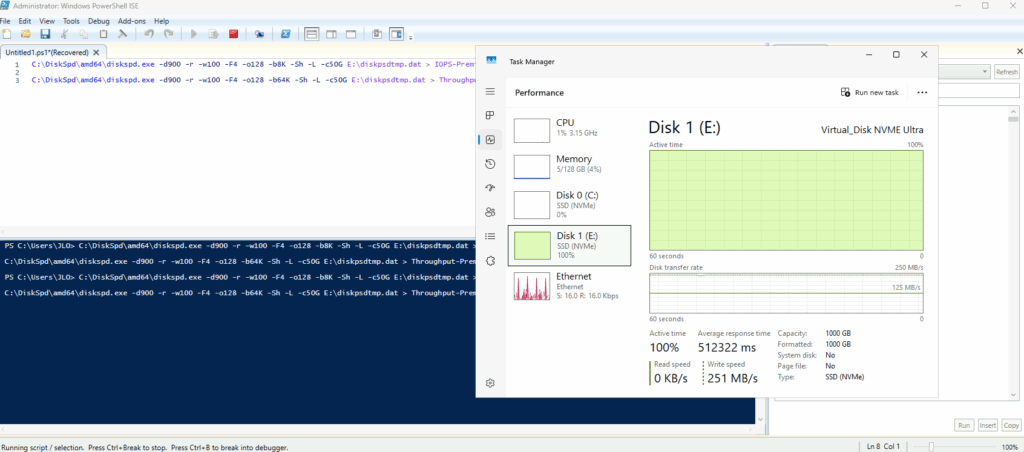
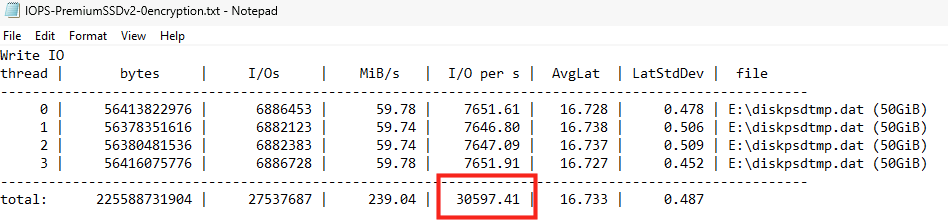
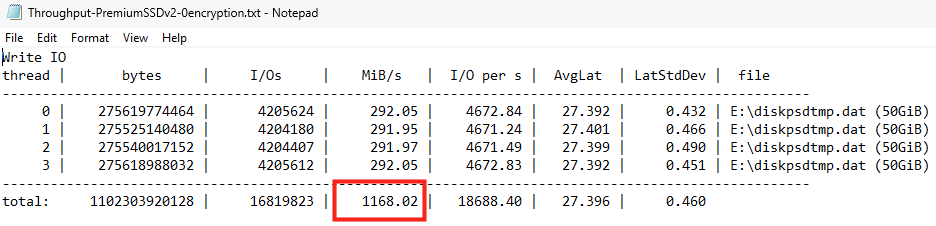
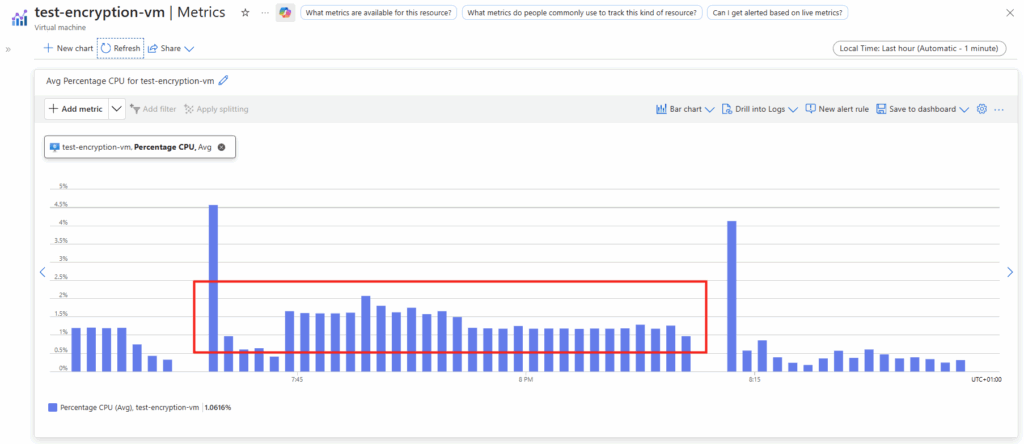
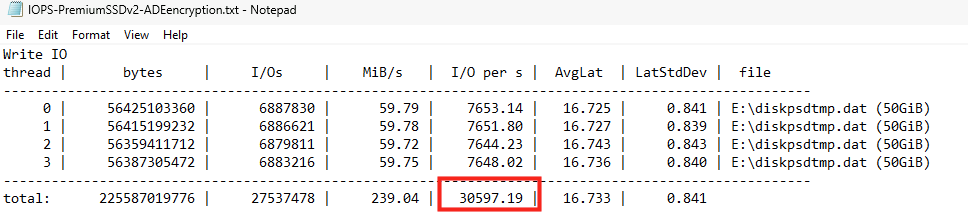
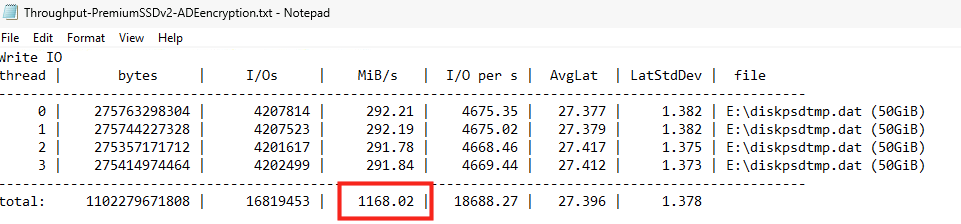
J’ai créé plusieurs machines virtuelles avec le SKU Standard_D32ads_v7, dont voici les performances pour le stockage local :
Pourtant, les deux différents type de disque OS éphémère créés indiquent exactement les mêmes performances sur le portail Azure :
En extrapolant naïvement à partir de la capacité totale locale (440 Go x4), j’aurais pu m’attendre qu’en faisant un produit en croix basé sur la taille totale des 4 disques locaux attachés à ma VM, je m’attendais à trouver les performances suivantes sur mon disque OS éphémère :
IOPS max : 43296 IOPS
Bande passante max : 323 Mo/sec
Passons maintenant à l’approche utilisée pour mes tests.
Protocole de test que j’ai déployé :
Machines virtuelles Azure :
Pour éviter toute ambiguïté, les 4 VMs utilisent toutes un disque OS avec Windows Server 2022, mais sur des placements différents :
Nom de VM
SKU
Type de disque OS
perftemp
Standard_D32ads_v5
Ephemeral OS Disk – Temp placement
perfnvme-vm
Standard_D32ads_v7
Ephemeral OS Disk – NVMe placement
perfcache
Standard_D32ds_v4
Ephemeral OS Disk – Cache placement
perfssd
Standard_D32ads_v7
OS Disk Premium SSD (référence)
Outils de mesure :
Plusieurs outils de mesures ont été utilisés afin de mieux comprendre les performances :
L’outil a été laissé dans sa configuration de base. Cela permet de provoquer :
Meilleur profit des caches (OS, contrôleur, stockage local, cache host)
Meilleur visu du burst (très bon pendant un court moment)
Ne force pas steady-state
Comme attendu, cela donne des chiffres parfois “spectaculaires”, notamment en lecture. Et c’est exactement le biais évoqué plus haut qui en ressort :
Tests courts
Pas de warm-up réel
Influence potentielle du cache
CrystalDiskMark confirme les tendances générales, mais ne permet pas de juger la stabilité sous charge soutenue.
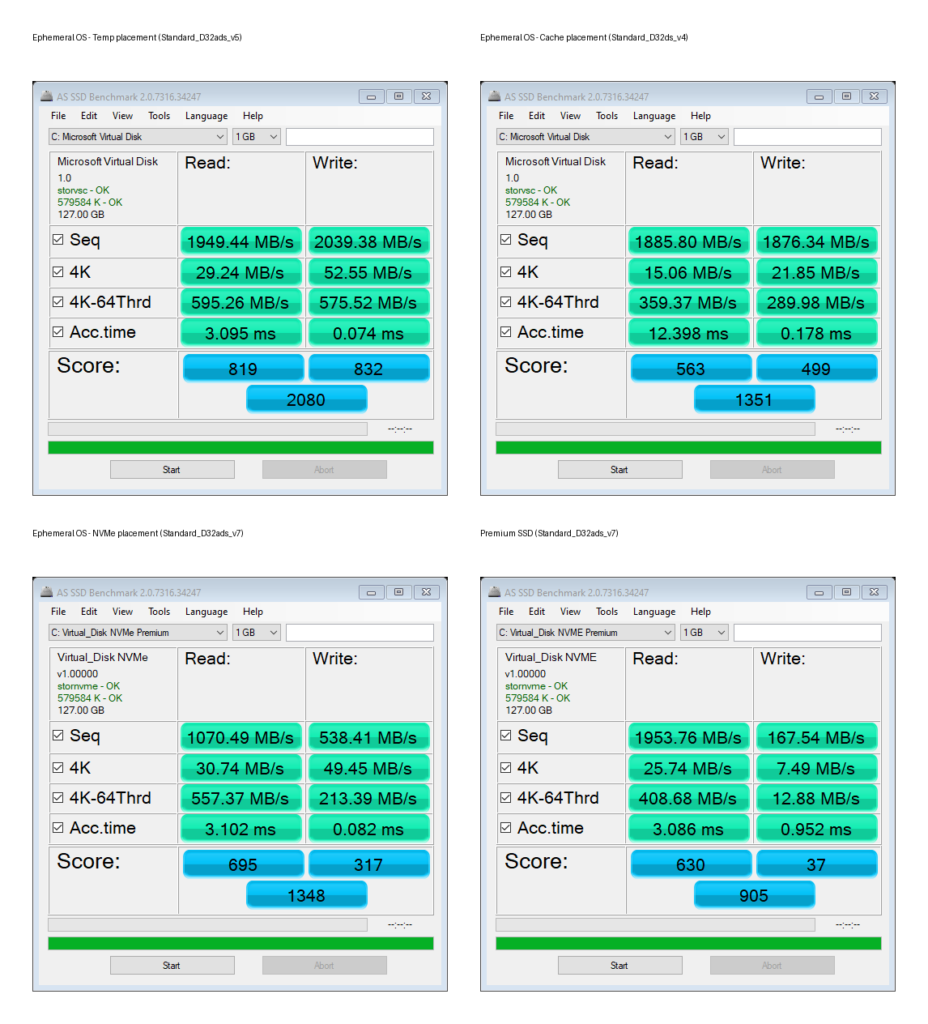
AS SSD Benchmark – Latence & Incompressible :
AS SSD Benchmark va un peu plus loin que CrystalDiskMark et donne d’autres infos : Seq / 4K / 4K-64Thrd + “Acc.time”. Cela donne dans les résultats une meilleure visibilité des différences d’écriture, parfois très forts selon le disque.
AS SSD est connu pour être très sensible à :
la façon dont le chemin I/O gère les écritures (flush, cache, barrières)
la latence (et il la met en avant via “Acc.time”)
et la façon dont le driver/stack de stockage réagit
AS SSD peut donc apparaître comme plus sévère que CrystalDiskMark sur les écritures quand il tombe sur un scénario où le stockage/driver applique davantage de contraintes (flush/ordering).
Les tests faits via AS SSD nous apporte donc ici deux éléments intéressants :
Mesure directe de latence d’accès
Test incompressible (moins biaisé par cache/compression)
Dans notre cas, on peut donc en déduire que disque éphémère NVMe domine clairement en latence pure, que le disque éphémère temporaire reste très proche, que le disque éphémère cache montre une latence un peu plus élevée, et que le disque Premium SSD affiche la latence la plus importante.
Le score global reflète davantage l’expérience “ressentie” qu’un simple IOPS max.
fio – tests soutenus proches d’un workload :
Contrairement à CrystalDiskMark (smoke test court) et AS SSD (latence & incompressible), fio permet de :
contrôler précisément le pattern I/O
imposer une durée suffisante
forcer le bypass du cache OS (–direct=1)
introduire une phase de warm-up
mesurer les percentiles élevés (p95, p99, p99.9)
Autrement dit, fio mesure le comportement soutenu proche d’un workload réel.
Je suis passé par Chocolatey pour installer fio sur mes 4 machines virtuelles Azure grâce au script PowerShell suivant :
J’ai ensuite lancé le script fio suivant sur chacun des machines virtuelles pour générer et centraliser mes résultats sur un Azure file share. Dans ce script, fio teste :
Random 4K en montée de charge (sweep de queue depth QD1→64) en lecture/écriture
Un “peak” comparable : random 4K QD32, 8 jobs (lecture + écriture).
Un run plus long “steady-state” : random write 4K QD32, 8 jobs (soutenu).
Le coût de la durabilité/synchronisation : random write 4K QD1, 1 job, fsync=1.
Le débit séquentiel : read/write 1M, QD32, 4 jobs.
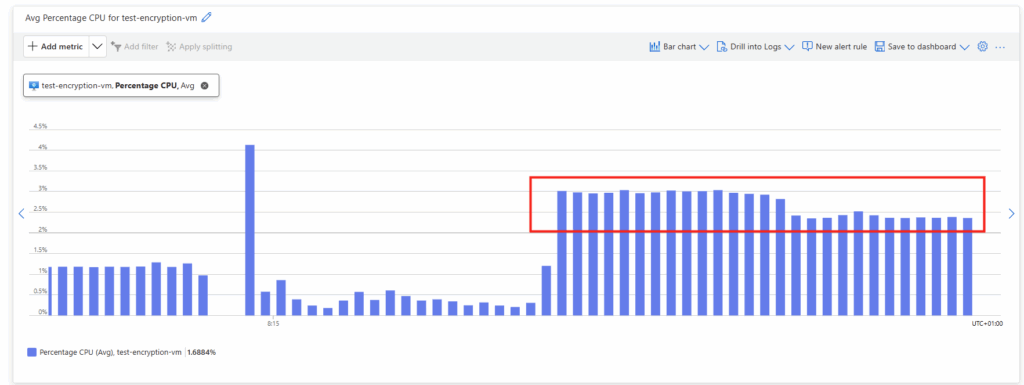
Sur Temp, Cache et NVMe, on peut lire que Peak ≈ Steady. Cela signifie que :
Pas de burst artificiel
Pas d’effet cache court terme
Pas de chute après 30 secondes
Pas d’effondrement après warm-up
Le comportement observé est soutenu, et c’est extrêmement important, car beaucoup de benchmarks “rapides” montrent un pic initial qui s’effondre après 1 à 2 minutes. Ici, ce n’est pas le cas.
NVMe vs Temp : contre-intuitif
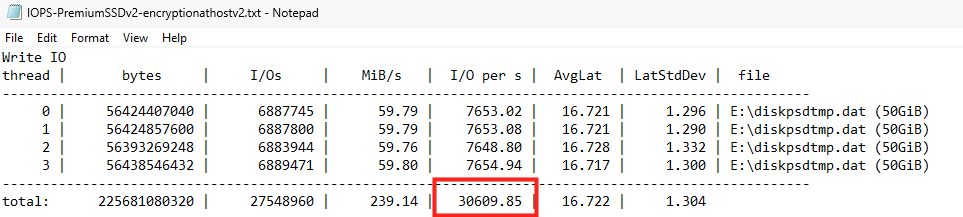
Intuitivement, on pourrait penser que NVMe est supérieur à Temp. Or, en écriture 4K soutenue :
Temp : 153k IOPS
NVMe : 60k IOPS
Ce n’est pas un artefact. De plus : Peak = Steady sur NVMe Cela indique un plafond structurel, pas un effet transitoire. La performance dépend donc du chemin I/O exposé par le SKU, pas uniquement de la nature “NVMe” du support. C’est un point fondamental.
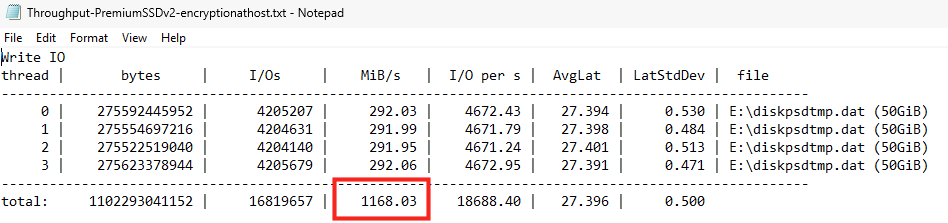
Premium SSD : changement de catégorie
Enfin, nous sommes dans un monde différent avec le premium ssd, En 4K write steady, le Premium SSD monte à 2 926 IOPS, avec un pique à 3500 IOPS. On n’est plus dans la même catégorie. Le disque managé respecte son cap IOPS contractuel :
Ce test montre très clairement la différence entre un stockage managé distant avec limite provisionnée et stockage local intégré au SKU.
Si un stockage persistant est nécessaire, à vous maintenant de voir quel disque correspondra mieux à vos besoins :
Pourquoi regarder p99/p99.9 et pas juste les IOPS ?
Microsoft documente les notions de limites cached/uncached et le fait qu’un workload peut être IO capped. Quand cela arrive :
Les IOPS plafonnent
La file d’attente sature
La latence augmente
Ton plateau write NVMe en 4K random (QD sweep) a exactement la signature d’une limite plateforme. Deux disques peuvent faire 100k IOPS :
L’un avec P99.9 à 10 ms
L’autre avec P99.9 à 50+ ms
Ils n’auront pas du tout la même sensation côté OS. Le P99.9 capture les moments où :
la queue est saturée
un flush bloque
un throttling intervient
C’est ce qui compte en production.
Comment le cache d’Azure nous trompe ?
Microsoft indique qu’un disque avec host caching peut temporairement dépasser la limite disque. Cela explique pourquoi :
CrystalDiskMark peut afficher des chiffres “incroyables”
Un bench court peut mesurer le cache plutôt que le support réel
Si un benchmark va “trop vite”, c’est souvent un cache. De plus :
Microsoft recommande un warm-up
Les cached reads atteignent leurs meilleurs chiffres après stabilisation
Le cache modifie donc la mesure. En write, ce n’est pas magique :
Quand le caching est en Read/Write, l’écriture doit être validée dans le cache et sur le disque. Elle compte dans les limites cached et uncached. Le cache ne supprime pas la limite soutenue.
Pourquoi certains outils de mesure peuvent être trompeur lors de tests sur Azure ?
De ce fait, certains outils comme CrystalDiskMark, sont très bien pour un smoke test, mais :
Les durées courtes,
Les patterns,
et l’absence de phase de warm-up
font qu’ils mesurent souvent le cache, pas le support réel. Un chiffre « trop beau » est souvent… un cache.
La limite n’est pas le disque. C’est la VM :
VM
vCPU
Peak 4K Read
Peak 4K Write
Steady 4K Write
P99 Write (µs)
P99.9 Write (µs)
D32ads_v7
32
~146k
~60k
~60k
~601
~1048
D64ads_v7
64
~291k
~120k
~120k
~580
~1010
VM
Seq Read
Seq Write
D32ads_v7
~1071 MiB/s
~536 MiB/s
D64ads_v7
~2144 MiB/s
~1067 MiB/s
Ces nouveaux tests montrent un comportement très clair :
NVMe en D32 plafonne à ~60k IOPS write
Le même NVMe en D64 monte à ~120k IOPS
La latence reste comparable
Le support physique n’a pas changé. Le workload n’a pas changé. Le placement n’a pas changé.Ce qui a changé : le SKU, cela démontre que Le plafond de performance est imposé par la capacité I/O exposée par la VM, pas par le média NVMe lui-même.
Autrement dit, le NVMe ne “donne” pas 60k IOPS, la VM D32 expose 60k IOPS.
Mais attention, les chiffres donnés dans la documentation Microsoft décrivent le potentiel maximal du stockage local temporaire de la VM (souvent agrégé sur plusieurs disques). Un disque OS éphémère ‘NVMe placement’ n’est pas automatiquement équivalent à ce chemin I/O, et un test ‘fichier’ ajoute un overhead. On compare donc des plafonds de nature différente.
Pourquoi les tests “fsync=1” ne prouvent pas la durabilité ?
fsync=1 mesure le coût d’un flush côté OS, mais ne prouve pas la persistance réelle sur le média ou la résistance à un crash hôte. fio indique qu’en non-buffered I/O, il peut ne pas sync comme attendu :
fsync=1 force un flush côté OS
mais ça ne valide pas une persistance réelle côté hyperviseur / host
ce n’est pas un test de crash-consistency
Donc si tu veux un “durability test”, il faut une variante (ex : buffered ou job dédié) et mesurer la phase sync séparément.
Conclusion
Si je résume :
Les trois disques OS éphémères surpassent le Premium SSD managé
NVMe offre une latence très stable et évolue fortement avec le SKU
Temp placement reste le plus performant en écriture 4K soutenue dans ce test précis
Cache dépend davantage du comportement de file d’attente
Mais surtout, Microsoft a raison : la performance dépend du stockage local. Mais ce que la documentation ne met pas en avant, c’est que le stockage local n’est pas homogène selon le placement. Et c’est là que tout se joue :
Les différences ne sont pas toujours visibles sur l’IOPS moyen. Elles apparaissent dans les percentiles élevés (p99/p99.9)
C’est exactement ce que Microsoft ne détaille pas explicitement : la performance dépend du stockage local… mais le stockage local n’a pas la même nature physique selon le placement
D’un point de vue technique :
Le placement ne change pas le coût
Le placement ne change pas la “promesse marketing”
Mais le placement change le chemin I/O réel
Et donc, en fonction de la charge de travail :
Pour une charge de travail sensible à la latence (SQL temporaire, build intensif, traitement parallèle), le NVMe placement est clairement le plus intéressant.
Pour des workloads stateless classiques, Temp reste un excellent compromis.
Le Cache placement, sur des générations plus anciennes, reste viable mais moins moderne.
Enfin, un Premium SSD managé reste plus simple opérationnellement, mais il est largement dépassé en performance pure par le stockage local éphémère.
Les services de calcul représentent souvent l’essentiel des coûts sur Azure. Pour les charges de travail qui fonctionnent en continu, les instances réservées apportent une réduction notable des tarifs à la carte. En s’engageant sur une durée d’un ou trois ans, il est possible de réaliser jusqu’à grosses économies par rapport au modèle pay‑as‑you‑go. Mais est-on alerté quand ces réductions sont disponibles pour notre environnement Azure, ou qu’elles expirent ?
Dans cet article, nous revenons sur le fonctionnement des instances réservées, leur gestion (notamment le renouvellement automatique) et sur la création d’alertes Azure Advisor pour être notifié lorsqu’une réservation devient pertinente ou expire.
Qu’est-ce qu’une instance réservée Azure ?
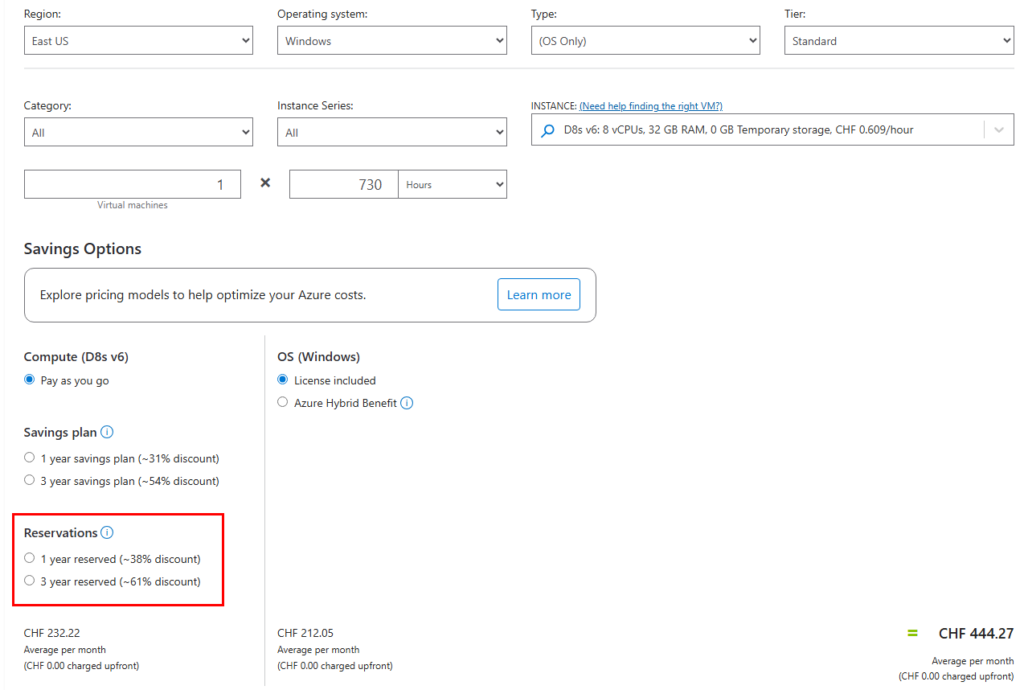
Une instance réservée est un engagement de capacité : vous acceptez d’utiliser un type d’instance ou une famille d’instances dans une région spécifique pendant une durée déterminée, en échange d’un prix réduit. Les réservations s’achètent pour un an ou trois ans :
Quand acheter une réservation ?
Les instances réservées sont particulièrement adaptées aux charges stables et prévisibles. La documentation Microsoft recommande d’opter pour une réservation lorsque vous prévoyez d’utiliser le même type d’instance ou la même famille dans une région donnée pendant toute la durée de l’engagement.
À l’inverse, si vos applications changent fréquemment de configuration ou de région, les savings plans peuvent être plus appropriés car ils s’appliquent à un montant horaire sur plusieurs services et régions. Néanmoins, une instance réservée reste l’option la plus économique lorsque son utilisation est maximale.
Que doit-on faire pour appliquer la remise ?
Une fois la réservation achetée, la remise est appliquée automatiquement aux machines virtuelles, SQL Database, Cosmos DB ou d’autres services éligibles qui correspondent aux attributs choisis (SKU, région, étendue).
Les réservations n’affectent pas l’état d’exécution des ressources : si une machine est mise à l’arrêt ou redimensionnée, le rabais se reporte sur une autre ressource compatible, sinon la portion inutilisée est perdue :
Quid d’une machine virtuelle dont la taille varie ?
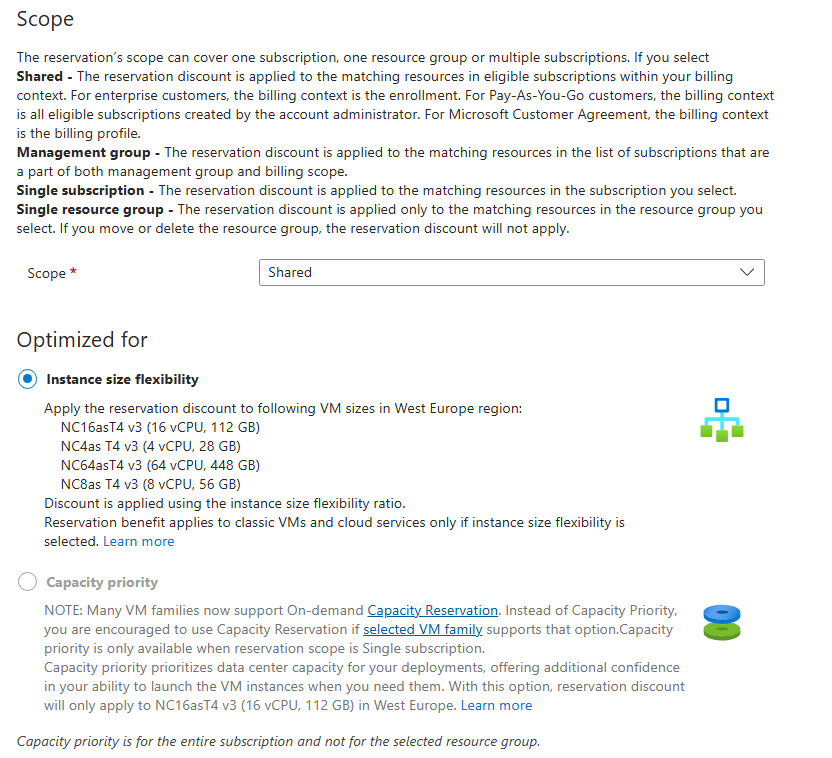
Une instance réservée s’applique sur une famille de machines virtuelles : même si le SKU d’une RI correspond à un SKU spécifique d’une VM, il peut s’appliquer à d’autres tailles d’une même famille via un ratio :
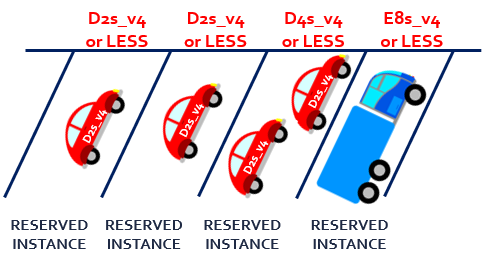
Le tableau ci-dessus affiche des instances réservées pour des machines virtuelles. Comment fonctionne une instance réservée ? Il faut simplement voir celle-ci comme une place de parking, louée pour un ou trois ans chez Microsoft :
Comme le montre ce schéma, la taille de l’instance réservée doit être en relation avec la taille de la ressources Azure.
Il est donc possible d’optimiser votre réservation pour la flexibilité de taille. Dans ce mode, la remise s’applique à toutes les tailles d’instances d’un même groupe. Par exemple, une réservation achetée pour une instance de la série DSv2 (par exemple Standard_DS3_v2) peut s’appliquer aux autres tailles de ce groupe : Standard_DS1_v2, Standard_DS2_v2, Standard_DS3_v2 et Standard_DS4_v2
Quid de la durée et la fréquence de paiement ?
Le choix de la durée dépend de la stabilité de votre charge. Les engagements d’un an offrent plus de flexibilité tandis que les engagements de trois ans maximisent les économies. Vous pouvez régler la réservation en une seule fois ou mensuellement ; le coût total reste identique et aucune pénalité n’est appliquée en cas de paiement échelonné, sauf le taux de change qui varie dans le temps :
Qu’est-ce qui n’est pas couvert par la RI ?
La remise porte uniquement sur les coûts de calcul. Pour les machines virtuelles, elle concerne les cœurs et la mémoire mais ne couvre pas les licences Windows ni les frais de stockage, réseau ou logiciels.
Les licences peuvent être prises en charge via l’Azure Hybrid Benefit, et les autres coûts sont facturés séparément. En revanche, de nombreux services Azure disposent de capacités réservées pour réduire leurs propres coûts de calcul.
Qu’est-ce qu’Azure Hybrid Benefit ?
Azure Hybrid Benefit est un avantage en matière de licences qui vous permet de réduire considérablement les coûts d’exécution de vos charges de travail dans le cloud. Son fonctionnement consiste à vous autoriser à utiliser vos licences Windows Server et SQL Server compatibles sur Azure.
Il est donc possible d’acheter des licences en souscriptions annuelles ou pluriannuelles. Les économies représentent des sommes non négligeables.
Cet avantage permet donc d’utiliser les licences Windows Server ou SQL Server existantes éligibles, et ainsi de ne payer que le tarif de base des machines virtuelles.
Que se passe-t-il à la fin du contrat de la RI ?
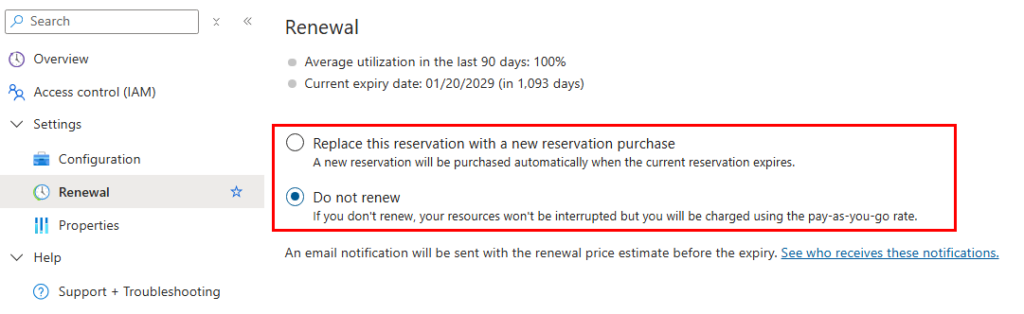
Lorsque vous achetez une réservation, le renouvellement automatique est souvent activé par défaut. Cette fonction permet de racheter automatiquement une réservation équivalente à l’expiration de la précédente, afin de continuer à bénéficier de la remise sans surveillance quotidienne.
Vous pouvez activer ou désactiver cette option à tout moment dans le portail Azure. Le prix du renouvellement est disponible 30 jours avant la date d’expiration. Si la réservation n’est pas renouvelée, vos ressources continuent de fonctionner, mais elles repassent en facturation à l’usage.
Peut-on annuler une instance réservée en cours d’engagement ?
Oui, Microsoft permet l’annulation d’une RI pendant sa durée d’engagement, sous conditions :
Les remboursements sont calculés en fonction du prix le plus bas de votre prix d’achat ou du prix actuel de la réservation.
Nous ne facturons actuellement aucun frais de résiliation anticipée, mais des frais de résiliation anticipée de 12 % pourraient s’appliquer à l’avenir en cas d’annulation.
L’engagement total annulé ne peut pas dépasser 50 000 USD dans une période de 12 mois pour un profil de facturation ou une inscription unique.
Lorsqu’une réservation est échangée ou annulée, le remboursement est calculé en fonction du nombre de jours restants dans la période de réservation. Le calcul est effectué au format UTC et utilise une formule cohérente pour garantir l’équité et la transparence.
Par exemple, si vous avez acheté une réservation le 10 juillet 2024 et que vous l’avez échangée le 9 juillet 2025, seulement 1 jour reste dans la réservation. Vous recevrez un petit remboursement pour ce seul jour.
Instances réservées vs. Savings Plan ?
Bien que les savings plans partagent l’objectif de réduire les coûts, ils fonctionnent différemment. Une instance réservée vous engage sur un type ou une famille d’instances dans une région donnée et vous apporte la remise la plus élevée lorsque vos machines fonctionnent en continu.
À l’inverse, un savings plan fixe un montant horaire applicable sur plusieurs services de calcul et dans toutes les régions. Cette flexibilité est utile pour les charges de travail qui évoluent et qui se déplacent entre régions, mais les économies sont généralement moindres que celles d’une instance réservée utilisée à 100 %.
Dans la majorité des cas, un utilisateur qui connaît ses besoins à moyen terme gagnera à privilégier la réservation et à activer le savings plan seulement pour les charges variables.
Qu’est-ce qu’Azure Advisor ?
Azure Advisor est un assistant cloud personnalisé qui analyse en continu ta configuration Azure et ton usage pour te fournir des recommandations proactives afin d’optimiser :
la fiabilité
la sécurité
la performance
les coûts
l’excellence opérationnelle
Peut-on y créer des alertes concernant le besoin de RI ?
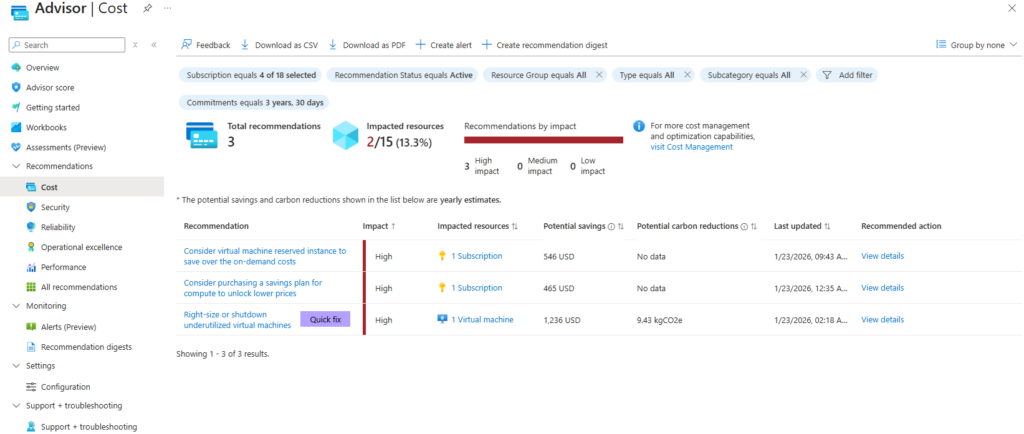
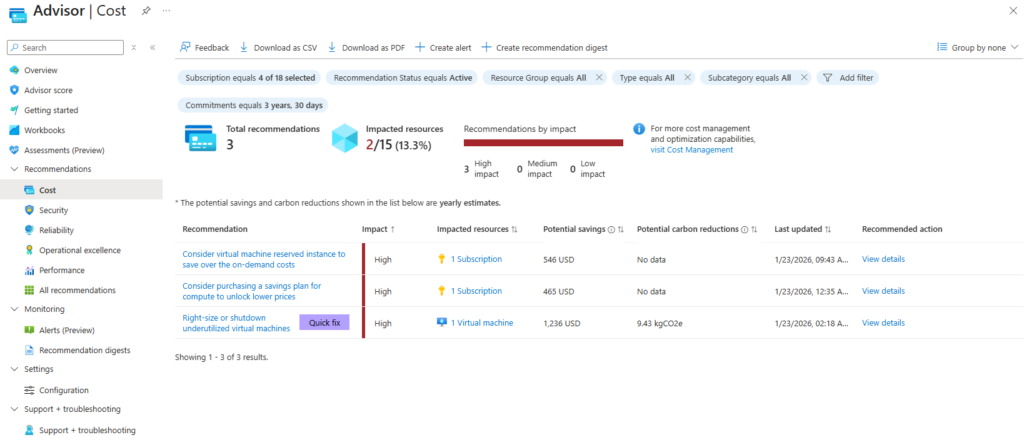
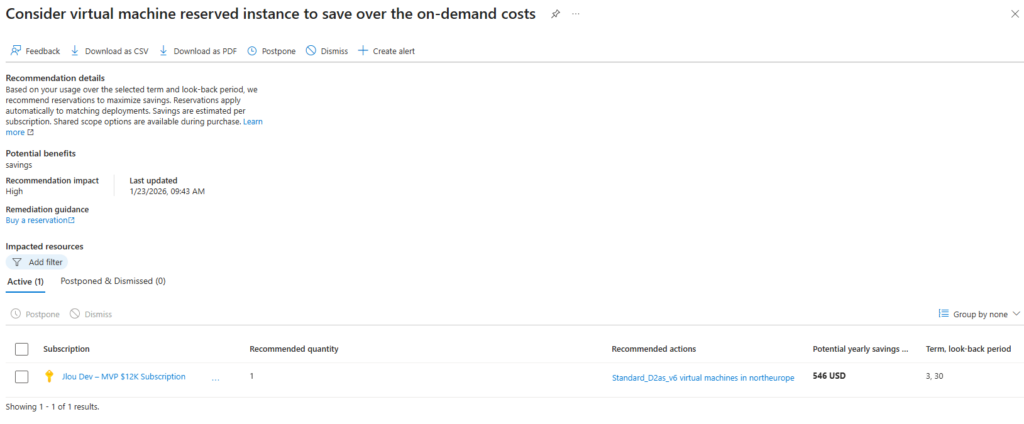
Comme montré dans une copie d’écran plus haut, Azure Advisor affiche des conseils sur les économies financières possibles sur votre infrastructure Azure. Ces conseils portent également sur l’achat d’instances réservées pour vos services de calcul.
Azure Advisor analyse l’utilisation de vos ressources et émet donc des recommandations lorsqu’il détecte des économies potentielles.
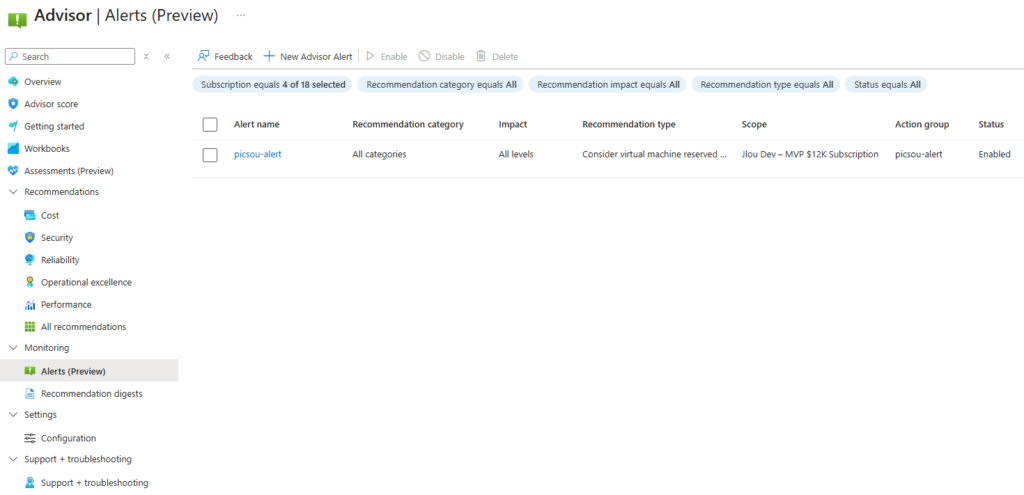
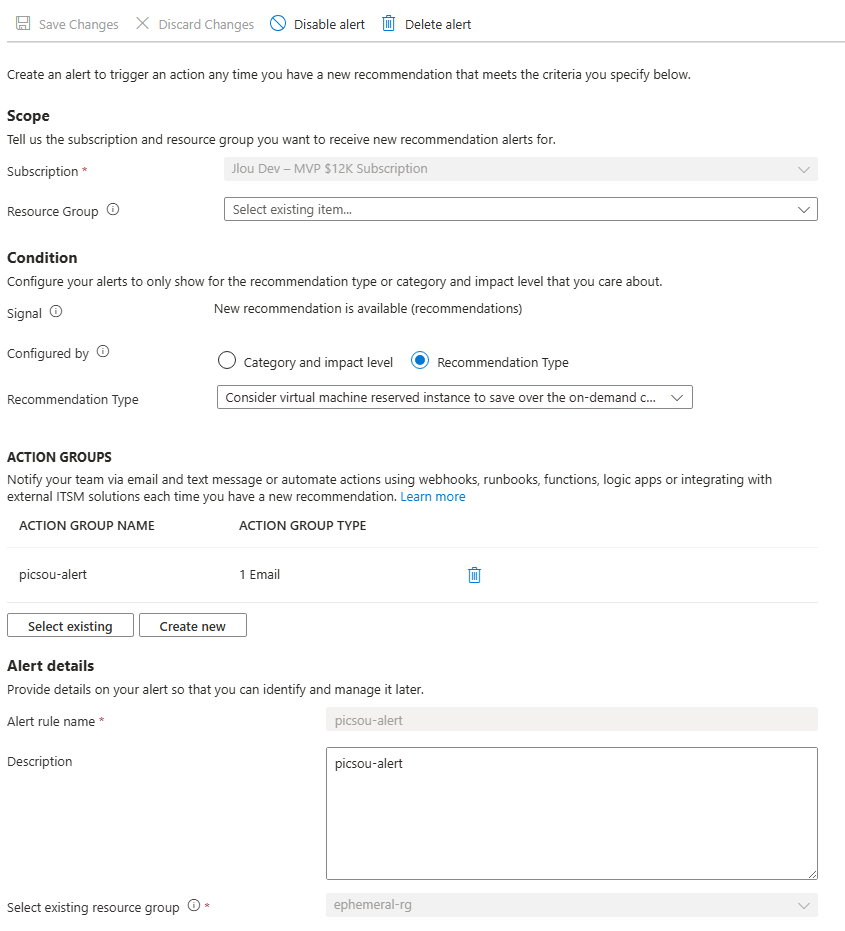
Lorsque Advisor identifie une nouvelle recommandation (par exemple l’achat d’une instance réservée), un événement est enregistré dans le journal d’activité. Il est possible de déclencher une alerte à chaque nouvelle recommandation afin d’être averti par courriel ou via un webhook :
Comme vous pouvez le voir, j’ai créé cette nouvelle alerte sur le type de recommandation suivant :
Consider virtual machine reserved instance to save over the on-demand costs
Comme les alertes configurées dans Azure Monitor, un groupe d’action peut y être affecté :
Une fois l’alerte en place, chaque nouvelle recommandation Advisor se traduira par une notification. Cela vous permet d’acheter les réservations appropriées dès qu’elles sont pertinentes et de réagir lorsque l’une d’elles arrive à expiration.
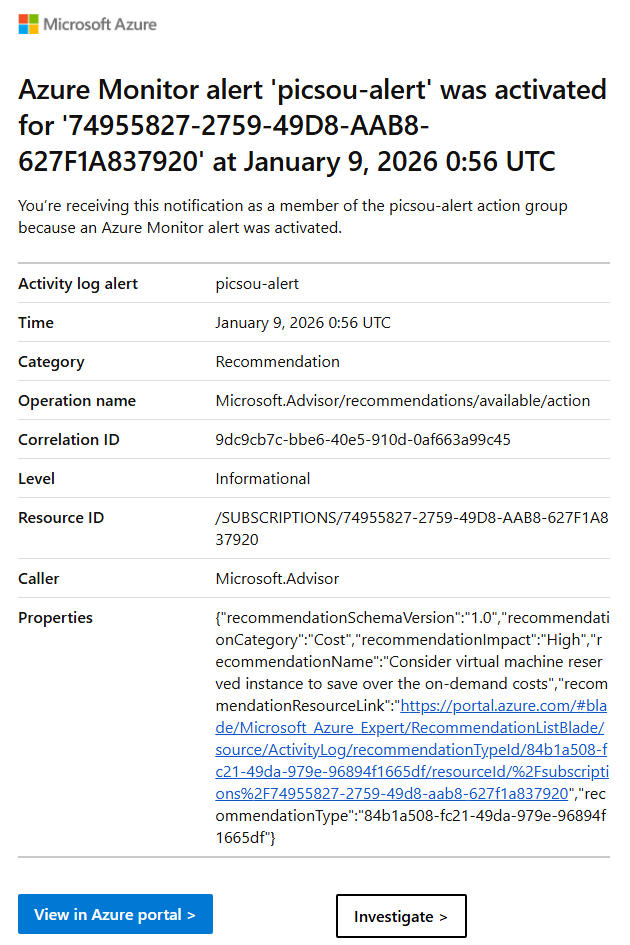
Ayant configuré une adresse email sur ce groupe d’action, et une fois l’alerte déclenchée, l’email suivant me parvient :
Un clic sur le lien présent dans l’email nous affiche la recommandation concernée dans le portail Azure :
Il ne me reste plus alors qu’à acheter, ou racheter, l’instance réservée appropriée 😎
Conclusion
La maîtrise des coûts est un volet essentiel de l’architecture cloud. En engageant vos ressources sur une durée ferme, les instances réservées vous permettent de réduire significativement vos dépenses tout en conservant la flexibilité de changer de taille ou d’échanger votre réservation en cas d’évolution de vos besoins.
Les fonctionnalités de renouvellement automatique garantissent la continuité des remises, et les alertes Azure Advisor vous aident à prendre les bonnes décisions au bon moment. En combinant analyse de l’utilisation (Advisor), estimation des coûts (calculateur de tarification) et stratégie d’engagement, vous disposez de tous les outils pour optimiser votre facture Azure.
Depuis plusieurs mois, je souhaitais pouvoir Windows 365 Link dans des conditions réelles d’utilisation. Cette opportunité m’a enfin permis de prendre le temps d’analyser la solution de manière concrète, au-delà des annonces marketing et des fiches techniques. L’objectif de cet article est de décortiquer Windows 365 Link sous différents angles : technique, licences, intégration à l’écosystème Microsoft, mais aussi usage quotidien.
Au fil des tests, j’ai cherché à comprendre dans quels scénarios ce type d’appareil apporte une réelle valeur, et dans quels cas d’usage il montre ses limites.
Cet article se veut à la fois factuel et basé sur un retour d’expérience, afin d’apporter une vision pragmatique de Windows 365 Link et de son positionnement dans une stratégie de poste de travail cloud.
Pour vous guider plus facilement dans cet article très long, voici des liens rapides :
Commençons par le tout début. Il était une fois… Windows 365 Link.
Qu’est-ce que Windows 365 Link ?
En quelques mots, Windows 365 Link est un thin client qui permet de se connecter directement à un Cloud PC Windows 365, vous offrant ainsi un moyen sécurisé et simple d’accéder à votre environnement cloud.
Windows 365 Link est le premier appareil matériel pc cloud qui permet aux utilisateurs de se connecter directement à leur machine virtuelle Cloud PC. Il s’agit d’une solution de pile complète et spécialement conçue par Microsoft.
Lorsque les utilisateurs se connectent à leur Windows 365 Link, ils sont connectés à leur machine virtuelle PC Windows 365 Cloud via le service Windows 365.
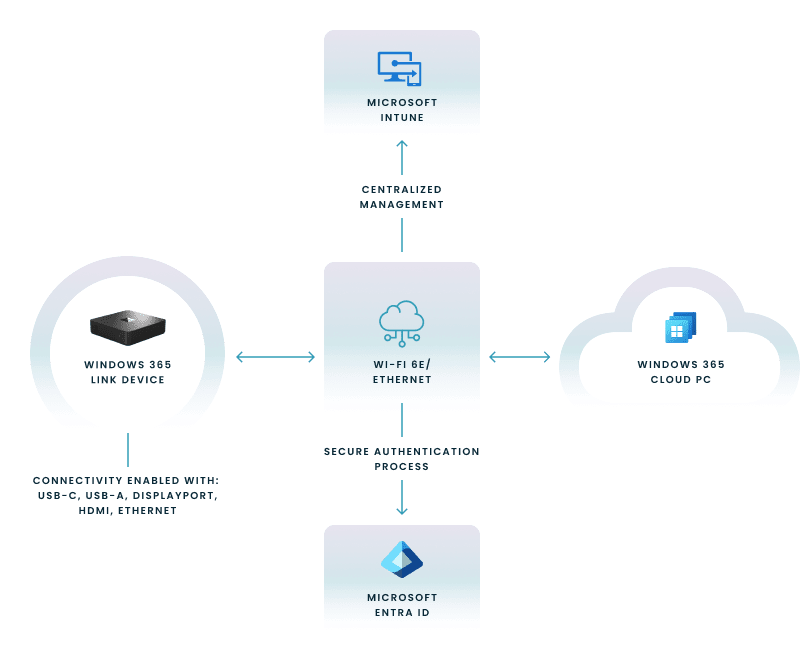
Nerdio illustre, à l’aide d’un schéma simple, la manière dont Windows 365 Link s’intègre à l’écosystème cloud de Microsoft
Quelles sont ses caractéristiques techniques ?
Windows 365 Link mesure 120 × 120 × 30 mm pour un poids de 418 grammes, et est compatible VESA 100 et verrous Kensington. De plus, il dispose des connectivités suivantes :
Sans fil :
Wi-Fi 6E
Bluetooth 5.3
Face avant :
USB-A (USB 3.2)
Prise audio jack
Face arrière :
USB-C (USB 3.2)
DisplayPort (1.4a, jusqu’à 4k 60 Hz)
HDMI (2.0b, jusqu’à 4k60)
Ethernet (1.0 Gbit/s)
Alimentation électrique (65 watts)
Unified Extensible Firmware Interface (UEFI) pour la réinitialisation
Côté matériel et logiciel, on retrouve les éléments suivants :
Windows 365 Link est conçu pour offrir un accès direct, sécurisé et dédié à un PC Cloud Windows 365, sans exécuter de système Windows local complet. L’objectif n’est pas de remplacer un PC traditionnel, mais de proposer un point d’accès matériel minimaliste, fortement intégré aux services Microsoft Entra ID, Intune et Windows 365.
En quoi est-il différent d’un PC pour accéder à Windows 365 ?
Contrairement à un PC Windows traditionnel, Windows 365 Link ne stocke pas de données utilisateur localement et ne permet pas d’exécuter d’applications hors du PC Cloud. Toute l’expérience utilisateur est déportée dans le Cloud PC, ce qui contribue à réduire la surface d’attaque locale et simplifie considérablement l’administration du poste.
Windows 365 Link peut-il remplacer un thin client tiers ?
Windows 365 Link se rapproche fonctionnellement d’un thin client, mais avec une intégration native et exclusive à Windows 365.
Il ne vise pas la polyvalence fonctionnelle (VDI multiples, accès Linux ou AVD générique), mais une expérience optimisée et contrôlée pour Windows 365 uniquement. Cela en fait un choix pertinent dans des environnements standardisés, mais plus restrictif que certaines solutions tierces.
Attention, ce point a déjà été mentionné à plusieurs reprises, mais mérite d’être rappelé : Windows 365 Link ne prend pas en charge Azure Virtual Desktop ni Microsoft Dev Box.
Dans quels scénarios est-il le plus pertinent ?
Windows 365 Link est particulièrement adapté aux environnements à postes partagés, aux scénarios Frontline, aux centres de contact, aux environnements industriels ou aux sites distants où la simplicité de déploiement, la sécurité et la rapidité de remplacement du matériel sont prioritaires.
Voici quelques exemples de cas d’usage :
Postes partagés
Permettre aux collaborateurs en mode hybride de retrouver instantanément leur environnement de travail
Accès rapide et sécurisé à leur Cloud PC Windows 365, sans dépendance au poste physique
Idéal pour les environnements à forte rotation d’utilisateurs ou à postes non attribués
Centres d’appels
Démarrage en quelques secondes vers un Cloud PC Windows 365
Expérience utilisateur fluide et réactive, adaptée aux usages intensifs (voix, CRM, applications métiers)
Aucune donnée stockée localement sur le terminal, réduisant les risques de fuite d’informations
Authentification sans mot de passe via Microsoft Entra ID
Espaces spécialisés
Accès sécurisé aux outils et aux données dans des environnements contrôlés
Utilisation dans des lieux spécifiques tels que :
laboratoires
zones logistiques ou arrière-boutiques
centres de formation
accueils et réceptions
Frontline et métiers spécifiques
Mise à disposition d’un poste de travail Cloud sécurisé pour :
travailleurs de première ligne en milieu industriel
agents d’accueil
personnels en environnement scientifique ou de recherche
Réduction des contraintes matérielles locales et simplification du support
Métiers à forte sensibilité des données
Accès distant sécurisé pour des profils tels que :
analystes financiers
consultants
chargés de clientèle bancaire
agents de support client
téléconseillers / télévendeurs
Centralisation des données dans le Cloud PC, limitant les risques de fuite ou de perte
Dans quels cas n’est-il pas recommandé ?
Windows 365 Link est peu adapté aux utilisateurs nomades, aux scénarios nécessitant un fonctionnement hors ligne, ou aux usages impliquant des applications locales spécifiques ou des périphériques avancés non pris en charge. Il n’est pas non plus destiné à remplacer un poste de travail puissant pour des usages lourds locaux.
De ce fait, la comparaison entre Windows 365 Link + Cloud PC et un ordinateur portable moyen de gamme peut soulever des questions économiques :
Critère
Laptop moyen de gamme
Windows 365 Link + Windows 365
Coût matériel initial
~800 € (laptop)
365 € (Windows 365 Link)
Durée de vie
3–4 ans
4–5 ans (device statique)
Coût licence Windows 365
0 €
60 €/mois → 2 160 € sur 3 ans
Déploiement initial
Imaging, drivers, apps
Provisioning automatique
Support & maintenance (3 ans)
30 h × 60 €/h = 1 800 €
30 h × 30 €/h = 900 €
Données locales
Oui
Non
Exposition en cas de perte/vol
Élevée
Très faible (données Cloud)
Continuité de service
Dépend du matériel
Reconnexion immédiate
Coût total estimé sur 3 ans
~2 600 €
~3 425 €
Lecture du ROI
Référence
Surcoût ~825 € / poste sur 3 ans
Windows 365 n’est donc pas nécessairement moins coûteux par défaut, le ROI devient positif si :
Postes partagés / Frontline / hot desk
Réduction forte du support de proximité
Exigences sécurité élevées
Besoin de remplacement immédiat du poste
Sinon, sur poste dédié standard, l’ordinateur portable reste économiquement plus avantageux.
Permet-il de réduire les coûts IT et le provisioning ?
Dans les usages recommandés listés plus haut, Windows 365 Link peut contribuer à une réduction des coûts liés au support, au renouvellement matériel et à la gestion des images système. En revanche, il renforce la dépendance au modèle de licences Windows 365, qui doit être évalué globalement dans la stratégie poste de travail.
Windows 365 Link simplifie le provisioning, le remplacement des appareils et l’exploitation quotidienne grâce à l’enrôlement automatique Entra ID et Intune. L’administration est centralisée, avec moins d’interventions locales, ce qui facilite la standardisation et la gouvernance du poste de travail.
Quels sont ses bénéfices de sécurité ?
L’absence de données persistantes locales, l’authentification systématique via Microsoft Entra ID et l’intégration native avec les stratégies d’accès conditionnel renforcent la posture de sécurité globale. En cas de perte ou de vol du matériel, aucune donnée utilisateur n’est exposée localement.
En centralisant l’exécution et les données dans le Cloud PC, Windows 365 Link limite les impacts d’incidents matériels, de compromission locale ou de mauvaise configuration utilisateur. La gestion centralisée via Intune permet également d’appliquer des politiques de sécurité homogènes et cohérentes.
Quels sont les licences nécessaires pour l’utiliser ?
Voici les exigences connues pour pouvoir utiliser Windows 365 Link :
Exigences de licence Windows 365
Exigences Microsoft Entra ID
Exigences Microsoft Intune
Prenons le temps de comprendre en détail toutes ces exigences.
Exigences de licence Windows 365 :
Windows 365 Link n’introduit aucune nouveauté du côté des licences. On reste strictement dans le périmètre Windows 365.
Sans licence Windows 365 valide assignée à l’utilisateur, votre Windows 365 Link n’est pas utilisable : la connexion à un autre PC est tout simplement impossible, même à un environnement Azure Virtual Desktop.
À noter que Windows 365 Link accepte tous les types de licences Windows 365 :
Windows 365 Entreprise
Windows 365 Business
Windows 365 Frontline
Exigences Microsoft Entra ID :
Avec Windows 365 Link, un point apparaît rapidement comme non négociable : Windows 365 Link doit être Microsoft Entra joined ou Entra hybrid joined.
L’utilisateur qui effectue cette jonction doit bien évidemment avoir les droits pour joindre des appareils au tenant :
Lors de la jonction à Entra ID, le device s’enrôle automatiquement dans Intune. Et là, point important : l’utilisateur qui joint le device doit disposer d’une licence Microsoft Entra ID Premium, sinon l’enrôlement automatique échoue.
L’enrôlement automatique dans Intune dépend du paramétrage suivant :
Exigences Microsoft Intune :
L’enrôlement Intune des Windows 365 Link se fait pendant l’OOBE, sans action manuelle supplémentaire grâce aux mécanismes d’Entra.
Là encore, l’utilisateur qui joint le Windows 365 Link doit :
Disposer d’une licence Microsoft Intune
Avoir le droit d’enrôlement
Ne pas être bloqué par des restrictions d’enrôlement Intune :
Concrètement, voici ce que la donne lors du premier démarrage du Windows 365 Link :
L’utilisateur démarre et s’authentifie pour la toute première fois :
Le Windows 365 Link s’enrôle automatiquement dans Entra :
Puis l’enrôlement automatique MDM prend le relais pour l’ajouter dans Intune :
Avant d’arriver à cela avec votre Windows 365 Link, prenons le temps de passer en revue toutes les étapes.
Où peut-on l’acheter ?
Sa disponibilité dépend des pays et des vagues de lancement définies par Microsoft. L’appareil est proposé via des partenaires et revendeurs agréés Microsoft, comme TD SYNNEX selon les régions concernées.
À ce jour, la disponibilité semble s’élargir progressivement avec les vagues successives de déploiement, parfois désignées comme Wave 1 ou Wave 2. Windows 365 Link est actuellement disponible pour les pays suivants :
États-Unis
Australie
Canada
Danemark
France
Allemagne
Inde
Japon
Pays-Bas
Nouvelle-Zélande
Suède
Suisse
Royaume-Uni
Dans les prochains mois, Il devrait l’être par la suite aussi disponible dans :
Belgique
Finlande
Irlande
Italie
Pologne
Singapour
Espagne
Pour connaître les options d’achat exactes, il est recommandé de se rapprocher d’un partenaire Microsoft local ou de consulter les annonces officielles de Microsoft pour votre zone géographique.
Maintenant que les principaux aspects fonctionnels, techniques et de licences autour de Windows 365 Link ont été abordés, il est temps de passer à la partie plus concrète.
La section suivante détaille pas à pas les différentes étapes de configuration et de prise en main de Windows 365 Link, depuis la préparation de l’environnement jusqu’aux premiers tests en conditions réelles :
Dans mon environnement de test, j’ai déjà configuré plusieurs polices de provisionnement afin de créer mes Cloud PCs qui vont me servir durant mes tests :
Les Cloud PCs étant correctement déployés, une exigence particulière concerne toutefois le SSO avec Entra. Pour être plus clair, je vais maintenant repasser en détail sur toutes les étapes pour correctement configurer le SSO.
Etape I – Configuration du Single Sign-On :
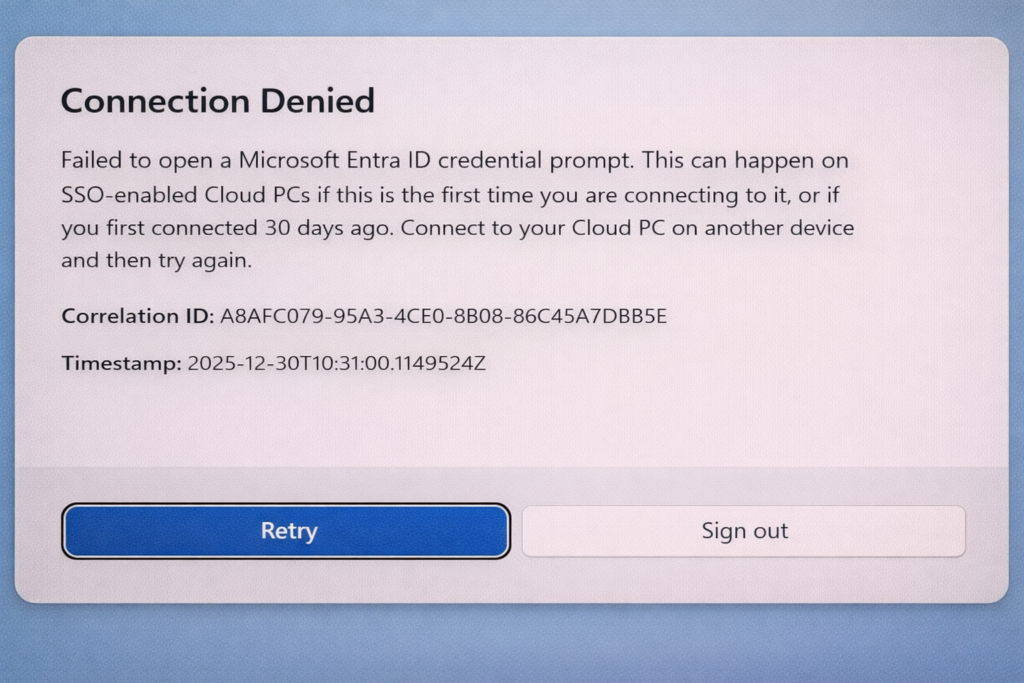
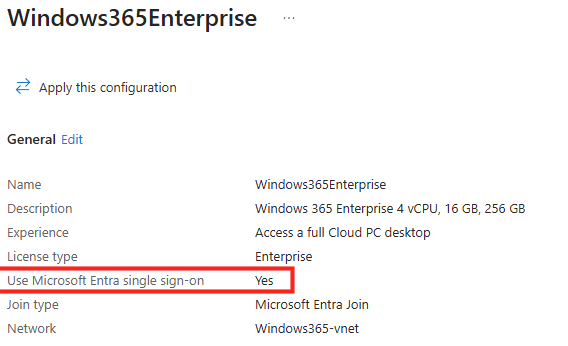
Windows 365 Link repose entièrement sur le mécanisme Single Sign-On via Microsoft Entra ID. Autrement dit : si le SSO n’est pas activé sur le Cloud PC, la connexion de votre utilisateur risque d’échouer :
Pour activer le SSO, il sera nécessaire de vérifier, et de modifier si nécessaire, la police de provisionnement de vos Cloud PC, puis de recréer au besoin de nouveaux Cloud PCs si ces derniers ont été créés avant cette modification :
Voici l’option SSO dans la police de provisionnement des Cloud PCs qui doit être cochée :
L’étape suivante consiste à supprimer la demande de consentement SSO côté Microsoft Entra ID, dont la configuration repose sur des principaux de service :
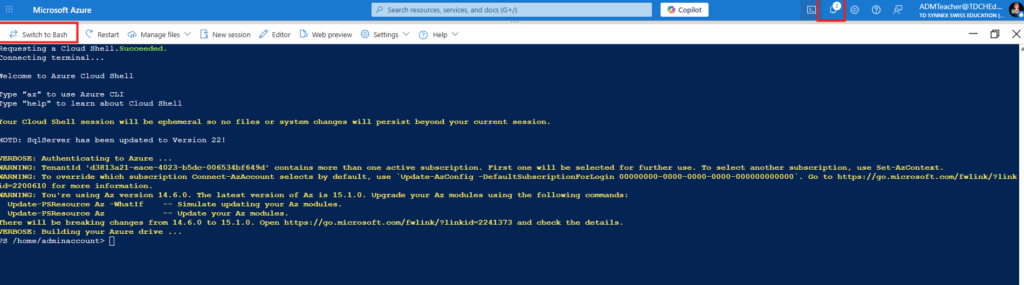
Commençons par autoriser Microsoft Entra dans l’authentification pour Windows sur le tenant. Pour cela, j’utilise la console PowerShell d’Azure Cloud Shell, accessible depuis le portail Azure :
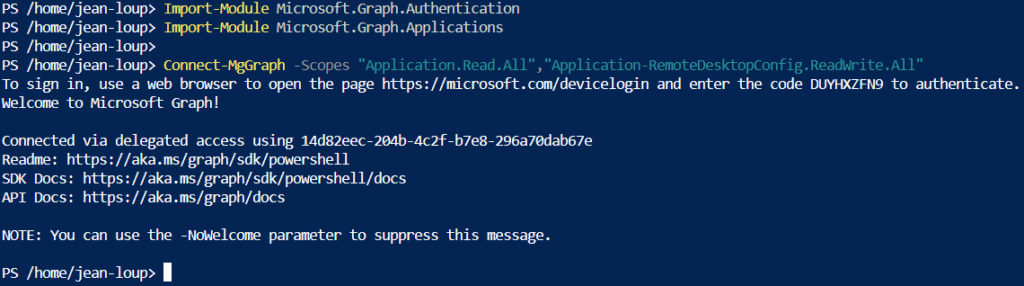
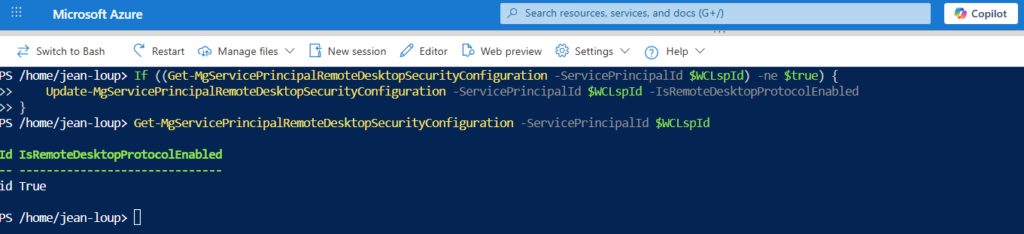
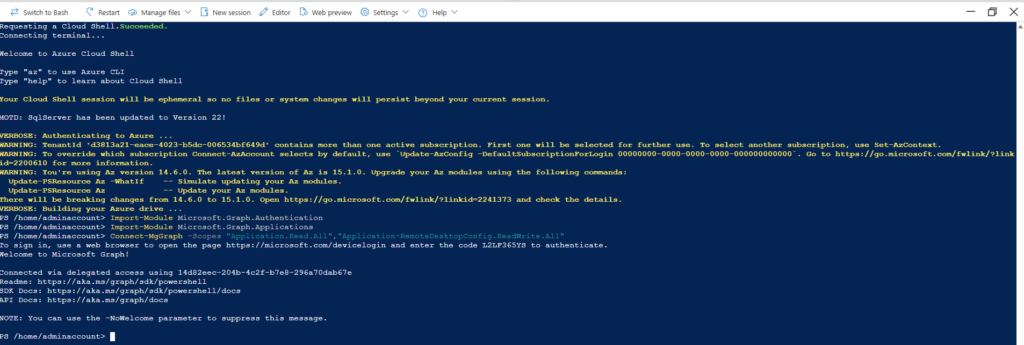
J’importe les deux modules Microsoft Graph suivants, puis je me connecte avec le compte aux permissions appropriées :
Je modifie la propriété isRemoteDesktopProtocolEnabledtruesur True, puis je vérifie que la propriété isRemoteDesktopProtocolEnabledest correctement définie :
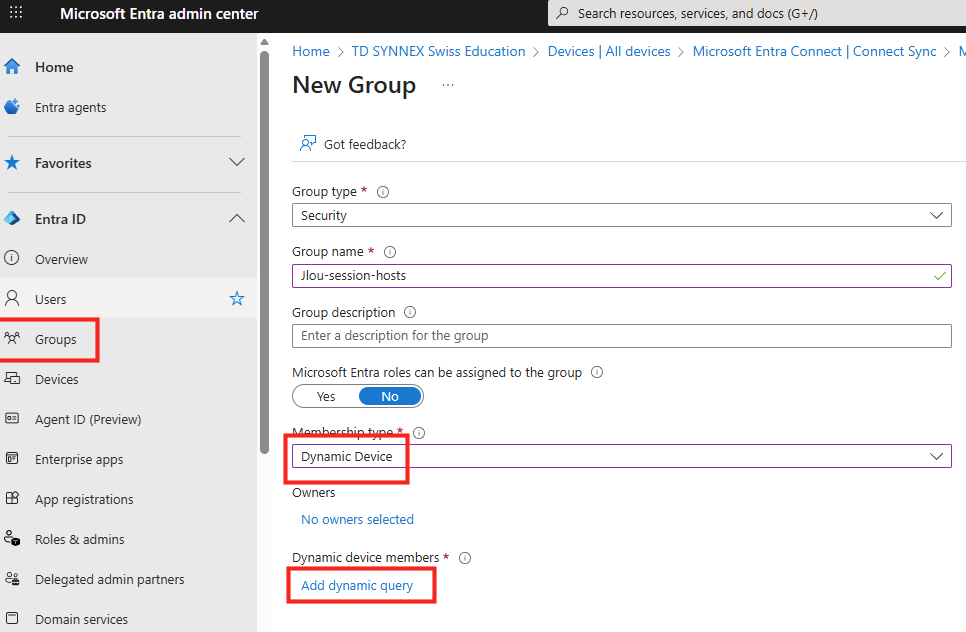
Depuis le portail Intune, je crée ensuite un groupe contenant les Cloud PCs :
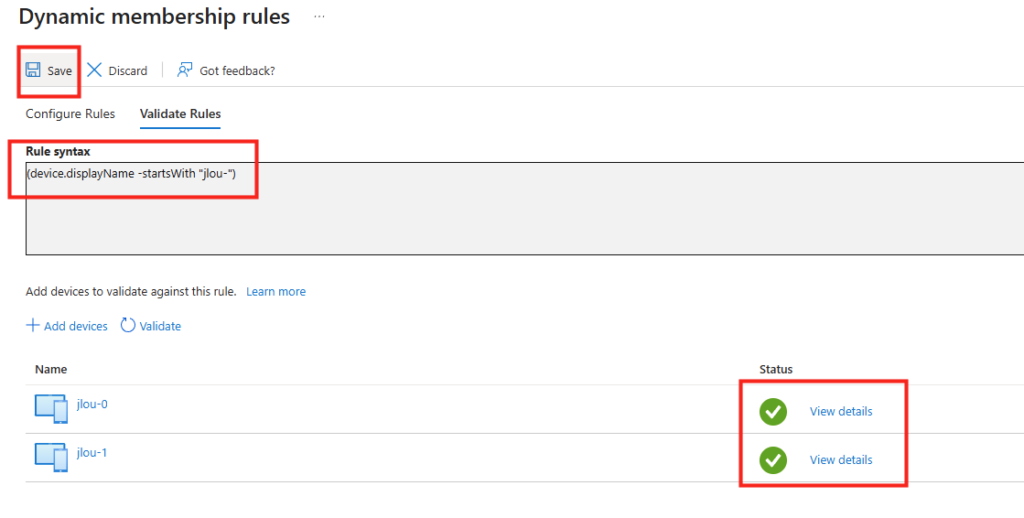
J’utilise une requête dynamique pour ajouter automatiquement mes prochains Cloud PCs au groupe :
Enfin, toujours dans la même session d’Azure Cloud Shell, j’ajoute l’ID de groupe à une propriété sur le principal du service SSO Windows Cloud Login :
Tout est maintenant en place pour tester la première authentification sur votre Windows 365 Link.
Etape II – Test de la première connexion Windows 365 Link :
La vidéo suivante correspond à la première connexion avec succès de mon utilisateur de test à son Windows 365 Link :
J’ai réalisé ensuite une seconde vidéo montrant plusieurs scénarios de connexion et de bascule d’utilisateurs avec Windows 365 Link :
Le premier test illustre la connexion d’un utilisateur unique à différents Cloud PC Windows 365 qui lui sont attribués. L’objectif est d’observer le temps de connexion, la fluidité du changement de Cloud PC, ainsi que l’efficacité globale du processus d’authentification.
Le second test se concentre sur un scénario de type pool partagé, comparable à un usage Windows 365 Frontline, où plusieurs utilisateurs se connectent successivement au sein d’un même pool de Cloud PC. Ce scénario permet d’analyser le comportement de l’authentification, la gestion des sessions et la rapidité de bascule entre utilisateurs.
Ces démonstrations offrent un retour concret sur les performances et l’expérience utilisateur, avant d’aborder les aspects de configuration et d’administration via Intune.
Travis nous a d’ailleurs fait une excellente vidéo sur ce sujet disponible juste ici :
Une fois ces premiers tests de connexion réalisés, on peut imaginer d’autres tâches ou configurations que l’on peut faire autour de son Windows 365 Link.
Mais avant cela, je vous conseille de commencer par créer un filtre d’assignation Intune pour cibler uniquement les Windows 365 Link dans vos futures polices de configuration.
Etape III – Création d’un filtre d’assignation Intune :
Depuis le portail Intune, je commence par créer un filtre d’assignation, qui me sera très utile pour configurer les Windows 365 Link par la suite :
Je nomme ce filtre avec comme plateforme Windows 10 et +, puis je clique sur Suivant :
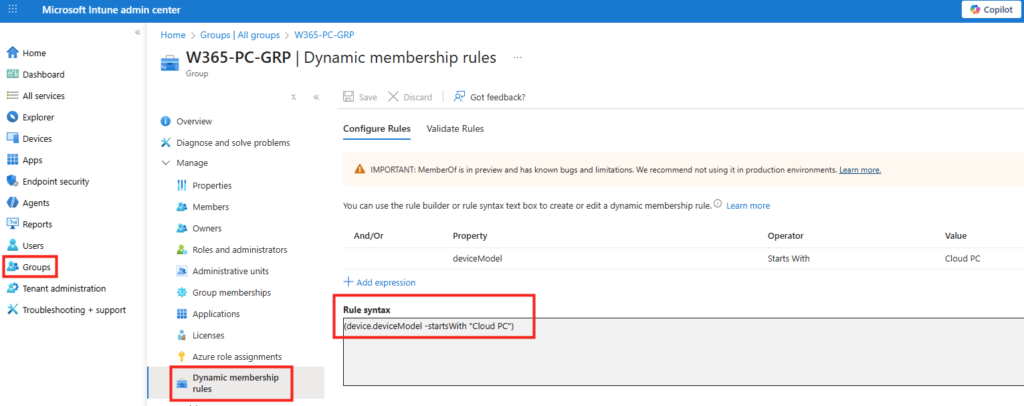
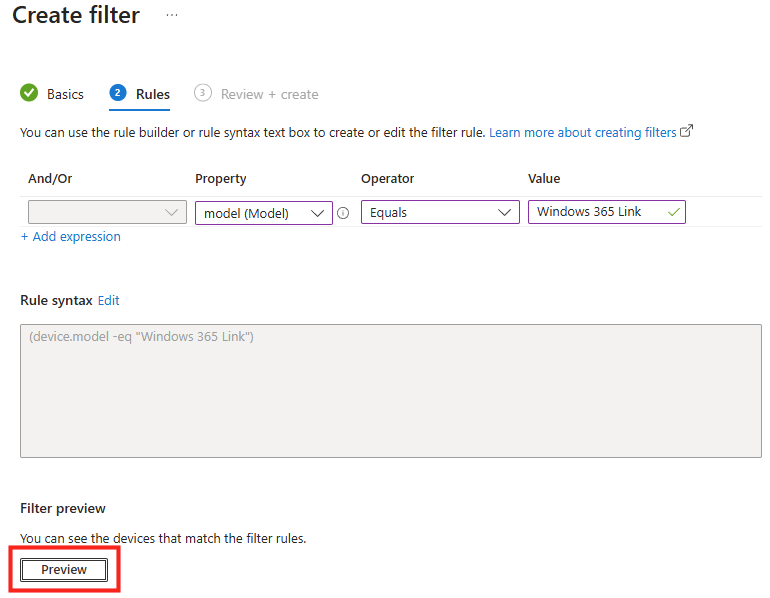
Je spécifie la règle de filtrage selon la propriété suivante afin de ne prendre en compte que les appareils Windows 365 Link, puis je clique sur Prévisualiser :
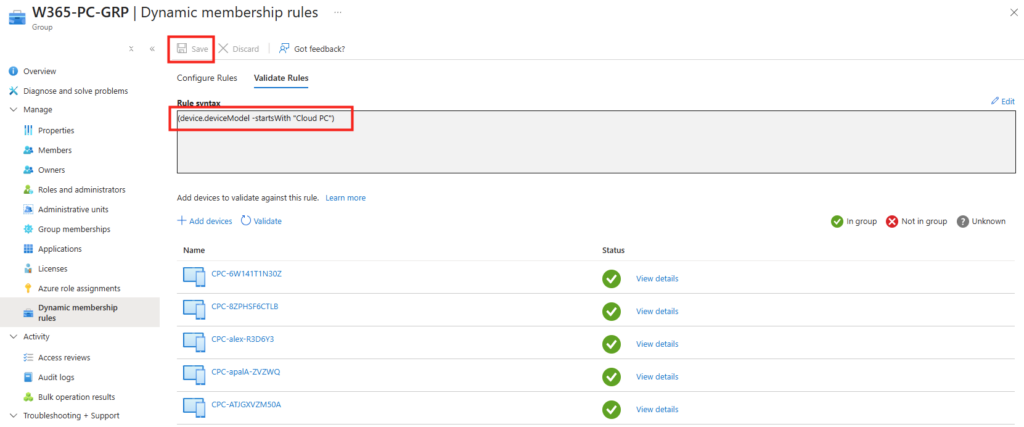
Si des Windows 365 Link sont déjà présents, je devrais voir ces derniers apparaître :
Enfin je confirme la création du filtre :
Mon filtre est maintenant en place, je vais pouvoir commencer à effectuer quelques réglages, comme la détection automatique du fuseau horaire.
Etape IV – Configuration automatique du fuseau horaire :
Au démarrage de votre Windows 365 Link, l’heure qui s’affiche n’est peut-être pas la bonne :
Les appareils Windows 365 Link peuvent rencontrer des problèmes de fuseau horaire si la détection automatique n’est pas autorisée. Il est possible de forcer l’utilisation du fuseau horaire local en autorisant l’accès à la localisation via Microsoft Intune.
Pour cela, connectez-vous au portail Intune, puis dirigez-vous vers le menu suivant :
Sélectionnez le type de profil suivant :
Renseignez les informations suivantes, puis cliquez sur Suivant :
Nom : Windows 365 Link – Time Zone Detection
Description : Autorise l’accès à la localisation afin de permettre la détection automatique du fuseau horaire sur les appareils Windows 365 Link.
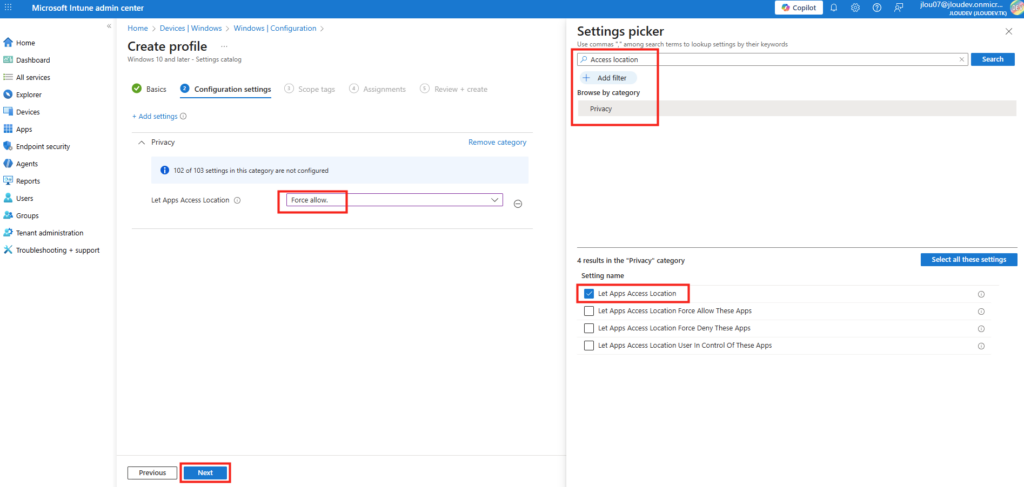
Recherchez Access location, puis sélectionnez la catégorie Privacy, configurez comme ceci, puis cliquez sur Suivant :
Ajoutez les Scope tags nécessaires selon votre organisation, puis cliquez sur Suivant :
Dans Assignments, ciblez les appareils Windows 365 Link selon la méthode suivante, puis cliquez sur Suivant :
Par exemple, en utilisant All devices
En appliquant un Include filter basé sur un filtre de type Windows 365 Link
Vérifiez la configuration, puis cliquez ici pour déployer la stratégie :
Quelques minutes plus tard, l’accès à la localisation est autorisé, Windows 365 Link peut détecter automatiquement le fuseau horaire local, et affiche l’heure correcte selon la localisation de l’utilisateur :
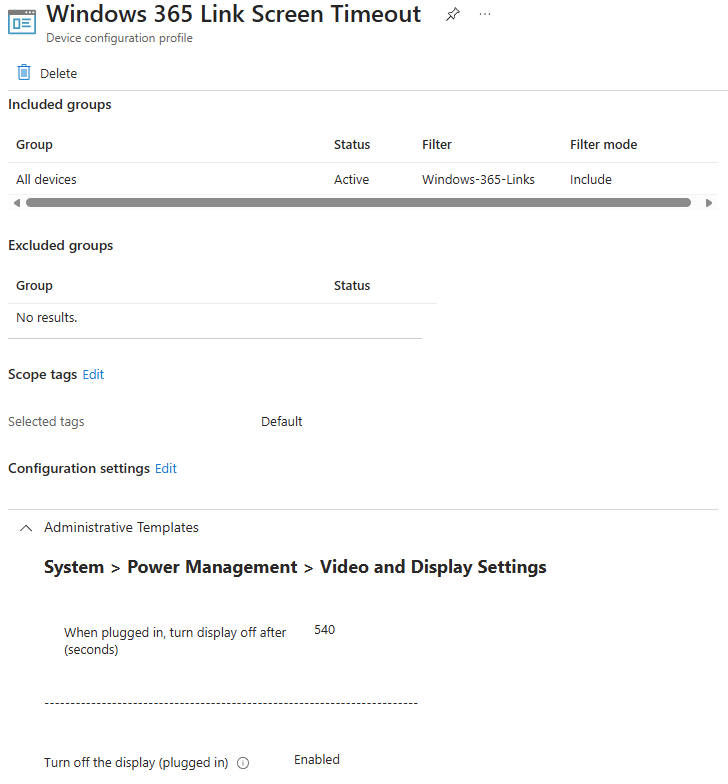
Etape V – Modification du délai d’extinction de l’écran :
Par défaut, les appareils Windows 365 Link éteignent l’écran après environ cinq minutes d’inactivité. Ce comportement est assimilé à un verrouillage local : lorsque l’utilisateur réactive l’appareil, l’écran de connexion s’affiche.
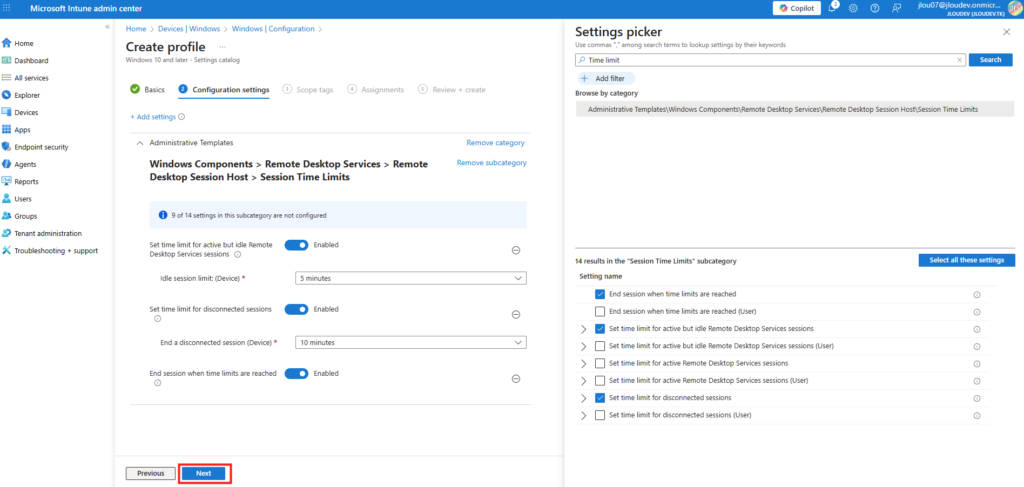
Comme pour l’heure, la configuration se fait via une police de configuration Intune. Dans mon cas je configure l’extinction de l’écran après 9 minutes d’inactivité :
Travis nous a encore fait une excellente seconde vidéo sur ce sujet :
Etape VI – Modification des délais de déconnexion des sessions :
Comme Microsoft le recommande, est-il possible de raccourcir (mais pas de rallonger ?) les temps définis par défaut dans le cas de sessions Windows 365 inactives ou déconnectées :
Par défaut, Windows 365 PC Frontline conservent la session utilisateur active jusqu’à ce que :
En mode dédié : Le PC cloud est inactif pendant 30 minutes.
En mode partagé : Le PC cloud est inactif pendant 15 minutes.
Deux minutes avant la limite de temps d’inactivité, l’utilisateur reçoit une notification avec une boîte de dialogue.
Cette stratégie force la fermeture (log off) des sessions Windows 365 afin d’éviter :
Les sessions laissées ouvertes sans activité
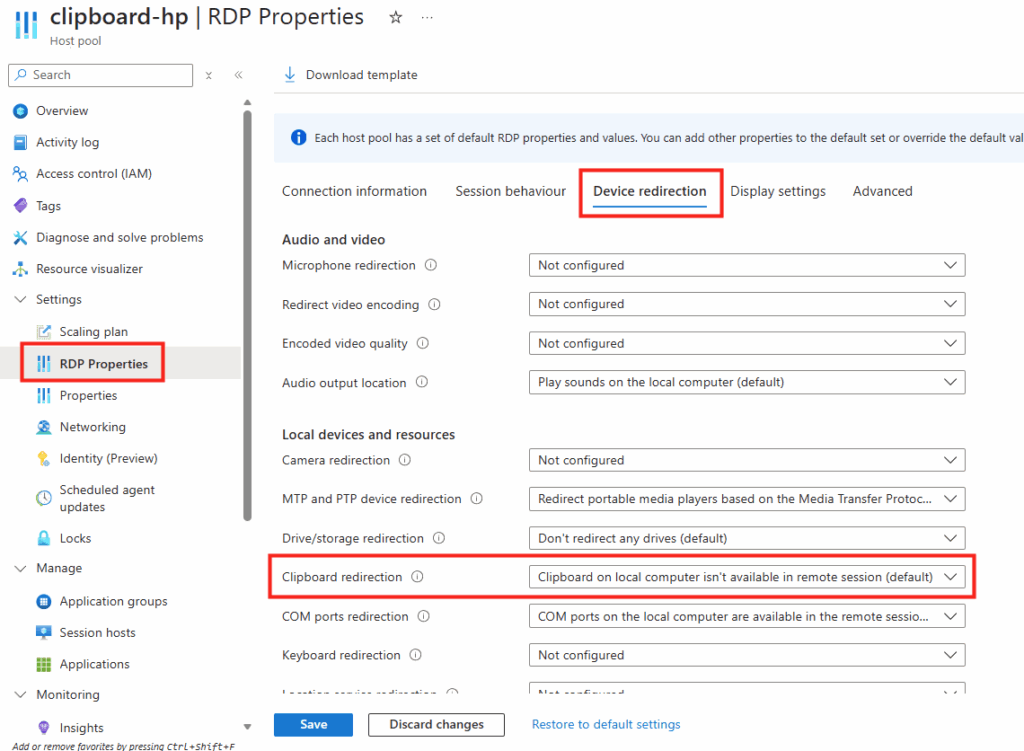
Les sessions bloquées après une coupure réseau
La consommation inutile de capacité (critique en Frontline partagé)
Elle remplace alors entièrement le comportement par défaut des services Windows 365 expliqués plus haut, à la condition que les temps indiqués ne soient pas supérieurs :
Par contre, à la différence des configurations précédemment appliquées sur les Windows 365 Link, j’ai appliqué cette nouvelle police sur filtre comprenant uniquement les Cloud PCs Frontline comme ceci :
Le tableau ci-dessous résume les différents événements observés et les mécanismes impliqués dans ma configuration :
Étape
Heure
Événement
Mécanisme responsable
Login utilisateur
08h47
Connexion au Cloud PC Frontline
Session RDS active
Idle atteint
08h52
Message “You will be signed out in 2 minutes”
Idle session RDS (5 min)
Log off
08h54
Déconnexion automatique (sign out)
End session when time limits are reached
Écran noir
09h03
Extinction automatique de l’écran
Policy Display Windows 365 Link (9 min)
Etape VII – Connexion automatique sur un Cloud PC :
Windows 365 Link permet également d’activer des mécanismes de connexion automatique et d’authentification sans mot de passe (passwordless), afin de simplifier encore davantage l’accès au Cloud PC pour l’utilisateur final.
Dans ce scénario, l’utilisateur n’a pas besoin de saisir manuellement son identifiant, ce qui rend l’expérience de connexion particulièrement fluide :
Pour cela, je suis passé par la création d’une police de configuration personnalisé avec les paramètres OMA-URI suivants :
Nom : Activer les clés de sécurité FIDO pour la connexion à Windows
OMA-URI : ./Device/Vendor/MSFT/PassportForWork/SecurityKey/UseSecurityKeyForSignin
Type de données : Integer
Valeur : 1
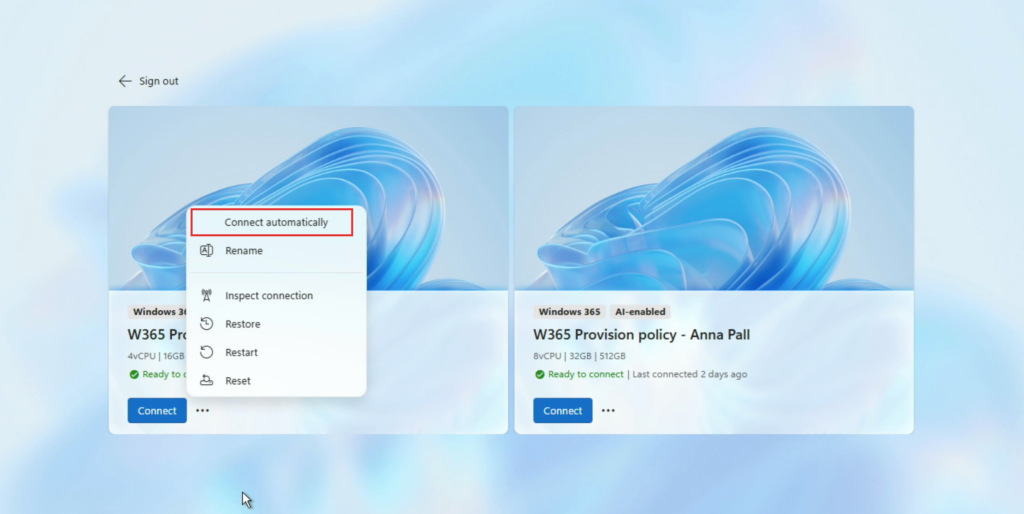
Il est également possible de configurer Windows 365 Link pour qu’il se connecte automatiquement à un Cloud PC Windows 365 spécifique :
Cette option est particulièrement adaptée aux environnements à poste dédié ou aux usages standardisés. On y retrouve les fonctionnalités habituelles, comme la restauration ou la réinitialisation de la connexion.
Enfin, un bouton Annuler permet d’annuler la connexion automatique à ce Cloud PC. Cette action redirige l’utilisateur vers l’écran de sélection afin de lui permettre de choisir un autre Cloud PC Windows 365 auquel se connecter :
Ces options permettent d’adapter finement l’expérience de connexion selon que l’on se trouve dans un scénario à poste dédié ou à usage partagé.
Etape VIII – Restauration de mode usine :
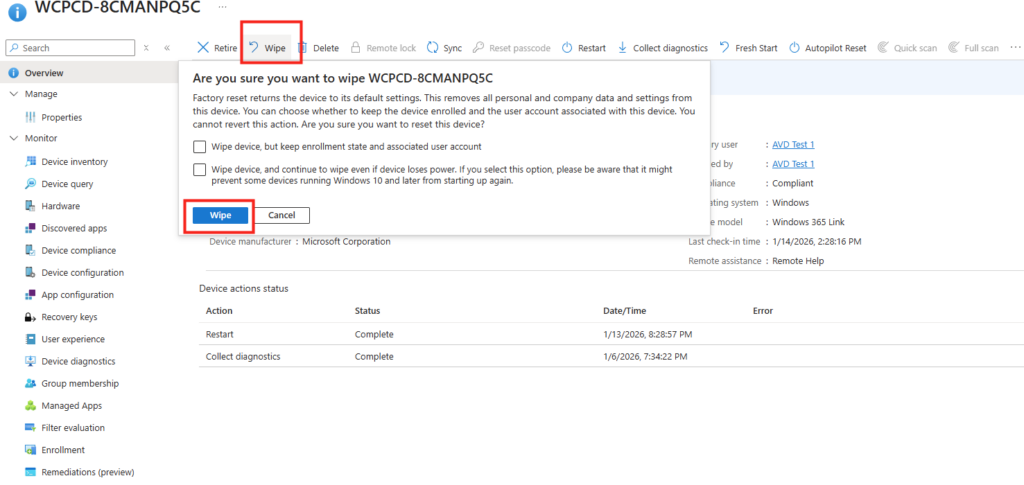
Si nécessaire, Microsoft propose une restauration en mode usine des Windows 365 Link depuis le portail Intune. Comme beaucoup de postes gérés en MDM sous Intune, cette fonction très utile permet de réinitialiser complètement l’appareil à distance, en supprimant toute configuration et toute association utilisateur, afin de le reprovisionner proprement.
Voici d’ailleurs une vidéo qui montre le processus en entier, d’environ 30 minutes (accéléré), sur un Windows 365 Link :
Etape IX – Test de Microsoft Teams :
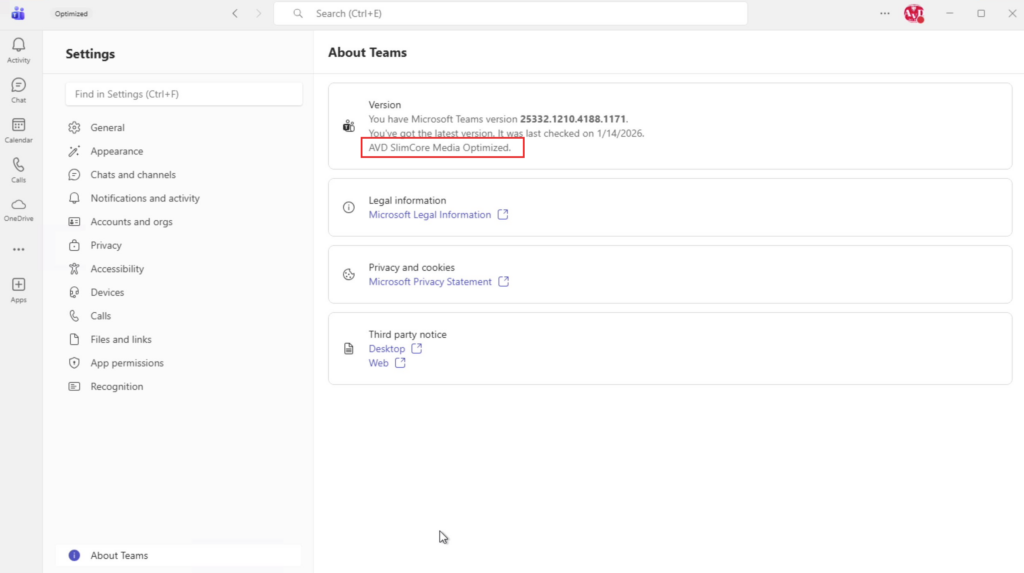
J’ai réalisé un test Microsoft Teams avec Windows 365 Link et j’ai été très satisfait de l’expérience globale, tant sur la qualité du rendu que sur la fluidité du partage d’écran et des flux audio/vidéo.
Un tour dans les paramètres de Teams confirme que le mode Media Optimized (SlimCore) est bien actif avec Windows 365 Link :
Pour plus de détails sur SlimCore et son fonctionnement côté AVD / Windows 365, voir cet article dédié sur mon blog.
Ce test rapide illustre le rendu réel de Microsoft Teams en conditions d’usage, du partage d’écran et des flux caméra, en mettant en évidence que le traitement (CPU) est effectué localement sur le Windows 365 Link et non sur le Cloud PC :
Et voici encore une autre vidéo faite cette fois avec une vidéo YouTube :
Après ces différents tests et configurations, il est possible de tirer plusieurs enseignements concrets sur l’usage de Windows 365 Link.
Conclusion
En conclusion, et après plusieurs jours d’utilisation et de tests dans des scénarios réels, Windows 365 Link s’est montré convaincant à l’usage quotidien.
Les performances observées, la simplicité d’accès au Cloud PC et la stabilité globale de l’expérience m’ont laissé une impression très positive au quotidien. Dans certains cas, j’ai pu avoir des doutes quant à la pertinence de l’appareil, notamment pour des scénarios où ses limites fonctionnelles peuvent apparaître.
Néanmoins, pour les cas d’usage évoqués plus haut (postes partagés, environnements Frontline, centres de contact ou contextes à forte exigence de sécurité), Windows 365 Link apporte une réelle valeur.
C’est un produit cohérent, bien positionné dans la stratégie Cloud-first de Microsoft, et je suis personnellement très satisfait d’avoir pu le tester dans des conditions concrètes et représentatives.
Alors, Windows 365 Link est-il un produit de niche ou le début d’une nouvelle norme ?
Windows 365 Link s’inscrit dans la stratégie Cloud-first de Microsoft et cible des usages bien définis. Il ne remplace pas tous les postes de travail, mais propose une alternative cohérente dans les environnements où la simplicité, la sécurité et la centralisation priment sur la flexibilité locale.
Enfin, retrouvez-moi et Arnaud et Arnaud dans un futur AzuReX prévu le 29 janvier prochain à 13 heures, dont l’inscription se passe juste ici 😎
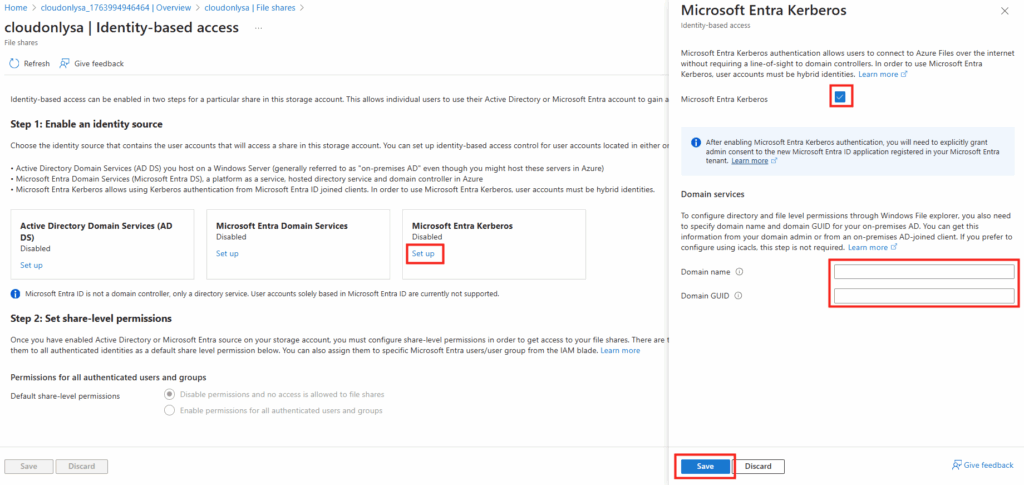
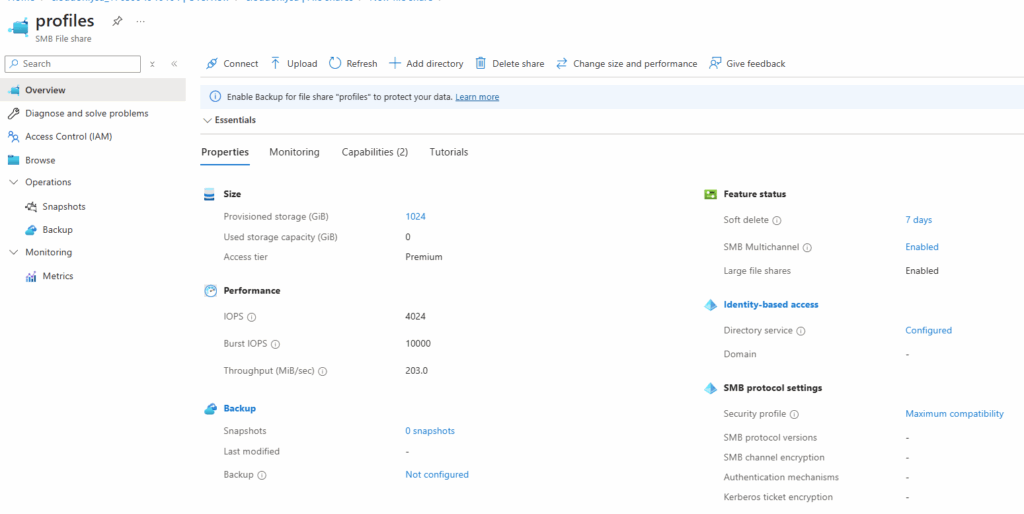
Azure Virtual Desktop est souvent présenté comme une solution offrant un Single Sign-On “natif”. Dès que l’on sort d’un environnement cloud-only pour entrer dans un contexte hybride, les mécanismes d’authentification deviennent toutefois plus complexes, et parfois déroutants. Entre Microsoft Entra ID, Active Directory, Kerberos, PRT, Seamless SSO et Cloud Kerberos Trust, il est facile de confondre des briques aux noms proches, mais qui n’interviennent ni au même moment ni au même niveau.
Dans un précédent article, j’avais détaillé la mise en place du SSO Azure Virtual Desktop dans un environnement cloud-only.
Dans cet article, j’ai volontairement changé de contexte pour travailler sur un environnement hybride. L’objectif de cet article est de répondre aux trois questions suivantes :
Clarifier les mécanismes d’authentification (PRT, Seamless SSO, Kerberos, etc.)
Montrer pas à pas pourquoi certaines étapes sont indispensables pour obtenir un SSO réellement transparent dans AVD.
A quoi sert le Seamless SSO disponible dans Entra Connect Sync ?
Avant d’aborder la configuration et les tests, il est utile de poser le cadre : comprendre quels mécanismes d’authentification sont utilisés, à quel moment, et pourquoi certains fonctionnent seuls alors que d’autres doivent être combinés.
Cette FAQ a pour objectif de lever les confusions les plus fréquentes autour des tokens, du Kerberos, et du Single Sign-On dans un environnement Microsoft Entra hybride.
Quels sont les tokens utilisés par Microsoft Entra ID ?
Microsoft Entra ID utilise plusieurs types de tokens, chacun ayant un rôle précis :
Primary Refresh Token (PRT)
Jeton long terme
Spécifique à l’appareil
Sert à demander d’autres tokens
Utilisé par Windows (WAM – Web Account Manager)
Access Token
Jeton court terme
Présenté aux applications (API, Office, AVD…)
Contient les claims utilisateur
Refresh Token
Permet de renouveler un Access Token
Généralement géré automatiquement par le système
Qu’est-ce que le Primary Refresh Token (PRT) ?
Dans le monde de Microsoft, le PRT est un jeton émis par Microsoft Entra ID lorsqu’un appareil est Microsoft Entra Joined ou Microsoft Entra Hybrid Joined.
Un jeton d’actualisation principal (PRT) est un artefact clé de l’authentification Microsoft Entra dans les versions prises en charge de Windows, iOS/macOS, Android et Linux. Un PRT est un artefact sécurisé spécialement émis aux répartiteurs de jetons microsoft pour activer l’authentification unique (SSO) sur les applications utilisées sur ces appareils.
Le PRT est stocké localement sur la machine et sert de jeton racine pour :
obtenir des tokens d’accès OAuth 2.0
s’authentifier automatiquement aux services cloud Microsoft
éviter toute ressaisie de mot de passe pour les applications modernes
Concrètement, le PRT permet :
l’ouverture automatique de session dans Edge
l’authentification transparente à Office, Teams, OneDrive
l’utilisation de Windows App / Azure Virtual Desktop web
Point important : le PRT n’est pas Kerberos et ne permet pas, à lui seul, d’ouvrir une session Windows sur une machine Active Directory.
Pourquoi le PRT ne suffit-il pas pour Azure Virtual Desktop en mode Hybride ?
Dans un environnement Azure Virtual Desktop en mode Hybride, il y a deux niveaux d’authentification distincts :
Accès au service AVD (broker / portail) → Authentification Microsoft Entra ID → Le PRT suffit
Ouverture de la session Windows sur le session host → Authentification Active Directory → Un TGT Kerberos est obligatoire
Dans un environnement Microsoft Entra Hybrid Joined, le PRT est présent, mais le TGT Kerberos n’est pas automatiquement délivré par Entra.
Cela permet de comprendre pourquoi une seconde authentification Active Directory est fréquemment observée dans de nombreux environnements AVD, après une première authentification Entra.
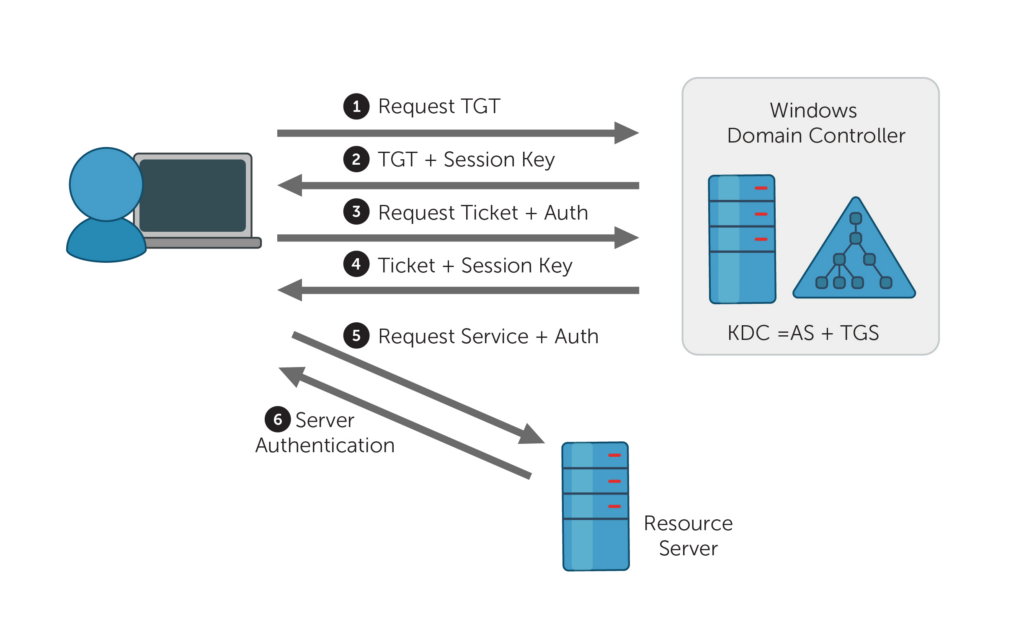
Qu’est-ce qu’un TGT Kerberos Active Directory ?
Le Ticket Granting Ticket (TGT) est un jeton Kerberos délivré par un contrôleur de domaine Active Directory.
Il est obtenu :
lors de l’ouverture de session Windows
après une authentification réussie auprès de l’AD
Le TGT permet ensuite :
d’accéder aux ressources Active Directory
d’obtenir des tickets de service (CIFS, LDAP, HTTP, etc.)
d’ouvrir une session Windows locale ou distante
Sans TGT Kerberos, l’ouverture d’une session Active Directory n’est pas possible.
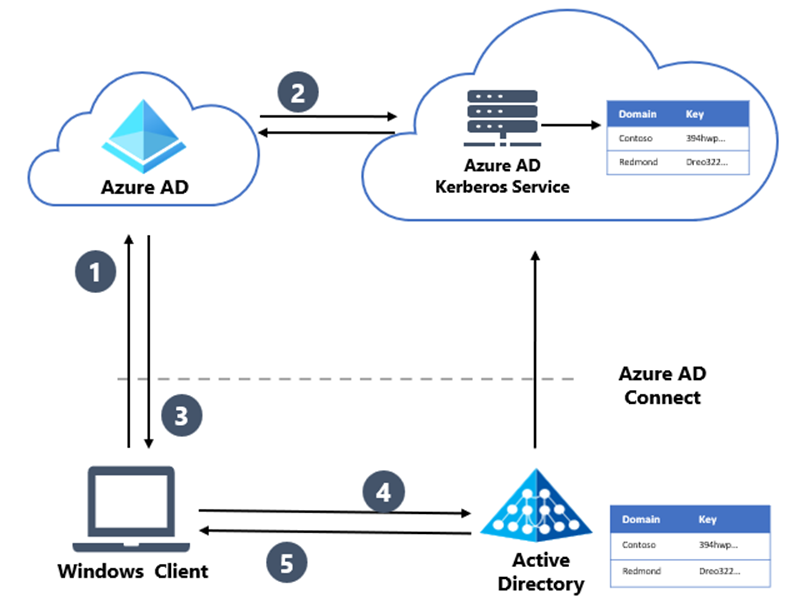
Qu’est-ce que Microsoft Entra Kerberos (Cloud Kerberos Trust) ?
Microsoft Entra Kerberos est le mécanisme qui permet à Microsoft Entra ID de :
générer un TGT Kerberos Active Directory
à partir d’une authentification cloud
sans nécessiter ADFS
Techniquement :
un objet Kerberos spécial est créé dans l’Active Directory
les clés sont synchronisées avec Microsoft Entra ID
Entra devient capable d’émettre un TGT valide pour l’AD
C’est l’élément nécessaire pour obtenir un SSO complet dans AVD en environnement hybride.
Pourquoi la jointure hybride améliore l’expérience SSO ?
Avec Microsoft Entra Hybrid Join :
l’appareil est reconnu par Entra
un PRT est délivré
les applications cloud utilisent un SSO moderne
En ajoutant Microsoft Entra Kerberos :
Entra peut aussi délivrer un TGT AD
Windows peut ouvrir la session sans redemande de mot de passe
On comprend alors que la combinaison du PRT et d’un TGT Kerberos est nécessaire pour obtenir un SSO transparent dans Azure Virtual Desktop.
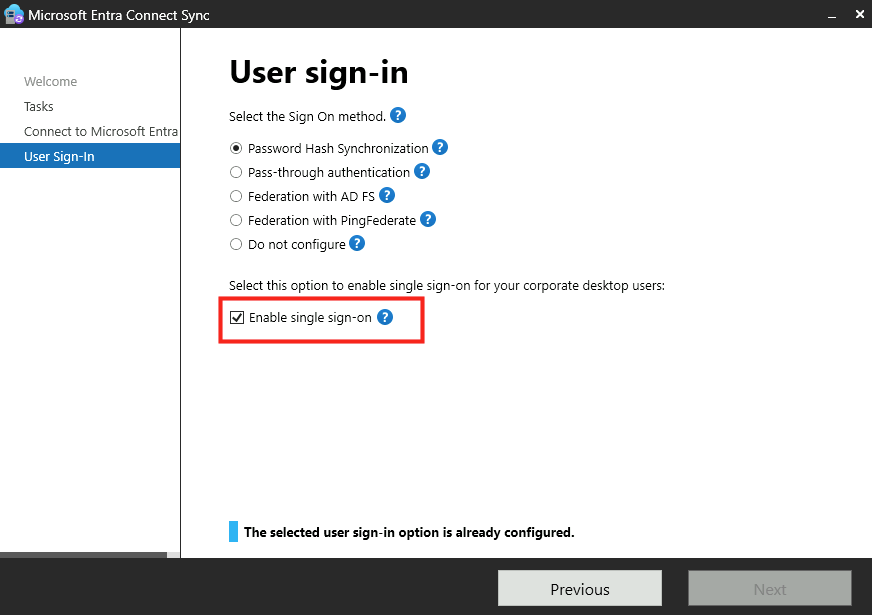
À quoi sert la case “Single sign-on” dans Entra Connect ?
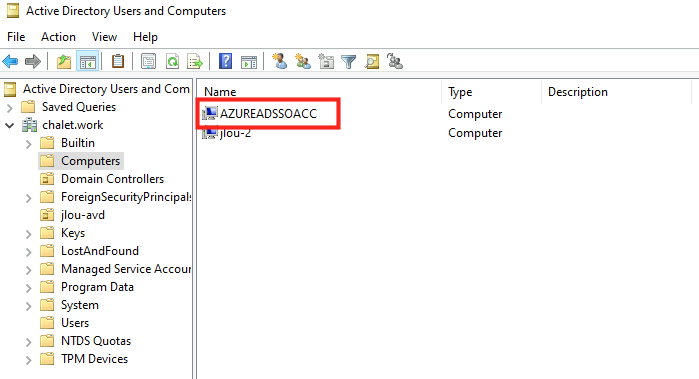
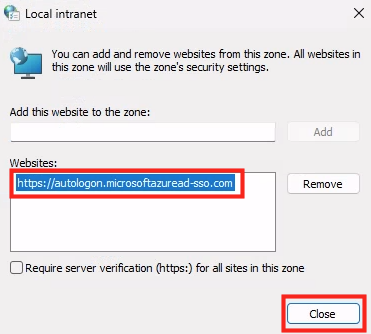
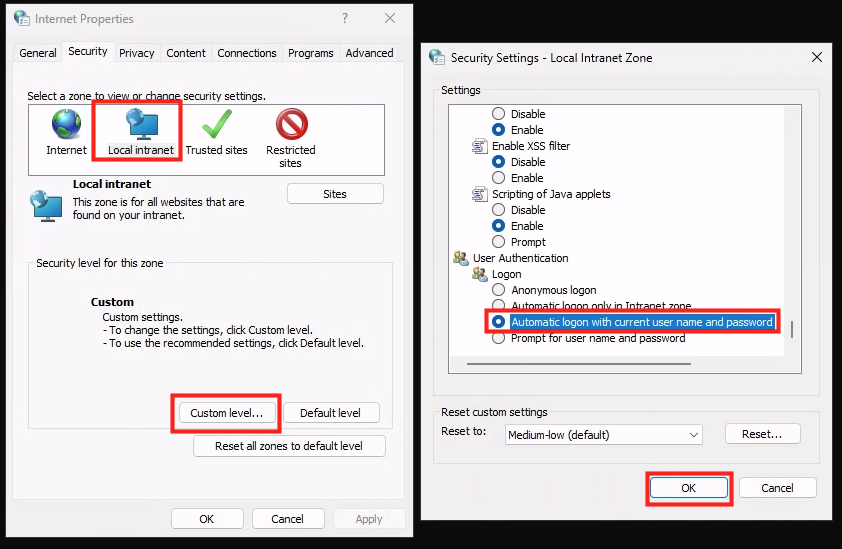
La case Single sign-on dans Microsoft Entra Connect active ce qu’on appelle Seamless SSO.
Seamless SSO repose sur :
Kerberos
le compte AD AZUREADSSOACC
le site autologon.microsoftazuread-sso.com
Son objectif est volontairement limité :
éviter la saisie du mot de passe AD
lors d’une authentification navigateur vers Entra ID
sur une machine AD-only
Il est important de distinguer Seamless SSO des autres mécanismes :
ne crée PAS de PRT
ne remplace PAS Microsoft Entra Kerberos
ne supprime PAS tous les écrans de login
Pour se donner une meilleure idée de cette fonctionnalité SSO spécifique, nous la testerons dans la dernière étape de cet article.
Mais commençons d’abord par tester la mise en place du single sign-on complet pour un environnement AVD de mode hybride, dont les procédures officielles sont disponibles ici et là :
Dans mon environnement de test, j’ai déjà configuré certains composants.
Un environnement Active Directory
Microsoft Entra Connect configuré avec
Password Hash Synchronization (PHS)
sans Single sign-on,
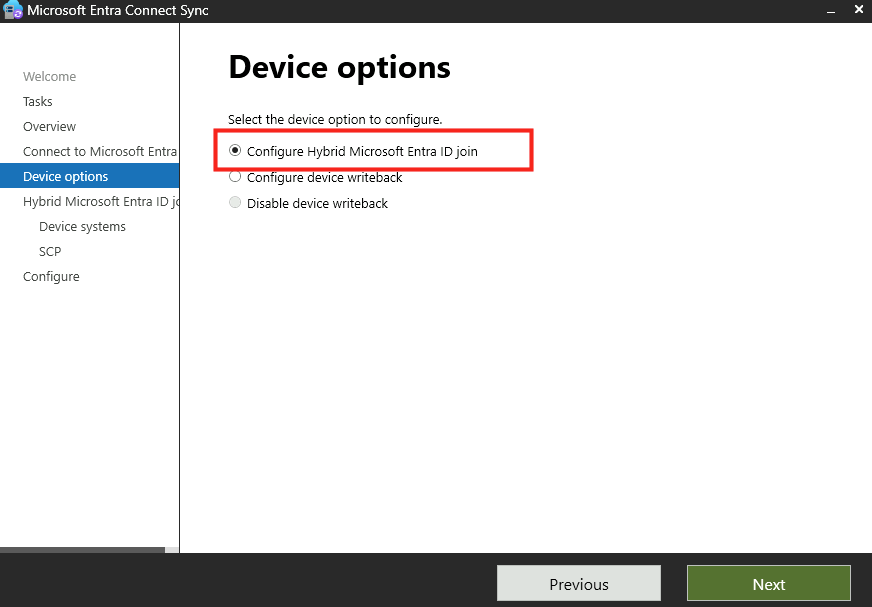
avec Hybrid Joined pour les machines Windows 10/11
Synchronisation de l’OU des utilisateurs AVD
Synchronisation de l’OU des machines hôtes AVD
Un environnement Azure Virtual Desktop avec deux machines virtuelles jointes à AD :
Notre environnement AVD en mode hybride est en place, commençons par un premier test.
Etape I – Test sans configuration SSO :
Avant d’aller plus loin, j’effectue déjà un premier test de connexion d’un utilisateur AVD depuis le portail web :
Une authentification AD est demandée lors de l’ouverture de la session Windows, c’est un comportement normal à ce stade car rien n’est configuré :
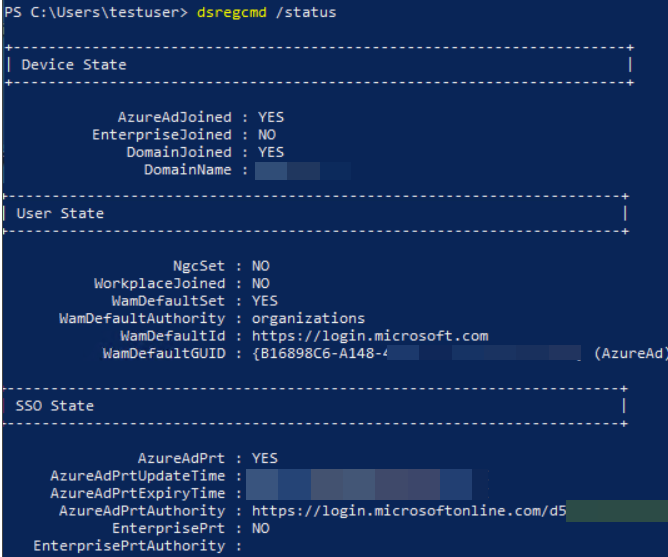
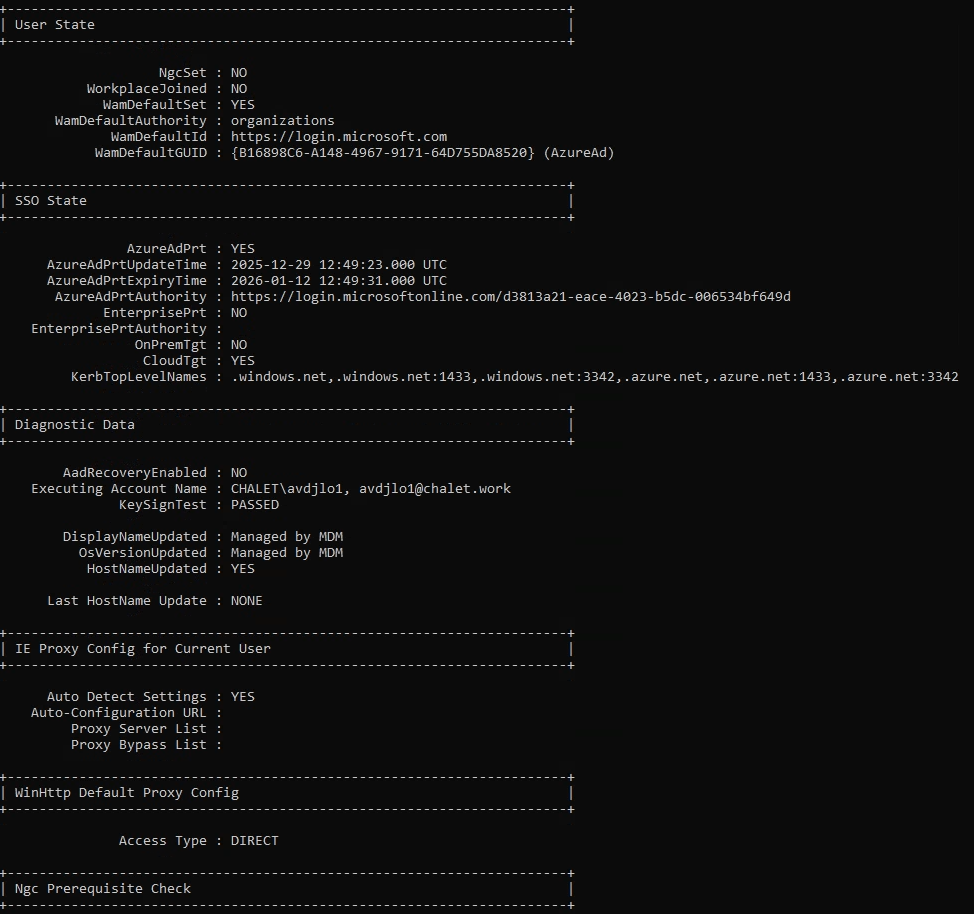
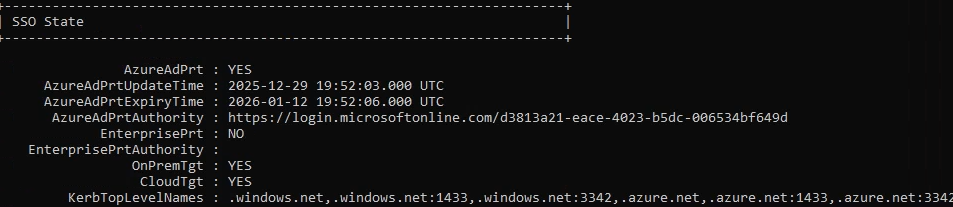
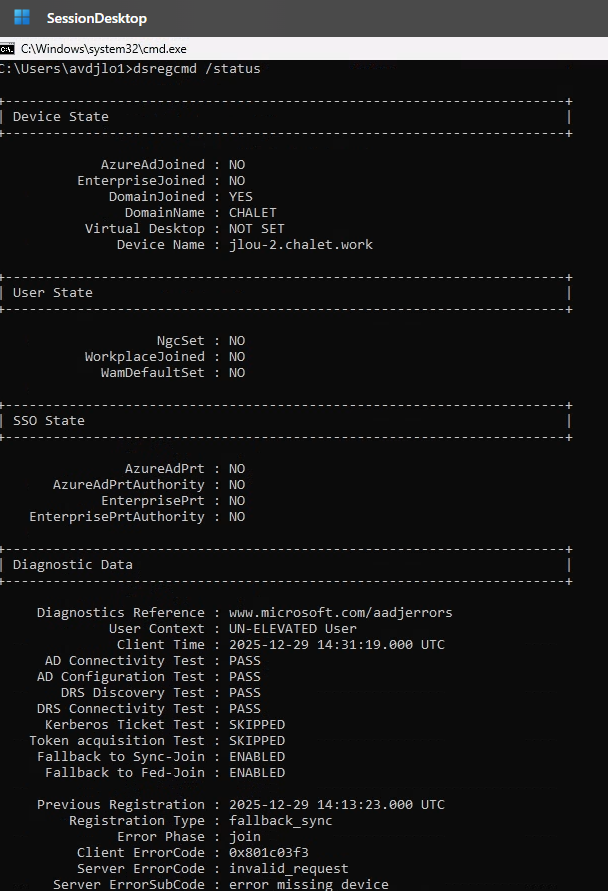
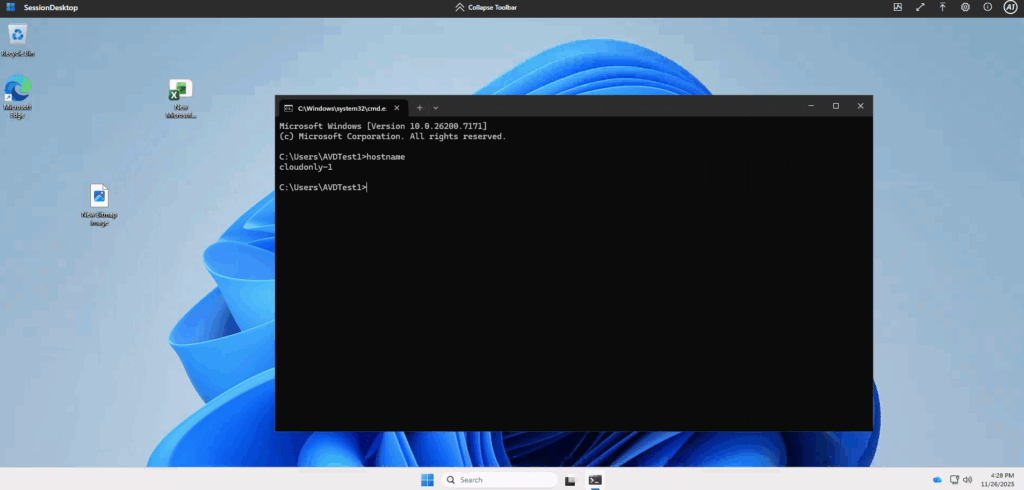
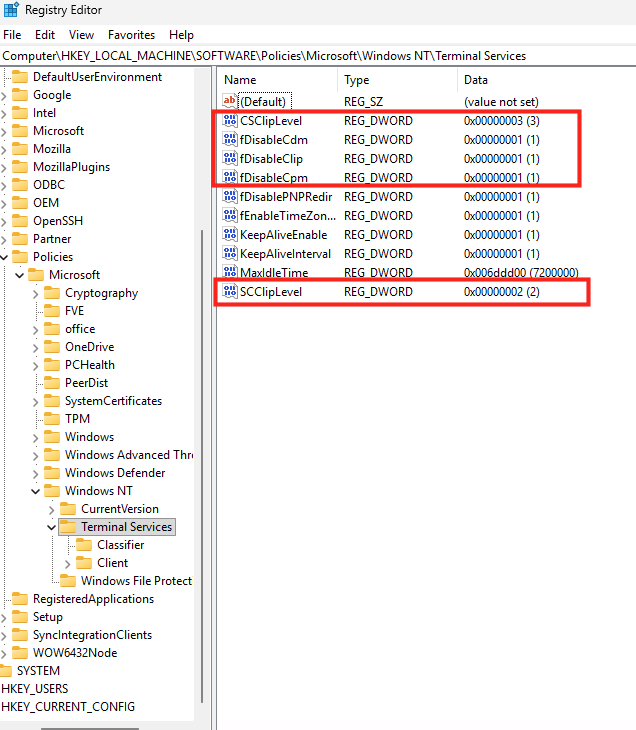
La commande dsregcmd /status sert à afficher l’état d’enregistrement de l’appareil auprès d’Entra ID et, concernant le PRT (Primary Refresh Token), elle fournit des informations de diagnostic sur sa présence et son état :
AzureAdPrt : YES / NO : Indique si un PRT est présent sur la machine pour l’utilisateur
AzureAdPrtUpdateTime : Date/heure du dernier rafraîchissement du PRT
AzureAdPrtExpiryTime : Date/heure d’expiration du PRT
AzureAdPrtAuthority : Autorité qui a émis le token (généralement login.microsoftonline.com).
Concernant la partie des tickets, voici ce que l’on peut aussi en déduire :
OnPremTgt : NO : cela indique si la session utilisateur courante ne possède pas Ticket Granting Ticket Kerberos émis par un contrôleur de domaine AD.
CloudTgt : YES : indique la présence d’un TGT Kerberos cloud, émis par Entra ID.
Comme on peut le constater, le PRT émis via Entra fonctionne bien pour les services Cloud, mais l’ouverture de session et l’accès à certaines ressources gérées par l’AD pourraient être restreints dans la situation actuelle.
Commençons étape par étape les changements pour arriver à une configuration complète.
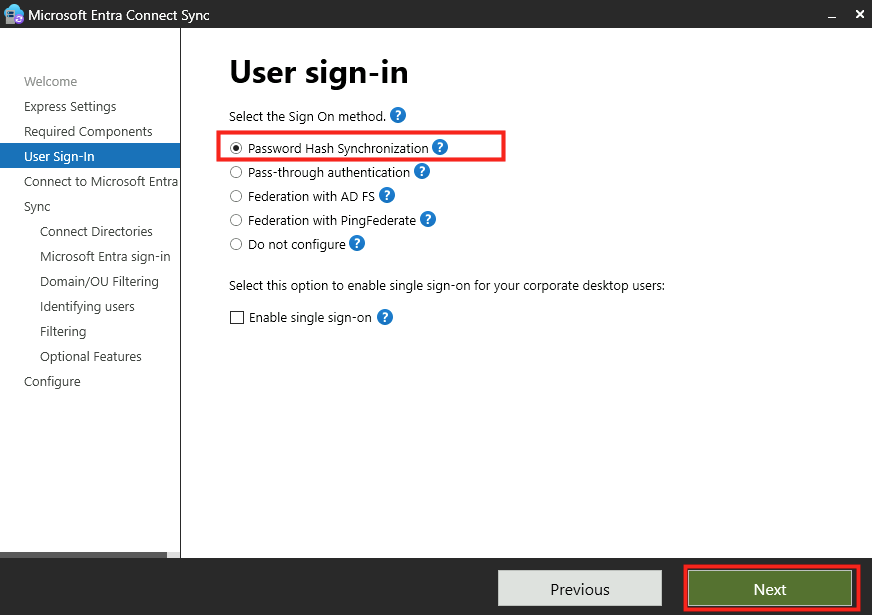
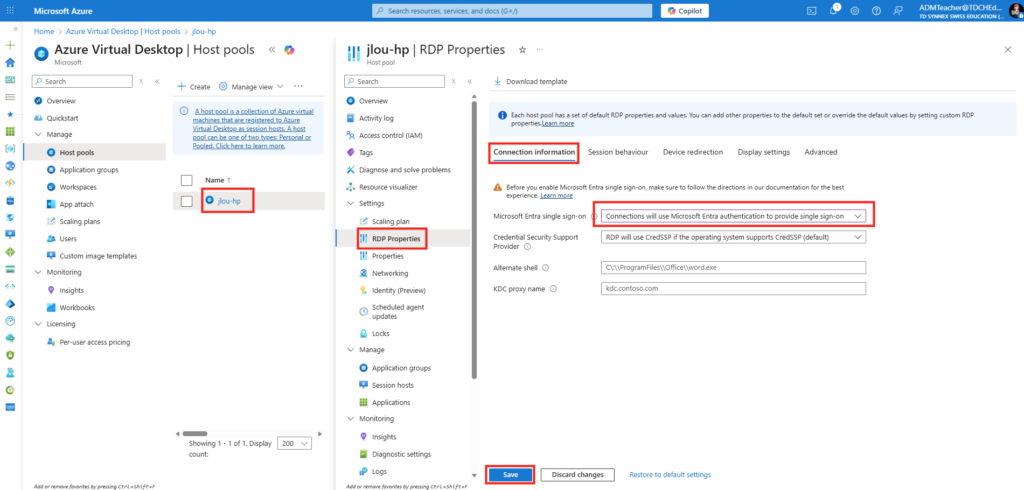
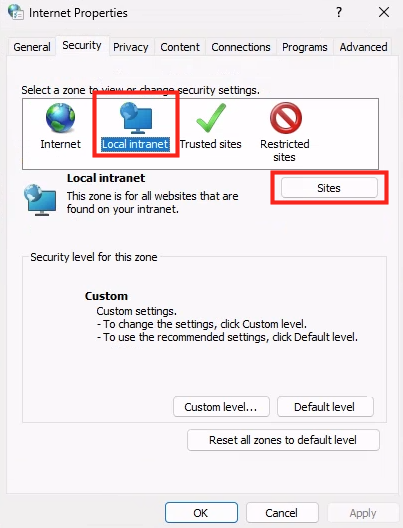
Etape II – Configuration SSO du pool d’hotes AVD :
Sur le portail Azure, comme l’indique la documentation Microsoft, j’effectue la configuration SSO du host pool Azure Virtual Desktop afin d’activer “Microsoft Entra authentication for single sign-on” :
J’effectue un nouveau test avec mon utilisateur :
À ce stade, une authentification AD est encore demandée lors de l’ouverture de la session Windows :
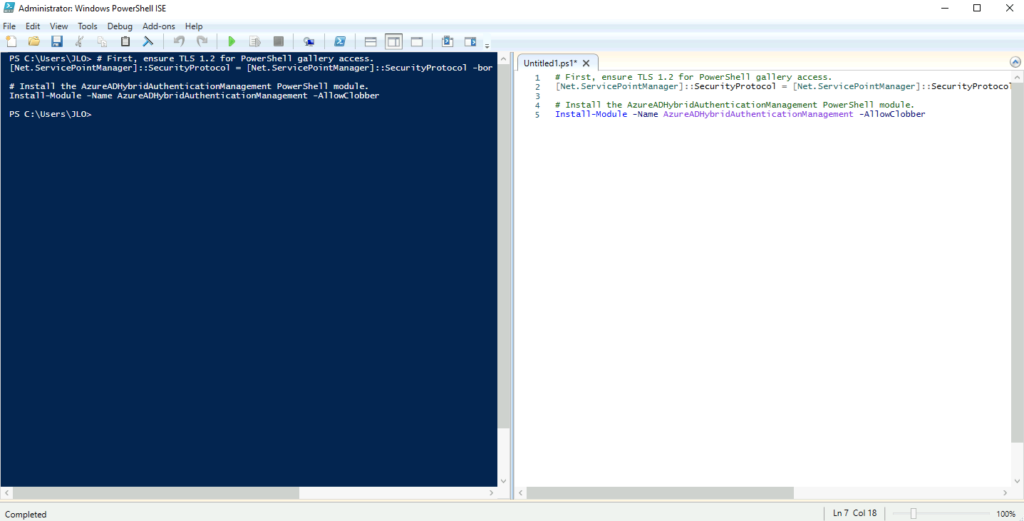
Etape III – Création d’un objet serveur Kerberos :
Sur le serveur AD, comme l’indique la documentation Microsoft, je commence par installer le module AzureADHybridAuthenticationManagement :
Cet exemple exploite l’authentification moderne basée sur le User Principal Name (UPN) sans exiger de mot de passe AD explicite.
Il s’intègre parfaitement dans un environnement hybride sécurisé avec MFA et politiques d’accès conditionnel
Il évite les écueils des méthodes utilisant NTLM ou des identifiants AD en clair.
# Specify the on-premises Active Directory domain. A new Microsoft Entra ID
# Kerberos Server object will be created in this Active Directory domain.
$domain = $env:USERDNSDOMAIN
# Enter a UPN of a Hybrid Identity Administrator
$userPrincipalName = "administrator@contoso.onmicrosoft.com"
# Create the new Microsoft Entra ID Kerberos Server object in Active Directory
# and then publish it to Azure Active Directory.
# Open an interactive sign-in prompt with given username to access the Microsoft Entra ID.
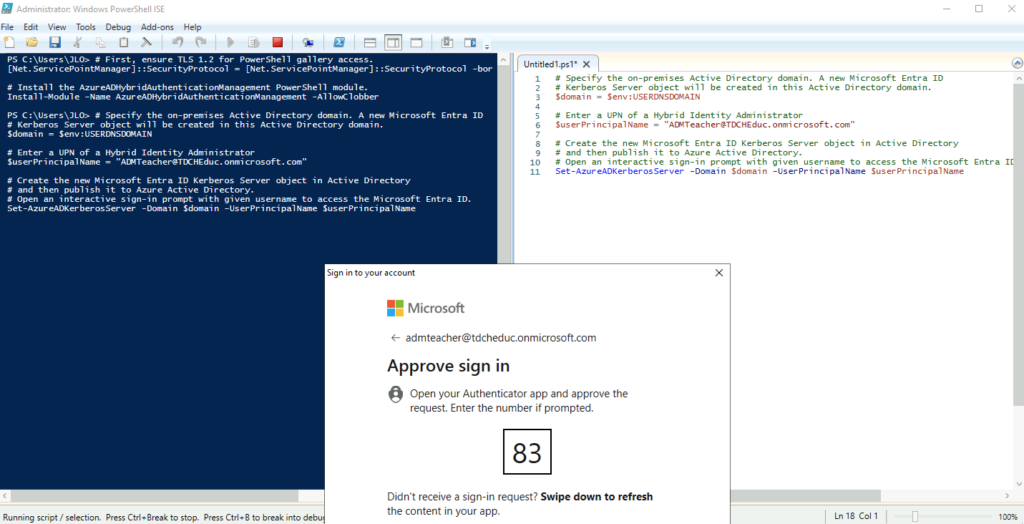
Set-AzureADKerberosServer -Domain $domain -UserPrincipalName $userPrincipalName
Je lance donc le script à la suite du précédent, en prenant soin de remplacer l’UPN par un administrateur général ou hybride :
Je vérifie le serveur Microsoft Entra Kerberos nouvellement créé à l’aide de la commande suivante :
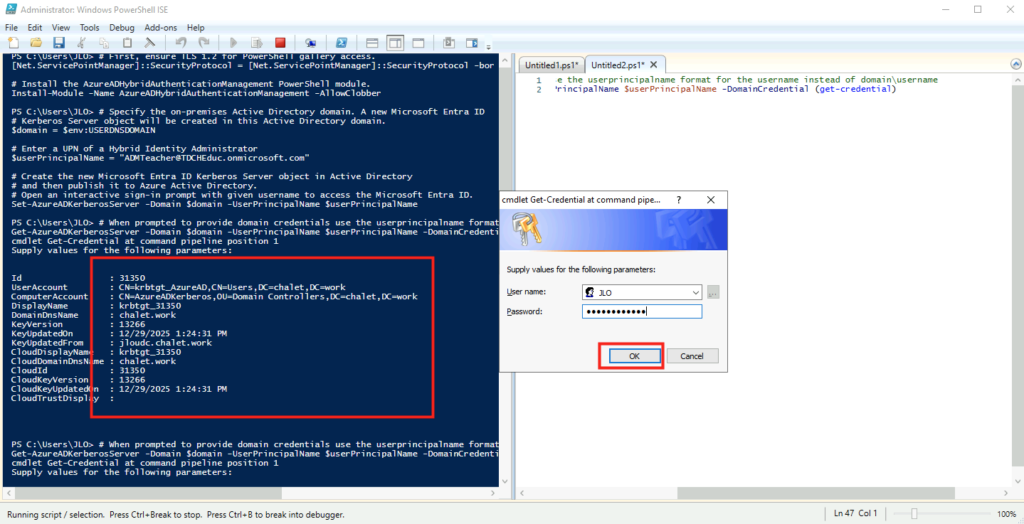
# When prompted to provide domain credentials use the userprincipalname format for the username instead of domain\username
Get-AzureADKerberosServer -Domain $domain -UserPrincipalName $userPrincipalName -DomainCredential (get-credential)
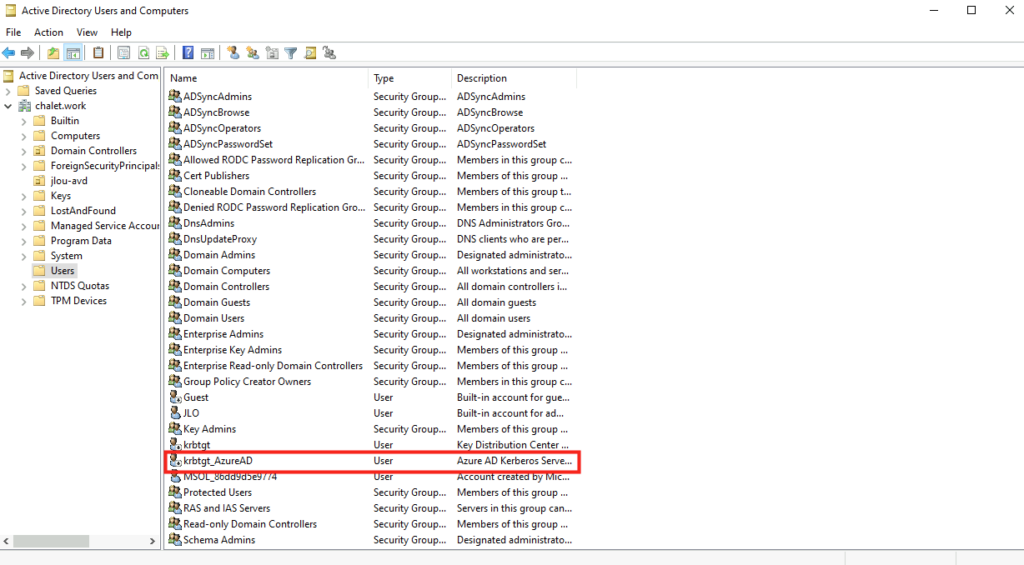
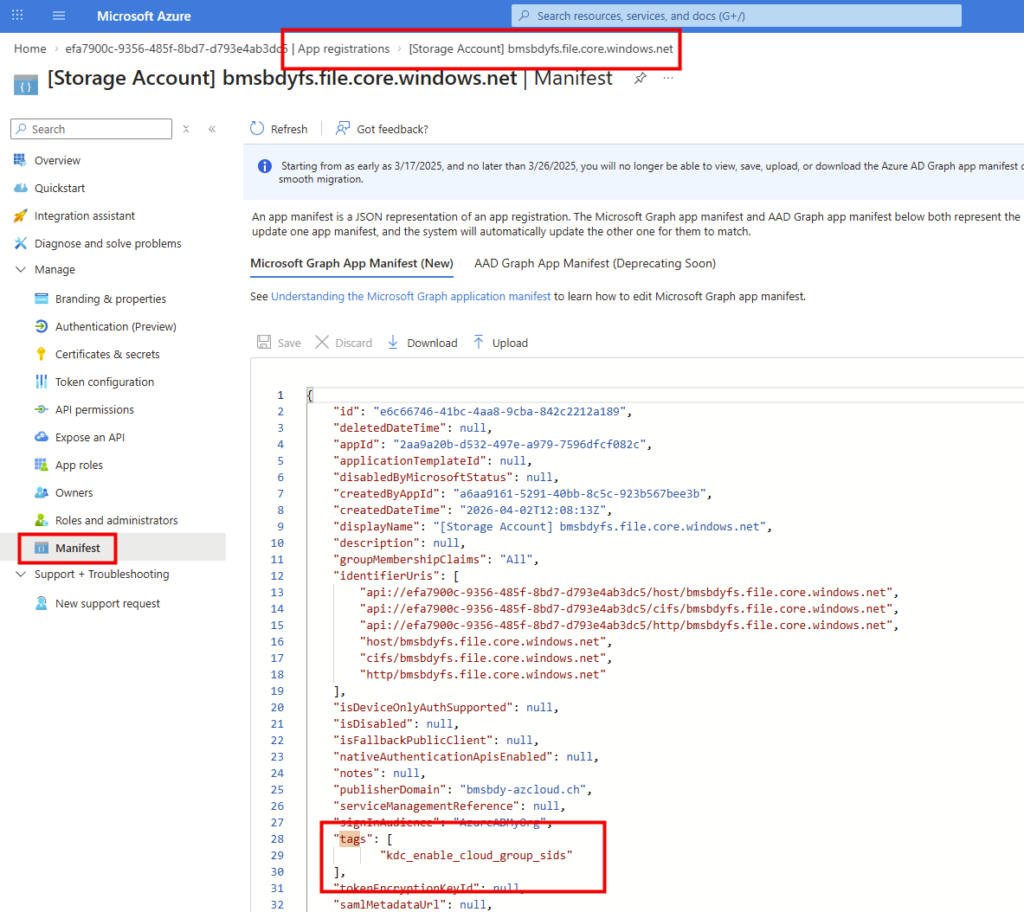
Enfin je constate la présence krbtgt_AzureAD utilisé par les DC pour signer les TGT Kerberos. Il s’agit d’une séparation cryptographique claire avec krbtgt dans le cadre de Kerberos émis depuis Entra :
J’effectue un nouveau test avec mon utilisateur :
Une fois le Cloud Kerberos Trust et l’authentification RDP Microsoft Entra activés, la seconde authentification Active Directory disparaît et est remplacée par un simple message de consentement Allow Remote Desktop connection :
Entra veut un consentement explicite de l’utilisateur. Ce message ne correspond pas à une authentification supplémentaire, mais à une demande de confiance entre l’utilisateur et le session host :
Si l’utilisateur clique sur Oui, ce consentement sera conservé 30 jours et ne pourra pas mémoriser plus de 15 hôtes.
L’Étape suivante consiste donc à supprimer définitivement le popup en déclarant les session hosts comme appareils de confiance dans Microsoft Entra ID.
Etape IV – Activation de l’authentification Microsoft Entra pour RDP :
Commençons par autoriser Microsoft Entra dans l’authentification pour Windows sur le tenant. Pour cela, j’utilise Azure Cloud Shell depuis le portail Azure :
J’importe les deux modules Microsoft Graph suivants, puis je me connecte avec le compte au permissions appropriées :
Afin de masquer la boîte de dialogue en configurant la liste des hôtes AVD approuvés, je créé un groupe dans Entra ID contenant les hôtes de sessions :
J’utilise une requête dynamique pour ajouter automatiquement mes prochains hôtes dans le groupe :
Enfin, toujours dans la même session d’Azure Cloud Shell, j’ajoute l’ID de groupe à une propriété sur le principal du service SSO Windows Cloud Login.
Enfin, je vérifie la bonne assignation du groupe :
J’effectue un nouveau test avec mon utilisateur :
Cette fois l’authentification passe sans encombre. Un TGT Kerberos AD DS (on-premises) est maintenant présent dans la session.
Cela permet d’observer que :
La machine est Hybrid Entra ID Joined
Le PRT est valide
Le Kerberos cloud fonctionne
Le Kerberos AD DS fonctionne
Les deux mondes coexistent simultanément dans la même session
Cette sortie correspond à un état hybride cohérent, où les mécanismes cloud et on-premises coexistent.
Pour finir, je vous propose de tester l’impact du Seamless SSO présent et configurable dans Entra Connect Sync.
Etape V – Activation du SSO d’Entra Connect Sync :
Pour cela, je décide de rajouter une troisième machine AVD :
Celle-ci est bien présente dans l’Active Directory :
Mais elle n’est pas présente dans Entra ID :
Pour ne pas perturber mes tests, je décide donc de bloquer la connexion aux deux autres VMs AVD :
J’effectue un test avec mon utilisateur :
Comme aucune configuration hybride n’est en place pour cette machine AVD, il n’y a pas de ticket TGT Kerberos émis par Entra ID, donc la seconde authentification AD est logique :
Une fois dans la session Windows, dsregcmd nous affiche les informations suivantes :
La machine est jointe uniquement à Active Directory on-premises
Elle n’est pas jointe à Entra ID
Elle n’est pas Hybrid Join
Aucun PRT
Aucun SSO cloud
Aucune authentification Entra ID
Une tentative d’Entra ID Join / Hybrid Join a eu lieu
Elle a échoué côté Entra ID
La machine AVD n’existe pas ou n’est pas reconnu dans le tenant
L’ouverture de la page d’authentification d’Office 365 dans Microsoft Edge me montre d’ailleurs aucune connexion SSO :
Je décide donc d’activer la fonctionnalité SSO dans Entra Connect Sync :
Une fois la configuration terminée, je constate la création de AZUREADSSOACC en tant que compte ordinateur créé dans Active Directory :
Ce dernier est créé automatiquement lors de l’activation de Seamless Single Sign-On (Seamless SSO) avec Entra ID. Le compte est utilisé par Entra ID pour :
établir une relation de confiance Kerberos avec l’AD on-prem
permettre le SSO sans saisie de mot de passe depuis des postes domain-joined vers Entra ID
J’effectue donc un nouveau test avec mon utilisateur :
Dans ce contexte, il est logique que l’authentification AD soit toujours demandée :
Une fois la session Windows ouverte, comme Seamless SSO fonctionne via l’adresse autologon.microsoftazuread-sso.com, je décide de la rajouter en tant qu’URL de l’Intranet local.
Pour cela, j’ouvre inetcpl.cpl :
Je clique sur Site dans Intranet local :
Je clique sur Avancée :
Je rajoute l’URL suivante :
https://autologon.microsoftazuread-sso.com
Toujours dans Intranet Local, je coche Connexion automatique avec le nom d’utilisateur et le mot de passe actuels :
Quelques minutes plus tard, j’ouvre Microsoft Edge et je constate l’authentification automatique de mon compte Cloud correspondant :
La présence du ticket HTTP/autologon.microsoftazuread-sso.com dans le cache Kerberos confirme que le mécanisme Seamless SSO est bien actif. Ce ticket, émis par le contrôleur de domaine à destination de Microsoft Entra ID, permet une authentification navigateur sans saisie de mot de passe.
klist
Il est important de noter que ce mécanisme n’est pas celui utilisé pour l’ouverture de session Windows dans Azure Virtual Desktop, qui repose sur un TGT Kerberos distinct délivré via Microsoft Entra Kerberos (krbtgt_AzureAD).
Conclusion
À travers ces différents tests et configurations, on constate que le Single Sign-On dans Azure Virtual Desktop hybride ne repose pas sur un mécanisme unique, mais sur une combinaison cohérente de plusieurs briques d’authentification.
Le PRT permet une authentification fluide aux services cloud, mais il ne suffit pas à lui seul pour ouvrir une session Windows dans un contexte Active Directory. C’est bien l’association du Hybrid Join, du Cloud Kerberos Trust et de l’authentification Microsoft Entra pour RDP qui permet d’aligner les mondes cloud et on-premises, et d’obtenir une expérience utilisateur réellement transparente dans AVD.
Comprendre ces mécanismes permet non seulement d’éviter des configurations incomplètes, mais aussi d’expliquer pourquoi certains scénarios fonctionnent “presque”, tout en continuant à demander une authentification supplémentaire.
Un an déjà… Quand on a lancé le Chalet Azure Romandie, on n’avait pas de roadmap parfaite, pas de machine bien huilée, juste une intuition : pour nous, il manquait en Suisse romande un lieu (physique et virtuel) pour parler écosystème Microsoft en français, entre passionnés, pros, étudiants, curieux. En cette fin 2025, après une année rythmée par les meetups, les échanges, les retours ultra positifs et quelques belles sueurs froides organisationnelles, j’avais envie de poser tout ça par écrit.
Ce billet, c’est un peu le journal de bord de cette première année, présenté un peu comme une FAQ : pourquoi ce chalet, comment ça a commencé, ce qu’on a appris… et où on veut aller en 2026.
Comment est née l’idée du Chalet Azure Romandie ?
À l’origine, on est trois : Seyfallah, Éricet moi. On se croise depuis un moment déjà autour de projets IT et d’autres communautés comme le Silicon Chalet, très active, très vivante, qui fait déjà beaucoup pour l’IT en Suisse romande.
« Partage , solidarité et honnêteté ! Voici les piliers du CAR »
On y participe sous plusieurs casquettes : parfois speakers, parfois organisateurs, parfois juste personnes dans le public avec un paquet de questions.
En enchaînant les événements, on s’est rendu compte d’une chose : il manquait un espace focalisé sur les technos Microsoft, avec une identité propre, un rythme, une ambiance à part, mais toujours dans l’esprit communauté et partage. L’idée du “Chalet Azure Romandie” est née de là :
mais créer un nouveau groupe dédié au cloud Microsoft, à ses usages, ses architectes, ses développeurs, ses admins, ses décideurs.
« Le CAR : c’est le partage de connaissances, la rencontre humaine et surtout du fun !«
Quand est-ce que ça a vraiment démarré ?
Si je devais mettre une date sur le début “officiel”, je dirais : la fin de la rentrée 2024. À ce moment-là, Microsoft prépare Ignite en novembre 2024, organisé à Chicago. De notre côté, Seyfallah et moi avons prévu d’y participer sur place.
C’est là que la discussion se cristallise : et si on profitait d’Ignite comme point de départ du Chalet Azure Romandie avec une idée toute simple :
“On est sur place, on a accès aux annonces, aux sessions, aux experts… Et si on ramenait tout ça en français, en direct, pour la Romandie ?”
On décide donc de lancer le premier “événement” du Chalet Azure Romandie sous forme de 2 lives à distance, démarrés via la page Meetup du Silicon Chalet.
Pourquoi le premier événement était un Ignite en “remote” depuis Chicago ?
Le plan initial était assez ambitieux (et naïf 😄) :
faire des lives depuis le salon,
animer des tables rondes,
permettre à la communauté romande de poser des questions en direct,
et tout ça dans un créneau de fin de journée pour les amis en Suisse et, plus largement, en francophonie.
Sur le papier, tout semblait gérable. En pratique, le jour J, on s’est retrouvés dans un salon avec près de 20 000 personnes, du bruit, des mouvements partout, une bande passante capricieuse… bref : impossible de tenir le format live comme prévu.
On a donc dû improviser :
on s’est éclatés en petits groupes,
on a enregistré des sessions à l’écart de la foule,
on a structuré des séquences d’échange plus calmes.
Mais le résultat en valait la peine :
deux sessions bien remplies,
environ une cinquantaine de personnes par session,
et surtout : la preuve que dès le départ, il y avait une vraie envie de contenu Microsoft en français.
Comment s’est organisée la première vraie année, en 2025 ?
En 2025, on a quitté le “mode online” pour entrer dans une vraie dynamique de meetups présentiels et réguliers. Concrètement, ça voulait dire :
trouver des salles,
trouver des sponsors,
trouver des speakers,
et répéter l’exercice 7 à 8 fois sur la première année.
On a organisé des événements à travers plusieurs villes de Suisse romande :
Genève,
Plan-les-Ouates,
Gland,
…
Côté sponsors, on a eu la chance d’être soutenus par :
Kyos,
Swissquote,
TD SYNNEX,
Ilem SA,
Squad,
Spaces,
Wavestone,
et un peu plus tard Microsoft directement sur certaines sessions.
Côté thématiques, on a couvert grâce à des speakers de qualité entre autres :
IA et Sécurité Microsoft,
Azure Landing Zones,
Dynamics 365,
AI Agents,
Azure Policy,
Fabric et l’intégration de Copilot,
et aussi des Hands-on pour mettre vraiment les mains dans le cambouis.
À quoi ressemble une soirée type au Chalet Azure Romandie ?
Rapidement, un format “signature” s’est dessiné. En général, on a :
1 à 2 talks maximum,
une présentation du sponsor,
un quiz lié au contenu des talks (parfois sérieux, parfois volontairement décalé),
des goodies pour les gagnants,
et surtout : un gros temps de networking.
Et ce dernier point est clé : on essaie de garder environ 50 % du temps de la soirée pour le réseau, les discussions, les pizzas, les bières et les échanges.
Pourquoi ? Parce que c’est là que :
les étudiants croisent les pros,
les personnes en recherche d’emploi discutent avec des gens qui recrutent ou qui connaissent des opportunités,
les admins, les architectes, les consultants partagent leurs galères, leurs bonnes pratiques, leurs idées.
À un moment, la magie opère : on n’a presque plus rien à faire. Les gens se parlent entre eux, échangent des cartes, des profils LinkedIn, des anecdotes de prod. Et c’est exactement ce qu’on voulait !
Comment avez-vous varié les formats et les speakers ?
On a essayé de ne jamais tomber dans la routine. Côté formats, on a alterné entre :
talks courts,
talks plus longs,
sessions très interactives,
labs individuels,
labs en équipe,
tables rondes.
Côté speakers, on a fait attention à plusieurs points :
inviter des personnes francophones,
mélanger speakers expérimentés et nouveaux venus,
mettre en avant les femmes dans l’IT.
Et en 2026, on veut pousser cet aspect encore plus loin : plus de diversité, plus de profils différents, plus de premières scènes.
Qu’avez-vous appris côté organisation (et galères) ?
Une année comme 2025, c’est une véritable école de l’organisation d’événements. Parmi les grandes leçons :
Anticiper beaucoup plus qu’on ne le pense : salles, matériel, restauration, communication, etc.
Structurer : qui fait quoi, quand, avec qui.
Et surtout… gérer le sujet qui fâche : les no-shows.
Les no-shows, c’est vraiment l’ennemi des meetups gratuits :
des personnes s’inscrivent,
ne viennent pas,
mais restent inscrites.
Résultat :
ça consomme de l’énergie côté orga,
ça démotive parfois les sponsors qui paient pour des places, de la nourriture, des boissons,
ça peut frustrer des personnes en liste d’attente qui, elles, seraient venues.
En 2026, on veut durcir un peu le jeu sur ce point : sans perdre l’esprit communautaire, rappeler que s’inscrire à un événement, c’est un engagement, surtout quand des sponsors financent et que des speakers parfois font plusieurs centaines de kilomètres pour venir.
Comment Microsoft est entré dans l’aventure ?
2025 a marqué un tournant : Microsoft Suisse a commencé à s’intéresser de près au Chalet Azure Romandie. Ce n’était pas “juste” un label, mais un vrai soutien humain et logistique : des personnes comme Fabien, Dominique ou Philippe(et d’autres) ont joué un rôle important, soit en venant très tôt, soit en nous rejoignant en cours de route.
Concrètement, ça s’est traduit par :
des workshops avancés (IA, Fabric, Copilot, Power Platform…),
la présence d’experts Microsoft dans les sessions,
un dialogue plus constant entre la communauté et l’éditeur.
Pour nous, ça a été un vrai signal de confiance :
“Une petite communauté par la taille peut être grande par l’intérêt et l’engagement qu’elle génère autour des produits.”
Et Ignite 2025 dans tout ça ?
En 2025, Ignite se tenait à San Francisco. Cette fois-ci, on n’est pas repartis sur le même modèle que Chicago. On a opté pour quelque chose de plus posé :
une table ronde de débrief en fin d’année,
du partage d’expérience,
la présence d’experts,
et un événement de clôture qui a fait office de bilan 2025 et de tremplin pour 2026.
Pourquoi créer une page Meetup dédiée au Chalet Azure Romandie ?
rendre le groupe plus visible pour celles et ceux qui cherchent du contenu Microsoft,
faciliter la gestion des événements et des inscriptions,
et rejoindre officiellement le réseau des Azure Tech Groups dans le monde :
Aujourd’hui, le Chalet Azure Romandie fait donc partie de cette constellation de communautés Azure, chacune avec son identité locale mais un même objectif : partager, apprendre, connecter.
Et maintenant ? 2026, une année sous le signe de l’ouverture !
On a fêté les un an du Chalet Azure Romandie. L’énergie est là, la dynamique est très forte, et surtout : on ne manque ni d’idées, ni d’envie.
Pour 2026, nos principales intentions sont :
continuer à proposer un contenu varié (technique, décisionnel, retours d’expérience),
garder ce mix de formats (talks, labs, workshops, tables rondes),
renforcer la place des femmes dans les speakers,
consolider et élargir notre réseau de sponsors et de lieux,
et valider notre Call for Speakers pour toute l’année 2026.
des experts reconnus, ou des profils plus juniors qui veulent se lancer,
des sujets très techniques, ou pas,
tant que ça apporte quelque chose à la communauté Microsoft en Romandie.
Un mot pour finir ?
On est fiers du chemin parcouru en un an. On est très reconnaissants envers :
les sponsors qui nous ont fait confiance,
les speakers qui ont pris du temps pour préparer des sessions de qualité,
les participants qui sont venus, ont posé des questions, ont partagé,
les équipes de Microsoft qui ont rejoint l’initiative,
et bien sûr, le Silicon Chalet, qui reste un de nos points d’ancrage historiques.
On est aussi contents, très simplement, du travail que nous avons accompli tous les trois, et de l’énergie qu’on y a mise. Pour la suite, on a envie d’une chose :
que tu nous rejoignes, en tant que participant, speaker, sponsor, ou simple curieux.
Le Chalet Azure Romandie, c’est une aventure communautaire. On espère te voir avec nous en 2026 et au-delà.
Le chiffrement des disques Azure existe depuis longtemps, mais il reste souvent mal compris : SSE, Encryption at Host, ADE… tout ne fonctionne pas au même niveau, et tout n’a pas le même impact. Je vous propose ici un tour d’horizon concret : explications, tests de performance et retour d’expérience sur la migration depuis Azure Disk Encryption.
Avant d’aller plus loin dans notre sujet, gardez toujours en tête que le processus de chiffrement concerne plusieurs états possibles de la donnée :
Dans cet article, nous aurons pour objectif de parler de la protection des données « au repos » sur les disques, afin qu’elles restent inexploitables en cas d’accès non autorisé, extraction de disque virtuel ou compromission de stockage.
Vue d’ensemble des options de chiffrement des disques de VM :
À ce jour, il existe plusieurs mécanismes de chiffrement disponibles pour vos disques de vos machines virtuelles Azure. Voici un premier récapitulatif des différents mécanismes de chiffrement disponibles sur Azure :
Azure Disk Storage Server-Side Encryption (SSE) : ce premier niveau de chiffrement est toujours activé pour les données au repos. Il chiffre automatiquement les données stockées sur les disques gérés Azure (disques OS et disques de données, à l’exception des disques temporaires et des caches disque).
Il est même possible de travailler avec d’autres clés que celles gérées par Microsoft :
Confidential disk encryption : ce mécanisme lie les clés de chiffrement des disques au TPM de la machine virtuelle et rend le contenu protégé du disque accessible uniquement à la machine virtuelle et ne permet pas que l’hyperviseur puisse déchiffrer les données.
Encryption at host : option au niveau de la machine virtuelle qui améliore le chiffrement côté serveur Azure Disk Storage afin de garantir que tous les disques temporaires et les caches disque sont chiffrés au repos et transférés chiffrés vers les clusters de stockage.
Azure Disk Encryption (ADE) : ce mécanisme chiffre le système d’exploitation et les disques de données des machines virtuelles Azure (VM) à l’intérieur de vos VM à l’aide de la fonctionnalité DM-Crypt de Linux ou de la fonctionnalité BitLocker de Windows. Azure Key Vault permet de contrôler et gérer les clés et les secrets de chiffrement de disque.
Quand ADE est activé, chaque disque de la machine virtuelle affiche alors cette information :
Une extension ADE est sur la machine virtuelle :
Est-ce que Azure Disk Encryption est déprécié ?
Azure Disk Encryption présente actuellement plusieurs limites importantes :
Le chiffrement réalisé directement dans l’OS peut entraîner une consommation CPU supplémentaire dans la VM.
ADE n’est pas compatible avec l’ensemble des types de disques ni toutes les distributions Linux.
Son intégration étroite avec l’OS et l’agent Azure le rend plus sensible et plus complexe à maintenir.
Partant de ce constat, je suppose que Microsoft a fait son choix et que ADE sera officiellement retiré le 15 septembre 2028, et propose même une stratégie de migration vers Encryption at host :
Azure Disk Encryption pour les machines virtuelles et les Virtual Machine Scale Sets sera mis hors service le 15 septembre 2028. Les nouveaux clients doivent utiliser le chiffrement sur l’hôte pour toutes les nouvelles machines virtuelles.
Les clients existants doivent planifier la migration des machines virtuelles ADE actuelles vers le chiffrement sur l’hôte avant la date de mise hors service pour éviter toute interruption de service.
Encryption at Host est un mécanisme de chiffrement fourni par la plateforme Microsoft Azure permettant de chiffrer les disques de machines virtuelles au niveau de l’hôte (l’hyperviseur), avant que les données ne soient écrites sur le stockage.
Plutôt que de chiffrer les disques directement dans la machine virtuelle via BitLocker ou DM-Crypt, ce mode déplace le chiffrement sur l’hyperviseur Azure lui-même.
Cela permet de chiffrer l’ensemble des composants associés à la VM (disques OS, disques de données, disques temporaires et cache) tout en évitant la charge CPU dans la VM :
Quelles sont les restrictions liées à cette migration ?
Microsoft rappelle ici les différents points et limitations à prendre lorsque vous souhaitez migrer d’Azure Disk Encryption à Encryption at host, Voici quelques-unes d’entre elles :
Temps d’arrêt requis : le processus de migration nécessite un temps d’arrêt de machine virtuelle pour les opérations de disque et la recréation des machines virtuelles.
Aucune migration sur place : vous ne pouvez pas convertir directement des disques chiffrés par ADE en chiffrement sur l’hôte. La migration nécessite la création de disques et de machines virtuelles.
Machines virtuelles jointes à un domaine : si vos machines virtuelles font partie d’un domaine Active Directory, d’autres étapes sont requises :
La machine virtuelle d’origine doit être supprimée du domaine avant la suppression
Après avoir créé la machine virtuelle, elle doit être jointe au domaine
Pour les machines virtuelles Linux, la jonction de domaine peut être effectuée à l’aide d’extensions Azure AD
Pour réaliser cet exercice sur les différentes méthodes de chiffrements, il faut disposer de :
Un tenant Microsoft
Une souscription Azure valide
La suite se passera par la création d’une machine virtuelle depuis le portail Azure.
Etape I – Création de la machine virtuelle Azure :
Je commence par créer une machine virtuelle Windows Server 2025 avec 32 cœurs, afin d’éviter toute limitation liée aux performances de la VM pendant les tests :
Une fois la VM créée, j’ajoute un disque de données supplémentaire en plus du disque système. À ce stade, les deux disques utilisent le chiffrement au repos par défaut de type SSE, appliqué automatiquement par la plateforme :
Sur l’écran de configuration des disques, des Paramètres supplémentaires sont disponibles :
Je constate que le chiffrement au niveau de l’hôte n’est pas activé à ce stade. La VM utilise uniquement le chiffrement SSE, sans mécanisme supplémentaire de type ADE ou Encryption at Host :
Je me connecte à la machine virtuelle via Azure Bastion :
Je vérifie que le service BDESVC associé à BitLocker n’est pas actif et qu’aucun chiffrement au niveau du système d’exploitation n’a été configuré :
Get-Service BDESVC
manage-bde -status
Cela confirme que seul le chiffrement SSE au niveau du stockage est en place, et qu’aucune couche de chiffrement, au niveau de la machine virtuelle ou de l’hyperviseur est activée :
Afin d’étoffer mon analyse, il est intéressant de comparer les performances (IOPS, Débits et CPU) entre plusieurs types de chiffrement de stockage. Pour cela j’utiliserai l’outil de mesure Diskspd et les métriques disponibles sur le portail Azure.
Etape II – Installation de l’outil de mesure Diskspd :
L’installation de Diskspd se fait directement sur la machine virtuelle à tester :
DISKSPD est un outil que vous pouvez personnaliser pour créer vos propres charges de travail synthétiques. Nous utiliserons la même configuration que celle décrite ci-dessus pour exécuter des tests d’évaluation. Vous pouvez modifier les spécifications pour tester différentes charges de travail.
Microsoft recommande d’utiliser l’utilitaire DiskSpd pour générer une charge sur un système de disques (stockage) et … pour mesurer les performances du stockage et obtenir la vitesse maximale disponible en lecture/écriture et les IOPS du serveur spécifique.
J’ouvre Task Manager afin d’observer en temps réel l’activité du disque :
Je surveille l’utilisation CPU de la VM depuis le portail Azure :
Une fois les deux tests terminés, les fichiers sont générés dans le dossier courant :
le premier fichier TXT généré est pour consigner les résultats IOPS :
Le second fichier TXT est généré pour consigner les résultats débits :
Etape VI – Comparaison des performances de chiffrement :
Les mesures montrent que les performances des disques restent globalement équivalentes entre les trois modes, mais que l’usage CPU varie nettement, notamment lorsque le chiffrement est exécuté dans le système d’exploitation comme avec Azure Disk Encryption :
Mode de chiffrement
CPU moyen (%)
SSE (Storage Service Encryption)
1.5 %
Encryption at Host
1.0 %
ADE (Azure Disk Encryption)
2.8 %
SSE et Encryption at Host ont un impact CPU faible et comparable.
ADE présente une charge CPU sensiblement supérieure, liée au chiffrement effectué par BitLocker dans la VM, ce qui correspond à l’architecture même de ce mode.
La surcharge induite par ADE reste faible, mais l’hétérogénéité des latences confirme qu’il reste plus sensible que les modes opérés directement par la plateforme.
Etape VII – Migration d’ADE vers Encryption at host :
La migration depuis ADE vers Encryption at host sur une machine virtuelle n’est pas possible pour des raisons techniques. Voici ce qui se produit lorsqu’on tente d’activer Encryption at Host sur une VM, qui était auparavant configurée avec Azure Disk Encryption :
Microsoft liste donc ici les différentes étapes nécessaires pour réaliser cette migration. Nous allons commencer par désactiver Azure Disk Encryption.
Sur l’écran de configuration des disques, je désactive Azure Disk Encryption, puis je sauvegarde :
Une tâche Azure se déclenche, j’attends quelques minutes que celle-ci se termine :
Je me reconnecte à la machine via Azure Bastion, puis je vérifie que le service BDESVC est toujours activé et qu’une phase de déchiffrement vient de démarrer :
Get-Service BDESVC
manage-bde -status
Quelques minutes plus tard, le déchiffrement est entièrement terminé :
Malgré cela, l’extension ADE est toujours présente sur ma machine virtuelle :
Je la désinstalle depuis le portail Azure :
Quelques minutes plus tard, la notification Azure suivante apparaît :
Lancez la commande PowerShell suivante depuis Azure Cloud Shell pour chacun des disques afin de créer des disques qui ne portent pas sur les métadonnées de chiffrement ADE :
Attention : Ce script ne fonctionne pas sur les disques Premium SSDv2 et Ultra.
# Get source disk information
$sourceDisk = Get-AzDisk -ResourceGroupName "MyResourceGroup" -DiskName "MySourceDisk"
# Create a new empty target disk
# For Windows OS disks
$diskConfig = New-AzDiskConfig -Location $sourceDisk.Location -CreateOption Upload -UploadSizeInBytes $($sourceDisk.DiskSizeBytes+512) -OsType Windows -HyperVGeneration "V2"
# For Linux OS disks (if not ADE-encrypted)
# $diskConfig = New-AzDiskConfig -Location $sourceDisk.Location -CreateOption Upload # -UploadSizeInBytes $($sourceDisk.DiskSizeBytes+512) -OsType Linux # -HyperVGeneration "V2"
# For data disks (no OS type needed)
# $diskConfig = New-AzDiskConfig -Location $sourceDisk.Location -CreateOption Upload # -UploadSizeInBytes $($sourceDisk.DiskSizeBytes+512)
$targetDisk = New-AzDisk -ResourceGroupName "MyResourceGroup" -DiskName "MyTargetDisk" -Disk $diskConfig
# Generate SAS URIs and copy the data
# Get SAS URIs for both disks
$sourceSAS = Grant-AzDiskAccess -ResourceGroupName "MyResourceGroup" -DiskName $sourceDisk.Name -Access Read -DurationInSecond 7200
$targetSAS = Grant-AzDiskAccess -ResourceGroupName "MyResourceGroup" -DiskName $targetDisk.Name -Access Write -DurationInSecond 7200
# Copy the disk data using AzCopy
azcopy copy $sourceSAS.AccessSAS $targetSAS.AccessSAS --blob-type PageBlob
# Revoke SAS access when complete
Revoke-AzDiskAccess -ResourceGroupName "MyResourceGroup" -DiskName $sourceDisk.Name
Revoke-AzDiskAccess -ResourceGroupName "MyResourceGroup" -DiskName $targetDisk.Name
Pour mon disque data configuré en premium SSDv2, je crée un snapshot manuellement :
Depuis le nouveau disque OS créé via le script plus haut, je relance la création d’une nouvelle machine virtuelle :
Je configure cette nouvelle machine virtuelle, en y intégrant le disque de data issu du snapshot, puis je lance sa création :
Une fois la machine virtuelle créée, j’éteins celle-ci, puis j’active Encryption at host dans les paramétrages des disques :
Je redémarre la machine virtuelle, puis je constate dans l’affichage du diagnostic le bon démarrage de celle-ci :
Conclusion
Au final, SSE et Encryption at Host couvrent aujourd’hui l’essentiel des besoins, avec un impact quasi nul sur la VM et une gestion simplifiée. SSE reste la base, toujours activée, tandis qu’Encryption at Host ajoute une couche complète de protection sans coût CPU notable.
ADE fonctionne encore, mais son intégration à l’OS et sa charge CPU supplémentaire en font une solution plus lourde à exploiter. Avec les résultats obtenus et sa dépréciation annoncée, il devient clairement le mécanisme à éviter pour les nouvelles machines virtuelles.
SSE : excellente base, impact minimal, tout est géré par la plateforme.
Encryption at Host : même niveau de performance que SSE, avec la garantie que toutes les couches (OS, data, cache, disque temporaire) sont chiffrées directement par l’hyperviseur.
ADE : Performances disque similaires, mais CPU plus élevé, dû au chiffrement dans la VM. Cela confirme pourquoi ce mode est progressivement remplacé par les autres mécanismes gérés par la plateforme.
Pour la majorité des workloads, Encryption at Host apparaît désormais comme l’option la plus propre, la plus simple et la plus pérenne.
Bienvenue dans ce lab pratique consacré à Microsoft Foundry, la plateforme unifiée qui permet d’explorer, tester et déployer des expériences d’intelligence artificielle au sein de l’écosystème Azure. Cet article retrace pas à pas les différentes étapes du lab afin de permettre à chacun de revivre l’expérience ou de la reproduire en autonomie.
Lors du Chalet Azure Romandie du 27 novembre 2025, les participants ont pu découvrir concrètement comment manipuler des modèles avancés comme gpt-4o et Sora, créer leurs propres agents, générer des vidéos IA, ajouter des filtres de sécurité, traduire des documents, ou encore produire un avatar animé.
Voici donc les 5 défis que vous pouvez également essayer :
Le Chalet Azure Romandie remercie d’ailleurs Philippe Paiola de chez Microsoft pour la création de ces défis 🙏.
Etape 0 – Connexion à Microsoft Foundry :
Pour réaliser cet exercice sur Microsoft 365 Archive, il vous faudra disposer d’une souscription Azure valide.
Ouvrez un navigateur web, puis saisissez l’URL du portail Azure AI Foundry (nouvellement Microsoft Foundry) :
Authentifiez-vous avec un e-mail professionnel ou personnel :
Une fois authentifiée, conservez l’ancienne présentation du portail de Microsoft Foundry, appelée encore Azure AI Foundry, afin de suivre les consignes ci-dessous plus facilement :
Commençons le premier défi par le déploiement d’un agent.
Défi I – Création d’un Agent Smith :
Nous allons déployer un agent qui s’appuiera sur le modèle gpt-4o et répondra aux différentes questions du défi.
Pour cela, cliquez-ici pour créer votre agent :
Mais comme aucun projet IA n’est encore présent, nous allons commencer par la création de celui-ici. Pour cela, renseignez les informations pour la création de votre nouveau projet IA, puis lancez sa création :
Dans le champ Projet, saisissez projet-agent
Développez options avancées
Choisissez la souscription Azure disponible
Donnez un nom unique à votre ressource Azure AI Foundry
Nommez rg-chalet-romandie le nom de votre groupe de ressource
Vérifiez que la région Azure East US 2 est bien sélectionnée
Attendez environ 2 à 3 minutes pour la fin de la création des ressources Azure :
Une fois le déploiement terminé, cliquez sur le menu Playgrounds afin de commencer par le déploiement d’un premier modèle IA, recherchez dans la liste le modèle gpt-4o, puis cliquez sur le bouton Confirmer :
Conservez les options de base de votre modèle, puis cliquez sur le bouton Déployer :
Une fois le modèle IA déployé, retournez dans le menu Playgrounds afin de lancer le prompt suivant sur le nouvel agent, automatiquement créé et lié à votre modèle :
Générer une blague sur les informaticiens
L’erreur suivante peut apparaître. Elle indique que les ressources IA ne sont pas encore entièrement accessibles :
Après plusieurs minutes et plusieurs essais, vous devriez obtenir une réponse dans le chat de la part de votre agent IA :
Votre défi est réussi, vous pouvez le faire valider, puis passez au défit suivant.
Défi II – Génération d’une vidéo IA :
Imaginez pouvoir créer des scènes vidéo réalistes, des animations et des effets spéciaux, à partir d’instructions textuelles simples et précises. Foundry vous permet de réaliser cette prouesse à l’aide du modèle Sora d’OpenAI.
La génération de vidéos dans ce cas est un processus asynchrone. Vous créez une demande de travail avec vos spécifications d’invite (ou prompt en anglais) de texte et de format vidéo, et le modèle traite la demande en arrière-plan.
Une fois terminé, récupérez la vidéo générée via une URL de téléchargement.
Cliquez sur le menu à gauche Playgrounds, puis le menu suivantafin de tester la génération de vidéos par l’IA :
Cliquez ici pour déployer un nouveau modèle IA destiné à la génération de la vidéo :
Choisissez le modèle Sora dans la liste, puis cliquez sur Confirmer :
Conservez les options de base, puis cliquez sur le bouton Déployer :
Une fois le modèle Sora déployé, retournez dans le menu Playgrounds afin de lancer le prompt de génération de la vidéo :
Sélectionnez la résolution 720p,une durée de 10 secondes, saisissez votre prompt qui générera une vidéo époustouflante, puis cliquez sur le bouton Générer.
Attendez quelques instants avant de pouvoir constater le résultat :
Après quelques instants, visionnez le résultat généré par Sora :
Votre défi est réussi, vous pouvez le faire valider, puis passer au défit suivant.
Défi III – Filtrage IA de contenu :
Microsoft Foundry embarque en standard les composants Azure AI Content Safety pour filtrer les contenus répréhensibles générés ou traités (détection de langage toxique, données personnelles partagées, etc…).
Nous allons créer un filtre et une liste de blocage basés sur le mot AWS. Nous allons dans un premier temps créer une liste de blocage :
Saisissez un nom représentant la liste, blocklistaws,puis cliquez sur le bouton suivant pour créer celle-ci :
Ajoutez un nouveau terme :
Saisissez le terme AWS, puis ajoutez-le :
Nous allons maintenant créer notre propre filtre de contenu et l’associer à notre liste de blocage. Pour cela, cliquez sur le bouton ci-dessous pour créer un filtre de contenu :
Saisissez un nom représentant le filtre, filtrereomandie, puis cliquez sur le bouton Suivant :
Dans l’étape Filtre d’entrée, pour chaque catégorie (haine, violence …), spécifiez le niveau de dureté appliqué à Highest blocking , cochez la case Liste de blocage, sélectionnez blocklistaws, puis cliquez sur Suivant :
Dans l’étape Filtre de sortie, pour chaque catégorie (haine, violence …), spécifiez le niveau de dureté appliqué à Highest blocking , cochez la case Liste de blocage, sélectionnez blocklistaws, puis cliquez sur Suivant :
Sélectionnez le modèle qui recevra ce filtre de contenu personnalisé, dans notre cas gpt-4o :
Confirmez le remplacement du filtrage de contenu de page par le nouveau :
Lancez la création du filtrage IA :
Retournez dans Playgrounds, puis cliquez sur Chat playground :
Collez le prompt suivant dans le chat :
Comment utiliser AWS ?
Un retour négatif de la part d’Azure IA Foundry, et invoquant blocklistaws, devrait apparaître. Continuez avec le prompt suivant :
Comment me faire très mal au bras ?
Un retour négatif de la part d’Azure IA Foundry, et invoquant Self-harm, devrait apparaître.
Votre défi est réussi, vous pouvez le faire valider, puis passer au défit suivant.
Défi IV – Traduction IA de documents :
La traduction automatique est l’un des domaines historiques de l’IA de Microsoft. L’entreprise propose un service de traduction basé sur des réseaux de neurones, connu sous le nom d’Azure AI Translator, capable de traduire instantanément du texte ou des documents entiers d’une langue à une autre.
Cliquez sur le menu suivant afin de générer une traduction de texte :
Cliquez sur Text translation :
Collez le texte suivant, choisissez le français comme langue de destination, puis lancez la traduction :
Azure Speech permet en résumé de tester et prototyper rapidement des fonctionnalités de reconnaissance vocale, conversion texte-vers-voix, traduction audio, etc., sans avoir à tout coder ou déployer de façon complète.
Cliquez sur le menu suivant afin de générer un avatar :
Choisissez le menu Text to speech avatar, puis cliquez sur Lisa parmi la liste des avatars disponibles :
Définissez la langue française, la voix de Vivienne, collez le texte ci-dessous, puis lancez la génération de la vidéo :
Romandie un jour, Romandie toujours.
Attendez quelques secondes la fin de la génération de la vidéo :
Une fois la vidéo générée, lancez-là pour en vérifier le contenu :
Une fois tous les défis terminés :
Conclusion
Ce parcours à travers Microsoft Foundry met en lumière la richesse des outils IA disponibles aujourd’hui : agents personnalisés, génération multimédia, filtrage de contenu, traduction, ou encore avatars vocaux.
Chaque défi illustre la maturité croissante de l’écosystème et la facilité avec laquelle il devient possible d’expérimenter, prototyper et imaginer de nouvelles solutions basées sur l’IA.
Que ce lab inspire de futurs projets et continue d’alimenter la dynamique d’innovation au sein de la communauté !
Depuis de longues années, la communauté Azure Virtual Desktop attendait la possibilité de déployer un environnement entièrement cloud, sans dépendance à un domaine Active Directory classique ou à une architecture hybride complexe. Cette évolution permet enfin d’envisager un modèle moderne, simplifié et résolument cloud-native.
Au-delà du progrès technique évident (principalement la simplification de l’infrastructure) cette nouveauté transforme aussi la manière d’aborder la gestion des accès distants et des profils utilisateurs.
Elle marque le passage d’un modèle traditionnel mêlant domaine Active Directory, synchronisation, et Kerberos hybride, vers un modèle entièrement cloud-only : plus léger, plus agile et parfaitement adapté aux organisations modernes, aux partenaires externes ou encore aux environnements projet éphémères.
Cette annonce fut d’ailleurs intégrée à celle des identités externes sur AVD et Windows 365 :
Pour offrir une expérience simplifiée dans un environnement mutualisé Azure Virtual Desktop pour les identités externes, vous pouvez créer un partage de fichiers dans Azure Files afin de stocker les profils FSLogix pour ces identités.
Cette fonctionnalité est désormais disponible en préversion publique. Pour créer un partage de fichiers SMB pour les profils FSLogix pour les identités externes :
Créez un nouveau compte de stockage et un nouveau partage de fichiers configurés pour utiliser l’authentification Microsoft Entra Kerberos.(Nouveau) Lorsque vous attribuez des autorisations pour le partage de fichiers, utilisez la nouvelle page Gérer l’accès pour attribuer des listes de contrôle d’accès (ACL) au groupe Entra ID contenant vos identités externes.
Microsoft illustre également cette nouveauté avec une copie d’écran montrant la gestion native des droits NTFS d’un partage Azure Files directement depuis le portail Azure, ce qui constitue une avancée très attendue :
Qu’est-ce qu’une identité cloud-only ?
Il s’agit d’un utilisateur géré uniquement dans Entra ID, sans représentation dans un Active Directory on-prem, ni synchronisation : idéal pour des contractors, partenaires, ou utilisateurs externes.
Est-ce que FSLogix fonctionne avec ces identités externes / cloud-only ?
Oui, le support FSLogix pour cloud-only & external identities est désormais en preview, ce qui permet de gérer les profils utilisateurs de façon identique à un utilisateur « classique ».
Que change concrètement pour un architecte cloud ou un administrateur ?
Cela signifie moins de dépendances à un AD on-prem, moins de complexité, une gestion simplifiée des utilisateurs externes ou contractors, et un modèle plus cloud-native.
Plusieurs vidéos sont également disponible pour vous aider à la tâche :
Pour y parvenir, plusieurs documentations sont disponibles afin de mettre en place toute la chaîne. Le premier guide Microsoft explique comment activer Kerberos Entra sur Azure Files, tandis que le second part de ce socle et donne seulement ce qu’il faut ajouter pour FSLogix :
Je vous propose donc de passer en revue, étape par étape, l’ensemble de la configuration permettant de tester cette nouvelle fonctionnalité encore en préversion.
L’objectif est de comprendre son fonctionnement réel, ses limites et les scénarios dans lesquels elle pourra s’intégrer :
Pour réaliser ce test FSLogix en mode 100% Cloud-only, il vous faudra disposer de :
Un abonnement Azure valide
Un tenant Microsoft
Afin d’être sûr des impacts de nos différentes actions, je vous propose de commencer par la création d’une nouvel utilisateur 100% Cloud, donc non synchronisé à un environnement Active Directory.
Etape I – Préparation de l’environnement :
Création d’un utilisateur cloud-only pour préparer l’environnement sans synchronisation AD :
Mise en place du réseau virtuel qui servira de base à l’environnement Azure Virtual Desktop :
Déploiement d’un compte de stockage Azure Files Premium pour accueillir les profils FSLogix :
Activation de l’identité Microsoft Entra directement sur le compte de stockage :
Activation du support Microsoft Entra Kerberos pour gérer l’authentification :
Application des permissions par défaut via le rôle Storage File Data SMB Share Contributor :
Création du partage de fichiers pour FSLogix, avec l’identité Microsoft Entra toujours active :
Recherche de l’application d’entreprise générée automatiquement pour ce compte de stockage :
Attribution du consentement administrateur global pour autoriser l’application
Validation de l’autorisation accordée à l’application d’entreprise :
Vérification des permissions héritées depuis l’admin consent sur l’application liée au stockage :
Ajout de la prise en charge des groupes dans le manifeste :
["kdc_enable_cloud_group_sids"],
Retrait du compte de stockage dans les polices d’accès conditionnel exigeant une MFA :
Création d’un environnement Azure Virtual Desktop avec deux machines virtuelles :
Activation du Single Sign-On directement dans les propriétés RDP :
Exécution du premier script PowerShell via Run Command pour activer la récupération du ticket Kerberos :
Vérification de la création des clés de registre attendues pour FSLogix :
Alternative via Intune pour gérer ces mêmes paramètres sans script :
!!! Redémarrage des machines virtuelles du host pool pour appliquer la configuration !!!
Etape II – Test de connexion AVD :
Attente du retour en ligne des machines dans l’environnement AVD :
Activation du mode de drainage sur la seconde machine pour préparer les tests :
Connexion avec l’utilisateur de test pour valider le fonctionnement :
Observation du démarrage du service FSLogix App Services à l’ouverture de session :
Création du dossier de profil FSLogix directement dans le file share :
Présence du fichier VHDx correspondant au profil utilisateur :
Impossibilité de supprimer le fichier VHDx car il est monté et en cours d’utilisation :
Confirmation dans les logs FSLogix que le profil VHDx est correctement chargé :
Inversion du mode de drainage sur les deux machines AVD :
Reconnexion avec l’utilisateur de test pour valider la bascule du profil :
Montage d’un partage réseau pour inspecter le contenu du partage de fichier Azure :
Vérification que la permission générée pour l’utilisateur de test est bien présente :
Afin de finaliser correctement la configuration des permissions pour les profils FSLogix, il est nécessaire de les restreindre pour plus de sécurité.
Etape III – Configurations des permissions NTFS Access Control Lists:
Depuis l’explorateur Windows, je constate que certaines permissions restent visibles, alors qu’elles ne devraient être retirées pour des questions de sécurité :
Je constate également l’impossibilité de modifier les permissions directement depuis Windows ou via une commande ICACLS :
Travis Roberts rencontre d’ailleurs le même souci que moi :
Pour configurer les Windows ACLs, il sera donc nécessaire de passer par le menu Manage Access, visible depuis un portail Azure en préversion, comme le recommande Microsoft dans la documentation :
Le bouton Manage access est alors visible juste ici :
Ce menu n’est d’ailleurs pas visible dans le portail classique d’Azure :
L’affichage des permissions NTFS Access Control Lists configurées par défaut :
Les permissions pour FSLogix doivent alors être reconfigurées comme telles :
Cela donne ceci sur le partage de fichier FSLogix :
Les tests initiaux montrent que l’intégration fonctionne correctement entre FSLogix et Azure Virtual Desktop. Toutefois, quelques écarts apparaissent encore entre la documentation Microsoft et le comportement observé dans mon environnement, ce qui mérite d’être signalé dans le cadre de cette préversion.
Pour compléter mon analyse, il est intéressant de comparer les performances (IOPS et Throughput) entre plusieurs types de stockage, notamment ceux intégrés avec Entra ID.
Etape IV – Tests de performances :
J’ai souhaité comparé les performances entre différents types de stockage afin de bien comprendre l’impact ou non des performances avec cette jointure à Entra ID :
Partage de fichiers sur un compte de stockage Premium joint à Entra ID
Partage de fichiers sur un compte de stockage Premium non joint à Entra ID
Disque Premium SSD v2, configuré avec 30000 IOPS et 1200 de Throughput
Pour réaliser les mesures, nous utiliserons l’outil Diskspd :
DISKSPD est un outil que vous pouvez personnaliser pour créer vos propres charges de travail synthétiques. Nous utiliserons la même configuration que celle décrite ci-dessus pour exécuter des tests d’évaluation. Vous pouvez modifier les spécifications pour tester différentes charges de travail.
Microsoft recommande d’utiliser l’utilitaire DiskSpd (https://aka.ms/diskspd) pour générer une charge sur un système de disques (stockage) et … pour mesurer les performances du stockage et obtenir la vitesse maximale disponible en lecture/écriture et les IOPS du serveur spécifique.
Sur votre machine virtuelle de test, téléchargez l’exécutable via ce lien Microsoft, puis ouvrez l’archive ZIP téléchargée :
Copiez le contenu de l’archive dans un nouveau dossier créé sur le disque C :
L’exécutable se trouve dans le sous-dossier amd64 :
Les 2 étapes suivantes sont dédiées aux tests de performances des disques via l’application Diskspd. Microsoft met d’ailleurs à disposition un protocole similaire de tests juste ici :
Deux séries de tests sont conseillées pour exploiter le deux caractéristiques suivantes :
IOPS
Débit
Le changement entre ces deux séries se fera au niveau de la taille des blocs.
Commencez une première salve de tests pour déterminer les IOPS max pour chacun des espaces de stockage :
Partage de fichiers sur un compte de stockage Premium joint à Entra ID :
Partage de fichiers sur un compte de stockage Premium non joint à Entra ID :
Disque Premium SSD v2 configuré avec 30000 IOPS et 1200 de Throughput :
Ouvrez Windows PowerShell ISE, puis lancez les commandes des test suivantes, une à une ou à la chaîne, en modifiant les paramètres si besoin :
Les arguments utilisés pour diskspd.exe sont les suivants :
-d900 : durée du test en secondes
-r : opérations de lecture/écriture aléatoires
-w100 : rapport entre les opérations d’écriture et de lecture 100%/0%
-F4 : nombre de threads max
-o128 : longueur de la file d’attente
-b8K : taille du bloc
-Sh : ne pas utiliser le cache
-L : mesure de la latence
-c50G : taille du fichier 50 GB
E:\diskpsdtmp.dat : chemin du fichier généré pour le test
> IOPS-AvecEntra.txt : fichier de sortie des résultats
Une fois tous les tests terminés, les résultats sont alors compilés pour les 3 stockages :
Scenario
IOPS
Bandwidth MB/s
Avec Entra ID
12,446.88
299.95
Sans Entra ID
15,032.54
341.17
Premium SSD v2
20,378.31
1,167.25
Les résultats montrent que le Premium SSD v2 délivre les meilleures performances dans ton environnement, avec le plus haut niveau d’IOPS et de bande passante, suivi par le scénario Sans Entra ID, puis par le scénario Avec Entra ID qui obtient systématiquement les valeurs les plus faibles.
La différence entre les scénarios avec et sans Entra ID pourrait s’expliquer par la présence d’une couche d’authentification et de gestion de profils qui ajoute des opérations supplémentaires lors des accès disque, en particulier si le système doit interroger un service distant, valider un token, ou maintenir une session d’identité pour chaque opération liée au profil utilisateur.
Même si cette charge reste faible en théorie, elle peut introduire une latence additionnelle dans un flux d’I/O intensif, ce qui réduirait mécaniquement les IOPS et la bande passante observées.
Conclusion
Le support des identités cloud-only et externes pour Azure Virtual Desktop, associé à l’intégration de FSLogix, représente une évolution majeure dans l’écosystème Microsoft. Cette approche permet désormais de déployer des environnements VDI complets sans aucune dépendance à Active Directory, tout en simplifiant considérablement l’architecture.
Cette modernisation apporte davantage de flexibilité, réduit les contraintes opérationnelles et ouvre la voie à de nouveaux scénarios cloud-native, adaptés aussi bien aux entreprises qu’aux équipes projet, partenaires ou prestataires externes.
Bien que la fonctionnalité soit encore en préversion, elle laisse entrevoir un futur où les environnements virtualisés seront plus simples, plus économiques et mieux intégrés à l’identité Microsoft Entra.
Depuis la mi-2025, Microsoft renforce progressivement les paramètres de sécurité par défaut dans ses environnements Windows 365 et Azure Virtual Desktop (AVD). L’un des changements les plus visibles pour les administrateurs et utilisateurs concerne la redirection du presse-papiers (clipboard), désormais désactivée par défaut dans les nouvelles configurations.
Cette évolution, alignée avec la Microsoft Secure Future Initiative (SFI), vise à limiter les risques d’exfiltration de données et à uniformiser la posture de sécurité entre Windows 365 et AVD. Mais concrètement, comment ce changement s’applique-t-il ? Quels paramètres contrôlent réellement le comportement du presse-papiers ? Et comment vérifier la configuration effective entre les deux couches (Propriétés RDP et stratégies GPO/Intune) ?
Dans mon précédent article, publié fin 2024, je présentais les options de durcissement du presse-papiers AVD via Intune et les propriétés RDP. Depuis mi-2025, Microsoft est passé d’une approche configurable à une approche imposée par défaut : les redirections (presse-papiers, lecteurs, USB, imprimantes) sont désormais désactivées nativement dans Windows 365 et AVD. Ce qui était un bon réflexe de sécurité devient aujourd’hui la norme.
Une excellente référence pour cette mise à jour est l’article de Dieter Kempeneers, Configure Advanced Clipboard AND Drive Redirection for AVD and Windows 365, dans lequel il détaille non seulement la désactivation par défaut des redirections (presse-papiers, lecteurs, imprimantes) sur les nouveaux hôtes AVD et les Cloud PC Windows 365, mais aussi la façon d’en réactiver certains comportements de façon granulaire.
Dans ce nouvel article, je décortique la logique de redirection RDP, les nouvelles valeurs par défaut introduites par Microsoft, et surtout, les implications pratiques pour vos déploiements et modèles AVD / Windows 365.
Depuis quand Microsoft a changé la règle du presse-papier pour Windows 365 ?
Microsoft a introduit de nouveaux paramètres de sécurité par défaut pour Windows 365 Cloud PCs le 18 juin 2025 :
Windows 365 renforce la sécurité des PC cloud en désactivant par défaut les redirections du presse-papiers, des lecteurs, des périphériques USB et des imprimantes pour tous les PC cloud nouvellement provisionnés et reprovisionnés. Cette modification minimise le risque d’exfiltration de données et d’injection de logiciels malveillants, ce qui offre une expérience plus sécurisée et s’aligne sur le principe de l’initiative Microsoft Secure Future Initiative (SFI) visant à activer et à appliquer par défaut les protections de sécurité.
Un message sous forme de bandeau est bien visible lors de la création d’une police de provisionnement Windows 365 :
D’ailleurs, la police de configuration de sécurité appelée Windows 365 Security Baseline et disponible sur Intune contient bien une restriction qui concerne les lecteurs, donc, de facto, le transfert de fichiers :
Est-ce que cette restriction concerne aussi Azure Virtual Desktop ?
Oui, les nouveaux pools d’hôtes Azure Virtual Desktop sont aussi concernés par ce renforcement :
Cette modification des paramètres par défaut de redirection sera bientôt effective. Afin d’aider les administrateurs informatiques à s’y préparer, une bannière pouvant être ignorée s’affichera sur la page d’accueil « Créer un pool d’hôtes » du portail Azure. Cette bannière informera les administrateurs des nouveaux paramètres par défaut pour les nouveaux pools d’hôtes et fournira des liens vers la documentation expliquant comment les remplacer en modifiant les propriétés RDP du pool d’hôtes une fois celui-ci créé.
Remarque : pour les pools d’hôtes existants, aucune modification ne sera apportée à la configuration de redirection en votre nom. Cependant, nous vous recommandons de renforcer la sécurité des paramètres en désactivant les redirections qui ne sont pas nécessaires. Pour effectuer ces modifications, consultez la section relative à la redirection des appareils dans la documentation sur les propriétés RDP.
Voici la nouvelle option de configuration RDP mise par défaut, et visible dans les propriétés du pool d’hôtes AVD :
D’ailleurs, la police de configuration de sécurité appelée Security Baseline for Windows 10 and later et disponible sur Intune contient bien une restriction qui concerne les lecteurs, donc de facto le transfert de fichiers :
Qu’est-ce que cela change pour mes futures créations AVD et Windows 365 ?
Pour AVD : pour tout nouveau pool d’hôtes créé après la date de changement, les redirections de presse-papier, lecteurs, USB et imprimantes seront désactivées par défaut.
Pour Windows 365 : idem pour tous les Cloud PCs nouvellement provisionnés ou reprovisionnés : les mêmes redirections sont désactivées par défaut.
Impact : vos modèles, templates ou polices qui s’appuyaient sur ces redirections devront être revus. Si vous aviez des scénarios utilisateur où l’on transférait facilement du contenu local vers le poste cloud, il faudra anticiper ce nouveau comportement.
Comment identifier la configuration actuelle des postes ?
Le comportement dépend de deux couches complémentaires. Le serveur RDP n’impose pas unilatéralement la redirection : il la négocie avec le client en fonction de ces deux niveaux :
Le client (.rdp / Propriétés RDP AVD) détermine ce qui est demandé ou refusé pour la session. Exemple : redirectclipboard:i:0 dans les propriétés RDP d’un host pool.
Le serveur (Policies / GPO / Intune) définit ce qui est autorisé ou interdit de manière globale sur la machine. Exemple : fDisableClipboard dans le registre des stratégies.
Première couche : configuration client / RDP Properties :
Ces valeurs correspondent à la configuration du service RDP. Elles sont mises à jour lorsque tu modifies les RDP Properties d’un host pool dans AVD, par exemple :
Ces valeurs représentent la couche de gouvernance :
Elles sont prioritaires sur les paramètres locaux et sont appliquées au démarrage du service TermService.
Elles déterminent ce qui est autorisé ou interdit globalement sur la machine, indépendamment des paramètres envoyés par le .rdp.
La configuration peut se faire très facilement depuis une police de configuration Intune :
Interaction entre les deux couches :
Le comportement effectif correspond toujours à la configuration la plus restrictive :
Policy (serveur)
RDP Property (client/session)
Résultat final
Autorise
Interdit (redirectclipboard:i:0)
❌ Redirection désactivée
Interdit
Autorise (redirectclipboard:i:1)
❌ Redirection désactivée
Autorise
Autorise
✅ Redirection active
Résultats de tests : comportement réel du presse-papiers RDP
Pour mieux comprendre ces nouveaux paramètres de redirection du presse-papiers, j’ai réalisé une série de tests sur plusieurs configurations RDP (AVD et Windows 365).
Le but était de vérifier quels types de données (texte, image, HTML, binaire, etc.) pouvaient être copiés dans chaque sens selon les paramètres du serveur et du client.
Les couches de configuration RDP :
Les deux couches peuvent définir différentes valeurs, mais elles ne s’écrasent pas : le moteur RDP évalue d’abord la police, puis les propriétés RDP :
Couche
Rôle
1. ConfigurationRDP
Paramètres appliqués au niveau du service RDP local. C’est ce qu’utilise la session à l’exécution. Modifié par les propriétés RDP d’un host pool AVD.
2. Policy configuration (GPO / Intune)
Paramètres de gouvernance. Écrits par une stratégie (GPO/MDM) et prioritaires sur la configuration locale.
Niveaux de granularité (SCClipLevel / CSClipLevel) :
Les valeurs SCClipLevel et CSClipLevel permettent aussi d’affiner très précisément la redirection dans chaque sens :
SC (Server → Client) : copier du cloud vers le poste local.
CS (Client → Server) : copier du poste local vers le cloud.
Niveau
Formats autorisés
Exemple
0
Aucune redirection
Blocage total
1
Texte brut uniquement
Copier/coller texte simple
2
Texte brut + images
Exemple : capture d’écran
3
Texte brut + images + RTF
Texte formaté (Word, Outlook)
4
+ HTML
Copier/coller depuis un navigateur
Comment cela se voit pour Windows 365 ?
Voici un récapitulatif des différents tests effectués, en modifiant les propriétés pour AVD ou Windows 365 :
Et voici le détail de ces tests avec les configurations Intune appliquées pour impacter le registre Windows :
Test A – Clipboard redirection isn’t available : Le presse-papiers est complètement désactivé côté session RDP. Aucun copier/coller ne fonctionne dans aucun sens :
Test B – Clipboard redirection is available : Le presse-papiers est activé côté session RDP. Le copier/coller fonctionne dans les deux sens :
Test C – Do not allow Clipboard redirection Disabled (fDisableClip=0). Le comportement dépend donc de la configuration du fichier .rdp, qui est activé. Le copier/coller fonctionne dans les deux sens :
Test D – Do not allow Clipboard redirection Enabled (fDisableClip=1). Blocage complet du copier/coller, même si le .rdp autorise la redirection :
Test E – Do not allow Clipboard redirection Disabled (fDisableClip=0), comme la configuration du fichier .rdp, qui est activé. Disable clipboard transfers from session host to client (SCClipLevel=0) et inversement (CSClipLevel=0). Aucun copier-coller descendant ou montant n’est possible :
Test F – Allow plain text : Autorise uniquement le texte brut (SCClipLevel=1 / CSClipLevel=0 / fDisableClip=0). Le copier/coller d’images fonctionne du host vers le client, mais pas inversement, et pas d’images ni de formats enrichis :
Test G – Allow plain text and image : Autorise texte brut + images (SCClipLevel=2 / CSClipLevel=0 / fDisableClip=0). Le copier/coller d’images fonctionne du host vers le client, mais pas inversement :
Test H – Ajoute le support du Rich Text (SCClipLevel=3 / CSClipLevel=0 / fDisableClip=0). Le copier/coller de texte et d’images fonctionne, mais pas HTML ni formats binaires. Le copier/coller d’images fonctionne du host vers le client, mais pas inversement :
Test I – Allow plain text, images, Rich Text Format and HTML. Ajoute HTML (SCClipLevel=4 / CSClipLevel=0 / fDisableClip=0). Formats binaires toujours bloqués.Le copier/coller d’images fonctionne du host vers le client, mais pas inversement :
Test J – Allow plain text, images, Rich Text Format, HTML and Binary. Autorise tous les formats, y compris binaires (CSClipLevel=0 / fDisableCdm=0 / fDisableClip=0). Tous les copier/coller possibles du host vers client :
Test K – Allow plain text (inverse direction). Même logique que F mais appliquée au client → host (SCClipLevel=0 / CSClipLevel=1 / fDisableClip=0). Seul le texte brut passe du poste local vers le cloud :
Test L – Allow plain text and images (inverse direction). Autorise texte et images du client vers la session (SCClipLevel=0 / CSClipLevel=2 / fDisableClip=0) :
Test M – Allow plain text, images and Rich Text Format (inverse direction). Ajoute RTF côté client → host (SCClipLevel=0 / CSClipLevel=3 / fDisableClip=0). HTML et binaire toujours bloqués :
Test N – Allow plain text, images, Rich Text Format and HTML (inverse direction). Permet HTML du client vers la session (SCClipLevel=0 / CSClipLevel=4 / fDisableClip=0) :
Test O – Allow plain text, images, Rich Text Format, HTML and Binary (inverse direction). Autorise tous les formats, y compris binaires (SCClipLevel=0 / fDisableCdm=0 / fDisableClip=0). Tous les copier/coller possibles du client vers le host :
Conclusion
La désactivation par défaut des redirections RDP dans Windows 365 et AVD s’inscrit dans une tendance claire : un durcissement progressif des environnements cloud Windows pour tendre vers le secure by default.
Pour les architectes et administrateurs, cela signifie qu’il faut désormais anticiper ce comportement dans les modèles de provisionnement, les recommandations Intune et les templates de pools AVD.
Le presse-papiers, souvent considéré comme un simple confort utilisateur, devient un point de contrôle important dans la stratégie de sécurité : il faut choisir entre flexibilité et maîtrise du flux de données entre les environnements locaux et cloud.
En maîtrisant les deux couches de configuration (Propriétés RDP et polices GPO/MDM) et les niveaux SCClipLevel / CSClipLevel, vous pouvez adapter finement le niveau de redirection autorisé, du simple texte brut jusqu’à la copie complète de formats binaires.
En résumé : ce changement n’est pas une contrainte, mais une opportunité d’élever le niveau de sécurité sans perdre la visibilité sur le fonctionnement interne du protocole RDP.