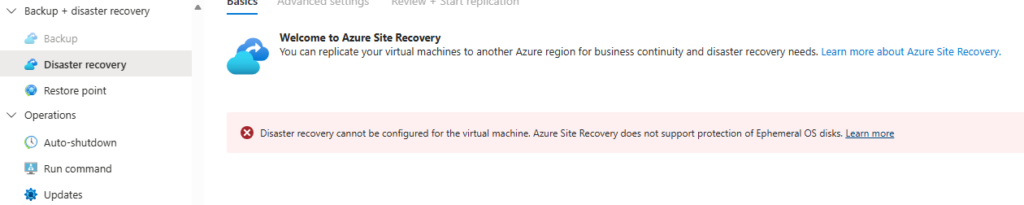
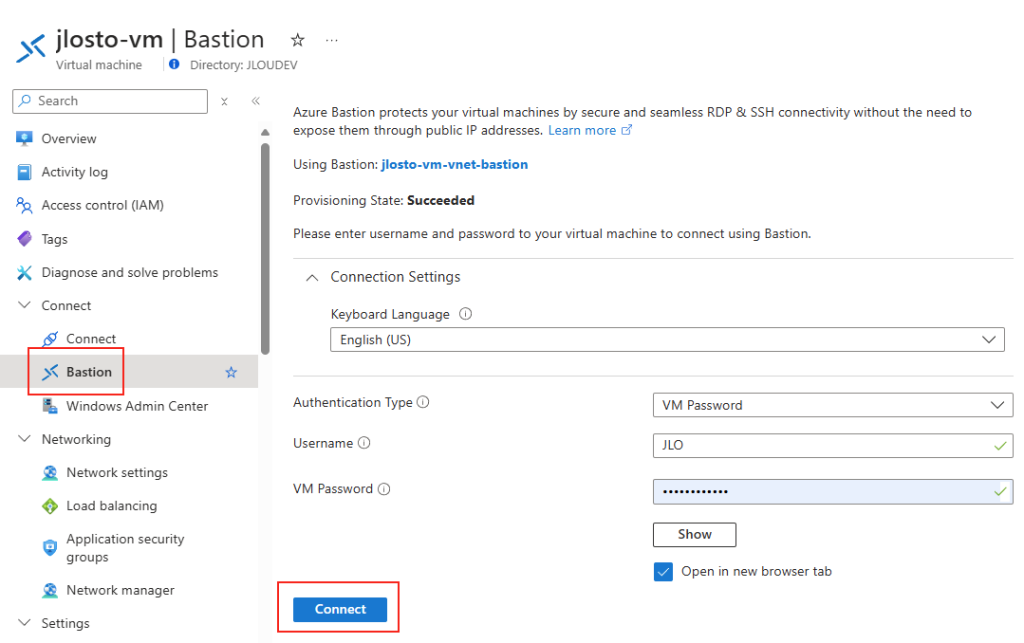
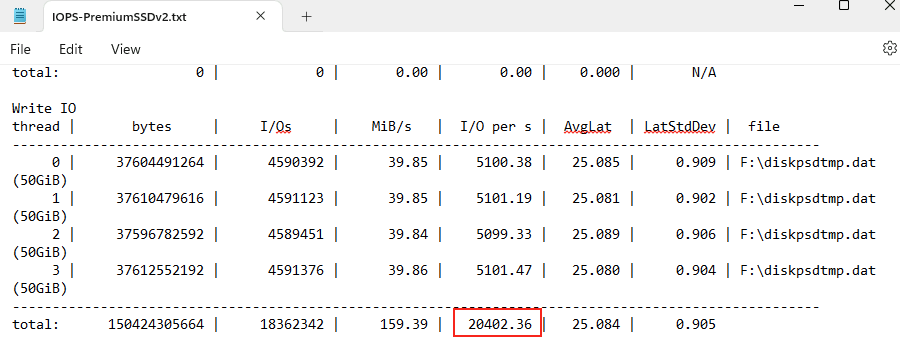
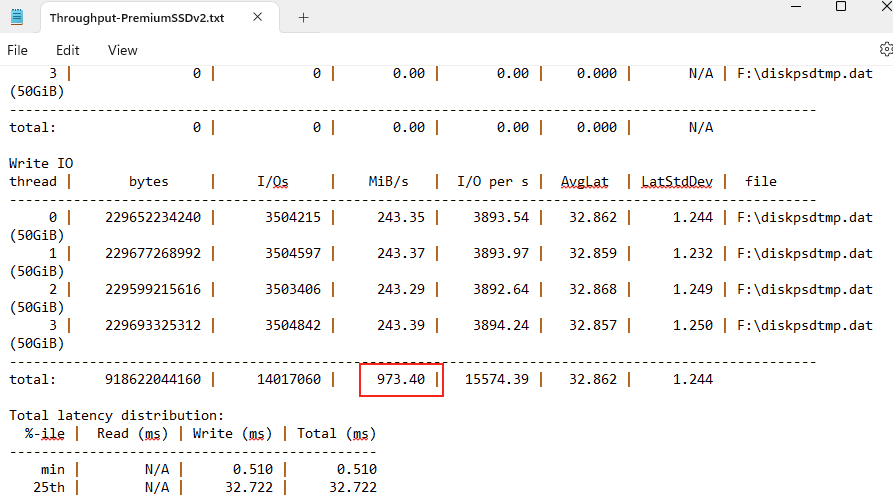
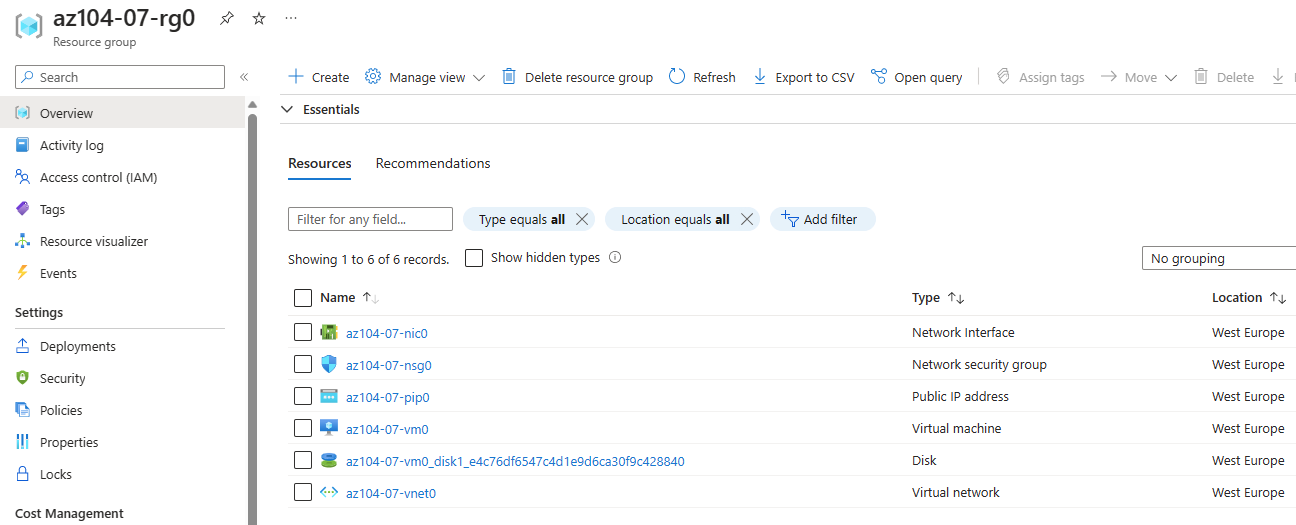
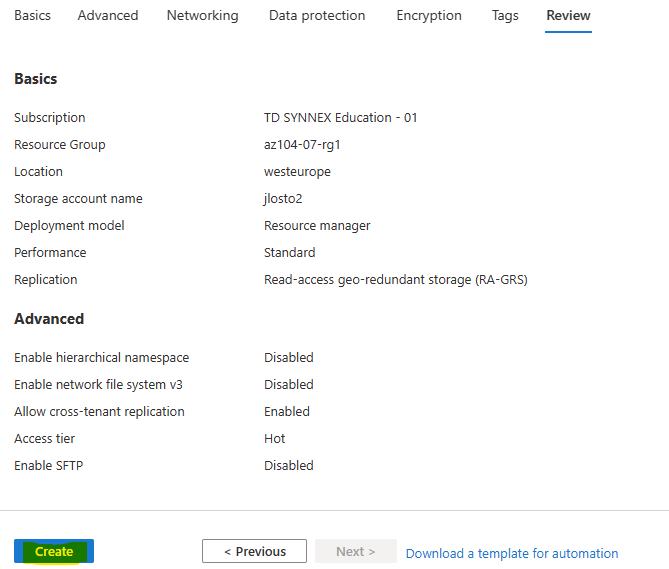
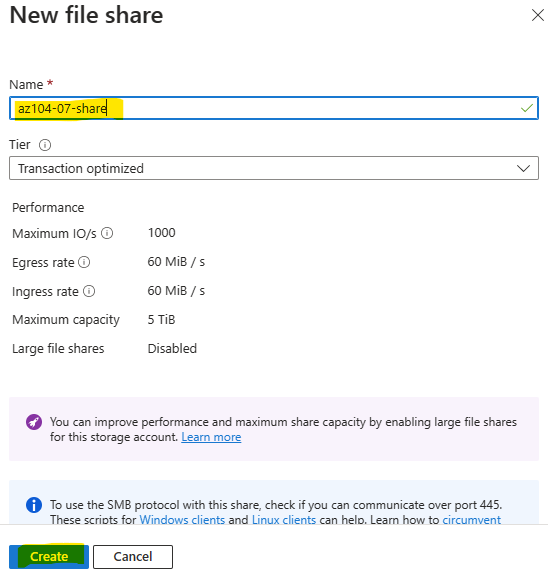
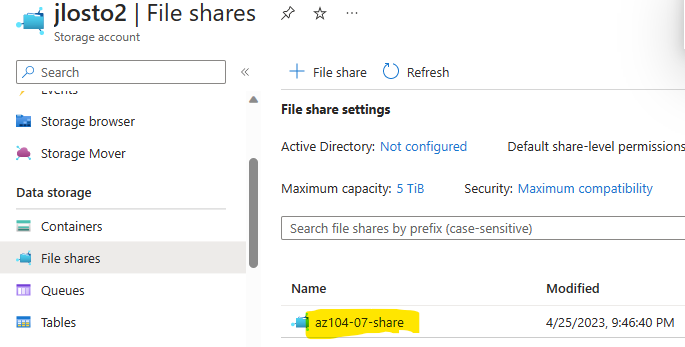
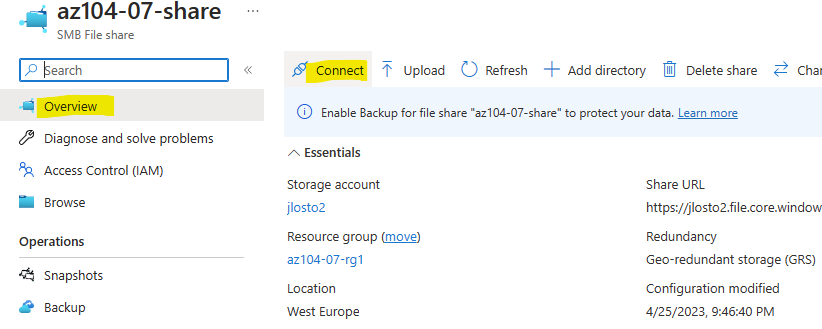
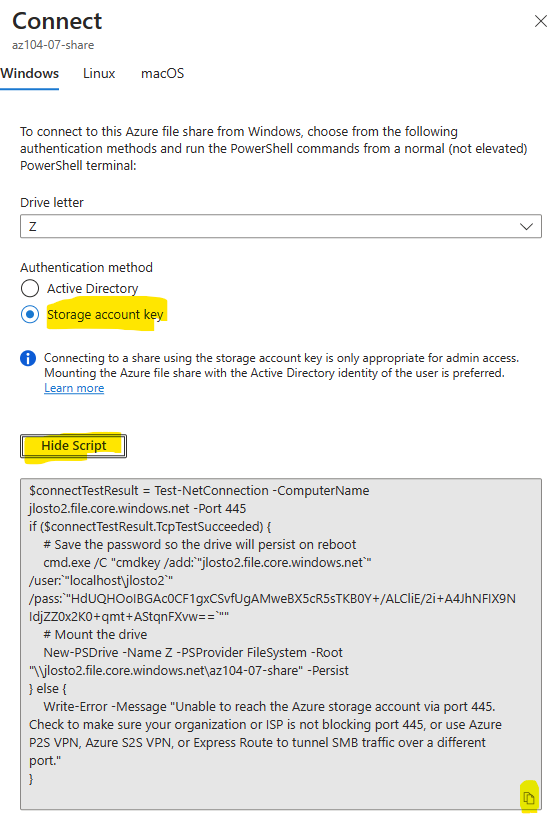
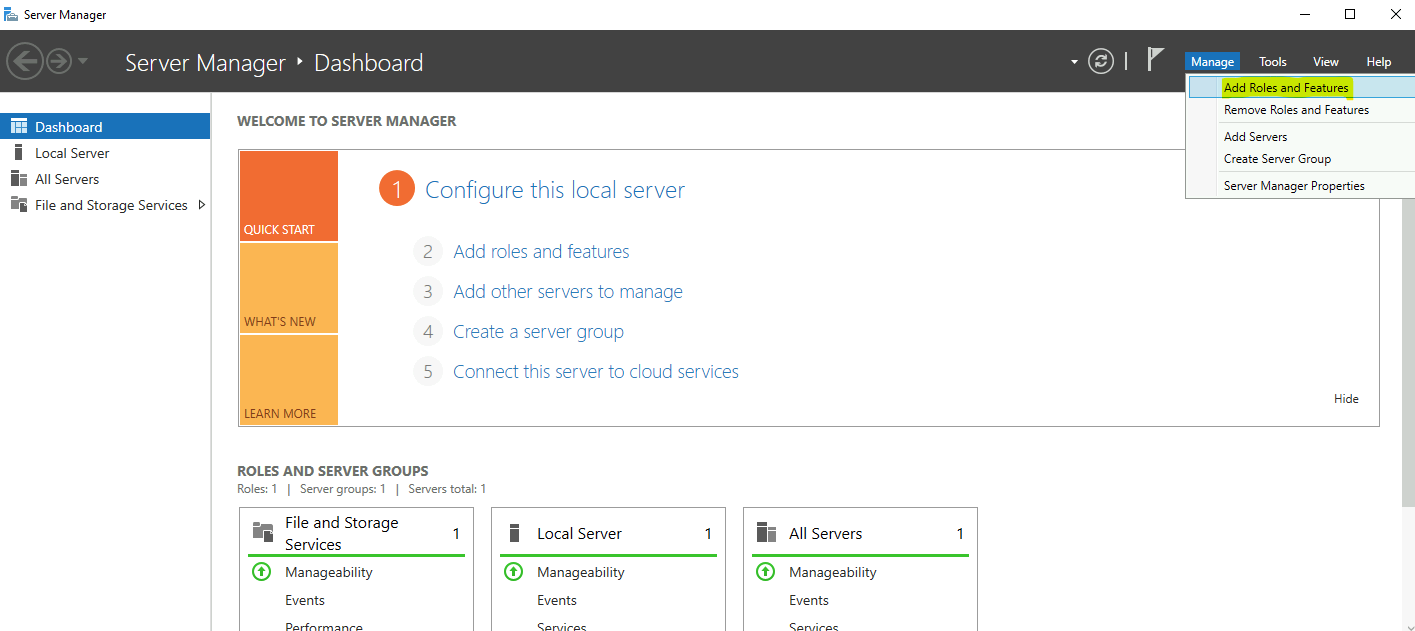
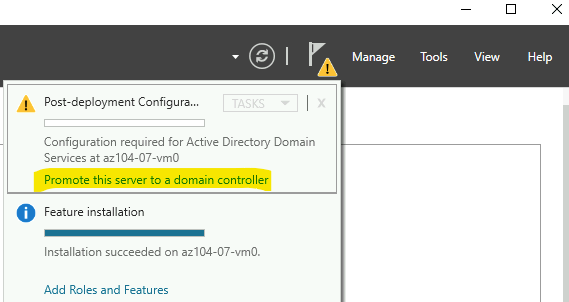
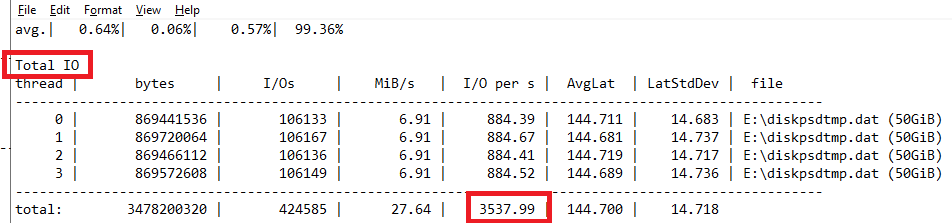
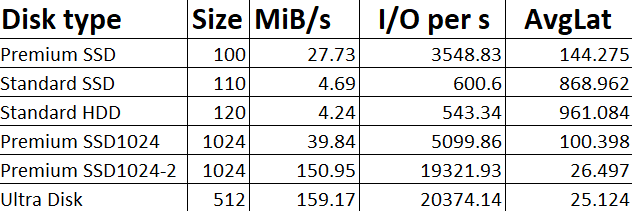
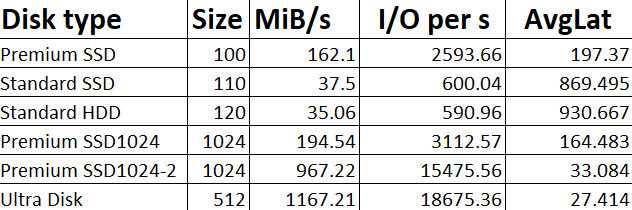
Vous avez vu passer l’annonce Microsoft parlant d’une file share comme une ressource Azure de premier niveau et vous vous dites : mais attendez, les partages de fichiers existent depuis des années dans Azure, où est la nouveauté ? Cet article est fait pour vous. On va partir du modèle historique : le compte de stockage pour dérouler ce que change vraiment le nouveau provider Microsoft.FileShares, passé en GA en 2026, et surtout vous aider à trancher : vous migrez, ou pas encore ?

Azure Files introduit une nouvelle expérience de gestion des services de partage de fichiers, désormais généralement disponible, dans laquelle les partages sont déployés en tant que ressources Azure indépendantes et de niveau supérieur via le Microsoft.
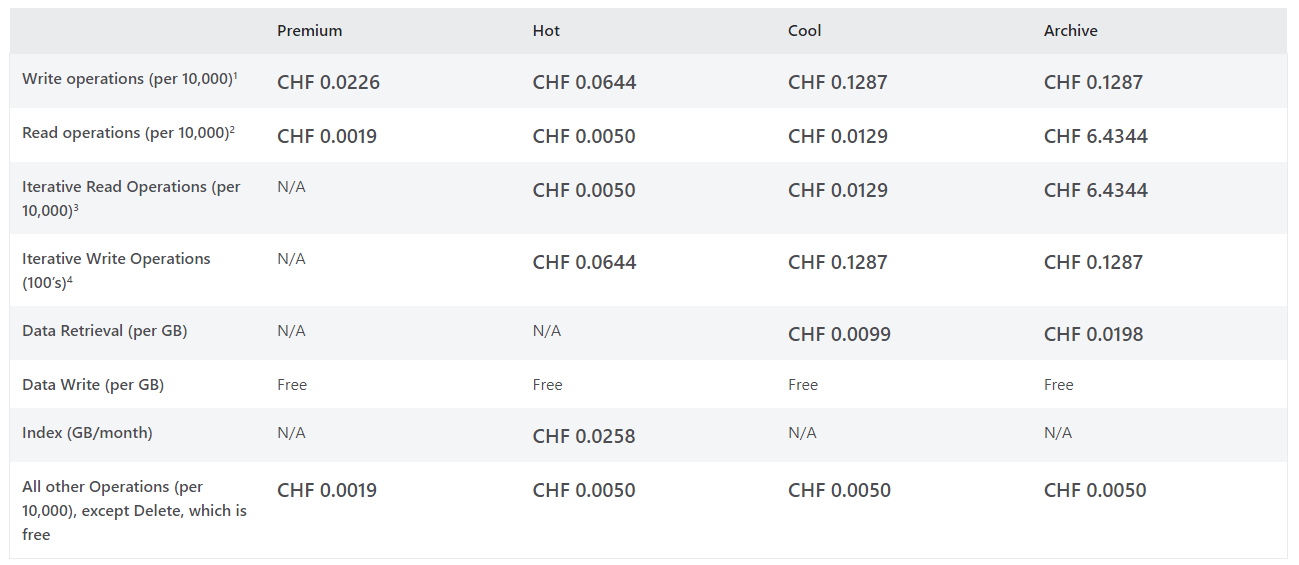
Chaque partage de fichiers a des performances dédiées, la sécurité, la mise en réseau et la facturation, ce qui permet une meilleure isolation, des performances prévisibles et un suivi précis des coûts.
L’expérience améliore également considérablement la mise à l’échelle et l’efficacité, prenant en charge jusqu’à 10 000 partages par abonnement par région, un provisionnement plus rapide et une automatisation native cloud via des modèles ARM, des Bicep et des flux de travail CI/CD.
Il est actuellement disponible pour les partages NFS 4.1.
– Source : Microsoft Learn
Pour vous guider plus facilement dans cet article, voici des liens rapides :
- 1. Le malentendu : un type file share existe déjà
- 2. Avant : tout partait du compte de stockage
- 3. Après : Microsoft.FileShares, ressource de premier niveau
- 4. La démo : on crée un partage, écran par écran
- 5. Ce que vous gagnez concrètement
- 6. Les limites au jour du GA
- 7. Alors, je l’utilise ou pas ?
- 8. Conclusion
1. Le malentendu : un type file share existe déjà
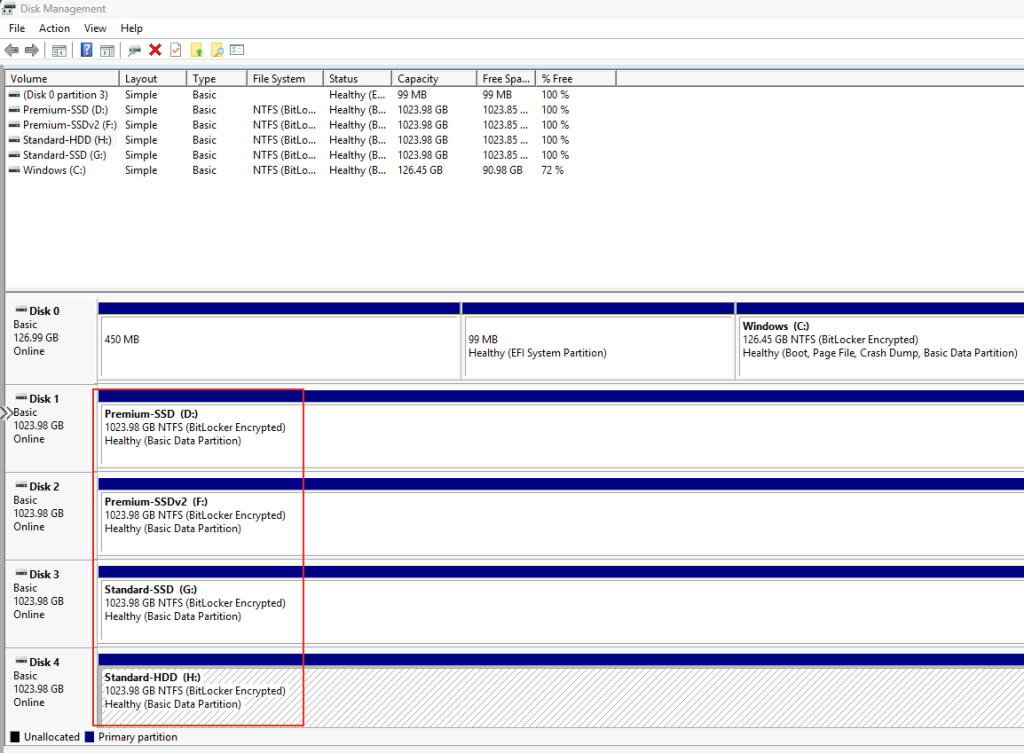
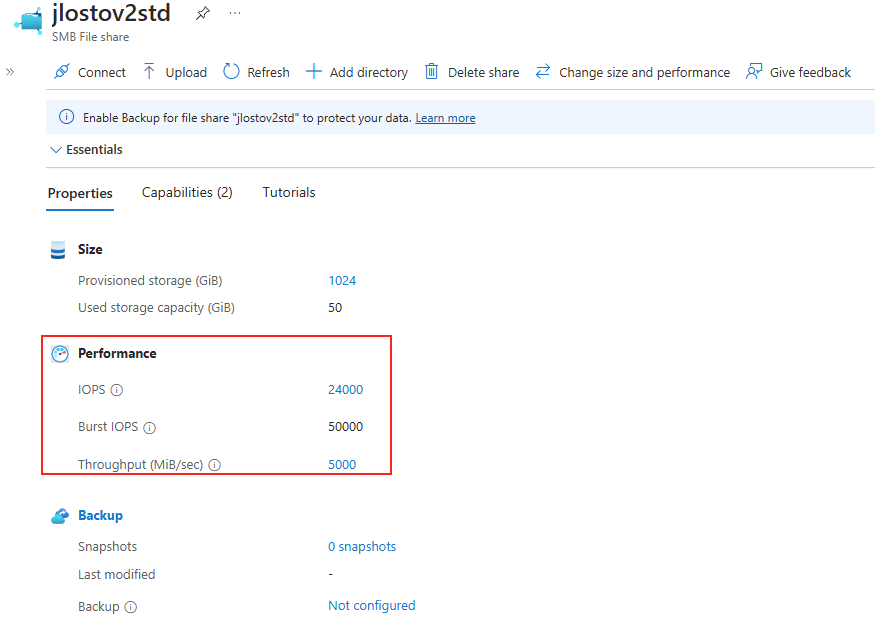
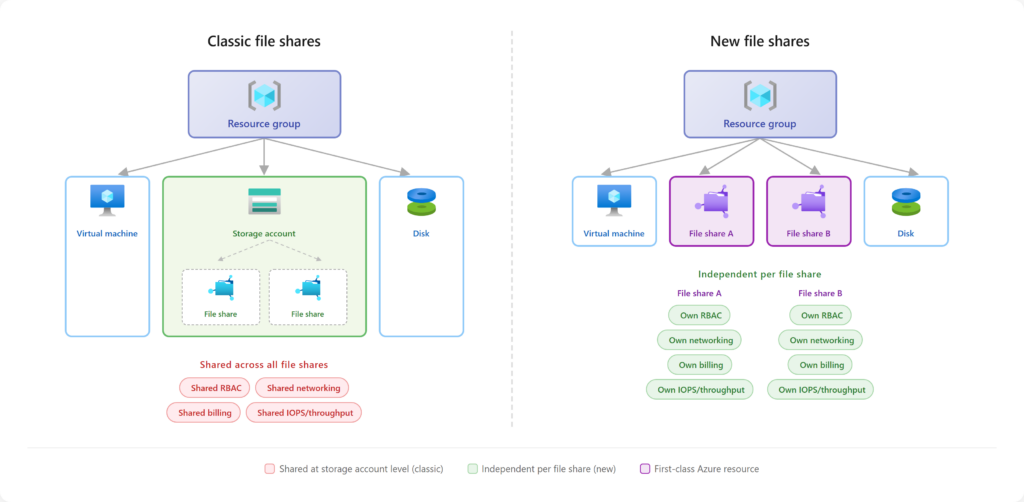
C’est la première confusion qu’il faut lever, parce qu’on l’entend partout : « des partages de fichiers, Azure en propose depuis longtemps ». Vrai… et faux. Jusqu’ici, le partage de fichiers n’a jamais été une ressource Azure à part entière. C’était toujours un objet enfant, créé à l’intérieur d’un compte de stockage. La ressource Azure, celle que vous voyiez dans votre groupe de ressources, c’était le compte de stockage et pas le partage :
Cette nuance n’est pas de la sémantique : c’est elle qui explique 90 % des frictions qu’on va voir. Tant que le partage était un sous-objet, il héritait de tout ce qui appartenait au compte. Le nouveau modèle casse précisément cet héritage.
2. Avant : tout partait du compte de stockage
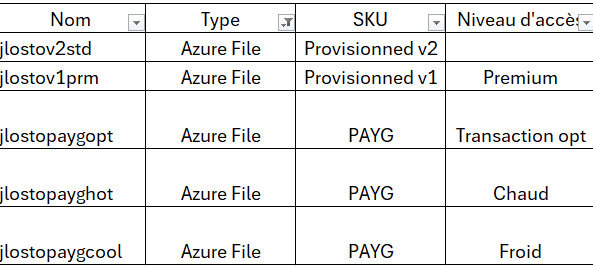
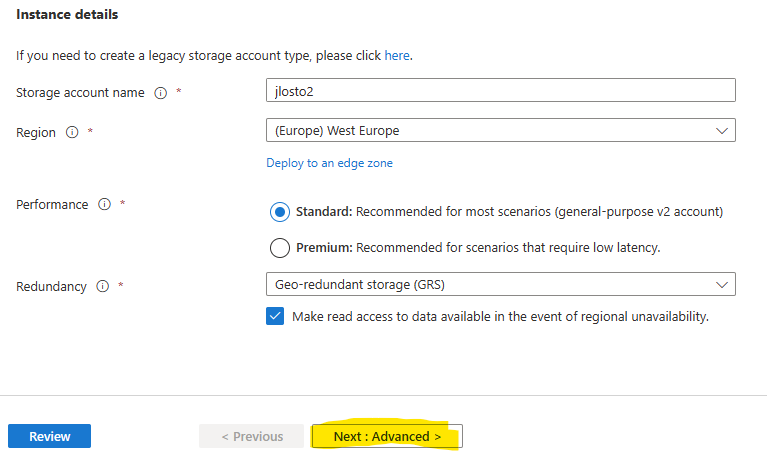
Pour rappel, jusqu’ici le schéma était le suivant : vous créiez un compte de stockage, vous choisissiez un SKU (général avec blobs/queues/tables, ou un SKU dédié file storage), puis vos partages SMB ou NFS sous ce compte. Tout partait de là, et c’est là que les ennuis commençaient.
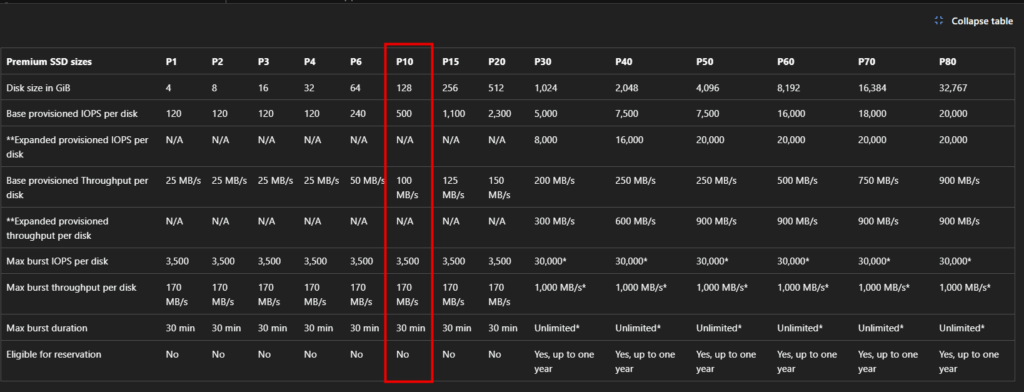
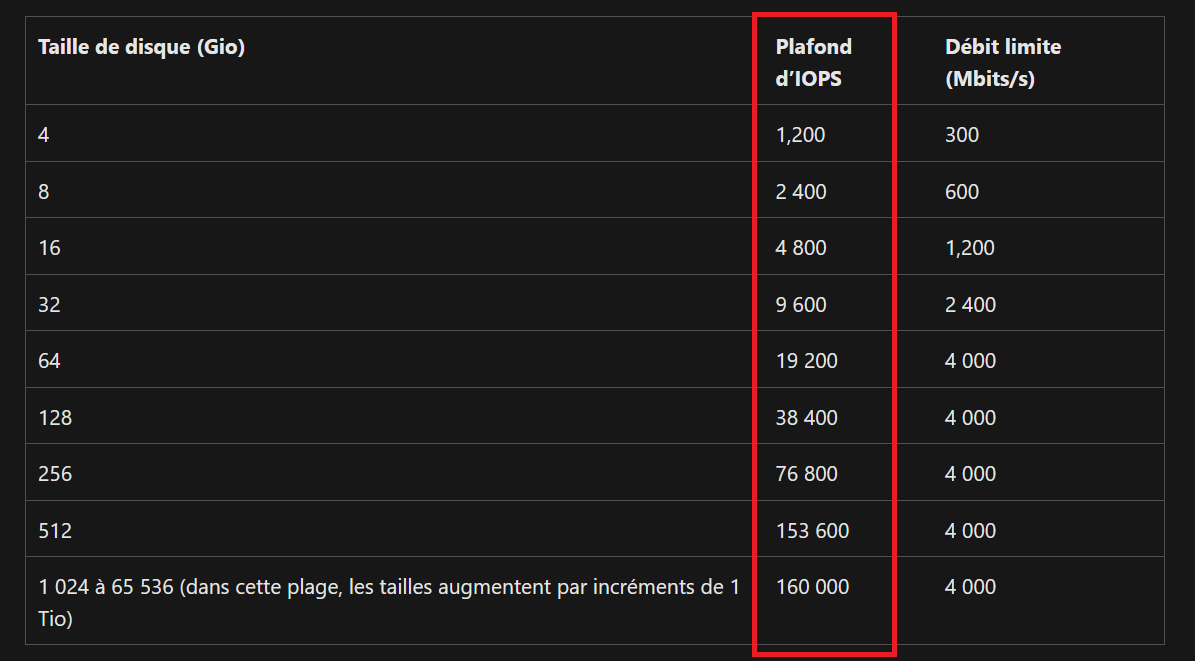
- Les limites sont partagées. IOPS, capacité provisionnée, débit : c’est le compte qui porte les plafonds, et tous les partages se les répartissent. Un partage gourmand peut pénaliser les autres.
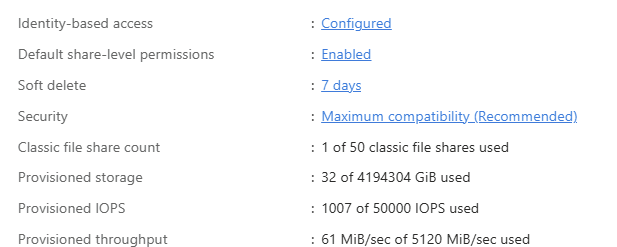
- Le control plane aussi est mutualisé. Créer, modifier, supprimer des partages, gérer les snapshots : ces opérations tapent dans des quotas au niveau du compte. À plusieurs administrateurs sur le même compte, ça devient un point de contention :
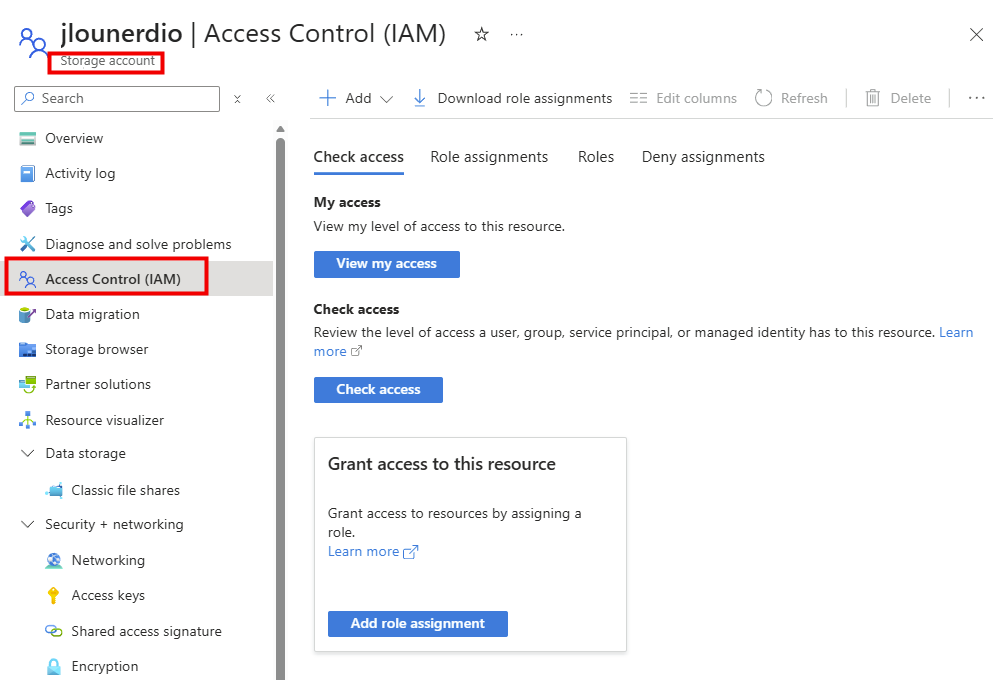
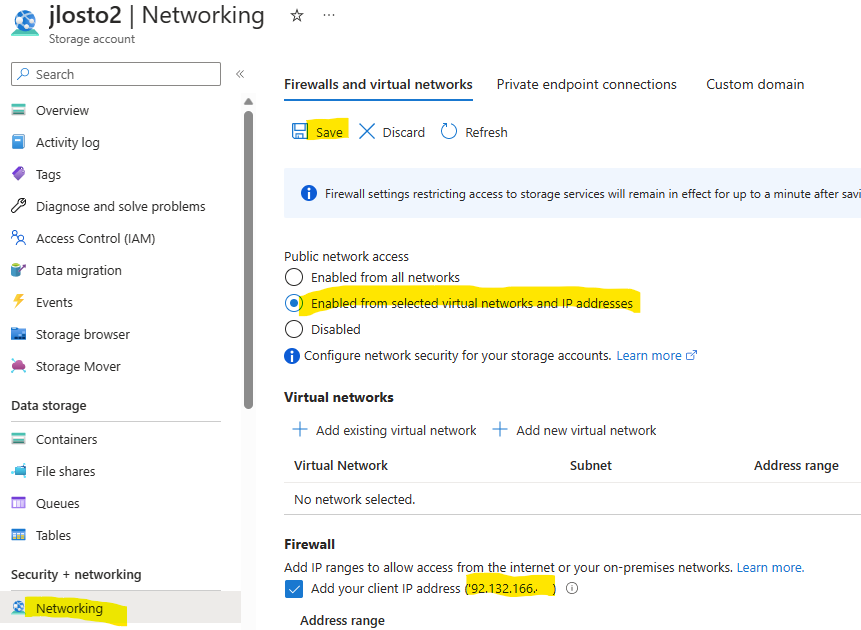
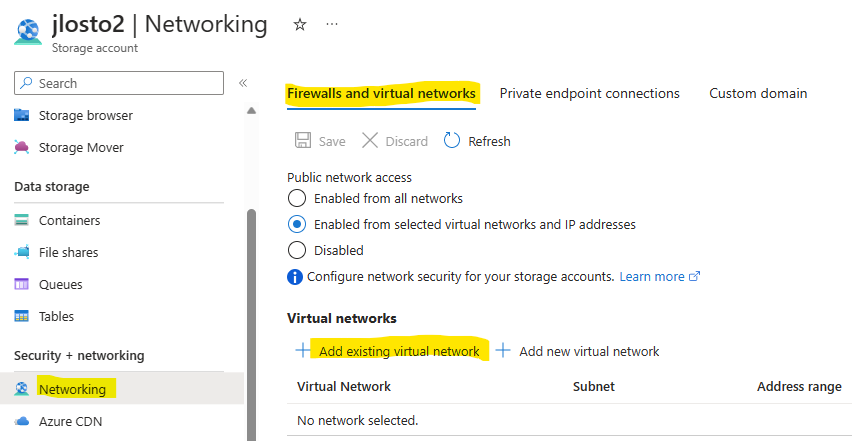
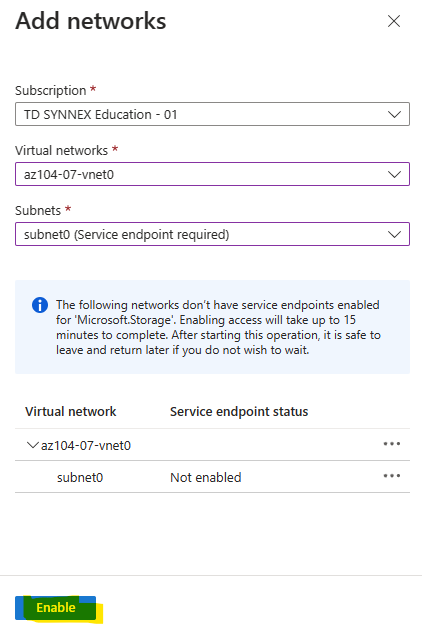
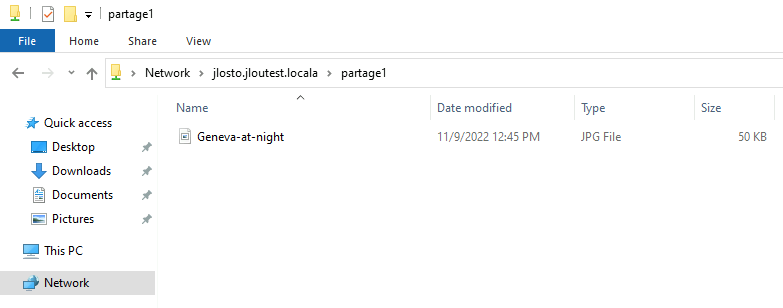
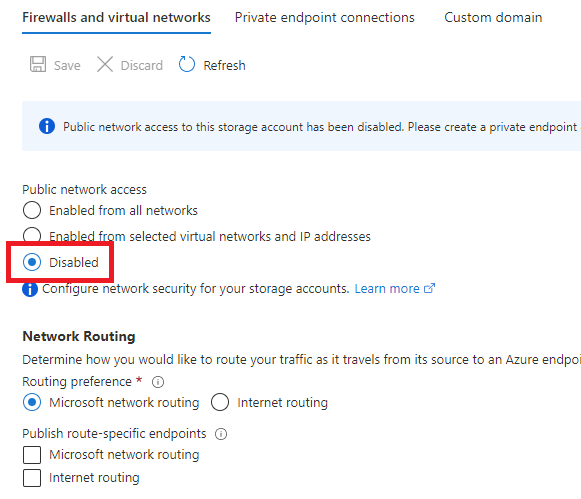
- Le réseau est hérité. C’est le compte de stockage qui porte la configuration réseau. Vos private endpoints, vos règles, vous les héritez du compte, donc pas de granularité par partage :
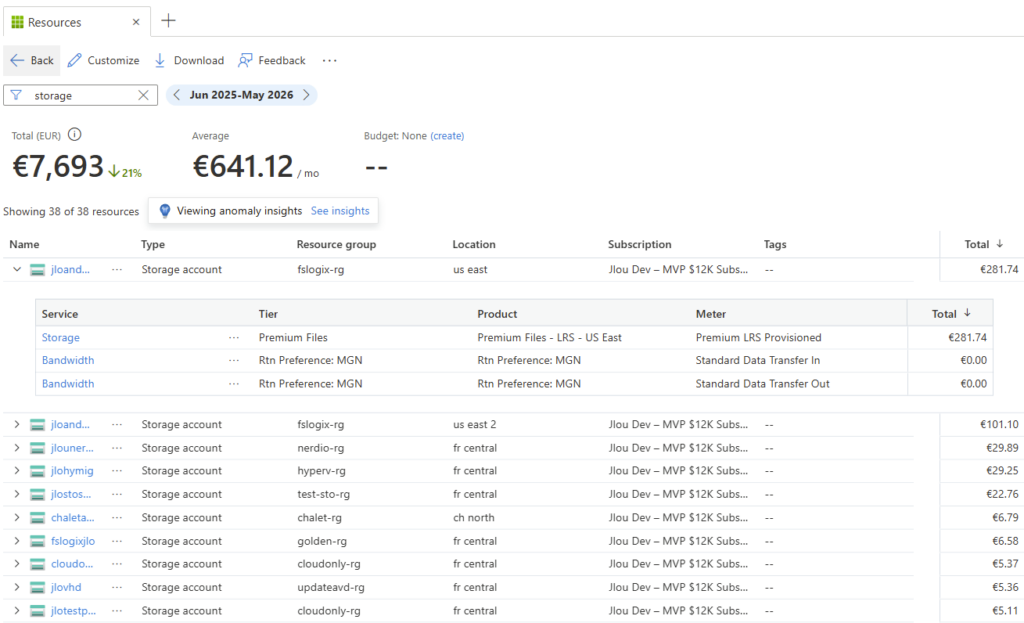
- La facturation est au niveau du compte. Bon courage pour faire du showback / chargeback propre par partage : il faut décortiquer une facture agrégée :
- La clé de compte est toute-puissante. La fameuse account key donne accès à tout ce qui vit dans le compte de stockage. Côté sécurité, c’est un secret à très large rayon d’action :
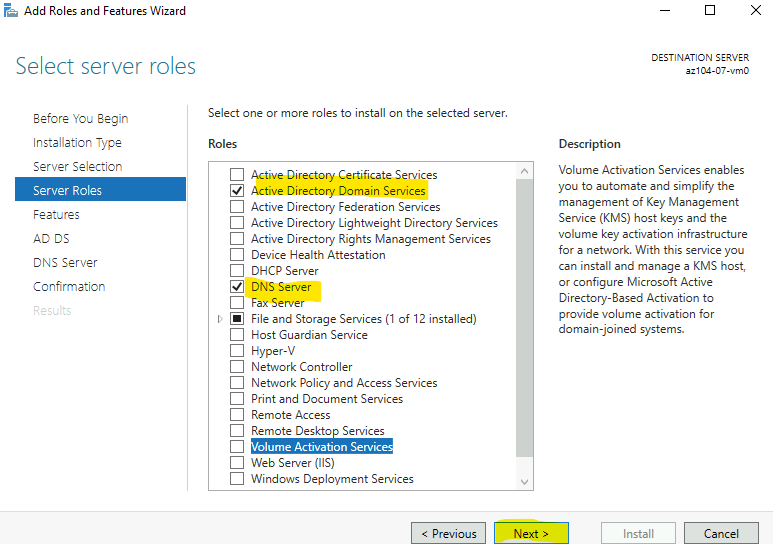
3. Après : Microsoft.FileShares, ressource de premier niveau
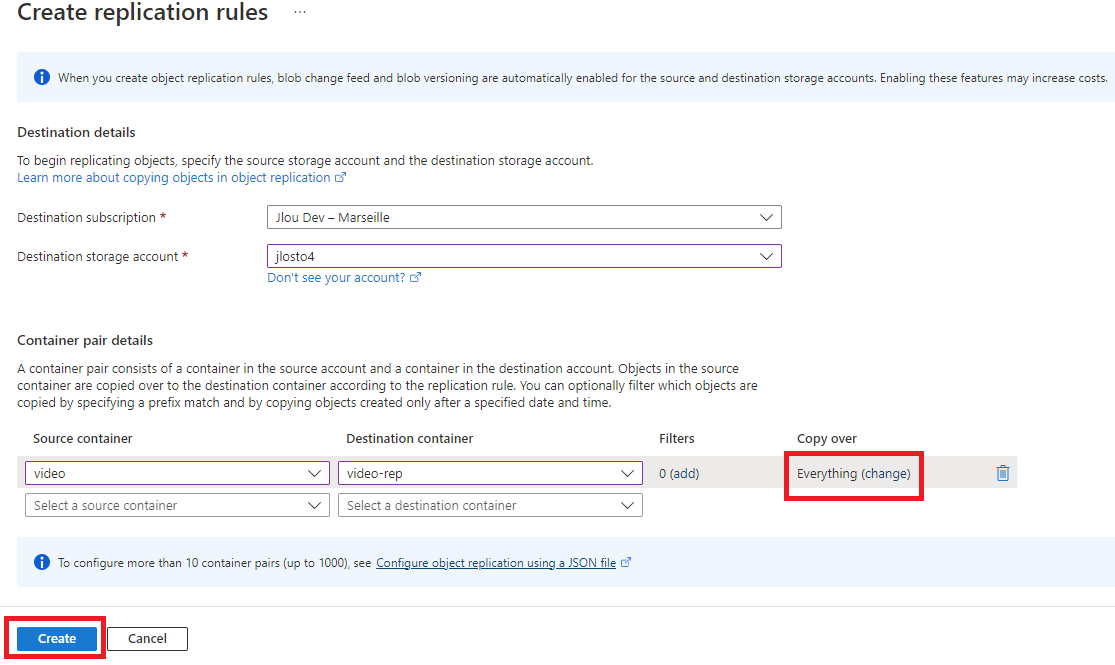
Concrètement, ça donne quoi ? Microsoft introduit un nouveau provider de ressources, Microsoft.FileShares, et avec lui un nouveau type de ressource top-level : le partage de fichiers lui-même. Pas d’enfant, pas de parent compte de stockage. Vous créez directement un file share dans un groupe de ressources et un abonnement, vous lui donnez un nom, et c’est tout.
Nous annonçons la mise à disposition générale d’une nouvelle expérience de gestion des services pour les partages de fichiers SSD Premium (NFS), qui permet de créer, sécuriser, faire évoluer et facturer chaque partage de fichiers de manière indépendante, sans être lié à un compte de stockage.
- Gestion familière et intuitive des partages de fichiers : l’expérience utilisateur s’aligne sur les modèles des NAS et des serveurs de fichiers sur site, ce qui améliore la convivialité par rapport au modèle classique.
- Infrastructure-as-Code : définissez la nomenclature, la capacité, les IOPS, la mise en réseau, les balises et la sécurité dans des modèles Bicep ou ARM pour une automatisation simplifiée avec vos outils DevOps préférés.
- Évoluez en fonction de la charge de travail : prise en charge de jusqu’à 10 000 partages de fichiers par abonnement et par région, avec une expérience de provisionnement des partages de fichiers 2,5 fois plus rapide.
- Sécurité et réseau au niveau des partages : restrictions réseau, instantanés et chiffrement limités au partage individuel, ce qui permet de faire correspondre les limites d’isolation aux limites de la charge de travail.
- Visibilité des coûts par partage : les compteurs de facturation s’affichent sous la ressource de partage de fichiers, ce qui permet aux équipes d’effectuer des refacturations précises, de suivre les coûts par charge de travail et d’améliorer la refacturation sans avoir recours à des solutions de contournement.
– Source : Microsoft Techcommunity
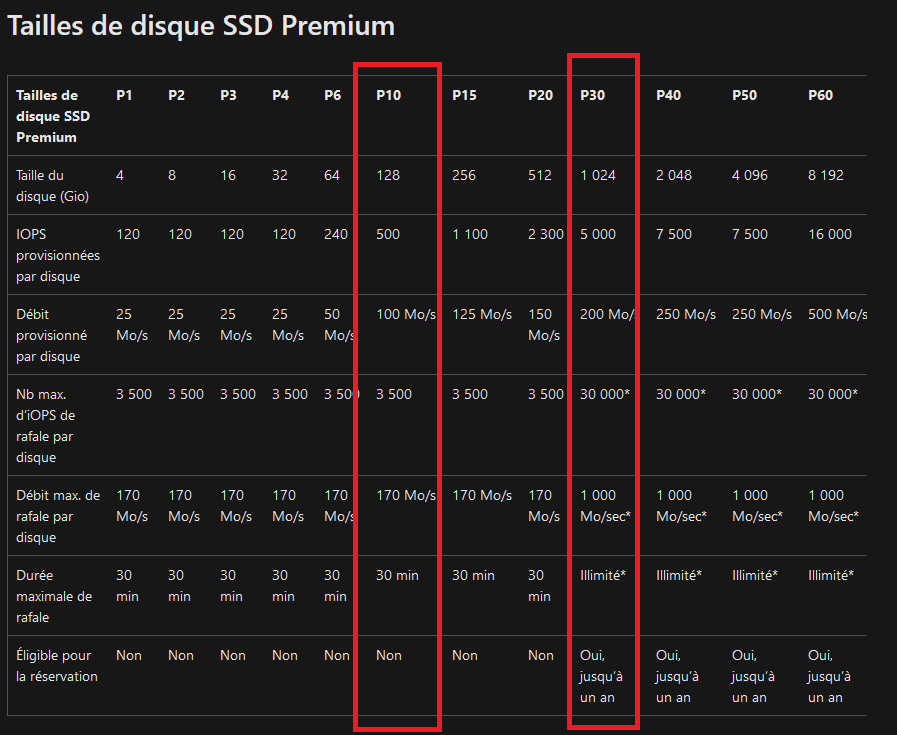
Au jour du GA, le périmètre est volontairement resserré :
- Tier SSD uniquement
- Protocole NFS 4.1 uniquement
- Facturation alignée sur le modèle provisioned v2 SSD
- Côté résilience, vous choisissez LRS ou ZRS
- Capacité, IOPS et débit se provisionnent indépendamment
Azure file share using Microsoft.FileShares is now generally available… shares are deployed as independent, top-level Azure resources through the Microsoft.FileShares resource provider, removing the dependency on storage accounts.
Source : Microsoft Learn
4. La démo : on crée un partage, écran par écran
Assez de théorie, passons aux mains dans le cambouis. Le mieux pour comprendre ce qui change, c’est de dérouler la création d’un partage dans le portail. Vous allez voir : il n’y a plus jamais le mot « compte de stockage » dans le parcours.
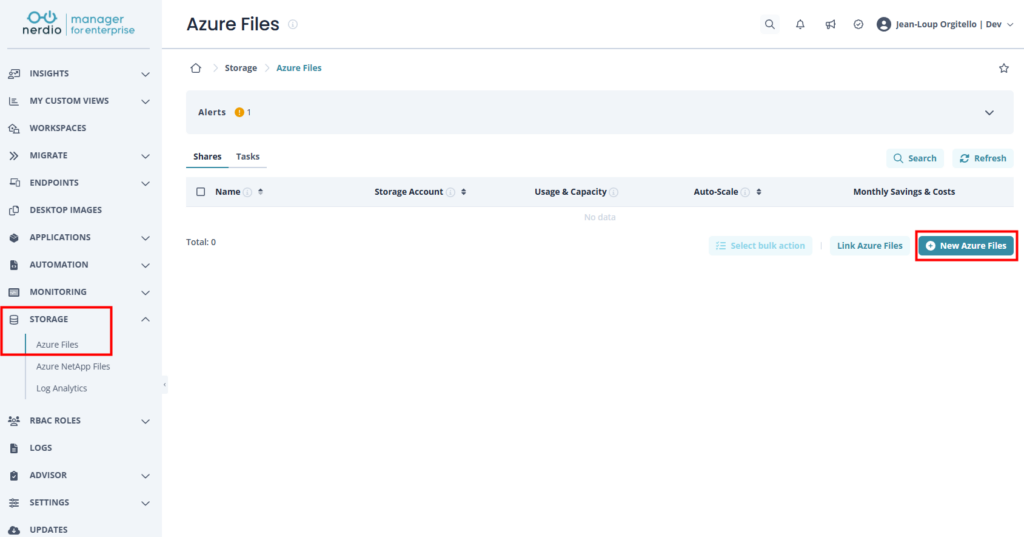
Étape 0 : Le nouveau point d’entrée « File shares »
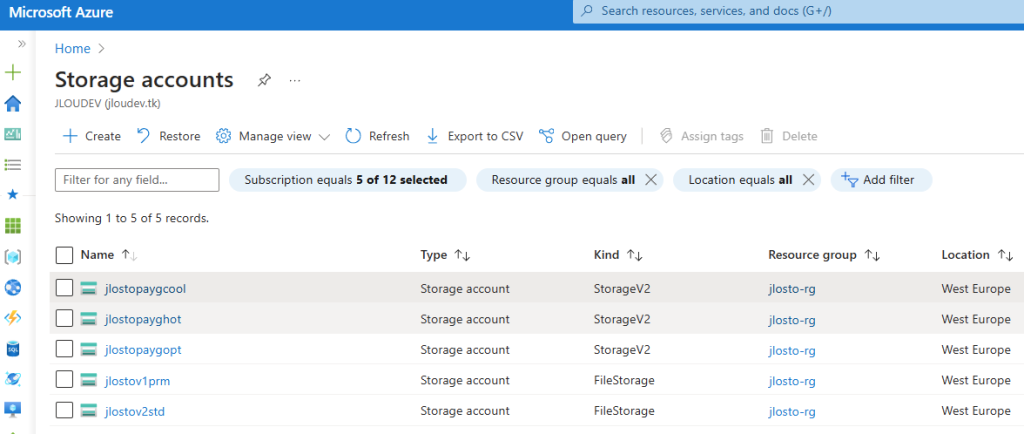
Depuis l’accueil du portail, vous cherchez directement File shares. C’est un hub à part entière, qui liste vos partages comme des ressources autonomes :
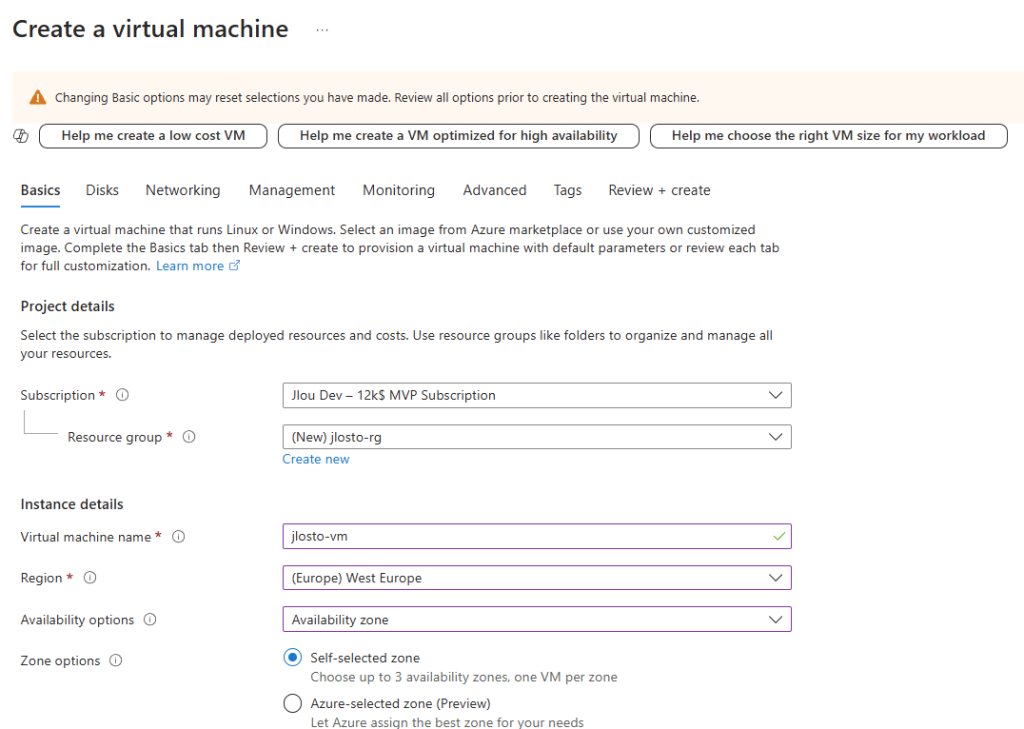
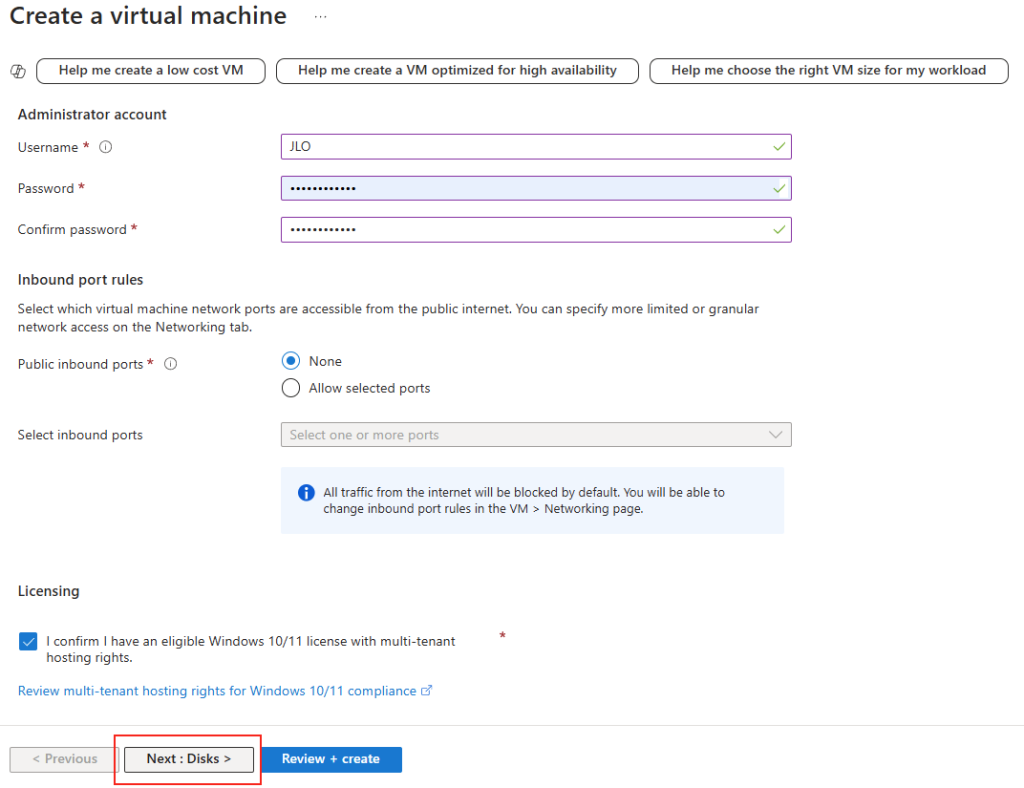
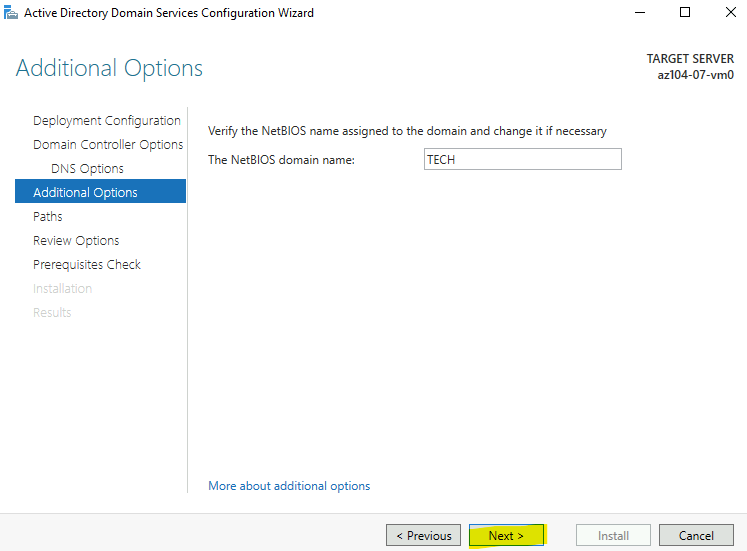
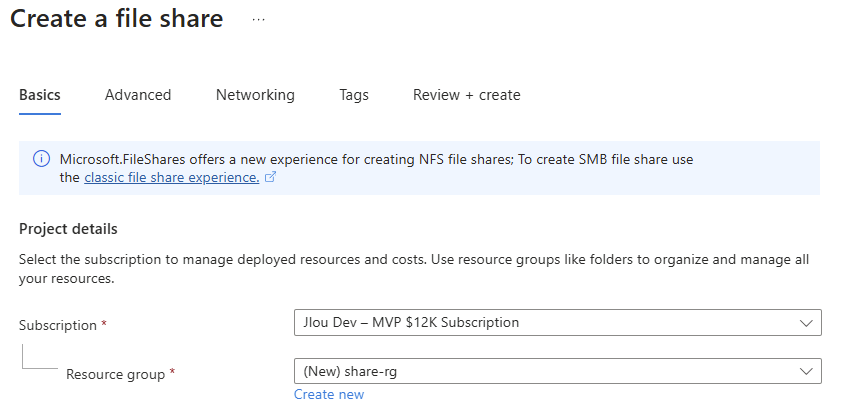
Étape 1 : Les bases : abonnement, groupe de ressources, nom
On clique sur Create. Et là, surprise par rapport au monde d’avant : on vous demande un abonnement, un groupe de ressources et un nom de partage. Point. Exactement comme pour n’importe quelle ressource Azure de premier niveau :
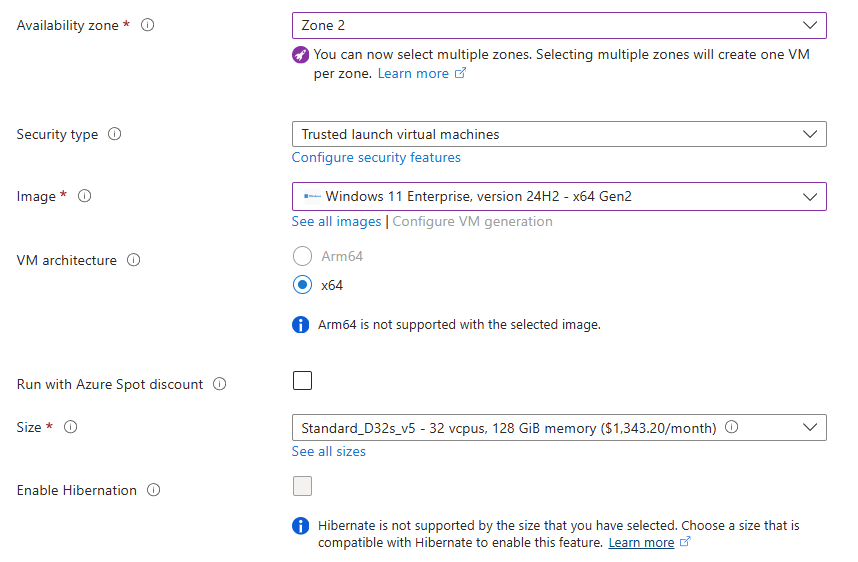
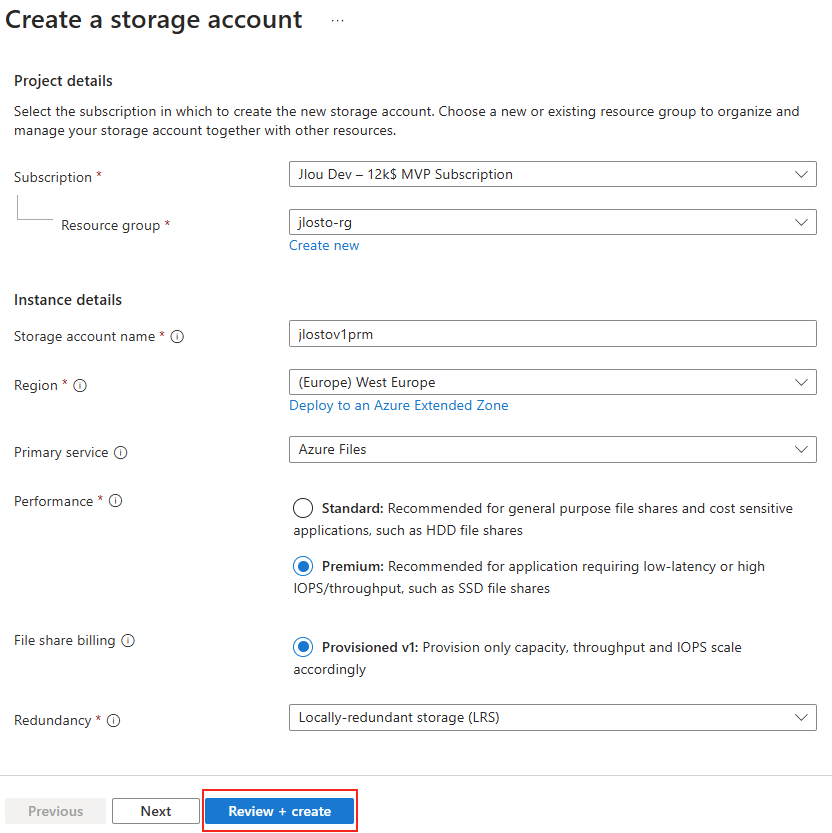
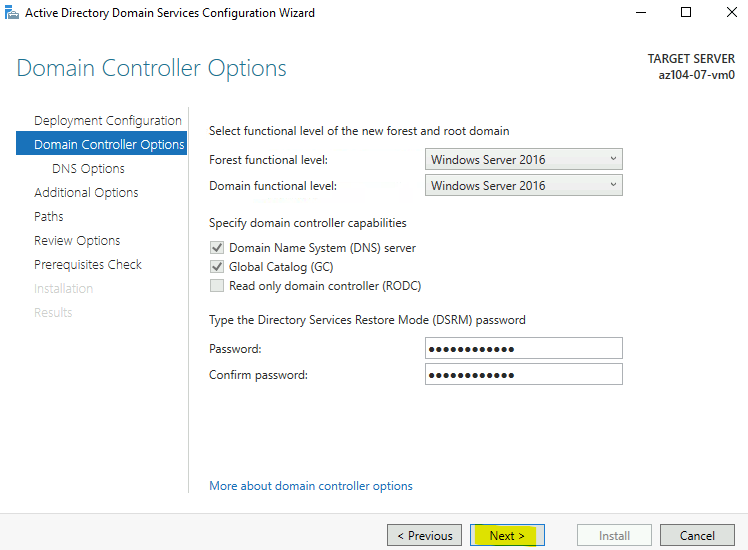
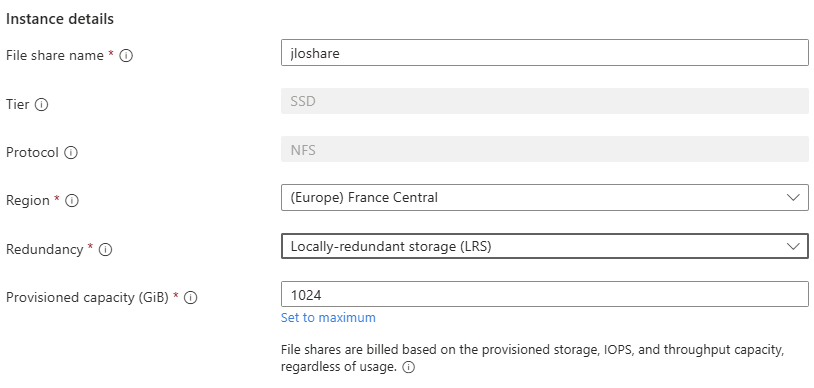
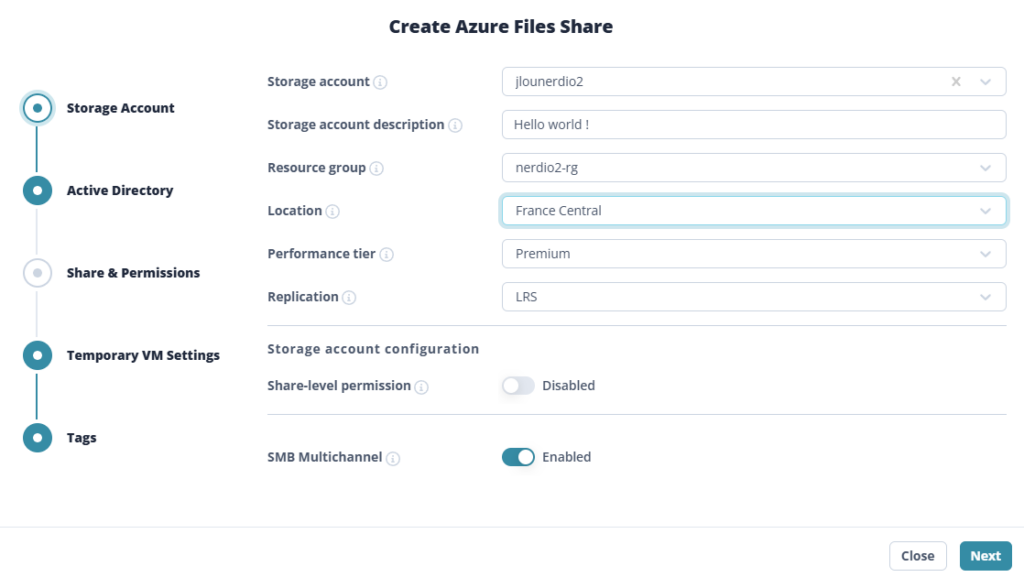
Étape 2 : Tier, protocole et résilience
Au GA, le choix est volontairement cadré : tier SSD et protocole NFS 4.1 imposés. La seule décision de résilience se fait ici, au niveau du partage : LRS (redondance locale) ou ZRS (redondance inter-zones) selon la région Azure choisie :
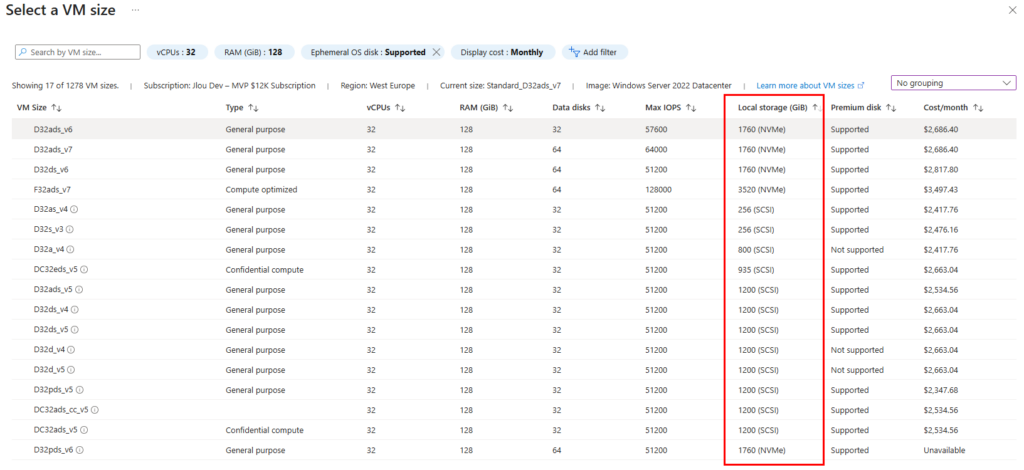
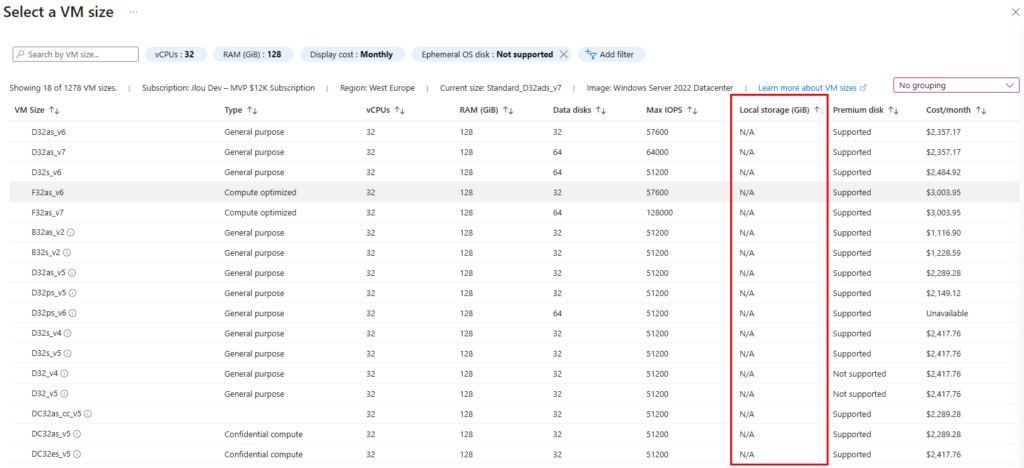
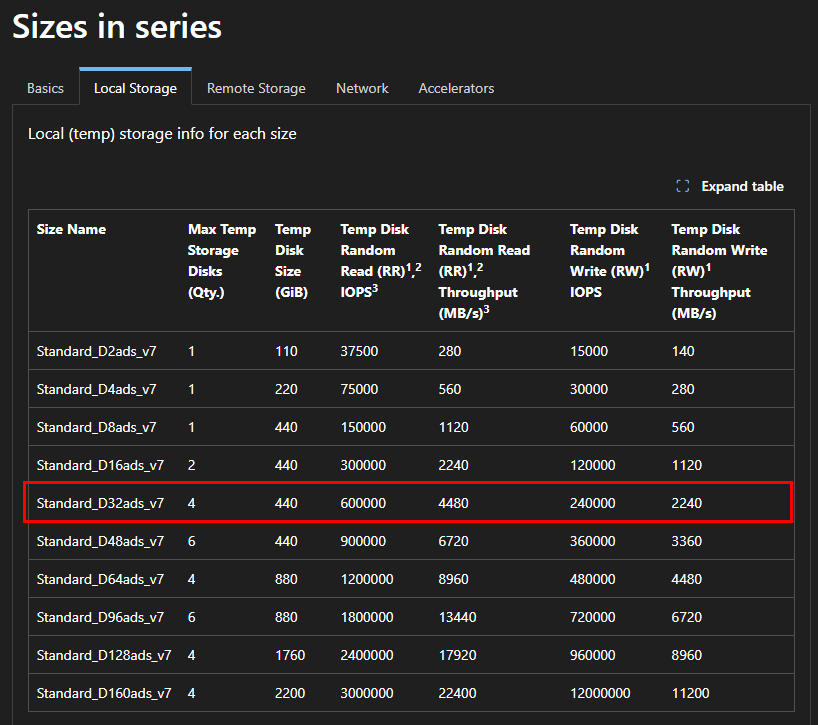
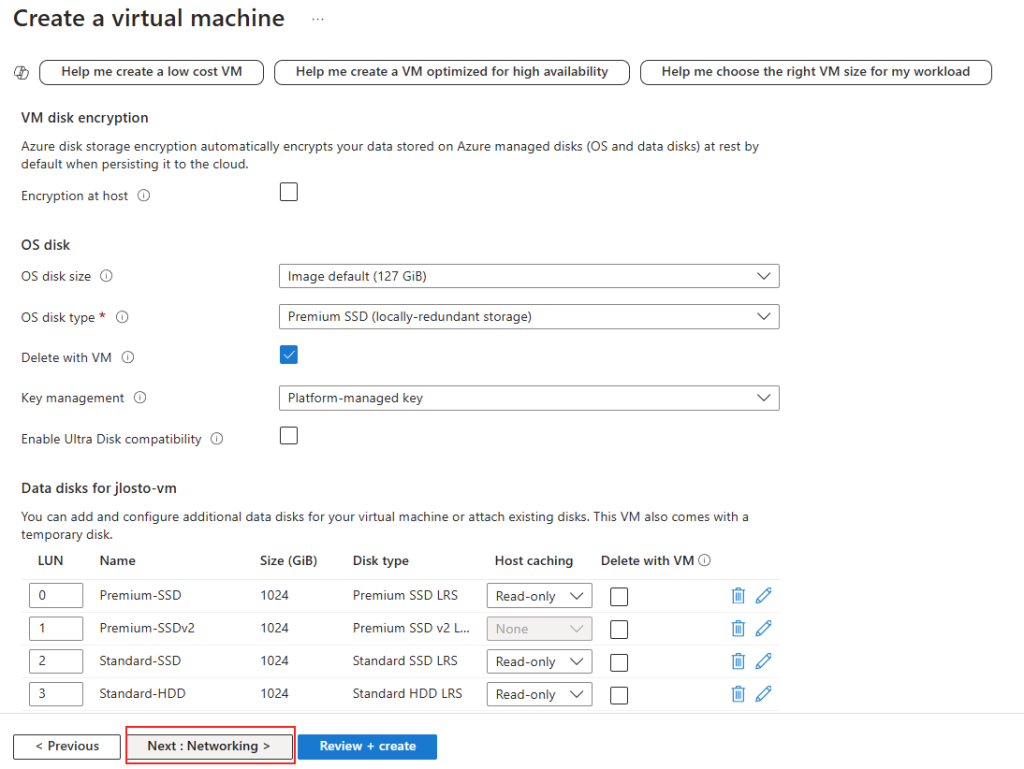
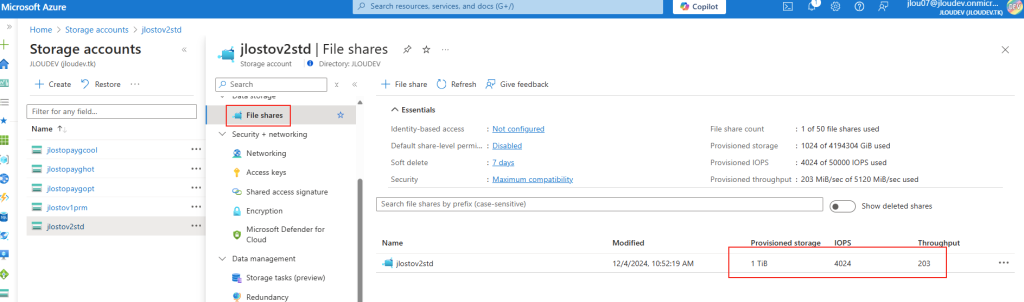
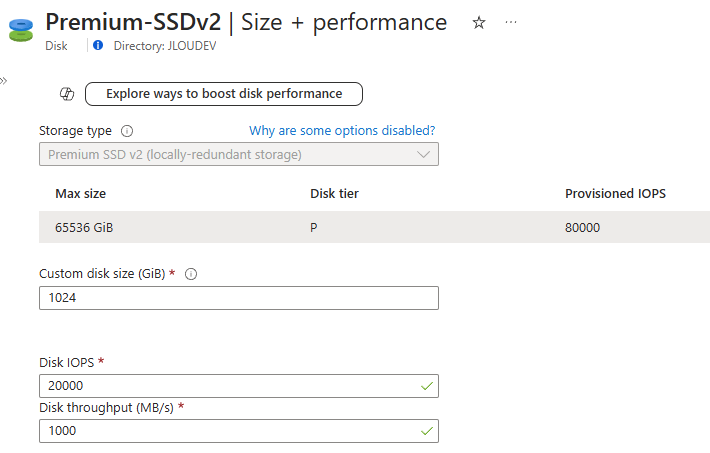
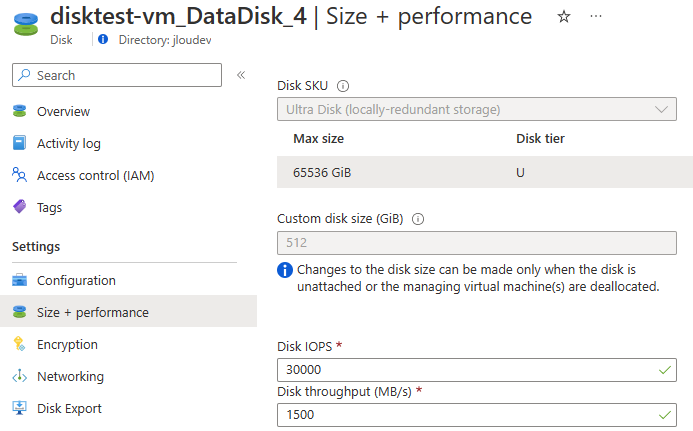
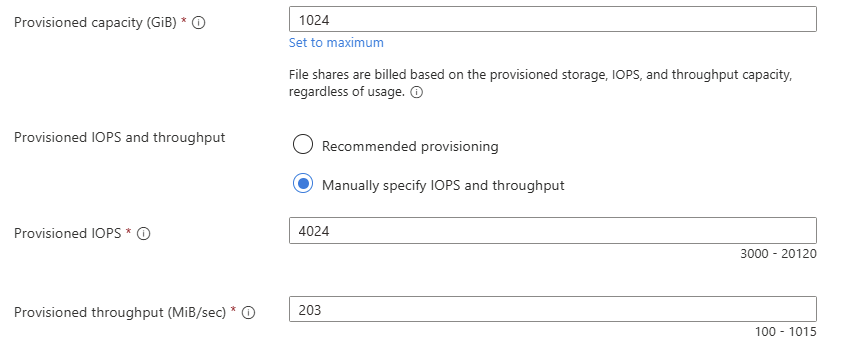
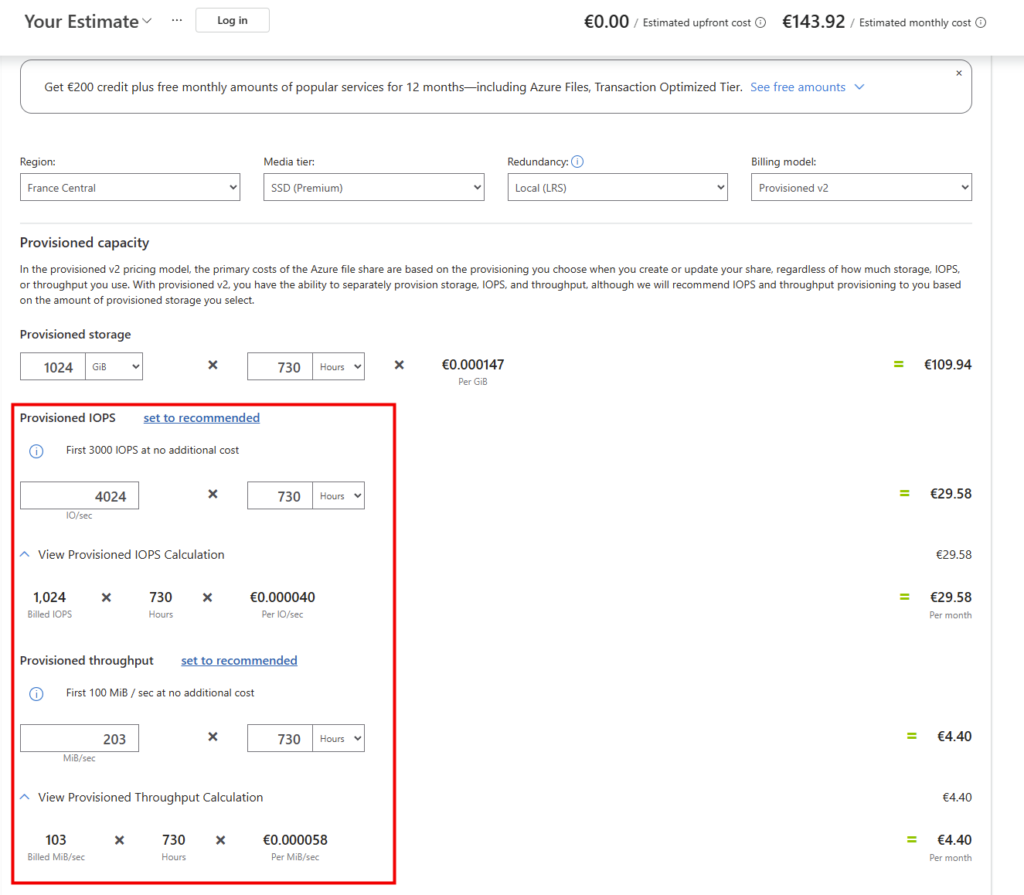
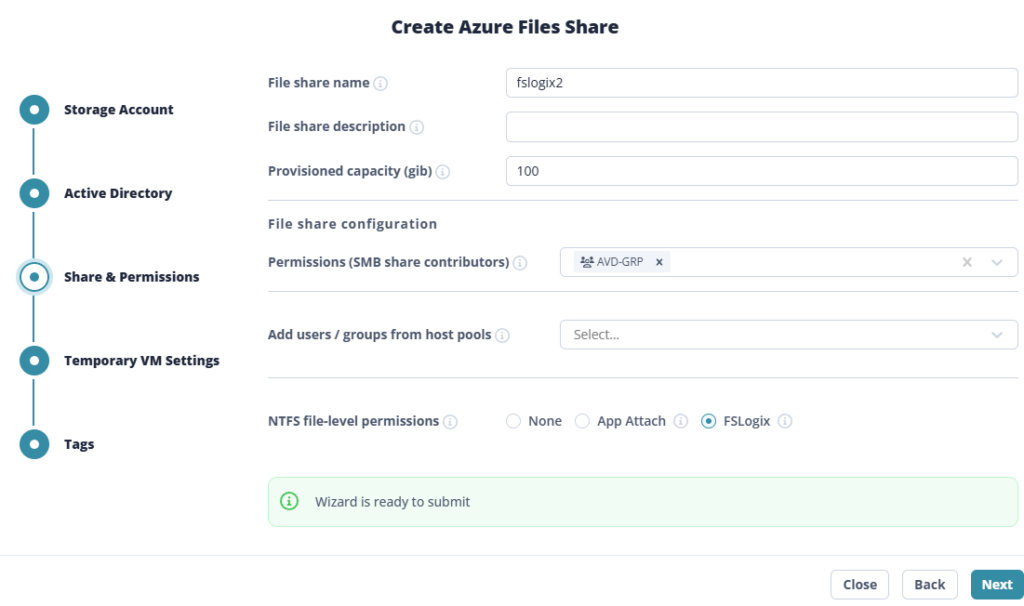
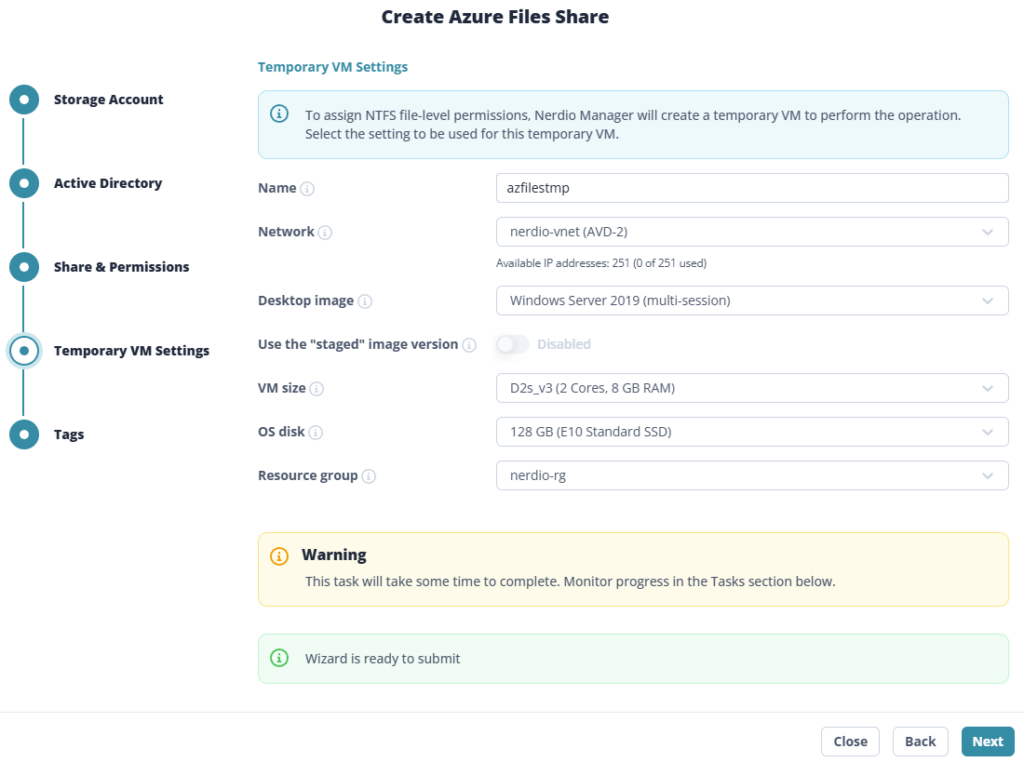
Étape 3 : Le cœur du sujet : capacité, IOPS et débit séparés
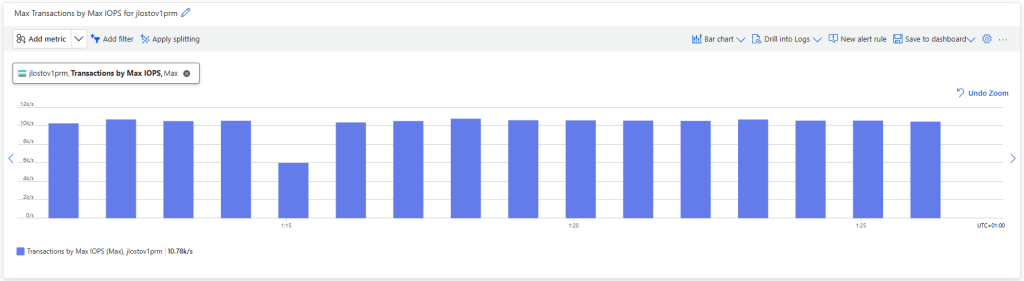
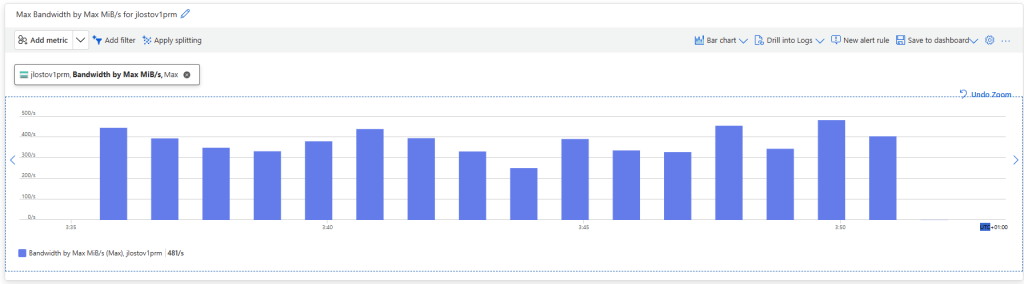
C’est l’écran le plus important. Vous provisionnez la capacité, les IOPS et le débit de façon indépendante. Plus de « budget commun » réparti entre tous les partages du compte : ce que vous réglez ici, ce sont les limites de ce partage, et de lui seul :
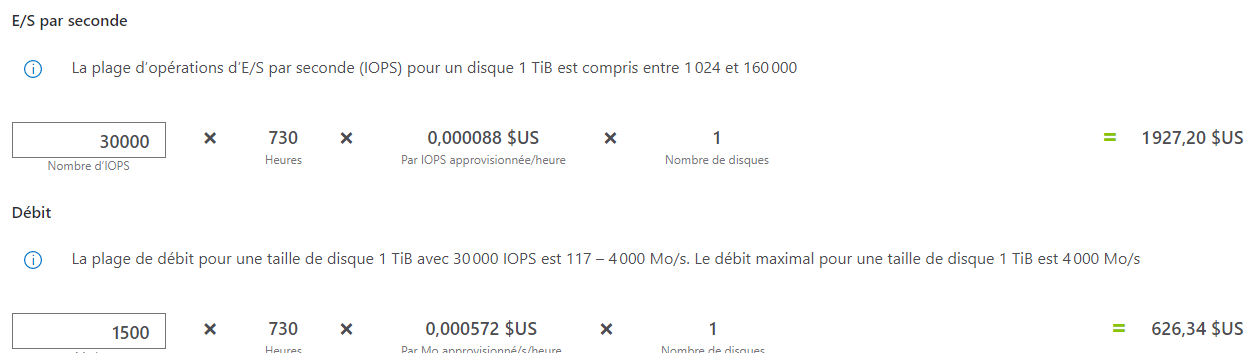
Le Calculateur de prix Azure vous permet de travailler ces valeurs, tout en mesurant l’impact sur le prix :
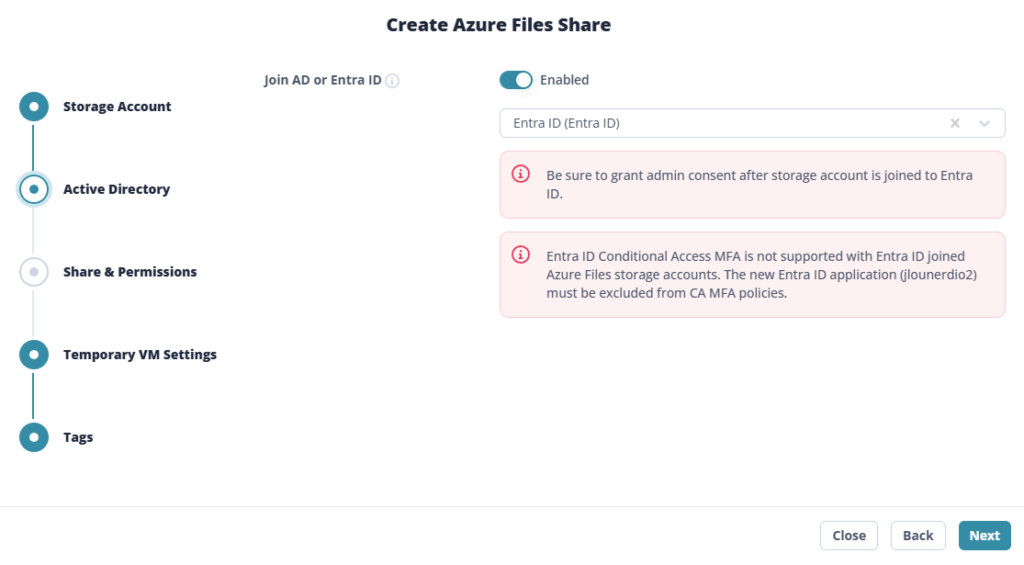
Étape 4 : L’onglet Advanced : root squash, chiffrement et nom de montage
C’est l’onglet qu’on a tendance à survoler, et c’est dommage, parce qu’il porte trois réglages qui changent la vie côté NFS :
- Protocol → Root squash. C’est le mapping de l’identité
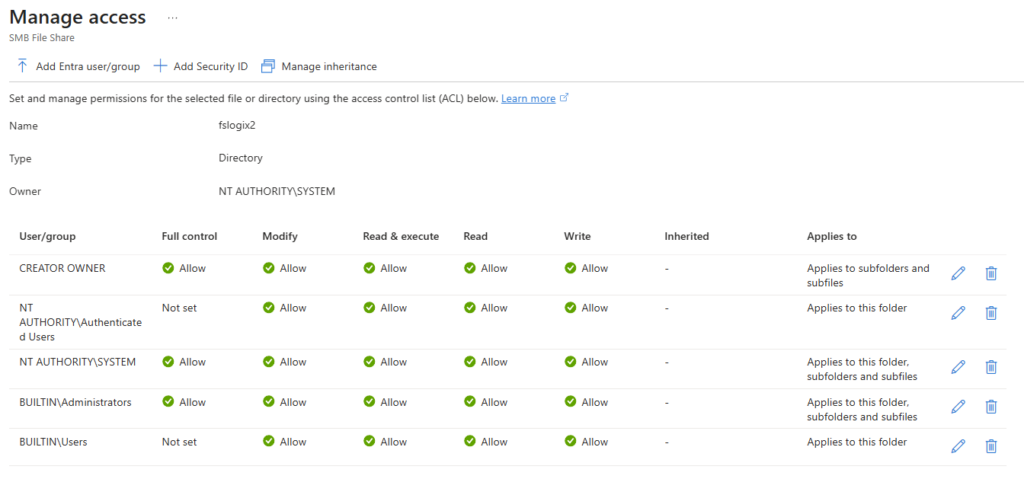
rootcôté client NFS. Vous choisissez entre no root squash, root squash et all squash selon le niveau de confiance que vous accordez aux clients qui montent le partage. - Security → Require encryption in transit. Vous imposez le chiffrement du flux entre le client et le partage. À garder activé sauf raison impérieuse.
- Other → Mount name. Vous donnez au partage un nom de montage différent du nom de la ressource Azure. Pratique pour garder des chemins de montage propres côté clients NFS sans vous imposer la convention de nommage Azure.
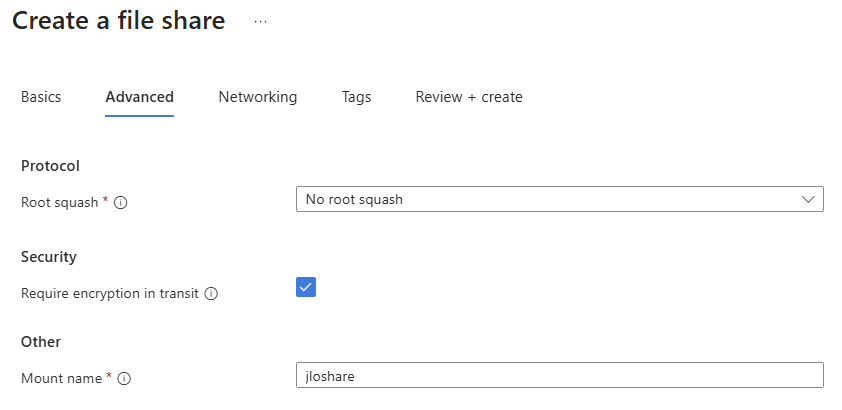
fstab et vos scripts. Vos clients NFS gardent des chemins courts et lisibles.Étape 5 : Le réseau, au niveau du partage
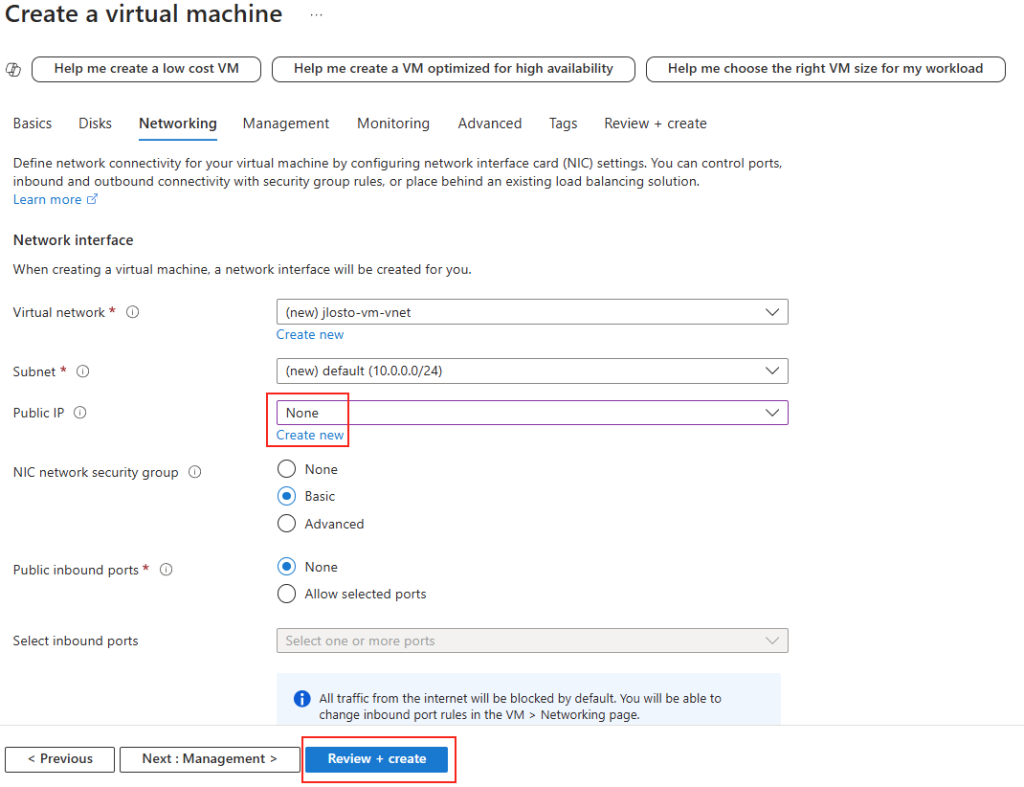
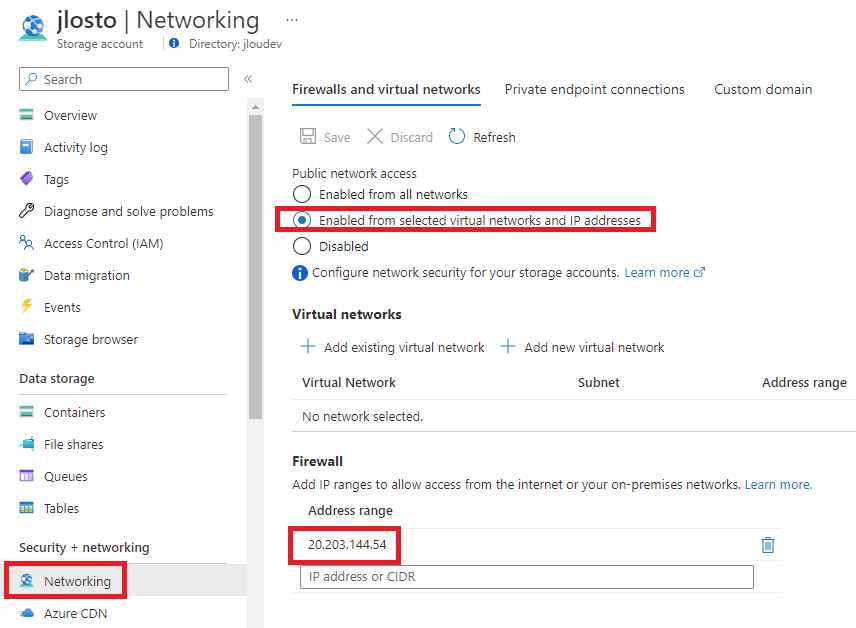
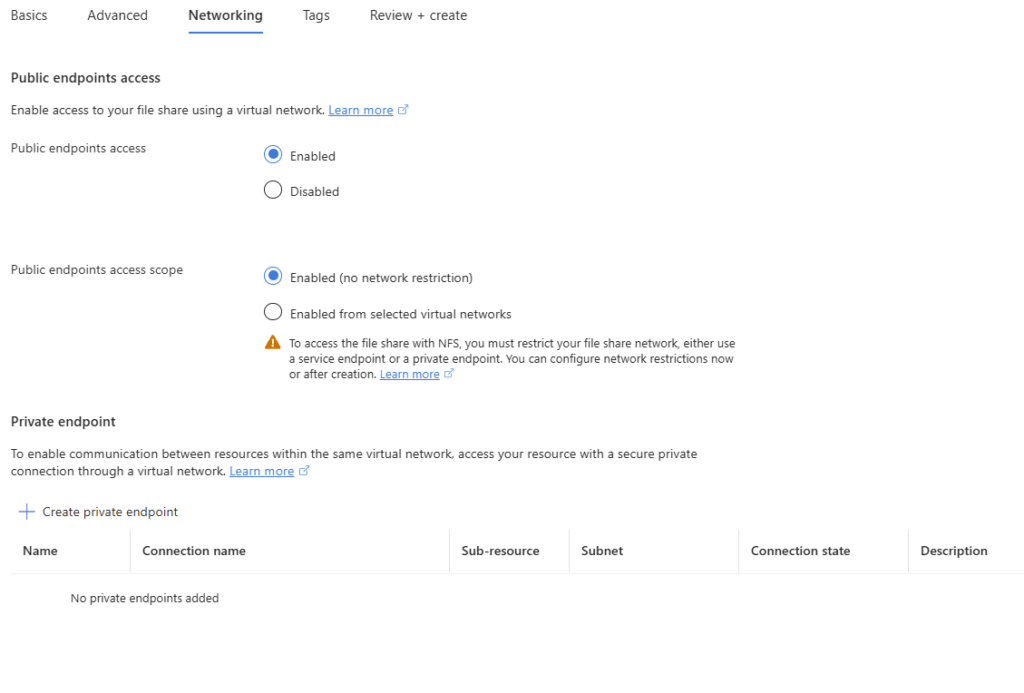
Autre changement de fond : la configuration réseau se fait ici, pas sur un compte parent. Vous décidez pour ce partage s’il est exposé en public endpoint ou enfermé derrière des private endpoints. Chaque partage a donc sa propre posture réseau :
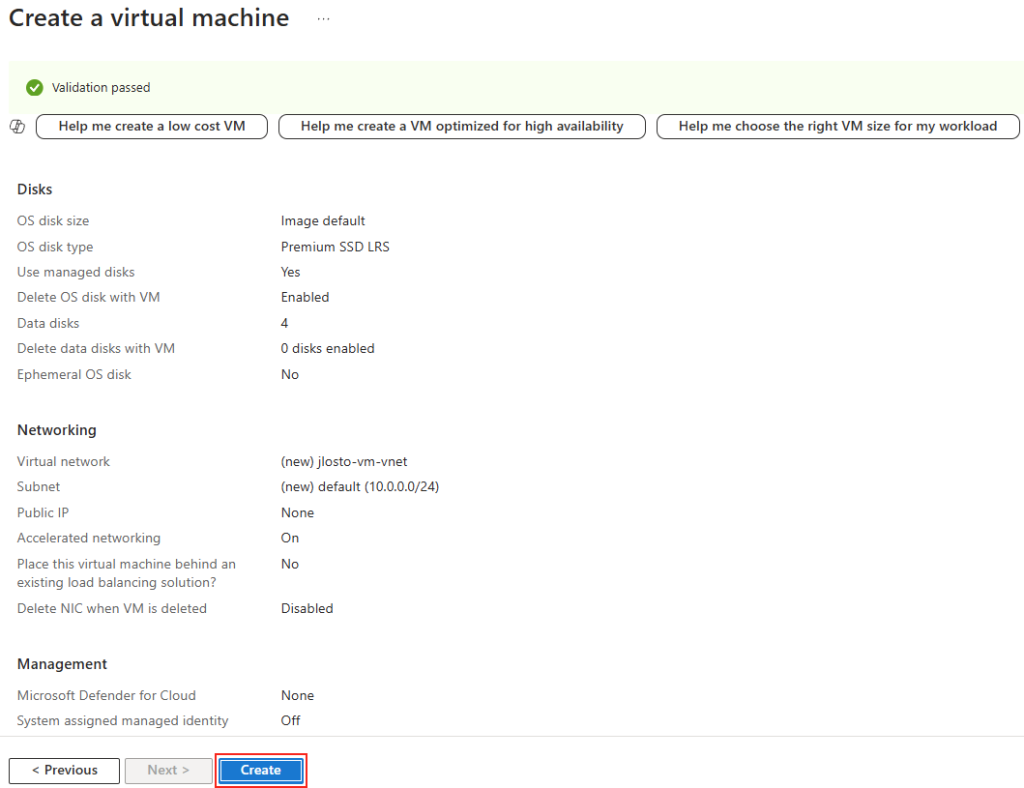
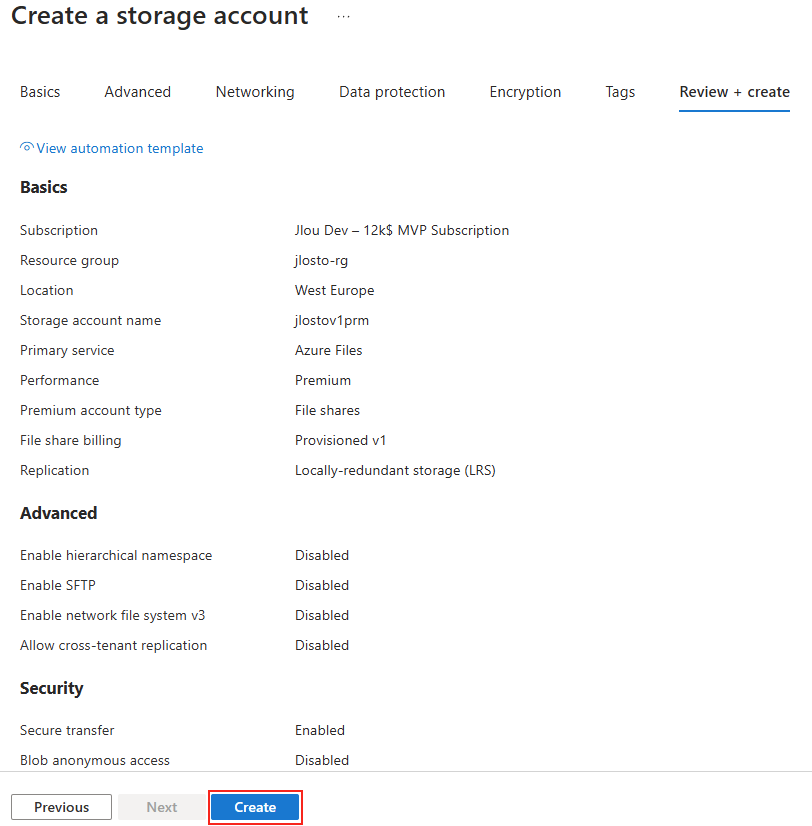
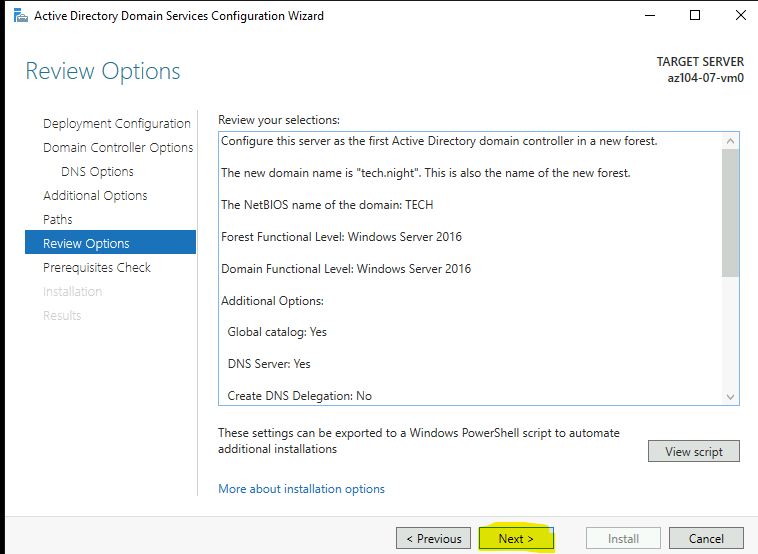
Étape 6 : Review + create, le moment de vérité
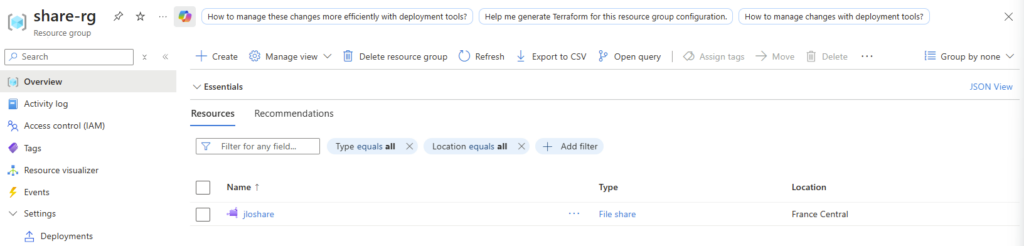
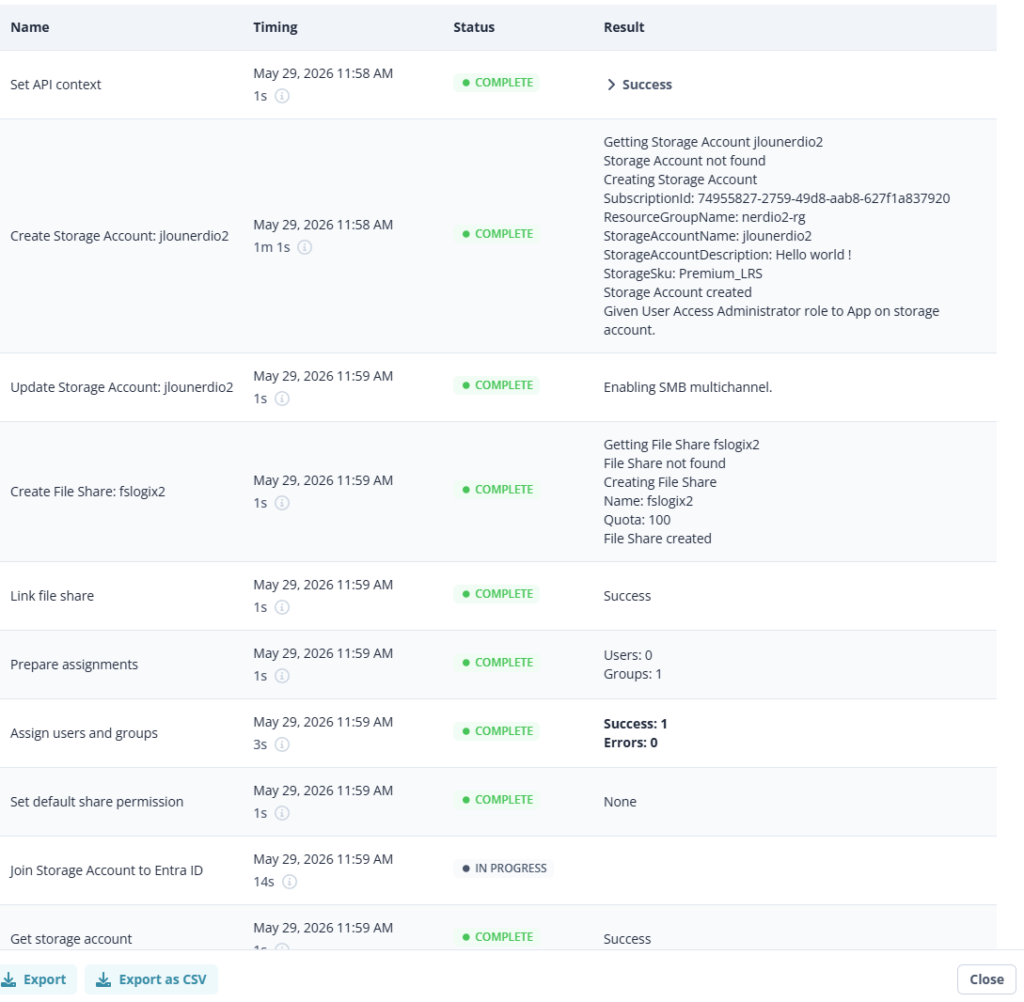
On valide, on crée. Et là, magie : le partage apparaît dans le groupe de ressources comme une ressource Microsoft.FileShares à part entière, avec ses propres tags, son propre coût, son propre control plane :
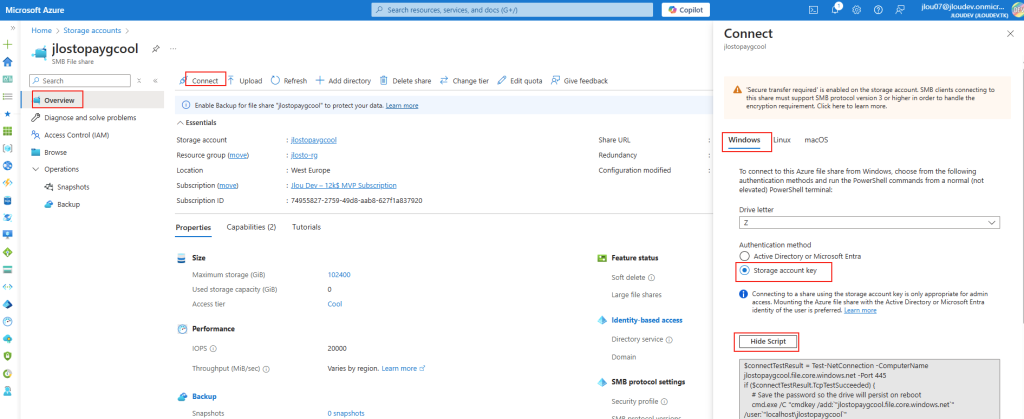
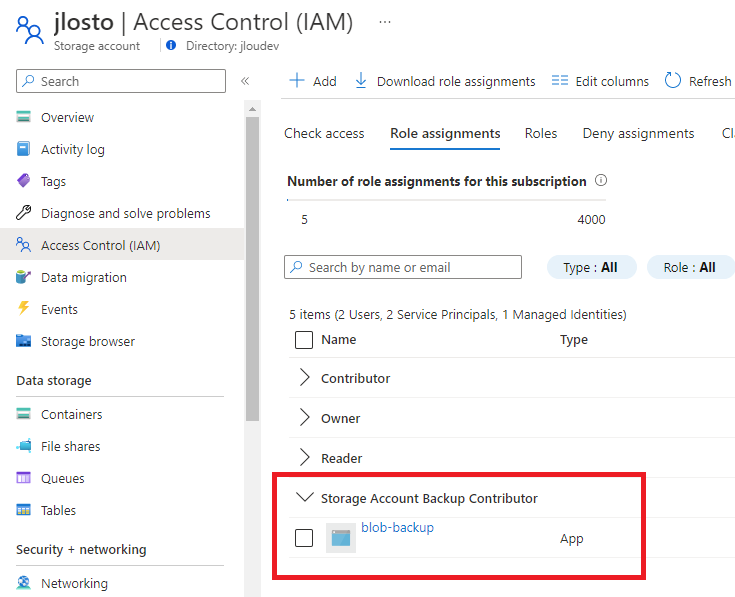
Aucune clé de compte à aller récupérer quelque part, parce qu’il n’y en a tout simplement pas :
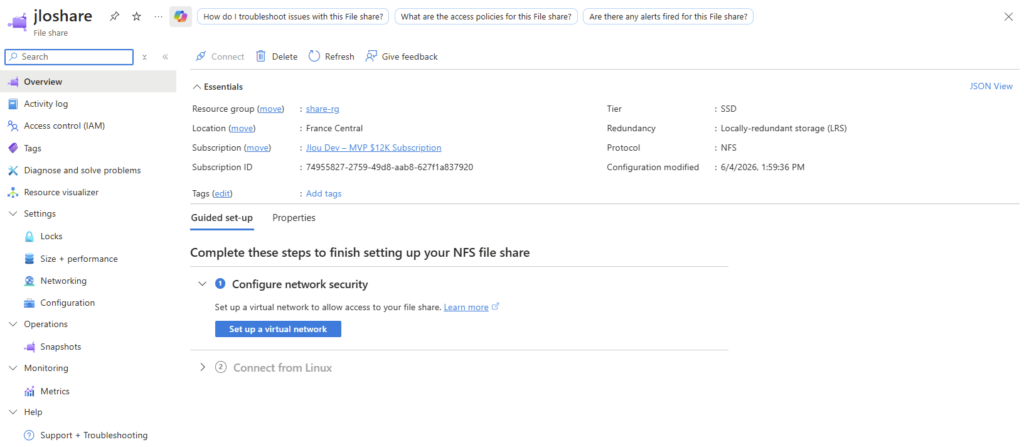
Du côté des performances et de la taille, tout est toujours rectifiable :
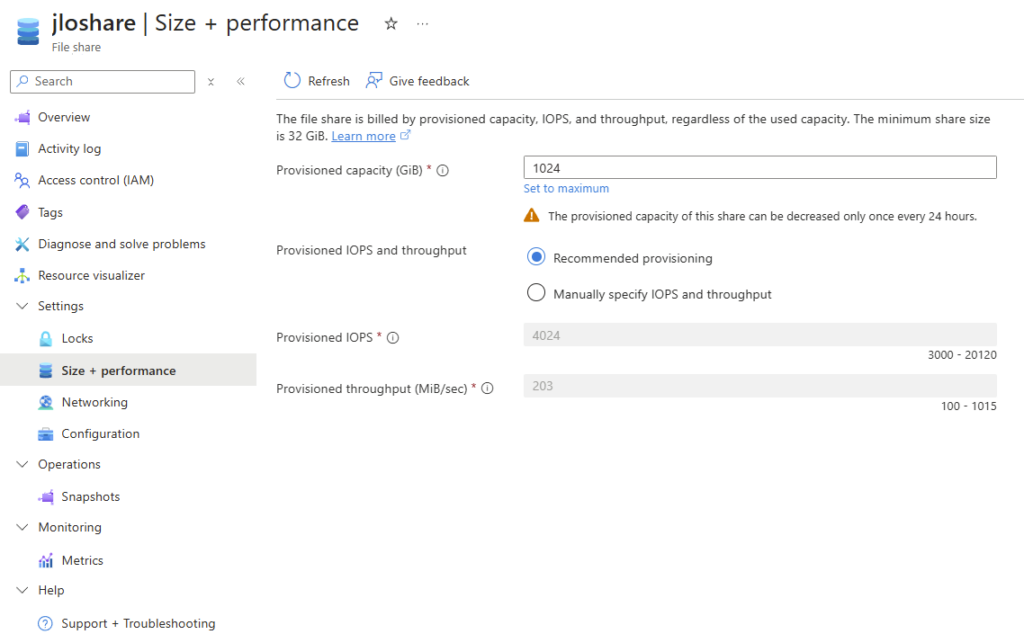
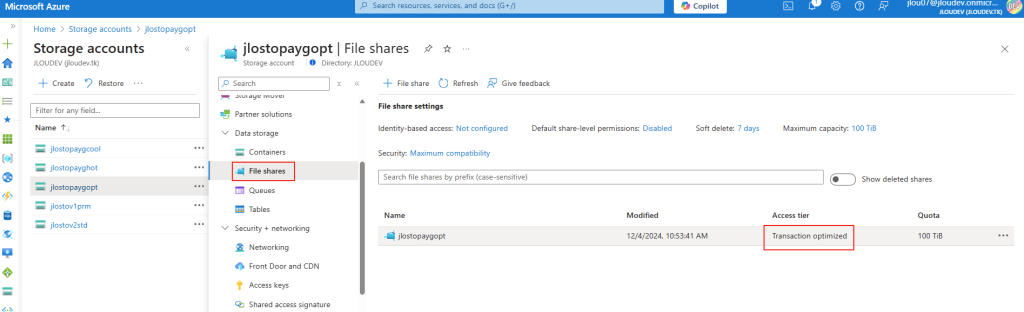
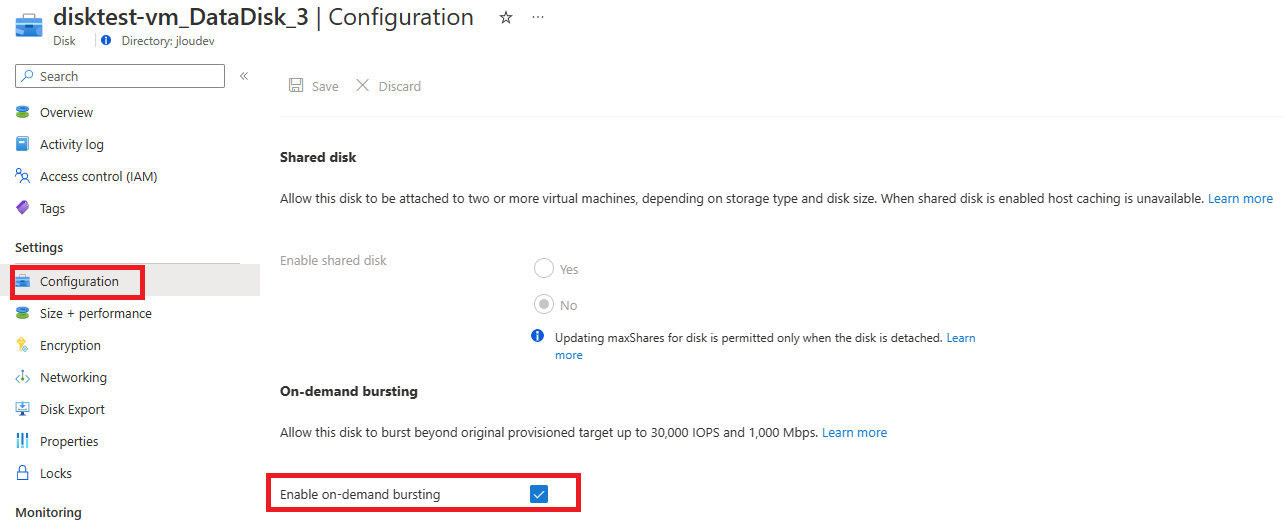
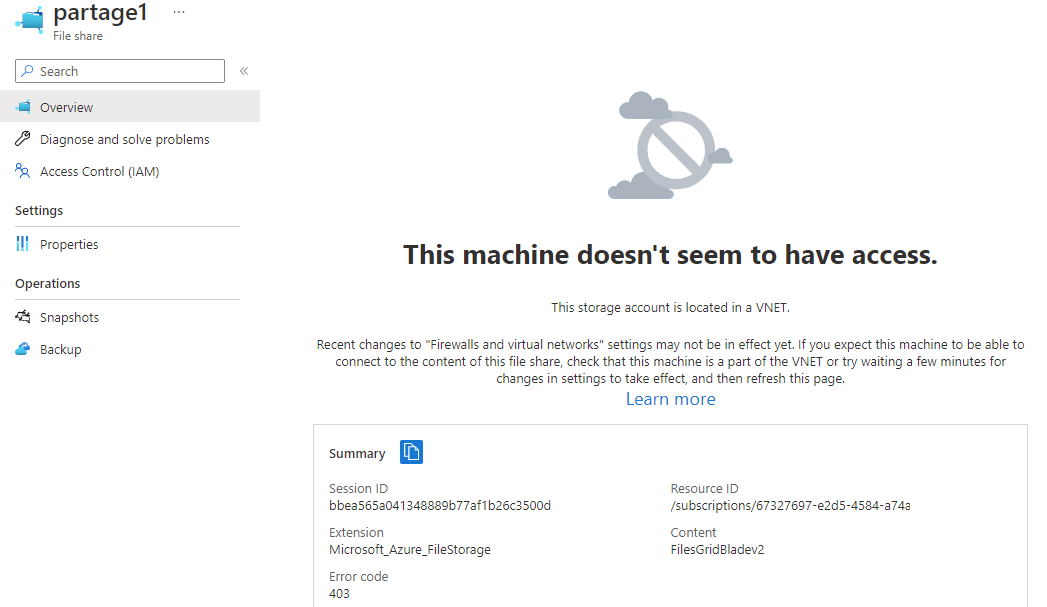
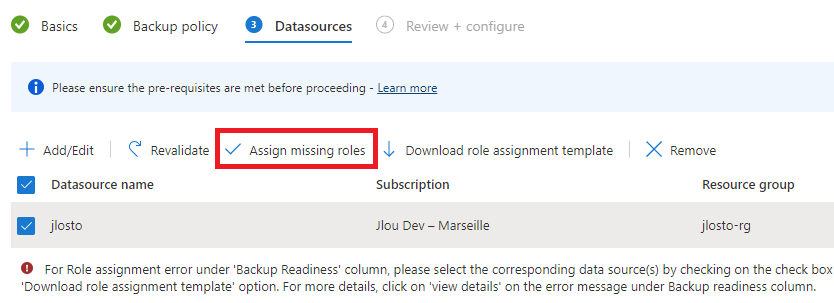
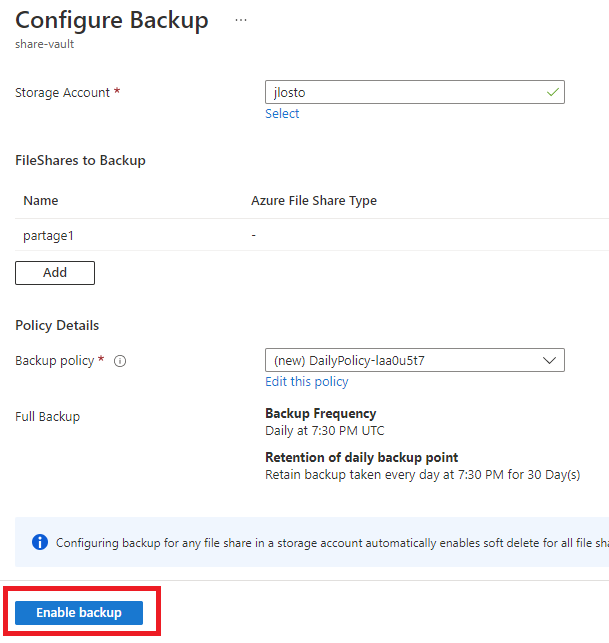
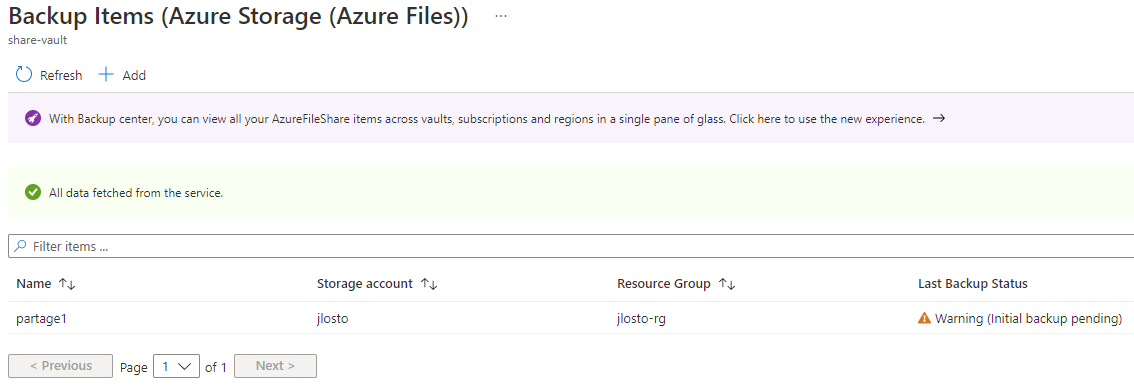
Et c’est là que le bât blesse. Du côté de la sauvegarde, un menu Snapshots est bien présent, mais il ne permet que des déclenchements manuels :
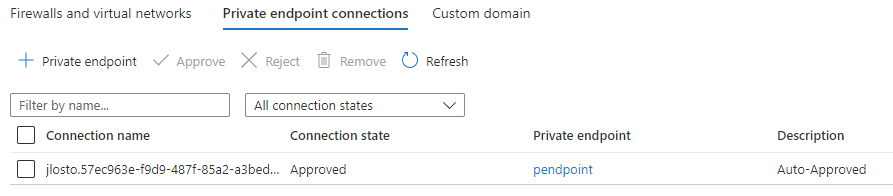
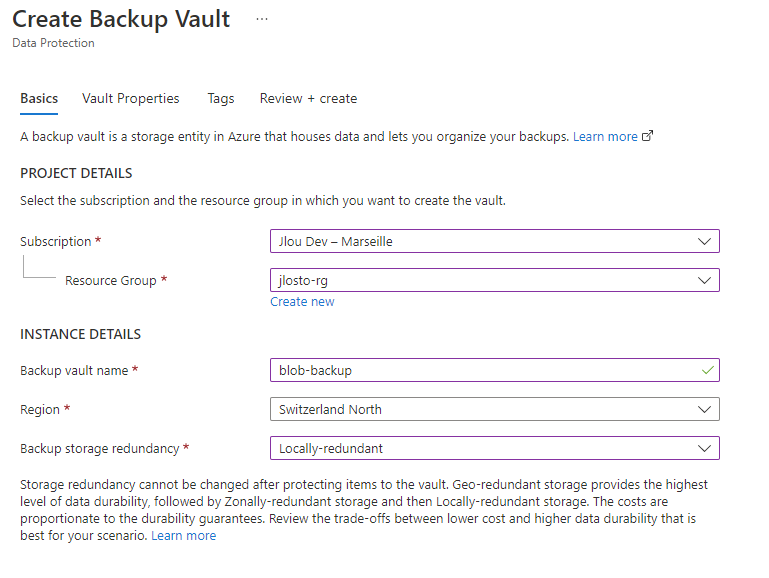
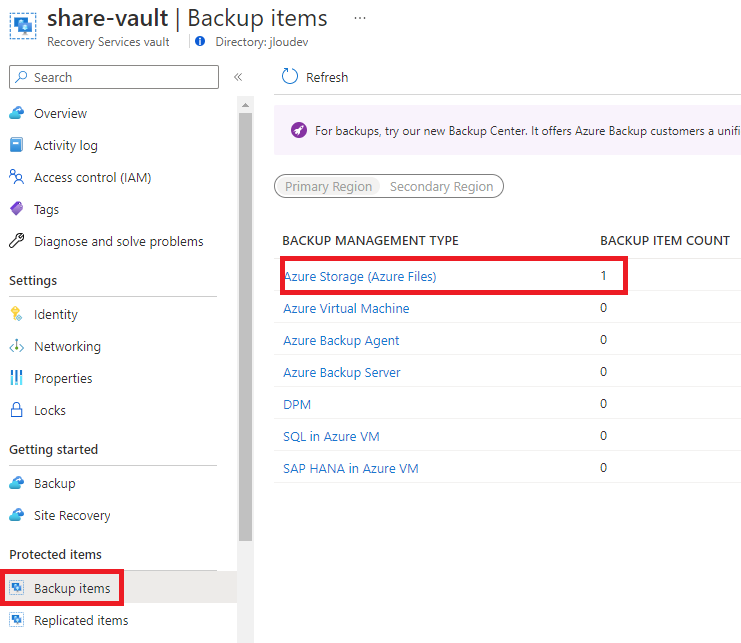
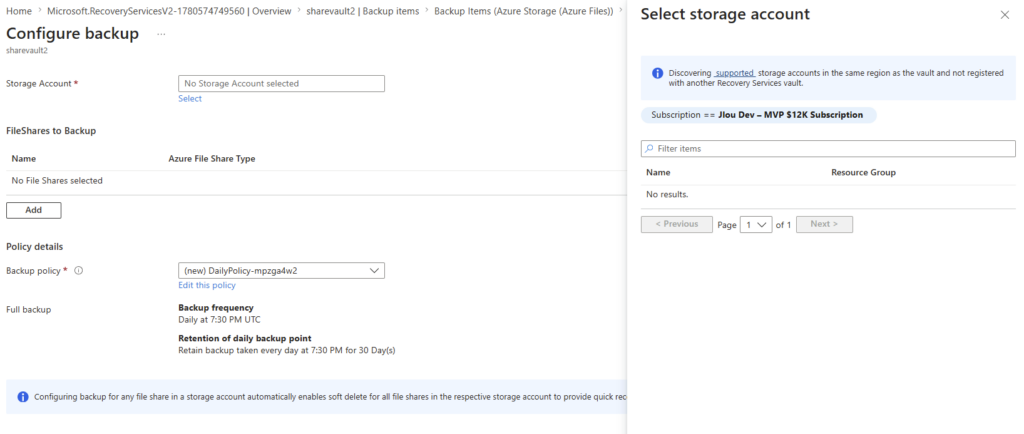
Plus inquiétant : le service de sauvegarde Azure Recovery Services vault ne le voit même pas :
Même chose pour les Backup vaults, qui ne sauvegardent pas ce type de stockage :
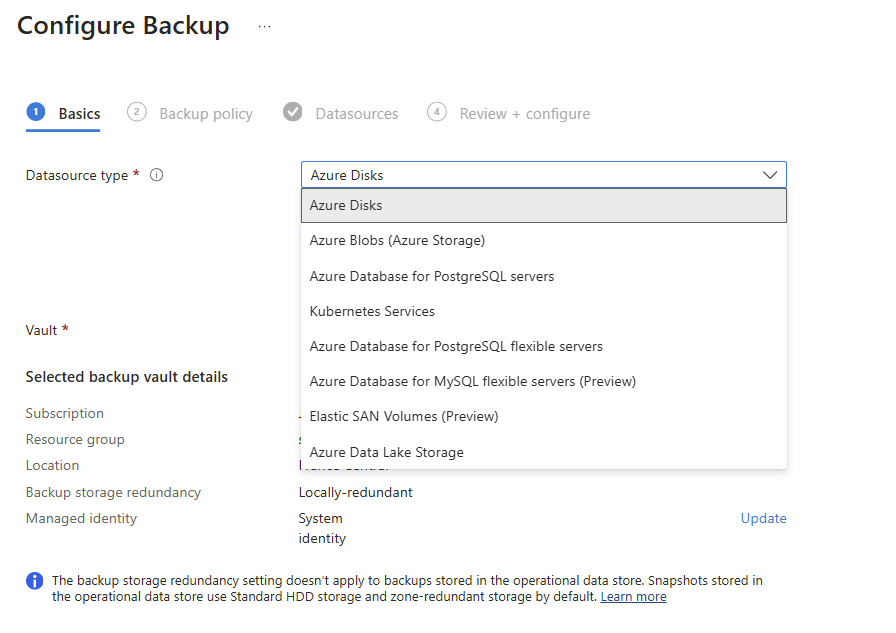
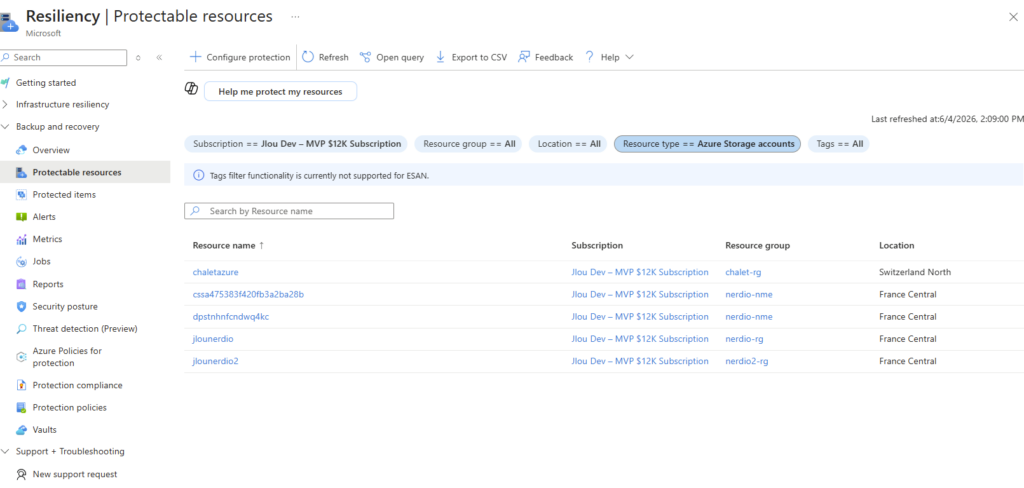
Et même le service Resiliency ne le détecte pas :
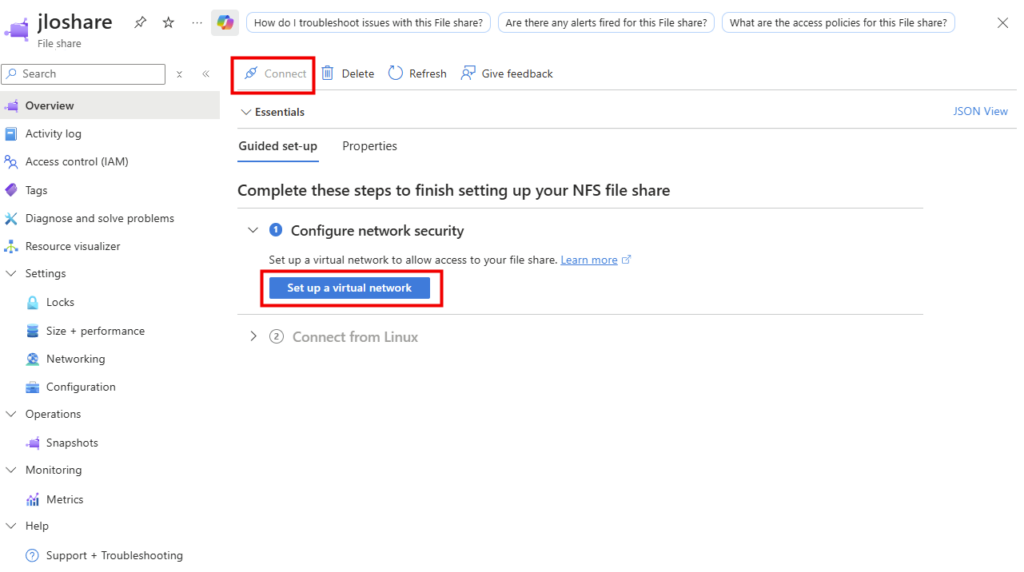
Étape 7 : On monte le partage : la lame Connect
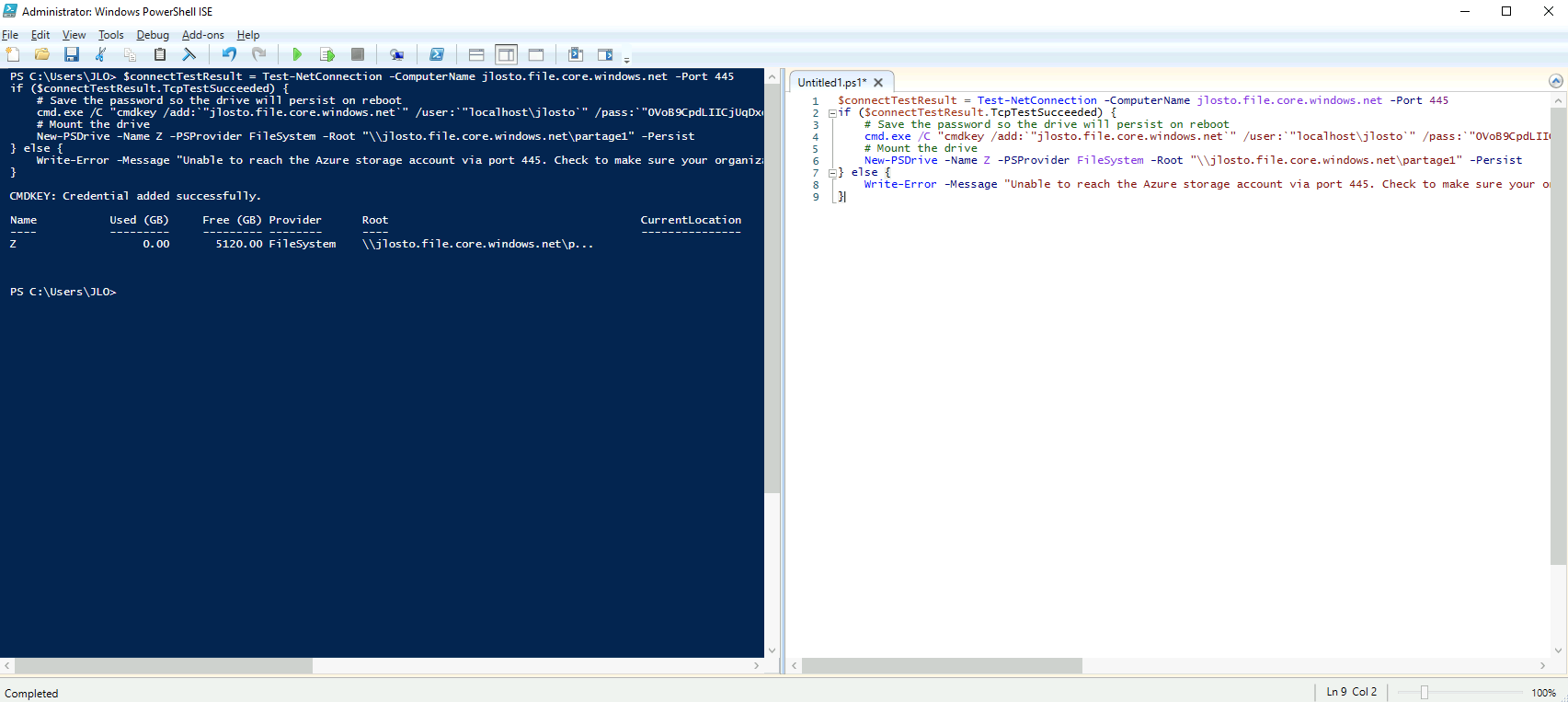
Mais avant d’aller plus loin dans la connexion, l’intégration réseau est obligatoire :
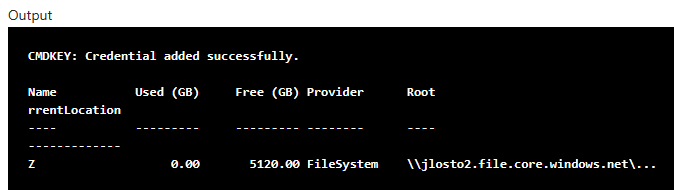
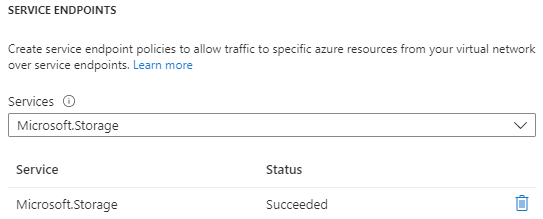
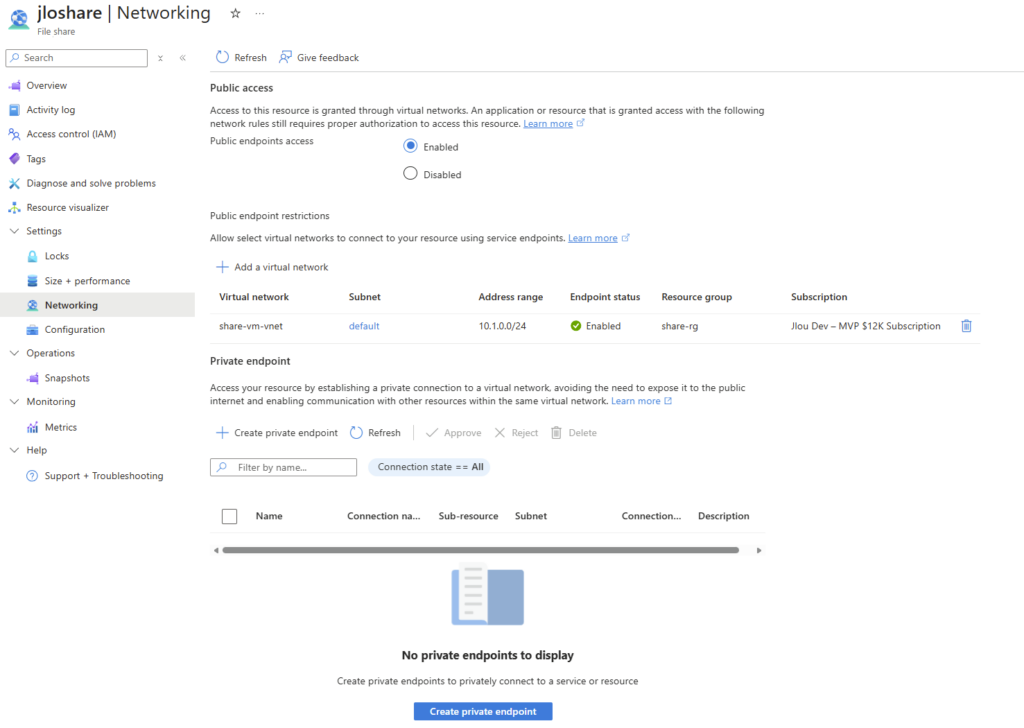
Mon réseau est à présent configuré sur celui de ma machine Linux via un Service Endpoint :
Reste à le monter côté client. La lame Connect du partage vous donne directement la commande de montage NFS, avec le bon endpoint et les bonnes options pré-remplis : vous n’avez qu’à la copier sur votre client Linux :
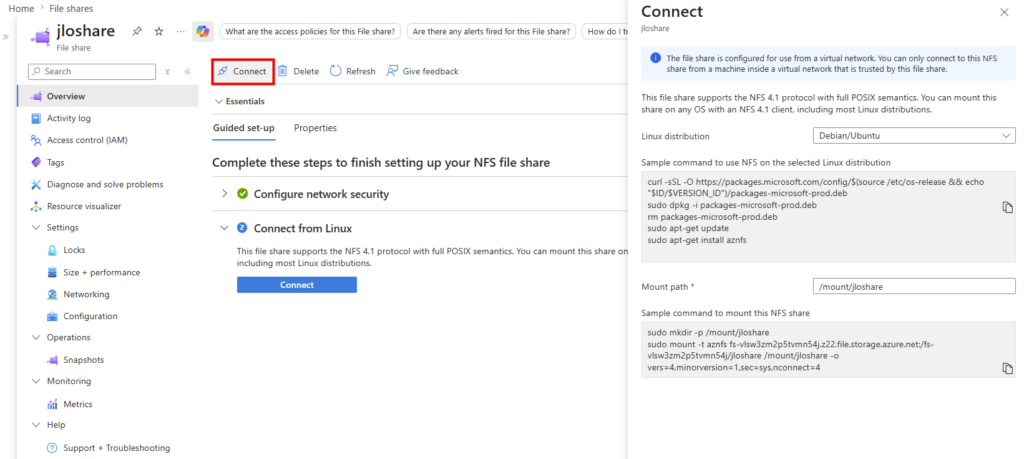
Téléchargez le paquet Microsoft correspondant à votre version d’Ubuntu, afin d’ajouter le dépôt officiel Microsoft (nécessaire pour installer ensuite des outils comme aznfs) :
curl -sSL -O https://packages.microsoft.com/config/$(source /etc/os-release && echo "$ID/$VERSION_ID")/packages-microsoft-prod.deb Installez le paquet téléchargé, puis supprimez l’installeur :
sudo dpkg -i packages-microsoft-prod.deb
rm packages-microsoft-prod.debLa commande sudo apt-get update met à jour la liste des paquets disponibles, puis sudo apt-get install aznfs installe le client Azure NFS (aznfs) depuis le dépôt Microsoft :
sudo apt-get update
sudo apt-get install aznfs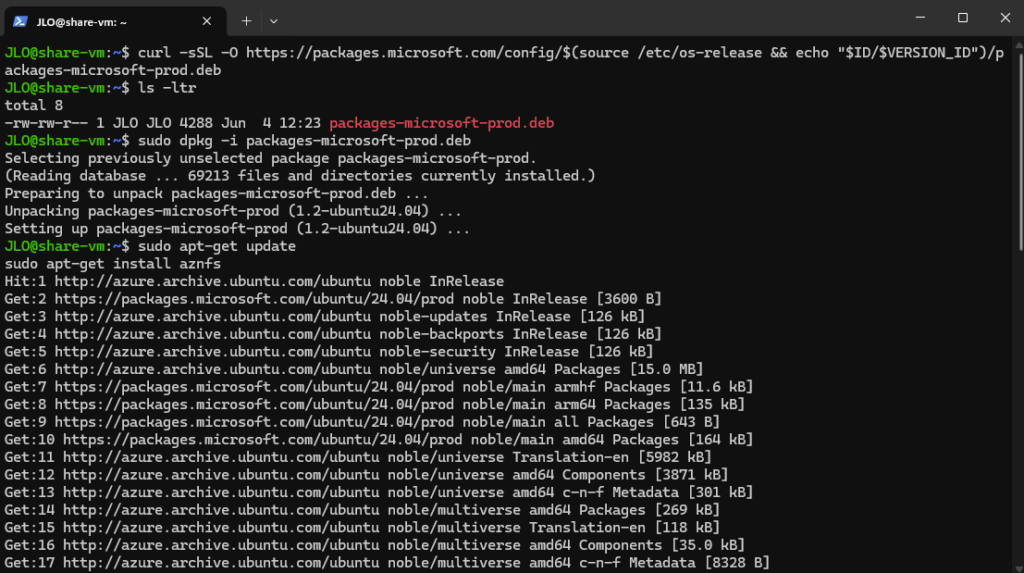
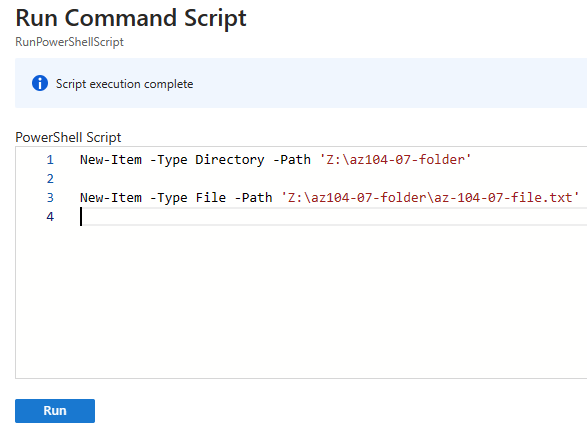
Créez le dossier /mount/jloshare qui servira de point de montage pour le partage NFS :
sudo mkdir -p /mount/jloshare Montez le partage Azure Files en NFS sur votre point /mount/jloshare en utilisant le client optimisé aznfs, avec des options de performance et de compatibilité NFS 4.1 :
sudo mount -t aznfs fs-vlsw3zm2p5tvmn54j.z22.file.storage.azure.net:/fs-vlsw3zm2p5tvmn54j/jloshare /mount/jloshare -o vers=4,minorversion=1,sec=sys,nconnect=4Affichez les systèmes de fichiers montés et filtrez pour vérifier que votre partage jloshare est bien monté :
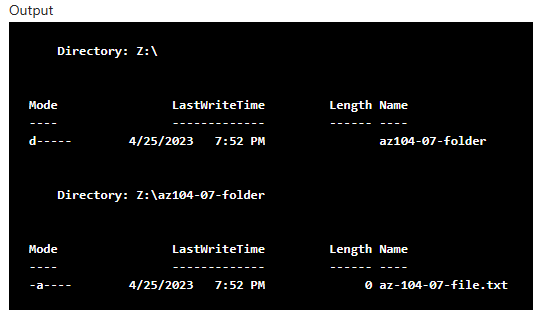
df -h | grep jloshare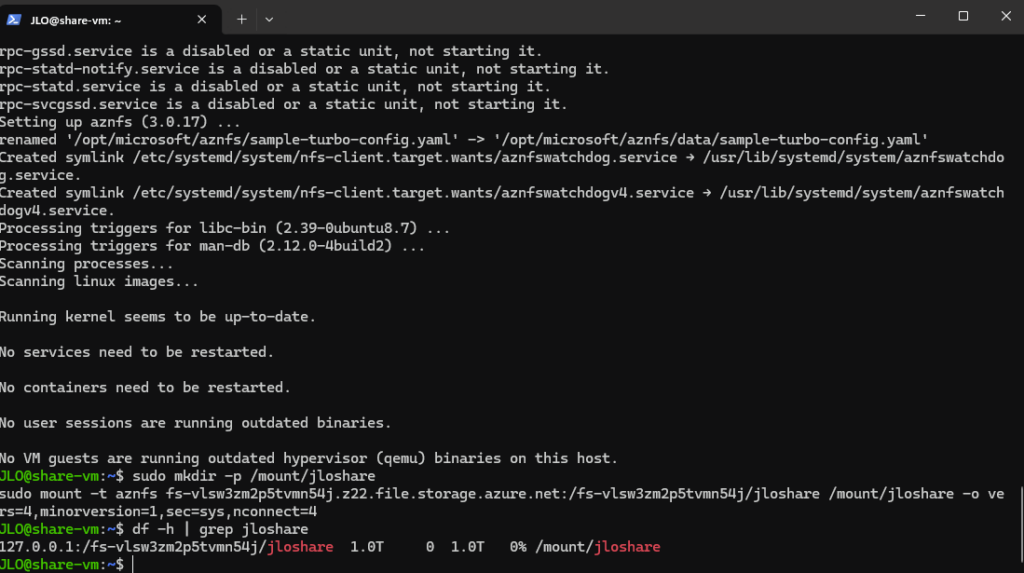
Depuis le portail Azure, la modification du volume du file share apparait immédiatement sur le partage :

5. Ce que vous gagnez concrètement
Le bénéfice tient en un mot : isolation. Tout ce qui était mutualisé au niveau du compte redescend au niveau du partage.
- Performance dédiée : chaque partage a ses propres limites de capacité, d’IOPS et de débit. Plus de voisin bruyant qui mange votre budget perf.
- Control plane par partage : les opérations (création, modification, suppression, snapshots) consomment un quota propre à chaque partage, sur un modèle de « seau » qui se recharge en continu. Les plafonds sont tellement hauts qu’en pratique, les blocages control-plane qu’on connaissait deviennent très improbables.
- Réseau par partage : public endpoint, private endpoints : vous les configurez au niveau du partage, pas d’un compte parent qui impose ses règles à tout le monde.
- Plus de clé de compte : il n’y a tout simplement pas d’account key toute-puissante. Le partage est sa propre ressource, avec sa propre surface de sécurité.
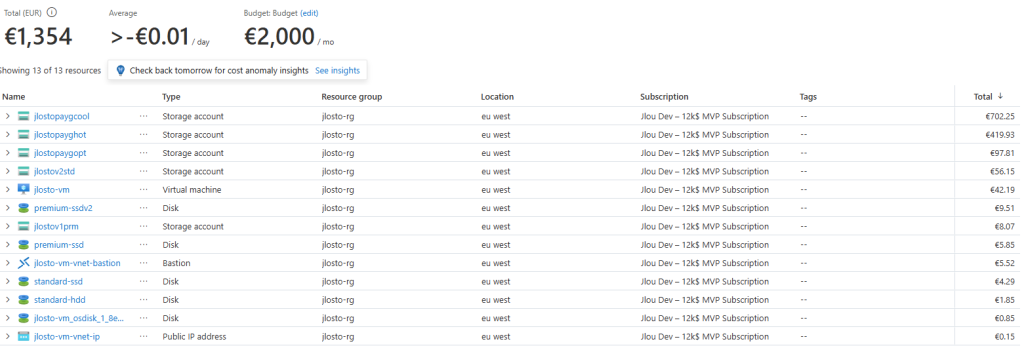
- Facturation et tags granulaires : le coût est porté par le partage (capacité + IOPS + débit), avec ses propres tags. Le showback / chargeback devient enfin trivial.
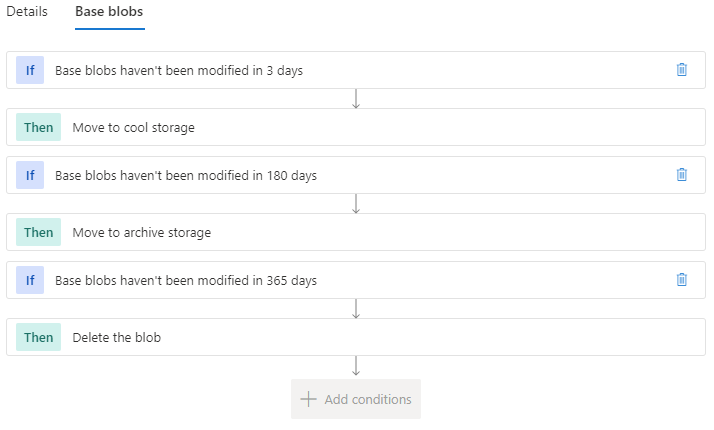
6. Les limites au jour du GA
Soyons honnêtes : « GA » ne veut pas dire « complet ». Le modèle est jeune, et plusieurs fonctionnalités qu’on tient pour acquises côté classique ne sont pas encore là. À l’heure où j’écris, il manque notamment :
- La sauvegarde managée. C’est le point noir : au GA, vous n’avez que des snapshots manuels. Pas d’Azure Backup sur ce type de ressource, ni coffre Recovery Services, ni Backup vault ne le prennent en charge et il n’apparaît pas non plus dans Resiliency (voir la démo §4). La protection de la donnée est entièrement à votre charge.
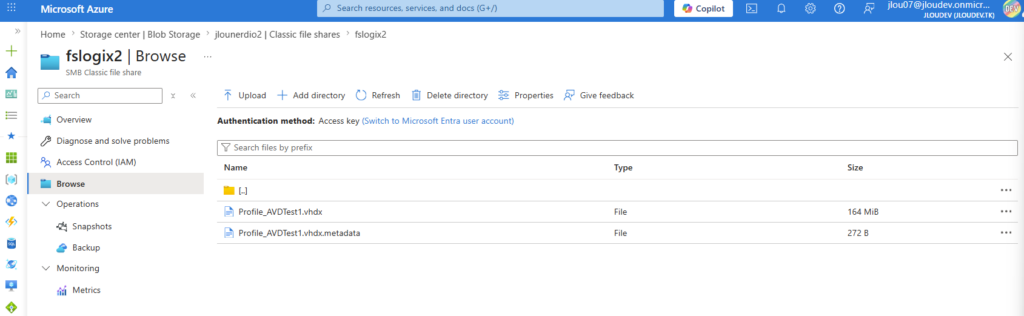
- SMB. C’est NFS 4.1 uniquement. Si vos workloads sont Windows/SMB (AVD + FSLogix, partages bureautiques…), ce modèle ne vous concerne pas encore.
- CMK (clés gérées par le client), soft delete / corbeille, autres protocoles. Tout ça est annoncé comme « à venir », mais pas disponible au GA.
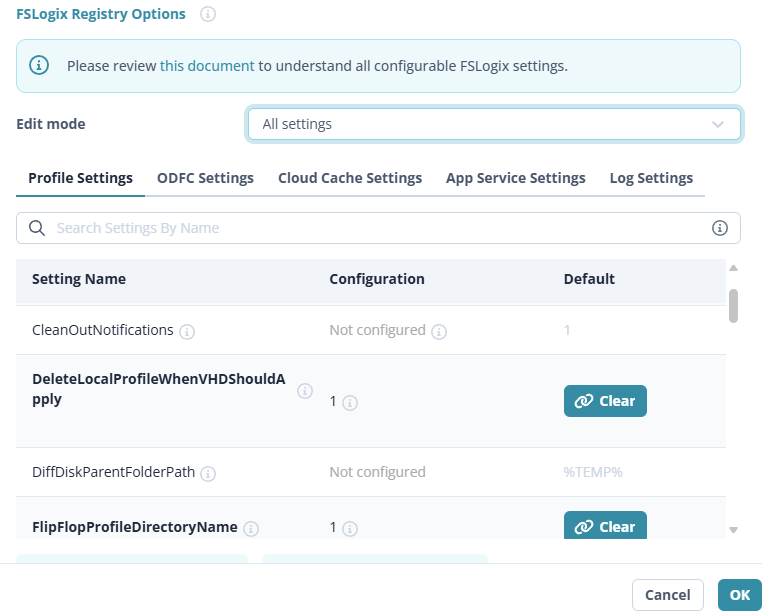
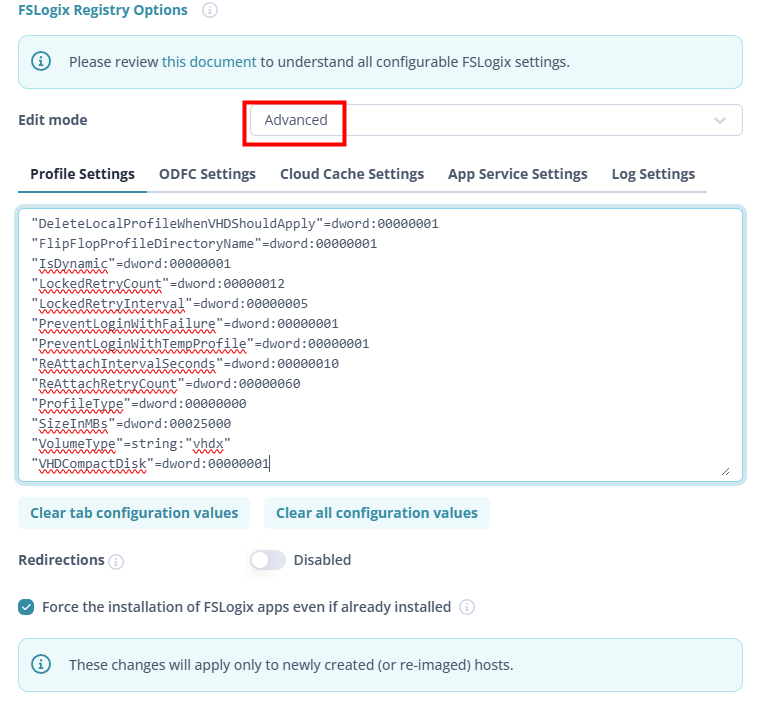
Microsoft.FileShares pour l’instant. Pour de l’AVD, restez sur le compte de stockage classique en Azure Files SMB (provisioned v2 SSD). SMB est annoncé « à venir » sur ce nouveau modèle : le jour où il arrive, l’isolation par partage et la fin de l’account key deviendront très intéressantes pour de l’AVD multi-équipes, mais on n’y est pas.7. Alors, je l’utilise ou pas ?
La règle est simple : si vos besoins rentrent dans le périmètre actuel, c’est le futur, foncez. Sinon, le classique fait toujours le job. Voici comment je le résume.
| Votre besoin | Microsoft.FileShares (nouveau) | Compte de stockage (classique) |
|---|---|---|
| Protocole NFS 4.1 | ✅ Oui | ✅ Oui |
| Protocole SMB | ❌ Pas encore | ✅ Oui |
| Tier SSD / HDD | ✅ SSD / ❌ HDD | ✅ SSD / ✅ HDD |
| Isolation perf / réseau / coût par partage | ✅ Oui | ❌ Mutualisé |
| Sans clé de compte | ✅ Oui | ❌ Clé présente |
| Snapshots manuels | ✅ Oui | ✅ Oui |
| Sauvegarde managée (Azure Backup, Recovery vault, Backup vault) | ❌ Pas encore | ✅ Oui |
| CMK / soft delete | ❌ Pas encore | ✅ Oui |
| IaC, CLI, PowerShell | ✅ Oui | ✅ Oui |
| Scale (partages / abo / région) | ✅ 10 000 | 1 000 |
8. Conclusion
Voilà : cette « nouvelle ressource file share », ce n’est pas un énième renommage, c’est un vrai changement d’architecture. Le partage cesse d’être un sous-objet du compte de stockage pour devenir une ressource Azure de plein droit, avec sa perf, son réseau, sa sécurité et sa facture à lui. À la clé : une isolation propre, la fin de la clé de compte toute-puissante, un coût traçable partage par partage et une vraie compatibilité infrastructure-as-code.
Les trois pièges à retenir avant de vous lancer :
- La sauvegarde, c’est le gros trou du GA : Snapshots manuels uniquement, et aucune prise en charge par Azure Backup (Recovery Services vault, Backup vault) ni par Resiliency. La protection de la donnée est à votre charge, n’y mettez rien de critique sans stratégie maison.
- NFS 4.1 / SSD uniquement : pas de SMB (donc pas de FSLogix / AVD), pas de HDD.
- Facturation provisioned v2 : dimensionnez correctement capacité, IOPS et débit, vous payez le provisionné.
Si vous êtes sur du NFS, foncez tester en lab : c’est clairement la direction que prend Azure Files. Pour le reste, le classique a encore de beaux jours devant lui, le temps que la sauvegarde managée, SMB et les autres briques manquantes débarquent.
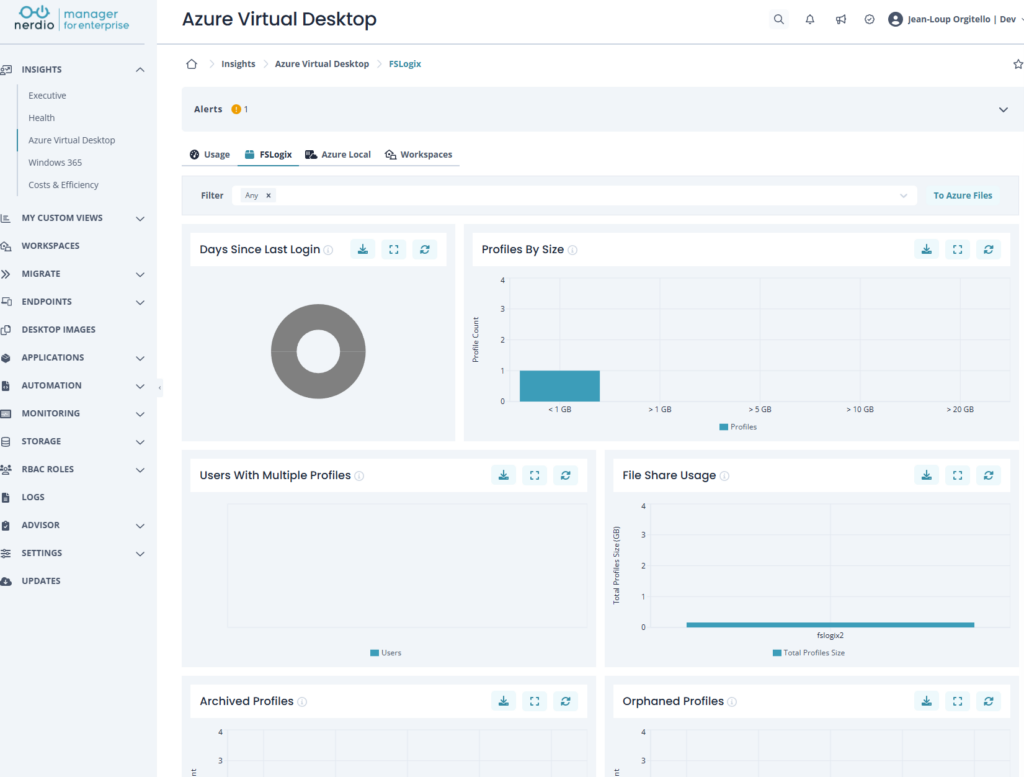
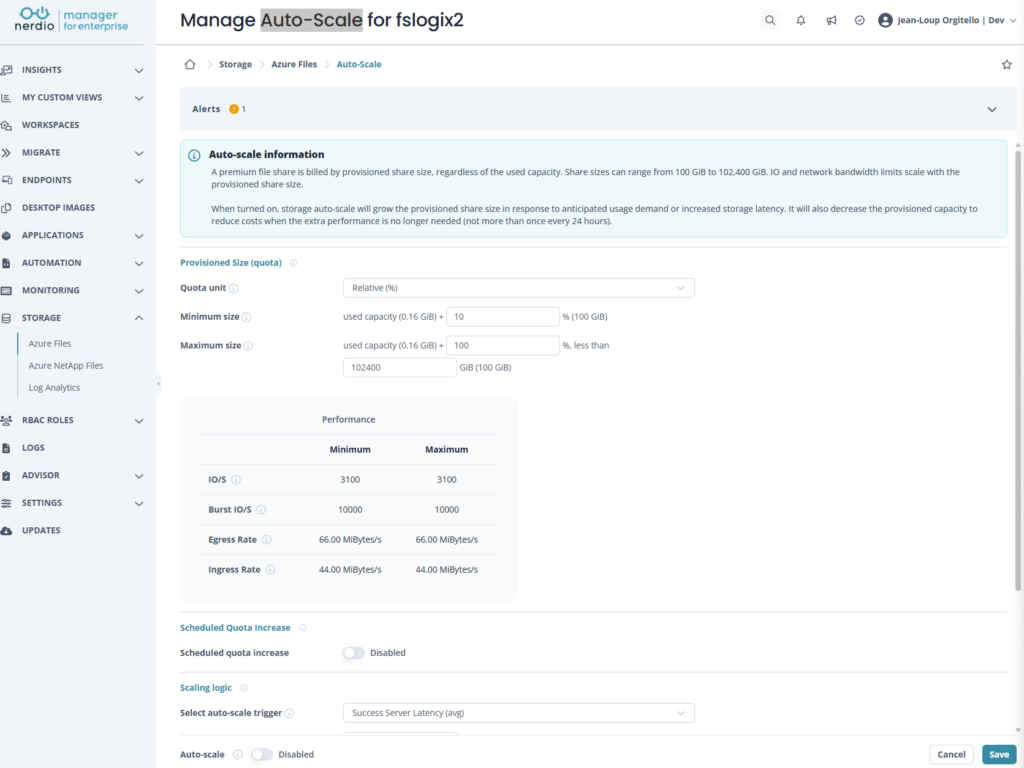
Dernier point, et il pèse lourd dès qu’on dimensionne du provisionné : la capacité réservée, vous la payez. Autant ne pas voir trop large « au cas où » et faire grossir le partage automatiquement quand le besoin arrive.
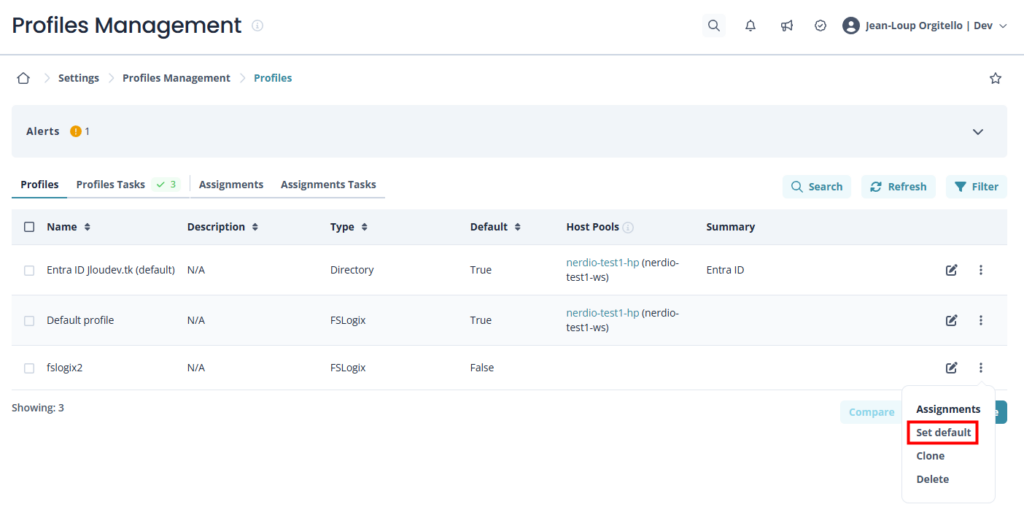
C’est exactement le sujet que je creuse côté FSLogix. À lire dans la foulée : Autoscalez le stockage FSLogix : faire grossir automatiquement le quota de vos partages Azure Files.


![Entra ID → Enterprise Applications — bouton Grant admin consent for [tenant] sur l'app du storage account](https://jlou.eu/wp-content/uploads/2026/05/image-347-1024x511.png)