
L’actualité concernant l’intelligence artificielle défile à un rythme effréné. Avec cette avalanche de nouveaux outils, de techniques et de possibles usages, combinant à la fois de réelles avancées, mais aussi parfois des discours marketing très prometteurs, chacun se doit de faire sa propre analyse, et de trier dans ces nouveautés les mises applications possibles dans au quotidien.
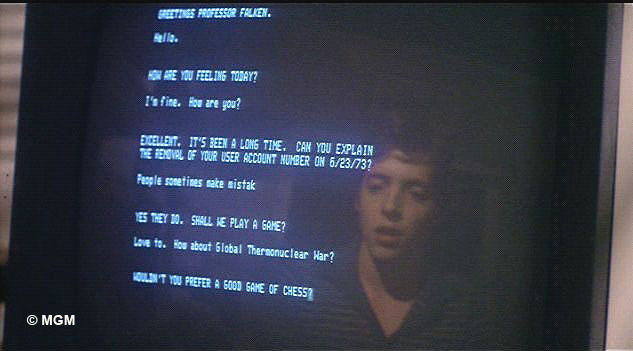
Qu’est-ce que les vecteurs dans le domaine de l’IA ?
Dans le domaine de l’IA, un vecteur est généralement utilisé pour représenter des données numériques. Un vecteur est une liste ordonnée de nombres. Par exemple, dans un espace à trois dimensions, un vecteur pourrait être représenté comme
[3, 4, 5], où chaque nombre représente une dimension spécifique.
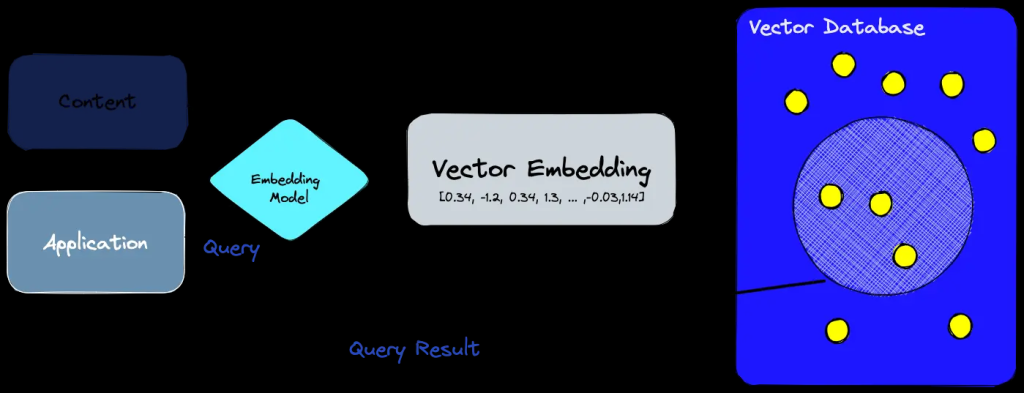
Dans l’IA, les vecteurs, c’est-à-dire des représentations numériques (ou embeddings) de données permettent donc de transformer du texte, des images ou d’autres données en une série de nombres qui représentent leurs caractéristiques essentielles. Ces représentations numériques facilitent la comparaison et la mesure de la similarité entre différents éléments.
L’embedding est une méthode de transformations de données provenant d’images, de textes, de sons, de données utilisateur, ou de tout autre type d’information, en vecteurs numériques. Cela revient à traduire le langage humain en une langue que les machines peuvent interpréter, capturant ainsi les nuances sémantiques ou contextuelles des éléments traités.
Grâce à une IA, la façon de rechercher des informations pertinentes repose sur la comparaison des vecteurs pour identifier les documents ou les images similaires. En d’autres termes, les vecteurs aident à comprendre et à exploiter la signification des données pour améliorer la précision des résultats de recherche.
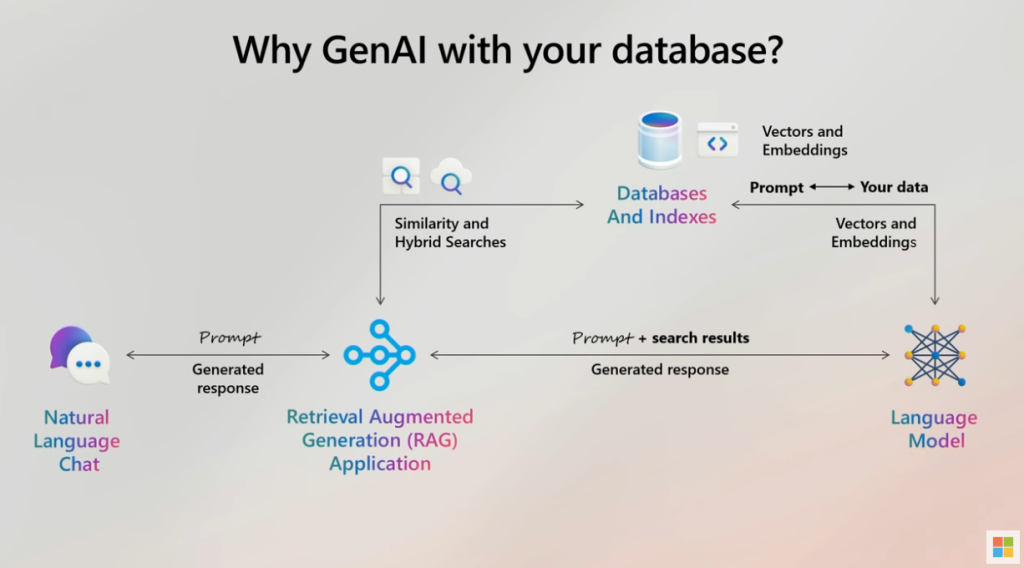
Où sont stockés les vecteurs ?
Traditionnellement, les vecteurs étaient stockés dans des bases de données dédiées, comme Pinecone ou Milvus, conçues spécifiquement pour gérer des données vectorielles et optimiser les recherches par similarité.
Cependant, avec l’évolution des technologies, certains SGBD relationnels, comme Azure SQL Database, intègrent désormais un support natif pour les vecteurs. Cela permet de stocker et d’interroger directement des vecteurs au sein d’une base de données SQL classique, simplifiant ainsi l’architecture des applications et réduisant la nécessité d’avoir un système séparé.
Depuis quand Azure SQL Database peut stocker les vecteurs ?
Azure SQL Database a commencé à prendre en charge du stockage des vecteurs lors de l’EAP (Early Adopter Preview) à partir du 21 mai 2024, avant d’être mis en Public Preview le 6 novembre 2024.
Qu’est-ce que le nouveau type de données Vector ?
Le type vector est un nouveau type de données natif dans Azure SQL Database spécifiquement conçu pour stocker des vecteurs. Plutôt que d’utiliser un format générique comme du JSON ou du varbinary, ce type offre un format dédié, compact et optimisé pour les opérations mathématiques, telles que le calcul de distances (cosinus, euclidienne, etc.).
Il permet ainsi d’effectuer directement dans la base de données des recherches par similarité, sans recourir à des systèmes externes spécialisés dans le stockage vectoriel.
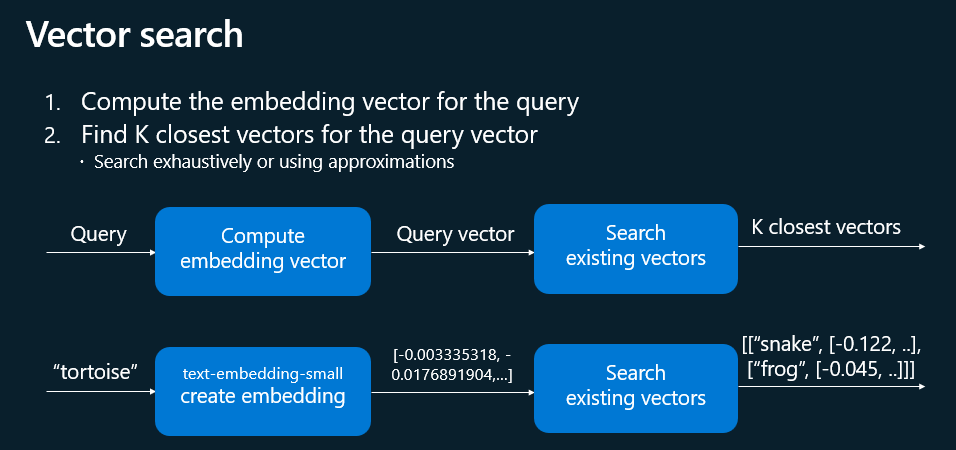
Comment fonctionne la recherche de distance entre 2 vecteurs ?
En utilisant des fonctions intégrées telles que VECTOR_DISTANCE, cela calcule une distance (cosinus, euclidienne, etc.) entre le vecteur de la requête et chaque vecteur stocké, permettant d’ordonner les résultats par similarité (la distance la plus faible indiquant la correspondance la plus proche).
Est-ce disponible sur SQL Server 2022 ?
Non, la fonctionnalité native de support des vecteurs n’est pas disponible dans SQL Server 2022. Actuellement, cette capacité est proposée dans Azure SQL Database. Microsoft prévoit d’intégrer des fonctionnalités similaires dans les futures versions, notamment SQL Server 2025.
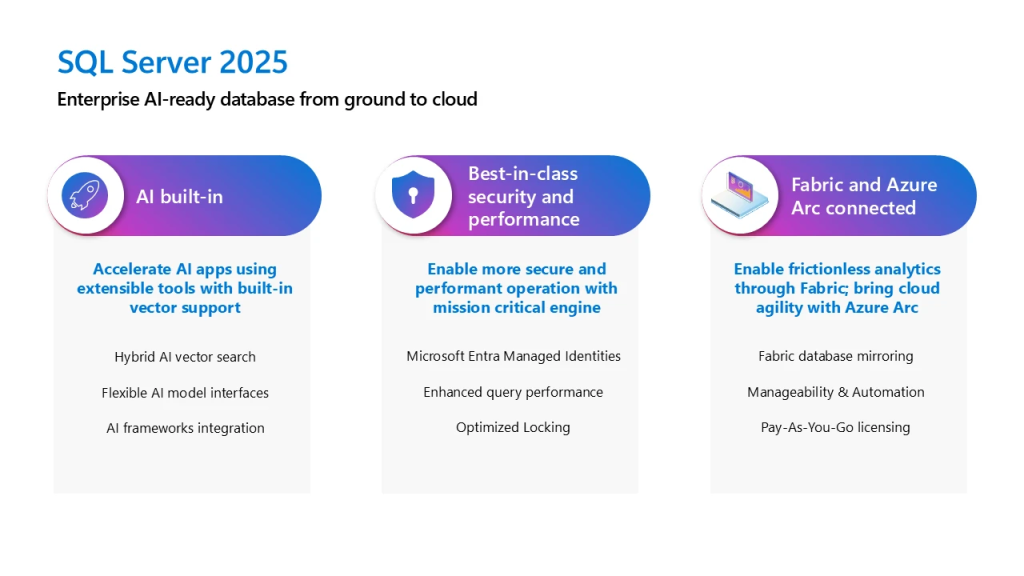
Pour la première fois, Microsoft apporte un support vectoriel natif à SQL Server. SQL Server 2025 sera une base de données vectorielle prête pour l’entreprise, capable de générer et de stocker en mode natif des incrustations vectorielles. Cette prise en charge native des vecteurs permettra aux clients de SQL Server d’exécuter des modèles d’IA génératifs en utilisant leurs propres données. Ils peuvent choisir le modèle d’IA requis grâce à la gestion extensible des modèles permise par Azure Arc.
Peut-on tester les vecteurs sur une base de données Azure SQL ?
Comme toujours, Alex Wolf, via son excellente chaîne YouTube The Code Wolf, nous montre la prise en charge des vecteurs IA au sein même des bases de données SQL :
Maintenant, il nous reste plus qu’à tester tout cela 😎💪
- Etape 0 – Rappel des prérequis
- Etape I – Création de la base de données Azure SQL
- Etape II – Création du service d’IA Computer Vision
- Etape III – Chargement des vecteurs d’images dans la DB SQL
- Etape IV – Calcul de distance entre les images et le mot-clef
- Etape V – Automatisation de l’importation des vecteur
- Etape VI – Automatisation du calcul de distance vectorielle
Etape 0 – Rappel des prérequis :
Afin de faire nos tests sur le base de données Azure SQL pour < comprendre le fonctionnement des vecteurs, nous allons avoir besoin de :
- Un tenant Microsoft active
- Une souscription Azure valide
Commençons par créer la base de données SQL depuis le portail Azure.
Etape I – Création de la base de données Azure SQL :
Depuis le portail Azure, commencez par rechercher le service de bases de données SQL :
Renseignez les informations de base, comme la souscription Azure et le groupe de ressources :
Cliquez-ici pour également créer un serveur SQL hébergeant notre base de données :
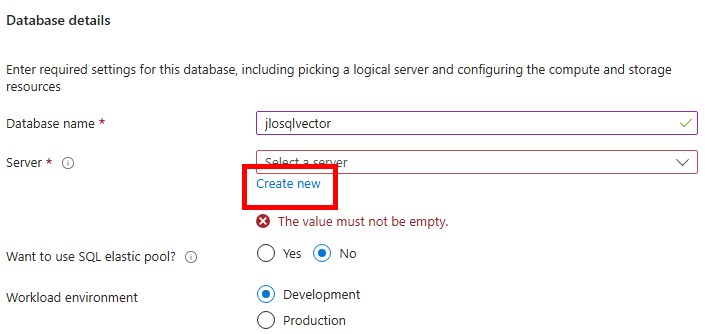
Renseignez un nom unique pour votre serveur SQL, indiquez un compte administrateur à ce dernier, puis cliquez sur OK :
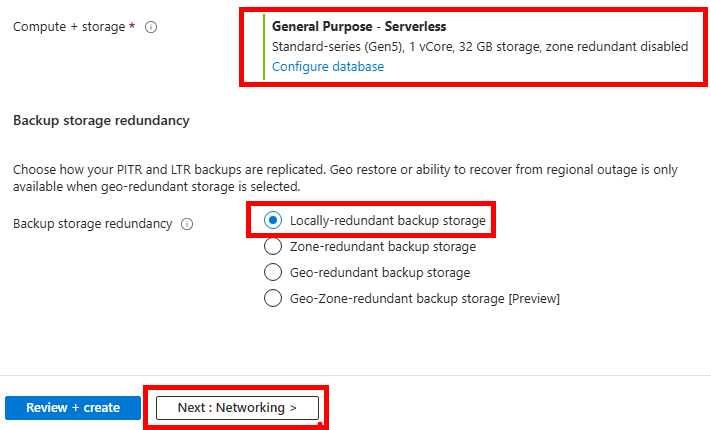
Conservez l’option de base pour la puissance votre serveur SQL, la réplication sur LRS, puis cliquez sur Suivant :
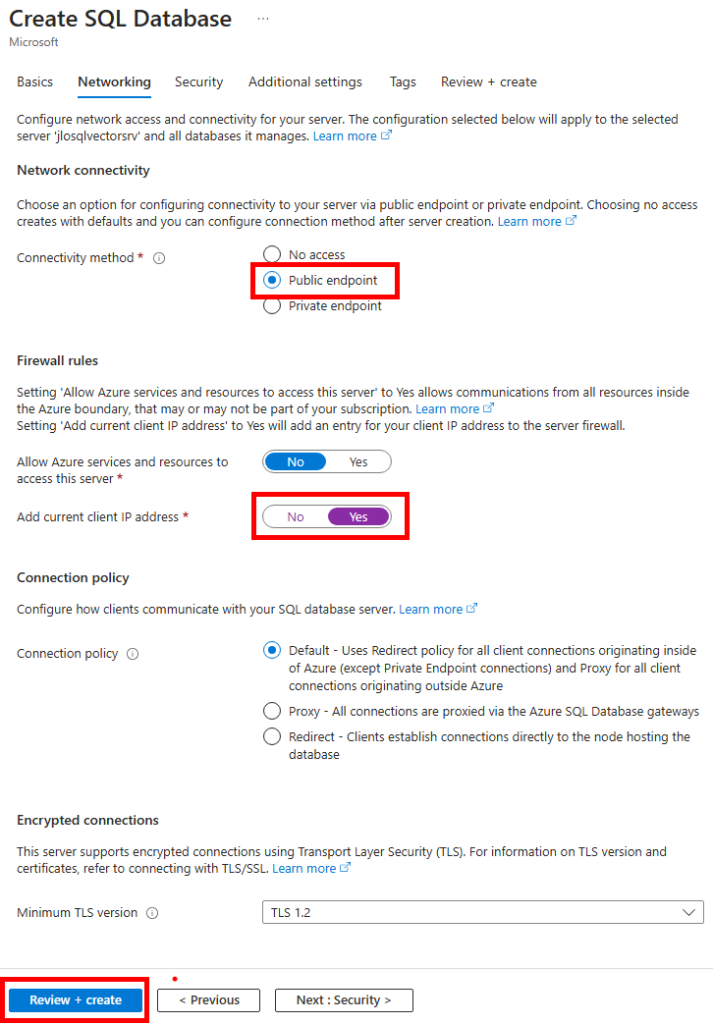
Conservez l’accès public pour nos tests, ajoutez-y votre adresse IP publique, puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création des ressources :
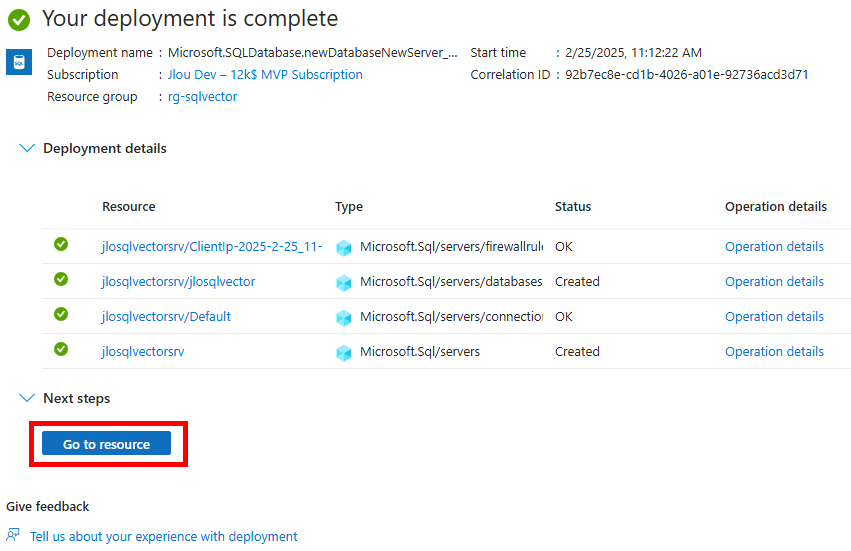
Attendez environ 5 minutes, puis cliquez-ici pour accéder aux ressources créées :
Copiez les éléments de connexion à cette base de données présents l’onglet ci-dessous, puis conservez cette valeur par la suite dans un éditeur de texte :
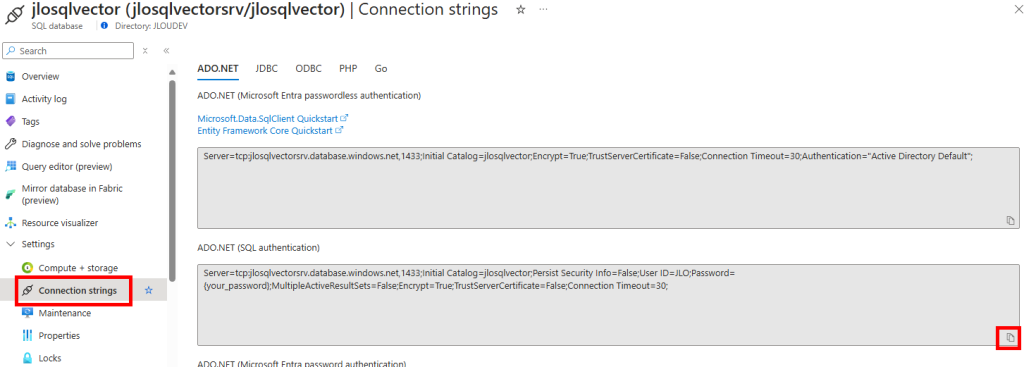
Utilisez un outil de gestion de base de données, comme SQL Server Management Studio (SSMS), ou Azure Data Studio, disponible lui sur cette page :
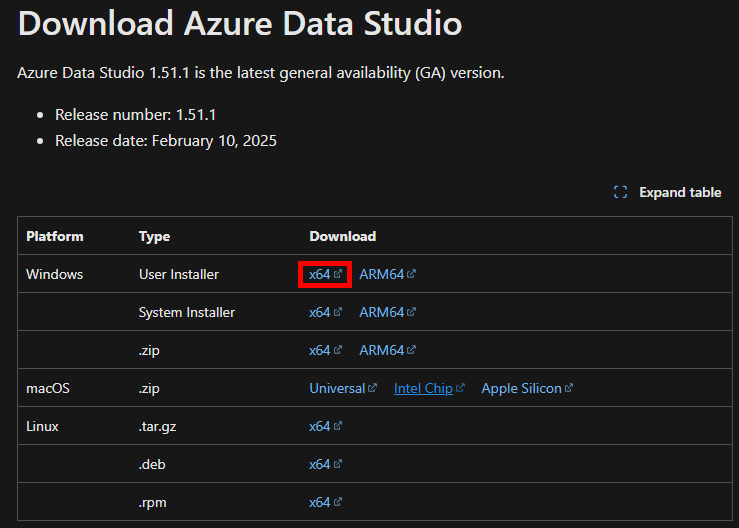
Acceptez les conditions d’utilisations, puis cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Suivant :
Cliquez sur Installer :
Cliquez sur Terminer :
Ouvrez Azure Data Studio, puis cliquez-ici pour créer une nouvelle connexion :
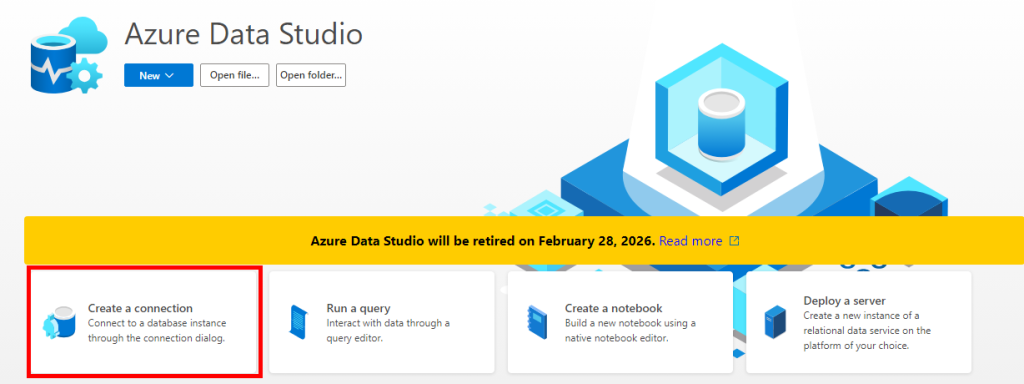
Collez les informations de connexion de votre base SQL précédemment copiées, renseignez le mot de passe de votre administrateur, puis cliquez sur Connecter :
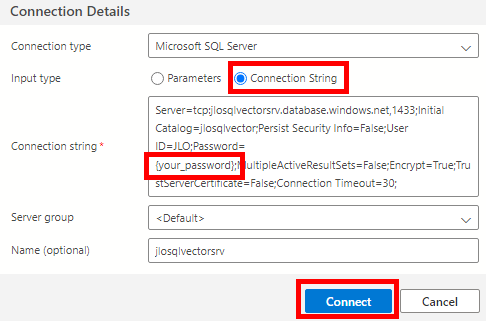
Saisissez la commande SQL suivante afin de créer la table liée au stockage des données et de leurs vecteurs :
CREATE TABLE dbo.demo
(
id INT PRIMARY KEY,
filename VARCHAR(50),
vectors VECTOR(1024) NOT NULL
)Exécutez la commande, puis obtenez la confirmation suivante :
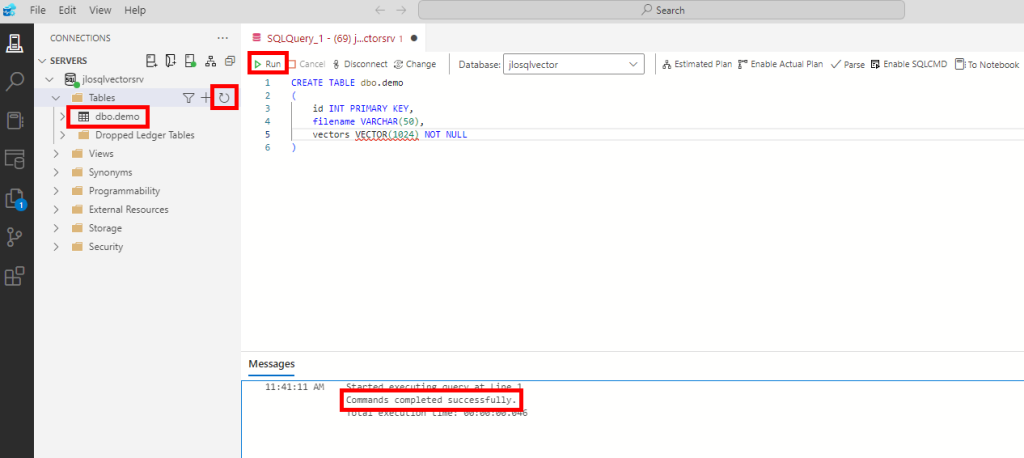
Notre base de données, encore vide en enregistrements et en vecteurs est maintenant prête.
Nous allons maintenant créer un le service d’intelligence artificielle sur Azure afin de créer calculer les vecteurs de nos futures données.
Etape II – Création du service d’IA Computer Vision :
Toujours sur le portail Azure, recherchez le service d’IA suivant :
Cliquez-ici pour créer un nouveau service :
Renseignez toutes les informations, en privilégiant un déploiement dans les régions East US ou West Europe, conservez le modèle de prix F0 (suffisant pour nos tests), puis lancez la validation Azure :
Une fois la validation Azure réussie, lancez la création des ressources :
Une fois le déploiement terminé, cliquez-ici :
Copiez les 2 informations suivantes dans votre bloc-notes afin de vous y connecter plus tard à via API :
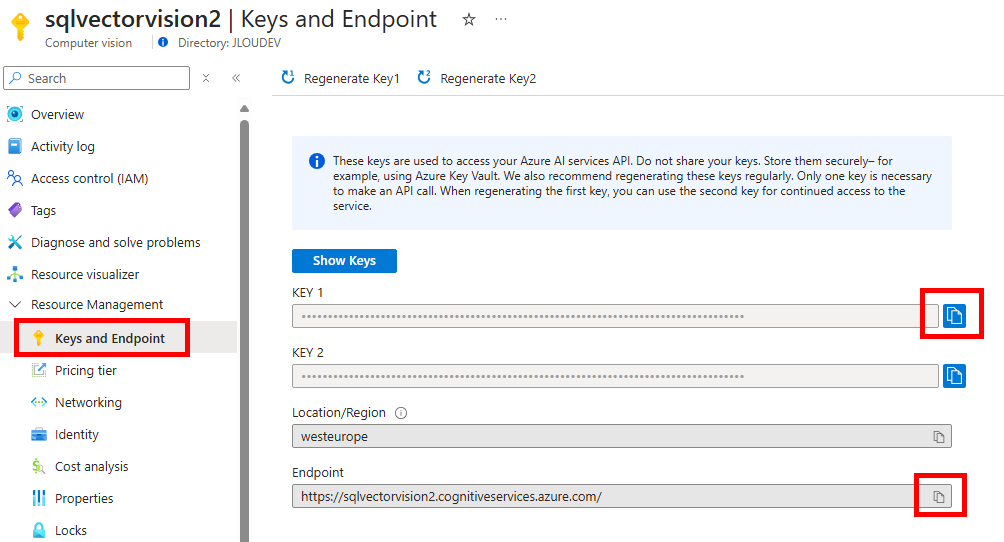
Afin d’envoyer différentes requêtes via API à notre service d’IA, utilisez un service dédié, comme par exemple Postman, disponible ici (créez un compte gratuit si nécessaire) :
Notre environnement manuel est maintenant prêt pour être testé.
La prochaine étape consiste à générer manuellement des vecteurs via notre service d’IA afin de les stocker dans votre base de données SQL.
Etape III – Chargement des vecteurs d’images dans la DB SQL :
Une fois connecté sur votre console Postman, cliquez-ici pour utiliser le service :
Notre premier objectif est de convertir les données d’une image en vecteur. Pour cela, choisissez la méthode de type POST, puis saisissez l’URL composée de la façon suivante :
- Point de terminaison de votre service Computer Vision
- Service API de vectorisation d’images proposé par Computer Vision
Cela donne l’URL suivante :
https://your-endpoint/computervision/retrieval:vectorizeImage?api-version=2024-02-01&model-version=2023-04-15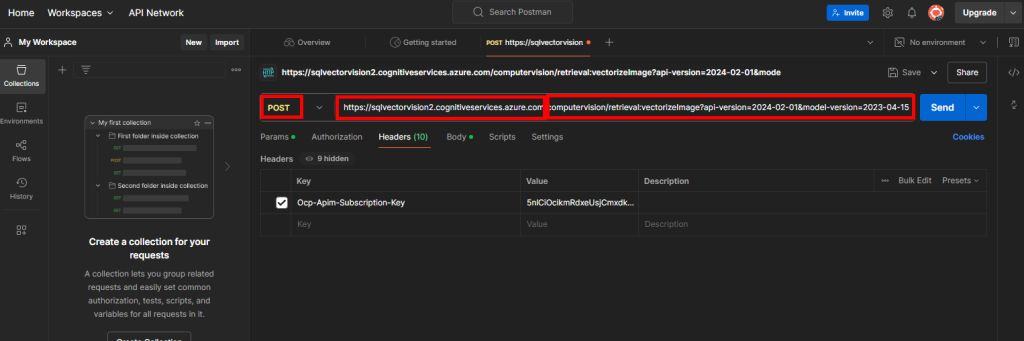
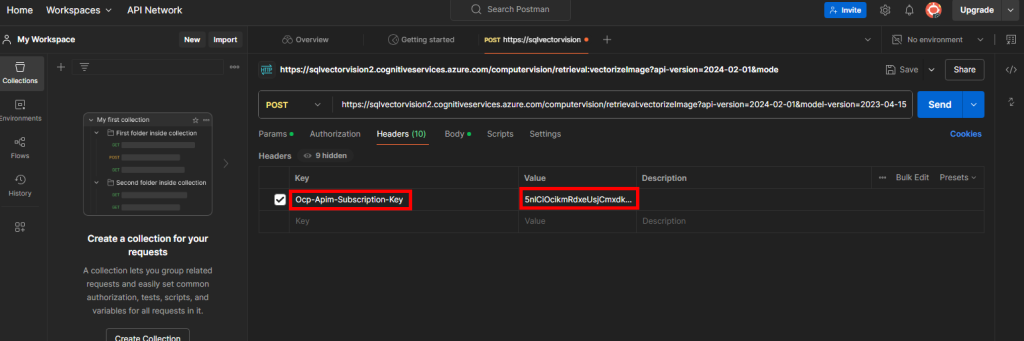
Rendez-vous dans l’onglet Headers afin de rajouter en valeur la clef de votre service IA Computer Vision sous la clef Ocp-Apim-Subscription-Key :
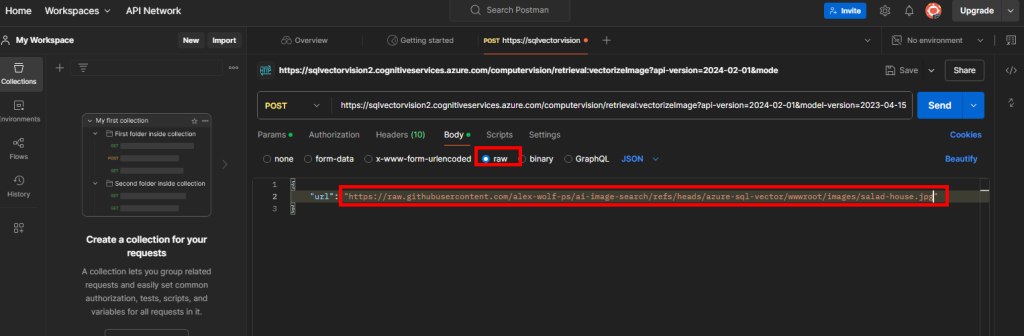
Rendez-vous dans l’onglet Body afin de rajouter en RAW l’URL publique d’une image en exemple :
{
"url": "https://raw.githubusercontent.com/alex-wolf-ps/ai-image-search/refs/heads/azure-sql-vector/wwwroot/images/salad-house.jpg"
}
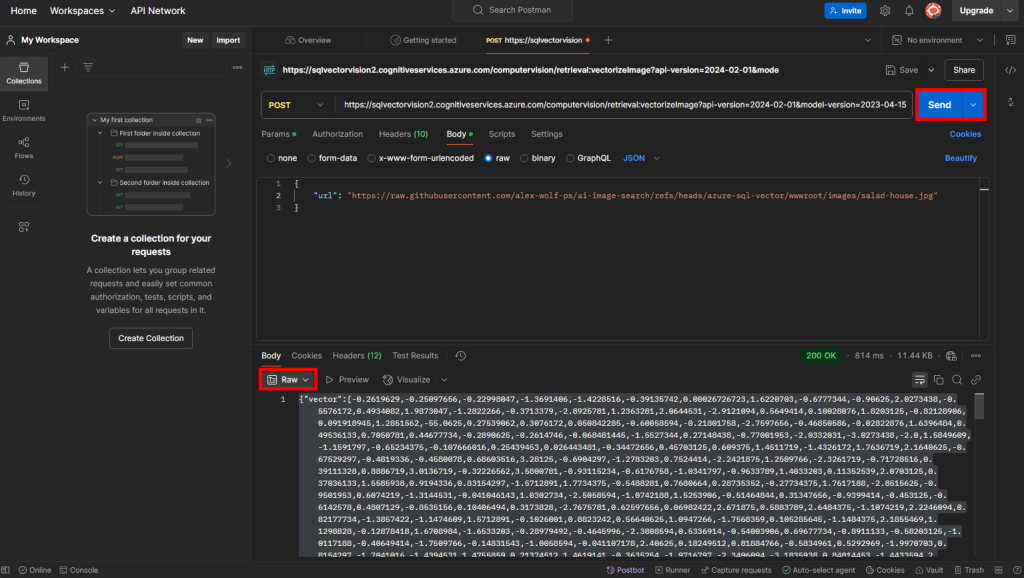
Cliquez ensuite sur Envoyer, puis changez le format de sortie des vecteurs calculés en RAW :
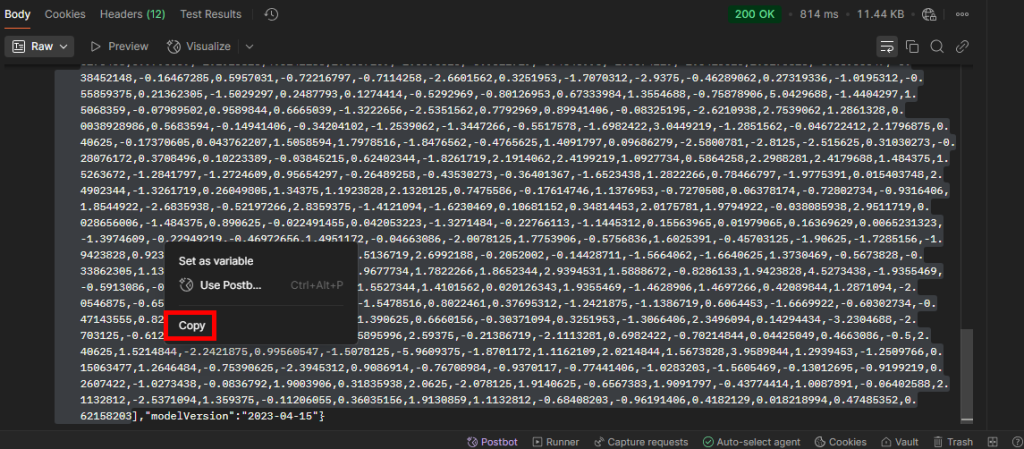
Copiez tous les vecteurs présents entre les 2 crochets :
Retournez sur Azure Data Studio, puis coller la requête SQL suivante afin de créer 3 enregistrements :
INSERT INTO dbo.demo (id, filename, vectors) VALUES
(1, 'latte.jpg', '[]'),
(2, 'cake.jpg', '[]'),
(3, 'salad.jpg', '[]')Entre les crochets de la ligne correspondante à l’image, collez les vecteurs précédemment copiés :
Recommencez la même opération de calcul des vecteurs sous Postman pour les 2 autres fichiers :
Cela donne la requête SQL finale suivante :
Exécutez la commande suivante, puis constatez le succès de celle-ci :
Contrôlez le résultat du chargement dans la base de données SQL via la requête suivante :
SELECT * FROM dbo.demo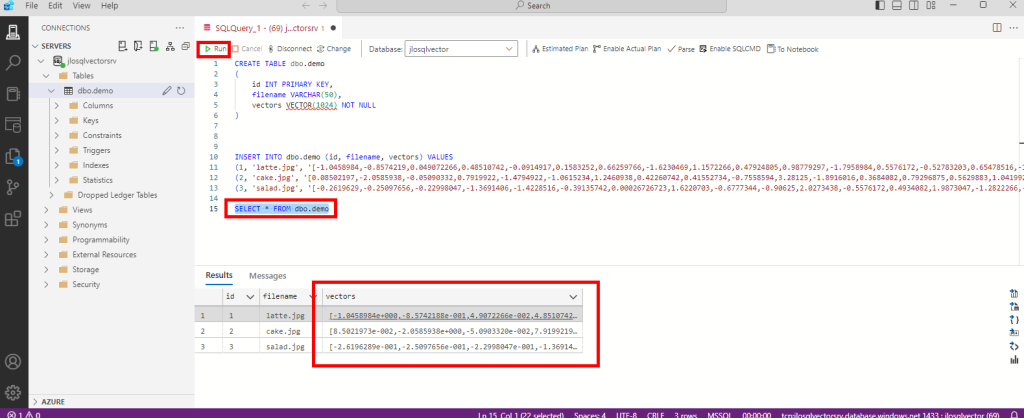
Notre base de données Azure SQL a bien stocké les vecteurs calculés par le service d’intelligence artificielle. La prochaine étape consiste à calculer la distance entre les vecteurs des images et les vecteur d’un mot-clef.
Etape IV – Calcul de distance entre les images et le mot-clef :
Retournez sur le service d’appel API Postman, puis créez un nouvel onglet de requête :
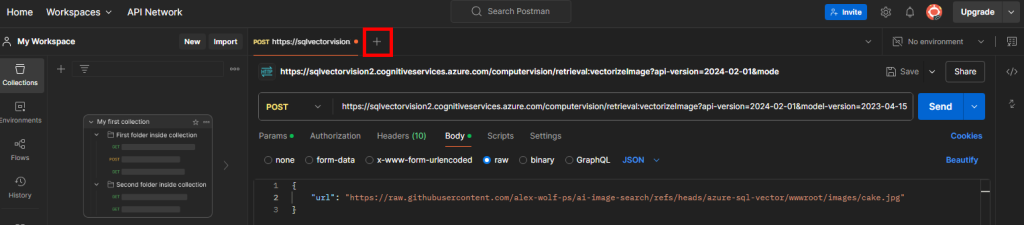
Choisissez à nouveau une méthode de type POST, puis l’URL composée de la façon suivante :
- Point de terminaison de votre service Computer Vision
- Service API de vectorisation de texte proposé par Computer Vision
Cela donne l’URL suivante :
https://your-endpoint/computervision/retrieval:vectorizeText?api-version=2024-02-01&model-version=2023-04-15Rendez-vous dans l’onglet Headers afin de rajouter à nouveau en valeur la clef de votre service Computer Vision sous la clef Ocp-Apim-Subscription-Key :

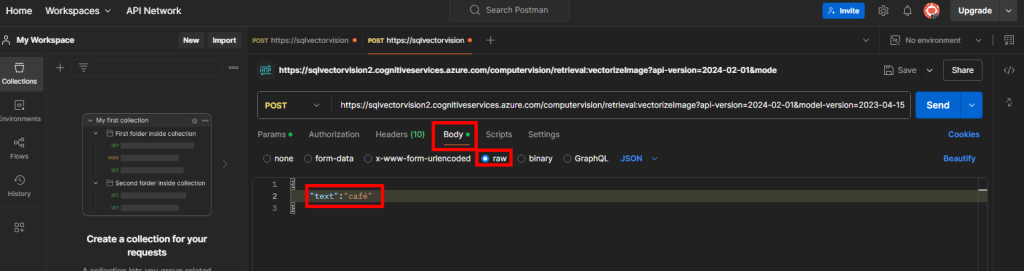
Rendez-vous dans l’onglet Body afin de rajouter en RAW le mot-clef :
{
"text":"café"
}
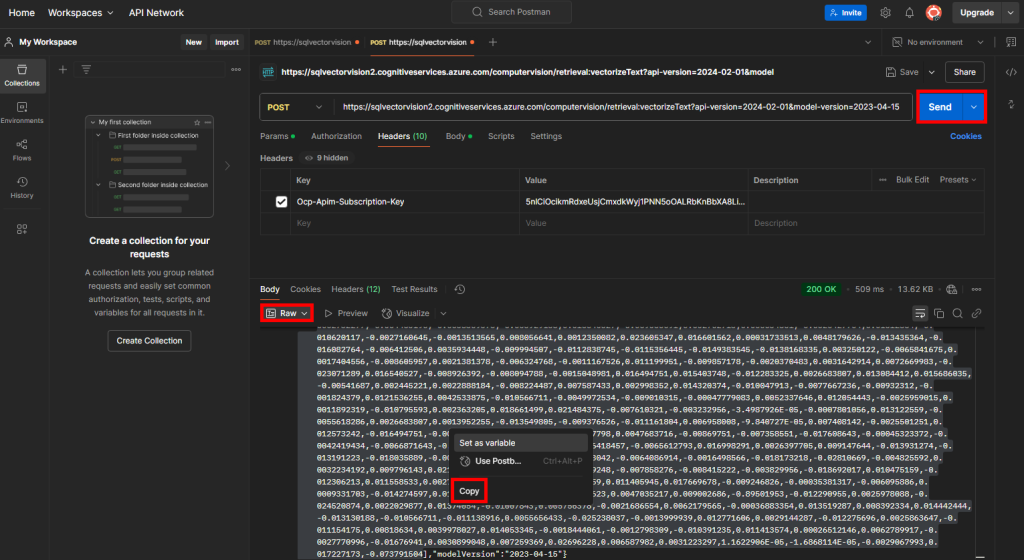
Cliquez ensuite sur Envoyer, changez le format de sortie des vecteurs calculés en RAW, puis copiez tous les vecteurs présents entre les 2 crochets :
Retournez sur Azure Data Studio, puis commencez par coller la requête SQL suivante afin de créer une variable qui stockera les vecteurs de notre mot-clef :
DECLARE @searchVector VECTOR(1024) = '[]'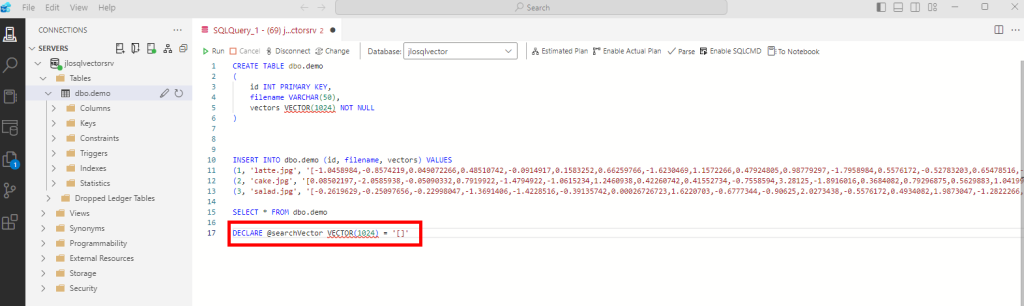
Entre les 2 crochets de la déclaration de variable, collez les vecteurs du mot-clef précédemment copiés :
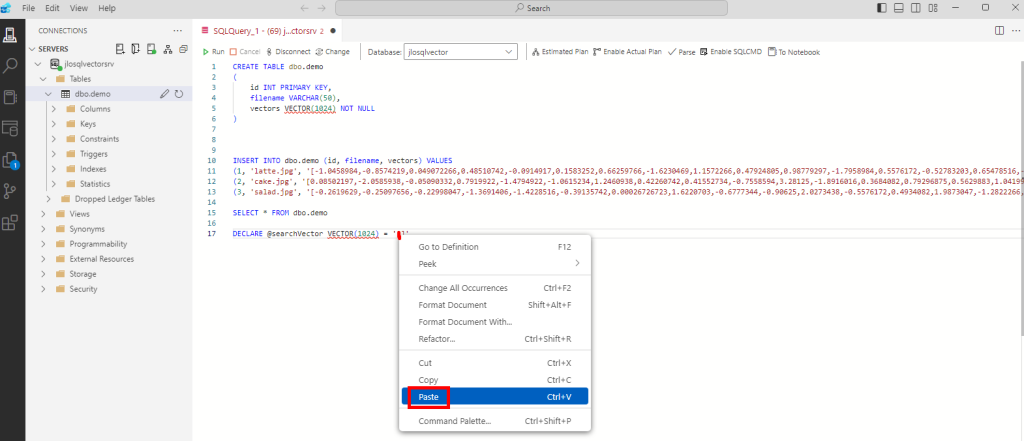
Ajoutez en dessous la requête SQL basée sur la fonction VECTOR_DISTANCE :
SELECT TOP(10) id, filename, VECTOR_DISTANCE('cosine', @searchVector, vectors)
AS Distance from demo ORDER BY DistancePuis exécutez l’ensemble afin de constater le résultat de distance entre le mot-clef et les 3 images :
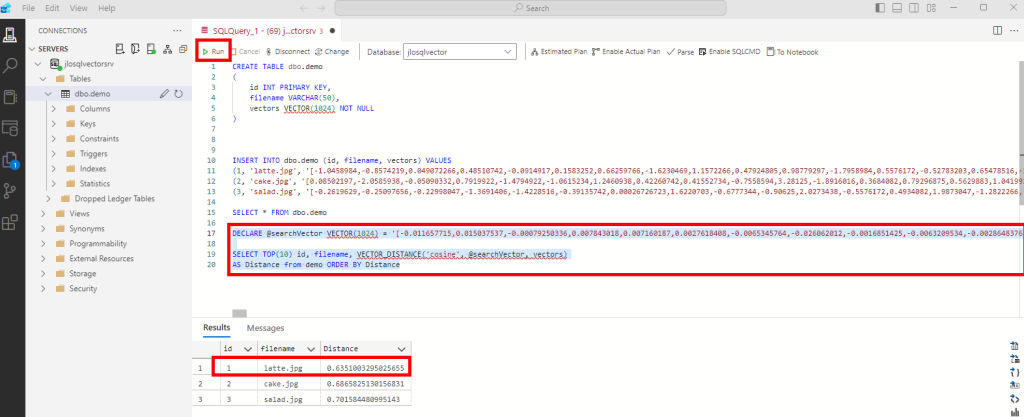
Ces différents tests nous démontrent la possibilité de stockage des vecteurs et la recherche de résultats basés sur la distance entre ces derniers, le tout dans une base de données SQL.
Toutes ces étapes de génération de vecteurs et de recherche sur les distances sont facilement intégrables dans une application, comme celle justement proposée par Alex Wolf.
Etape V – Automatisation de l’importation des vecteur :
Retournez sur Azure Data Studio afin de créer une seconde table dédiée à notre application :
CREATE TABLE dbo.images
(
id INT PRIMARY KEY,
name VARCHAR(50),
vectors VECTOR(1024) NOT NULL
)
Rendez-vous sur la page GitHub suivante afin de télécharger l’application au format ZIP :
Décompressez l’archivage dans le dossier local de votre choix :
Ouvrez l’application Visual Studio Code, puis ouvrez le dossier correspondant à votre application :
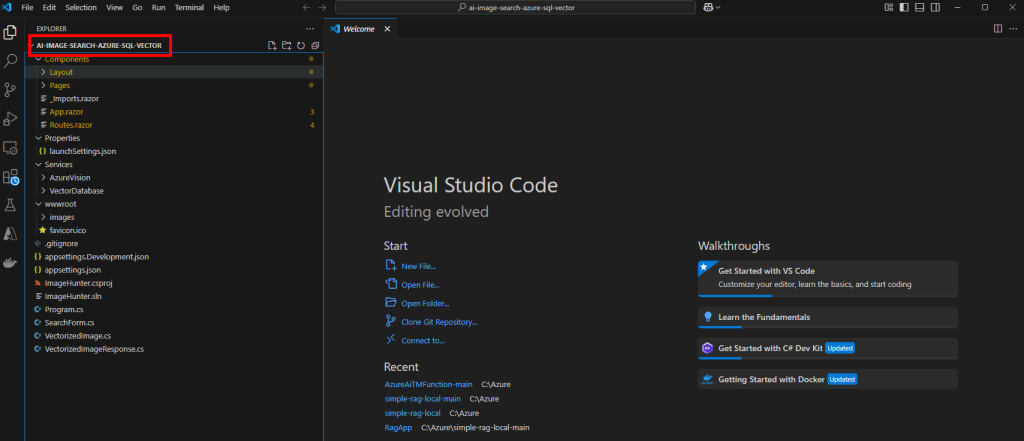
Ouvrez le fichier Program.cs pour y renseigner votre le point de terminaison, ainsi que la clef de votre service Computer vision, puis Sauvegardez :
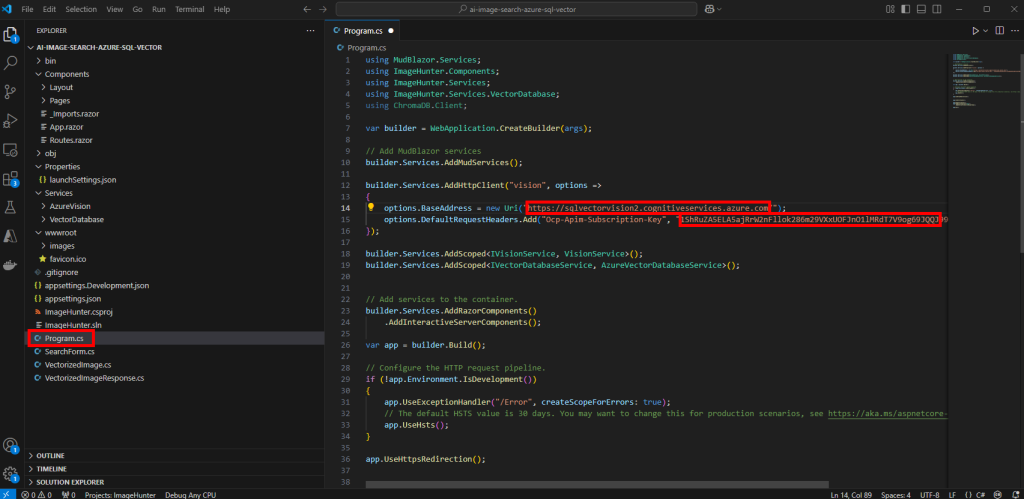
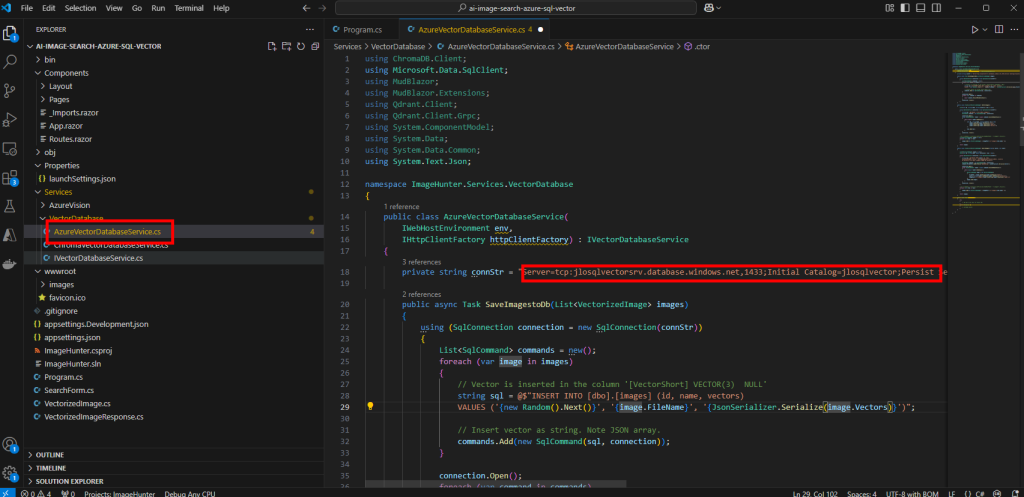
Ouvrez le fichier AzureBectorDatabaseService.cs pour y renseigner les informations de connexion de votre base SQL précédemment copiées avec le bon mot de passe, puis Sauvegardez :
Démarrez l’application via la commande .NET suivante :
dotnet run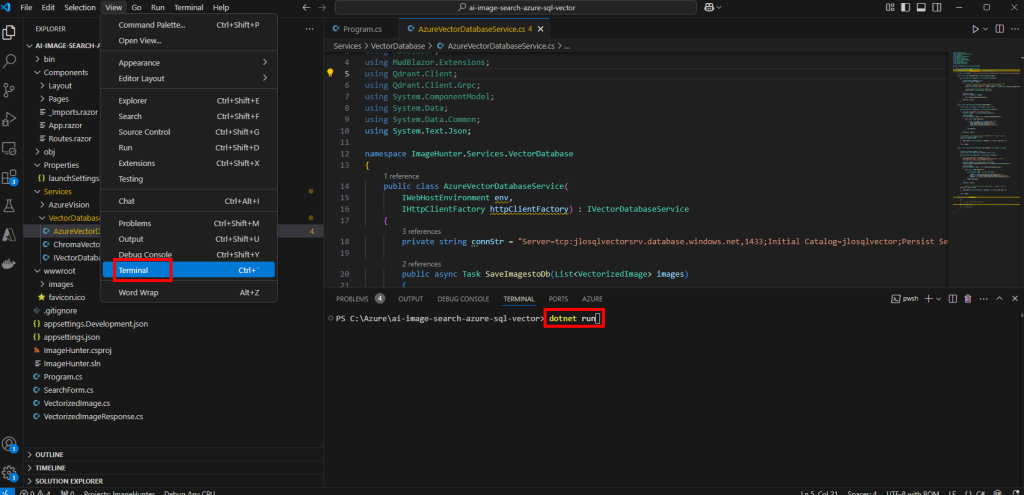
Quelques secondes plus tard, l’application est démarrée, l’URL et le port exposé s’affichent :
Collez cette URL dans un navigateur internet pour ouvrir l’application, puis cliquez sur le bouton ci-dessous pour charger une ou des images au format JPG :
Sélectionnez-le ou les fichiers images de votre choix, puis cliquez sur Ouvrir :
Cliquez-ici pour téléversé le ou les fichiers :
Constatez l’apparition de la vignette de vos images téléversées :
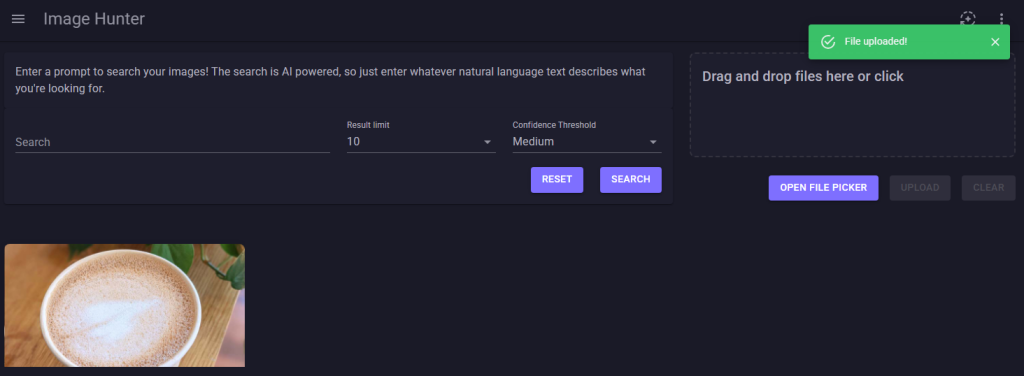
Effectuez la même opération avec d’autres images plus ou moins variées :
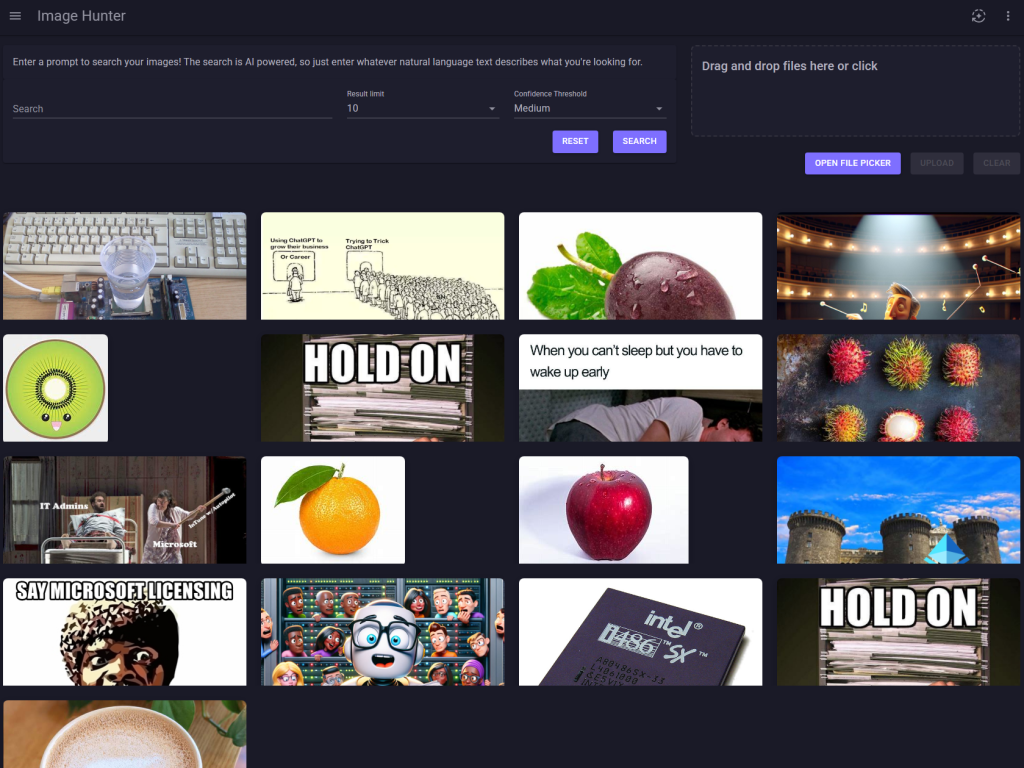
Retournez sur Azure Data Studio, puis lancez la requête SQL suivante pour voir le chargement de des données et des vecteurs dans la seconde table créée :
SELECT * FROM dbo.images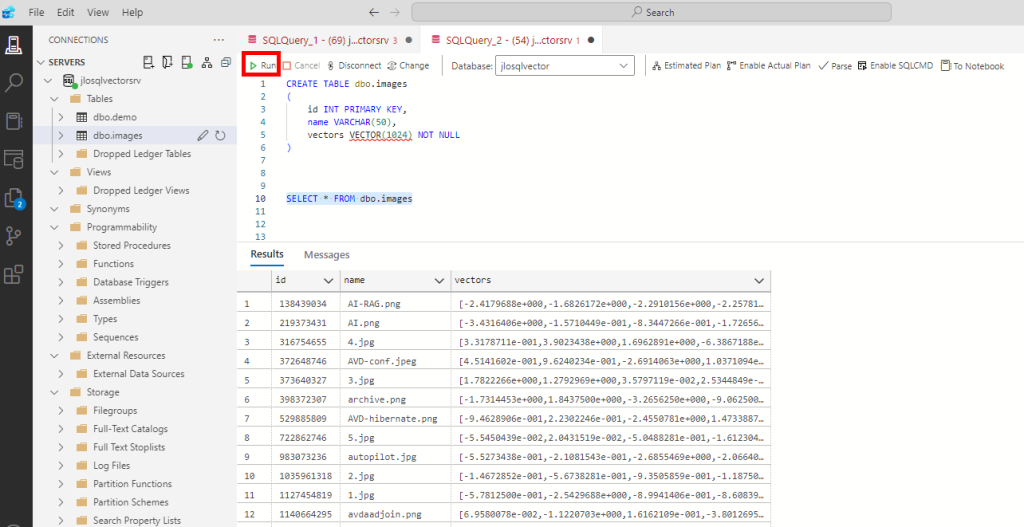
Notre application contient maintenant des fichiers images, avec leurs vecteurs dans notre base de données SQL grâce à notre service d’IA Computer Vision.
Il nous reste maintenant qu’à rechercher via un mot-clef, transposé lui-aussi en vecteurs via l’IA, à des images dont les vecteurs lui seraient proches.
Etape VI – Automatisation du calcul de distance vectorielle :
Retournez sur la page web de votre application, saisissez un mot-clef dans la zone prévue à cet effet, puis cliquez sur Rechercher afin de constater la pertinence des résultats :
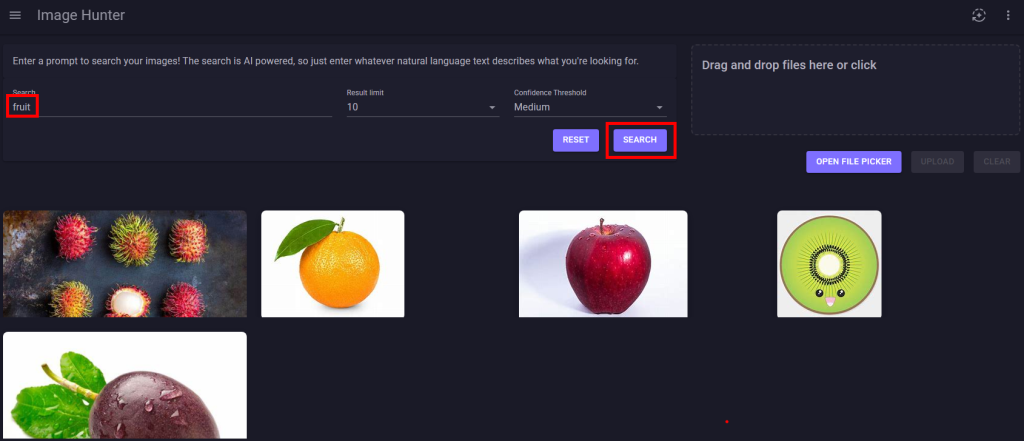
Refaites d’autres tests en jouant également avec les 3 niveaux du seuil de confiance :
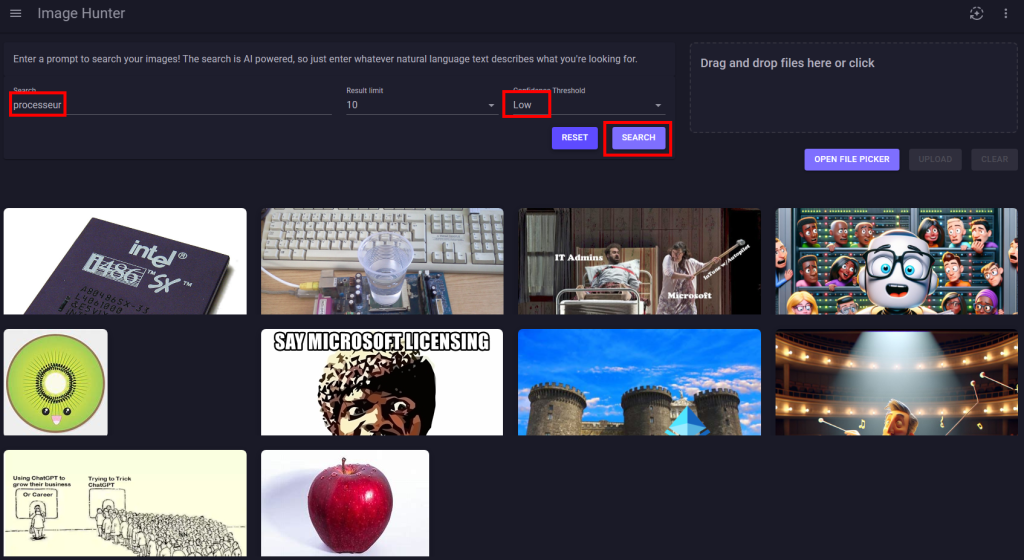
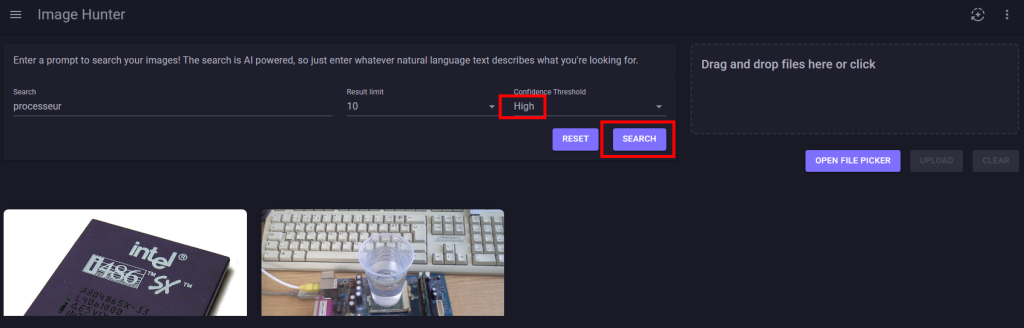
Les résultats retournés varient selon le niveau du seuil de confiance :
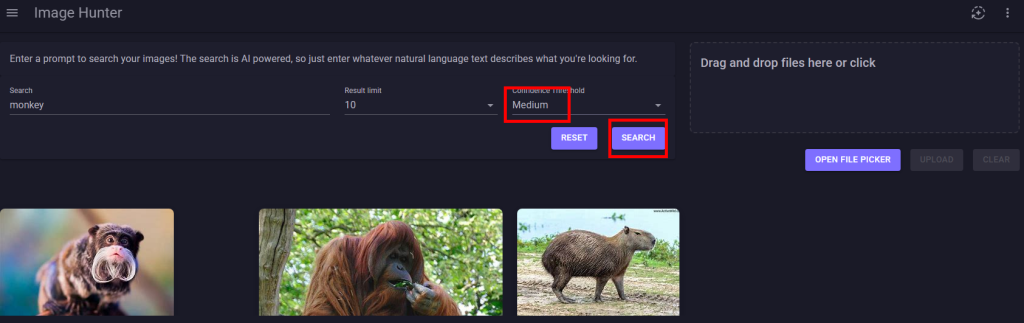
La faible quantité d’images chargées et le niveau de confiance réglé sur moyen donne des résultats trop larges :
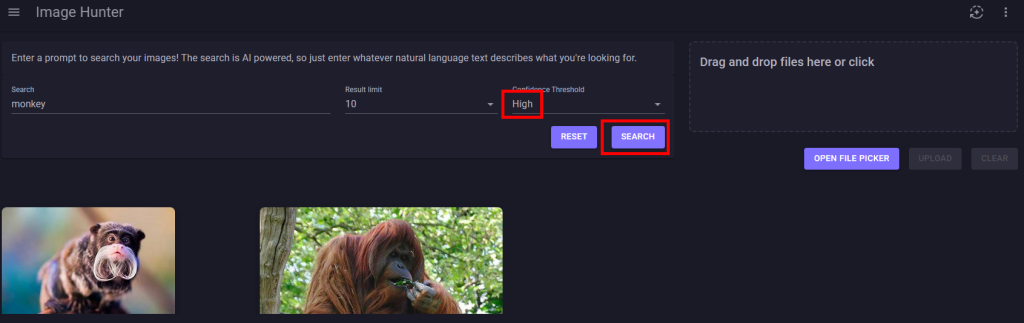
Cette approximation peut se corriger avec un niveau de confiance élevé :
Conclusion
En conclusion, l’intégration native du type de données vector dans Azure SQL Database marque une avancée majeure pour les développeurs souhaitant exploiter l’intelligence artificielle directement au sein de leur SGBD.
Cette fonctionnalité permet de stocker et d’interroger des vecteurs de manière optimisée, simplifiant ainsi l’architecture des applications en éliminant le besoin d’une base de données vectorielle externe.
En adoptant ces outils, les équipes peuvent désormais transformer et analyser leurs données de façon plus intuitive et sécurisée, tout en tirant parti de l’écosystème SQL existant. C’est un pas décisif vers une intégration plus fluide de l’IA et la modernisation d’environnements traditionnels.