Dans les environnements de bureaux à distance modernes (Azure Virtual Desktop, Windows 365, Citrix …) l’expérience utilisateur dépend énormément du protocole d’affichage distant, du réseau, des ressources , … Quand tout fonctionne bien, personne ne s’en préoccupe. Mais dès qu’un utilisateur dit : « mon Cloud PC lag », « la vidéo est saccadée », « j’ai un délai quand je tape au clavier » … on entre immédiatement dans une zone grise. Bon courage pour comprendre la cause !

Un problème d’affichage distant peut venir de nombreux endroits : réseau, client, serveur, GPU, codec vidéo, politiques de compression et j’en passe.
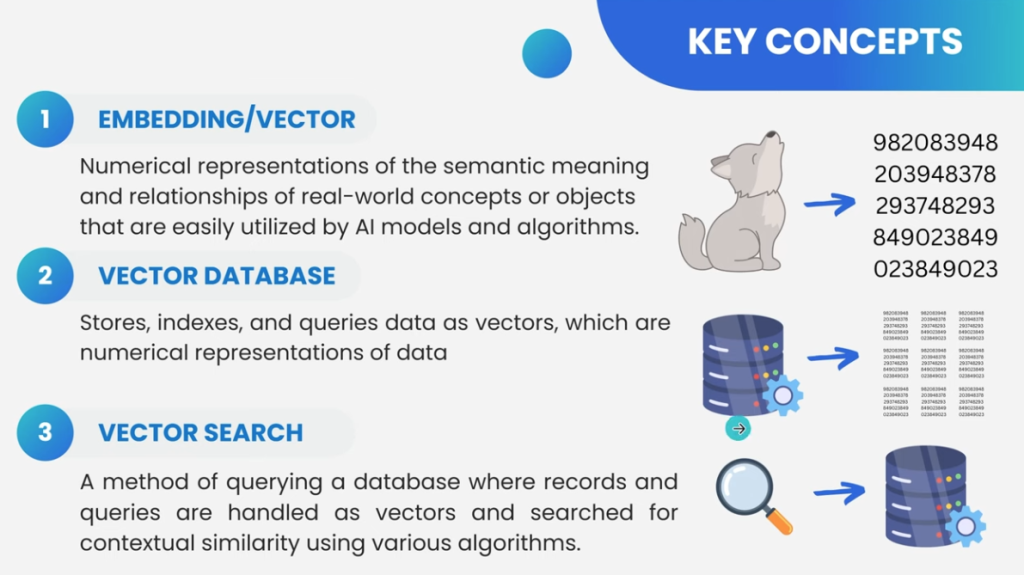
C’est exactement pour cela que j’aime beaucoup un outil que j’utilise régulièrement lors de phases de troubleshooting : Remote Display Analyzer (RDA).
Cet outil permet de voir et tester en direct ce que fait réellement le protocole d’affichage distant :
Avant d’aller plus loin, je voulais remercier l’équipe RDA de m’avoir donné une licence pour réaliser mes tests.
Et pour vous guider plus facilement dans cet article très long, voici des liens rapides :
- Qu’est‑ce que Remote Display Analyzer ?
- Combien coûte RDA ?
- Comment fonctionne RDA ?
- Comment interpréter les métriques de RDA ?
- Qu’est-ce que les « Skipped Frames » ?
- Quelques exemples de problèmes que RDA permet d’analyser
- Peut-on modifier certains réglages graphiques avec RDA ?
Qu’est‑ce que Remote Display Analyzer ?
Remote Display Analyzer (RDA) est un petit et très léger outil conçu pour analyser les protocoles d’affichage utilisés dans les environnements de virtualisation de poste de travail.
Il ne supporte pas que des environnements Microsoft, mais bon nombre de solutions présentes sur le marché, notamment :
- Microsoft RDP
- Azure Virtual Desktop
- Windows 365
- Citrix HDX
- Omnissa / VMware Horizon Blast
- Nutanix Frame
Combien coûte RDA ?
Remote Display Analyzer est décliné en plusieurs éditions afin de répondre à des besoins différents. En plus de l’édition Community, il existe une édition Personal ainsi qu’une édition Company, qui offrent des fonctionnalités avancées adaptées à des usages plus professionnels ou à grande échelle :
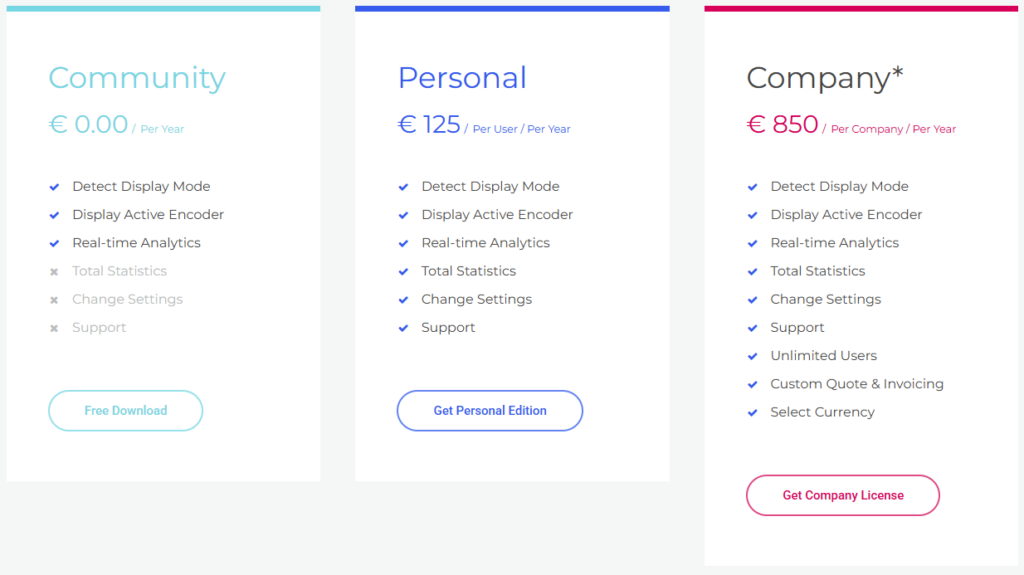
Il existe une version gratuite de RDA : l’édition Community permet d’accéder aux statistiques temps réel du protocole d’affichage, ce qui est largement suffisant pour de nombreux scénarios de diagnostic et de troubleshooting :
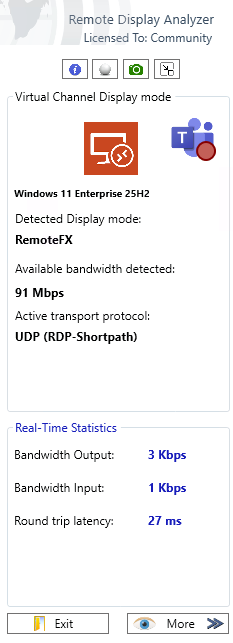
Voici un lien de téléchargement de la version gratuite de RDA. Enfin les deux autres versions payantes sont plus complètes, et remontent plus données :
Comment fonctionne RDA ?
Comme annoncé plus haut, Remote Display Analyzer ne nécessite aucune installation préalable. L’outil se présente sous la forme d’un simple exécutable qui peut être lancé directement à l’intérieur d’une session distante, sans configuration particulière.
Voici un lien vers ses fonctionnalités. Dès que RDA est lancé, il détecte automatiquement :
- le protocole utilisé
- le mode d’affichage actif
- l’encodeur vidéo
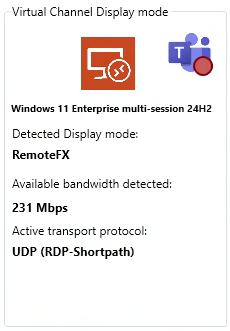
Dans le cas d’Azure Virtual Desktop, Remote Display Analyzer permet également de vérifier si la session utilise RDP Shortpath.
- RDP Shortpath est un mode de transport UDP qui permet d’améliorer les performances et de réduire la latence dans les sessions AVD.
- Lorsque Shortpath est actif, le trafic RDP ne passe plus uniquement par le service de gateway Azure, mais peut établir un chemin direct entre le client et la machine virtuelle.
Remote Display Analyzer permet de vérifier immédiatement si la session utilise le transport TCP classique ou le mode UDP (RDP Shortpath) :
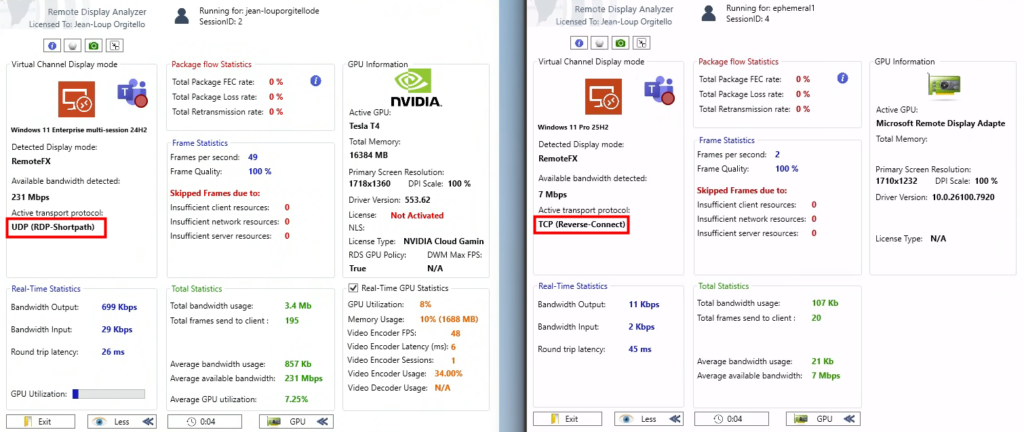
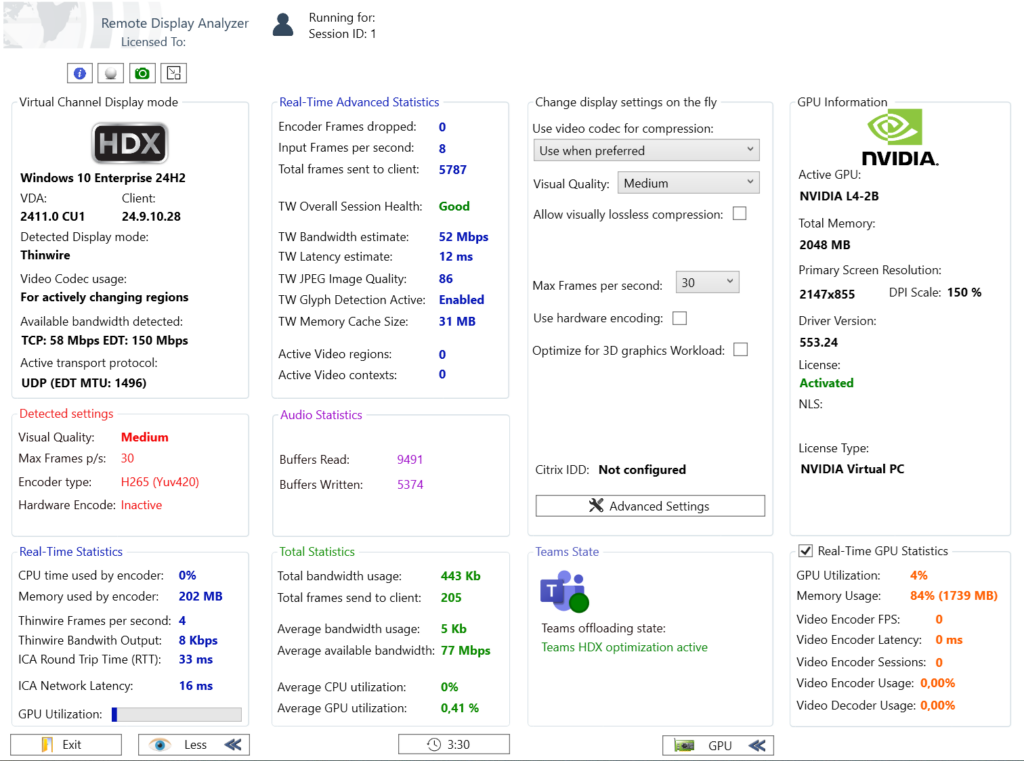
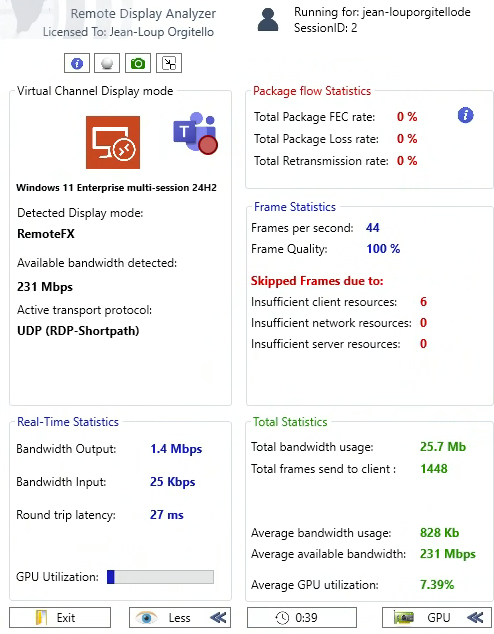
Il affiche également différentes métriques en temps réel, comme par exemple :
- bande passante utilisée
- latence réseau
- nombre de frames
- frames perdues
- GPU
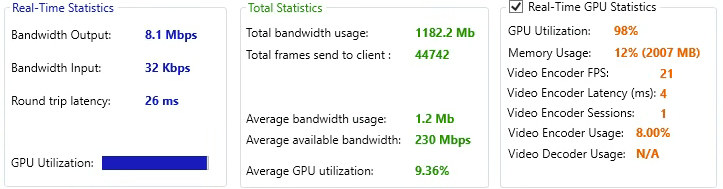
Il vous informe sur les statistiques portant sur les paquets envoyés et les contraintes potentielles sur ces derniers, mais également sur les FPS envoyés :

Enfin, il vous donne des informations utiles sur le GPU :
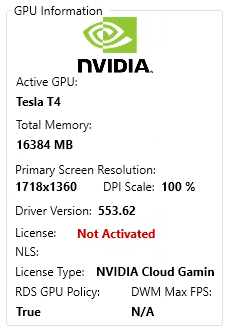
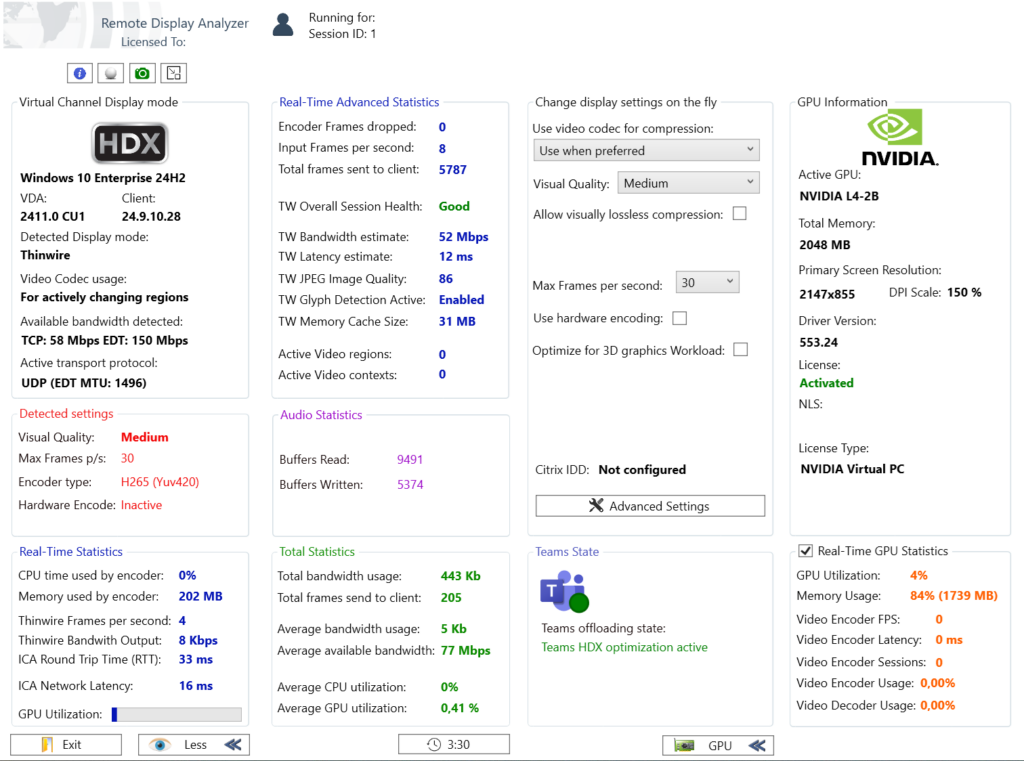
Dans les environnements Azure Virtual Desktop ou Windows 365 utilisant des machines virtuelles avec GPU (par exemple NV-series ou NVads), l’encodage vidéo peut être offloadé vers le GPU. Lorsque cette accélération est active :
- la charge CPU diminue
- l’encodage vidéo devient plus rapide
- l’expérience utilisateur est plus fluide
Remote Display Analyzer permet de vérifier si l’encodeur vidéo GPU est réellement utilisé et d’observer en temps réel la latence de l’encodeur ainsi que le nombre de frames générées.
Cela permet notamment de vérifier que les politiques GPU sont correctement appliquées sur les session hosts AVD.
Comment interpréter les métriques de RDA ?
Certaines métriques sont particulièrement utiles pour comprendre l’expérience utilisateur.
- FPS :
- Un environnement fluide tourne généralement entre 25 FPS et 60 FPS
- En dessous de 20 FPS, les utilisateurs commencent souvent à percevoir des saccades.
- Latence round-trip :
- < 40 ms → excellent
- 40-80 ms → correct
- 100 ms → visible
- Video Encoder Latency
- Une latence encodeur trop élevée peut indiquer : CPU saturé, GPU absent, codec mal configuré
Qu’est-ce que les « Skipped Frames » ?
Dans les protocoles d’affichage distants, toutes les images générées par l’application ne sont pas forcément envoyées au client.
Lorsque certaines ressources deviennent limitées, le protocole peut décider d’ignorer certaines images afin de maintenir une expérience utilisateur acceptable.
Remote Display Analyzer permet d’identifier trois types de frames ignorées :
Skipped frames – client
Cela signifie que le client ne peut pas décoder ou afficher les images assez rapidement. Les causes les plus fréquentes sont :
- client peu puissant
- GPU absent
- décodage vidéo logiciel
- écran haute résolution
Skipped frames – network
Dans ce cas, c’est le réseau qui devient le facteur limitant. Le protocole décide alors de réduire le flux graphique. Cela peut être causé par :
- bande passante insuffisante
- latence élevée
- pertes de paquets
- congestion réseau
Skipped frames – server
Ici le problème vient du serveur lui-même. Cela peut être dû à :
- CPU saturé
- GPU saturé
- trop de sessions par host
- encodage vidéo trop lourd
Quelques exemples de problèmes que RDA permet d’analyser :
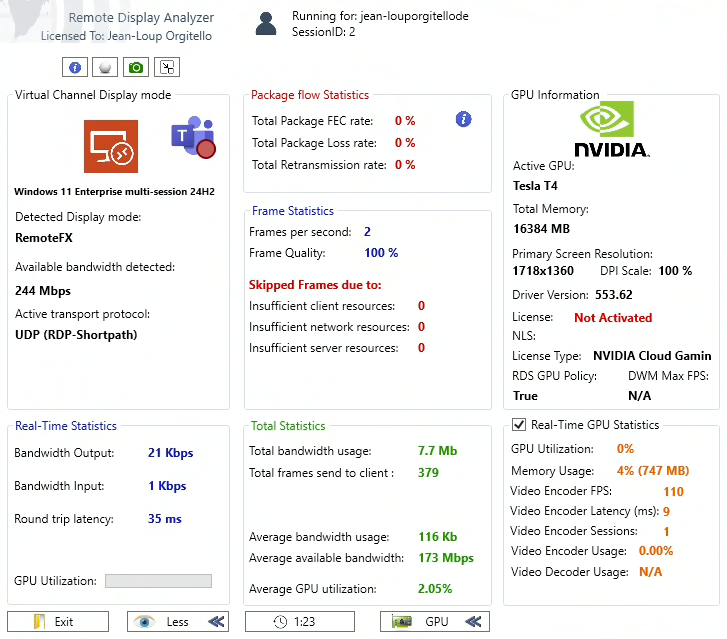
Un premier cas fréquent concerne la latence élevée dans les sessions distantes. Les utilisateurs peuvent ressentir un délai entre l’action réalisée sur le clavier ou la souris et la réaction affichée à l’écran. Dans ce type de situation, Remote Display Analyzer permet de visualiser la latence réseau, le nombre de frames envoyées et les éventuelles frames perdues afin d’identifier si le problème vient du réseau, du serveur ou du client.
Dans l’exemple ci-dessous, RDA analyse une session Windows 11 dans Azure Virtual Desktop :
Comme la vidéo le montre, il peut être très instructif de simuler différents niveaux de latence réseau afin d’observer comment la session se comporte dans des conditions WAN plus difficiles. Remote Display Analyzer permet alors de suivre en temps réel l’impact de la latence sur la fluidité et la réactivité.
Un autre problème courant concerne les vidéos ou les animations qui deviennent saccadées. Les utilisateurs peuvent par exemple remarquer que Microsoft Teams, YouTube ou certaines applications graphiques ne sont pas fluides. Dans ce cas, l’outil permet d’analyser le nombre d’images par seconde, le codec vidéo utilisé ainsi que la bande passante réellement consommée par la session :
On rencontre également souvent des problèmes d’image floue ou de compression trop forte. Dans ces situations, le texte peut sembler légèrement dégradé ou certaines images peuvent apparaître très compressées. Remote Display Analyzer permet alors de tester différents niveaux de compression et différentes qualités d’image afin de trouver le bon compromis entre qualité visuelle et consommation réseau.
Enfin, certains environnements rencontrent des problèmes de charge CPU trop élevée sur les serveurs. Cela peut se produire lorsque l’encodage vidéo est effectué par le CPU plutôt que par le GPU. Dans ce type de scénario, RDA permet de vérifier si l’encodage GPU est réellement utilisé ou si le CPU est responsable du traitement graphique :
Peut-on modifier certains réglages graphiques avec RDA ?
Ce qui rend l’outil vraiment intéressant est une autre capacité. Remote Display Analyzer permet de modifier certains paramètres d’affichage en live pour les environnements Citrix. Cela permet de faire des tests très rapides pour comprendre l’impact réel d’une configuration. Par exemple :
- codec vidéo
- profondeur de couleur
- compression
- qualité d’image
- frames par seconde
Comme le rappelle l’éditeur dans leur FAQ, RDA nécessite les droits administrateur pour pouvoir effectuer ces modifications.
Conclusion
Remote Display Analyzer est un outil extrêmement simple, mais particulièrement utile dans les environnements EUC.
Lorsqu’un utilisateur signale que son bureau distant est lent ou que la vidéo est saccadée, il est souvent difficile de savoir immédiatement si le problème vient du réseau, du client, du serveur ou du protocole lui-même.
Grâce à ses métriques en temps réel et à sa capacité à modifier certains paramètres graphiques à la volée, Remote Display Analyzer permet de mieux comprendre le comportement du protocole d’affichage distant.
Pour les administrateurs travaillant avec Azure Virtual Desktop, Windows 365, Citrix ou Horizon, c’est clairement un outil que je recommande d’avoir dans sa boîte à outils de troubleshooting.